我把传统项目问答升级成了 Agent-RAG:Spring Boot + FastAPI + ChromaDB 工程落地实践
还在让 AI 靠"猜"理解你的项目吗?
我最近把 SwiftBoot 里的项目问答链路从"普通 RAG 检索"升级成了一套更像工程系统的 Agent-RAG:前面先做意图分流,再按需调用源码检索或文档检索,后面再接长期记忆、实时增量索引和流式输出。做完之后,一个很直观的变化是:AI 不再只会给通用答案,而是真的开始"按项目说话"了。
先说结论:为什么我没有停在"普通 RAG"
很多人给项目接 AI 的第一步,通常是这样的:
- 把代码切片
- 存进向量库
- 用户一提问就统一检索
- 把结果拼进 Prompt 里让大模型回答
这条路当然能跑通,但只要项目稍微复杂一点,很快就会遇到几个问题:
- 用户明明在问"具体哪段代码怎么实现",系统却把一堆说明文档也塞进来
- 用户其实在问"这个功能怎么用",系统却优先命中了底层源码片段
- 代码刚改完,知识库还是旧的
- 前一轮已经聊过的上下文,下一轮又得重新解释一遍
- AI 虽然答对了,但你不知道它到底引用了哪些内容
我后来意识到,问题不在于"有没有 RAG",而在于检索链路太粗了。
如果把所有问题都丢给同一种检索策略,最后得到的往往不是"更聪明的 AI",而是"更昂贵的模糊匹配"。
所以这次我做的不是再加一个向量库,而是把整条问答链路拆开,做成了一套更像真实系统的 Agent-RAG。
这套 Agent-RAG 到底长什么样
我先给一张流程图,基本就是 SwiftBoot 里现在的实际链路。
CODE
DOC
MEMORY
CHAT
用户提问
Spring Boot / SysAiController
意图预检 /intent/detect
意图类型
Agent 工具 fetch_source_impl
Agent 工具 fetch_business_doc
长期记忆召回 /memory/query
直接回答或快路径规则
FastAPI /retrieve
ChromaDB 检索 code/doc 集合
按 intent + tool_name 二次重排
返回相关代码/文档片段
历史记忆集合 memory
LLM 生成最终回答
SSE 流式输出到前端
Watchdog 文件监听
增量切片解析
project-skills 技能库
如果只看这张图,最核心的区别就 3 个:
- 不是"所有问题统一检索",而是先做意图路由
- 不是"一个 search 工具包打天下",而是拆成源码检索和文档检索两个工具
- 不是"只管查代码",而是把长期记忆、增量同步、技能知识库、流式输出一起纳入链路
1. Java 侧不直接硬搜,而是先把问题变成"任务类型"
SwiftBoot 这边的后端入口在 SysAiController。我这里没有让大模型一上来就盲搜,而是先定义了两个明确的 Agent 工具:
fetch_source_impl:专门查源码fetch_business_doc:专门查业务文档
对应代码大致就是这样:
java
private JSONArray buildAgentTools() {
JSONArray tools = new JSONArray();
JSONObject fetchSourceTool = new JSONObject();
fetchSourceTool.set("type", "function");
JSONObject f1 = new JSONObject();
f1.set("name", "fetch_source_impl");
f1.set("description", "当用户询问具体代码实现、报错排查、数据库表结构、接口定义或类方法时调用。");
JSONObject fetchDocTool = new JSONObject();
fetchDocTool.set("type", "function");
JSONObject f2 = new JSONObject();
f2.set("name", "fetch_business_doc");
f2.set("description", "当用户询问系统整体架构、业务流程、功能使用说明时调用。");
tools.add(fetchSourceTool);
tools.add(fetchDocTool);
return tools;
}这个设计看起来很简单,但收益特别大。
因为很多项目问答失败,不是向量库不行,而是问题类型没有分清楚。
举个最典型的例子:
- "
SysUserController里分页查询怎么做的?"这显然应该走源码检索 - "这个系统的权限中心怎么使用?"这其实更适合走文档和技能知识
你要是让这两类问题用同一套召回逻辑,最终结果大概率就是一锅粥。
2. FastAPI 这层不是摆设,它承担了真正的检索编排
我把检索引擎单独放在了 Python 侧,用 FastAPI 暴露接口,核心入口包括:
/retrieve/memory/add/memory/query/intent/detect/nlp/similarity
主入口大致像这样:
python
app = FastAPI(title="SwiftBoot AI Knowledge Engine")
@app.post("/retrieve")
async def retrieve_knowledge(request: QueryRequest):
results = db.query(
request.question,
n_results=request.n_results,
intent=request.intent,
tool_name=request.tool_name
)
return {"results": response}
@app.post("/memory/add")
async def add_memory(request: MemoryAddRequest):
memory_db.add_messages(request.user_id, payload, request.session_id)
return {"status": "ok"}
@app.post("/memory/query")
async def query_memory(request: MemoryQueryRequest):
results = memory_db.query(
request.question,
user_id=request.user_id,
n_results=request.n_results,
session_id=request.session_id
)
return {"results": response}这样拆分有两个实际好处:
第一,Java 侧职责更清晰
Java 后端负责:
- 接收用户请求
- 组织 Agent 调用
- 管控安全与会话
- 做 SSE 流式输出
Python 引擎负责:
- 检索
- 向量重排
- 记忆召回
- 意图识别
- 增量知识同步
这比把所有东西都堆进一个 Controller 里舒服太多。
第二,检索策略可以单独演进
后面你要升级 embedding、换重排逻辑、补分集合召回,甚至接更复杂的检索实验,都可以主要在 Python 层做,不会把整个业务后端搅乱。
3. 真正让我觉得"有点意思"的,是这层意图路由
很多所谓项目 RAG,用户不管问什么,系统都只会做一件事:检索。
但 SwiftBoot 这里我单独做了 intent_routing.json,用"语义 + 规则"混合方式先判定问题类型,当前主要有 4 类:
CODEDOCMEMORYCHAT
配置里能看到很明确的分流规则:
json
{
"settings": {
"similarity_threshold": 0.70,
"fallback_to_rules": true,
"default_intent": "CHAT"
},
"intents": [
{ "id": "CODE" },
{ "id": "DOC" },
{ "id": "MEMORY" },
{ "id": "CHAT" }
]
}它背后的思路其实很朴素:
- 能判断成闲聊,就别浪费检索资源
- 能判断成历史追问,就优先走长期记忆
- 能判断成文档型问题,就别用代码片段污染上下文
- 真正需要查实现时,再去调源码工具
这一步做完之后,整个问答体验的"稳定感"会明显提升。
因为系统终于不再是"见问题就搜",而是开始像个值班工程师一样先判断:你现在到底是在问原理、问实现、问历史,还是随口聊一句。
4. 向量库不是只存一份文本,而是至少分成 code / doc / memory 三层
这次我在 ChromaDB 里没有偷懒地把所有东西都塞到一个集合里,而是拆成了:
code:源码相关切片doc:文档相关切片memory:历史对话长期记忆
对应初始化逻辑在 vector_store.py 里能看到:
python
self.collection = self.client.get_or_create_collection(name=COLLECTION_NAME)
self.doc_collection = self.client.get_or_create_collection(name=DOC_COLLECTION_NAME)后面在检索阶段,又会根据 intent 和 tool_name 做一次偏置重排:
python
prefer_code = tool_name == "fetch_source_impl" or intent in ["CODE", "DEBUG"]
prefer_doc = tool_name == "fetch_business_doc" or intent == "DOC"
if prefer_code and item["origin"] == "code":
origin_bonus += 0.18
if prefer_doc and item["origin"] == "doc":
origin_bonus += 0.18这块别小看。
很多项目问答系统做不准,问题不在召回,而在召回后没有做偏置重排。
也就是说,系统虽然查到了相关内容,但不知道当前上下文里谁该排前面。
而我这里的做法就是:
- 你走源码工具,我就给代码片段更高权重
- 你走文档工具,我就给 markdown 和 schema 更高权重
- 最后再统一返回 Top-N
这种"轻量但明确"的工程策略,往往比单纯堆模型更有性价比。
5. 代码一改,知识库就得跟着动,不然 AI 很快就开始胡说
我觉得项目 AI 最容易被忽略的一点,是知识库新鲜度。
你今天刚改完一个接口,结果 AI 还在按昨天的代码回答,这种体验其实比"完全不会"还糟糕,因为它会给你一种"它好像懂"的错觉。
所以我在 ai-engine/file_watcher.py 里接了 Watchdog,直接监听项目目录变化。
可监听的目录包括:
swiftboot-backendswiftboot-uidevDocproject-skillsai-enginerelease_notes
文件变动后的处理链路是:
- 识别文件类型
- 先删旧切片
- 重新解析
- 再写入向量库
关键逻辑大致是这样:
python
def _process_event(self, event):
source_id = filename.replace("\\", "/")
self.db.delete_by_source(source_id)
if filename.endswith(".java"):
chunks = self.java_parser.parse_file(filename)
elif filename.endswith(".py"):
chunks = self.py_parser.parse_file(filename)
elif filename.endswith(".vue"):
chunks = self.vue_parser.parse_file(filename)
if chunks:
self.db.add_documents(chunks)这意味着在 SwiftBoot 里,知识库不是"定期离线构建"的,而是跟着开发动作一起增量更新的。
这一步对体验的改善很直接:
- 刚改完 Controller,就能马上追问实现
- 刚补完文档,文档型问答就能命中新内容
- 刚新增技能知识,后端下次加载就能把它纳入项目背景
6. 这套链路不只是"能查到",还尽量做到"能解释为什么这么答"
我自己其实不太喜欢那种完全黑盒式的 AI。
它给你一个答案,看起来很像那么回事,但你不知道它到底是:
- 真查到了代码
- 碰巧猜对了
- 还是在一本正经地胡说
所以我在工具执行这层,特意把"引用文件名"和"检索耗时"这些信息保留下来。
在 executeAgentTool 里,除了调 /retrieve,还会:
- 按工具类型二次过滤结果
- 记录工具调用耗时
- 提取引用文件名
- 把查阅过的文件反馈给前端
对应代码片段:
java
ragRequest.set("question", query);
ragRequest.set("n_results", 10);
ragRequest.set("intent", detectedIntent);
ragRequest.set("tool_name", functionName);
String ragResponse = HttpRequest.post(RAG_API_URL)
.timeout(60000)
.body(ragRequest.toString())
.execute()
.body();
AiTraceContext.addToolCall(functionName, args, "RAG_SEARCH_RESULT", ragDuration);最近版本里,我还把这一层继续往前推了一步,把工具调用和检索上下文纳入了 AI Trace 追踪链路。
这件事的意义不是"让界面更酷",而是让系统更可调试。
因为你终于可以看清楚:
- 这次为什么走了源码检索
- 命中了哪些文件
- 工具调用花了多长时间
- 最终回答是不是建立在正确上下文上
从工程角度看,这比"答对一次"更重要。
7. 别忽略长期记忆,它决定了系统像不像"在持续协作"
除了知识检索,我这里还补了一层对话记忆。
SysAiController 会在合适的时候尝试调用 /memory/query,把和当前问题相近的历史内容召回回来。对用户来说,最直观的感受是:
- 你不用每次都重新解释同一个模块背景
- 上一轮刚聊过的设计结论,下一轮还能接着说
- 系统会更像"持续协作",而不是"每问一次都重新开机"
这部分不是为了炫技,而是因为真实开发就是连续的。
只做代码检索,不做上下文连续性,AI 很容易变成一个"每次都像第一次见你"的同事。
8. 这套架构最适合什么场景
如果你的项目符合下面这些特征,这种 Agent-RAG 方案会特别合适:
- 后端、前端、AI 引擎混合技术栈
- 代码和文档都很多
- 业务问题和源码问题混在一起
- 项目迭代快,知识库必须跟着更新
- 你希望 AI 不只是生成代码,还能解释项目
反过来说,如果只是一个十几个文件的小 Demo,其实没必要把链路做这么完整。
但只要进入"真实项目协作"阶段,你就会发现:越是复杂的项目,越不能用单一检索思路硬顶。
最后说下我这次踩出来的一个判断
做项目级 AI,真正难的不是"把大模型接进来",而是把下面这几件事同时做好:
- 让系统知道什么时候该查源码,什么时候该查文档
- 让知识库能跟着代码实时更新
- 让历史对话能被合理召回
- 让结果尽可能可追踪、可解释
- 让整条链路不打断用户的交互体验
说白了,Agent-RAG 的重点不是 Agent,也不是 RAG,而是工程编排。
我这次在 SwiftBoot 里做的,就是把这套编排真正落到了项目里,而不是停在一个概念 Demo。
效果图
首页展示
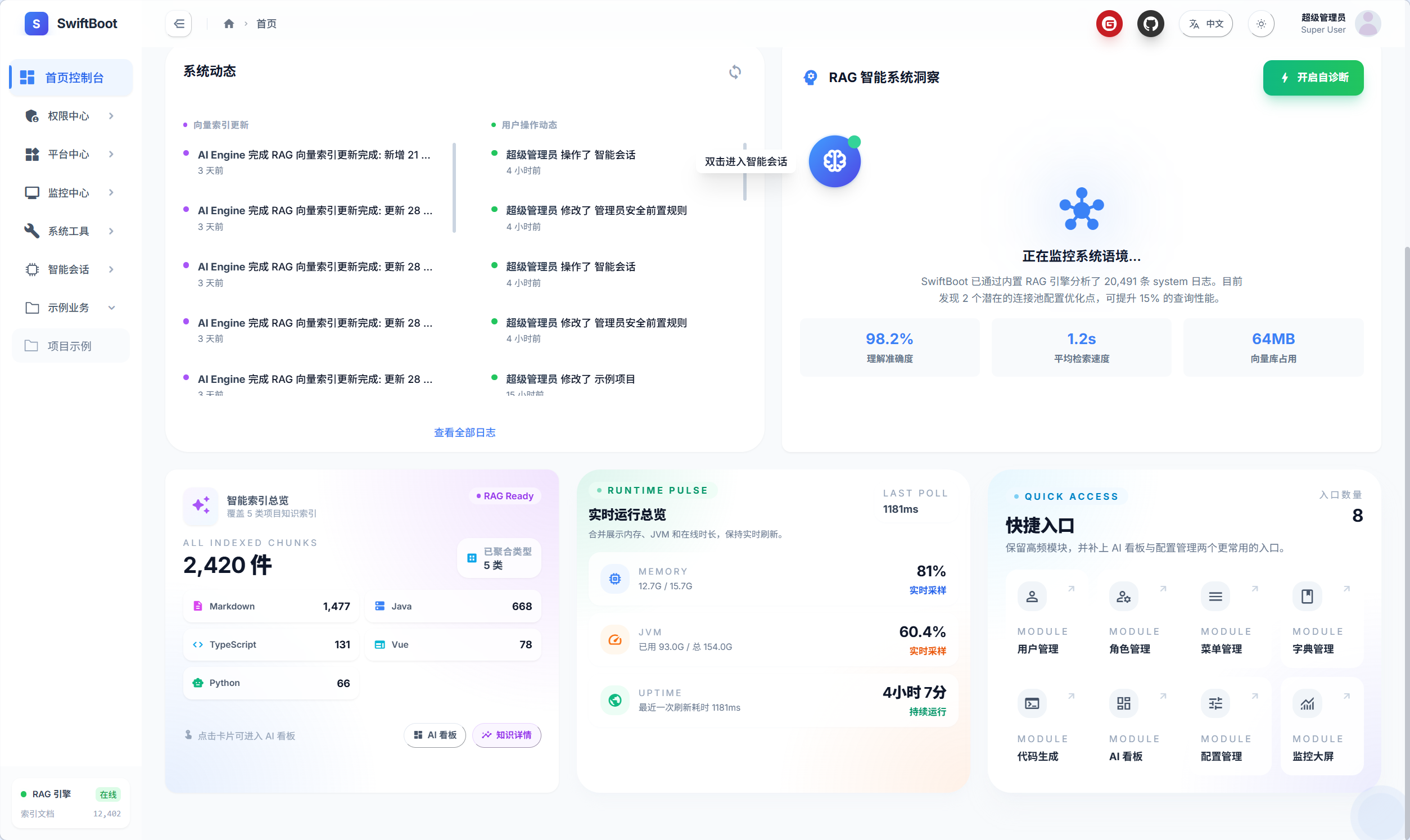
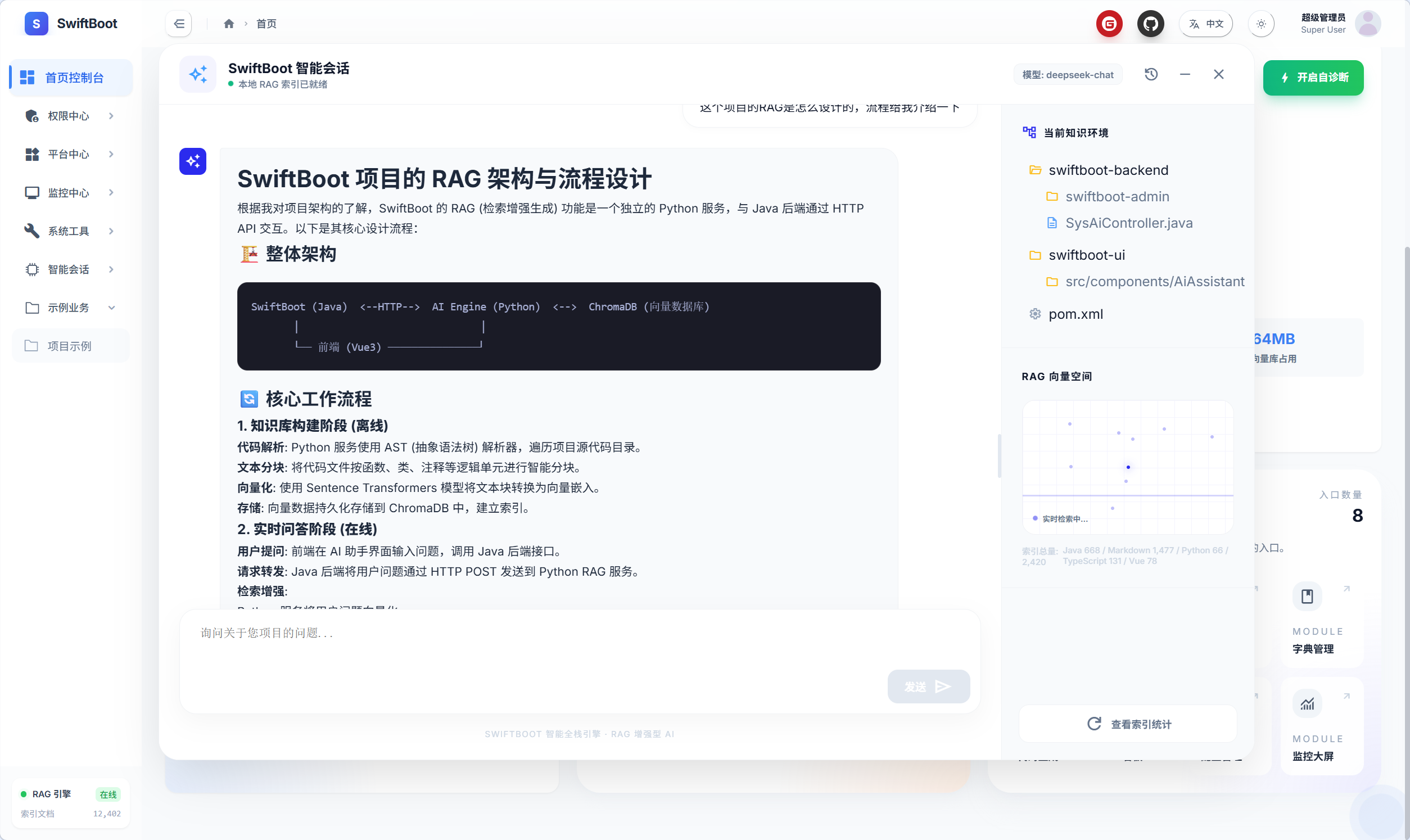
智能会话窗口
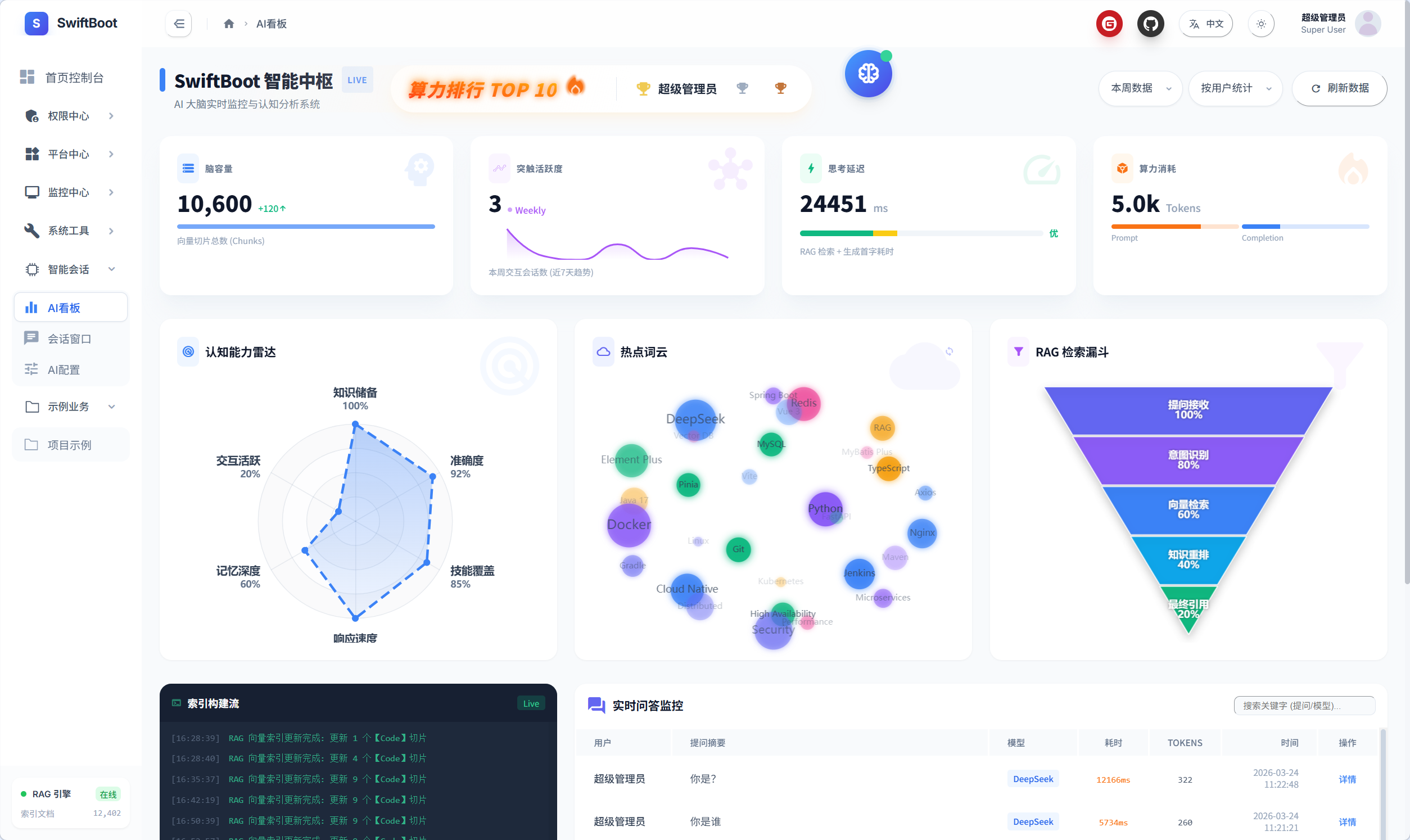
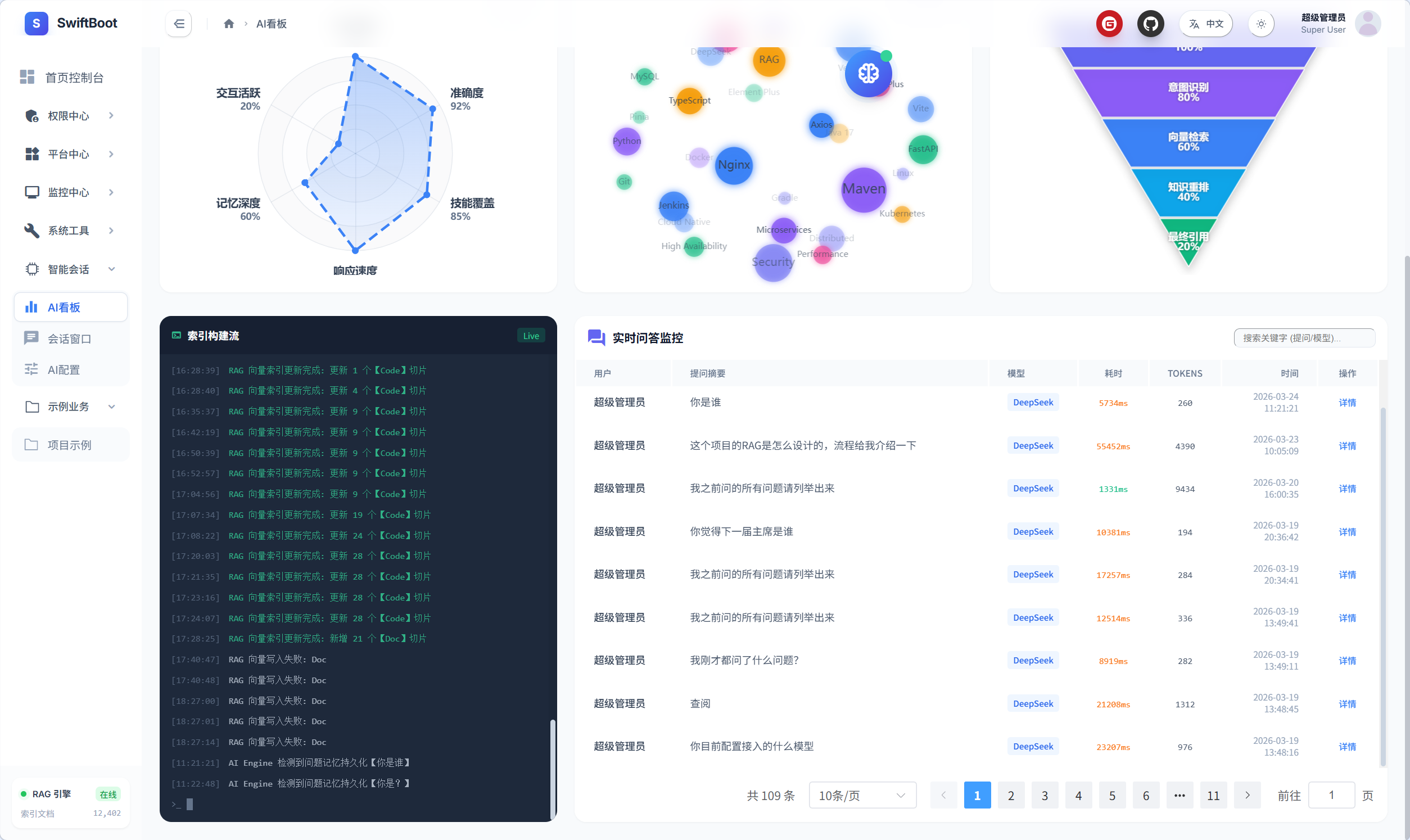
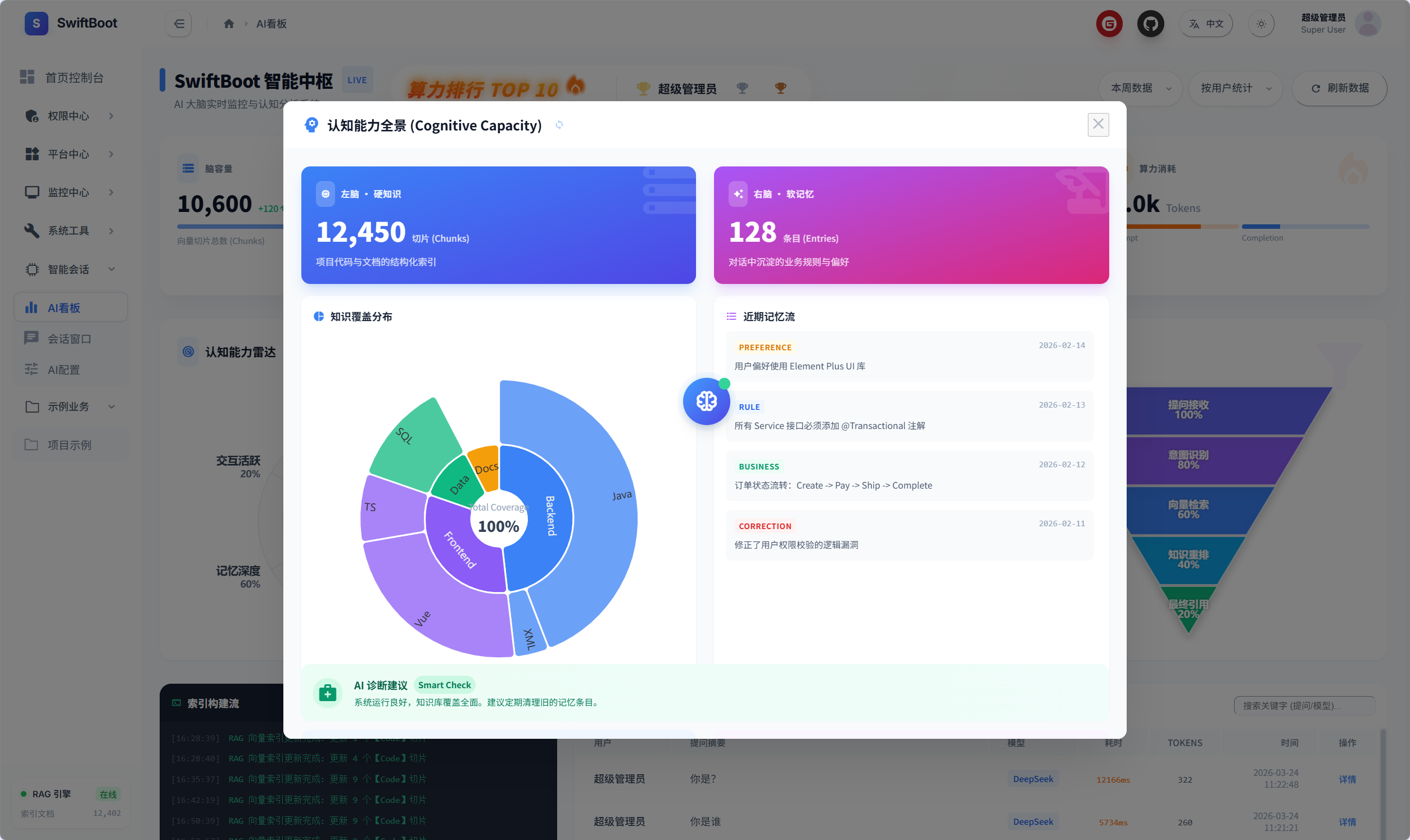
AI看板
本地知识库chunk来源
算力消耗排行榜 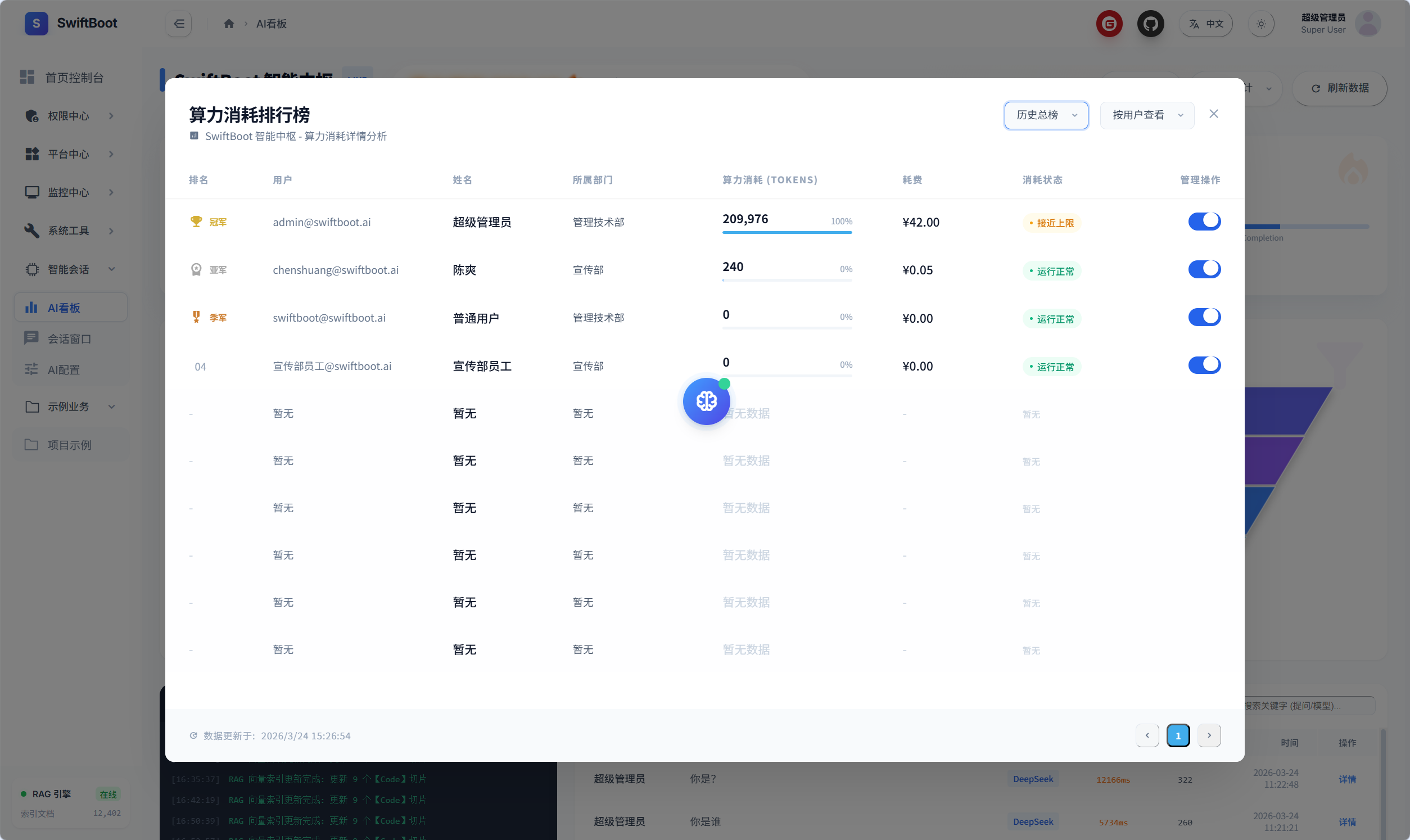
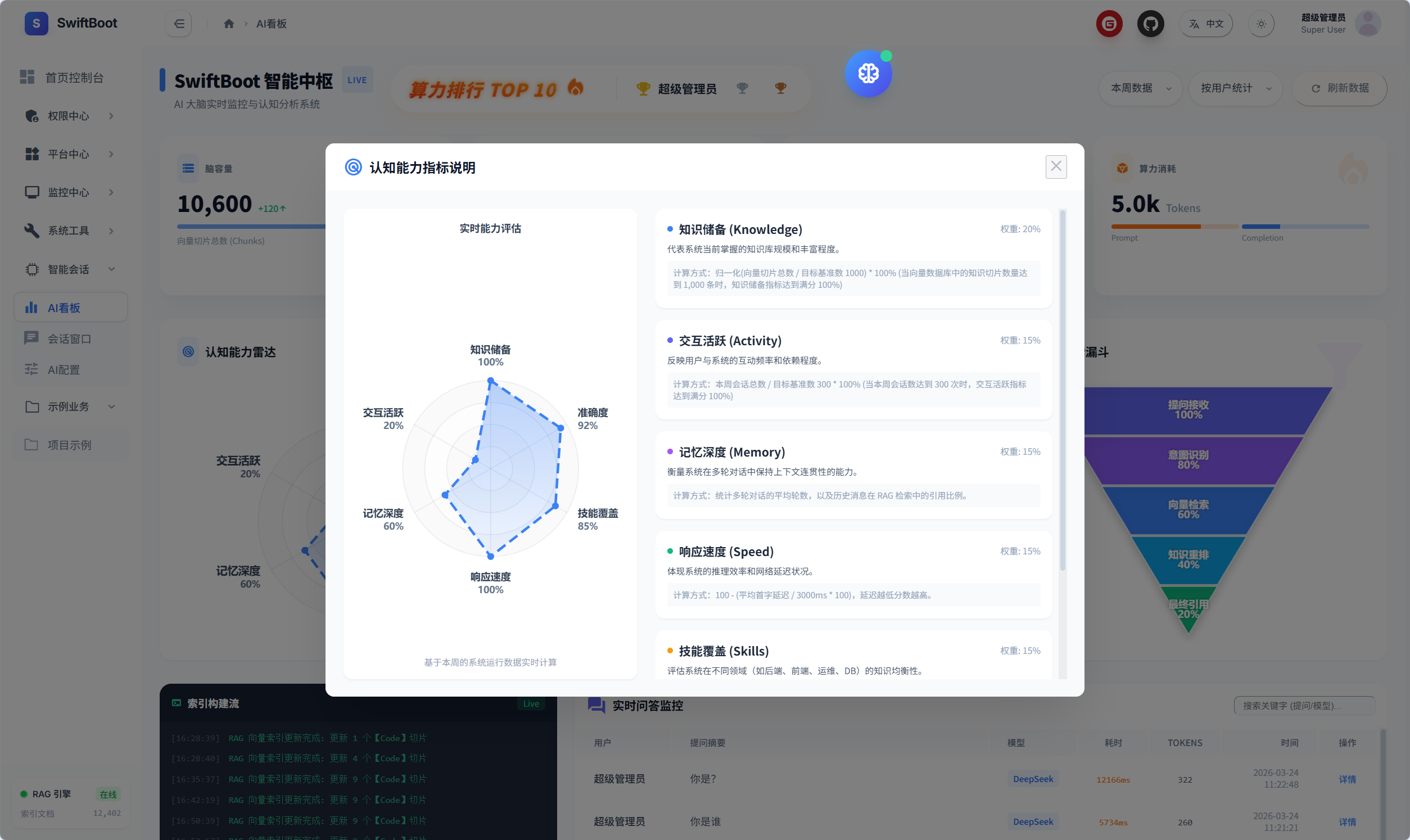
模型能力指标
算力消耗分析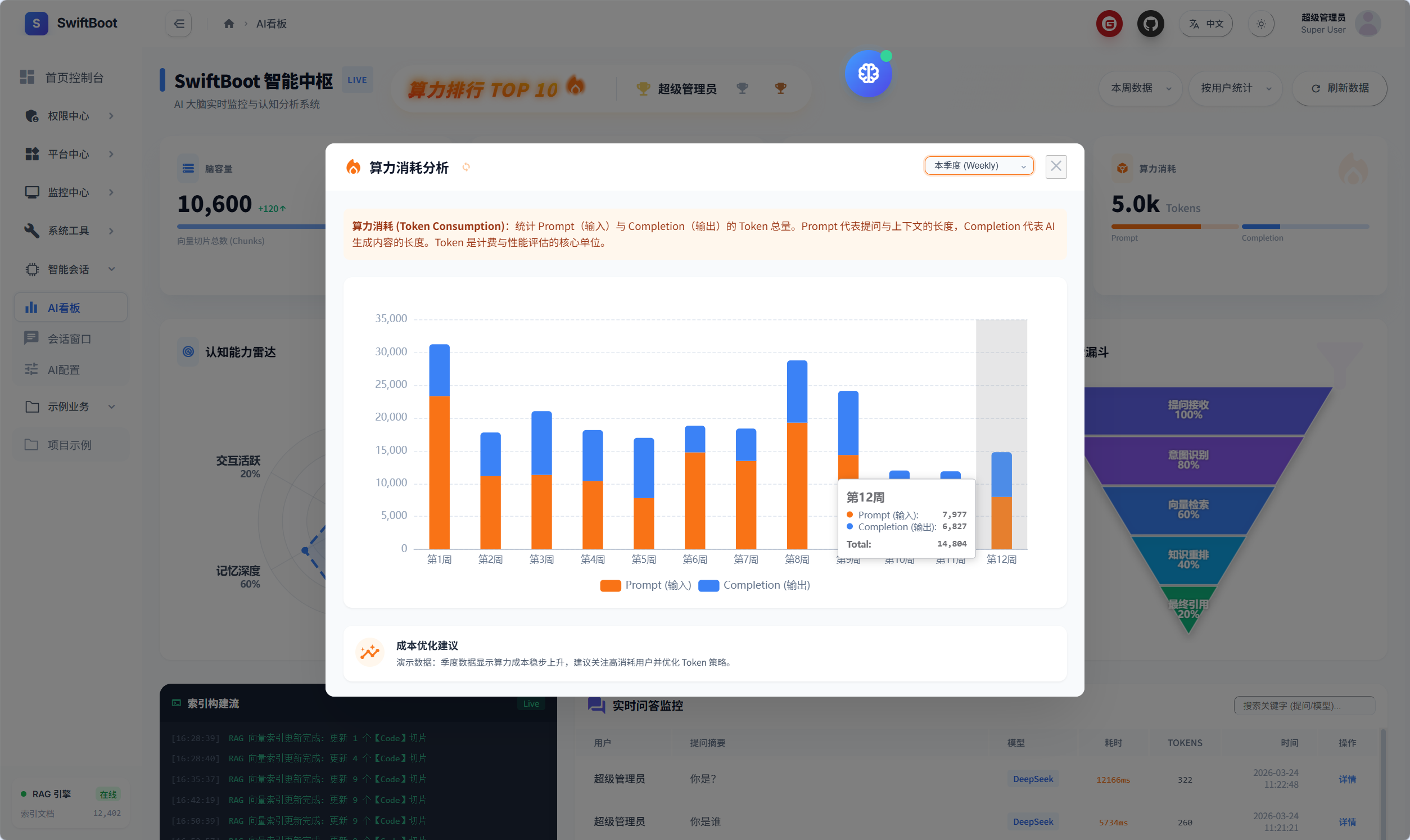
源码与项目地址
这套 Agent-RAG 的完整思路和工程实现,我已经放进 SwiftBoot 里了。它不是单独的实验仓库,而是直接融进了一个可以持续演进的 Spring Boot 3 + Vue 3 全栈项目。
如果你也在做这些方向,可以直接拉代码看实现,或者拿里面的链路去改成你自己的版本:
- Gitee: https://gitee.com/cs_shuang/SwiftBoot
- GitHub: https://github.com/328pikapika-bot/SwiftBoot
- 联系方式:
17334981104(同微)
如果你后面想把这篇文章再升级成"更适合发布"的版本,我建议再补 2~3 张图:
- AI 助手对话界面
- 索引构建流或 AI Trace 界面
- 配置页/规则治理页
但如果你只是先发 CSDN,这一版带 Mermaid 流程图已经够用了。
如果你也在做项目级 AI,欢迎来交流。
我自己越来越确定一件事:相比"再换一个更强的模型",很多时候先把检索链路和工程结构搭对,收益反而更大。
#Java #SpringBoot #FastAPI #ChromaDB #RAG #Agent #AI #开源项目