
| 🔭 个人主页: 散峰而望 |
|---|
《C语言:从基础到进阶》《编程工具的下载和使用》《C语言刷题》
《C++》《算法竞赛从入门到获奖》《人工智能》《AI Agent》
愿为出海月,不做归山云
🎬博主简介



【基础算法】剪枝与记忆化搜索:算法优化的双刃剑,效率倍增的实战指南
- 前言
- [1. 剪枝与优化](#1. 剪枝与优化)
-
- [1.1 数的划分](#1.1 数的划分)
- [1.2 小猫爬山](#1.2 小猫爬山)
- [2. 记忆化搜索](#2. 记忆化搜索)
-
- [2.1 斐波那契数](#2.1 斐波那契数)
- [2.2 Function](#2.2 Function)
- [2.3 天下第一](#2.3 天下第一)
- [2.4 滑雪](#2.4 滑雪)
- 结语
前言
在算法设计与优化中,剪枝与记忆化搜索是两种强大的技术,能够显著提升程序效率。剪枝通过提前终止无效分支减少计算量,常用于搜索与回溯问题;记忆化搜索则通过存储中间结果避免重复计算,适用于递归与动态规划场景。这两种方法如同双刃剑,合理运用能实现效率倍增,但过度或不恰当的优化可能适得其反。
本指南将通过经典案例(如数的划分、小猫爬山、斐波那契数等)剖析剪枝与记忆化搜索的核心思想,结合实战演示如何平衡优化与代码复杂度,帮助开发者掌握高效算法的设计精髓。
1. 剪枝与优化
剪枝,形象地说,就是剪掉搜索树中的冗余分支,从而减小搜索规模,排除无必要的搜索路径,达到优化时间复杂度的目的。在深度优先遍历中,常见的剪枝方法有以下几种:
- 排除等效冗余
如果在搜索过程中,通过某一个节点往下的若干分支中,存在最终结果等效的分支,那么就只需要搜索其中一条分支。 - 可行性剪枝
如果在搜索过程中,发现有一条分支是无论如何都拿不到最终解,此时就可以放弃这个分支,转而搜索其它的分支。 - 最优性剪枝
在最优化的问题中,如果在搜索过程中,发现某一个分支已经超过当前已经搜索过的最优解,那么这个分支往后的搜索,必定不会拿到最优解。此时应该停止搜索,转而搜索其它情况。 - 优化搜索顺序
在有些搜索问题中,搜索顺序是不影响最终结果的,此时搜索顺序的不同会影响搜索树的规模。
因此,应当先选择一个搜索分支规模较小的搜索顺序,快速拿到一个最优解之后,用最优性剪枝剪掉别的分支。 - 记忆化搜索
记录每一个状态的搜索结果,当下一次搜索到这个状态时,直接找到之前记录过的搜索结果。记忆化搜索,有时也叫动态规划。
1.1 数的划分

算法原理:
搜索策略:
题目类似于组合型枚举。
- 将
[1, n]个数放在k个坑里,使得所有坑内数的总和为n。 - 其中,不同的坑内的数可以相同。
- 但是,
[1, 2]与[2, 1]被视为同一种分法,因此这是一种组合型枚举 。在为每一个坑选择填入哪个数时,应该从上一次填入的数开始枚举,以避免产生重复的组合。
剪枝策略:
- 当我们已经填充了
cnt个坑,当前总和为sum时,如果后续所有坑位都填入允许的最小值 ,总和仍然会超过n,则说明之前填入的数过大,后续无论如何填充都无法满足条件,此时可以直接"剪掉"这条搜索路径,不再继续向下探索。
注意:剪枝条件设置的位置不同,会导致生成的搜索树大小不同,直接影响算法效率。

参考代码:
cpp
#include <iostream>
using namespace std;
int n, k;
int path, ret;
void dfs(int pos, int begin)
{
if(pos == k)
{
if(path == n) ret++;
return;
}
for(int i = begin; i <= n; i++)
{
if(path + i * (k - pos) > n) return;
path += i;
dfs(pos + 1, i);
path -= i;
}
}
int main()
{
cin >> n >> k;
dfs(0, 1);
cout << ret << endl;
return 0;
}1.2 小猫爬山
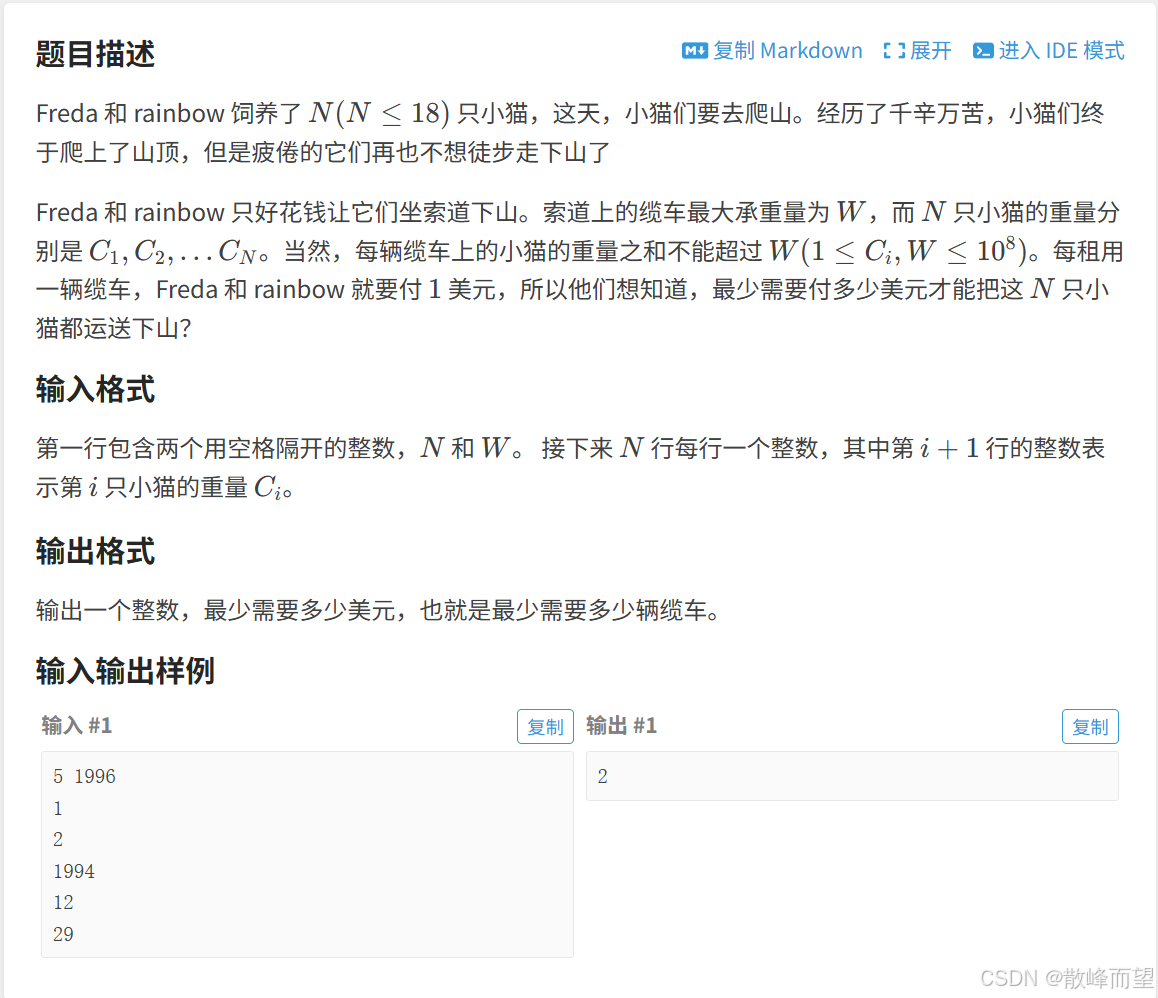
算法原理:
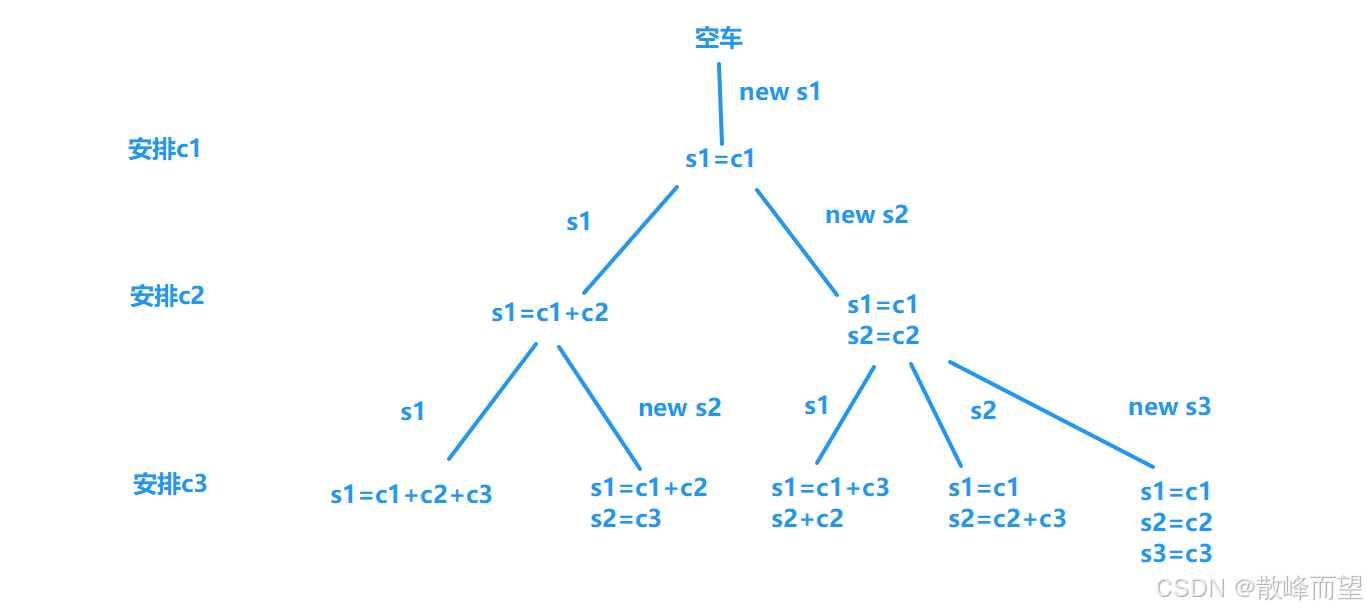
搜索策略:依次处理每一只猫,对于每一只猫,我们都有两种处理方式:
- 要么把这只猫放在已经租好的缆车上;
- 要么重新租一个缆车,把这只猫放上去。
剪枝:
- 在搜索过程中,我们用全局变量记录已经搜索出来的最小缆车数量。如果当前搜索过程中,已经用的缆车数量大于全局记录的最小缆车数量,那么这个分支一定不会得到最优解,剪掉。
- 优化枚举顺序一:从大到小安排每一只猫
◦ 重量较大的猫能够快速把缆车填满,较快得到一个最小值;
◦ 通过这个最小值,能够提前把分支较大的情况提前剪掉。 - 优化枚举策略二:先考虑把小猫放在已有的缆车上,然后考虑重新租一辆车
◦ 因为如果反着来,我们会先把缆车较大的情况枚举出来,这样就起不到剪枝的效果了。
参考代码:
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 20;
int n, w;
int c[N];//小猫信息
int cnt;//当前用多少车
int s[N]; //每一辆车重量
int ret = N;
bool cmp(int a, int b)
{
return a > b;
}
void dfs(int pos)
{
//最优性剪枝
if(cnt >= ret) return;
if(pos > n)
{
ret = cnt;
return;
}
//先安排已有的车
for(int i = 1; i <= cnt; i++)
{
if(s[i] + c[pos] > w) continue;
s[i] += c[pos];
dfs(pos + 1);
s[i] -= c[pos];//恢复现场
}
//重开一辆
cnt++;
s[cnt] = c[pos];
dfs(pos + 1);
//恢复现场
s[cnt] = 0;
cnt--;
}
int main()
{
cin >> n >> w;
for(int i = 1; i <= n; i++) cin >> c[i];
//优化搜索顺序
sort(c + 1, c + 1 + n, cmp);
dfs(1);
cout << ret << endl;
return 0;
}2. 记忆化搜索
记忆化搜索也是一种剪枝策略。
通过一个"备忘录",记录第一次搜索到的结果,当下一次搜索到这个状态时,直接在"备忘录"里面找结果。
记忆化搜索,有时也叫动态规划。
-
如何实现记忆化搜索
(1) 创建备忘录;
(2) 递归返回的时候,先存储到备忘录里面;
(3) 递归的时候,先往备忘录里面看一看有没有相关的值。
-
所有的递归以及暴搜,都能用记忆化搜索来优化吗
不是,必须在递归过程中出现大量 "完全相同的问题"。
注意:初始化备忘录时,备忘录中一定不能存在递归过程中可能出现的值。
2.1 斐波那契数
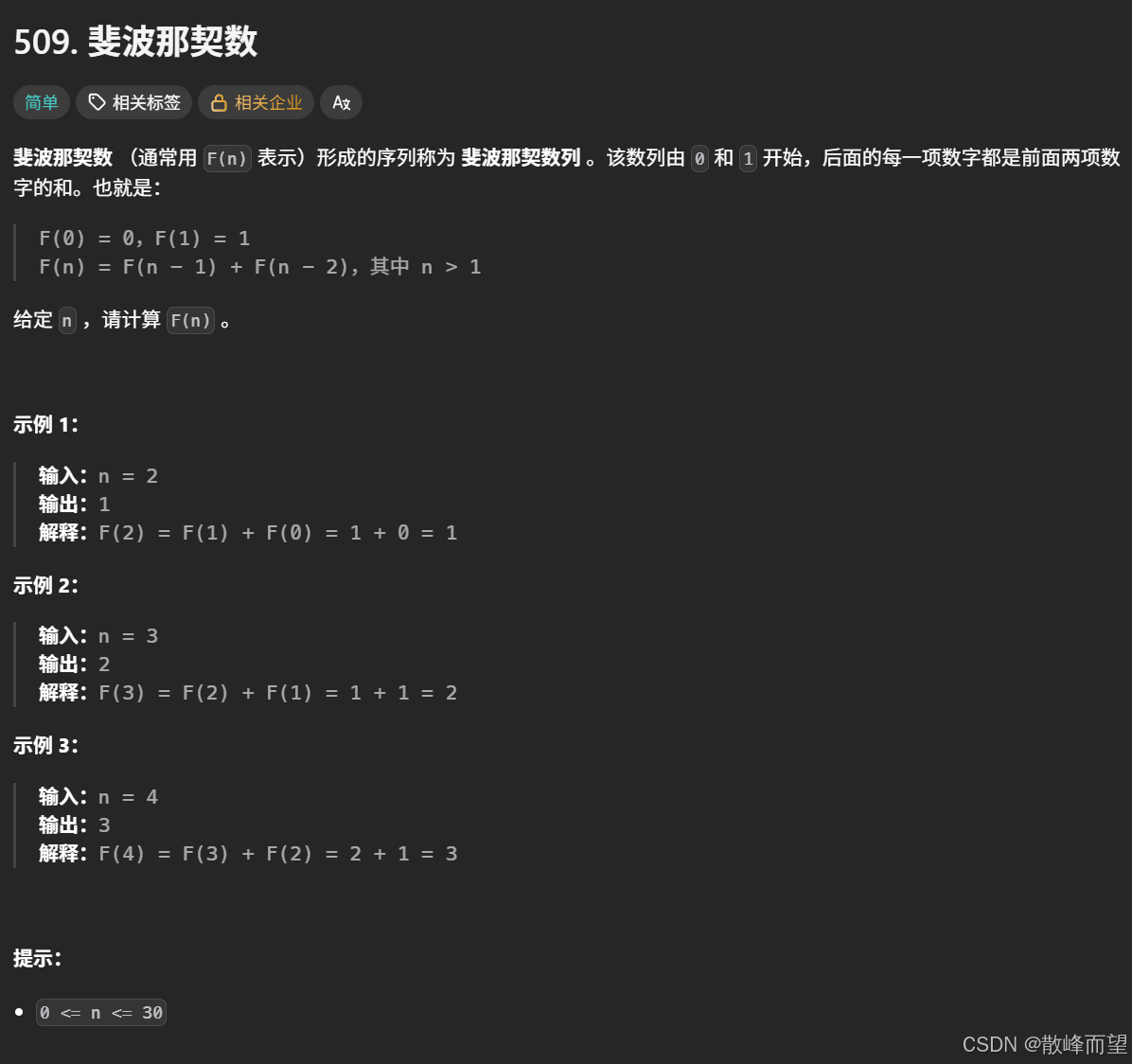
算法原理:
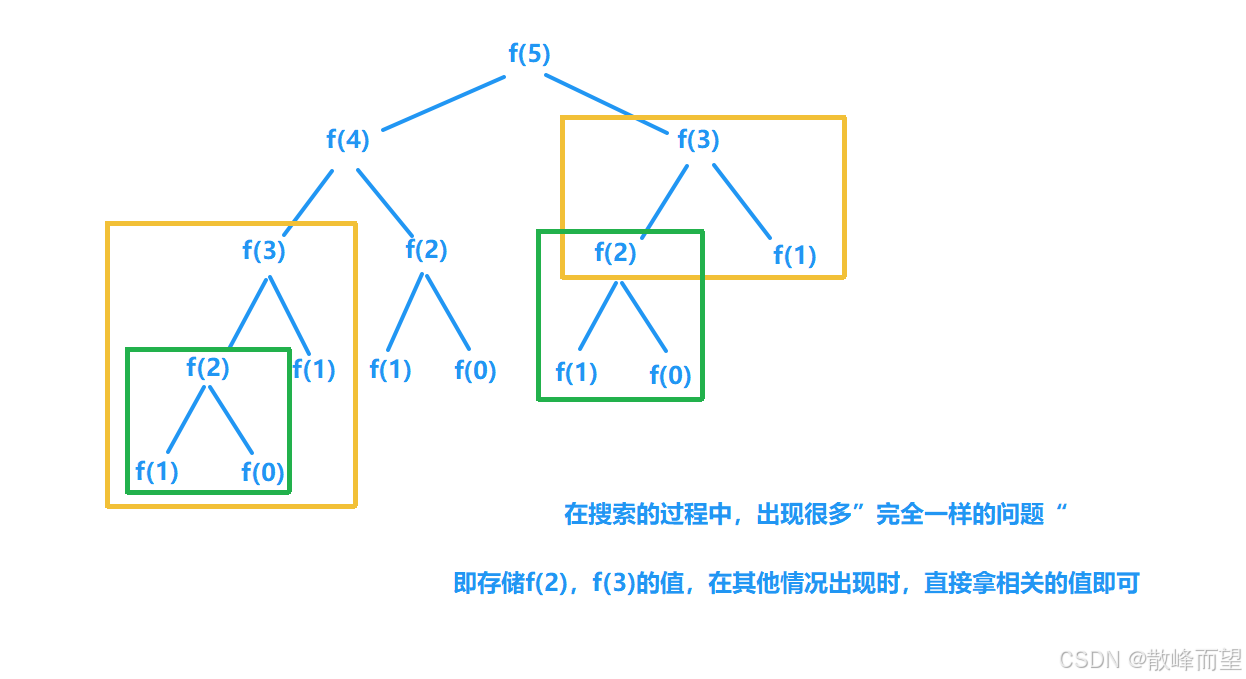
在搜索的过程中,如果发现特别多完全相同的子问题,就可以添加一个备忘录,将搜索的结果放在备忘录中。下一次在搜索到这个状态时,直接在备忘录里面拿值。
算法原理:
cpp
class Solution {
int f[35];//备忘录
public:
int fib(int n) {
memset(f, -1, sizeof f);
return dfs(n);
}
int dfs(int n) {
if(f[n] != -1) return f[n];
if(n == 0 || n == 1) return n;
f[n] = dfs(n - 1) + dfs(n - 2);
return f[n];
}
};2.2 Function

算法原理:
题目叙述的非常清楚,我们仅需按照「题目的要求」把「递归函数」写出来即可。但是,如果不做其余处理的话,结果会「超时」。因为我们递归的「深度」和「广度」都非常大。
通过把「递归展开图」画出来,我们发现,在递归过程中会遇到大量「一模一样」的问题,如下图(因为递归展开过于庞大,这里只画出了一部分):
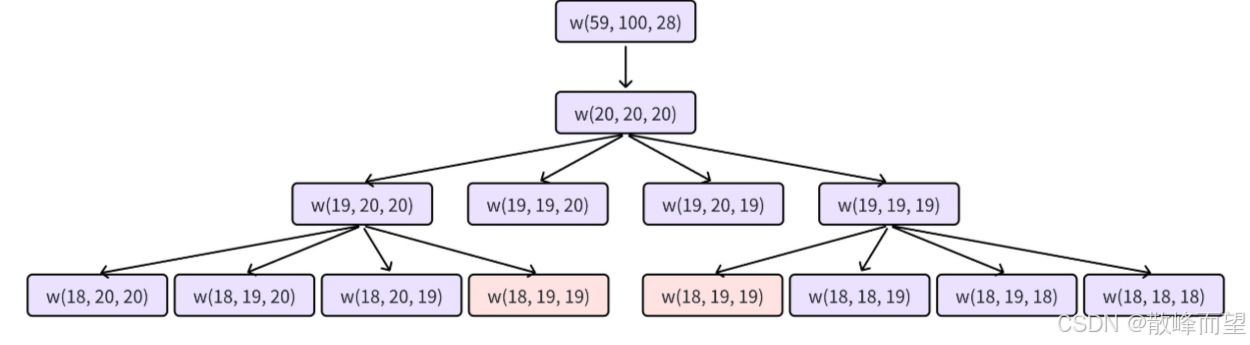
因此,可以在递归的过程中,把每次算出来的结果存在一张「备忘录」里面。等到下次递归进入一模一样 的问题之后,在备忘录里面直接把结果拿出来,起到大量剪枝的效果。
参考代码:
cpp
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 25;
LL a, b, c;
LL f[N][N][N];//备忘录
LL dfs(LL a, LL b, LL c)
{
if(a <= 0 || b <= 0 || c <= 0) return 1;
if(a > 20 || b > 20 || c > 20) return dfs(20, 20, 20);
if(f[a][b][c]) return f[a][b][c];
if(a < b && b < c) return f[a][b][c] = dfs(a, b, c -1) + dfs(a, b - 1, c - 1) - dfs(a, b - 1, c);
else return f[a][b][c] = dfs(a - 1, b, c) + dfs(a - 1, b - 1, c) + dfs(a - 1, b, c -1) - dfs(a - 1, b - 1, c -1);
}
int main()
{
while(cin >> a >> b >> c)
{
if(a == -1 && b == -1 && c == -1) break;
printf("w(%lld, %lld, %lld) = %lld\n", a, b, c, dfs(a, b, c));
}
} 2.3 天下第一

算法原理:
用递归模拟整个游戏过程:dfs(x, y) 的结果可以由 dfs((x + y) % p, (x + y + y) % p) 得到。
因为测试数据是多组的,并且模数都是 p,再加上递归的过程中会遇到相同的子问题,所以可以把递归改写成记忆化搜索。其中:
f[x][y] = 1,表示cbw赢;f[x][y] = 2,表示zhouwc赢;f[x][y] = 3表示这个位置已经被访问过,如果没被修改成1或者2,那就表明平局。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 1e4 + 10;
int x, y, p;
char f[N][N];//备忘录
char dfs(int x, int y)
{
if(f[x][y]) return f[x][y];
f[x][y] = '3';
if(x == 0) return f[x][y] = '1';
if(y == 0) return f[x][y] = '2';
return f[x][y] = dfs((x + y) % p, (x + y + y) % p);
}
int main()
{
int T; cin >> T >> p;
while(T--)
{
cin >> x >> y;
char ret = dfs(x, y);
if(ret == '1') cout << 1 << endl;
else if(ret == '2') cout << 2 << endl;
else cout << "error" << endl;
}
return 0;
} 2.4 滑雪

算法原理:
暴力枚举思路
遍历整个矩阵,计算以每一个位置 [i, j] 作为起点时,能够滑行的最远距离。最终,在所有计算结果中取最大值,即为问题的答案。
如何求解以 [i, j] 为起点的最远距离?
核心思路是递归地向四周探索:
- 从
[i, j]位置向 上、下、左、右 四个方向进行判断。 - 如果相邻位置的值 小于 当前位置的值(即满足下滑条件),则递归地计算 以该相邻位置为起点 的最远滑行距离。
- 从四个方向可能的结果中,找出那个 最大的距离 ,然后在此基础上 +1 (代表从
[i, j]移动到该相邻位置的一步),即得到从[i, j]出发的最远距离。
优化:从 DFS 到记忆化搜索
- 在递归求解过程中,以不同位置为起点的最大距离会被重复计算,这些是 相同的子问题。
- 因此,可以将基础的深度优先搜索(DFS)改造为 记忆化搜索(Memoization)。
- 具体做法是:使用一个缓存数组(例如
f[i][j])来存储已经计算出的、以[i, j]为起点的最远距离。当再次需要这个结果时,可以直接从缓存中读取,避免重复的递归计算,从而大幅提升算法效率。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 110;
int n, m;
int a[N][N];
int f[N][N];
int dx[] = {0, 0, 1, -1};
int dy[] = {1, -1, 0, 0};
int dfs(int i, int j)
{
if(f[i][j]) return f[i][j];
int len = 1;
//上下左右方向搜
for(int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if(x < 1 || x > n || y < 1 || y > m) continue;
if(a[i][j] <= a[x][y]) continue;
len = max(dfs(x, y) + 1, len);
}
return f[i][j] = len;
}
int main()
{
cin >> n >> m;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
cin >> a[i][j];
int ret = 1;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
ret = max(dfs(i, j), ret);
cout << ret << endl;
}结语
剪枝与记忆化是算法优化的核心手段。剪枝通过减少无效路径提升效率,记忆化通过避免重复计算加速执行。二者往往结合使用,在搜索、动态规划等问题中效果显著。掌握这些技术需要深入理解问题本质,合理设计剪枝条件和记忆化策略。实践中的关键在于平衡时空开销,针对具体问题选择最佳优化方式。
愿诸君能一起共渡重重浪,终见缛彩遥分地,繁光远缀天。
