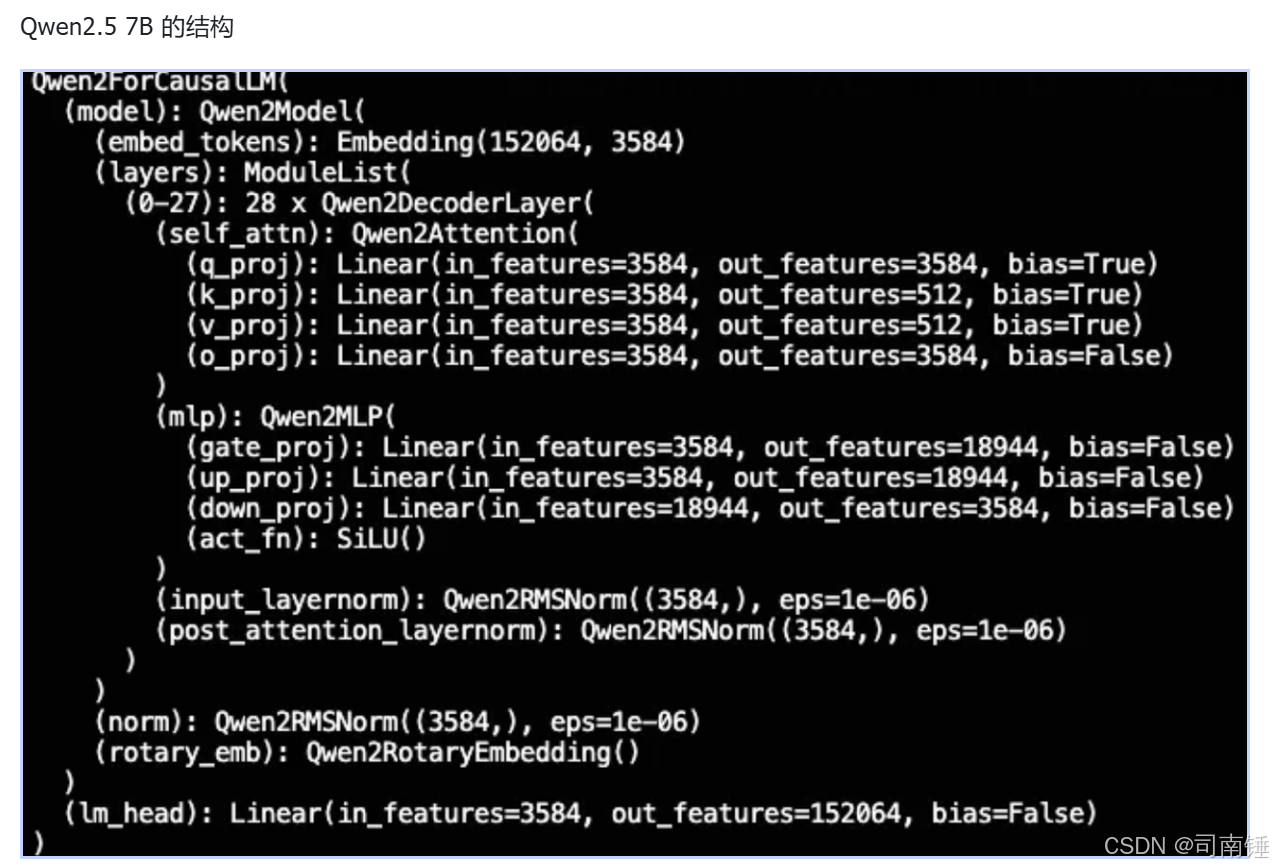
一、整体架构:因果语言模型的骨架
从打印结果可以看到,顶层是 Qwen2ForCausalLM,这是专门用于自回归文本生成的包装类,内部包含两大核心模块:
Qwen2ForCausalLM
├── model: Qwen2Model # Transformer 主干网络
└── lm_head: Linear(3584, 152064, bias=False) # 语言模型头- Qwen2Model:模型的「大脑」,负责将输入 token 编码为高维语义特征。
- lm_head:模型的「嘴巴」,将最终的隐藏态映射到词表概率,决定下一个生成的 token。
这种设计是当前开源 LLM 的标准范式:主干负责特征提取,头部负责概率预测,解耦让训练和推理更灵活。
二、词嵌入层:文本到向量的第一步转换
Qwen2Model 的第一层是词嵌入层:
python
Embedding(152064, 3584)- 词表大小 (152064):Qwen2 系列使用的分词器词表大小,覆盖中英文及多语言场景,比 Llama 2 的 32k 词表更丰富。
- 隐藏维度 (3584) :也叫
hidden_size,是整个模型的基础维度,决定了 token 语义表达的精细程度。7B 版本选择 3584 而非 4096,是在参数量和性能之间的折中。
这一步的作用是:把离散的 token ID 转换成 3584 维的稠密向量,让后续 Transformer 层可以处理。
三、解码器层:28 层堆叠的核心计算单元
Qwen2.5-7B 共有 28 层 Qwen2DecoderLayer,这是模型的核心计算单元,每层都包含「注意力 + 前馈网络」的经典结构:
Qwen2DecoderLayer
├── self_attn: Qwen2Attention # 自注意力机制
├── mlp: Qwen2MLP # 前馈神经网络
├── input_layernorm: Qwen2RMSNorm(3584,)
└── post_attention_layernorm: Qwen2RMSNorm(3584,)3.1 自注意力:GQA 设计的高效实现
注意力层是模型捕捉长距离依赖的关键,Qwen2.5-7B 采用了分组查询注意力 (GQA):
python
Qwen2Attention(
q_proj: Linear(3584, 3584, bias=True)
k_proj: Linear(3584, 512, bias=True)
v_proj: Linear(3584, 512, bias=True)
o_proj: Linear(3584, 3584, bias=False)
)- Q/K/V 投影差异 :
- Query (Q) 维度保持 3584,保证注意力表达能力;
- Key (K) 和 Value (V) 维度压缩到 512,是典型的 GQA 设计。
- 头数计算 :若每个头维度为 128,则 Q 头数 = 3584 / 128 = 28,K/V 头数 = 512 / 128 = 4。即 28 个查询头共享 4 个键值头,既保留了多头注意力的效果,又大幅减少了 K/V 缓存的显存占用。
- 输出投影 (o_proj):将注意力结果映射回 3584 维,且无偏置,进一步减少参数。
3.2 前馈网络:GLU 结构的非线性变换
MLP 层负责对注意力输出做非线性变换,Qwen2.5-7B 采用了门控线性单元 (GLU) 结构:
python
Qwen2MLP(
gate_proj: Linear(3584, 18944, bias=False)
up_proj: Linear(3584, 18944, bias=False)
down_proj: Linear(18944, 3584, bias=False)
act_fn: SiLU()
)- 中间维度 (18944):约为隐藏维度的 5.28 倍(18944 / 3584 ≈ 5.28),是 LLM 中常见的扩展比例,既能提升模型容量,又不会过度增加计算量。
- GLU 计算流程 :
gate_proj和up_proj分别对输入做线性变换;- 两者经过
SiLU激活后逐元素相乘; - 结果由
down_proj映射回 3584 维。
- 无偏置设计:所有线性层均无偏置,这是现代 LLM 的主流选择,可稳定训练并减少参数数量。
3.3 归一化:RMSNorm 替代 LayerNorm
Qwen2.5-7B 没有使用传统的 LayerNorm,而是采用了 RMSNorm:
python
Qwen2RMSNorm(3584, eps=1e-06)- 设计优势:RMSNorm 只做缩放,不做均值减法,计算更高效,且在大模型训练中表现更稳定,能缓解梯度消失问题。
- 位置设计 :
input_layernorm:作用于注意力层输入;post_attention_layernorm:作用于 MLP 输入。
这种「前归一化」设计(Pre-LN)是当前 Transformer 的主流范式,能让训练更稳定。
四、辅助组件:位置编码与最终归一化
除了解码器层,Qwen2Model 还包含两个关键辅助组件:
4.1 旋转位置编码 (RoPE)
python
rotary_emb: Qwen2RotaryEmbedding()Qwen2.5-7B 使用 旋转位置编码 (RoPE) 注入位置信息,而非可学习的绝对位置嵌入:
- RoPE 通过旋转 query 和 key 的向量,让模型自然感知 token 的相对位置;
- 无需额外学习参数,且能外推到更长的上下文长度,是当前大模型的首选位置编码方式。
4.2 最终归一化与语言模型头
python
norm: Qwen2RMSNorm(3584,)
lm_head: Linear(3584, 152064, bias=False)- norm:在所有解码器层之后,对最终隐藏态做一次全局归一化,保证输出分布稳定。
- lm_head:将 3584 维隐藏态映射到 152064 维词表,输出每个 token 的概率分布。无偏置设计进一步减少了参数量。
五、核心参数与设计意图总结
我们可以把 Qwen2.5-7B 的关键参数整理成表格:
| 关键参数 | 数值 | 设计意义 |
|---|---|---|
| 层数 | 28 | 平衡模型深度与计算效率 |
| 隐藏维度 | 3584 | 基础语义表达维度 |
| MLP 中间维度 | 18944 | 约 5.28 倍隐藏维度,提升非线性能力 |
| 词表大小 | 152064 | 覆盖多语言与丰富词汇 |
| 注意力机制 | GQA | 28 个 Q 头,4 个 K/V 头,节省显存 |
| 激活函数 | SiLU | 平滑非线性激活,训练更稳定 |
| 归一化 | RMSNorm | 高效稳定的归一化方式 |
| 位置编码 | RoPE | 无参数位置编码,支持长上下文 |
设计意图总结
- 高效推理:GQA + RMSNorm + 无偏置线性层,在保证性能的同时,显著降低显存占用和计算量,适合部署到消费级显卡。
- 强表达能力:28 层深度 + 5.28 倍中间维度 + 大词表,让模型具备理解复杂语义和生成高质量文本的能力。
- 训练稳定:RoPE 位置编码 + Pre-LN 归一化设计,让长文本训练更稳定,收敛更快。
六、结语
从 Qwen2.5-7B 的结构可以看出,现代大语言模型的设计已经高度工程化:在保证性能的前提下,通过 GQA、RMSNorm、无偏置线性层等技术,不断优化效率与部署成本。
如果你正在学习大模型微调或部署,读懂这些结构细节,能帮你更好地理解代码、排查问题,甚至根据业务需求定制模型结构。
延伸思考
- Qwen2.5-7B 的参数量具体是多少?可以通过各层维度手动计算验证。
- 对比 Llama 3-7B,两者在注意力机制、MLP 结构上有哪些差异?
- 如果要把 Qwen2.5-7B 部署到移动端,需要对哪些结构做优化?