论文: SpaceMind: A Modular and Self-Evolving Embodied Vision-Language Agent Framework for Autonomous On-orbit Servicing
作者: Aodi Wu, Haodong Han, Xubo Luo, Ruisuo Wang, Shan He, Xue Wan
单位: 中国科学院大学 · 中科院空间应用工程与技术中心
发表时间: 2026年4月15日

摘要翻译
自主在轨服务(Autonomous On-orbit Servicing)要求具身智能体能够通过视觉传感器感知环境、推理三维空间态势,并在长时间跨度内执行多阶段任务。本文提出 SpaceMind ,一个模块化且自进化的视觉-语言模型(VLM)智能体框架,将知识、工具和推理分解为三个独立可扩展的维度:带动态路由的技能模块 、带可配置配置文件的MCP工具 ,以及可注入的推理模式技能 。一个 MCP-Redis 接口层使得同一套代码库无需修改即可在仿真和物理硬件上运行;技能自进化机制(Skill Self-Evolution)将操作经验蒸馏为持久化的技能文件,无需模型微调。
通过 192次闭环实验 验证 SpaceMind,覆盖5颗卫星、3种任务类型和2种环境(UE5仿真和物理实验室),并刻意引入退化条件(曝光不足、位置偏移)以进行压力测试。在标称条件下,所有模式均实现90--100%导航成功率;在退化条件下,Prospective 模式 是唯一能在搜索-接近任务中取得成功的模式。自进化研究表明,智能体在6组实验中的4组能从单次失败片段中恢复,包括从完全失败恢复到100%成功 ,以及检查分数从12分提升至59分(满分100) 。真实世界验证确认,零代码修改即可将同一智能体迁移到物理机器人,实现100%交会成功率。
一、前言:当大模型望向星辰大海
截至2023年,地球低轨道的编目太空碎片和老化卫星已超过 20,000个。NASA的OSAM-2、ESA的ClearSpace-1、RemoveDEBRIS等任务已经展示了主动碎片清除和卫星延寿的早期概念。然而,当前的在轨服务操作仍然依赖为已知合作目标预先编程的序列,这严重限制了它们应对真实在轨遭遇中多样且不可预测条件的能力。
近年来,研究者开始探索将视觉-语言模型(VLM)作为航天器操作智能体,表明大型基础模型可以通过自然语言推理分解复杂的太空任务。但这些努力仍处于演示阶段:它们在简化的游戏环境中通过读取屏幕文本来操作,而非处理真实的视觉传感器数据;它们只处理单一任务,使用单一的提示词,缺乏跨目标或跨环境的系统性评估。
更广泛的AI智能体研究 landscape 被数字世界应用(如网页导航、代码生成、对话系统)或简单的物理场景(如桌面操作、室内导航)所主导。而自主在轨服务则要求具身智能体:
-
通过真实传感器感知
-
在物理三维环境中执行6自由度(6-DoF)运动控制
-
维持跨越数十个决策步骤的多阶段任务,从远程搜索到近距离接近,再到精细诊断(如图1所示)
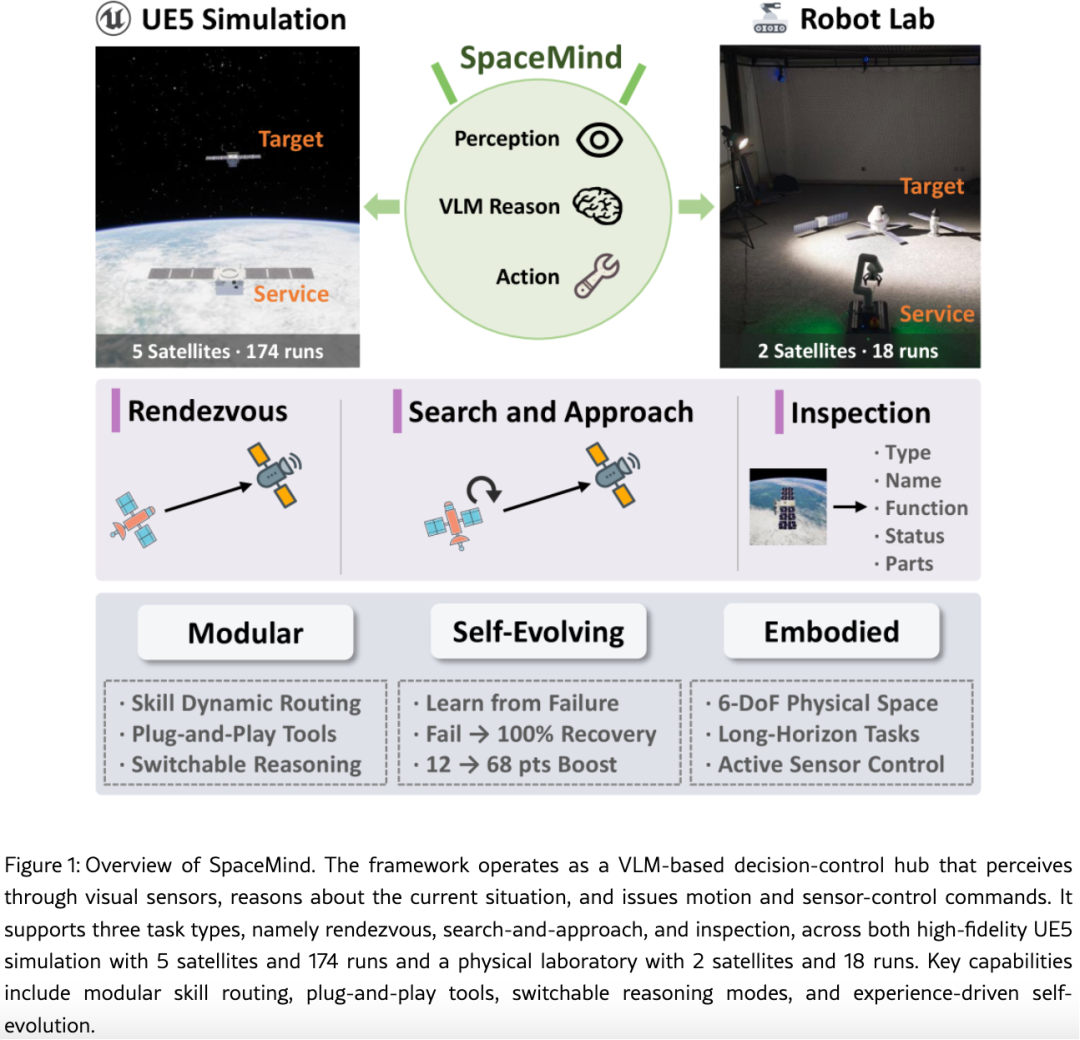
如何为这一领域构建可扩展、可适应、由传感器驱动的智能体框架,仍然是一个开放问题。
构建这样的框架面临四个相互关联的挑战:
挑战一:缺乏面向太空操作的模块化智能体架构。 现有的太空智能体原型将所有任务知识编码在单一的提示词中,随着任务数量增加变得不可维护;仿真和真实硬件通常需要独立的代码库,缺乏连接它们的接口抽象。
挑战二:太空智能体缺乏灵活的推理深度和跨步骤记忆。 不同任务复杂度需要不同的决策深度------简单的交会可能只需要直接动作选择,而搜索-接近任务则受益于深思熟虑的多候选评估。现有方法没有切换推理策略的机制。此外,智能体需要跨决策步骤的持久记忆来从目标丢失中恢复并动态调整策略。
挑战三:太空智能体无法从经验中改进。 当前设计是一次性执行器,每次片段都从零开始,放弃了先前运行中获得的运营知识。太空操作本质上是重复执行场景------相同的任务类型在不同目标和条件下反复出现;能够积累经验的智能体可以显著提高长期可靠性。传统的适应方法对于在轨部署不切实际:微调需要标注数据和梯度更新,强化学习需要显式的奖励函数设计,上下文学习受限于上下文窗口且不会跨会话持久化。
挑战四:太空智能体架构背后的设计决策缺乏系统性实证验证。 先前研究在少量运行中报告单一任务的结果,没有证据表明模块化架构是否可扩展、应选择哪种推理模式、自进化是否有效,或同一架构是否能跨环境迁移。
二、SpaceMind 架构:四层递进式设计
SpaceMind 使用 VLM 作为决策控制中枢,通过视觉传感器感知环境,推理当前态势,调用专用工具,并发出运动指令。其设计包含四个递进层次:
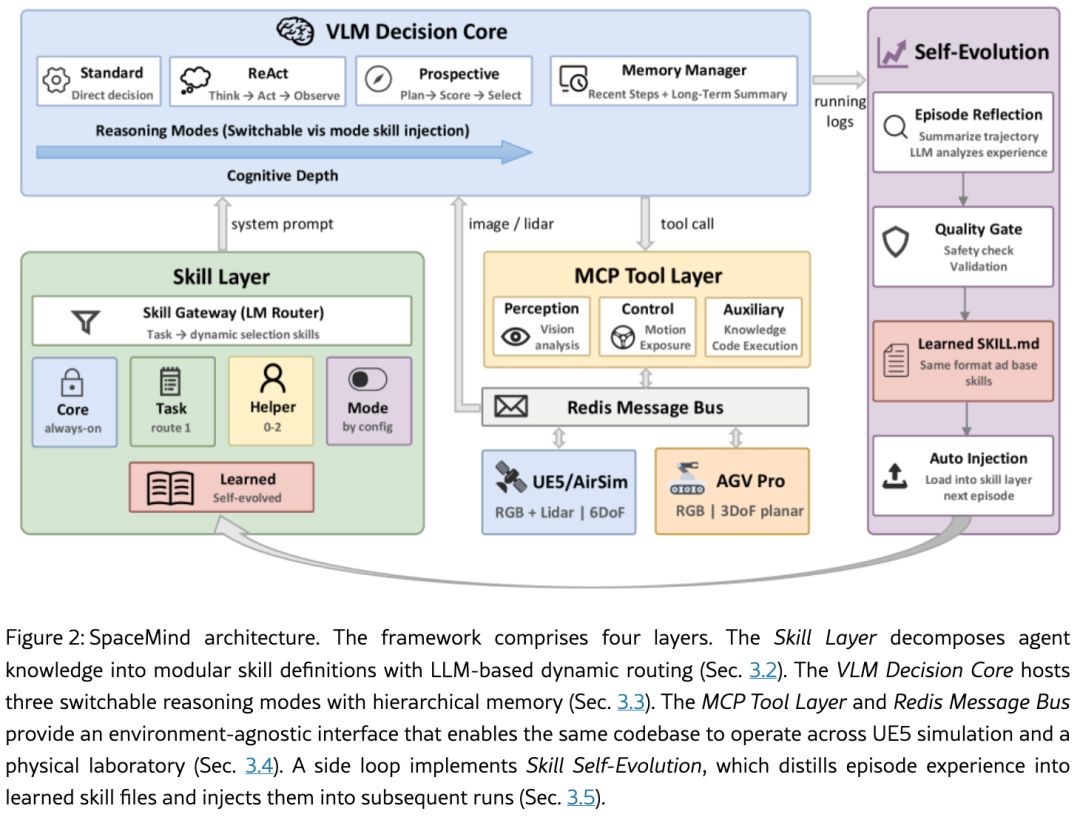
2.1 系统概览与核心公式

2.2 技能层与动态路由(Skill Layer & Dynamic Routing)
现有 VLM 太空智能体方法将所有任务知识编码在单一的系统提示词中,这带来了三个问题:提示词随着任务增加变得不可管理;共享策略(如距离相关的步长衰减、目标丢失恢复)无法跨任务复用;操作中积累的经验没有结构化的存储容器。
SpaceMind 将智能体知识分解为独立的技能模块,并根据任务动态路由。每个技能是一个自包含的知识单元,由结构化头部和自然语言主体组成:
-
头部:声明技能名称、类别、描述适用性的路由摘要、以及用于目录匹配的路由关键词
-
主体:包含将逐字注入VLM系统提示词的操作指令
技能按三层分类法组织:
-
核心技能(Core):始终激活,提供跨所有任务共享的基础运营知识,包括坐标约定、安全约束和一般动作策略
-
任务技能(Task):编码特定任务类型的主要策略(如交会、搜索-接近、检查)。每个片段恰好选择一个任务技能
-
辅助技能(Helper):提供补充主要任务技能的辅助策略,如距离相关的步长衰减、目标丢失恢复程序或多模态感知工作流。每个片段选择0-2个辅助技能
**技能网关(Skill Gateway)**在每个片段开始时执行动态路由。网关接收当前任务描述、活跃工具配置文件和推理模式作为输入,对可用任务和辅助技能目录发出轻量级LLM调用。LLM选择一个主要任务技能和最多两个互补的辅助技能,以及其自然语言选择理由。如果路由调用失败(如输出格式错误),网关回退到框架配置中声明的默认技能组合,确保鲁棒性。
此外,**模式技能(Mode Skills)**提供推理模式特定的指令,基于活跃推理模式注入,并与任务技能完全解耦,因此任何任务和推理模式的组合都可以无干扰地组合。自进化机制生成的技能与手工编写的技能共享相同格式,通过相同的路由管道无缝注入。
最终的系统提示词通过串联活跃核心技能、路由的任务和辅助技能、模式特定技能以及任何适用的学习技能来组装。所有技能分配、工具配置文件、推理模式和网关参数都通过单一的声明式配置文件 管理,实现了四维解耦:任何任务、推理模式、工具集和技能组合的组合都可以在不修改代码的情况下指定。
2.3 推理模式与记忆(Reasoning Modes & Memory)
不同的运营场景需要不同的认知深度。SpaceMind 在同一架构中托管三种推理模式,形成可按任务选择的认知深度梯度:
Standard 模式:VLM接收当前观察、组装的系统提示词和可用工具列表,直接产生单个工具调用作为其动作。如果选择的工具是感知操作(如图像分析或分割),其结果可以触发同一决策步骤内的后续VLM调用来选择运动动作。此模式计算开销最低,适用于可以从当前观察确定正确动作的任务。
ReAct 模式:遵循 ReAct 范式,每个决策步骤允许最多三轮内部的 Thought--Action--Observation 循环。智能体首先生成显式的推理轨迹,然后选择并执行工具,观察结果后再决定是否继续推理或提交运动动作。当调用运动或终止工具时,内部循环终止。此模式通过注入模式技能激活,适用于需要在提交动作前收集信息的任务。
Prospective 模式:受 Tree of Thoughts 等深思熟虑搜索策略启发,智能体在高不确定性场景中采用两阶段审议过程:
-
规划阶段:VLM生成三个候选动作,每个伴随预测结果和风险评估
-
选择阶段:第二次VLM调用评估候选并选择预测结果最有利的动作
此模式通过注入两个互补的模式技能(一个用于规划,一个用于选择)激活,提供最高的认知深度,使智能体能够在提交前推理动作后果。如果规划阶段产生格式错误的输出,系统优雅地降级为直接选择。
所有三种模式都仅通过模式技能注入激活,并与任务特定技能完全解耦。切换模式只需要配置更改,无需修改智能体的决策循环或任务逻辑。
分层记忆系统:为支持跨步骤推理,SpaceMind 维护两层记忆:
-
近期记忆:保留最近N个步骤的详细记录,包括智能体的分析、工具选择、参数和结果
-
长期记忆:将较早的步骤压缩为捕捉累积轨迹信息的自然语言摘要
两层串联并注入为每次VLM调用的上下文输入,使智能体能够检测并从目标丢失中恢复、避免重复失败策略、并跟踪跨扩展片段的任务完成进度。
2.4 接口与通信架构(Interface & Communication)
SpaceMind 的一个关键设计目标是同一智能体代码库在不同物理环境中无需修改即可运行。这要求将智能体的决策逻辑与任何特定传感器或执行器后端的具体细节解耦。
MCP 工具协议 :所有可执行能力都通过 Model Context Protocol (MCP) 作为工具暴露给智能体,这是连接语言模型与外部函数的标准化接口。智能体通过统一的调用约定按名称和参数调用工具,无需知道每个工具的实现方式。工具分为四类:
-
感知工具:分析当前视觉输入,包括亮度评估、部件级分割、区域裁剪和缩放
-
控制工具:发出运动和传感器命令,如平移和旋转运动、相机曝光调整、任务终止
-
知识工具:提供描述航天器特征的领域知识库访问
-
辅助工具:支持可选能力,如用于数值计算的代码执行
工具配置文件机制控制每个实验中智能体可见的工具。每个配置文件指定允许工具白名单;运行时,只有同时出现在MCP服务器完整目录和活跃配置文件白名单中的工具才会呈现给VLM。这实现了受控的消融研究(如移除距离感知以测试纯视觉操作)和特定环境的工具集(如物理实验室的最小配置文件),全部通过配置完成。
两个设计决策值得讨论:
-
平移和旋转运动作为独立的工具暴露,而非单一的6-DoF命令,防止VLM产生耦合的平移-旋转动作导致意外的螺旋轨迹------这是早期开发中观察到的失败模式
-
相机曝光调整作为显式工具暴露,使智能体在检测到低曝光或过曝光时能够主动改善自身感知质量,而非被动接受退化的输入
Redis 消息总线:在MCP工具实现和物理环境之间,Redis 发布-订阅消息总线提供第二层抽象。统一命名约定定义通信通道:传感器数据通过指定键(如最新RGB图像、最新LiDAR摘要)和图像到达通知向上游流动,控制命令通过相应命令主题(如姿态变化增量、曝光调整)向下游流动。
在UE5仿真中,AirSim桥接进程将传感器数据写入Redis并消费运动命令。在物理实验室中,ROS2传感器桥接将相机帧发布到相同的Redis键,单独的运动执行器订阅相同的命令主题来驱动移动机器人。两个后端填充和消费相同的Redis通道;智能体的决策循环不包含任何环境条件代码。
这种两层抽象产生了一个具体的可移植性保证:相同的智能体决策循环、MCP工具服务器和通信契约在两个环境中零代码修改即可运行。将SpaceMind扩展到新的环境后端只需要为该后端的传感器和执行器实现Redis读写端点。
2.5 技能自进化机制(Skill Self-Evolution)
太空在轨服务本质上是重复执行领域:相同的任务类型在不同目标和条件下反复出现。每次片段后丢弃所有运营经验的智能体放弃了从自己的成功和失败中改进的机会。
传统适应方法在此设置中都有显著局限:
-
微调:需要标注训练数据和梯度计算,两者在轨道上都不切实际
-
标准上下文学习:受限于上下文窗口,不会跨会话持久化
-
检索增强生成(RAG):只能检索现有文档,无法从经验中合成新的运营知识
-
强化学习:需要显式奖励函数设计,在物理环境中样本效率低下
SpaceMind 引入 Skill Self-Evolution 机制,使智能体能够在不修改模型权重的情况下,自主生成、验证和积累跨片段的运营知识。
该机制作为标准决策循环的外循环运行(见图2右侧)。每个片段结束后,执行以下管道:
片段摘要:系统记录完整的工具调用轨迹、成功或失败结果、终止原因,以及智能体运动和感知历史的结构化摘要。
经验反思 :将片段摘要与近期先前片段的摘要以及当前活跃的技能定义一起提供给VLM进行专门的反思调用。VLM分析什么有效、什么失败以及原因,并产生结构化的变异决策,指定五种操作之一:
-
创建:创建新的学习技能,捕捉先前未知的运营模式
-
覆盖:用精炼或补充规则覆盖现有技能
-
重写:当证据支持根本性修订时重写现有技能
-
禁用:禁用被发现有害的学习技能
-
无变化:当前经验不支持修改
质量门:每个提议的变异在应用前通过多阶段验证门。门强制执行四个约束:
-
安全短语黑名单:拒绝包含可能覆盖安全规则指令的变异
-
指纹去重检查:防止语义冗余的技能积累
-
任务范围绑定:确保在一个任务上下文中学习的技能不会污染另一个任务的知识库
-
父技能验证:确认覆盖和重写操作的目标技能实际存在
未通过任何约束的变异被丢弃,审计日志记录拒绝原因。
学习技能生成:通过质量门的变异被物化为新技能文件,与手工编写的技能共享相同格式,确保与现有技能路由基础设施的兼容性。每个学习技能包含五个结构化部分:
-
Intent:技能旨在实现什么
-
Trigger:技能应激活的条件
-
Rule:编码操作指令
-
Constraints:划定安全边界
-
Evidence:记录激励技能的片段观察
附加元数据记录技能的来源、版本、原始片段和适用任务范围。
自动注入:在每个后续片段开始时,技能运行时加载所有学习技能与基础技能集一起。检索函数基于其声明的范围和触发条件将学习技能匹配到当前任务和推理模式,选择最相关的top-k学习技能注入系统提示词,与动态路由的基础技能一起。
这一设计有四个区别于先前自改进方法的属性:
-
自然兼容:学习技能与模块化技能架构天然兼容------使用相同数据格式,通过相同路由管道,与基础技能组合无需特殊处理
-
持久且可审计:每个变异都记录完整来源,技能文件可以被人类操作员检查、编辑或回退
-
渐进式进化:技能通过版本化覆盖逐步积累,而非整体替换,允许渐进精炼
-
安全保证:即使VLM的反思产生不安全或冗余的建议,硬约束也能阻止其进入活跃技能集
三、实验验证:192次闭环运行的系统性评估
SpaceMind 通过 192次闭环运行 的四个实验活动进行评估,在UE5高保真仿真和物理实验室环境中进行。
3.1 实验设置
仿真环境:基于UE5和AirSim插件构建,扩展SpaceSense-Bench平台提供高保真光学渲染和多传感器仿真。场景中放置五颗不同几何形状和规模的卫星模型:CAPSTONE、IBEX、BioSentinel、New Horizons 和 Huygens。智能体通过RGB相机和LiDAR距离传感器感知环境,通过MCP工具调用控制6-DoF位置和姿态,经由Redis消息总线中继。
实验室环境:物理测试台由myAGV Pro全向移动机器人(Mecanum轮,40kg负载)组成,配备Orbbec Gemini 2立体RGB相机(1920×1080分辨率)。机器人运行ROS2 Humble,通过Redis桥接与相同的智能体决策循环通信。两颗1米直径的3D打印卫星模型(CAPSTONE和Artemis)作为目标。运动约束为3-DoF平面运动。
任务类型:定义了三种难度递增的任务类型:
-
Rendezvous (Rndz.):目标可见;接近到约2米
-
Search-and-Approach (Search):目标不可见;先找到然后接近到约2米
-
Inspection (Insp.):近距离五维结构化记录

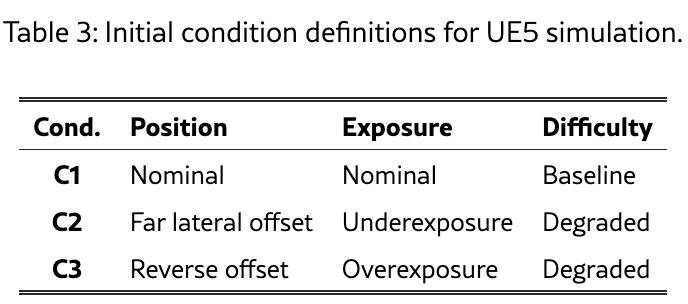
初始条件定义(见表3):
| 条件 | 位置 | 曝光 | 难度 |
|---|---|---|---|
| C1(标称条件) | 标准位置 | 标准曝光 | 基线 |
| C2(退化条件) | 远侧向偏移 | 曝光不足 | 退化 |
| C3(退化条件) | 反向偏移 | 曝光过度 | 退化 |
所有三种任务(Rendezvous、Search-and-Approach、Inspection)均在每种初始条件下测试,形成完整的3×3×3实验矩阵。
VLM模型:所有实验均使用开源的 Qwen3-VL-235B-A22B 模型 作为 VLM 决策核心,温度 ≤0.3 以促进所有活动的输出稳定性。
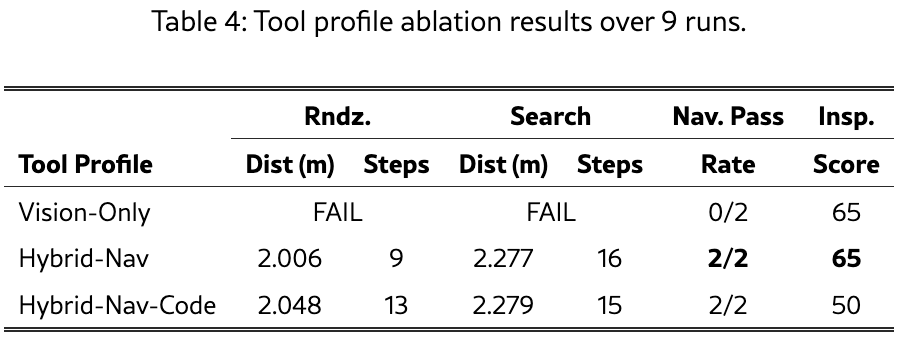
3.2 工具消融实验
9次运行的工具消融研究表明,移除LiDAR距离感知会导致导航失败,验证了模块化工具配置机制的有效性。
3.3 多卫星推理模式评估(Multi-Satellite Reasoning Mode Evaluation)
推理评估活动提供了跨越 5颗卫星 、3种任务 、3种推理模式 (Standard、ReAct、Prospective)和 3种初始条件 的系统比较,总计 135次运行。
3.3.2 结果总览
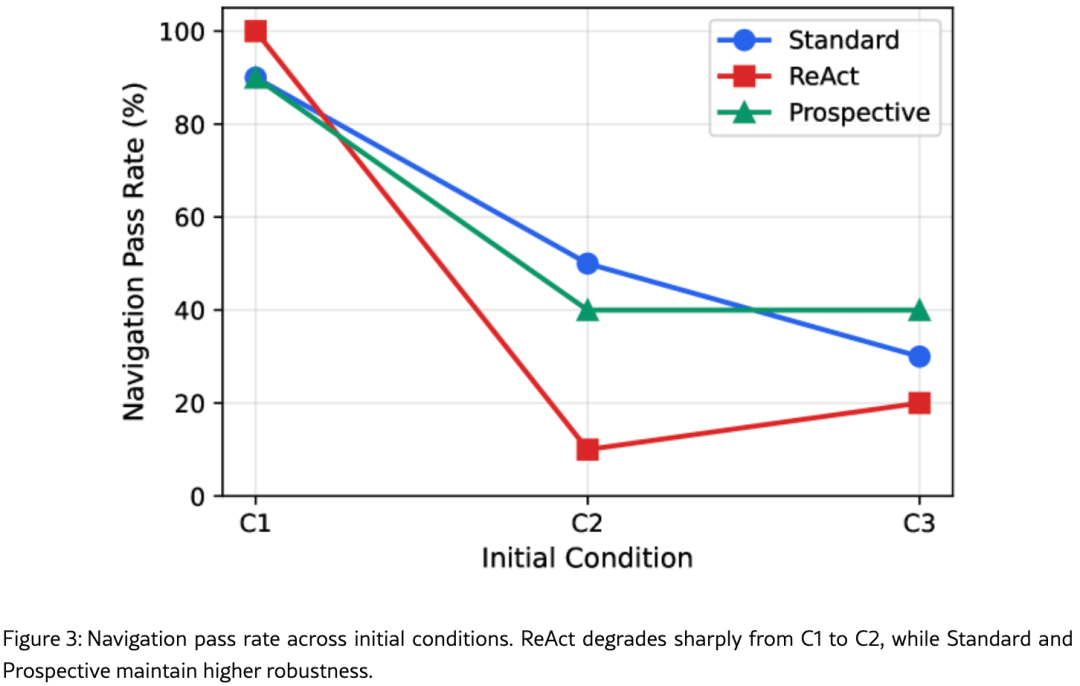
表5汇总了所有模式和条件下的导航与检查结果。表3可视化了从C1到C3的导航通过率退化情况。
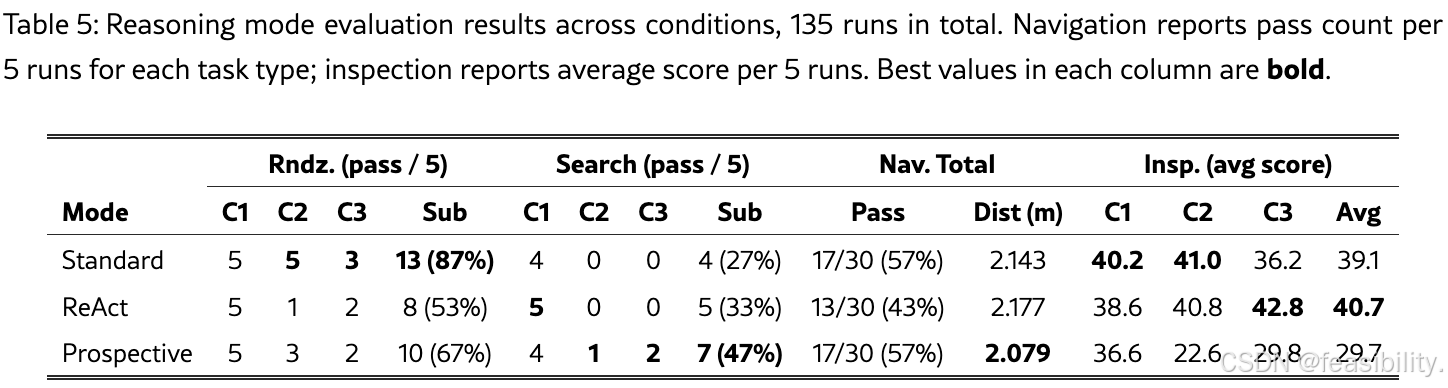
发现一:标称条件下的全面成功
在标称条件(C1)下,所有三种模式均实现90--100%的导航成功率。这表明在理想条件下,三种推理模式都能有效完成任务,差异主要体现在计算开销和决策步数上。
发现二:没有单一模式主导所有任务
实验结果揭示了一个核心结论:没有单一推理模式在所有任务和条件下都占主导地位。三种模式各有其优势领域和脆弱点,这直接验证了SpaceMind可切换推理模式架构的设计价值------需要根据任务类型和环境条件动态选择最合适的认知深度。
发现三:Rndz./Search分裂暴露出根本不同的退化模式
当分别考察交会(Rendezvous)和搜索-接近(Search-and-Approach)时,三种模式表现出截然不同的退化模式:
Standard模式:
-
交会任务 :在三种条件下均表现最强,C1达到5/5,C2保持5/5,C3为3/5,交会子总计13/15(87%),为三种模式最高。这表明当目标可见时,直接决策策略足够高效且鲁棒。
-
搜索任务 :在退化条件下完全崩溃 ,C2为0/5,C3为0/5,搜索子总计仅4/15(27%)。当目标不可见且环境退化时,缺乏深思熟虑的直接决策无法有效恢复。
-
导航总计:17/30(57%),与Prospective持平。
-
检查任务 :C1得分40.2(三种模式最高),平均39.1。
ReAct模式:
-
交会任务 :C1完美5/5,但C2骤降至1/5,C3为2/5,交会子总计8/15(53%) 。原文分析指出,多数失败是因为Thought--Action--Observation循环在目标远离预期位置时发生振荡,导致达到50步超时限制。
-
搜索任务 :C1完美5/5,但C2/C3均为0/5,搜索子总计5/15(33%)。
-
导航总计:13/30(43%),为三种模式最低。
-
检查任务 :呈现反直觉模式 ------C3得分42.8,超越Standard的36.2和Prospective的29.8,为三种模式在C3条件下最高。
Prospective模式:
-
交会任务 :C1为5/5,C2为3/5,C3为2/5,交会子总计10/15(67%),介于Standard和ReAct之间。
-
搜索任务 :唯一在退化条件下实现搜索成功的模式 ------C2为1/5,C3为2/5,搜索子总计7/15(47%),几乎是Standard 27%的两倍。其候选预测机制通过评估多个运动假设后再提交,避免了盲目探索。
-
导航总计:17/30(57%),与Standard持平。
-
终端距离 :2.079 m,为三种模式最精确。
-
检查任务:表现相对较弱,C1仅36.6,C3仅29.8,平均29.7为三种模式最低。
发现四:Prospective的搜索优势具有任务特异性
Prospective的优势特定于搜索-接近任务------在这些任务中目标必须首先被找到。对于交会任务(目标已经可见),Standard模式足够且额外推理开销没有收益。这解释了为何Prospective的交会子总计(67%)反而低于Standard(87%):在简单任务中过度推理不仅无益,还可能引入不必要的复杂性。
发现五:检查任务的反直觉模式------ReAct的"快速终止"优势
检查任务出现了一个 counter-intuitive pattern(反直觉模式):
-
ReAct在C3条件下得分最高(42.8),超越Standard(36.2)和Prospective(29.8)
-
原文分析揭示原因:ReAct的快速终止策略(1--3步)限制了幻觉积累。在退化视觉条件下,智能体越快完成检查并终止,越少机会积累错误感知
-
Prospective的两阶段推理反而放大了VLM幻觉风险------在能见度差的情况下,生成三个候选动作并评估的过程会引入更多推理步骤,每一步都可能产生幻觉,导致检查报告质量下降
这一发现极具实践意义:在感知质量退化的场景中,"少即是多"------更少的推理步骤反而可能带来更好的结果。
发现六:图3的宏观退化趋势
从图3的导航通过率曲线可以观察到:
-
C1(标称条件):三种模式均接近100%,差异不大
-
C2(远侧向偏移+曝光不足):ReAct急剧退化至约10%,Standard降至约50%,Prospective降至约40%
-
C3(反向偏移+曝光过度):Standard继续降至约30%,Prospective维持在约40%,ReAct回升至约20%
发现七:动态技能路由验证
从135次运行中提取的路由决策显示,技能网关实现了 100%的预期分配一致性:
-
交会任务 → 接近(approach)+ 距离(distance)技能
-
搜索-接近任务 → 搜索(search)+ 目标恢复(target-recovery)+ 距离(distance)技能
-
检查任务 → 检查(inspection)+ 感知(perception)技能
无需人工干预,LLM-based技能网关即可从模块化目录中可靠地组合任务适用的技能集,验证了动态路由机制的有效性。
3.3.3 模式选择部署指南
基于以上发现,论文提出了具体的模式选择指南:
-
标称条件 + 简单任务(交会):Standard 模式------计算开销最低,成功率已足够
-
退化条件 + 搜索任务:Prospective 模式------唯一可靠选择
-
退化条件 + 检查任务:ReAct 模式------快速终止策略最优
-
长程/高不确定性任务:Prospective 模式------认知深度最高
这一系统评估首次为VLM太空智能体的推理模式选择提供了实证基础,而非依赖直觉或假设。
3.4 自进化实验
自进化评估活动覆盖 30次运行 ,分为 6组,每组包含一个基线(BL)运行和最多5轮迭代进化运行(R1--R5),测试智能体从失败中自主恢复和迭代改进的能力。
3.4.1 实验设计与设置
实验分组(见表6):
| 卫星 | 任务 | 条件 | 基线结果 | 基线详情 | 进化后最佳结果 | 进化后详情 | 评判 |
|---|---|---|---|---|---|---|---|
| CAPSTONE | Search | C1 | OK | 2.597 m | 0/5 | --- | No benefit |
| CAPSTONE | Insp. | C2 | 50 pt | --- | 65 pt | +30% | Positive |
| New Horizons | Search | C1 | FAIL | 10 st | 3/5 | 2.102m | Positive |
| New Horizons | Rndz. | C3 | FAIL | 20 st | 5/5 | 7 st | Strong+ |
| Huygens | Rndz. | C2 | OK | 2.209m | 3/5 | 2.169m | No benefit |
| Huygens | Insp. | C1 | 12 pt | --- | 68 pt | +467% | Strong+ |
注:st = steps(步数),pt = points(分数)。BL = 推理评估活动中的基线。
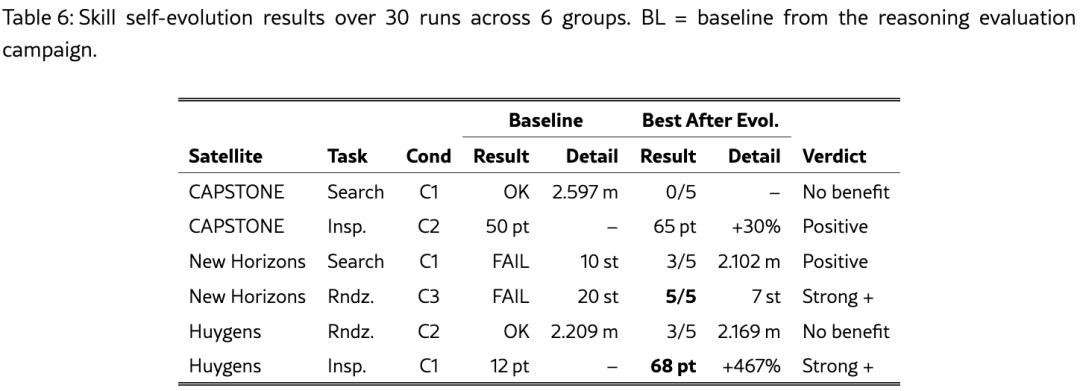
实验逻辑:每组从基线(BL)开始,运行一次片段。随后,自进化机制分析该片段并生成学习技能。在接下来的运行(R1--R5)中,这些学习技能被自动注入系统提示词。每组最多运行5轮迭代,或直到结果不再改善。
图4展示了六组的学习曲线,按任务类型分三列(Rndz.、Search、Insp.)。Rndz.组中柱状图表示成功率,虚线表示步数;Insp.组中实线表示分数,虚线水平线标记基线水平。绿色 表示明确的正向收益,灰色表示无显著改善。
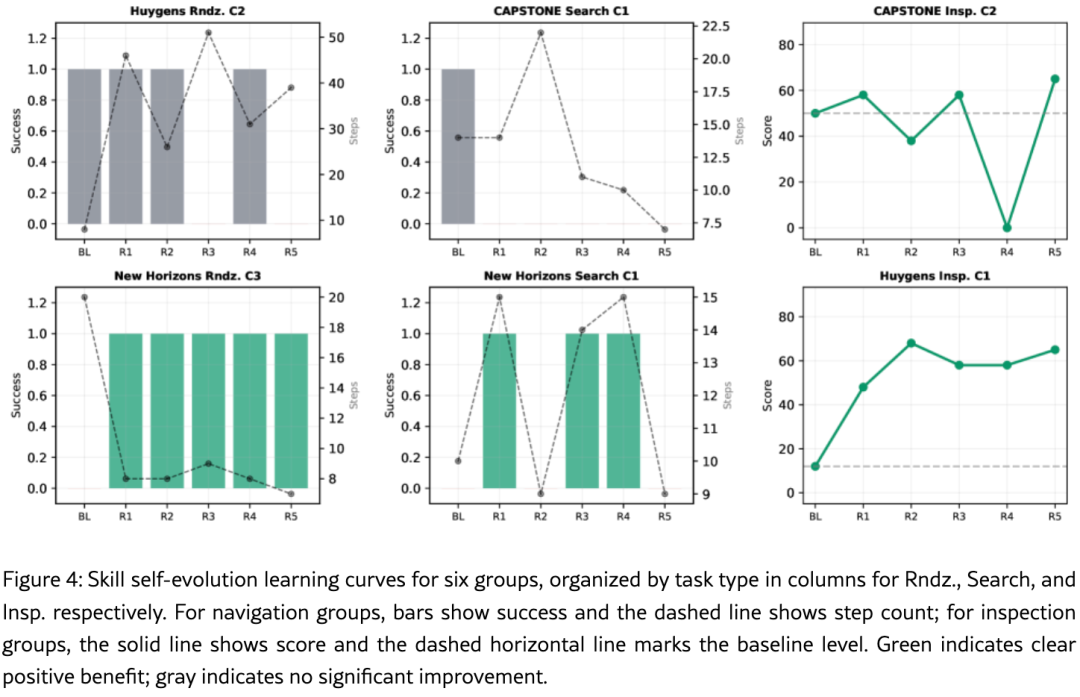
发现一:最引人注目的结果------从失败中恢复的能力
表的组4: New Horizons Rndz. C3(左下图)------ 完全失败到100%成功
-
Table 6基线:FAIL,20 st
-
Table 6进化后 :5/5成功 ,7 st
-
评判:Strong +
动态趋势:R1-R5全部为成功,步数从约20步稳步下降至7步。这一收敛趋势清晰可见:学习技能不仅修复了导致失败的错误,还发现了更优的运动规划策略------远距离大步长接近、近距离小步长精确控制。
****表的组3: New Horizons Search C1(中下图)------ 完全失败到部分成功
-
Table 6基线:FAIL,10 st
-
Table 6进化后 :3/5成功,2.102 m
-
评判:Positive
动态趋势 :R1即转为成功,步数约15步。R2再次失败,R3-R4成功,R5失败。这一波动模式反映了搜索任务的固有不确定性,但R1的立即成功证明了反思机制能够从单次失败片段即可提取可执行知识。
发现二:检查任务的一致增益------覆盖式变异的价值
两组检查组均通过overlay mutation机制实现持续改进。
表的组2: CAPSTONE Insp. C2(右上图)------ 温和提升
-
Table 6基线:50 pt
-
Table 6进化后 :65 pt,+30%
-
评判:Positive
动态趋势:右上子图中,实线从BL的50分(虚线水平线)波动上升,R1约58分,R2降至约38分,R3回升至约58分,R4骤降至0分,R5最终收敛至65分。论文指出"the incremental overlay refinement of perception strategies proves particularly effective for this task type"(感知策略的增量式叠加改善对这种任务类型特别有效)。虽然曲线存在波动,但最终收敛到高于基线的水平,验证了这种改善机制在检查任务中的价值。
表的组6: Huygens Insp. C1(右下图)------ 最戏剧性的提升
-
Table 6基线 :12 pt
-
Table 6进化后 :平均59.4 pt ,最佳68 pt ,+467%
-
评判:Strong +
动态趋势:右下子图中,实线从BL的12分(接近底部的绿色点)持续上升,R1跃升至约48分,R2达到峰值约68分,R3-R4稳定在约58分,R5回升至约65分。论文强调"from 12 to an average of 59.4 points"(从12分到平均59.4分),这一平均值而非单次最佳值的表述说明提升具有统计显著性。从12分到48分的R1跃升表明初始失败中蕴含大量"低垂果实"------第一次反思即纠正了系统性感知缺陷。
发现三:成功场景的进化风险------基线成功时无收益
表的组1: CAPSTONE Search C1(中上图)------ 成功到全面失败
-
Table 6基线:OK,2.597 m
-
Table 6进化后 :0/5
-
评判:No benefit
动态趋势:中上子图中,BL为成功(灰色柱状),步数约14步。R1-R5全部转为失败,R2步数飙升至约22步,R5降至约7步但成功率仍为0。这一"成功→全面失败"的逆转揭示了核心风险:基线成功时的轨迹被过度拟合为通用策略,当条件微变时完全失效。
表的组5: Huygens Rndz. C2(左上图)------ 成功但效率波动
-
Table 6基线:OK,2.209 m
-
Table 6进化后:3/5,2.169 m
-
评判:No benefit
动态趋势:左上子图中,BL为成功(灰色柱状),步数约8步。R1-R3维持成功但步数剧烈波动(45→25→50步),R4-R5成功率降至60%。虽然终端距离从2.209 m微幅优化到2.169 m,但步数的不稳定波动表明学习技能引入了不必要的复杂性,破坏了原有简洁策略的效率。
3.5 真实世界验证
18次运行的真实世界验证确认:相同的架构------包括完全相同的智能体决策循环、MCP工具签名和Redis通信协议------可以在零代码修改 的情况下操作物理机器人,唯一的变化是将物理后端替换为ROS2传感器桥接和电机控制器,实现100%交会成功率,并展示了跨目标的涌现规模适应和行为一致性。
3.5.1 实验设置
实验规模 :两颗卫星模型(CAPSTONE和Artemis)× 三种任务(Rndz.、Search、Insp.)× 每种组合3次重复,总计 18次运行。
硬件配置:
-
机器人平台:myAGV Pro全向移动机器人(Mecanum轮,40kg负载)
-
传感器:Orbbec Gemini 2立体RGB相机(1920×1080分辨率)
-
软件栈:ROS2 Humble,通过Redis桥接与智能体决策循环通信
-
运动约束:3-DoF平面运动(与仿真的6-DoF不同)
关键设计 :智能体决策循环、MCP工具服务器和Redis通信契约完全不变,仅将UE5/AirSim后端替换为ROS2传感器桥接和电机控制器。
3.5.2 结果总览
表7汇总了18次运行的结果:
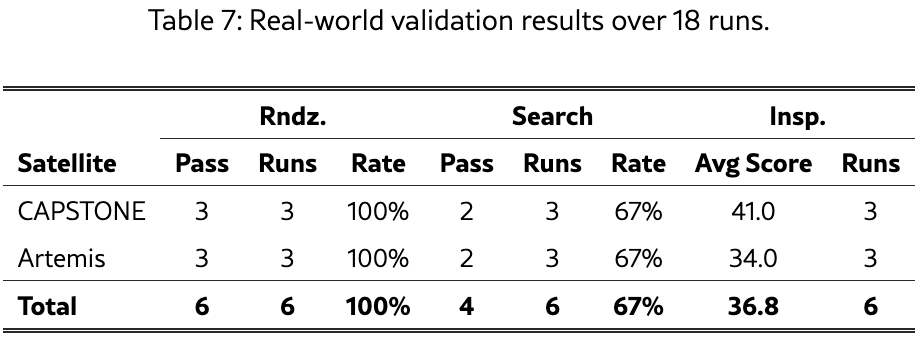
核心结果:
-
交会任务 :完美通过率 6/6(100%)
-
搜索任务 :**4/6(67%)**通过率
-
检查任务 :平均得分 36.8分
3.5.3 三个物理环境特有观察
论文强调了三个仅出现在物理环境中的关键观察,这些观察揭示了仿真到真实迁移中的涌现行为和潜在风险:
观察一:涌现的规模自适应(Emergent Scale Awareness)
智能体自主 将步长从仿真中的1--2m/步调整为实验室中的0.1--0.2m/步,无需任何显式重新配置。
分析 :这一涌现行为是SpaceMind架构鲁棒性的有力证明。在仿真中,智能体学会了"大步长快速接近"的策略,因为仿真环境的空间尺度较大(卫星距离通常数米至数十米)。当迁移到物理实验室时,面对1米直径的卫星模型和有限的空间,智能体通过视觉反馈自主感知到"目标在视野中显得更大",从而推断出"需要更小的步长"。
这种自适应并非通过显式编程实现,而是VLM的空间推理能力 的涌现表现------智能体从视觉输入中推断出尺度关系,并调整运动策略。这验证了SpaceMind的认知弹性:智能体不仅执行预定义策略,还能根据环境反馈动态调整参数。
观察二:行为一致性验证(Behavioral Consistency)
目标恢复技能(target-recovery skill)的偏航(yaw) ±90°扫描模式 从仿真到物理环境完全不变地迁移。
深度分析 :在搜索任务中,当目标丢失时,智能体执行yaw±90°的扫描搜索。这一行为模式在UE5仿真中形成后,在物理机器人上被原样复现 ,没有任何代码修改或参数调整。这证明了SpaceMind的技能抽象层的有效性------技能描述的是"做什么"(搜索丢失目标)而非"怎么做"(具体的电机控制指令),因此可以在不同物理后端上实现相同的高层行为。
这一观察对太空操作尤为重要:在轨服务中,某些策略(如搜索模式、接近轨迹)需要在不同航天器平台上复用。SpaceMind的技能层提供了这种行为级可移植性,而非低级的控制指令级移植。
观察三:近距离安全边界的必要性(Safety Margin Requirement)
一次检查运行中发生了碰撞,原因是15次迭代中累积的小步长运动导致智能体过于接近目标表面。
深度分析 :这是18次运行中唯一一次安全事故,但它揭示了一个关键的设计教训:在近距离操作(close-proximity operations)中,需要显式的安全边界(explicit safety margins)。在仿真中,碰撞检测可能不够严格,或者智能体学会了"尽可能接近以获得更好的检查视角"。但在物理环境中,这种策略可能导致实际碰撞。
这一发现直接反馈到SpaceMind的质量门设计------未来的学习技能生成应包含"最小安全距离"的硬约束,且该约束不应被任何overlay或rewrite操作覆盖。这也提示在检查任务的技能定义中,应加入"当距离小于阈值时自动终止或后退"的安全规则。
3.5.4 代表性案例分析:CAPSTONE搜索-接近任务
图5 展示了一个真实的搜索-接近任务的第三人称视角,共14步:
Step 1:初始姿态,目标不在视野内
Step 4:通过偏航扫描搜索检测到目标
Step 5:航向对准目标
Step 8:近距离接近目标
Step 12:接近过程中发生横向偏移,智能体恢复
Step 14:重新对准并在距目标表面0.8 m处终止(成功)

这一案例生动展示了SpaceMind在物理环境中的 完整决策链 :搜索→检测→对准→接近→漂移恢复→精确终止。值得注意的是,Step 12的横向漂移恢复证明了分层记忆系统的价值------智能体能够从之前的步骤中记住目标位置,即使暂时偏离也能恢复跟踪。
3.5.5 验证结论
论文总结:"These results validate the interface and communication architecture and demonstrate that SpaceMind's modular design generalizes across environments."(这些结果验证了接口和通信架构,并证明SpaceMind的模块化设计可以跨环境泛化。)
具体而言,真实世界验证确认了三个核心设计目标:
-
零代码修改迁移:MCP-Redis双层抽象确实实现了"相同代码库,不同物理后端"的设计承诺
-
行为一致性:高层技能(如搜索模式)在不同环境中表现一致,验证了技能抽象的通用性
-
涌现自适应:智能体能够自主适应环境尺度变化,无需人工干预
同时,碰撞事件也揭示了未来改进方向:在检查任务中引入显式安全边界约束,将安全规则提升为不可覆盖的核心技能。
3.6 定性分析:涌现行为的四个典型案例
论文通过四个代表性片段展示了SpaceMind设计所涌现的复杂行为。Figure 6展示了每个片段的关键帧图像,从智能体的传感器视角记录了决策过程的视觉证据。

3.6.1 案例一:实验室目标丢失恢复(Lab Target-Lost Recovery)
场景 :物理实验室中CAPSTONE搜索任务关键帧:(a) Step 1 ------ 初始姿态,目标不可见;(b) Step 42 ------ 目标已找到并接近
行为描述 : 在物理实验室的CAPSTONE搜索任务中,初始姿态下目标不在视野内(Fig. 6a)。在target-recovery skill(目标恢复技能) 的指导下,智能体执行了一个有界的偏航扫描 :先向右转6次(每次15°),再向左转9次(每次15°),最终检测到目标并切换至接近模式。整个片段历时42步 ,在距目标1.13 m处终止(Fig. 6b)。
涌现机制分析 : 这一案例展示了模块化技能知识与分层记忆系统的协同作用 。target-recovery skill提供了高层策略("当目标丢失时执行偏航扫描"),但具体的扫描参数(6次右转+9次左转)并非硬编码,而是由VLM根据当前态势动态生成。分层记忆系统记录了之前的转向历史和目标检测结果,使智能体能够避免重复搜索已扫描区域。42步的长片段也证明了智能体在扩展时间跨度上维持任务目标的能力------从搜索到检测再到接近,跨越数十个决策步骤而不迷失。
3.6.2 案例二:主动曝光调整(Active Exposure Adjustment)
场景 :C2低曝光条件下的检查任务关键帧:(c) Step 1 ------ 图像几乎全黑;(d) Step 10 ------ 曝光调整后目标清晰可见
行为描述 : 在C2的曝光不足条件下,初始相机图像几乎全黑(Fig. 6c)。智能体首先调用亮度诊断工具(brightness diagnostic tool) 评估图像质量,识别出曝光不足问题,随后调用**曝光控制工具(exposure-control tool)**增加相机曝光。调整后,目标变得清晰可见(Fig. 6d),智能体继续进行部件级检查。
涌现机制分析 : 这一案例凸显了SpaceMind作为主动决策控制中枢 而非被动感知消费者的角色。传统视觉系统通常被动接受传感器输入,无论质量如何。而SpaceMind能够诊断自身感知质量的问题 ,并主动调用工具修复它 。这种"感知-诊断-修复-再感知"的闭环是具身智能的关键特征------智能体不仅感知环境,还能改善自身的感知能力。
更深层的意义在于:这一行为并非通过显式编程实现("如果图像暗则调曝光"),而是VLM从工具列表中自主选择了亮度诊断和曝光调整工具的组合。这验证了MCP工具暴露设计的有效性------将相机曝光调整作为显式工具,使智能体能够将其纳入推理链。
3.6.3 案例三:Prospective候选预测(Prospective Candidate Prediction)
场景 :C2退化条件下的New Horizons搜索任务关键帧:(e) Step 1 ------ 空视野;(f) Step 29 ------ 目标已到达
行为描述 : 在C2条件下的New Horizons搜索任务中,Standard和ReAct模式均以50步超时失败,但Prospective模式在29步 内成功到达目标,终端距离2.007 m(Fig. 6e--f)。在规划阶段,智能体生成三个候选运动方向,每个伴随预测结果和风险评分;选择器选择风险最低的选项,避免了导致其他模式超时的盲目探索。
涌现机制分析 : 这一案例是Prospective模式认知深度的直观证明。在Standard模式下,智能体直接选择动作,当目标不可见且环境退化时,容易陷入"随机探索→失败→再探索"的死循环。在ReAct模式下,虽然引入了推理循环,但单一路径的迭代仍可能在错误方向上持续尝试。
Prospective模式的两阶段审议(规划→评分→选择)从根本上改变了探索策略:
-
规划阶段:生成多个假设("向左搜索"、"向右搜索"、"向前推进")
-
评分阶段:评估每个假设的风险("向左可能偏离轨道"、"向右视野更开阔"、"向前可能错过目标")
-
选择阶段:基于评分选择最优策略
这种"先思考再行动"的机制使智能体在信息不完整时仍能做出结构化决策,而非盲目试错。Fig. 6e的空视野到Fig. 6f的目标到达,直观展示了这一认知深度带来的实际收益。
3.6.4 案例四:自进化失败恢复(Self-Evolution Failure Recovery)
场景 :New Horizons Rndz. C3组的自进化过程关键帧:(g) Step 1 ------ 基线失败时的初始视野;(h) Step 8 ------ 学习技能注入后成功接近
行为描述 : 在New Horizons Rndz. C3组中,基线在20步时失败(Fig. 6g)。经过一轮自进化后,进化运行时生成了一条学习技能,编码了距离相关步长缩减策略。从Round 1起智能体持续成功,步数从20步收敛到7步(Fig. 6h)。该学习技能以标准技能文件形式持久化,可被审计、可移植,并由技能网关自动路由。
涌现机制分析 : 这一案例是自进化机制完整闭环的直观展示:
-
失败:基线在20步时因距离估计错误或步长控制不当而失败
-
反思:自进化外循环分析失败片段,识别核心问题------"在接近目标时未根据距离调整步长,导致 overshoot 或碰撞"
-
生成:VLM生成学习技能,编码规则:"当距离>5m时步长1m,距离2-5m时步长0.5m,距离<2m时步长0.2m"
-
验证:质量门检查安全短语、指纹去重、任务范围绑定
-
注入:学习技能在下一轮自动加载,与基础技能一起注入系统提示词
-
成功:智能体在Step 8即成功接近目标(Fig. 6h),步数从20优化到7
Fig. 6g到Fig. 6h的视觉对比极具说服力:基线失败时的视野与成功接近时的视野几乎相同(同一任务、同一卫星、同一初始条件),唯一的变化是学习技能的注入。这证明了自进化的因果效应------性能提升确实源于生成的学习技能,而非随机波动。
此外,学习技能以标准文件格式持久化,意味着它可以在不同会话、不同环境、甚至不同卫星任务中被复用。例如,为New Horizons Rndz. C3生成的距离相关步长策略,可能被技能网关自动路由到Huygens Rndz. C2任务中,实现跨任务的知识迁移。
3.6.5 四个案例的跨主题洞察
四个案例从不同维度验证了SpaceMind的核心设计决策:
| 案例 | 验证的设计决策 | 涌现行为 | 关键证据 |
|---|---|---|---|
| 目标丢失恢复 | 模块化技能 + 分层记忆 | 42步长程搜索-接近 | Fig. 6a--b |
| 主动曝光调整 | MCP工具协议 + 显式传感器控制 | 自主改善感知质量 | Fig. 6c--d |
| Prospective候选预测 | 可切换推理模式 + 两阶段审议 | 退化条件下的结构化探索 | Fig. 6e--f |
| 自进化失败恢复 | 技能自进化 + 质量门 | 从失败中提取可审计知识 | Fig. 6g--h |
这些定性案例与192次运行的定量评估形成互补:定量数据证明了统计显著性,而定性案例展示了智能体在做什么、如何做、以及为什么这样做。两者共同构建了SpaceMind作为太空具身智能体的完整证据链。
四、核心创新与技术意义
4.1 四大核心贡献
-
面向在轨服务的模块化智能体架构:提出SpaceMind,一个为自主航天器操作量身定制的VLM智能体框架,将智能体知识、工具和推理分解为三个独立可扩展的维度------带动态路由的技能模块、基于MCP的带可配置配置文件的工具、以及可注入的推理模式技能。环境无关的接口层使相同代码库能在高保真太空仿真和物理实验室之间无修改运行。
-
面向多阶段太空任务的多模式推理:在同一统一架构中实现三种可切换推理模式(Standard、ReAct、Prospective),为从简单交会到退化条件下长程搜索-接近的任务提供可配置的认知深度。分层记忆系统支持跨步骤上下文推理,用于目标丢失恢复和扩展片段上的策略调整。
-
面向自主在轨改进的技能自进化:引入一种机制,使智能体能够在每次服务片段后自主将运营经验蒸馏为持久、结构化的技能文件,无需模型微调或奖励函数设计,在6组实验中的4组实现显著的失败恢复。
-
全面的闭环验证:开展首个VLM太空智能体的系统性评估,跨越192次运行、5颗卫星、3种任务、3种推理模式和2种互补环境,为每个架构设计决策提供实证基础。
4.2 技术意义与行业影响
SpaceMind 的出现标志着太空机器人领域从预编程自动化 向认知自主化的范式转变:
从"硬编码"到"软智能":传统在轨服务依赖为特定目标预先编程的序列,而SpaceMind通过VLM的自然语言推理能力,使智能体能够理解和适应未见过的目标卫星,实现了真正的"通用太空操作智能"。
从"一次性"到"终身学习":技能自进化机制打破了"每次任务从零开始"的局限,使太空智能体具备了在轨持续改进的能力。这在太空探索中尤为重要------因为每次发射都极其昂贵,智能体能够从每次接触中学习并积累经验,将显著提升长期任务的可靠性和效率。
从"仿真-现实鸿沟"到"无缝迁移":MCP-Redis双层抽象架构首次实现了太空智能体从仿真到物理硬件的零代码修改迁移。这一设计不仅降低了开发成本,更重要的是为"仿真训练-真实部署"的标准化流程奠定了基础。
从"单一策略"到"认知弹性":三种可切换推理模式的引入,使智能体能够根据任务复杂度和环境条件动态调整认知深度。这种"认知弹性"对于应对太空环境中固有的不确定性至关重要。
4.3 局限与未来方向
尽管SpaceMind取得了显著进展,仍存在一些局限和未来方向:
-
计算资源:VLM推理需要较大的计算资源,在轨部署可能需要边缘计算优化或模型压缩
-
延迟敏感:太空通信的延迟特性要求智能体具备更强的自主决策能力,减少对地面控制的依赖
-
多智能体协作:当前框架专注于单智能体操作,未来可扩展至多智能体协同在轨服务
-
真实在轨验证:实验室验证是重要的第一步,但真实太空环境(微重力、辐射、极端温度)的验证仍是最终目标
五、结论
SpaceMind是 一个面向自主在轨服务的模块化且自进化的具身VLM智能体框架,代表了太空具身智能领域的一个重要里程碑。SpaceMind将智能体知识、工具和推理分解为三个独立可扩展的维度,并引入了技能自进化机制,该机制能够在无需模型微调的情况下,将运营经验蒸馏为持久、可审计的技能文件。
通过跨越 5颗卫星 、3种任务 、3种推理模式 和 2种环境 的 192次闭环运行 ,证明了该框架在标称条件下实现 90--100%的导航成功率 ,在6组实验中的4组通过自进化从失败中恢复,并以零代码修改迁移到物理硬件。这些结果确立了SpaceMind作为构建自主太空操作中可适应、传感器驱动智能体的实用基础。
SpaceMind的出现标志着太空机器人领域从预编程自动化向认知自主化的重要转变。其模块化架构解决了可扩展性挑战,多模式推理提供了认知灵活性,而技能自进化机制则赋予了智能体从经验中持续改进的能力。这些设计决策的系统性验证------从工具消融到推理模式比较,从自进化学习到真实世界迁移------为每个架构选择提供了实证基础。
SpaceMind研究团队的未来工作将聚焦于在真实太空环境中验证该框架,扩展至多智能体协同场景,并进一步优化边缘计算部署效率。SpaceMind所展示的"从失败中学习、在运行中进化"的能力,或许正是下一代自主太空系统所需的核心认知范式。
参考资料
-
代码: GitHub - wuaodi/SpaceMind
-
会议版本: IAA Conference on AI in and for Space (SPAICE 2025)
创作不易,禁止抄袭,转载请附上原文链接及标题