文章目录
- [力扣 56.合并区间](#力扣 56.合并区间)
- [力扣 160.相交链表](#力扣 160.相交链表)
- 踩坑记录

力扣 56.合并区间
题目描述
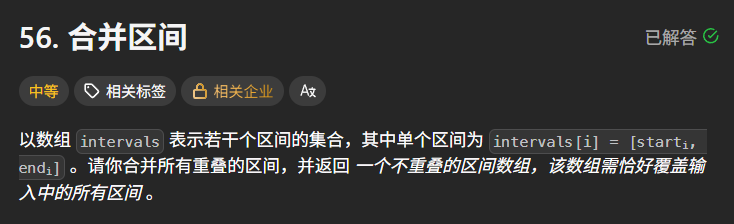
示例 1:
输入:intervals = \[1,3,2,6,8,10,15,18]
输出:\[1,6,8,10,15,18]
解释:区间 1,3 和 2,6 重叠, 将它们合并为 1,6.
示例 2:输入:intervals = \[1,4,4,5]
输出:\[1,5]
解释:区间 1,4 和 4,5 可被视为重叠区间。
示例 3:输入:intervals = \[4,7,1,4]
输出:\[1,7]
解释:区间 1,4 和 4,7 可被视为重叠区间。
提示:1 <= intervals.length <= 104
intervalsi.length == 2
0 <= starti <= endi <= 104
思路简述
由于输入的区间数组是无序的,若直接暴力合并区间,需要O(n²)的时间复杂度。因此我们可以先按区间的左端点进行升序排序,让存在重叠可能性的区间彼此相邻,最终仅需一次线性遍历即可完成全量区间的合并。
完成排序后,我们可以保证数组中后序区间的左端点一定大于等于前序区间的左端点,不会出现后续区间整体落在前置区间左侧的情况。此时遍历过程中仅会遇到以下三种场景(为了便于理解,下述说明将区间展开进行直观表述)
为了便于遍历统计,同时避免修改原输入数组导致难度增加,我们可以额外开辟一个结果数组ret,并将排序后的第一个区间先加入结果数组完成初始化,再从第二个区间开始遍历处理。
- 两个数组部分重叠:
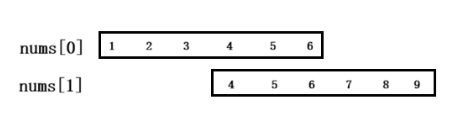
该场景下,结果数组中最后一个区间的右端点,大于等于当前遍历区间的左端点,且小于当前遍历区间的右端点。此时两个区间存在部分重叠,只需更新结果数组中最后一个区间的右端点,将其扩展为当前遍历区间的右端点即可完成合并。
-
前置区间完全覆盖当前区间:
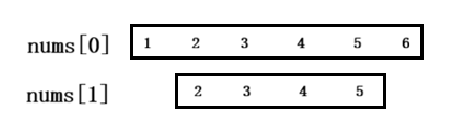
该场景下,结果数组中最后一个区间的右端点,大于等于当前遍历区间的右端点。此时当前区间被完全覆盖在已有区间内,无需进行任何操作,直接跳过当前区间即可。
-
两个区间无重叠部分:
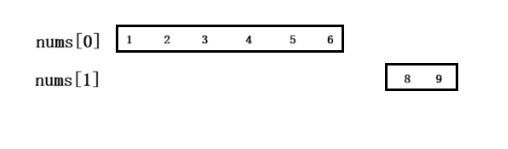
该场景下,结果数组中最后一个区间的右端点,小于当前遍历区间的左端点。此时两个区间无任何重叠,直接将当前遍历区间加入结果数组即可。
代码实现
cpp
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& in) {
// 空输入处理:如果输入区间为空,直接返回空结果
if (in.empty()) return {};
// 按区间的起始值升序排序,这是合并区间的前提(保证后续可顺序合并)
sort(in.begin(), in.end(), [](const vector<int>& a, const vector<int>& b){
return a[0] < b[0]; // 排序规则:前一个区间的起始值 < 后一个则排在前面
});
// 初始化结果数组,先放入第一个区间作为合并的基准
vector<vector<int>> ret;
ret.push_back(in[0]);
// j 指向结果数组中当前正在处理(待合并)的最后一个区间
int j = 0;
// 从第二个区间开始遍历所有输入区间
for(int i = 1; i < in.size(); i++)
{
// 情况1:当前区间与待合并区间重叠(待合并区间的结束 >= 当前区间的起始)
// 且当前区间的结束更大,需要更新待合并区间的结束值
if(ret[j][1] >= in[i][0] && ret[j][1] < in[i][1])
ret[j][1] = in[i][1];
// 情况2:当前区间与待合并区间完全不重叠(待合并区间的结束 < 当前区间的起始)
// 将当前区间加入结果数组,并更新j指向新的待合并区间
else if(ret[j][1] < in[i][0])
{
ret.push_back(in[i]);
j++;
}
// 情况3:当前区间被待合并区间完全包含(ret[j][1] >= in[i][1]),无需处理
}
return ret;
}
};复杂度分析
- 时间复杂度:O(nlogn)
排序操作的时间复杂度为O(nlogn),后续仅需一次线性遍历处理区间,整体时间复杂度由排序操作主导。 - 空间复杂度:O(n)
除排序算法本身所需的栈空间外,仅额外开辟了存储结果的数组。最坏情况下(输入区间无任何重叠),结果数组需要存储全部n个区间,因此空间复杂度为O(n)。
力扣 160.相交链表
题目描述

示例 1:
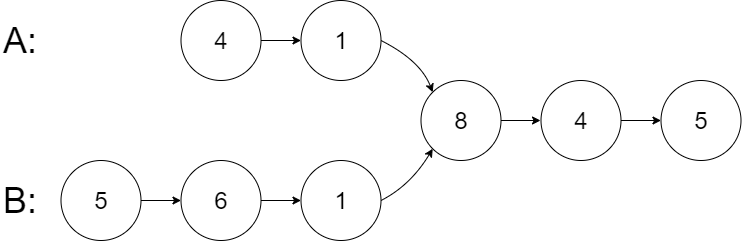
输入:intersectVal = 8, listA = 4,1,8,4,5, listB = 5,6,1,8,4,5, skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 4,1,8,4,5,链表 B 为 5,6,1,8,4,5。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
--- 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
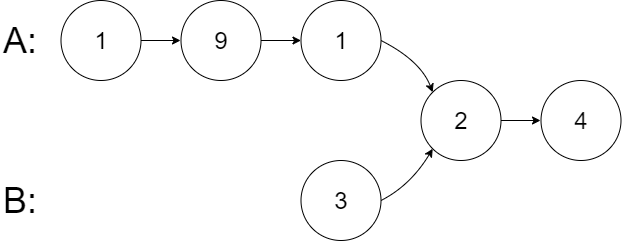
输入:intersectVal = 2, listA = 1,9,1,2,4, listB = 3,2,4, skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 1,9,1,2,4,链表 B 为 3,2,4。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
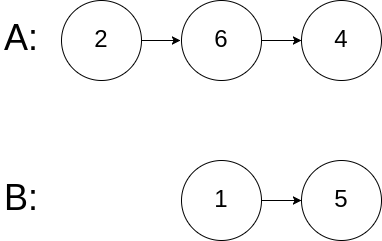
输入:intersectVal = 0, listA = 2,6,4, listB = 1,5, skipA = 3, skipB = 2
输出:No intersection
解释:从各自的表头开始算起,链表 A 为 2,6,4,链表 B 为 1,5。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
思路简述
方法一:哈希表+遍历
该方法基于哈希集合的快速查找特性实现,核心逻辑分为两次遍历:
- 第一次遍历链表A,将链表中的所有节点存入哈希集合;
- 第二次遍历链表B,逐个检查当前节点是否存在于哈希集合中。
由于我们按链表从头至尾的顺序遍历,第一个匹配到的节点,就是两个链表的相交起始节点。若遍历完链表B仍无匹配节点,则说明两个链表不存在相交。
方法二:双指针遍历
该方法可以在O(1)额外空间内实现需求,我们先用一个通俗的类比理解核心逻辑:
小明从家出发走3米到达T型路口,小刚从家出发走5米到达同一个T型路口,路口到共同终点的距离为3米。若两人以相同速度同时出发,想要在途中相遇并同时抵达终点,只需让两人都走完全程「自家到终点 + 对方家到终点」,总路程完全一致,最终必然会在T型路口(相交点)相遇。
对应到算法中,我们设置两个指针分别从链表A和链表B的头节点出发同步遍历:
- 若指针遍历完当前链表,则立即跳转到另一个链表的头节点继续遍历;
- 若两个链表存在相交节点,两个指针最终会在相交节点相遇;
- 若两个链表无相交节点,两个指针最终会同时走到两个链表的末尾空节点,循环终止。
我们可以用示例图片手动模拟一下,会发现当两个指针走的路程相同时,经过一轮的交换会同步
代码实现
方法一:哈希表+遍历
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 定义哈希集合,用于存储链表 A 的节点指针(内存地址)
// 关键注意:链表相交的本质是「两个链表指向同一个内存地址的节点」,而非节点值相同!
unordered_set<ListNode*> hash;
// 用临时指针遍历链表 A,避免直接修改原头节点 headA
ListNode* newheadA = headA;
while(newheadA != nullptr)
{
hash.insert(newheadA); // 将当前节点的内存地址插入哈希集合
newheadA = newheadA->next; // 指针后移,遍历下一个节点
}
// 用临时指针遍历链表 B,同理避免修改原头节点 headB
ListNode* newheadB = headB;
while(newheadB != nullptr)
{
// 检查当前节点的地址是否存在于哈希集合中
// 若存在,说明该节点是两个链表的相交起始节点,直接返回
if(hash.find(newheadB) != hash.end())
return newheadB;
newheadB = newheadB->next; // 指针后移,继续检查下一个节点
}
// 遍历完链表 B 仍未找到相交节点,说明两链表不相交,返回 nullptr
return nullptr;
}
};方法二:双指针遍历
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 前置判断:若任一链表为空,必然无相交节点,直接返回 nullptr
if(headA == nullptr || headB == nullptr)
return nullptr;
// 定义两个临时指针,分别从两个链表的头节点开始遍历
// 用临时指针避免修改原链表的头节点 headA 和 headB
ListNode* newheadA = headA;
ListNode* newheadB = headB;
// 核心循环:当两个指针未相遇时持续遍历
// 循环终止的两种情况:
// 1. 两链表相交:指针会在「相交起始节点」处相遇(newheadA == newheadB 且非空)
// 2. 两链表不相交:指针会同时走到两个链表的末尾(均为 nullptr),此时也满足相等
while(newheadA != newheadB)
{
// 指针移动逻辑(关键!):
// 若当前指针走完了自己的链表(到达 nullptr),则跳转到另一个链表的头节点继续走
// 若未走完,则继续向后遍历下一个节点
// 原理:两指针走的总路程均为「链表A长度 + 链表B长度」,因此必然同时到达交点或末尾
newheadA = newheadA == nullptr ? headB : newheadA->next;
newheadB = newheadB == nullptr ? headA : newheadB->next;
}
// 循环结束后,newheadA 和 newheadB 指向同一位置:
// 若相交则为「相交起始节点」,若不相交则为 nullptr,直接返回即可
return newheadA;
}
};复杂度分析
- 时间复杂度:两种方法均为 O(m + n),其中m、n分别为链表A和链表B的节点个数,两个方法均仅需对两个链表各遍历一次。
- 空间复杂度:
- 哈希表法:O(m),最坏情况下需要存储链表A的全部m个节点。
- 双指针法:O(1),仅使用了两个临时指针,无额外的空间开销。
踩坑记录
- 合并区间的边界判断中,
ret[j][1] >= in[i][0]必须包含等号!题目明确区间端点重合(如1,4和4,5)属于可合并的场景,遗漏等号会导致端点相邻的区间无法正确合并。 - 相交链表的双指针解法不会出现死循环:当两链表无相交节点时,两个指针最终会同时遍历完两个链表,同时指向空节点,此时
pA == pB的循环终止条件成立,不会无限遍历。
这这篇博客,有没有帮到正在为算法题头大的你呀?从合并区间的排序小妙招,到相交链表的双指针巧解,连面试官最爱揪的边界踩坑点都帮你一一标出来咯,下次面试再碰到这两道高频题,保证能稳稳拿下,丝毫不慌!
如果这份超用心的题解有帮到你的话,可不可以动动小手,给这篇内容点一个大大的赞呀?顺便也点一下收藏,下次刷题复盘的时候,就能一下子找到这份算法攻略啦~
还有还有!千万别忘了关注 up 主哦!后续还会更新更多力扣经典题的超详细拆解!
