示例选择器
⼀旦我们有了示例数据集,就需要考虑提示中应该有多少个示例。关键的权衡是,更多的示例通常会提高性能,但更大的提示会增加成本和延迟。超过某个阈值,太多示例可能会开始混淆模型。而且LLM有上下文窗口,一旦提示词过多,导致模型的输出推理不行了。
在 LangChain 中,示例选择器就可以帮我们从⼀组【示例的集合】中根据具体策略选择正确的【示例子集】构建少样本提示。
选择策略有:
• Length :根据特定【长度】内可以容纳的数量选择示例。
• Similarity :使用输入和示例之间的【语义相似性】来决定选择哪些示例
MMR :使用输入和示例之间的【最大边际相关性】来决定要选择哪些示例。
• Ngram :使用输入和示例之间的【ngram 重叠】来决定要选择哪些示例。
按长度选择示例(Length)
当我们担心构造提示时,将超过上下文窗口长度,根据特定长度内可以容纳的数量选择示例。在LangChain中LengthBasedExampleSelector:
to_messages是PromptValue的方法,
FewShotPromptTemplate继承自BasePromptTemplate,BasePromptTemplate继承自PromptValue的方法。
输出结果,
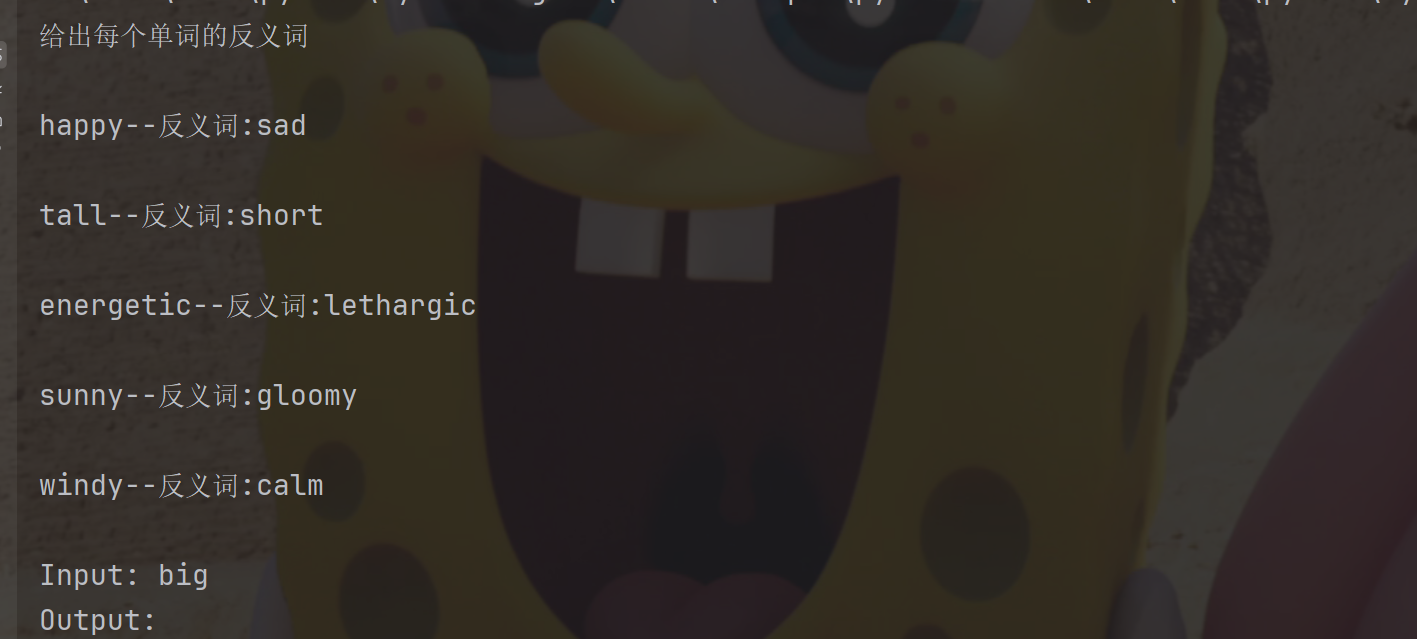
这里注意,我们给少样本提示词,给的不再是完整实例,而是示例选择器选择后的示例
可以看到,示例选择器将所有的示例都选择了,因为还没有超过设置的示例最大长度,长度计算是根据字符串中由换行符或空格分隔的"单词"数量得到的(默认)。
接下来让我们加⼊长输入,验证长度选择器筛选示例。

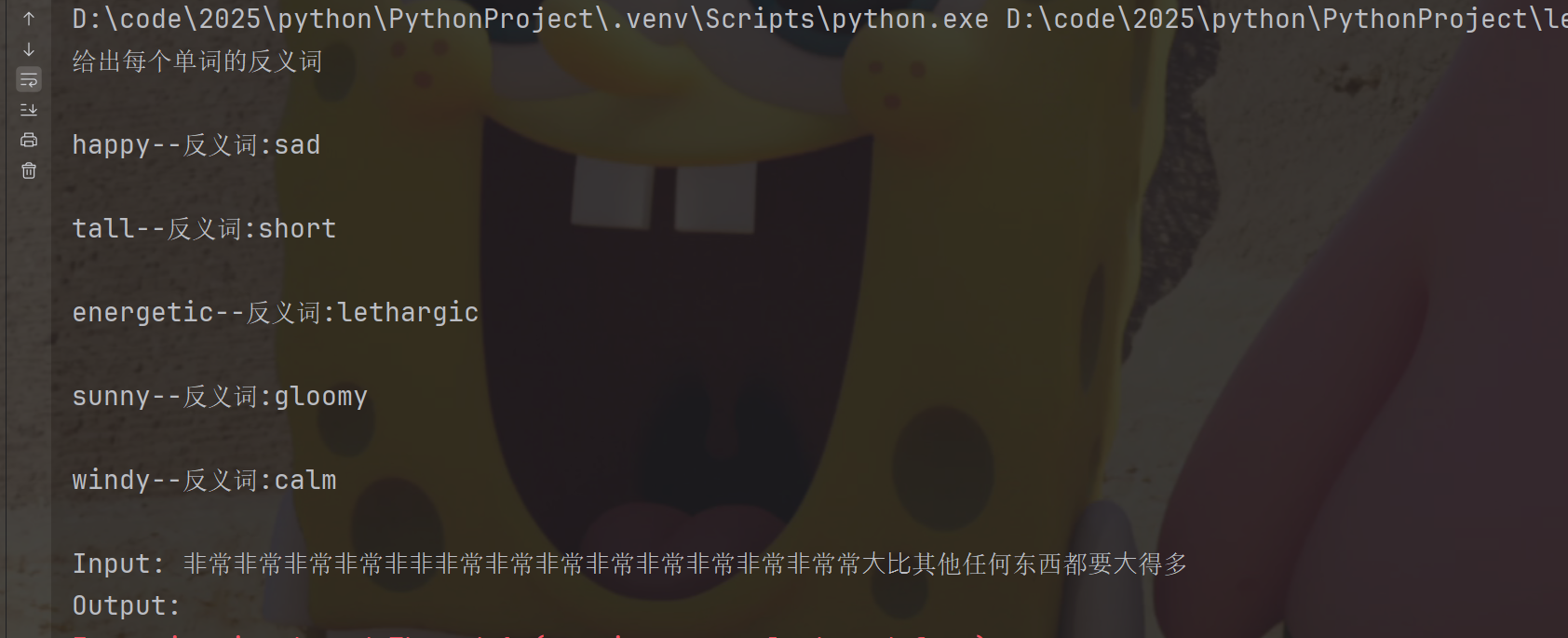
确实是按照\n,或者空格分割的
下面,我们将
max_length设置为5,意味着最多5个空格+换行,发现,少了最后一个windy,符合预期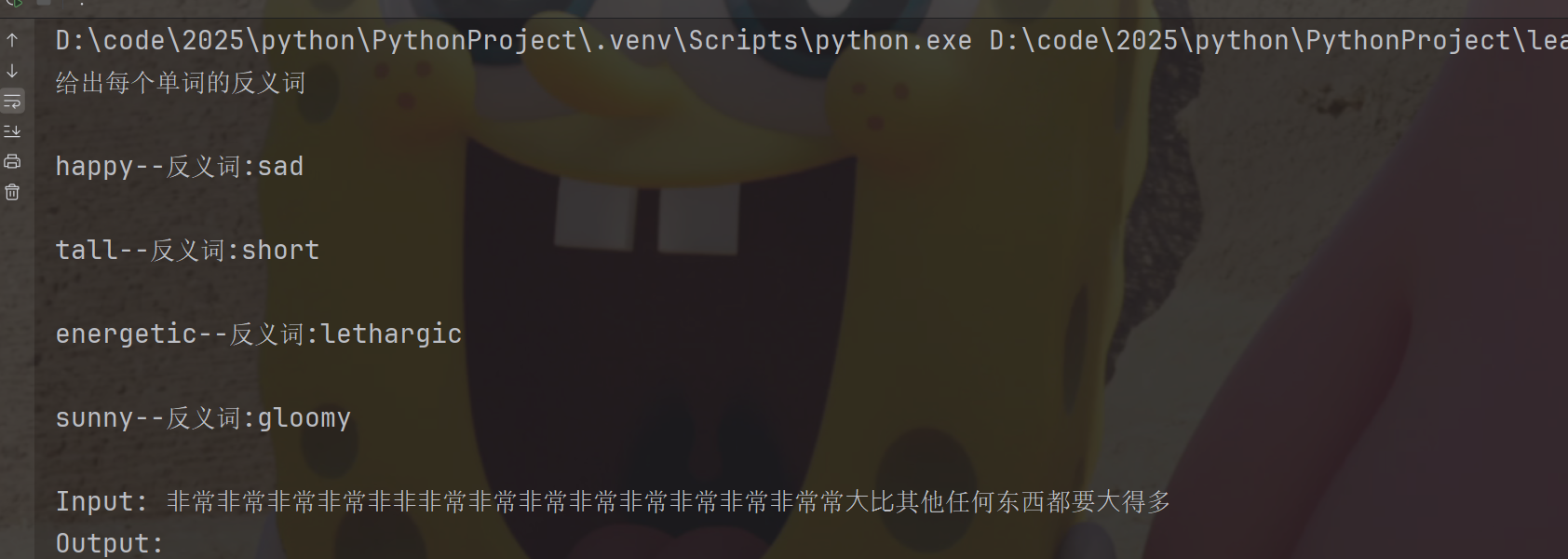
按语义相似性选择示例(Similarity)
什么是语义相似?它是衡量⽂本在【含义上】的接近程度。例如下述两段⽂本:
text1 = "我喜欢猫" text2 = "我讨厌狗"
这两段文本表面相似度低,但语义上都是表达对动物的态度。
LangChain 能根据输⼊和示例之间的语义相似性来决定选择哪些示例,它通过查找与输入具有最⼤余弦相似性的嵌⼊示例来实现这⼀点。我们之前学的嵌入式模型,如果两个输入语义相似,那么在数学上他们的直接距离/余弦角是相近的,我们可以用数学衡量,而这里我们借助embedding API interface。
对于上面同样的例子,我们把示例选择器从长度换成语义相似:
我们使用
SemanticSimilarityExampleSelector的from_examples这个方法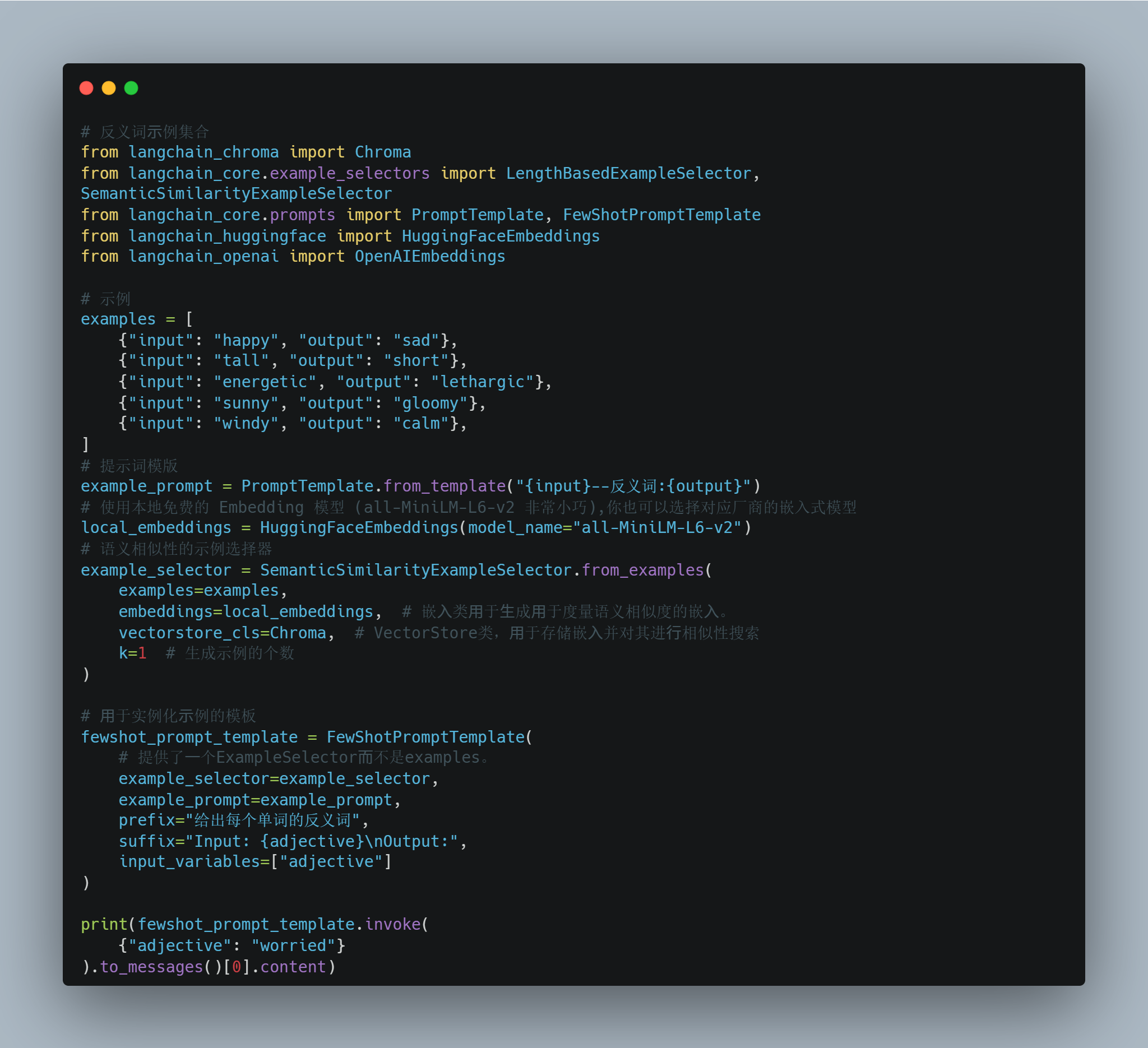

if k = 2:

按最大边际相关性选择示例(MMR)
什么是最⼤边际相关性?它是⼀种重新排序算法,它使用语义相似性作为基础工具,从⼀个候选集中挑选出⼀组既能代表查询主题又彼此多样化的结果
那语义相似性和MMR有啥区别?举个例子:
语义相似性】就像面试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打⼀个分数。
• 【最大边际相关性】就像团队经理(MMR算法)要组建⼀个团队。目标是选出⼀组"精华"结果,
而不是⼀个单⼀结果。就像我们刷视频,语义相似性就是根据我们的喜爱,刻画画像,精准推荐给用户最喜欢的,而MMR,则会推荐用户喜欢的视频的前提下,还会推荐一下其他方面的,以免"信息茧房"
而他们俩的使用场景:
语义相似性使用场景:搜索引擎的基础排序、重复检测、聚类、语义搜索。
MMR 使用场景:
◦ 推荐系统:推荐与用户兴趣相关但⼜不同类型的物品,避免"信息茧房"。
◦ ⽂档摘要:从长文档中选择能代表主旨⼜包含不同信息的句子,避免摘要内容重复。
◦ RAG (检索增强生成):在从知识库检索完⼀堆相关文档后,使用 MMR 进行去重和多样化筛选,
再交给LLM生成答案,能有效提升答案质量和减少幻觉问题。
LangChain 提供了按最大边际相关性选择示例的能力:
MaxMarginalRelevanceExampleSelector它的使用方式和SemanticSimilarityExampleSelector类似
python
# 最大边际相关性选择实例
local_embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples=examples,
embeddings=local_embeddings, # 嵌⼊类⽤于⽣成⽤于度量语义相似度的嵌⼊。
vectorstore_cls=Chroma, # VectorStore类,⽤于存储嵌⼊并对其进⾏相似性搜索,向量数据库
k=2 # 生成示例的个数
)他会推荐和worried相关的内容,还会推荐一些无关的:
比如,让他推荐三个:
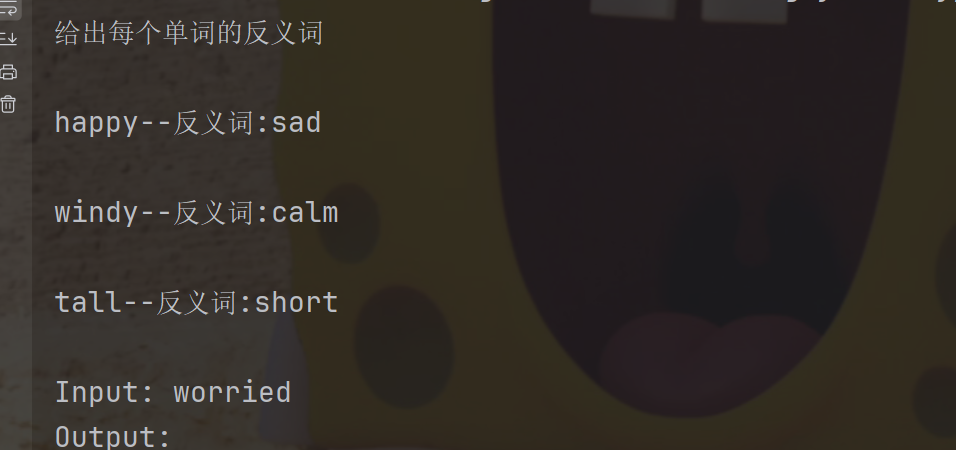
ngram 重叠选择示例(Ngram)
什么是【ngram】?ngram 指⼀个文本序列中连续的 n 个词(word) 或字符(character)
什么是【ngram 重叠】?通过计算它们之间共同拥有的 ngram 数量来⼀种衡量两段文本相似度的方法。这种方式只对比两段文本是否在文本方式一样,比如非常!= 很。
所以有了语义 ngram 重叠?不再比较词本身,而是比较词背后的语义向量(Embedding)。也就是说,它不是看两个词 苹果 和 iPhone 的字面是否相同,而是计算它们在语义空间中的向量是否相似。 如果相似度超过某个阈值,就认为它们"重叠"了
所以它常常用于剽窃检测, 能够发现那些改换了词汇但保留了核心思想的"智能"剽窃。
LangChain中的Ngram是NGramOverlapExampleSelector。他主要有三个属性,其中最重要的是threshold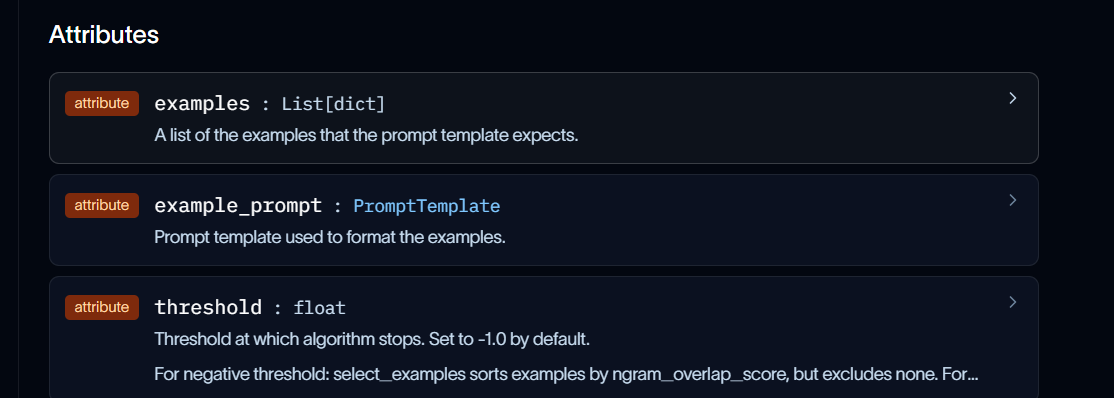
这个属性
对于负阈值:按 重叠分数 对示例进行排序,但不排除任何示例。
◦ 对于等于 0.0 的阈值:按 重叠分数 进行排序,并排除与输入没有 ngram 重叠的示例。
◦ 对于大于 1.0 的阈值:排除所有示例,并返回⼀个空列表。
、举个例子:
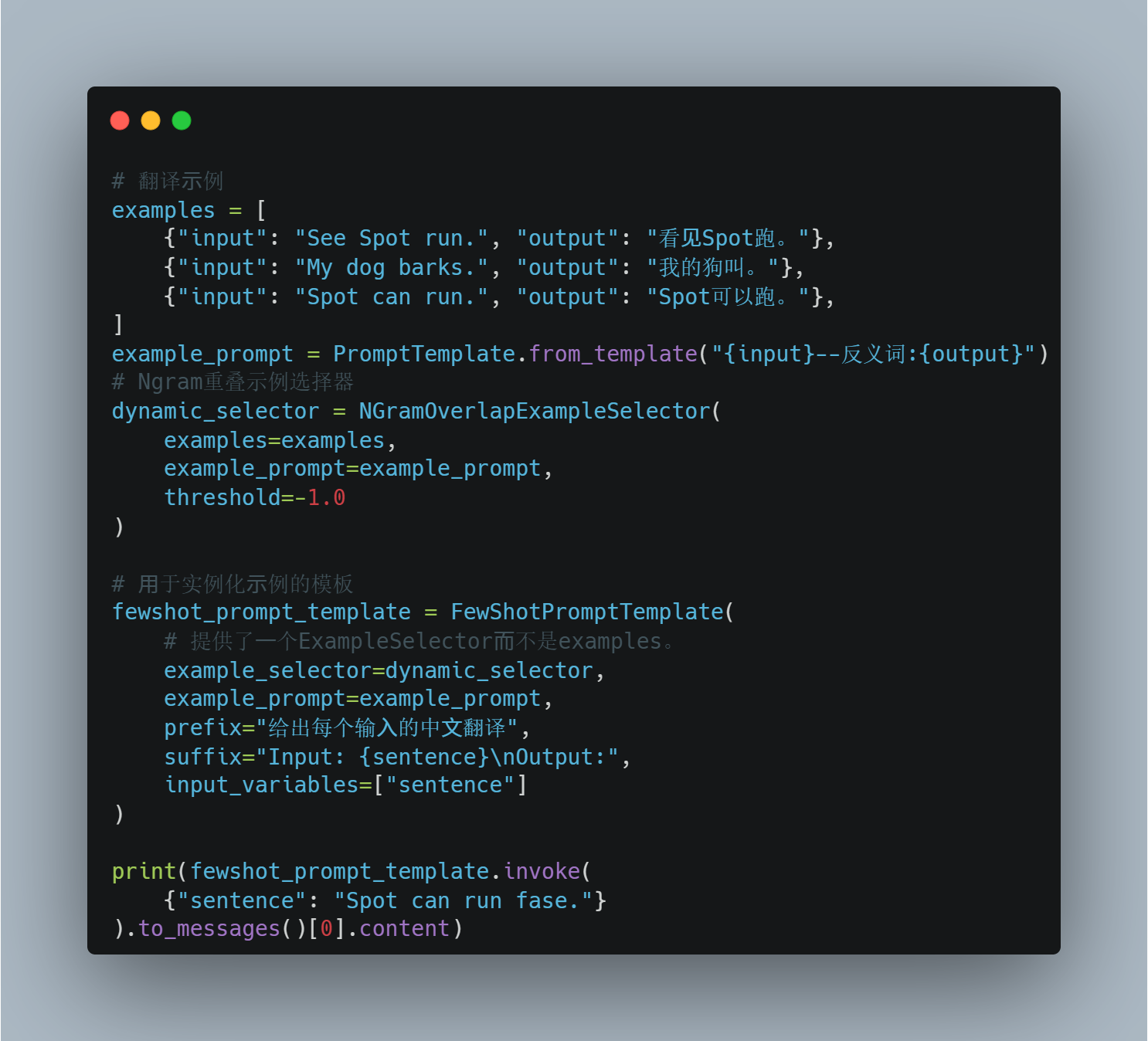
如果threshold = -1,示例都保留:

threshold = 0,示例只保留相关的

threshold = 1,示例全部排除
threshold 的范围也可以小数浮动调整,看具体的选择示例对模型的效果吧