GTC 2026 之后,外界最容易被放大的,依然是芯片、算力、推理、Agent、物理 AI 这些高热度议题。但如果把黄仁勋这场演讲仅仅理解为一次"算力迭代更新",其实只看到了表层。真正值得企业重视的,是他在整场演讲中反复释放出的一个更底层的信号:AI 的竞争正在从模型层继续下沉,落到数据处理体系、软件栈和数据基础设施本身。
结构化与非结构化数据处理的整体加速能力 , 被黄仁勋放在"完整 AI 栈"的语境里来讲,AI 时代真正的分水岭,已经不只是"有没有模型",而是**"** 企业能不能把数据真正变成 AI 可以持续调用的生产资料 "。

一、GTC 2026 传递出的核心观点,不是"模型更强",而是"数据处理要重做一遍"
AI 正在逼迫整个企业数据处理体系从"服务人"的计算框架,转向"同时服务人和 AI"的新框架。黄仁勋在演讲中强调,结构化数据仍然是企业计算中的 Ground Truth,是业务运行、经营判断和管理决策的事实来源;但接下来,直接消费这些数据的主体不再只是分析师、管理者和业务人员,也包括模型、Agent 和各类自动化系统。AI 访问数据的频率、更高并发的调用方式,以及对实时性和上下文完整性的要求,都会把原本够用的数据处理能力,迅速变成新的瓶颈。
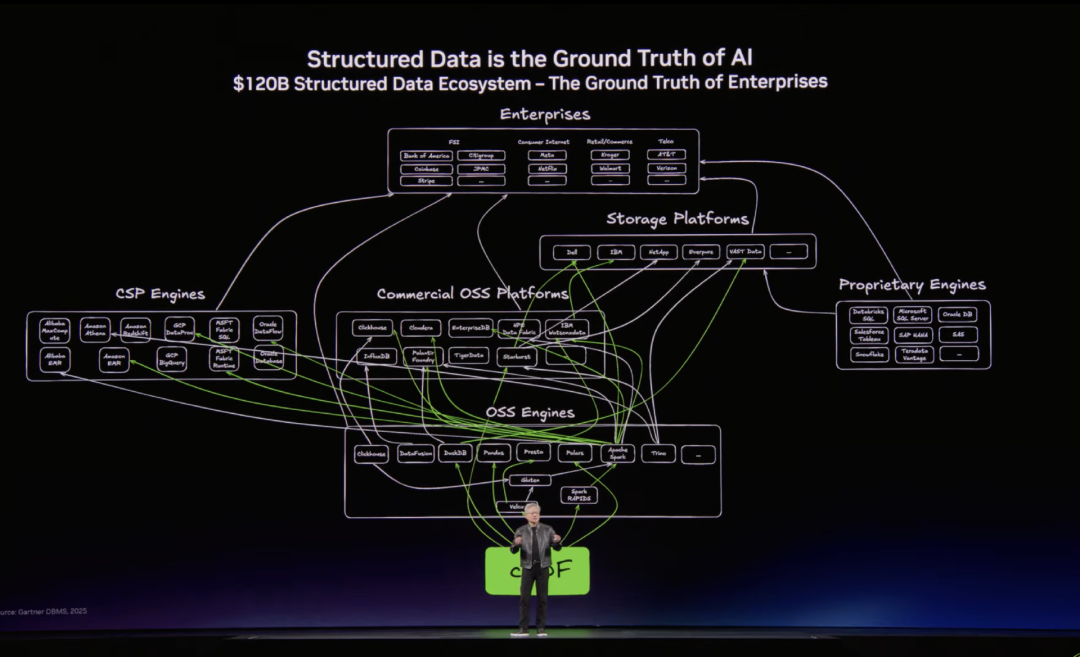
这背后其实意味着企业数据体系角色的变化。过去,数据平台的目标往往是支撑 BI、报表、专题分析和离线经营复盘,重点是"把数据算出来";而在 AI 时代,数据平台越来越需要承担另一层责任:不仅要能产出结果,还要让机器可以高频访问、组合调用、语义检索并持续复用这些结果 。AI 时代的数据处理已经不能只围绕表和报表设计,而必须同时处理表、文本、图像、视频、语音、向量索引和语义检索。这里变化的不是某个单点技术,而是企业数据基础设施的边界被重新定义了。所以一个更现实的判断是:模型能力快速普及之后,企业之间真正拉开差距的,会越来越多地体现在数据底座是否足够完整,是否既能承载结构化事实,又能吸收非结构化知识,并最终把两者一起转化为 AI 可用的数据资产 。
二、AI 正在重构结构化与非结构化数据的关系
黄仁勋这次关于数据处理的表述,最值得细拆的地方,在于他没有把企业数据简单分成"传统数据"和"AI 数据",而是把问题拉回到了更本质的两类对象:结构化数据与非结构化数据。这种划分非常关键,因为它对应的不是技术流派,而是企业长期以来两套不同的数据世界。
第一套世界,是以 SQL、Spark、 Pandas **、数仓、湖仓、指标体系为核心的结构化数据世界。**这套体系已经非常成熟,也支撑了过去企业数字化的大部分成果。cuDF 针对的正是这一类 DataFrame 工作负载,包括 pandas、Polars 和 Apache Spark 等主流框架。它要解决的问题是"能不能以更低成本、更高吞吐、更短时延去处理"。当 AI 与 Agent 开始直接接入这些结构化事实层时,原本服务于人类分析节奏的数据处理性能,就会被机器调用节奏迅速放大。过去一天跑一次 ETL、一个小时刷新一次宽表,可能已经够用;但当成百上千个智能体开始围绕指标、库存、合同、风险、工单、用户行为实时取数时,企业对数据处理速度和成本结构的要求会发生数量级变化。

**第二套世界,则是长期被企业"存着但用不好"的非结构化数据世界。**当前,非结构化数据已经占到当今企业数据的 80%,而且还在持续增长;cuVS 面向的就是这类数据背后的向量检索与语义搜索基础能力,包括与 FAISS、Amazon OpenSearch Service、Milvus 等引擎的协同。这里有一个非常重要的变化:过去非结构化数据之所以难以进入企业核心数据体系,不是因为它不重要,而是因为它难以建立统一索引、难以高质量检索、难以被计算流程稳定消费。PDF、制度文档、会议纪要、录音录像、巡检图像、合同扫描件、客服语音、设备视频流,这些东西企业一直在积累,但很长时间里,它们更多只是"被保存下来",而不是"被真正计算"。

AI 的出现改变了这一点。因为大模型与多模态模型的本质能力之一,就是把原本难以直接计算的内容,先转译为可表示、可嵌入、可搜索、可关联的语义对象。cuVS 里明确提到,它服务的是向量索引构建、向量检索、语义搜索以及 RAG 等场景。也就是说,黄仁勋这次真正想讲的,不只是"GPU 还能加速数据库",而是企业数据处理的对象已经变了:从只处理表,变成同时处理表与语义;从只处理结构化事实,变成同时处理事实与上下文;从只做分析准备,变成同时为模型调用和智能体执行提供底层支撑。
这里面最深的一层逻辑其实是:AI 不是在削弱结构化数据的重要性,反而是在抬高结构化数据的价值,同时把过去大量沉没在系统外、文件中、知识碎片里的非结构化数据重新纳入企业计算体系 。 结构化数据解决的是确定性、口径一致性和经营事实问题;非结构化数据补充的是上下文、语义、经验和知识问题。企业真正能跑出高质量 AI 应用,靠的从来不是二选一,而是把这两类数据重新组织起来。黄仁勋把 cuDF 和 cuVS 并列放在同一套企业数据处理叙事里,本质上就是在表达这一点:未来的数据底座,必须同时覆盖结构化与非结构化。
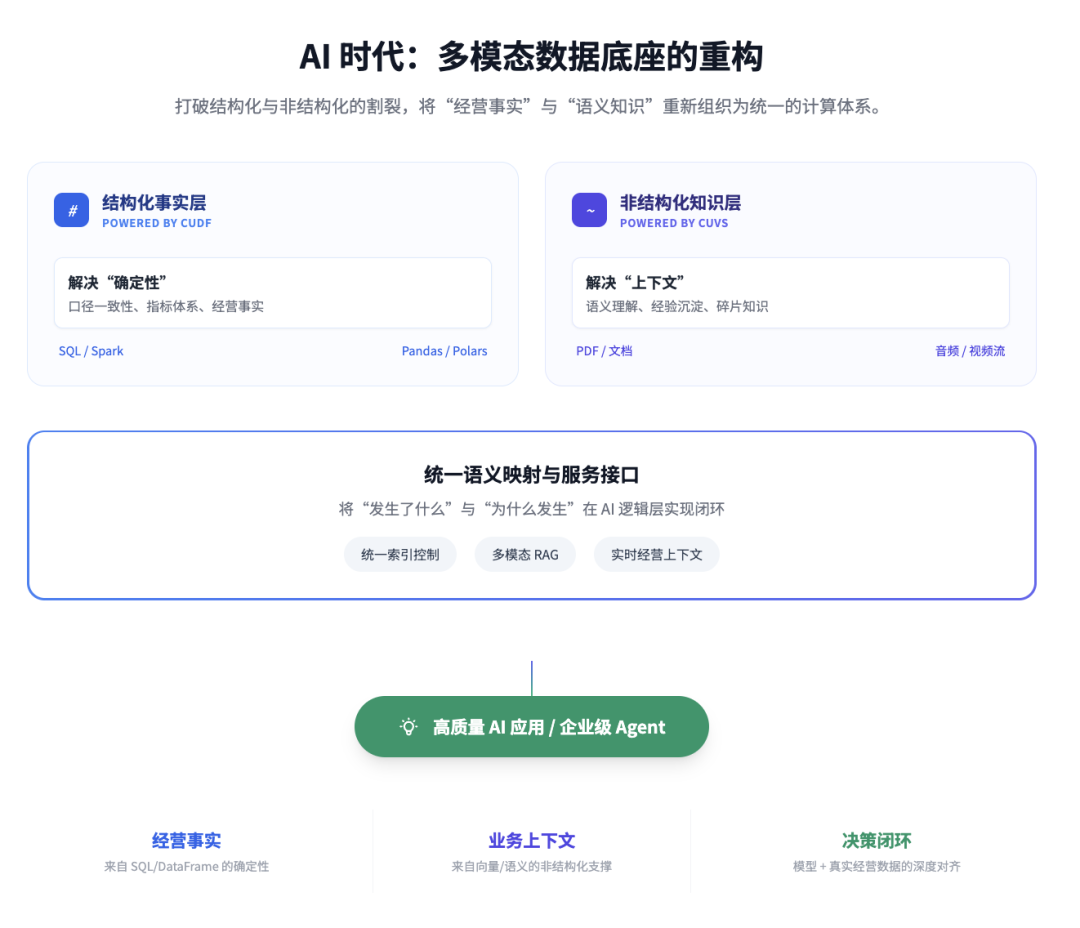
从企业实践角度看,这个判断尤其重要。企业做 Agent 时常常会遇到一个非常现实的问题:模型能理解语言,却拿不到真实业务上下文;能读文档,却接不上经营事实;能生成答案,却无法和指标、规则、流程形成闭环 **。**这恰恰说明,AI 时代真正的门槛不是模型接得够不够多,而是数据底座有没有完成从"结构化时代"向"多模态时代"的升级。
三、袋鼠云的多模态数据中台,回应 AI 时代的数据底座需求
如果顺着黄仁勋这套逻辑继续往下推,结论其实很清楚:AI 时代企业最需要的,是一个能统一承载结构化与非结构化数据、统一完成治理与加工、统一形成语义索引与数据服务的数据底座 。也正是在这个意义上,多模态数据中台才会成为越来越多企业真正需要的新基础设施。
袋鼠云多模态数据中台的价值在于它把过去分属不同体系的两类数据重新放到同一个生产框架里。结构化数据仍然要经过采集、治理、建模、指标沉淀和服务输出,保证口径一致、过程可追溯、结果可复用;而非结构化数据则不再只是被挂在文件系统或知识库里,而是需要完成解析、抽取、切分、向量化、语义标注、权限控制、检索增强和服务编排,进入可管理、可搜索、可调用的企业数据资产体系。前者解决"事实",后者补足"语境";前者提供确定性基础,后者提供理解和生成所需的知识背景。AI 时代真正稳定的数据底座,必须把两者接到一起。这个方向与 NVIDIA 在 GTC 2026 所表达的"同时加速 Structured 与 Unstructured Data Processing"完全同频。

袋鼠云多模态数据中台产品架构
更关键的是,企业需要的从来不只是"能处理",而是"能落到业务"。这也是袋鼠云多模态数据中台与泛知识库方案之间的本质差别。很多企业现在做非结构化数据利用,仍停留在文档问答、知识检索、单点 RAG 的层面,能回答一些问题,但很难真正接入经营分析、指标监测、流程决策和业务执行。这类系统的问题不在模型,而在底座:文档和表没有打通,知识和指标没有打通,语义检索和业务规则没有打通,最终导致 AI 只能"解释",无法"参与"。而真正的数据底座,必须同时具备三层能力:**一是统一承载多模态数据资产,二是把多模态数据转化为 AI 可调用的数据对象,三是把这些对象继续接入指标体系、分析体系与业务流程。**只有这样,AI 才不是悬在业务上方的一个问答层,而是能进入经营、管理和执行环节的生产能力。这个方向,正是黄仁勋所谓"AI 将直接使用 structured data,同时把 unstructured data 转化为可计算资源"的企业化落点。
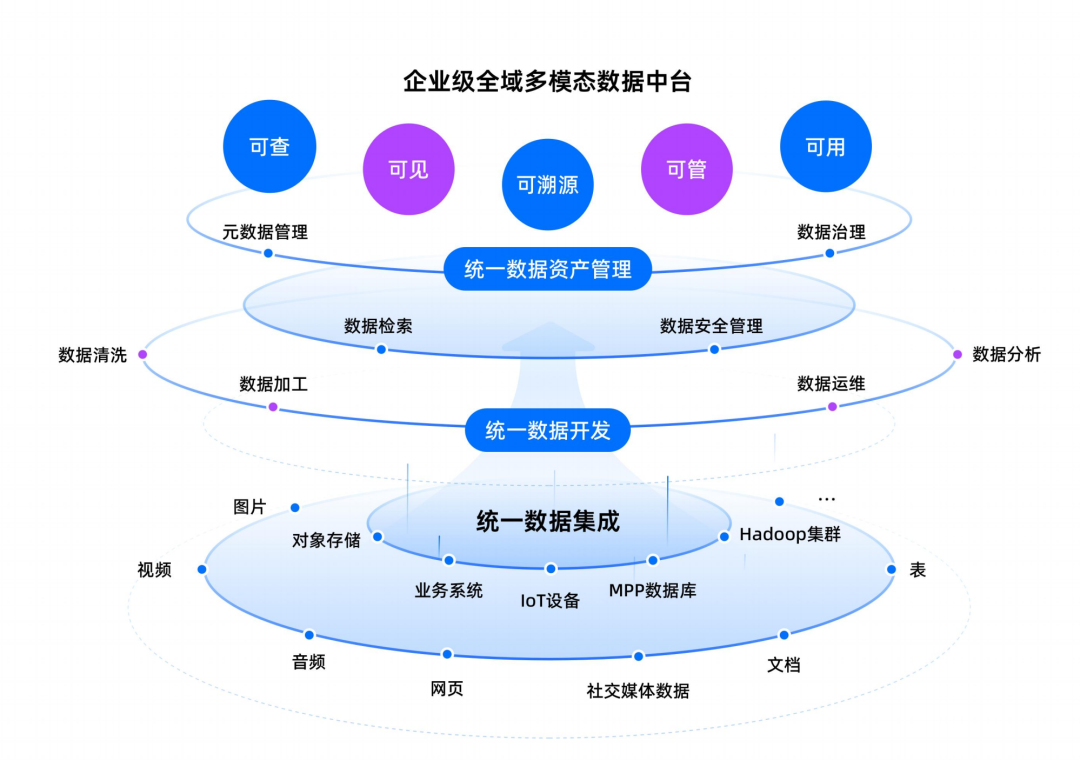
从底层架构上看,袋鼠云多模态数据中台之所以适合作为 AI 时代的数据底座,也在于它并没有否定传统数据平台,而是在原有数据中台能力之上完成扩展。GTC 2026 释放出的一个重要信号,是包括 Google Cloud、IBM watsonx.data、Oracle、Snowflake、Starburst 等在内的数据平台生态,正在吸收新的结构化与非结构化数据加速能力,而不是推倒重来。AI 时代的数据底座演进,本质上是"原有数据基础设施向多模态和 AI-ready 方向升级",不是简单另起炉灶。袋鼠云多模态数据中台也不是绕开原有数据平台,而是帮助企业把结构化资产、非结构化资产和 AI 应用需求放到一张架构图里重新组织。

再往业务层看,这种底座能力的意义会更加直接。对企业而言,AI 时代最稀缺的是持续、低成本、可信任地生成业务价值的能力。一个真正有效的多模态数据中台,应该至少支撑四类事情:让结构化经营数据能被模型与 Agent 安全调用;让 PDF、图像、音视频、日志、知识文档等非结构化数据转化为可搜索、可关联、可复用的语义资产;让结构化指标和非结构化知识在同一语境中协同工作;让 AI 的输出可以回到分析、决策、流程和业务执行中形成闭环。只有到这一步,企业的数据底座才不再只是"存数据、管数据、出报表"的平台,而是支撑智能应用长期运行的底层生产系统。
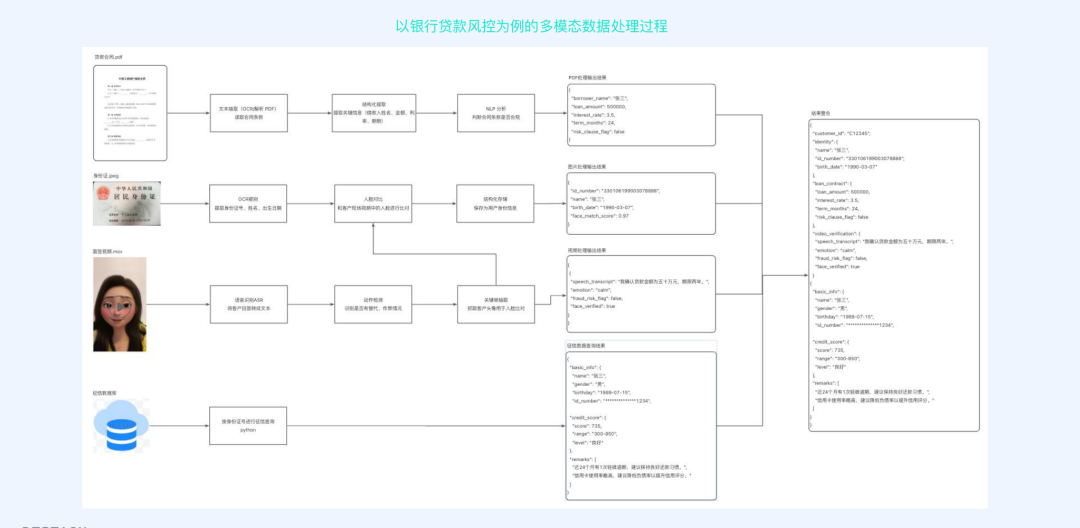
四、GTC 2026 真正提醒企业的,是该重新理解"数据底座"
如果说过去十年,企业竞争拼的是数字化能力;那么未来几年,企业竞争拼的,就是能否把数据真正转化为智能时代的基础资源。GTC 2026 让这件事变得前所未有地清晰:AI 不是简单叠加在企业之上的一层新应用,它正在倒逼企业重建数据底层秩序 **。**那些仍然把结构化数据和非结构化数据分开管理、把数据平台和 AI 应用割裂建设的企业,迟早会发现,自己投入了模型,却撑不起真正的智能化生产。真正的分水岭正在形成。未来能够跑出来的企业,一定是最先完成底座升级的企业。因为所有看得见的智能,背后都站着一套看不见、但足够坚实的数据基础设施。