目录
[十二、推荐写法 @ 运算符](#十二、推荐写法 @ 运算符)
一、前言
如果说机器学习领域有一个最重要的数学运算,那么答案大概率是:
矩阵点积(Dot Product)无论是:
线性回归
逻辑回归
PCA
神经网络
Transformer
卷积神经网络其底层都离不开矩阵点积。
甚至可以说:
整个深度学习,本质上就是大量矩阵点积的组合。
因此,理解矩阵点积是学习机器学习和深度学习的重要基础。
二、什么是点积
在线性代数中:
两个向量可以进行一种特殊运算:
点积
Dot Product例如:
向量A:
[1,2,3]向量B:
[4,5,6]点积定义:
A·B
=
1×4
+
2×5
+
3×6结果:
=
4
+
10
+
18
=
32因此:
[1,2,3]
·
[4,5,6]
=
32三、点积的几何意义
点积不仅仅是数字运算。
它还表示:
两个向量之间的相似程度公式:
A·B
=
|A|
×
|B|
×
cosθ其中:
θ
表示两个向量夹角当:
θ = 0°则:
cosθ = 1点积最大。
说明:
两个向量方向完全一致当:
θ = 90°则:
cosθ = 0点积为0。
说明:
两个向量垂直这也是:
推荐系统
文本相似度
向量检索大量使用点积的原因。
四、矩阵点积是什么
向量点积可以扩展到矩阵。
例如:
矩阵A:
[
[1 2]
[3 4]
]矩阵B:
[
[5 6]
[7 8]
]矩阵乘法:
A × B并不是:
对应位置相乘而是:
行 × 列进行点积。
五、矩阵乘法规则
矩阵:
(m,n)可以乘:
(n,k)结果:
(m,k)即:
前一个矩阵列数
=
后一个矩阵行数否则无法计算。
例如:
(2,3)
×
(3,4)合法。
结果:
(2,4)例如:
(2,3)
×
(2,4)非法。
因为:
3 ≠ 2六、矩阵点积计算过程
矩阵A:
[
[1 2]
[3 4]
]矩阵B:
[
[5 6]
[7 8]
]计算:
第一行第一列:
1×5 + 2×7
=
19第一行第二列:
1×6 + 2×8
=
22第二行第一列:
3×5 + 4×7
=
43第二行第二列:
3×6 + 4×8
=
50最终:
[
[19 22]
[43 50]
]七、矩阵点积流程图
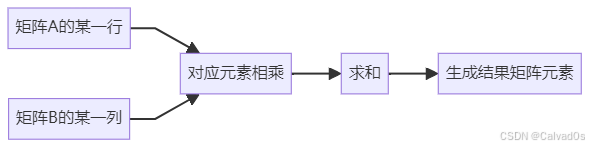
八、使用Python手写点积
先实现向量点积。
python
a = [1,2,3]
b = [4,5,6]
result = 0
for i in range(len(a)):
result += a[i] * b[i]
print(result)输出:
32九、手写矩阵乘法
python
A = [
[1,2],
[3,4]
]
B = [
[5,6],
[7,8]
]
result = [
[0,0],
[0,0]
]
for i in range(len(A)):
for j in range(len(B[0])):
for k in range(len(B)):
result[i][j] += (
A[i][k] * B[k][j]
)
print(result)输出:
[
[19,22],
[43,50]
]十、NumPy中的dot
NumPy提供:
np.dot()实现点积。
示例:
python
import numpy as np
a = np.array([
1,
2,
3
])
b = np.array([
4,
5,
6
])
print(
np.dot(a,b)
)输出:
32十一、矩阵点积
python
import numpy as np
A = np.array([
[1,2],
[3,4]
])
B = np.array([
[5,6],
[7,8]
])
print(
np.dot(A,B)
)输出:
[
[19 22]
[43 50]
]十二、推荐写法 @ 运算符
Python 3.5以后:
支持:
@作为矩阵乘法符号。
python
import numpy as np
A = np.array([
[1,2],
[3,4]
])
B = np.array([
[5,6],
[7,8]
])
print(A @ B)输出:
[
[19 22]
[43 50]
]这是目前最推荐的写法。
十三、dot与*的区别
很多新手容易混淆:
A * B和:
A @ B假设:
python
A = np.array([
[1,2],
[3,4]
])
B = np.array([
[5,6],
[7,8]
])元素乘法:
A * B结果:
[
[5 12]
[21 32]
]矩阵乘法:
A @ B结果:
[
[19 22]
[43 50]
]区别非常大。
十四、机器学习中的应用
线性回归公式:
y = Wx + b实际上:
W 与 x 的点积NumPy实现:
python
import numpy as np
W = np.array([
0.5,
1.2,
0.8
])
X = np.array([
100,
80,
60
])
b = 10
y = np.dot(W,X) + b
print(y)十五、神经网络中的应用
一个神经元:
z
=
W·X
+
b然后:
激活函数例如:
ReLU
Sigmoid
Tanh整个神经网络:
本质上就是:
矩阵点积
+
非线性函数不断重复。
十六、批量数据点积
假设:
X.shape
(1000,784)表示:
1000张图片
每张784个特征权重:
W.shape
(784,128)计算:
Z = X @ W结果:
(1000,128)一次完成:
1000个样本
128个神经元的计算。
十七、性能对比
普通Python循环:
for ...复杂度高。
NumPy:
A @ B底层调用:
BLAS
OpenBLAS
MKL高性能数学库。
速度通常提升:
几十倍
甚至上百倍十八、矩阵点积与深度学习
现代深度学习训练过程中:
GPU大部分时间都在执行:
矩阵乘法例如:
CNN
Transformer
BERT
GPT本质都是:
超大规模矩阵点积因此:
GPU算力
≈
矩阵乘法能力十九、点积与余弦相似度
推荐系统经常使用:
Cosine Similarity公式:
cosθ
=
A·B
/
(|A| × |B|)NumPy实现:
python
import numpy as np
A = np.array([1,2,3])
B = np.array([4,5,6])
similarity = (
np.dot(A,B)
/
(
np.linalg.norm(A)
*
np.linalg.norm(B)
)
)
print(similarity)输出:
0.9746说明:
两个向量非常相似二十、总结
矩阵点积是机器学习和深度学习最重要的基础运算之一。
核心思想:
行与列做点积数学规则:
(m,n)
×
(n,k)
=
(m,k)NumPy常用实现:
np.dot(A,B)或者:
A @ B应用场景:
线性回归
逻辑回归
PCA
神经网络
Transformer
推荐系统可以这样理解:
机器学习中的"学习"
本质是在不断调整权重矩阵
而模型的预测过程
本质就是矩阵点积掌握矩阵点积之后,你就真正迈进了机器学习和深度学习的大门。