1. 正则表达式介绍
核心定义:
正则表达式(简称 "正则")就是一套字符匹配的 "规则公式" ------ 你用特定的符号组合成 "规则",去文本里找符合这个规则的内容。
最核心的逻辑:
正则的本质是:用 "元字符"(特殊符号) + 普通字符,描述你要找的字符模式。
比如:
- 普通字符:a、1、中(就是字面意思,匹配自己)
- 元字符:\d、*、^(有特殊含义,是正则的核心)
使用步骤:
1. 导包.
import re
2. 正则校验.
result = re.match(pattern=正则规则, str=要校验的字符串, flag=0)
参1: 正则表达式, 参2: 要校验的字符串, 参3: 可选项, 例如: 忽略大小写, 多行模式等...
3. 获取到匹配的数据.
result.group()
2. match 和 search 匹配函数(Python 里用)
这两个是 Python 内置的正则函数,核心作用是用正则规则去文本里找内容,
从左往右, 逐个字符的匹配, 不会跳过某个字符, 即: 全词匹配.
第一步:先导入正则模块(所有操作的前提)

match 函数:只从文本开头匹配
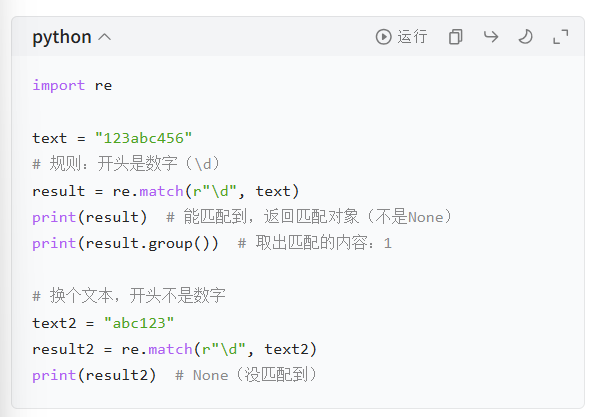
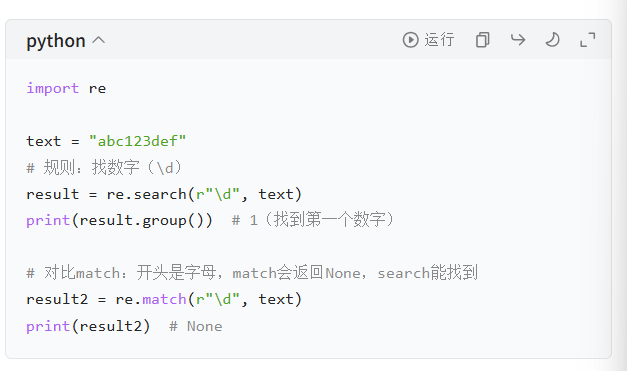
search 函数:在文本任意位置匹配,
从左往右, 依次匹配, 即: 只要某部分满足条件即可.
- 语法:re.search(正则规则, 要匹配的文本)
- 特点:扫描整个文本,找到第一个符合规则的内容就停;比 match 灵活,日常用得更多。
- 例子:
关键区别(记死)
|--------|----------|------------|----------------|
| 函数 | 匹配位置 | 没匹配到返回 | 适用场景 |
| match | 文本开头 | None | 校验文本开头是否符合规则 |
| search | 文本任意位置 | None | 找文本里是否有符合规则的内容 |
3. compile 函数:预编译正则规则
核心作用:
如果同一个正则规则要重复用很多次 (比如处理 10 万条大模型训练数据),先用compile把规则编译成 "正则对象",能提升运行速度(对你来说,主要是代码更简洁)。
- 语法:pattern = re.compile(正则规则) → 得到一个 "规则对象",之后用这个对象调用 match/search。
- 例子:
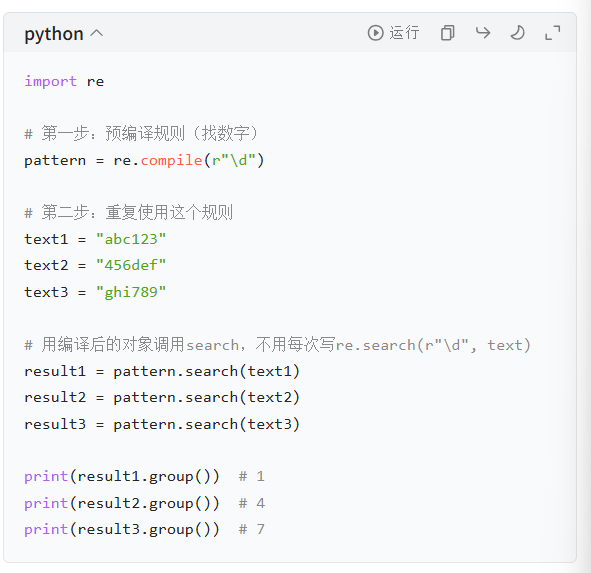
什么时候用?
规则要重复用(比如循环处理数据)→ 用 compile,省时间。
- 规则只用一次 → 直接用 re.match/re.search 就行,不用多此一举。
4. 匹配单个字符
这是正则的基础,核心是 "用符号匹配一个字符",记下面这几个最常用的(不用多,够用就行):
|--------|---------------------|-------------------------------------------------------------------|
| 符号 | 含义 | 例子 |
| . | 匹配任意 1 个字符(除换行) | re.match(r".", "a") → 匹配 a;re.match(r".", "1") → 匹配 1 |
| \d | 匹配 1 个数字(0-9) | re.match(r"\d", "8") → 匹配 8;re.match(r"\d", "a") → None |
| \w | 匹配 1 个字母 / 数字 / 下划线 | re.match(r"\w", "") → 匹配;re.match(r"\w", "@") → None |
| \s | 匹配 1 个空白符(空格 / 制表符) | re.match(r"\s", " ") → 匹配空格;re.match(r"\s", "a") → None |
| \[\] | 匹配 \[\] 里的任意 1 个字符 | re.match(r"abc", "b") → 匹配 b;re.match(r"0-9", "5") → 匹配 5 |
实操例子(零基础能看懂)
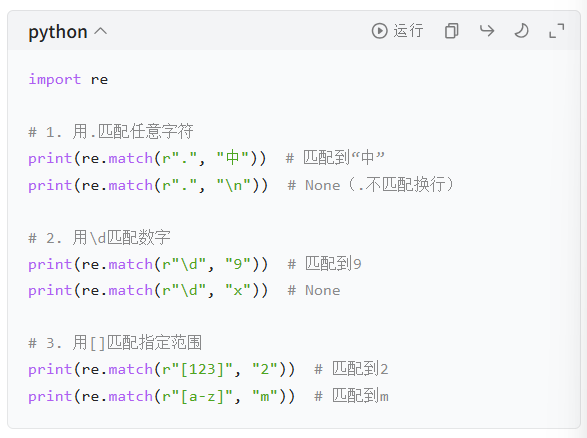
5. 匹配多个字符
单个字符不够用?用这些符号控制 "匹配的数量",和上面的单个字符搭配用(核心中的核心):
|--------|-------------|--------------------------------------------------------------------------|
| 符号 | 含义 | 例子(结合 \d) |
| * | 匹配 0 次或多次 | re.match(r"\d*", "123") → 匹配 123; re.match(r"\d*", "abc") → 匹配空(0 次) |
| + | 匹配 1 次或多次 | re.match(r"\d+", "123") → 匹配 123; re.match(r"\d+", "abc") → None |
| ? | 匹配 0 次或 1 次 | re.match(r"\d?", "1") → 匹配 1; re.match(r"\d?", "abc") → 匹配空 |
| {n} | 匹配正好 n 次 | re.match(r"\d{3}", "123") → 匹配 123; re.match(r"\d{3}", "12") → None |
| {n,} | 匹配至少 n 次 | re.match(r"\d{2,}", "123") → 匹配 123; re.match(r"\d{2,}", "1") → None |
| {n,m} | 匹配 n 到 m 次 | re.match(r"\d{2,4}", "12345") → 匹配 1234(最多 4 次) |
实操例子(最常用的场景)
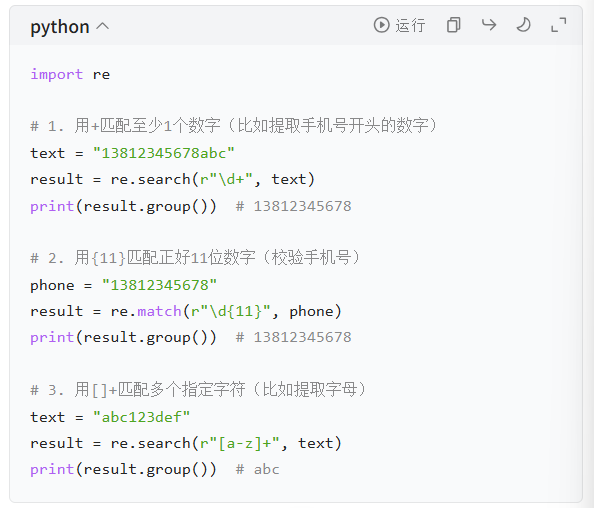
6. 校验开头和结尾
想确保文本 "开头是 XX" 或 "结尾是 XX"?用这两个符号:
|--------|--------|----------------------------------------------------------------------------|
| 符号 | 含义 | 例子 |
| ^ | 匹配文本开头 | re.match(r"^abc", "abc123") → 匹配 abc; re.match(r"^abc", "123abc") → None |
| | 匹配文本结尾 | re.search(r"123", "abc123") → 匹配 123; re.search(r"123$", "123abc") → None |
关键:^ 和 $ 一起用 = 完全匹配(校验整个文本)
比如校验是不是纯 11 位数字(手机号):
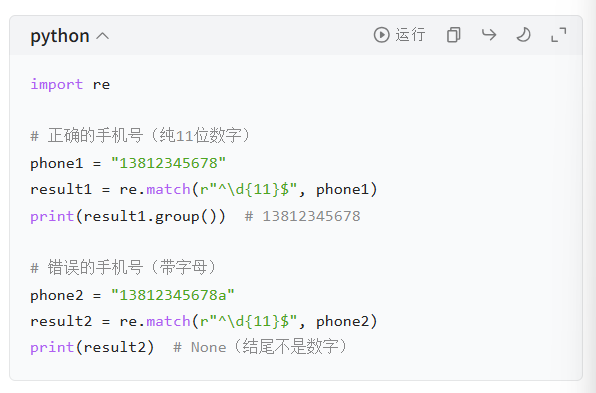
7. 正则 - 或者(|)
想匹配 "要么 A,要么 B"?用|符号,相当于逻辑里的 "或"。
- 语法:规则1|规则2
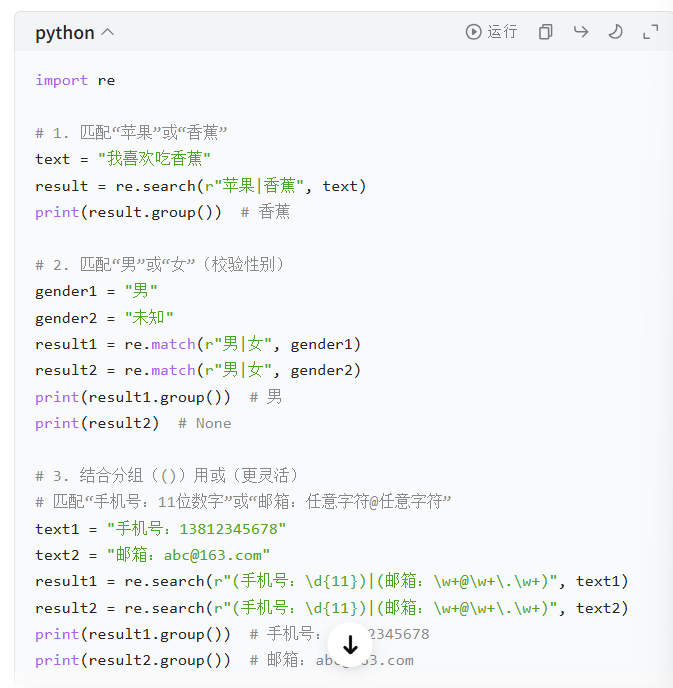
- 例子:匹配 "苹果" 或 "香蕉"、匹配 "男" 或 "女"
实操例子