前言
在开发社交类应用的关系模块时,我们经常会遇到这样一个问题:用户点下"关注"按钮,背后到底要做什么?如果只是简单地把关系写入数据库,那太简单了。但真实场景中,一次关注操作需要同步更新多个地方------关注列表、粉丝列表、用户计数、缓存,甚至可能还要推送到推荐系统、数据仓库。
更棘手的是,这些下游系统可能分布在不同的存储介质中:MySQL、Redis、Kafka、ES......如何在保证主业务高可用的前提下,让这些下游数据最终保持一致?如何在系统演进过程中,不影响已有代码就能接入新的下游?
这篇文章,我想和大家分享一下我在关系模块中落地的一套"一主多从 + 事件驱动"的架构方案。这套方案的核心思想很简单:只有一个主表是业务真理,其他所有下游都是这个真理的投影。通过这种方式,我们不仅彻底解决了困扰已久的"双写不一致"问题,还让系统具备了极高的可扩展性和可恢复性。
一、从"双写"困境说起
1.1 一个简单的关注操作,背后有多复杂?
假设我们正在设计一个社交应用的关注功能。用户 A 关注用户 B,表面上只是一次简单的关系变更,但落到系统层面,至少需要处理以下几件事:
- 在关注表中插入一条记录,表示 A 关注了 B
- 在粉丝表中插入一条记录,表示 B 多了一个粉丝 A
- 更新用户计数,A 的关注数 +1,B 的粉丝数 +1
- 更新缓存,把这条新关系加入关注列表和粉丝列表的 ZSet 中,保证查询时能实时看到
这个流程看起来没什么问题,但它隐藏着一个巨大的风险:双写不一致 。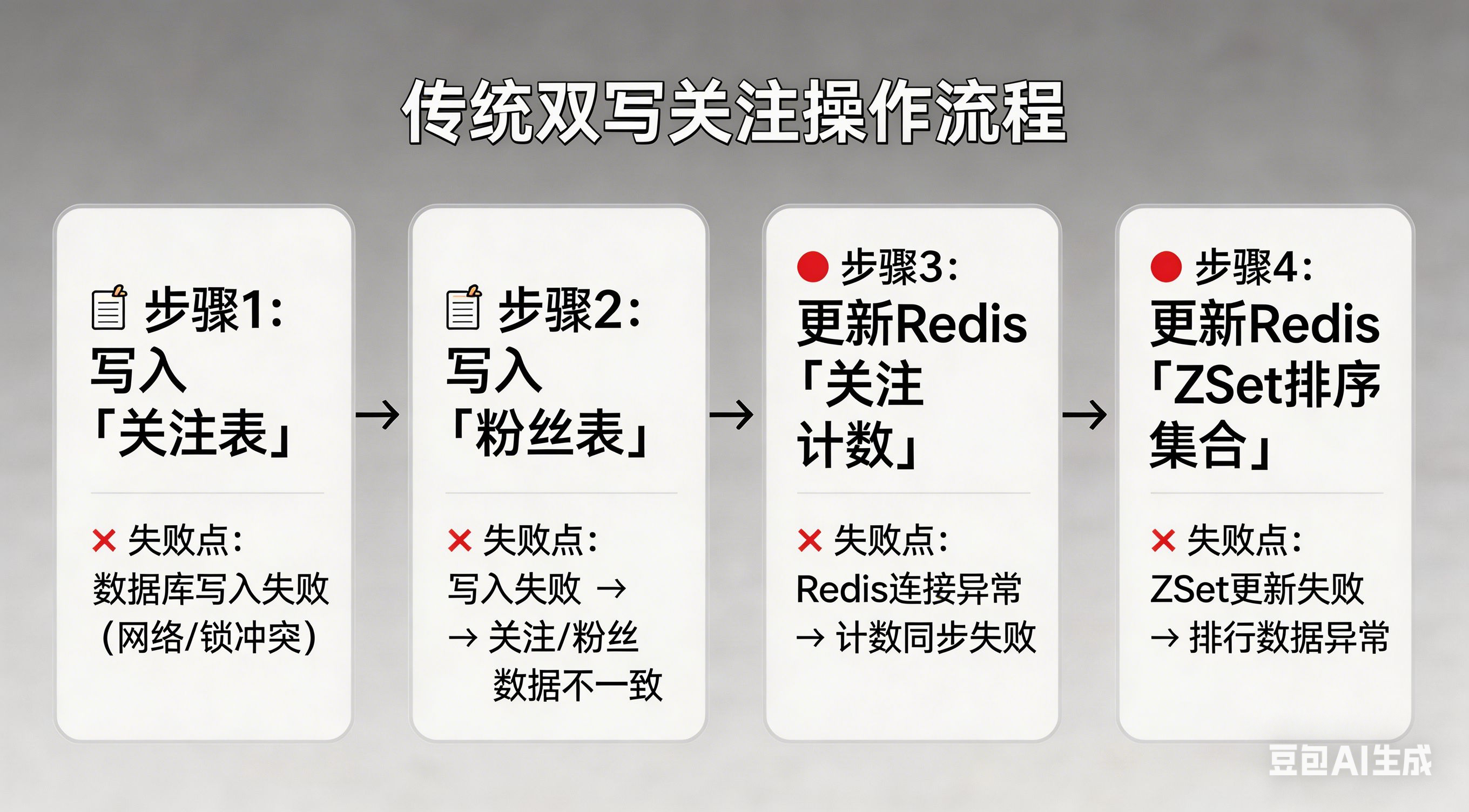
1.2 双写不一致是怎么发生的?
最常见的实现方式是:在同一个业务方法里,依次调用这些操作。如果所有操作都成功,那万事大吉。但问题在于,这些操作跨越了不同的存储系统:
- 关注表、粉丝表在 MySQL 中
- 计数和缓存可能在 Redis 中
- 如果还发了 MQ 通知其他下游,那就更多了
这些操作无法被同一个事务管理。当我们在代码里依次调用它们时,可能会出现这样的情况:
关注表写入成功 ✅
粉丝表写入成功 ✅
Redis 计数更新 ✅
Redis ZSet 更新 ❌(网络抖动,超时了)结果就是:用户已经成功关注了(主表有记录),但粉丝列表缓存里看不到这个人。虽然用户刷新后可能会从数据库重新加载,但体验已经打了折扣。更严重的是,如果粉丝表也失败了,那就会产生"我关注了你,但你那边看不到我"的数据不一致。
1.3 为什么不能用一个分布式事务搞定?
有的朋友可能会说:那我把所有操作放在一个分布式事务里,用 XA 或者 TCC 不就行了?
理论上可行,但实践中代价极高:
- 性能差:分布式事务涉及两阶段提交,需要多次网络交互,锁时间变长,吞吐量急剧下降
- 架构复杂:需要引入事务协调者,增加系统的复杂度和维护成本
- 高可用变差:任何一个参与者(比如 Redis)挂掉,整个事务就会阻塞或回滚,主业务也会受影响
- 强耦合:主业务代码和下游存储耦合在一起,以后想加一个新的下游(比如数据仓库),就得改主流程代码
在社交关系这种高并发场景下,这种方案基本不可行。
1.4 换个思路:让主业务轻装上阵
上面的困境,本质上是因为我们试图在一次操作中同步完成所有事情。但如果换个角度思考:主业务只需要保证核心数据落地,其他事情可以异步去做。
这就是事件驱动架构的核心理念。把一次关注操作拆分成两部分:
- 写路径:只做最核心的事------把关注关系写入主表,同时记录下"发生了什么事件"
- 读路径:下游系统根据事件,自行更新自己的投影表/缓存/计数
这样,主业务的复杂度大幅降低,下游的失败不会影响主业务,而且新增下游只需要订阅事件,完全不需要改主流程。
但这里又出现一个新问题:如何保证事件一定能可靠地传递给下游?
二、Outbox 模式:事件可靠传递的关键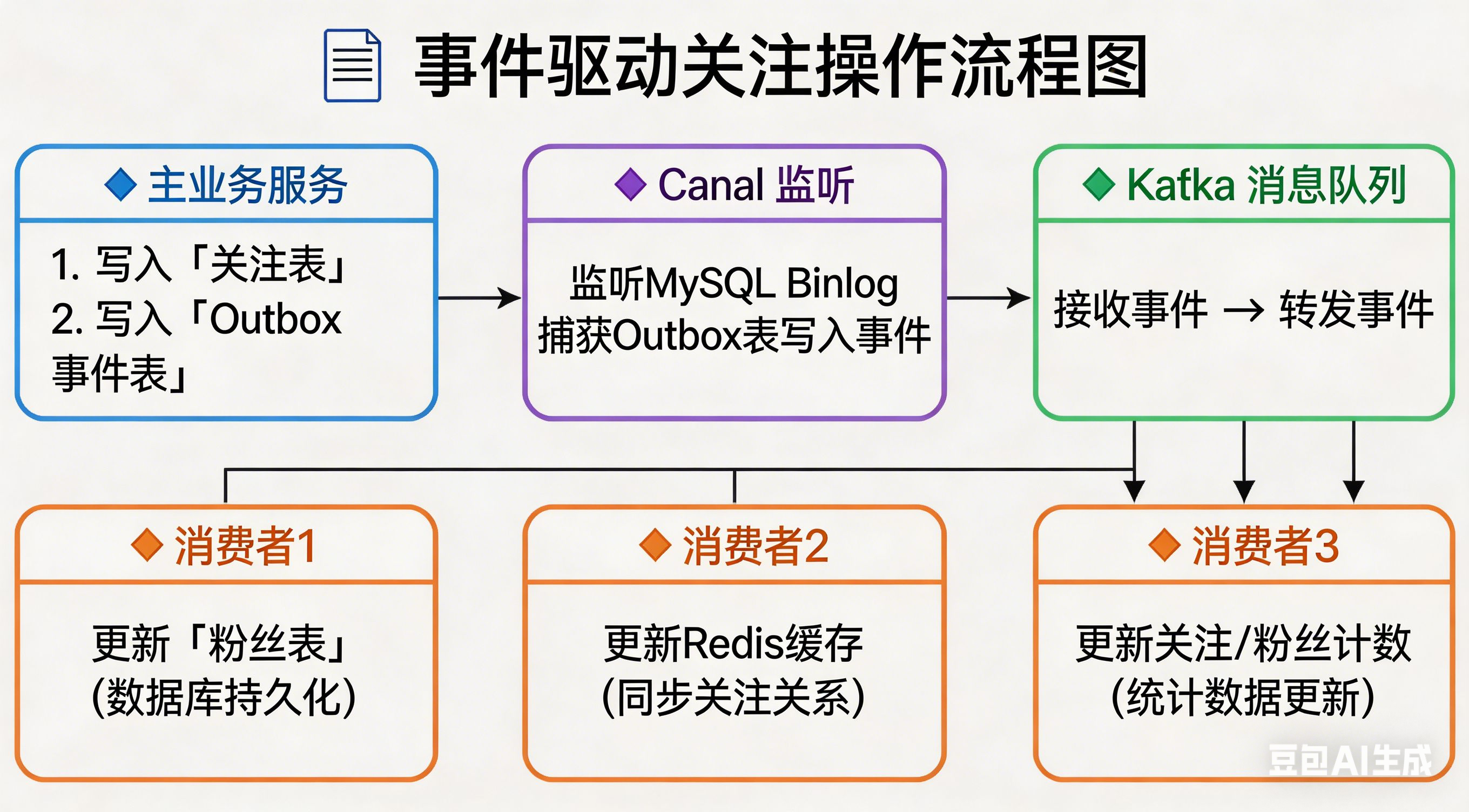
2.1 直接发 MQ 的隐患
如果我们把事件直接发给 MQ,可能会遇到这样的问题:
关注表写入成功 ✅
发送 MQ 消息 ❌(网络超时)主表有数据,但消息没发出去,下游永远不知道这次关注操作。数据不一致就此产生。
2.2 Outbox 模式的思路
Outbox 模式的核心思想是:把"写入事件"和"写入业务数据"放在同一个本地数据库事务中。
也就是说,我们在插入关注记录的同时,也往一个叫 outbox 的表中插入一条事件记录。这两个操作要么同时成功,要么同时失败。
java
@Transactional
public void follow(long from, long to) {
// 1. 插入关注表
mapper.insertFollowing(...);
// 2. 插入 outbox 表(同一个事务)
outboxMapper.insert(...);
}这样一来,只要主表写成功了,事件就一定落盘了。即使后续 MQ 挂了、下游系统挂了,事件都稳稳地存在数据库中,绝不会丢。
2.3 Outbox 表的设计
我们的 outbox 表结构如下:
sql
CREATE TABLE outbox (
id BIGINT UNSIGNED NOT NULL,
aggregate_type VARCHAR(64) NOT NULL, -- 业务模块,如 "following"
aggregate_id BIGINT UNSIGNED NULL, -- 业务实体ID,如关系ID
type VARCHAR(64) NOT NULL, -- 事件类型,如 "FollowCreated"
payload JSON NOT NULL, -- 事件详情(JSON格式)
created_at TIMESTAMP(3) NOT NULL,
PRIMARY KEY (id),
KEY idx_agg (aggregate_type, aggregate_id),
KEY idx_ct (created_at)
);几个关键字段的作用:
aggregate_type:区分不同业务模块,方便以后扩展(比如订单模块也可以用同一张 outbox 表)type:事件类型,下游根据这个决定要做什么操作payload:最重要的字段,存的是序列化后的完整事件数据,下游拿到后直接使用,无需再查库
三、Canal:从数据库到消息队列的桥梁
3.1 事件落盘了,怎么通知下游?
现在事件已经稳稳地存在 outbox 表里了,接下来要解决的问题是:如何把事件从 outbox 表发送给下游系统?
一种方案是写一个定时任务,轮询 outbox 表,把未发送的事件捞出来发出去。但轮询有两个问题:
- 延迟高:轮询间隔决定了事件延迟,间隔短则数据库压力大,间隔长则事件实时性差
- 有状态:需要记录哪些事件已经发送过,增加了复杂性
有没有更好的方案?让数据库主动告诉我们有新事件了。
3.2 利用 MySQL 的 binlog
MySQL 的 binlog 是数据库的"操作日志",所有数据变更都会被记录在里面。如果我们能实时订阅 binlog,就能第一时间感知到 outbox 表有新数据写入。
这就像给数据库装了一个"监听器",一旦有变化,马上就能收到通知。
3.3 Canal 登场
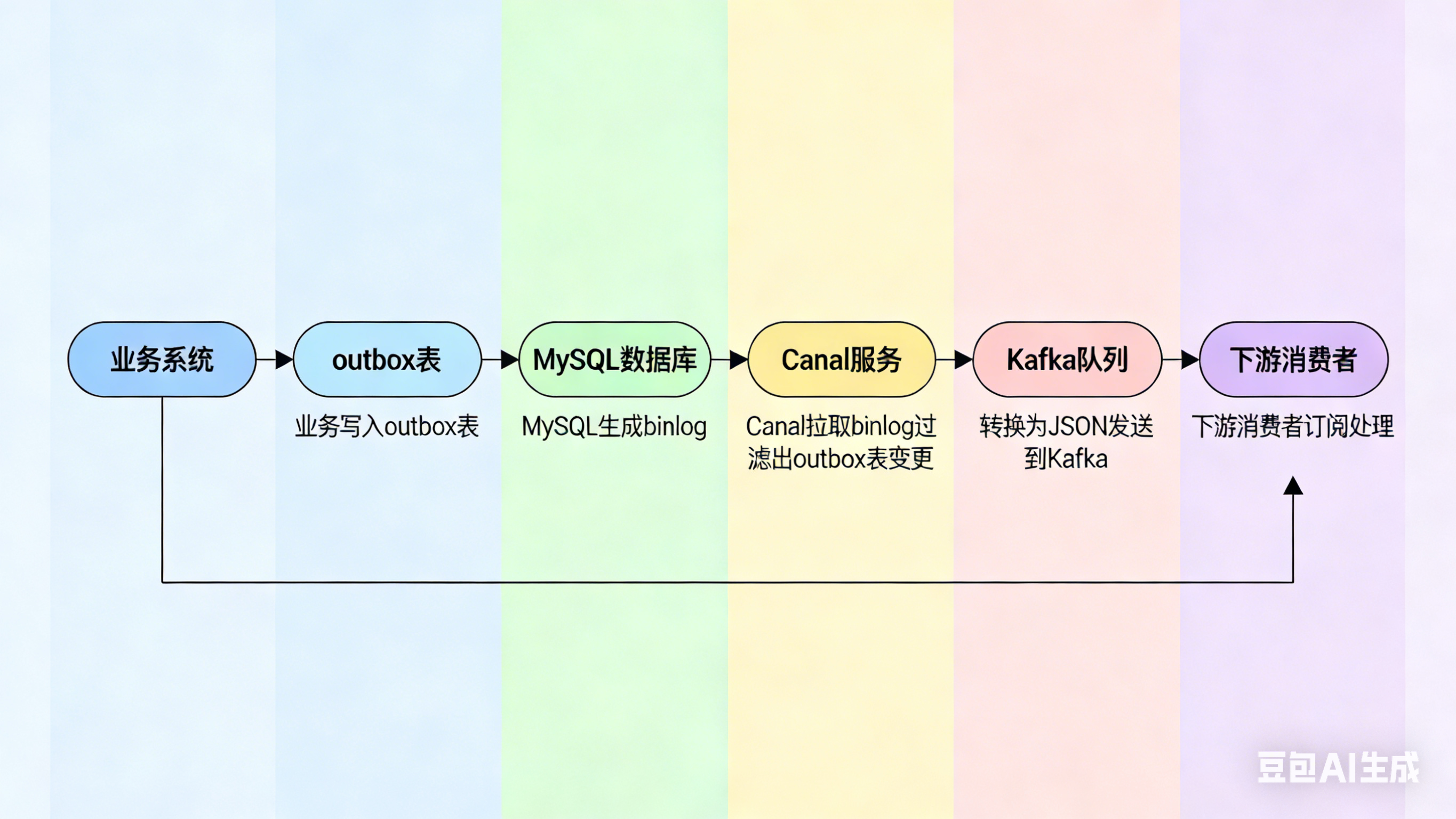
Canal 是阿里开源的一个 MySQL binlog 订阅组件。它伪装成一个 MySQL 从库,向主库拉取 binlog,然后解析成我们能理解的结构化数据。
整个过程对业务代码完全无侵入:
- 业务代码正常写入 outbox 表(本地事务)
- MySQL 生成 binlog
- Canal 拉取 binlog,过滤出 outbox 表的变更
- Canal 将事件转换为 JSON 格式,发送到 Kafka
- 下游消费者订阅 Kafka 主题,拿到事件进行处理
这样一来,业务代码完全不需要关心消息发送的逻辑,只需要专注于自己的事务,剩下的交给 Canal 和 Kafka 搞定。
3.4 Canal 能拿到哪些信息?
从 outbox 表的 binlog 中,Canal 能拿到以下关键信息:
- 表名:用于过滤,只处理 outbox 表的变更
- 事件类型:INSERT、UPDATE、DELETE,我们只关心 INSERT
- 变更的行数据:也就是 outbox 表中插入的那条记录的所有字段
其中最重要的是 payload 字段,它里面包含了完整的事件数据,下游拿到后可以直接反序列化使用。
四、一主多从:投影的思想
4.1 什么是投影?
有了可靠的事件流,我们就可以引入"一主多从"的思想了。
主表 :只有一个,是业务真理的源头。在我们的场景中,following 表就是主表,它记录了所有的关注关系。
从表(投影):可以有多个,每个投影都基于主表的事件,独立维护自己的数据视图。它们服务于不同的业务场景,比如:
follower表:粉丝视角的投影,专门用于查询"谁关注了我"- Redis ZSet:缓存投影,用于高性能的列表查询
- 用户计数:聚合投影,记录用户的关注数和粉丝数
- 未来还可以有:推荐系统的关系图谱、数据仓库的同步表、ES 的搜索索引......
4.2 投影的特点
投影有几个非常重要的特点:
-
只依赖事件:每个投影只需要消费事件流,不需要知道主表的存在。主表改了字段,只要事件格式不变,投影完全无感。
-
相互独立:每个投影是独立的服务或模块,一个挂了不影响其他的,也不影响主业务。
-
可重建:因为投影的数据全部来源于事件,如果某个投影数据损坏了,只需要从事件流中重新消费一遍,就能完全重建。
-
可扩展:想加一个新的投影?没问题,新起一个消费者订阅事件就行,完全不用改主流程代码。
4.3 投影的更新流程
以 follower 表为例,它的更新流程是这样的:
关注事件 (FollowCreated)
↓
Canal 捕获 → Kafka
↓
消费者收到事件
↓
插入 follower 表(to_user_id = 被关注者, from_user_id = 关注者)
↓
同时更新 Redis ZSet 和用户计数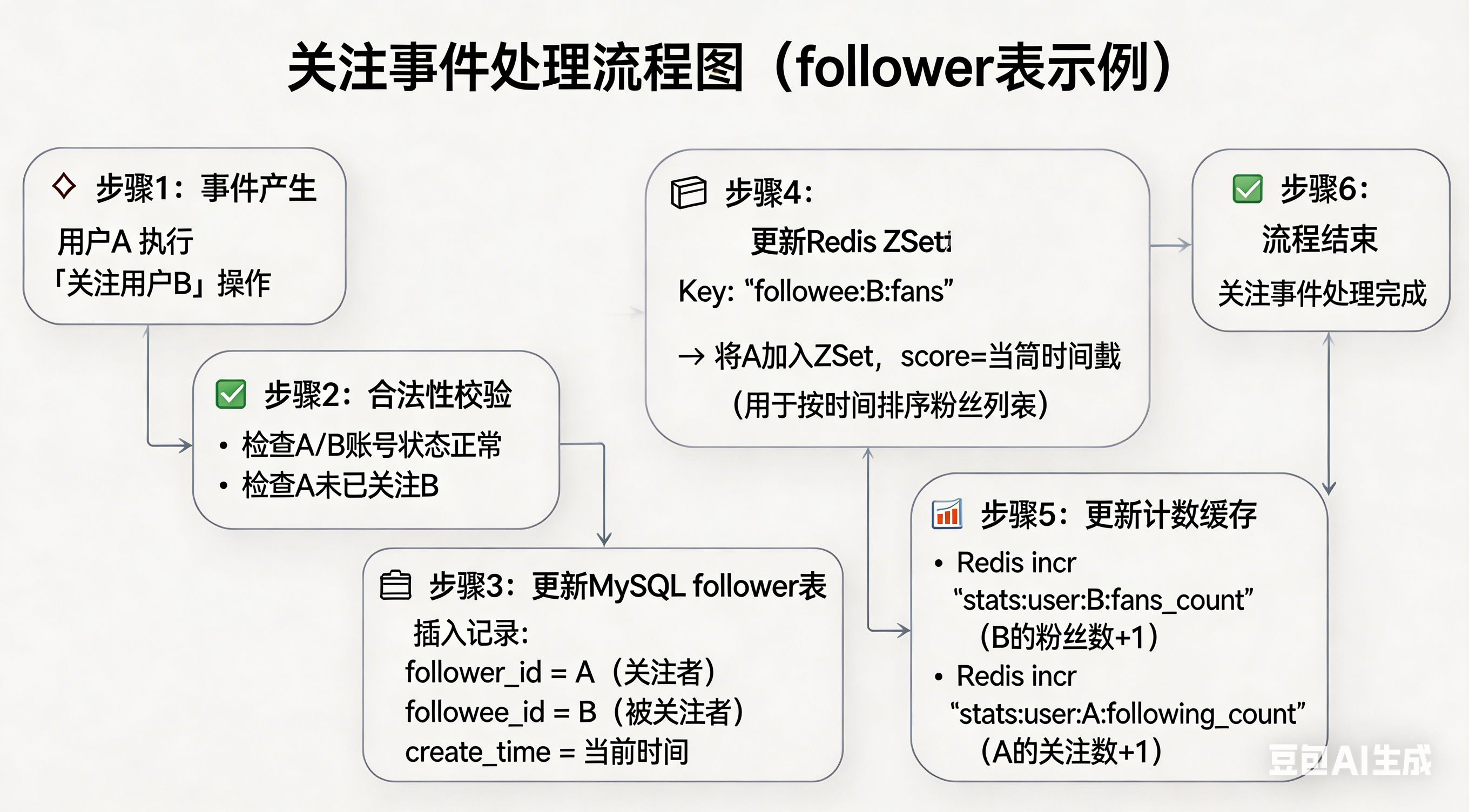
取消关注事件也是类似的流程,只是操作变成了删除。
4.4 为什么要区分主表和从表?
有的朋友可能会问:既然有事件流了,为什么还要维护 following 主表?直接用 outbox 的事件来查询不行吗?
理论上可以,但实践中不行。因为:
- 查询性能:要查询 A 关注了谁,如果用事件流来算,需要把 A 的所有关注事件都找出来,过滤掉取消关注的,才能得到当前状态。这在事件量大的情况下是不可接受的。
- 实时性:事件流是按时间排序的,没有按用户维度的索引。直接查询需要扫大量数据。
- 状态更新:取消关注是一个"状态变更",如果用事件流来表示,也是插入一条新事件。但查询当前状态时,需要找到最新的事件来判断是否取消。这增加了复杂度。
所以,主表是"当前状态"的快照,用于快速查询和业务判断;outbox 是"事件历史",用于驱动下游投影和实现可追溯性。两者分工明确,缺一不可。
五、实战中的关键细节
5.1 幂等处理:防止重复消费
Kafka 的消息可能因为重试等原因被重复消费。为了保证数据的一致性,下游处理必须支持幂等。
我们的做法是:在 Redis 中设置一个去重键,键的格式为 dedup:rel:{事件类型}:{fromUserId}:{toUserId}:{关系ID},并设置 10 分钟的过期时间。处理事件时,先用 setIfAbsent 尝试设置这个键,如果设置成功,说明是第一次处理;如果设置失败,说明已经处理过了,直接跳过。
java
String dedupKey = "dedup:rel:" + evt.getType() + ":"
+ evt.getFromUserId() + ":" + evt.getToUserId()
+ ":" + (evt.getId() == null ? "0" : evt.getId());
Boolean first = redis.opsForValue().setIfAbsent(dedupKey, "1", Duration.ofMinutes(10));
if (first == null || !first) {
return; // 已经处理过
}5.2 有序性:如何保证列表按时间排序?
产品要求关注/粉丝列表按创建时间倒序排列,最新关注的人排在最前面。
我们的解决方案是:用 Redis 的 ZSet 作为列表缓存,把用户 ID 作为 member,把 created_at 的时间戳作为 score。ZSet 天然支持按分数排序,查询时用 reverseRange 就能直接拿到倒序排列的列表。
如果缓存未命中,就从数据库查,按 created_at 排序,然后回填到 ZSet 中,保证缓存和数据库顺序一致。
分页方面,我们支持两种方式:
- 偏移分页:直接取 ZSet 中指定范围的元素
- 游标分页:用上一页最后一条的时间戳作为 cursor,查询 score 小于 cursor 的数据
5.3 大V用户的优化
对于粉丝量巨大的大V用户,Redis 的 ZSet 可能存储了数百万条数据。每次查询都从 Redis 读取全部数据显然不现实。
我们的优化是:在本地缓存中存储大V用户的前 500 名粉丝/关注列表。当查询命中大V用户时,直接从本地缓存读取,避免了 Redis 的大数据量传输。
本地缓存用的是 Caffeine,设置 10 分钟过期,并限制最大条目数为 1000,防止内存溢出。
5.4 容错与恢复
这套架构的容错能力体现在多个层面:
Kafka 挂了怎么办?
- 主业务完全不受影响,因为主业务只写数据库
- Canal 有本地存储,发不出去的消息会暂存在本地,等 Kafka 恢复后再发送
Canal 挂了怎么办?
- Canal 记录了 binlog 的消费位点,重启后会从上次的位置继续拉取
- MySQL 的 binlog 默认保留 7 天,只要在这个时间内恢复,就不会丢数据
下游消费者挂了怎么办?
- Kafka 的消息会保留,消费者恢复后可以继续消费
- 结合幂等设计,重复消费也不会产生副作用
数据出现不一致怎么办?
- 我们有定时对账任务,每天对比主表数据与各个投影的数据,发现不一致就自动修复
这些机制共同保证了系统的高可靠性。即使部分组件出现故障,最终数据也能达到一致,最多只是中间有几个小时的延迟。
六、这套方案的收益
6.1 彻底解决双写不一致
这是最直接的收益。主表写入和事件写入在同一个事务里,要么都成功,要么都失败。下游所有投影都基于同一个事件流,天然保证了最终一致性。
6.2 写路径极致轻量
一次关注操作,主业务只需要做两件事:写 following 表 + 写 outbox 表。没有任何网络 I/O(Redis、Kafka)参与,也没有额外的业务逻辑。P99 延迟大幅降低,系统吞吐能力显著提升。
6.3 高可扩展性
想加一个新的下游?只需要新增一个 Kafka 消费者,订阅同一个主题,做自己的投影就行。主流程代码一行都不用改。
我们后续可能接入的推荐系统、数据仓库、搜索服务等,都可以这样轻松接入。
6.4 可修复与可追溯
因为所有的事件都保留在 outbox 表和 Kafka 中,任何投影都可以在需要的时候重建。万一某个投影数据损坏了,不需要停机,只需要重新消费事件流就能恢复。
同时,事件本身也提供了完整的审计能力,可以追溯某个用户什么时候关注了谁、什么时候取消,这对于风控和运营分析都很有价值。
6.5 业务与存储解耦
下游投影可以自由选择最适合自己的存储介质:粉丝表用 MySQL、列表用 Redis ZSet、计数用独立的计数服务、大数据分析用 ClickHouse......每个投影独立演进,互不影响。
七、一些常见问题与思考
Q1:为什么不用直接订阅 following 表的 binlog,而要多写一个 outbox 表?
这个问题我们一开始也想过,后来发现直接订阅主表有几个痛点:
-
事件太杂:主表的变更可能来自各种场景------用户正常操作、后台批量修复、数据迁移等。如果直接订阅,下游无法区分哪些变更是"需要通知的"。而 outbox 表只有我们主动要发事件时才会写入,天然就做了过滤。
-
字段变化:直接订阅主表,下游需要解析主表的字段结构。如果主表结构变了,下游都要跟着改。而 outbox 的 payload 是预先打包好的 JSON,下游直接使用,与主表结构解耦。
-
事件语义:主表的 UPDATE 可能代表取消关注,也可能只是更新时间戳。下游需要自己推断业务含义,容易出错。而 outbox 的 type 字段直接告诉我们是什么事件,语义明确。
Q2:这样设计会不会有"事件延迟"的问题?
确实会有延迟。从用户点下关注,到下游投影更新完成,中间经过:事务提交 → binlog 生成 → Canal 拉取 → Kafka 发送 → 消费者处理,整个链路可能会有几十到几百毫秒的延迟。
但在社交场景中,这个延迟是可以接受的。用户关注后,粉丝列表不需要在 1ms 内就显示出来。而且我们会在缓存未命中时主动从数据库回填,保证用户刷新后能看到最新数据。
Q3:如果 outbox 表写入成功,但 Canal 一直没消费到怎么办?
Canal 会持续拉取 binlog,除非 Canal 挂了。如果 Canal 挂了,重启后它会从上次消费的位点继续,不会漏数据。只要 MySQL 的 binlog 还在(我们保留 7 天),就能完整恢复。
Q4:outbox 表会不会越来越大?需要清理吗?
是的,outbox 表会持续增长。我们可以根据业务需求定期清理,比如保留最近 7 天的数据。因为下游投影已经消费完了,历史事件除了审计,没有太多作用。如果某个投影需要重建,我们可以从数据库的全量快照 + 最近的事件来重建,不需要保留全部历史。
总结
回顾整个关系模块的演进过程,我最大的收获是:在复杂系统中,学会"做减法"往往比"做加法"更重要。
一开始,我们想把所有事情都在一次请求里完成,结果被双写不一致、性能瓶颈、扩展困难等问题困扰。后来我们换了一个思路:让主业务只做最核心的事,把其他工作交给事件流异步处理。这个转变,本质上是在复杂度与可靠性之间做了一次正确的取舍。
这套"一主多从 + 事件驱动"的架构,给我们带来了几点深刻的认识:
第一,业务真理只能有一个。 多个地方存同一份数据,迟早会不一致。与其到处同步,不如定下一个唯一的数据源,其他都作为它的投影。投影可以坏、可以慢、可以重建,但真理不能乱。
第二,用本地事务解决分布式难题。 Outbox 模式告诉我们,跨系统的分布式事务很难做,但我们可以把"事务边界"缩小到单个数据库内,用本地事务保证业务数据与事件的一致性。剩下的,交给可靠的消息队列和幂等的消费者。
第三,事件是解耦的利器。 主业务不需要知道下游是谁、下游需要什么,只需要发布事件。下游也不需要知道主业务怎么做,只需要知道自己要处理什么事件。这种松耦合让系统在演进时几乎不受限制。
第四,可修复性比完美一致更重要。 在分布式系统中,100% 的强一致性很难做到,但我们可以做到"最终一致 + 可修复"。只要有完整的事件记录,任何投影都能重建,任何不一致都能修复。这种确定性给了我们很大的信心。
这套方案虽然是在关系模块中落地的,但它的思想可以应用到很多场景:订单系统、支付系统、内容发布系统......只要是"主业务 + 多个下游"的架构,都可以借鉴这种模式。
最后想说,没有完美的技术方案,每个方案都是在特定约束下的取舍。这套方案适用于需要高吞吐、高可用、高扩展性的场景,但如果你对实时性要求极高(比如要求毫秒级强一致),那可能就需要换一种思路了。
希望这篇文章能给你一些启发。
