Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

大家好呀,欢迎来到博主新开的《Effective Python 3rd Edition》学习笔记系列,毕竟也读过几百篇 SCI ,这次来试试阅读原版学习是一种怎样的体验。小伙伴们感兴趣的话,请一定要点赞,收藏加关注呀!
第二章 Strings and Slicing
Python 最初作为一种用于编排命令行实用程序和处理输入和输出数据的脚本语言而变得流行。凭借用于字符串和序列处理的内置语法、方法和模块,Python 成为传统 shell 和其他常见脚本语言(例如 Perl)的有力的替代品。 从那时起,Python 不断向邻近领域发展,成为解析文本、生成结构化数据、检查文件格式、分析日志等的理想编程语言。
通过使用 bytes 和 str 类型,Python 程序能够与人类语言文本进行交互、处理底层二进制数据格式、执行输入/输出(I/O)操作并与外部世界进行通信。Python 针对这些字符类型、列表以及其他类型进行了抽象处理,以提供一个通用的接口用于索引、序列化等操作。这些功能极为重要,几乎在所有程序中都能见到它们的踪影。
Item 10: 清楚 bytes 与 str 之间的区别
在 Python 中,有两种类型可以表示字符数据的序列:bytes 和 str。bytes 类型的实例包含未经处理、无符号的 8 位值(通常以 ASCII 编码形式显示):
a = b"h\x65llo"
print(type(a))
print(list(a))
print(a)
>>>
<class 'bytes'>
[104, 101, 108, 108, 111]
b'hello'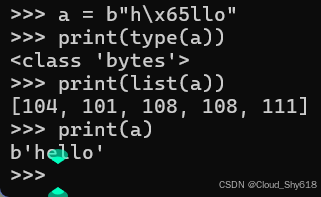
str 实例包含表示人类语言中文字字符的 Unicode 代码点:
a = "a\u0300 propos"
print(type(a))
print(list(a))
print(a)
>>>
<class 'str'>
['a', '`', ' ', 'p', 'r', 'o', 'p', 'o', 's']
à propos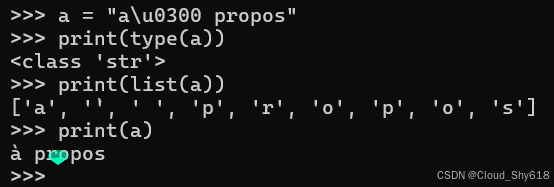
重要的是,一个 str 对象并不具有与之关联的二进制编码,而一个 bytes 对象则没有与之关联的文本编码。若要将 Unicode 数据转换为二进制数据,必须调用 str 对象的 encode 方法;若要将二进制数据转换为 Unicode 数据,则必须调用 bytes 对象的 decode 方法。你可以明确指定这些方法所采用的编码方式,或者接受系统默认的编码方式,后者通常是 UTF-8(但并非始终如此,这一点你稍后将看到)。
当你编写 Python 程序时,在接口的最远边界对 Unicode 数据进行编码和解码非常重要;这种方法通常称为 Unicode 三明治。 程序的核心应该使用 str 类型,它包含 Unicode 数据,并且不应该假设任何有关字符编码的信息。 此设置允许您非常接受替代文本编码(例如 Latin-1、Shift JIS 和 Big5),同时严格控制输出文本编码(理想情况下为 UTF-8)。
字符数据类型之间的差异在 Python 代码中会导致两种常见情况:
- 您希望对包含 UTF-8 编码字符串(或其他某种编码方式)的原始 8 位序列进行操作。
- 您希望对没有特定编码的 Unicode 字符串进行操作。
你通常需要两个辅助函数来在这些情况之间进行转换,并确保输入值的类型符合代码的预期。
第一个函数接受一个 bytes 或者 str 对象,并始终返回一个 str 对象:
def to_str(bytes_or_str):
if isinstance(bytes_or_str, bytes):
value = bytes_or_str.decode("utf-8")
else:
value = bytes_or_str
return value # Instance of str
print(repr(to_str(b"foo")))
print(repr(to_str("bar")))
>>>
'foo'
'bar'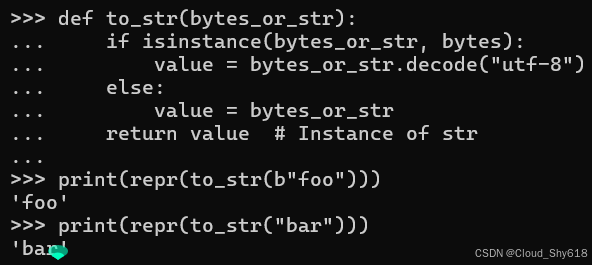
第二个函数接受一个 bytes 或者 str 对象,并始终返回一个 bytes 对象:
def to_bytes(bytes_or_str):
if isinstance(bytes_or_str, str):
value = bytes_or_str.encode("utf-8")
else:
value = bytes_or_str
return value # Instance of bytes
print(repr(to_bytes(b"foo")))
print(repr(to_bytes("bar")))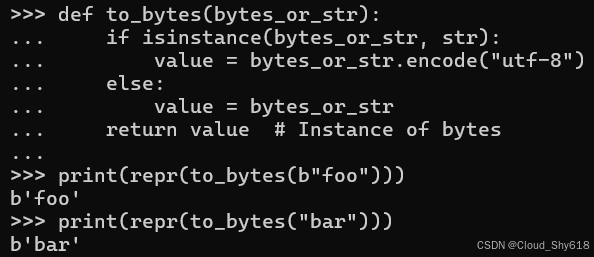
在处理 Python 中的原始 8 位值和 Unicode 字符串时,存在两大难点。
第一个问题是,bytes 和 str 似乎具有相同的处理方式,但它们的实例彼此间并不兼容,因此你必须谨慎对待所传递的字符序列的类型。通过使用 + 运算符,您可以分别将 bytes 添加到 bytes 和 str 中:
print(b"one"+b"two")
print("one"+"two")
>>>
b'onetwo'
onetwo但您无法将 str 实例添加到 bytes 实例中:
b"one"+"two"
>>>
Traceback ...
TypeError: can't concat str to bytes你也不能将 bytes 实例添加到 str 实例中:
"one"+b"two"
>>>
Traceback ...
TypeError: can only concatenate str (not "bytes") to str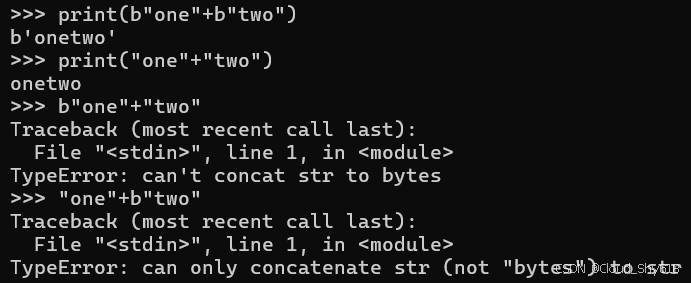
通过使用二进制运算符,您可以进行 bytes 与 bytes 的比较以及 str 与 str 的比较:
assert b"red" > b"blue"
assert "red" > "blue"但你不能将 str 对象与 bytes 对象进行比较:
assert "red" > b"blue"
>>>
Traceback ...
TypeError: '>' not supported between instances of 'str' and 'bytes'此外,你也不能将 bytes 对象与 str 对象进行比较:
assert b"blue" < "red"
>>>
Traceback ...
TypeError: '<' not supported between instances of 'bytes' and 'str'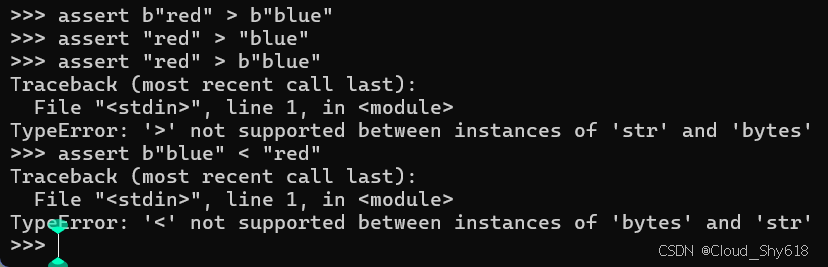
比较 bytes 和 str 对象以判断其是否相等时,结果始终为 False,即便它们所包含的字符完全相同(此处为 ASCII 编码的 "foo"):
print(b"foo" == "foo")
>>>
False
% 运算符适用于每种类型的格式化字符串(详情请参阅 Item 11:"优先使用内插式 F 字符串而非 C 风格格式化字符串和 str.format")
blue_bytes = b"blue"
blue_str = "blue"
print(b"red %s"%blue_bytes)
print("red %s"%blue_str)
>>>
b'red blue'
red blue但是你不能将 str 对象传递给 bytes 字符串,因为 Python 不知道要使用什么二进制文本编码:
print(b"red %s"%blue_str)
>>>
Traceback ...
TypeError: %b requires a bytes-like object, or an object that implements __bytes__, not 'str'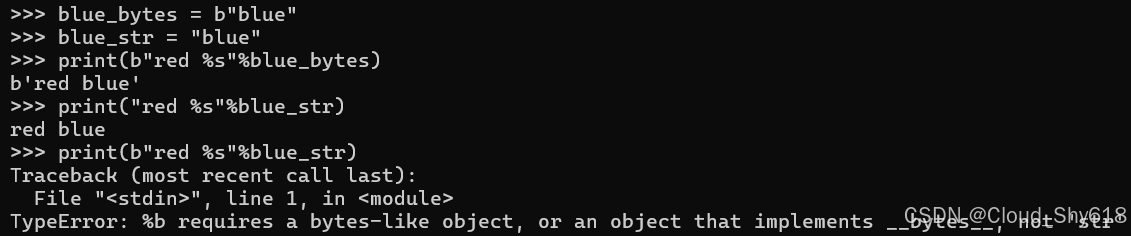
但是,您可以使用 % 运算符将 bytes 对象传递给 str 字符串,或者可以在插值格式字符串中使用 bytes对象,但它不会执行您期望的操作:
print("red %s"%blue_bytes)
print(f"red {blue_bytes}")
>>>
red b'blue'
red b'blue'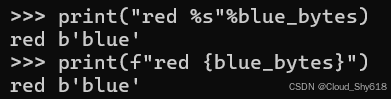
在这些情况下,代码实际上在 bytes 对象上调用 __repr__special 方法(请参阅 Item 12:"了解打印对象时 repr 和 str 之间的差异"),并用它代替 %s 或者 {blue_bytes},这就是 b"blue" 文字出现在输出中的原因。
第二个问题是涉及文件句柄(由 openbuilt-in 函数返回)的操作默认需要 Unicode 字符串而不是原始字节。 这可能会导致意想不到的失败,特别是对于习惯了 Python 2 的程序员来说。例如,假设我想将一些二进制数据写入文件。这个看似简单的代码报错了:
with open("data.bin", "w") as f:
f.write(b"\xf1\xf2\xf3\xf4\xf5")
>>>
Traceback ...
TypeError: write() argument must be str, not bytes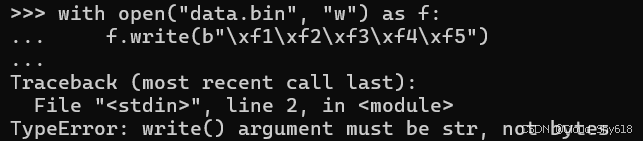
异常的原因是由于文件是以写入文本模式("w")而不是写入二进制模式("wb")打开的。 当文件处于文本模式时,写入操作期望包含 Unicode 数据的字符串,而不是包含二进制数据的字节实例。 在这里,我通过将打开模式更改为 "wb" 来解决此问题:
with open("data.bin", "wb") as f:
f.write(b"\xf1\xf2\xf3\xf4\xf5")
从文件读取数据也存在类似的问题。例如,这里我尝试读取上面编写的二进制文件:
with open("data.bin", "r") as f:
data = f.read()
>>>
Traceback ...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf1 in position 0: invalid continuation byte
提示:博主的命令行工具的默认编码格式为 'gbk',当表达的意思是一样的。
上面的报错是因为文件是以读取文本模式("r")而不是读取二进制模式("rb")打开的。 当句柄处于文本模式时,它使用系统默认的文本编码,使用 bytes.decode(用于读取)和 str.encode(用于写入)方法来解释二进制数据。在大多数系统上,默认编码是 UT F-8,它无法接受二进制数据 b"\xf1\xf2\xf3\xf4\xf5",从而导致上述错误。 这里,通过将打开模式更改为 "rb" 来解决这个问题:
with open("data.bin", "rb") as f:
data = f.read()
assert data == b"\xf1\xf2\xf3\xf4\xf5"或者,可以显式指定 open 函数的编码参数,以确保不会对任何特定于平台的行为感到意外。 例如,这里假设文件中的二进制数据实际上是编码为 "cp1252"(旧版 Windows 编码)的字符串:
with open("data.bin", "r", encoding="cp1252") as f:
data = f.read()
assert data == "ñòóôõ"异常消失了,文件内容的字符串解释与读取原始字节时返回的内容非常不同。 这里的教训是,您应该检查系统上的默认编码(使用 python3 -c 'import locale; print(locale.getpreferred-encoding())')以了解它与您的期望有何不同。 如有疑问,您应该显式传递编码参数以打开。
注意:
- bytes 包含 8 位值的序列,str 包含 Unicode 代码点的序列。
- 使用辅助函数确保您操作的输入是您期望的字符序列类型(8 位值、UTF-8 编码字符串、Unicode 代码点等)。
- bytes 和 str 不能与运算符(如 >、==、+ 和 %)一起使用。
- 如果要从文件读取或写入二进制数据,请始终使用二进制模式(如 "rb" 或 "wb")打开文件。
- 如果您想从文件中读取或写入 Unicode 数据,请注意系统的默认文本编码。 显式地将编码参数传递给 open 以避免出现意外。
Item 11: 与 C 样式格式字符串和 str.format 相比,更喜欢插值 F 字符串
字符串存在于整个 Python 代码库中。 它们用于在用户界面和命令行实用程序中呈现消息。 它们用于将数据写入文件和套接字。 它们用于指定 Exception details 中出了什么问题(请参阅 Item 88:"考虑显式链接异常以澄清回溯")。 它们用于日志记录和调试(请参阅 Item 12:"了解打印对象时 repr 和 str 之间的区别")。
格式化是将预定义文本与数据值组合成可读消息并存储为字符串的过程。 Python 有四种不同的格式化字符串的方法,这些方法内置于语言和标准库中。 除本项最后介绍的一项外,所有这些都有严重的缺点,您应该理解并避免这些缺点。
C-Style Formatting
在 Python 中格式化字符串的最常见方法是使用 % 格式化运算符。 运算符左侧以格式字符串形式提供了预定义的文本模板。 要插入到模板中的值作为单个值或格式运算符右侧的多个值的元组提供。 例如,这里使用 % 运算符将难以读取的二进制和十六进制值转换为整数字符串:
a = 0b10111011
b = 0xC5F
print("Binary is %d, hex is %d"%(a, b))
>>>
Binary is 187, hex is 3167
格式字符串使用格式说明符(如 %d)作为占位符,这些占位符将被格式化表达式右侧的值替换。 格式说明符的语法来自 C 的 printf 函数,它已被 Python(以及其他编程语言)继承。Python 支持 printf 所期望的所有常用选项,例如 %s、%x 和 %f 格式说明符,以及对小数位、padding、fill 和对齐的控制。 许多刚接触 Python 的程序员都从 C 风格的格式字符串开始,因为它们很熟悉并且易于使用。
Python 中的 C 风格格式字符串存在四个问题。
第一个问题是,如果更改格式化表达式右侧元组中数据值的类型或顺序,可能会由于类型转换不兼容而出现错误。 例如,这个简单的格式化表达式可以生效:
key = "my_var"
value = 1.234
formatted = "%-10s = %.2f"%(key, value)
print(formatted)
>>>
my_var = 1.23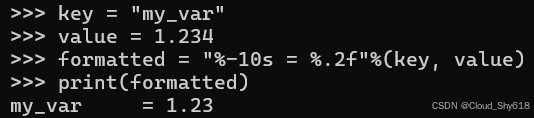
但是如果你交换键和值,你会在运行时得到一个异常:
reordered_tuple = "%-10s = %.2f"%(value, key)
>>>
Traceback ...
TypeError: must be real number, not str
保留右侧参数的原始顺序但更改格式字符串会导致相同的错误:
reordered_string = "%.2f = %-10s"%(key, value)
>>>
Traceback ...
TypeError: must be real number, not str
为了避免这个问题,您需要不断检查 % 运算符的两侧是否同步;这个过程很容易出错,因为每次更改都必须手动完成。
C 样式格式化表达式的第二个问题是,当您需要在将值格式化为字符串之前对值进行少量修改时,它们会变得难以阅读,而这是一种极其常见的需求。 在这里,我列出了厨房食品储藏室的内容,没有对值进行任何内联更改:
pantry = [
("avocados", 1.25),
("bananas", 2.5),
("cherries", 15),
]
for i, (item, count) in enumerate(pantry):
print("#%d: %-10s = %.2f"%(i, item, count))
>>>
#0: avocados = 1.25
#1: bananas = 2.50
#2: cherries = 15.00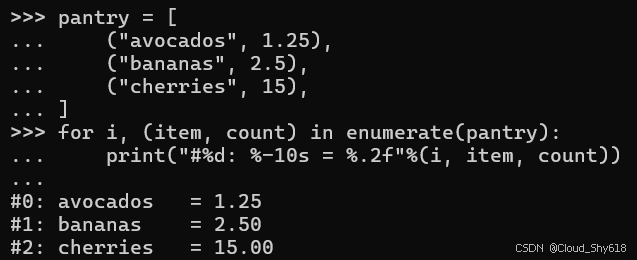
现在,我对正在格式化的值进行一些修改,以使打印的消息更有用。这会导致格式化表达式中的元组变得太长,以至于需要将其拆分为多行,但会损害可读性:
for i, (item, count) in enumerate(pantry):
print(
"#%d: %-10s = %d"
%(
i + 1,
item.title(),
round(count),
)
)
>>>
#1: Avocados = 1
#2: Bananas = 2
#3: Cherries = 15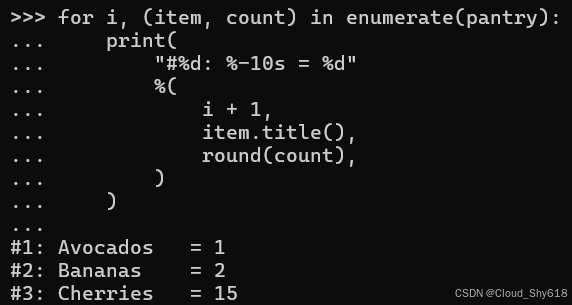
格式化表达式的第三个问题是,如果您想在格式字符串中多次使用相同的值,则必须在右侧元组中重复它:
template = "%s loves food. See %s cook."
name = "Max"
formatted = template %(name, name)
print(formatted)
>>>
Max loves food. See Max cook.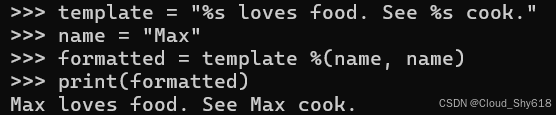
如果您必须对正在格式化的值进行重复的小修改,这尤其令人烦恼并且容易出错。 例如,这里我在一个对 name 的引用上调用 title() 方法,但不在另一个引用上调用,这会导致输出不匹配:
name = "brad"
formatted = template % (name.title(), name)
print(formatted)
>>>
Brad loves food. See brad cook.
Python 中的 % 运算符有助于解决其中一些问题,因为它还能够使用字典而不是元组进行格式化。字典中的键与具有相同名称的格式说明符匹配,例如 %(key)s。 在这里,我使用此功能来更改格式化表达式右侧的值的顺序,而不影响输出,从而解决上面的第 1 个问题:
key = "my_var"
value = 1.234
old_way = "%-10s = %.2f" % (key, value)
new_way = "%(key)-10s = %(value).2f" % {
"key": key, # Key first
"value": value,
}
reordered = "%(key)-10s = %(value).2f" % {
"value": value,
"key": key, # Key second
}
assert old_way == new_way == reordered在格式化表达式中使用字典还能解决上文提到的第 3 个问题,因为它允许多个格式指定符引用同一值,从而使得无需重复提供该值:
name = "Max"
template = "%s loves food. See %s cook."
before = template % (name, name) # Tuple
template = "%(name)s loves food. See %(name)s cook."
after = template % {"name": name} # Dictionary
assert before == after然而,字典格式字符串引入并加剧了其他问题。 对于上面的问题 2,关于在格式化值之前对值进行小的修改,由于右侧存在字典键和冒号运算符,格式化表达式变得更长并且视觉上更嘈杂。 在这里,我使用和不使用字典渲染相同的字符串来显示这个问题:
for i, (item, count) in enumerate(pantry):
before ="#%d: %-10s = %d" % (
i + 1,
item.title(),
round(count),
)
after = "#%(loop)d: %(item)-10s = %(count)d" % {
"loop": i +1,
"item": item.title(),
"count": round(count),
}
assert before == after在格式化表达式中使用字典也会增加冗余度,这是 Python 中 C 风格格式化表达式存在的第 4 个问题。每个键都必须至少被明确提及两次------一次在格式指定符中,一次作为字典中的键,还可能再次出现在包含字典值的变量名中:
soup = "lentil"
formatted = "Today's soup is %(soup)s." % {"soup": soup}
print(formatted)
>>>
Today's soup is lentil.
除了涉及重复字符外,这种冗余还会导致使用字典的格式化表达式变得冗长。这些表达式往往需要跨越多行,格式字符串需跨多行进行拼接,而字典赋值则需每行处理一个值以用于格式化:
menu = {
"soup": "lentil",
"oyster": "kumamoto",
"special": "schnitzel",
}
template = (
"Today's soup is %(soup)s, "
"buy one get two %(oyster)s oysters, "
"and our special entrée is %(special)s."
)
formatted = template % menu
print(formatted)
>>>
Today's soup is lentil, buy one get two kumamoto oysters, and our special entrée is schnitzel.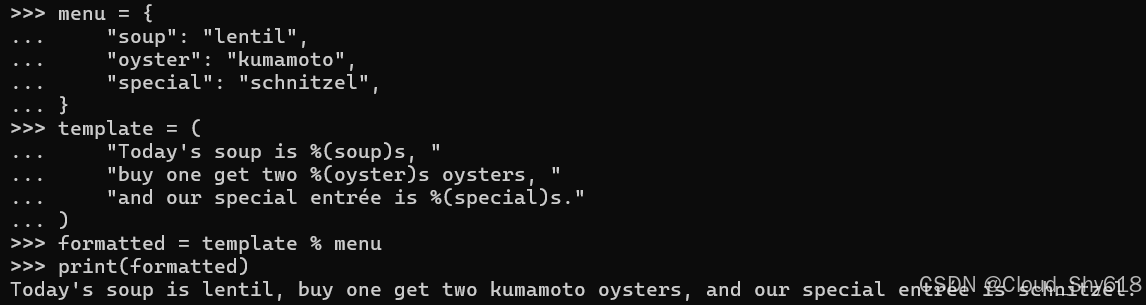
为了了解这种格式化表达式会产生什么结果,你的眼睛必须不断在格式化字符串的行与字典的行之间来回切换。这种割裂使得发现错误变得困难,而且如果需要在格式化前的任何值上进行微小修改,可读性也会进一步下降。肯定有更合适的方法。
format 内置函数和 str.format
Python 3 新增了对高级字符串格式化的支持,这种格式化方式比使用 % 运算符的旧 C 风格格式字符串更具表现力。对于单个 Python 值而言,可通过内置的 format() 函数来访问这一新功能。例如,在此示例中,我使用了部分新选项(, 用于千位分隔符和 ^ 用于居中)来格式化数值:
a = 1234.5678
formatted = format(a, ",.2f")
print(formatted)
b = "my string"
formatted = format(b, "^20s")
print("*", formatted, "*")
>>>
1,234.57
* my string *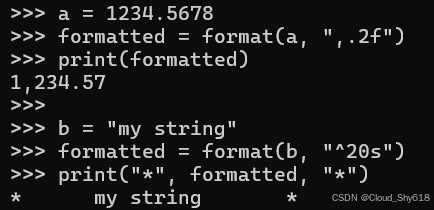
您可利用此功能通过调用 str 类型的新 format 方法来同时格式化多个值。与使用 C 风格的格式说明符(如 %d)不同,您可使用 {} 来指定占位符。默认情况下,格式字符串中的占位符将按照它们在 formatmethod 中出现的顺序被相应位置传递的参数所替换:
key = "my_var"
value = 1.234
formatted = "{} = {}".format(key, value)
print(formatted)
>>>
my_var = 1.234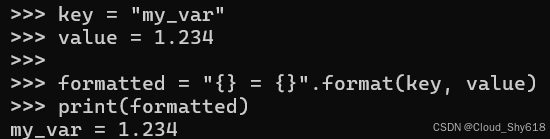
在每个占位符内,您可选择提供一个冒号字符,随后跟格式指定符,以自定义如何将数值转换为字符串的方式(完整的选项范围请参见 https://docs.python.org/3/library/string.html#format-specification-mini-language ):
formatted = "{:<10} = {:.2f}".format(key, value)
print(formatted)
>>>
my_var = 1.23
思考这一机制运作方式的方法是,格式指定符将与值一同被传递给内置的 format() 函数(如上述示例中的 format(value, ".2f"))。该函数调用的结果将取代整个格式化字符串中的占位符。你可以通过使用 __format__special 方法来根据具体类别对格式化行为进行定制。
在使用 str.format() 函数时还需注意另一个细节,即对花括号({})进行转义处理。你需要将花括号加倍处理({{)以避免它们被误认为是占位符(就像你需要在 C 风格的格式化字符串中加倍 % 字符以对其进行正确转义一样):
print("%.2f%%" % 12.5)
print("{} replaces {{}}".format(1.23))
>>>
12.50%
1.23 replaces {}
在括号内,你还可以指定传递给 format 方法的参数的位序索引,用于替换占位符。这样便能够对格式化字符串进行更新,以重新排列输出顺序,而无需你同时更改格式化表达式右侧的内容,从而解决了上文提到的第 1 个问题:
formatted = "{1} = {0}".format(key, value)
print(formatted)
>>>
1.234 = my_var
同一个位置索引还可能在格式字符串中被多次引用,而无需将值传递给格式化方法多次,这解决了上文提到的第 3 个问题:
formatted = "{0} loves food. See {0} cook.".format(name)
print(formatted)
>>>
Max loves food. See Max cook.
提示:博主先前在命令行中输入的 name 为 brad。
遗憾的是,这种新格式方法并未对解决上述第 2 个问题起到任何作用,导致你的代码在需要对值进行格式化前的微小修改时变得难以阅读。新旧方法在可读性方面几乎无甚差别,两者都同样显得杂乱无章:
for i, (item, count) in enumerate(pantry):
old_style = "#%d: %-10s = %d" % (
i + 1,
item.title(),
round(count),
)
new_style = "#{}: {:<10s} = {}".format(
i + 1,
item.title(),
round(count),
)
assert old_style == new_style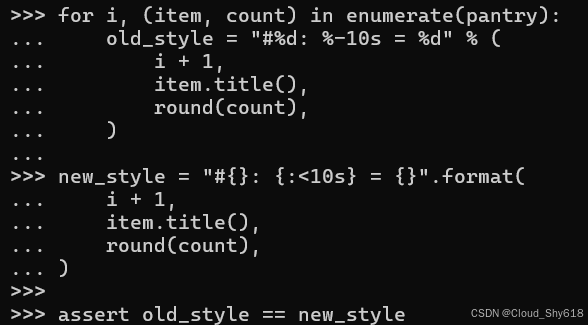
对于 str.format 方法,还有更为高级的指定选项可供选择,例如在占位符中使用字典键和列表索引的组合,以及将值强制转换为 Unicode 和 repr 字符串等:
formatted = "First letter is {menu[oyster][0]!r}".format(menu=menu)
print(formatted)
>>>
First letter is 'k'
但是,这些特性并不能帮助减少上面问题 4 中重复键的冗余。例如,这里我比较了在 C 风格格式化表达式中使用字典的冗余性与以新的方式将关键字参数传递到 format 方法的冗余性:
old_template = (
"Today's soup is %(soup)s, "
"buy one get two %(oyster)s oysters, "
"and our special entrée is %(special)s."
)
old_formatted = old_template % {
"soup": "lentil",
"oyster": "kumamoto",
"special": "schnitzel",
}
new_template = (
"Today's soup is {soup}, "
"buy one get two {oyster} oysters, "
"and our special entrée is {special}."
)
new_formatted = new_template.format(
soup = "lentil",
oyster = "kumamoto",
special = "schnitzel",
)
assert old_formatted == new_formatted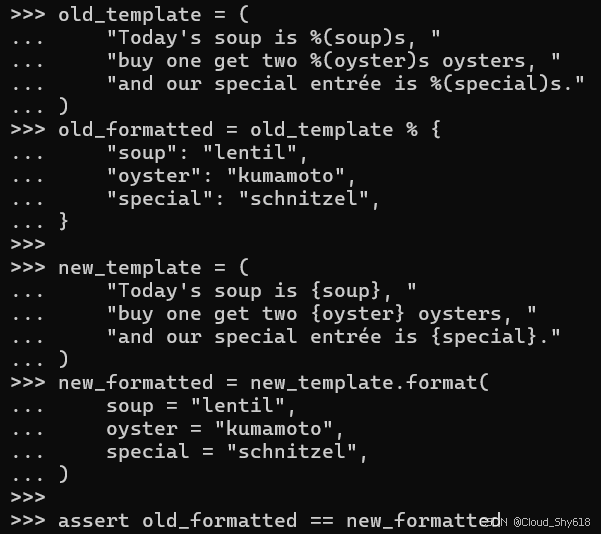
这种风格略微减少了噪声,因为它去除了字典中的一些引号和格式指定符中的少量字符。然而,它并不具备足够的吸引力。此外,在占位符内使用字典键和索引的先进功能只是 Python 表达式功能的一小部分。这种表达力的缺失非常局限,从根本上削弱了 str.format 方法的整体价值。
鉴于这些缺陷以及仍存在的 C 风格格式化表达式所引发的问题(以上第 2 和第 4 个问题),在此建议您总体上应避免使用 str.format 方法。了解格式说明符中采用的新微型语言(即冒号之后的全部内容)以及如何使用内置的 format 函数是十分重要的。但 str.format 方法的其他部分应被视为一种历史遗留产物,它有助于您理解 Python 的新 f-string 机制以及它们为何如此强大。
插值格式字符串
Python 3.6 新增了内插式格式字符串------简称 f-strings------用以一劳永逸地解决上述问题。这种新的语言语法要求你在格式字符串前加上一个 f 字符,这与字节字符串以 b 字符开头、原始(未转义)字符串以 r 字符开头的方式类似。
F-strings 将格式化字符串的表达能力发挥到了极致,通过彻底消除提供需格式化键值时的冗余性,解决了上文提到的第 4 个问题。它们通过允许你以格式化表达式的一部分形式引用当前 Python 作用域中的所有名称,来实现这种简洁性:
key = "my_var"
value = 1.234
formatted = f"{key} = {value}"
print(formatted)
>>>
my_var = 1.234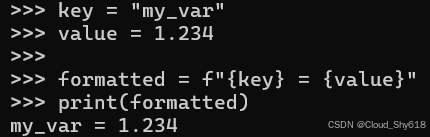
与新版格式中内置的微型语言相关的所有选项均可在 f 字符串内的占位符中以冒号后为选项提供,同时还可像 str.format 方法(即使用 !r 和 !s)那样强制将值转换为 Unicode 格式和 repr 字符串:
formatted = f"{key!r:<10} = {value:.2f}"
print(formatted)
>>>
'my_var' = 1.23
在所有情况下,使用 f 字符串进行格式化比使用带有 % 运算符和 str.format 方法的 C 样式格式字符串要短。 在这里,按照从最短到最长的顺序一起显示每个选项,并将赋值的左侧对齐,以便您可以轻松比较它们:
f_string = f"{key:<10} = {value:.2f}"
c_tuple = "%-10s = %.2f"%(key, value)
str_args = "{:<10} = {:.2f}".format(key, value)
str_kw = "{key:<10} = {value:.2f}".format(key=key, value=value)
c_dict = "%(key)-10s = %(value).2f" % {"key": key, "value": value}
assert c_tuple == c_dict == f_string
assert str_args == str_kw == f_string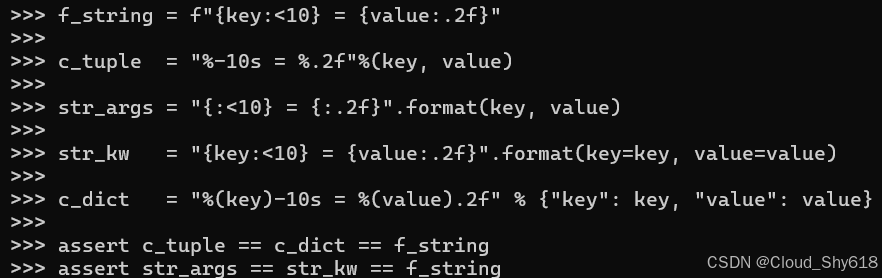
F-strings 还使您能够将完整的 Python 表达式放在占位符大括号内,通过允许对使用简洁语法格式化的值进行小修改来解决上面的问题 2。 使用 C 样式格式和 str.format 方法需要多行的内容现在可以轻松地放在一行中:
for i, (item, count) in enumerate(pantry):
old_style = "#%d: %-10s = %d" % (
i + 1,
item.title(),
round(count),
)
new_style = "#{}: {:<10s} = {}".format(
i + 1,
item.title(),
round(count),
)
f_string = f"#{i+1}: {item.title():<10s} = {round(count)}"
assert old_style == new_style == f_string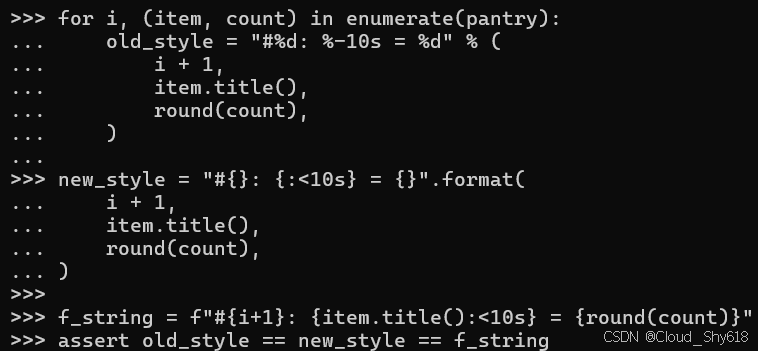
或者,如果想要更清楚的话,您可以通过依赖相邻字符串串联将 f 字符串拆分为多行(请参阅 Item 13:"优先选择显式字符串连接而不是隐式字符串连接,尤其是在列表中")。 尽管这比单行版本更长,但它仍然比任何其他多行方法更清晰:
for i, (item, count) in enumerate(pantry):
print(f"#{i+1}: "
f"{item.title():<10s} = "
f"{round(count)}")
>>>
#1: Avocados = 1
#2: Bananas = 2
#3: Cherries = 15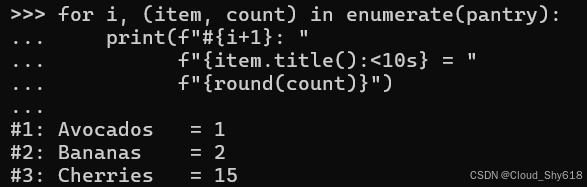
Python 表达式也可能出现在格式说明符选项中。 例如,在这里通过使用变量来参数化要打印的位数,而不是在格式字符串中对其进行硬编码:
places = 3
number = 1.23456
print(f"My number is {number:.{places}f}")
>>>
My number is 1.235
f-strings 提供的表现力、简洁性和清晰度的结合使它们成为 Python 程序员的最佳内置选项 。 每当您发现自己需要将值格式化为字符串时,请选择 f 字符串而不是其他替代方案。
注意:
- 使用 % 运算符的 C 风格格式字符串会遇到各种陷阱和冗长问题。
- str.format 方法在其格式说明符迷你语言中引入了一些有用的概念,但它在其他方面重复了 C 样式格式字符串的错误,应该避免。
- F-strings 是一种用于将值格式化为字符串的新语法,它解决了 C 样式格式字符串的最大问题。
- F-strings 简洁而强大,因为它们允许将任意 Python 表达式直接嵌入到格式说明符中。
Item 12: 了解打印对象时 repr 和 str 之间的区别
当您调试 Python 程序时,使用 print 函数和格式字符串(请参阅 Item 11:"与 C 样式格式字符串和 str.format 相比,更喜欢插值 F 字符串")或通过 logging 内置模块输出将让您取得意外的进展。 Python 对象内部通常可以通过普通属性轻松访问(请参阅 Item 55:"优先选择公共属性而不是私有属性")。 您需要做的就是调用 print 来查看程序运行时的状态如何变化,并推断出哪里出错了(有关更高级的方法,请参阅 Item 114:"考虑使用 pdb 进行交互式调试")。
print 函数能够输出您提供的任何可读内容的字符串版本。 例如,我可以使用带有基本字符串的 print 来查看字符串的内容,而无需周围的引号字符:
print("foo bar")
>>>
foo bar这相当于以下所有这些替代方案:
Calling the strfunction before passing the value to print
Using the "%s"format string with the %operator
Using the default formatting of the value with an f-string
Calling the formatbuilt-in function
Explicitly calling the __format__special method
Explicitly calling the __str__special method
在下面,展示出它们都产生了相同的输出:
my_value = "foo bar"
print(str(my_value))
print("%s" % my_value)
print(f"{my_value}")
print(format(my_value))
print(my_value.__format__("s"))
print(my_value.__str__())
>>>
foo bar
foo bar
foo bar
foo bar
foo bar
foo bar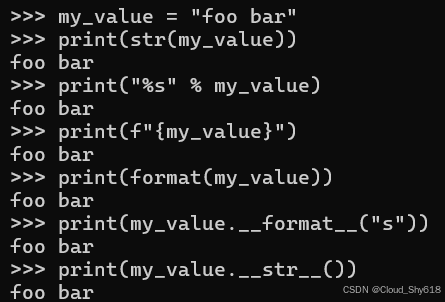
问题在于,人类可读的值字符串并不能明确该值的实际类型和具体组成。 例如,请注意 print 的默认输出中您无法区分数字 5 和字符串 "5" 的类型:
int_value = 5
str_value = "5"
print(int_value)
print(str_value)
print(f"Is {int_value} == {str_value}?")
>>>
5
5
Is 5 == 5?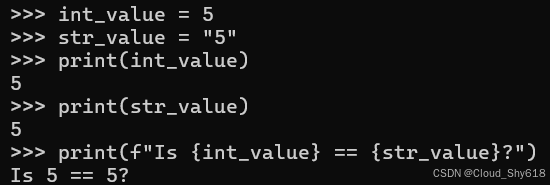
如果您正在使用 print 调试程序,这些类型差异很重要。调试时您几乎总是希望看到对象的再现。 repr 内置函数能够返回对象的可打印表示形式,这应该是最容易理解的字符串序列化。 对于许多内置类型,repr 返回的字符串是一个有效的 Python 表达式:
a = "\x07"
print(repr(a))
>>>
'\x07'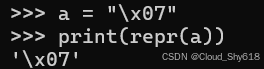
将 repr 返回的值传递给 eval 内置函数通常会生成与开始时相同的 Python 对象:
b = eval(repr(a))
assert a == b当然,在实际中,您应该极其谨慎地使用 eval(请参阅 Item 91:"除非您正在构建开发工具,否则请避免使用 exec 和 eval")。当您使用 print 进行调试时,您应该在打印之前在某个值上调用 repr 以确保类型中的任何差异都清晰可见:
print(repr(int_value))
print(repr(str_value))
>>>
5
'5'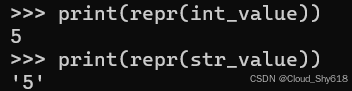
这相当于使用带有 % 运算符的 "%r" 格式字符串或带有 !r 类型转换的 f-string:
print("Is %r == %r?" % (int_value, str_value))
print(f"Is {int_value!r} == {str_value!r}?")
>>>
Is 5 == '5'?
Is 5 == '5'?
当给 str 内置函数一个用户定义类的实例时,它首先尝试调用 __str__special 方法。 如果未定义,则会调用 __repr__special 方法。 如果 __repr__ 也没有被类实现,那么调用将通过方法解析(参见 Item 53:"用 super 初始化父类"),最终从对象父类调用默认实现。 不幸的是,对象子类的 repr 的默认实现并不是特别有用。 例如,这里我定义了一个简单的类,然后打印它的一个实例,这最终导致对 object.__repr__ 的调用:
class OpaqueClass:
def __init__(self, x, y):
self.x = x
self.y = y
obj = OpaqueClass(1, "foo")
print(obj)
>>>
<__main__.OpaqueClass object at 0x1009be510>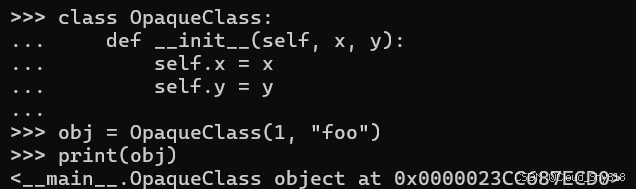
此输出无法传递给 eval 函数,并且它没有说明对象的实例字段。为了改进这一点,我在这里定义了自己的 __repr__ 特殊方法,该方法返回一个包含重新创建对象的 Python 表达式的字符串(请参阅 Item 51:"定义轻量级类的首选数据类",了解定义 __repr__ 的另一种方法):
class BetterClass:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"BetterClass({self.x!r}, {self.y!r})"现在 repr 的值更加有用:
obj = BetterClass(2, "bar")
print(obj)
>>>
BetterClass(2, 'bar')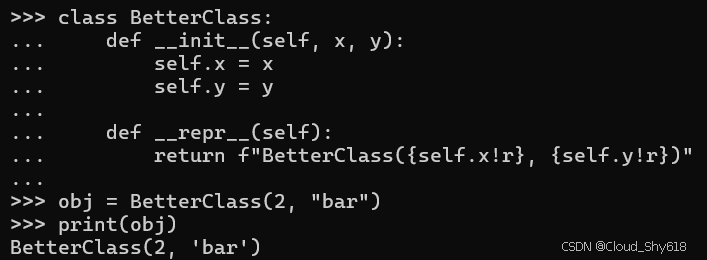
在此类的实例上调用 str 会产生相同的结果,因为未定义 __str__ 特殊方法,导致 Python 回退到 __repr__:
print(str(obj))
>>>
BetterClass(2, 'bar')要让 str 打印输出不同的人类可读格式的字符串(例如,显示在 UI 元素中),我可以定义相应的 __str__special 方法:
class StringifiableBetterClass(BetterClass):
def __str__(self):
return f"({self.x}, {self.y})"现在 repr 和 str 针对每个不同的目的返回不同的可读字符串:
obj2 = StringifiableBetterClass(2, "bar")
print("Human readable:", obj2)
print("Printable: ", repr(obj2))
>>>
Human readable: (2, bar)
Printable: BetterClass(2, 'bar')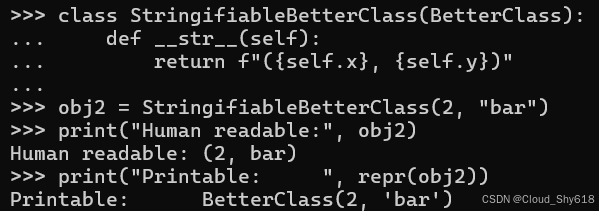
注意:
- 在内置 Python 类型上调用 print 会生成人类可读的字符串版本的值,该版本会隐藏类型信息。
- 在内置 Python 类型上调用 repr 会生成一个包含值的可打印表示形式的字符串。 repr 字符串通常可以传递给 eval内置函数来获取原始值。
- 在格式字符串中 %s 能生成人类可读的字符串,如 str %r 生成可打印的字符串,如 repr。 F-string 会为替换文本表达式生成人类可读的字符串,除非您指定 !r 转换后缀。
- 您可以在类上定义
__repr__和__str__特殊方法来自定义实例的可打印和人类可读的表示形式,这可以帮助调试并简化将对象集成到人机界面中的过程。