
文章目录
- 一、四个概念的精准定义
-
- [1. Seq2Seq (Sequence-to-Sequence)](#1. Seq2Seq (Sequence-to-Sequence))
- [2. Encoder-Decoder (编码 - 解码架构)](#2. Encoder-Decoder (编码 - 解码架构))
- [3. RNN (Recurrent Neural Network, 循环神经网络)](#3. RNN (Recurrent Neural Network, 循环神经网络))
- [4. Attention (注意力机制)](#4. Attention (注意力机制))
- 二、它们之间的组合演变史(联系的核心)
-
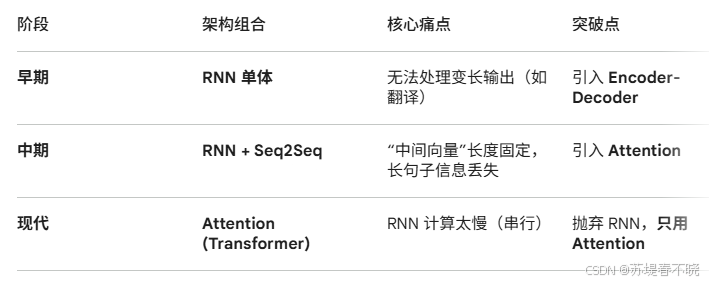
- 第一阶段:经典组合 (2014)
- 第二阶段:引入注意力 (2015-2016)
- [第三阶段:Transformer 革命 (2017 - 至今)](#第三阶段:Transformer 革命 (2017 - 至今))
- 三、深度对比表
- 四、通俗类比总结
- 五、最终结论
一、四个概念的精准定义
1. Seq2Seq (Sequence-to-Sequence)
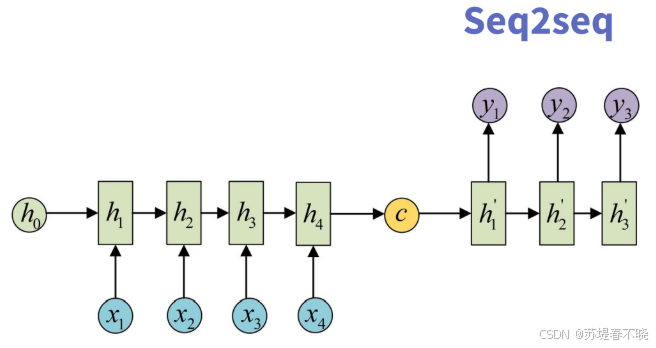
- 本质 :一种任务范式 或问题类型。
- 定义:输入是一个序列(Sequence),输出也是一个序列(Sequence),且两者长度通常不同。
- 例子 :
- 机器翻译:中文序列 → \to → 英文序列。
- 文本摘要:长文章序列 → \to → 短摘要序列。
- 问答系统:问题序列 → \to → 答案序列。
- 关系 :Seq2Seq 是目标 ,Encoder-Decoder 是实现这个目标的最常用架构。
2. Encoder-Decoder (编码 - 解码架构)
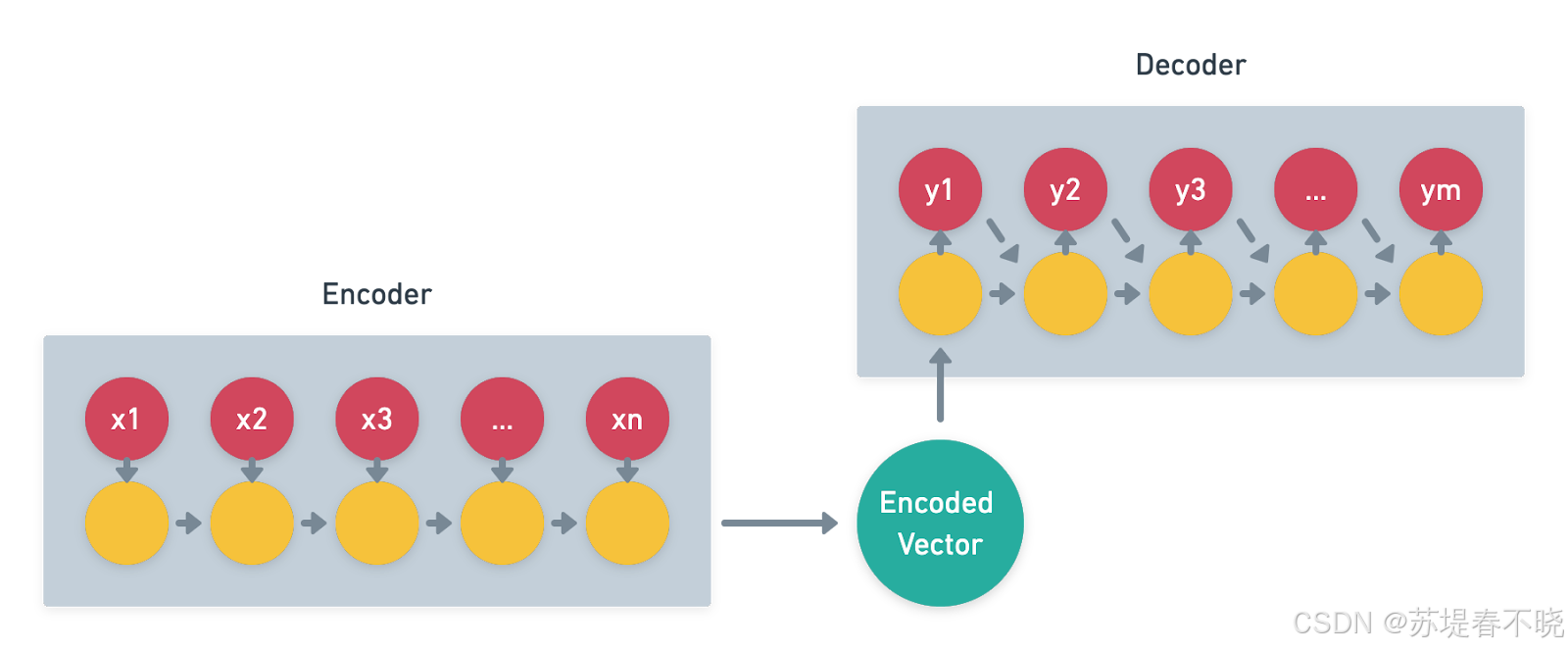
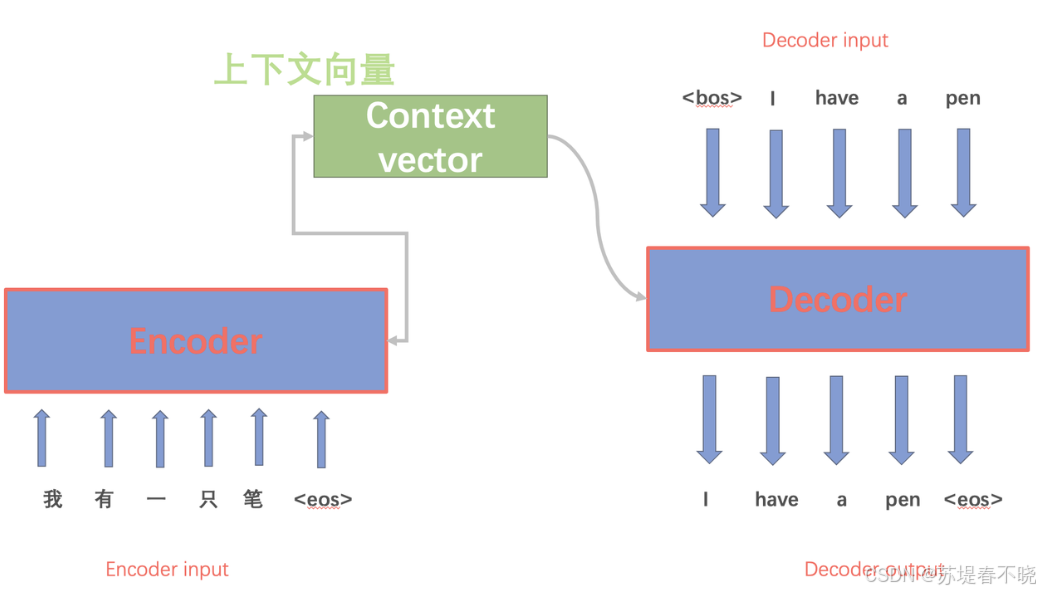
- 本质 :一种神经网络拓扑结构。
- 功能 :
- Encoder :负责"压缩",将任意长度的输入序列转换成一个固定维度的上下文向量 (Context Vector) 或一组状态表示。
- Decoder:负责"解压",将这个向量还原成任意长度的输出序列。
- 地位 :它是实现 Seq2Seq 任务的具体骨架。
- 适用范围:不仅用于 NLP,还用于图像描述(Image Captioning,Encoder是CNN,Decoder是RNN)、语音合成等。
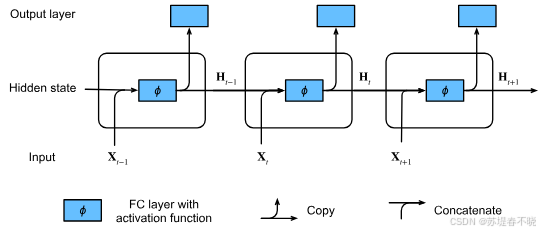
3. RNN (Recurrent Neural Network, 循环神经网络)
- 本质 :一种神经网络单元(算子/层)。
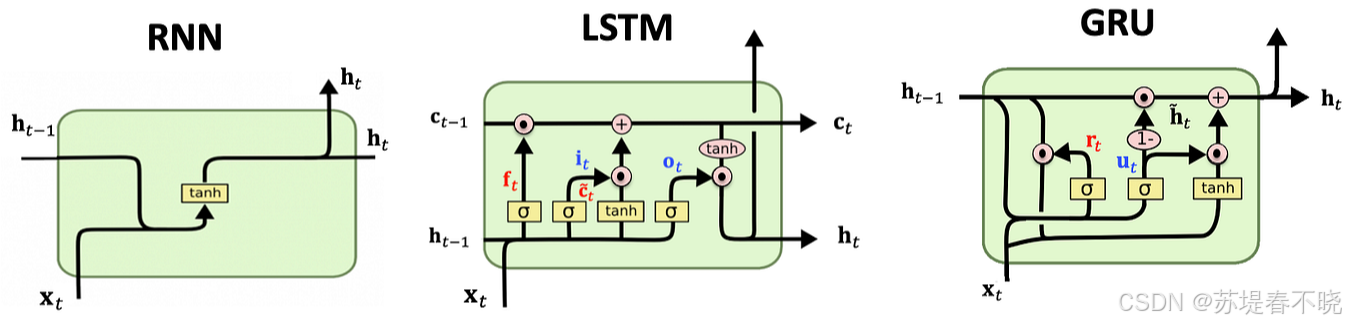
- 特点 :具有"记忆"功能,处理数据是串行 的( t t t 时刻依赖 t − 1 t-1 t−1 时刻)。包含 LSTM、GRU 等变种。
- 角色 :它是早期构建 Encoder 和 Decoder 的核心积木。
- 局限:无法并行计算(慢),长距离记忆能力差(梯度消失)。
4. Attention (注意力机制)
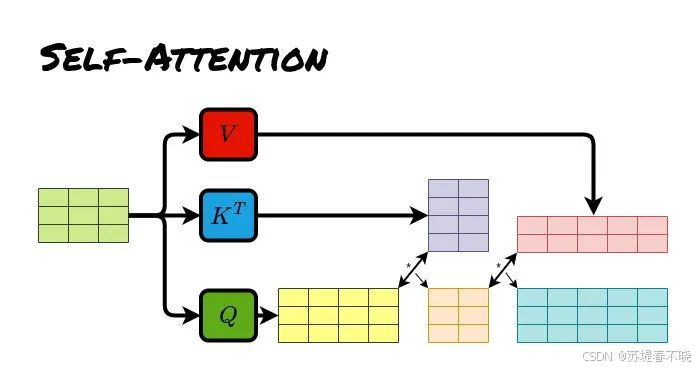
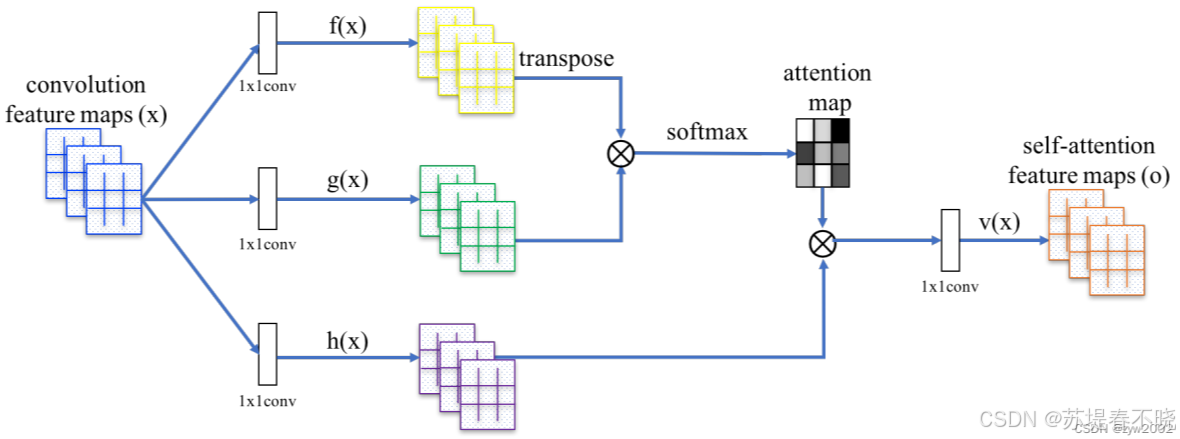
- 本质 :一种算法机制 或加权策略。
- 功能:允许模型在处理当前信息时,动态地关注输入序列中的不同部分,并赋予不同的权重。
- 角色 :
- 作为插件:加在 RNN 的 Encoder-Decoder 之间,解决长句子遗忘问题。
- 作为核心:在 Transformer 中,完全取代 RNN,成为唯一的构建模块(Self-Attention)。
- 核心价值:解决了"信息瓶颈"和"长距离依赖",并实现了并行计算。
Attention 最初是为了打破 RNN 在 Seq2Seq 任务中的瓶颈而诞生的。
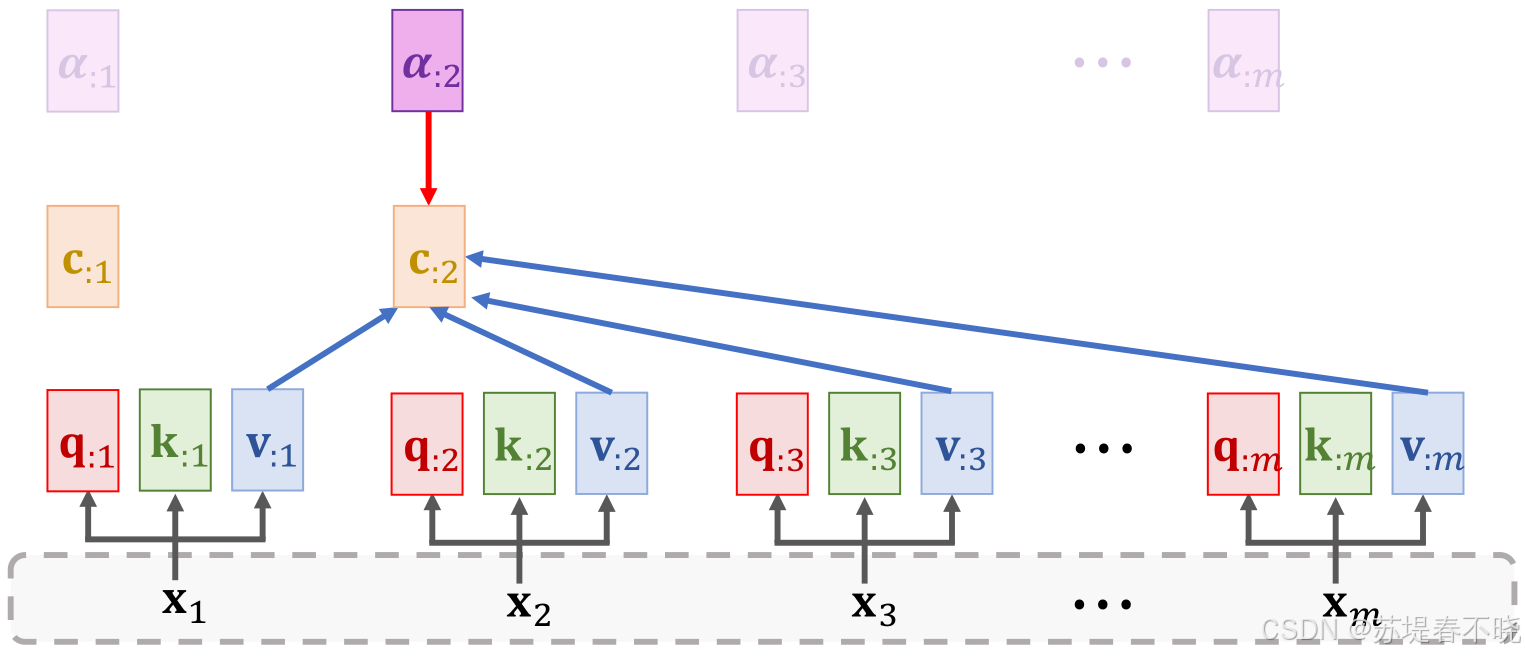
Seq2Seq (序列到序列:一种任务类型)
Encoder-Decoder (编解码器:一种设计模式)
RNN (循环神经网络:一种计算组件)
Attention (注意力机制:一种增强插件)
二、它们之间的组合演变史(联系的核心)
第一阶段:经典组合 (2014)
公式 :
Seq2Seq 任务=Encoder-Decoder 架构+RNN 单元
- 结构 :
- Encoder 是一个 RNN,读完句子,把最后一个隐藏状态 h n h_n hn 传给 Decoder。
- Decoder 是另一个 RNN,靠着 h n h_n hn 开始生成。
- 问题 :如果句子太长, h n h_n hn 存不下所有信息(信息瓶颈),导致翻译头尾不一致。
第二阶段:引入注意力 (2015-2016)
公式 :
Seq2Seq 任务=Encoder-Decoder 架构+RNN 单元+Attention 机制
- 改进 :
- Encoder RNN 不再只传最后一个状态,而是保留所有步骤 的状态 h 1 , . . . , h n h_1, ..., h_n h1,...,hn。
- Decoder 在生成每个词时,通过 Attention 机制,去"查询"Encoder 的所有状态,动态生成一个上下文向量。
- 结果:大幅提升了长句子的翻译效果,但底层依然依赖 RNN,训练速度还是慢(因为 RNN 必须串行)。
第三阶段:Transformer 革命 (2017 - 至今)
公式 :
Seq2Seq 任务=Encoder-Decoder 架构+Attention 单元 (Self-Attention)(RNN 被抛弃!)
- 变革 :
- 发现 Attention 太强了,完全可以替代 RNN 来做特征提取。
- Encoder 由多层 Self-Attention 组成。
- Decoder 由多层 Masked Self-Attention + Cross-Attention 组成。
- 结果:实现了完全并行计算,训练速度飞快,效果远超 RNN。这就是现在的 BERT (Encoder only), GPT (Decoder only), T5 (Encoder-Decoder) 的基础。
三、深度对比表
| 维度 | Seq2Seq | Encoder-Decoder | RNN | Attention |
|---|---|---|---|---|
| 分类属性 | 任务/问题类型 | 网络拓扑结构 | 基础网络单元 | 计算机制/算法 |
| 核心问题 | 如何将变长输入映射为变长输出? | 如何压缩信息再还原信息? | 如何处理序列依赖和记忆? | 如何动态聚焦关键信息? |
| 依赖性 | 依赖具体的模型架构来实现 | 依赖具体的单元 (RNN/Transformer) 来填充 | 可独立用于分类、预测等 | 通常嵌入在架构中,也可独立成模型 |
| 计算方式 | 取决于底层实现 | 取决于底层实现 | 串行 (不可并行,慢) | 并行 (矩阵运算,快) |
| 长距离依赖 | 取决于底层实现 | 取决于底层实现 | 弱 (随长度增加而衰减) | 极强 (任意两点距离为1) |
| 典型代表 | 翻译、摘要、对话 | 机器翻译模型、图像描述模型 | LSTM, GRU | Transformer, BERT, GPT |
四、通俗类比总结
用建造一座跨海大桥来类比:
- Seq2Seq :是这座桥要完成的任务目标(把车从A岸运到B岸)。
- Encoder-Decoder :是桥梁的基本结构设计图(一边引桥,一边主桥)。
- RNN :是建造桥梁使用的传统材料/工艺(比如钢筋混凝土,适合一步步浇筑)。
- Attention :是一种先进的施工技术/物流系统(让建材能直接精准投放到任何需要的地方,不用顺着路搬)。
想象你要把一本中文小说翻译成英文小说 (这是 Seq2Seq 任务):
-
Encoder-Decoder 是你的工作流程:
- 先找一个人(Encoder)读完整本中文书,写一份"读书笔记"。
- 再找一个人(Decoder)看着这份"读书笔记",写出英文小说。
-
RNN 是这两个人的工作方式(旧式):
- 他们读书/写字必须一个字一个字按顺序来。
- 读到第100页时,可能已经忘了第1页的内容(记忆有限)。
- 只能一个人接一个人地工作,没法同时开工(串行)。
-
Attention 是升级版的工作技巧:
- 在 RNN 基础上:写英文时,译者(Decoder)不再只看那份简短的"读书笔记",而是可以随时翻回中文原书(Encoder 的所有状态),想看哪页看哪页(注意力加权)。
- 在 Transformer 中:干脆不需要按顺序读书了。一群人同时读整本书,每个人手里都有全书的索引,随时可以关联任何两个段落(Self-Attention),效率极高。
五、最终结论
- Seq2Seq 是我们要做什么(任务)。
- Encoder-Decoder 是我们搭建的架子(架构)。
- RNN 是以前填在这个架子里的砖块(旧组件,有缺陷)。
- Attention 是现在填在这个架子里的高科技材料(新组件,甚至可以直接取代砖块成为墙体本身)。
现在的趋势是:Seq2Seq 任务 几乎都由基于 Attention 的 Encoder-Decoder (即 Transformer) 来完成,RNN 已逐渐退出主流舞台,仅在一些特定小规模或流式场景中偶尔使用。