
论文:Training Language Models via Neural Cellular Automata
作者:Dan Lee, Seungwook Han, Akarsh Kumar, Pulkit Agrawal(MIT · Improbable AI Lab)
链接:arXiv:2603.10055 · 代码
自然语言 pre-training 的三重困境
大型语言模型(LLMs)的能力主要在 pre-training 阶段习得。规模定律(scaling laws)告诉我们,模型越大、数据越多,性能越好。然而这条路正在逼近三个硬性天花板。
- 高质量文本有限。Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data(2022)预测,人类产出的高质量文本将在 2028 年前被耗尽。继续沿现有路线扩张,所需数据量呈指数增长,但供给却是有限的。
- 人类偏见的污染。自然语言是人类认知的有损记录,内嵌了各类社会偏见。使用这些数据训练的模型在对齐方面面临持续挑战,而清洗和筛选数据本身代价高昂。
- 知识与推理的纠缠。语言模型在自然文本上学习时,无法将"事实性知识"与"推理能力"解耦,两者以难以分离的方式混合在同一参数空间中。
这三重困境共同指向一个根本问题:自然语言是通往智能的唯一路径吗?
本文作者的答案是:不是。他们提出用神经元胞自动机(Neural Cellular Automata,NCA)生成的纯合成数据,对语言模型进行"pre-pre-training",即在接触任何自然语言之前,先让模型在合成的时空结构数据上完成一轮训练。
核心假设:结构比语义更重要
在深入方法之前,有必要理解这项工作背后的核心理论假设。
作者认为,LLMs 中涌现的推理能力(few-shot learning、chain-of-thought 等),其本质依赖的是自然语言的底层计算结构,而非其语义内容本身。
自然语言文本之所以有用,不是因为它谈论的是人类世界,而是因为它蕴含了从推理轨迹到程序性指令的多样结构。next-token prediction 迫使模型内化支持这些结构的潜在计算过程。(Language modeling is compression ,A latent space theory for emergent abilities in large language models)
基于这一假设,如果能够人工合成一种数据,使其:
- 具有与自然语言相似的统计结构 (Learning to see by looking at noise ) 如近似的尺度不变性 (Relations between the statistics of natural images and the response properties of cortical cells ) 或者 Zipfian 分布 (Data distributional properties drive emergent in-context learning in transformers ,Human behavior and the principle of least effort);
- 蕴含丰富且多样的时空规律;
- 能够系统性地控制复杂度;
- 可以无限低成本地生成,
那么这种数据就有可能替代自然语言承担"结构学习"的功能。
这个想法的支撑来自两个方向:
- 视觉领域已有工作证明,在分形、噪声等合成图像上预训练的视觉模型能够向真实图像迁移(Procedural Image Programs for Representation Learning);
- 理论上,An Explanation of In-Context Learning as Implicit Bayesian Inference 证明了 in-context learning 等价于对潜在规律的隐式 Bayesian 推断,而这一推断机制与数据的语义无关,只与其统计结构有关。

Neural Cellular Automata(NCA)是什么?
NCA 是经典 Conway 生命游戏的神经网络泛化版本。在经典 cellular automata(CA)中,每个格子的状态根据固定规则更新;而在 NCA 中,这个规则被替换为一个参数化的神经网络 f θ f_\theta fθ。
基本设置
本文使用 12 × 12 12 \times 12 12×12 的二维离散网格,周期性边界条件(左右、上下循环相连),状态字母表大小 n = 10 n = 10 n=10(每个格子可以处于 10 种状态之一,用 10 维 one-hot 向量表示)。
转移动态由神经网络 f θ f_\theta fθ 控制,将每个格子的 3 × 3 3 \times 3 3×3 邻域映射到下一时刻状态的概率分布:
c i ( t + 1 ) ∼ softmax ( f θ ( c N ( i ) ( t ) ) τ ) c_i^{(t+1)} \sim \text{softmax}\!\left(\frac{f_\theta\!\left(c_{N(i)}^{(t)}\right)}{\tau}\right) ci(t+1)∼softmax τfθ(cN(i)(t))
其中 c i ( t ) c_i^{(t)} ci(t) 是格子 i i i 在时刻 t t t 的状态, N ( i ) N(i) N(i) 是其 3 × 3 3 \times 3 3×3 邻域, τ = 10 − 3 \tau = 10^{-3} τ=10−3 是一个极小的温度参数------使采样几乎确定性(几乎总是选取 logit 最大的状态),同时保留极微小的随机性。
f θ f_\theta fθ 的网络结构为: 3 × 3 3 \times 3 3×3 卷积(4 channels) → \to → cell-wise MLP(hidden size 16,ReLU 激活) → \to → 输出 10 个 logits。
多样性的来源
每生成一条训练序列, θ \theta θ 和初始状态 c ( 0 ) c^{(0)} c(0) 都会随机重新采样:
- θ \theta θ:网络权重随机初始化;
- c ( 0 ) c^{(0)} c(0):每个格子的初始状态从 { 0 , 1 , ... , 9 } \{0, 1, \ldots, 9\} {0,1,...,9} 均匀采样。
这意味着每条序列都是由一套独特的"物理定律"驱动的------模型无法记忆具体规则,只能在每条序列的 context 中实时推断。这一设计刻意对齐了 in-context learning 的 Bayesian 框架。
复杂度的控制
NCA 动态的复杂度差异巨大:有些 θ \theta θ 会让格子快速收敛到固定点或短周期循环(低熵、低复杂度),有些则会产生混沌、不可预测的时空结构(高熵、高复杂度)。
作者使用 gzip 压缩率作为复杂度的实用度量------由于 Lempel-Ziv 压缩提供了 Kolmogorov 复杂度的可计算上界(An Introduction to Kolmogorov Complexity and Its Applications ),gzip 压缩率是序列内在复杂度的合理代理指标:
r = compressed bytes raw bytes × 100 % r = \frac{\text{compressed bytes}}{\text{raw bytes}} \times 100\% r=raw bytescompressed bytes×100%
- 压缩率低( r ≈ 20 % r \approx 20\% r≈20%)意味着序列高度规律、可压缩性强
- 压缩率高( r ≥ 50 % r \geq 50\% r≥50%)意味着序列具有丰富的不可压缩结构
默认筛选策略:保留 r ≥ 50 % r \geq 50\% r≥50% 的序列(50%+ 复杂度带)用于 pre-pre-training。
从格子状态到语言模型 Token
NCA 产生的是一个二维的离散格子序列,而语言模型需要的是一维的整数 token 序列。这中间需要一套 tokenization 方案。
Patch Tokenization
参考 Vision Transformer(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale )的 patch tokenization 思路,作者将每个时间步的 12 × 12 12 \times 12 12×12 格子用非重叠的 2 × 2 2 \times 2 2×2 patch切分,每个 patch 包含 4 个格子。每个 patch 内的 4 个格子状态各取 { 0 , ... , 9 } \{0, \ldots, 9\} {0,...,9},将其组合为一个整数(双射映射):
token_id = s 1 ⋅ 10 3 + s 2 ⋅ 10 2 + s 3 ⋅ 10 + s 4 \text{token\_id} = s_1 \cdot 10^3 + s_2 \cdot 10^2 + s_3 \cdot 10 + s_4 token_id=s1⋅103+s2⋅102+s3⋅10+s4
其中 s 1 , s 2 , s 3 , s 4 ∈ { 0 , ... , 9 } s_1, s_2, s_3, s_4 \in \{0, \ldots, 9\} s1,s2,s3,s4∈{0,...,9} 是 patch 内四个格子的状态。这样产生的词汇表大小恰好为 10 4 = 10000 10^4 = 10000 104=10000 个 patch token。 12 × 12 12 \times 12 12×12 的网格被切分成 6 × 6 = 36 6 \times 6 = 36 6×6=36 个 patch,每个时间步贡献 36 个 token。
序列构造
每个时间步的 36 个 patch token 按行优先顺序排列,并在两端加上特殊分隔符:
⟨ grid ⟩ , p 1 , p 2 , ... , p 36 ⏟ 36 patch tokens , ⟨ / grid ⟩ \langle\text{grid}\rangle,\ \underbrace{p_1, p_2, \ldots, p_{36}}_{\text{36 patch tokens}},\ \langle/\text{grid}\rangle ⟨grid⟩, 36 patch tokens p1,p2,...,p36, ⟨/grid⟩
多个时间步首尾拼接,截断至最长 1024 tokens,构成一条训练序列。每条序列约覆盖 ⌊ 1024 / 38 ⌋ ≈ 27 \lfloor 1024 / 38 \rfloor \approx 27 ⌊1024/38⌋≈27 个时间步的 NCA 演化过程。
训练目标
与语言模型的 pre-training 完全一致,使用标准的自回归 cross-entropy 损失:
L = − ∑ i = 1 N log p ϕ ( x i ∣ x < i ) \mathcal{L} = -\sum_{i=1}^{N} \log p_\phi(x_i \mid x_{<i}) L=−i=1∑Nlogpϕ(xi∣x<i)
其中 x = ( x 1 , x 2 , ... , x N ) x = (x_1, x_2, \ldots, x_N) x=(x1,x2,...,xN) 是 tokenized 轨迹, p ϕ p_\phi pϕ 是 transformer 参数化的概率分布。
由于每条序列对应唯一的 θ \theta θ(动态规则),模型要准确预测下一个 patch,必须从当前 context 中推断出这条序列背后的隐藏规律,再据此预测。
这与 An Explanation of In-Context Learning as Implicit Bayesian Inference 提出的"in-context learning = 对潜在概念的隐式 Bayesian 推断"在形式上完全对应。
只不过这里的"概念"是 NCA 的转移规则 θ \theta θ,而非自然语言的语义主题。
Pre-Pre-Training 框架
三阶段训练范式
本文采用三阶段训练范式:
| 阶段 | 数据 | 目标 |
|---|---|---|
| Pre-pre-training | NCA 合成轨迹(164M tokens) | 学习可迁移的计算原语 |
| Pre-training | 自然语言语料(OpenWebText / OpenWebMath / CodeParrot) | 习得语言知识 |
| Fine-tuning | 任务数据集 | 特定任务适配 |
本文主要研究第一阶段到第二、三阶段的迁移效果。
模型与迁移设置
模型使用 Llama-based transformer,参数规模 1.6B(24 层,32 heads,hidden size 2048,weight-tying)。
NCA pre-pre-training 结束后,执行以下迁移操作:
- 丢弃并重新初始化 embedding 层:NCA 词汇表(10000 个 patch token)与自然语言词汇表完全不同,无法复用;
- 保留所有 transformer 层权重(attention、MLP、LayerNorm):这些层在 NCA 训练中习得的计算结构被期望能够迁移;
- pre-training 阶段更新全部参数:没有任何参数被冻结。
Baselines
实验设置了三个基线对比方法:
- Scratch:随机初始化,直接在自然语言数据上 pre-training,不做任何 pre-pre-training;
- C4 pre-pre-training:先在 C4 自然语言数据集上 pre-pre-training(匹配 token 预算),再迁移到目标域;
- Dyck pre-pre-training:先在 K-Dyck 形式语言数据上 pre-pre-training(参考 Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases,2025),K-Dyck 是另一种非语义合成数据方案。
K-Dyck 语言是什么?
K-Dyck 语言( D k D_k Dk)是经典括号匹配语言的推广:有 k k k 种不同类型的括号对,合法序列要求所有括号类型正确且完全匹配。例如 k = 2 k=2 k=2 时括号对为
()和[],([])合法而([)]不合法。其形式文法为:S → ε ∣ S S ∣ a 1 S b 1 ∣ a 2 S b 2 ∣ ⋯ ∣ a k S b k S \;\to\; \varepsilon \;\mid\; S\,S \;\mid\; a_1\, S\, b_1 \;\mid\; a_2\, S\, b_2 \;\mid\; \cdots \;\mid\; a_k\, S\, b_k S→ε∣SS∣a1Sb1∣a2Sb2∣⋯∣akSbk
本文使用 k = 128 k = 128 k=128(128 种括号对,256 个 token 类型)、无限嵌套深度的 K-Dyck 数据,通过随机展开上述上下文无关文法(CFG)生成训练序列。
K-Dyck 要求模型学会追踪括号的嵌套层级与类型匹配,这与代码的结构(函数调用嵌套、条件块、括号匹配)高度同构,因此在 HumanEval 上表现与 NCA 相当。
然而,K-Dyck 的本质是单一 CFG 的多样实例化,计算多样性的天花板是固定的;相比之下,NCA 的每条序列有独立的随机 θ \theta θ,覆盖了从简单规则到图灵完备的广泛计算函数类,多样性远超 K-Dyck。
主要实验结果
NCA Pre-Pre-Training 持续改善语言建模
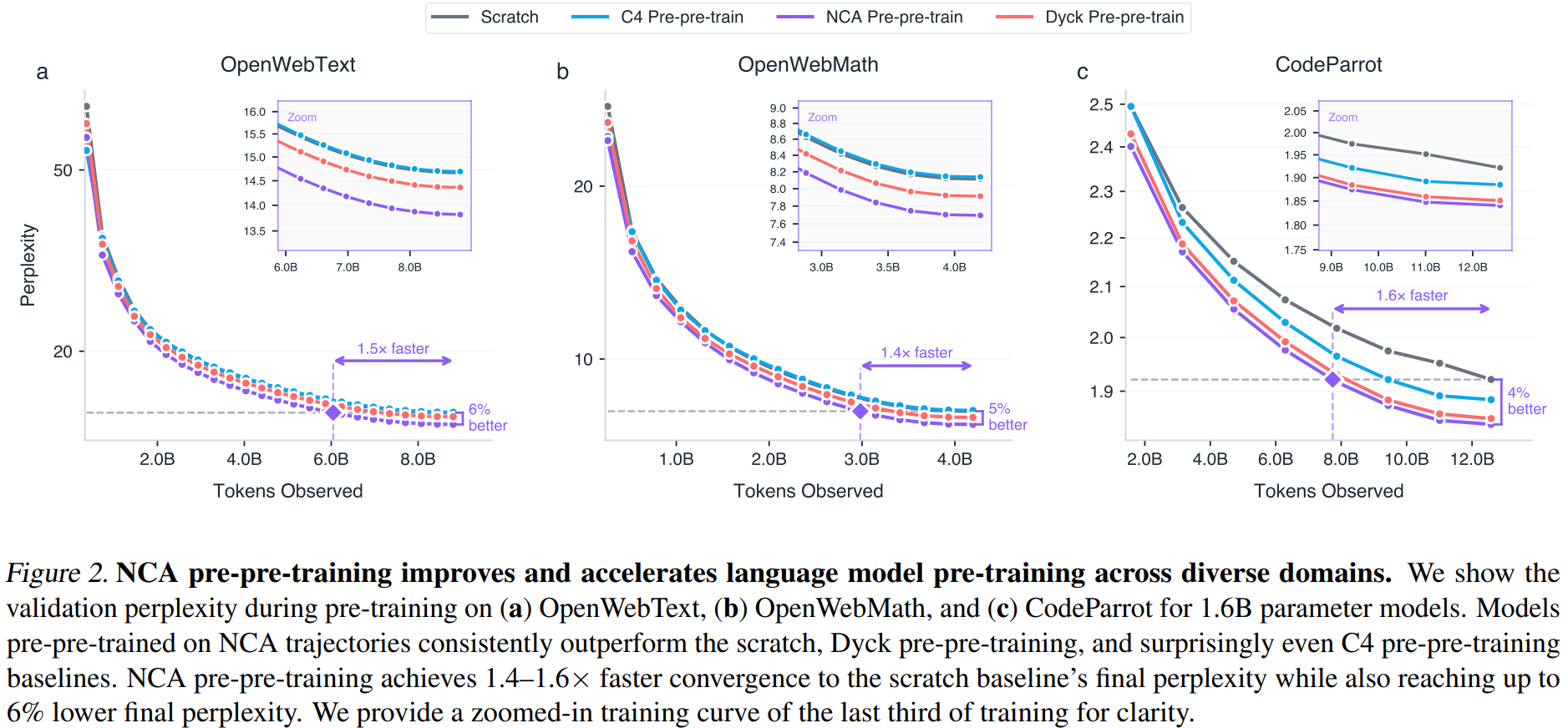
对三个下游自然语言语料分别进行完整 pre-training,评估指标为验证集困惑度(perplexity)。
| 语料 | 困惑度改善 | 收敛加速 | Token 效率增益 |
|---|---|---|---|
| OpenWebText | 6% | 1.5× | 31% |
| OpenWebMath | 5% | 1.4× | 27% |
| CodeParrot | 4% | 1.6× | 49% |
困惑度改善在整个训练过程中持续存在并往往进一步扩大,排除了"这只是一个更好的初始化"的解释,NCA pre-pre-training 真正提高了 token 效率。
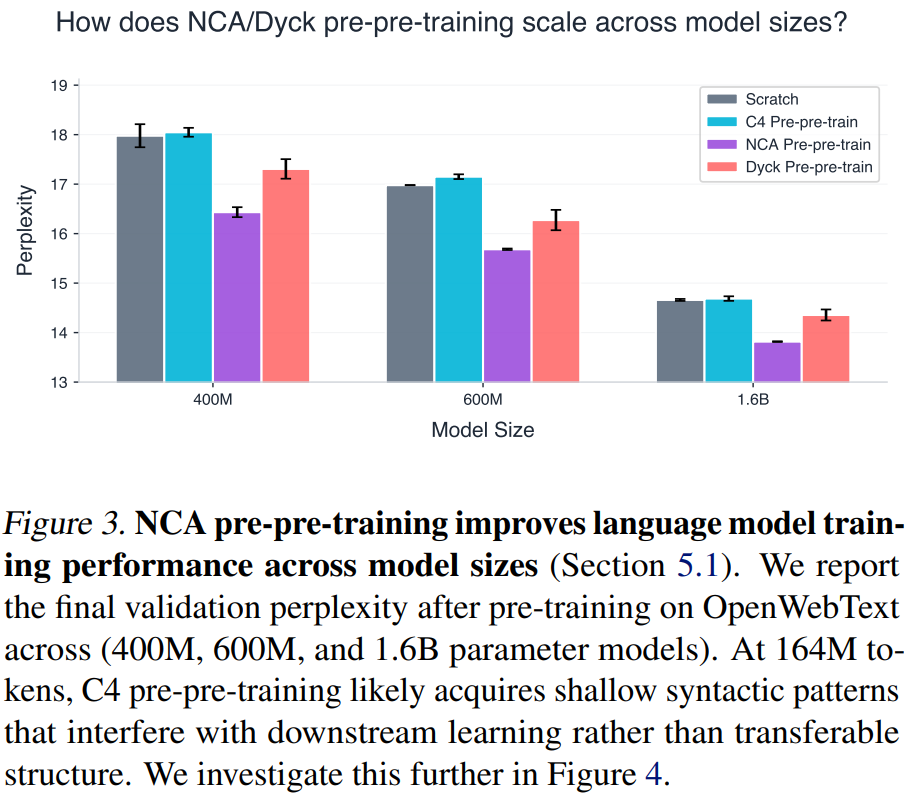
在三种模型规模(400M、600M、1.6B)上,NCA 均优于所有三个基线,多个随机种子下结果一致。相对增益随模型规模增大而减小,符合预期(更大的模型本身是更强的基线,边际改善更难获得)。
最令人惊讶的以小胜大
仅 160M tokens 的 NCA 数据,优于 1.6B tokens 的 C4 自然语言数据,即便后者在 token 预算上多出 10 倍,即便保留 C4 的 embedding 层也不例外。
作者对此解释,在 1.6B tokens 这一有限预算下,C4 pre-pre-training 仍处于训练的早期阶段,根据 compute-optimal scaling laws(Training Compute-Optimal Large Language Models,2022),1.6B 参数的模型需要约 32B tokens 才能充分训练。在这个早期阶段,模型主要习得浅层局部模式(句法模式、词语搭配等),而非具有广泛迁移价值的长程依赖跟踪和 in-context rule inference 能力。
NCA 序列则更纯粹:每条序列都强制执行一个完整的规则推断任务,没有任何语义捷径可以走。每个 NCA 序列代表一个独特函数,使得每个 token 都在贡献对通用计算机制的学习,而非领域特定的统计模式。
迁移至下游推理任务
困惑度是语言建模质量的代理指标,但不是我们终极关心的能力。作者进一步评估了在推理 benchmarks 上的表现:
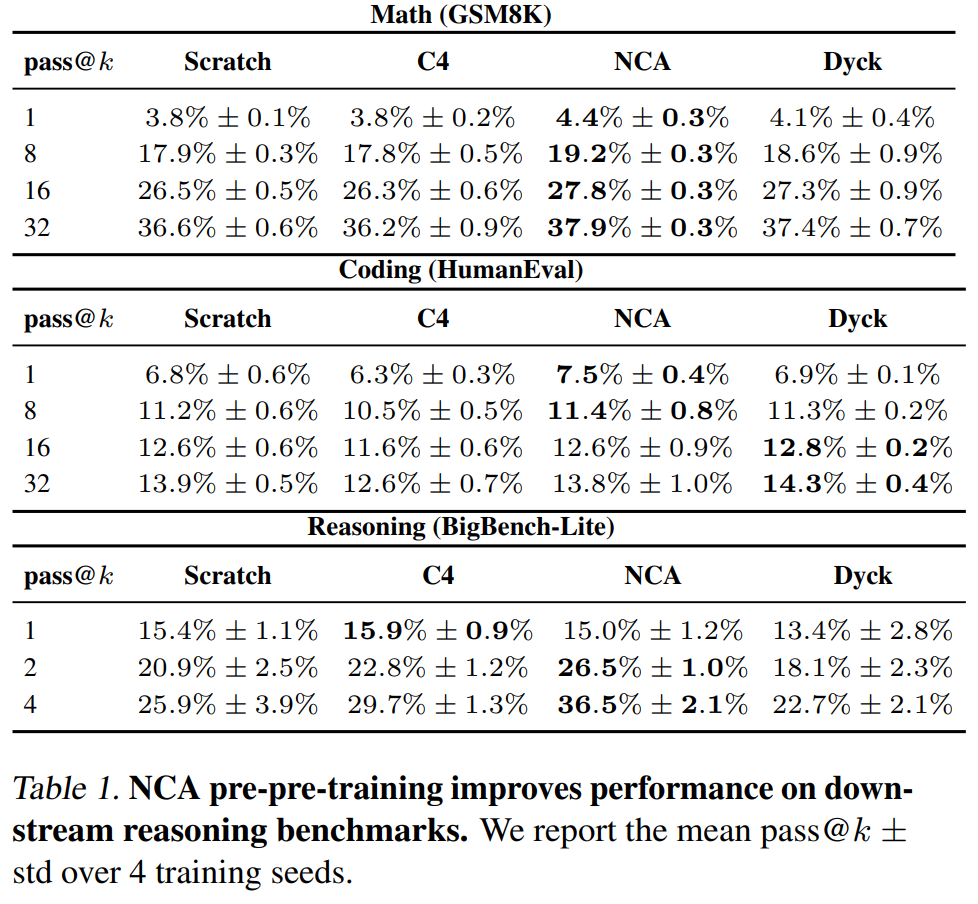
几点值得注意的现象:
- 在 HumanEval 的较高 pass@k 上,Dyck pre-pre-training 与 NCA 相当甚至略优。作者认为这源于 Dyck 语言与 code 的结构重叠------两者都需要追踪嵌套逻辑和分隔符模式。
- 在 BigBench-Lite 的 pass@4 上,NCA 的优势最为显著(36.5% vs. 29.7% vs. 25.9%),表明 NCA 训练的模型在反复采样时覆盖了更广的正确解空间。
- pass@k 中的 k k k 越大,NCA 的相对优势越明显,说明 NCA pre-pre-training 提升的是模型解空间的多样性(多次采样能找到正确解的概率),而非单次预测的确定性。
机制分析:什么驱动了迁移?
Attention 层是最具迁移价值的组件
为了定位迁移信号来自哪里,作者进行了选择性重初始化实验:在 NCA pre-pre-training 结束后,分别重新初始化不同的组件(Attention、MLP、LayerNorm),然后执行 pre-training,观察性能变化。
结论非常明确,重新初始化 attention 权重导致的性能退化最大,在 OpenWebText 和 CodeParrot 上均如此。MLP 和 LayerNorm 的影响则呈现领域依赖性:
- 在 OpenWebText 上,保留 MLP 和 LayerNorm 反而降低了迁移效果------这些层编码了 NCA 特有的统计量,干扰了语言学习;
- 在 CodeParrot 上,这些组件的影响可以忽略不计。
这一发现支持了如下的功能分工假说:
- Attention 层:学习通用的长程依赖追踪机制和 in-context learning 电路(induction heads,In-Context Learning and Induction Heads,2022),可以跨域迁移;
- MLP 层:存储领域特定的知识和统计模式,迁移效果取决于源域(NCA)与目标域的对齐程度。
复杂度与目标域的匹配原则
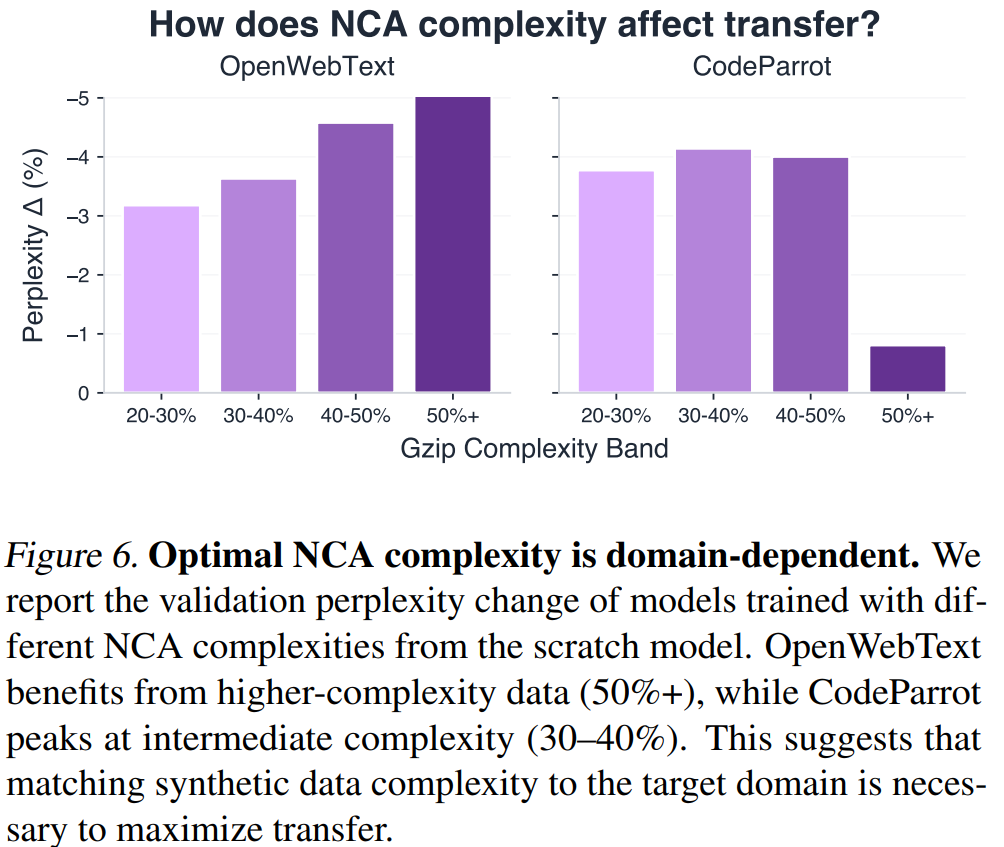
复杂度调控实验:以不同 gzip 压缩率区间(20-30%,30-40%,40-50%,50%+)的 NCA 数据分别进行 pre-pre-training,比较迁移效果。
核心发现:最优 NCA 复杂度因下游域而异,且与目标语料库的内在复杂度直接对应:
| 目标域 | 语料 gzip 率 | 最优 NCA 复杂度带 |
|---|---|---|
| OpenWebText | ~70% | 50%+(高复杂度) |
| OpenWebMath | ~58% | 50%+(高复杂度) |
| CodeParrot | ~32% | 30-40%(中等复杂度) |
这一"复杂度匹配原则"(complexity matching principle)提供了一个在自然语言 pre-training 中从未有过的调控杆:与其增加通用 token 数量,不如调整合成数据的复杂度分布使其与目标域对齐,以更低的计算代价获得更好的迁移效果。
Alphabet Size 的 Scaling 行为
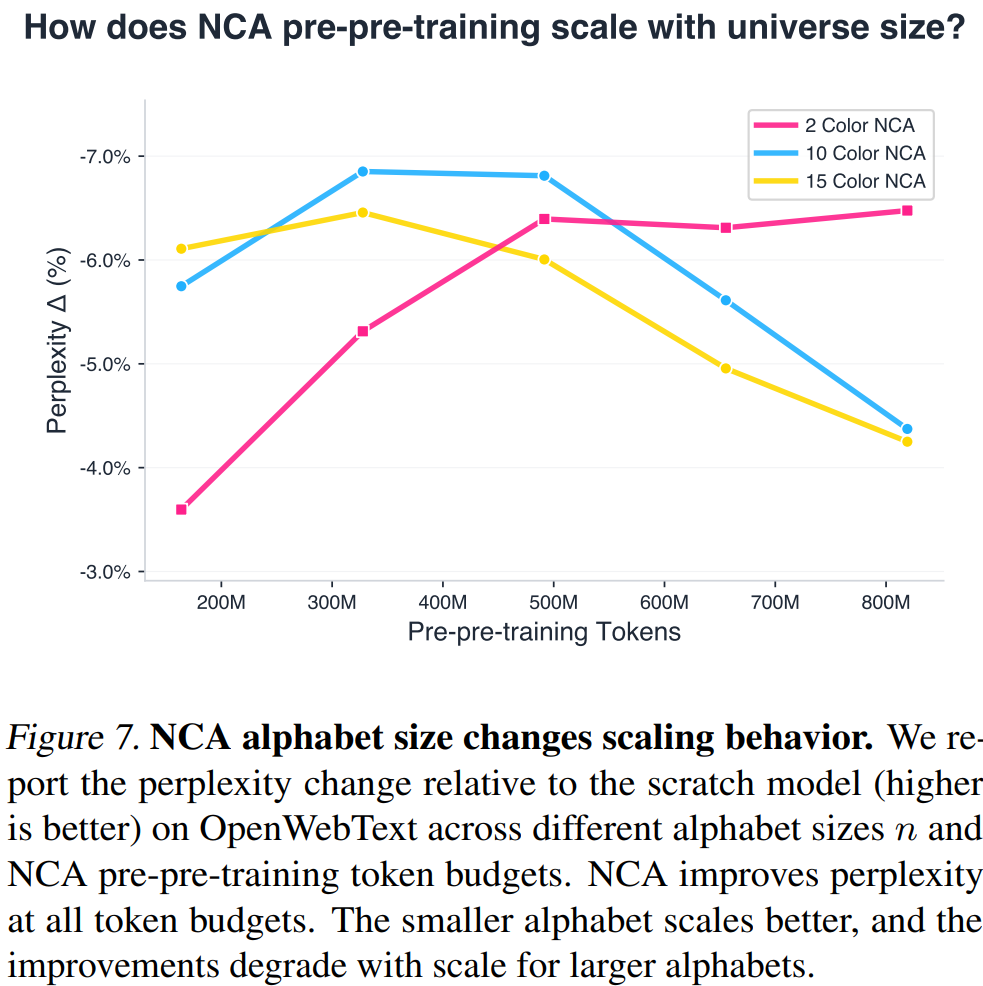
对 NCA 状态字母表大小 n ∈ { 2 , 10 , 15 } n \in \{2, 10, 15\} n∈{2,10,15} 的消融实验揭示了一个反直觉的现象。
更大的 alphabet( n = 10 , 15 n = 10, 15 n=10,15)会产生更复杂的 NCA 动态,但其扩展规律呈现反向 U 形:在中等 token 预算时效果最优,超过后趋于平稳甚至退化。
出人意料的是,最小的 alphabet( n = 2 n = 2 n=2)在 token 预算增大时仍持续改善,展现出最佳的扩展性。作者推测原因是:较小的规则空间将采样集中于具有更一致、更普遍可迁移结构的动态上。较大 alphabet 虽然能表达更复杂的动态,但在没有主动引导的情况下,难以保证采样到的 NCA 具有最优的迁移价值。
为什么合成数据能优于语言数据?
In-context Rule Inference 的"纯粹性"
在自然语言文本中,模型可以依赖词语的语义共现先验作为预测捷径------例如,看到"巴黎"就预测"法国",看到"if" 就预测"then"。这些捷径有时会阻碍模型学习更深层的计算机制(Shortcut Learning in Deep Neural Networks,2020 称之为"shortcut learning")。
在 NCA 序列中,每条序列的动态规则完全由随机 θ \theta θ 决定,模型没有任何语义捷径可以走。唯一的预测策略是:从 context 中推断 θ \theta θ,再据此推断下一个状态。这迫使模型发展出更纯粹的 in-context rule inference 能力。
用 An Explanation of In-Context Learning as Implicit Bayesian Inference(2022)的 Bayesian 框架表述:NCA pre-pre-training 鼓励模型进行
p ( θ ∣ x < i ) ∝ p ( x < i ∣ θ ) ⋅ p ( θ ) p(\theta \mid x_{<i}) \propto p(x_{<i} \mid \theta) \cdot p(\theta) p(θ∣x<i)∝p(x<i∣θ)⋅p(θ)
的隐式推断,而自然语言 pre-pre-training 在有限 token 预算下大量学习的是更浅层的 p ( x i ∣ x < i ) p(x_i \mid x_{<i}) p(xi∣x<i) 的表面统计规律。
Epiplexity:确定性过程也能产生有用信息
经典信息论认为确定性变换不能增加信息量,这似乎质疑了 NCA(本质上是确定性动态系统)为何能提供有用的训练信号。
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence(2026)提出的 epiplexity 概念回答了这个问题:对于计算能力有限的观察者,确定性过程可以产生"有用的结构信息"。NCA 的局部规则(如 Conway 生命游戏中的滑翔机)能够产生涌现结构,而一个有限容量的模型无法暴力模拟这些涌现------它必须学习能够在更粗粒度抽象层次上预测演化的表征。正是这种"学习抽象表征"的压力,与语言建模对"学习语言规律"的压力存在深层对应。
NCA 作为通用计算的样本
NCA 作为一类计算系统,覆盖了从平凡(固定点)到图灵完备(Turing Universality of the Game of Life,证明 Conway 生命游戏是图灵完备的)的广泛计算函数。这种多样性使得记忆单个规则变得不可行,迫使模型学习普遍的规则推断机制。相比之下,K-Dyck 或字符串复制这类先前的合成任务,每种任务只对应一类固定的计算结构,多样性有限。
Token 效率的定量计算
论文在附录中定义了一个更精确的 Token Efficiency Gain 指标:
Token Efficiency Gain = 1 − T PPT NCA + T PT NCA T PPT base + T PT base \text{Token Efficiency Gain} = 1 - \frac{T_{\text{PPT}}^{\text{NCA}} + T_{\text{PT}}^{\text{NCA}}}{T_{\text{PPT}}^{\text{base}} + T_{\text{PT}}^{\text{base}}} Token Efficiency Gain=1−TPPTbase+TPTbaseTPPTNCA+TPTNCA
其中 T PPT T_{\text{PPT}} TPPT 是 pre-pre-training 阶段消耗的 token 数, T PT T_{\text{PT}} TPT 是在 pre-training 阶段达到 scratch baseline 最终 loss 所需的 token 数。对于 scratch baseline, T PPT base = 0 T_{\text{PPT}}^{\text{base}} = 0 TPPTbase=0。
该指标衡量的是:在达到等效性能的情况下,总 token 消耗的节省比例。
实测结果:
| 目标域 | Token Efficiency Gain |
|---|---|
| OpenWebText | 31% |
| OpenWebMath | 27% |
| CodeParrot | 49% |
以 CodeParrot 为例,这意味着:使用 NCA pre-pre-training 后,达到 scratch 模型最终性能只需 51% 的总 token 预算,节省了近一半的计算资源。
NCA 数据的统计特性:为什么它"像"自然语言?
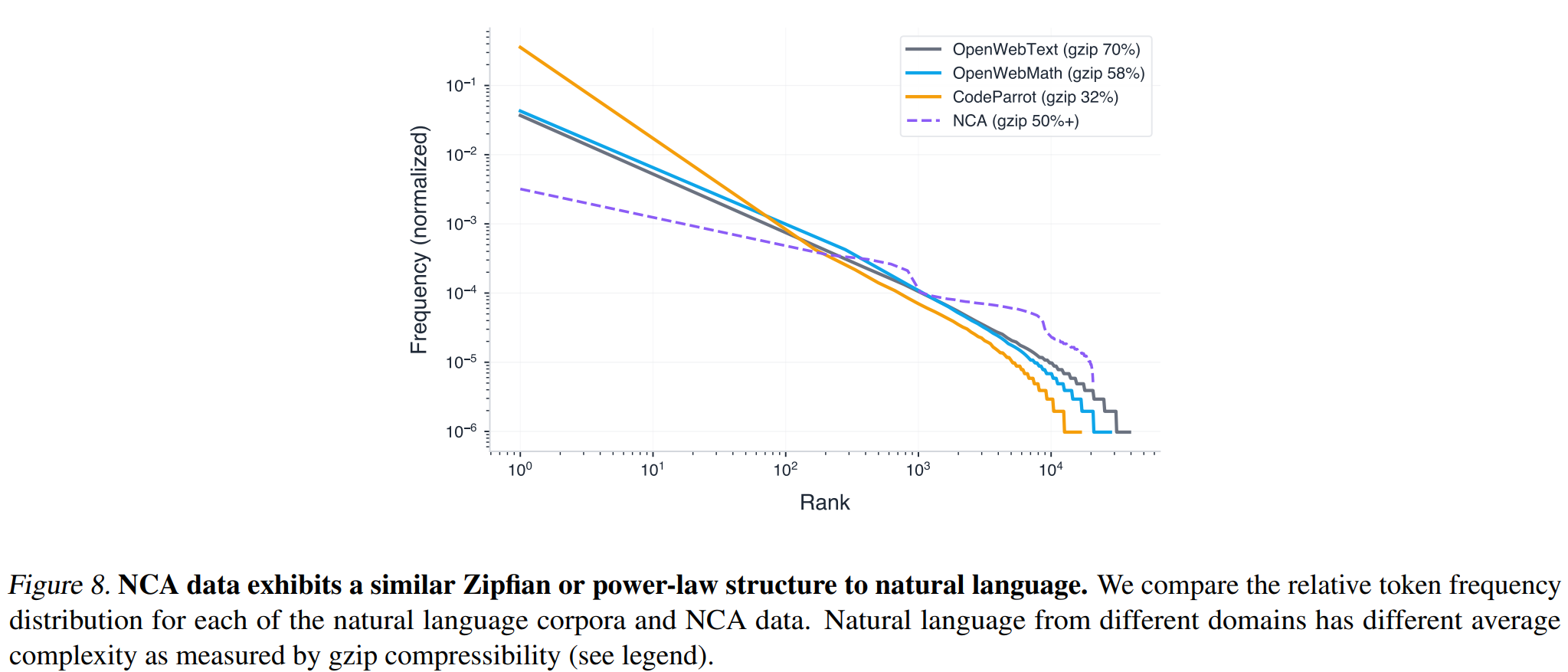
附录 A 的分析揭示了 NCA 数据具有与自然语言相似的重尾 Zipfian(幂律)分布:token 频率随 rank 的下降呈幂律衰减,与 OpenWebText、OpenWebMath、CodeParrot 的分布高度相似。
Learning to See by Looking at Noise 提出了"naturalistic data" 的概念:重要的不是数据本身是否来自自然,而是数据是否复现了自然界的统计结构。Zipfian 分布和 approximate scale-invariance 是自然语言的两大关键统计特征,NCA 数据恰好同时具备。
局限性与未来工作
已知局限
- Alphabet 扩展的瓶颈。对于较大的 alphabet( n = 10 , 15 n = 10, 15 n=10,15),存在明显的 token 预算下的 U 形收益曲线:在中等预算时效果最优,超过后改善停滞。这表明有效的合成 pre-training 高度依赖数据生成器的结构选择,而非仅仅是数据规模。
- 复杂度度量的局限。Gzip 压缩率和 alphabet 大小是复杂度的两个视角,但复杂度本身是多维的,一个序列可以高度可压缩却具有丰富的长程依赖,或反之。目前缺乏能够精确刻画"哪种复杂度对哪种任务有益"的理论框架。
- 能否完全替代自然语言? 目前的工作仅验证了 NCA 作为 pre-pre-training 信号的价值,并未回答"能否用 NCA 完全替代自然语言 pre-training" 这一更根本的问题。
未来方向
- 原则性的合成数据设计方法:如何根据目标域的计算特性,自动设计最优的合成数据生成器?复杂度匹配的方向是已经明确的,但精确化的方法尚待开发。
- 更多维度的复杂度调控:NCA 网络规模、网格尺寸、epiplexity 等维度的影响尚未系统研究。
- 迈向完全合成 pre-training:作者的终极愿景是在合成数据上完成全部 pre-training,再用少量筛选后的自然语言进行 fine-tuning 以习得语义。NCA 代表了向这一目标迈出的第一步。
总结
这篇工作提出并验证了一个挑战直觉的核心命题:精心设计的合成数据(NCA)可以在数量远少于自然语言的情况下,提供更有效的语言模型预训练信号。
其成功背后的机理可以归结为两点:
- 结构而非语义:NCA 的时空结构迫使模型学习 in-context rule inference 这一通用计算能力,而不是浅层的语义共现模式;
- 可控的复杂度:NCA 提供了自然语言数据中从未有过的调控维度,可以系统性地调整合成数据的复杂度分布,使其与目标域的计算特性对齐。
这项工作的意义不仅在于"NCA 有效",而在于它开辟了一条新的研究方向:问题不再是"合成 pre-training 是否可行",而是"如何设计能最大化模型学习效果的合成数据分布"。