一、问题背景
在机器学习中,训练完一个模型(如正则化线性回归)后,常常会遇到:
预测误差很大,模型效果不佳。
此时的核心问题不是模型不行,而是需要判断模型属于高偏差(欠拟合) 还是高方差(过拟合)。只有诊断正确,才能采取有效的优化策略。
二、核心模型回顾
本文以正则化线性回归为例,其损失函数为:
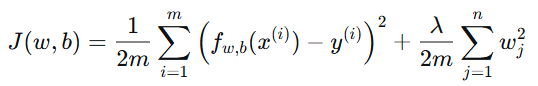
其中:
-
第一项为训练误差,衡量模型对数据的拟合能力;
-
第二项为正则化项,用于控制模型复杂度;
-
λ 为正则化强度系数。
三、偏差与方差的定义
1. 高偏差(High Bias)------ 欠拟合
-
表现:训练误差高,测试误差也高。
-
原因:模型过于简单,无法捕捉数据中的规律。
-
示例:用一条直线拟合明显呈曲线分布的数据。
2. 高方差(High Variance)------ 过拟合
-
表现:训练误差很低,但测试误差很高。
-
原因:模型过于复杂,将数据中的噪声也学习进来。
-
示例:使用高次多项式拟合,拟合曲线剧烈震荡。
四、调试策略总览
| 问题类型 | 解决方法 |
|---|---|
| 高偏差 | 增加特征、添加多项式特征、减小正则化参数 λ |
| 高方差 | 增加训练样本、减少特征数量、增大正则化参数 λ |
五、策略详解
高偏差(欠拟合)的应对方法
-
增加特征
通过特征工程引入更多有效特征。例如,在房价预测中,除了面积,增加房间数、地段、楼层等特征。
-
添加多项式特征
引入特征的高次项或交互项,使模型能够拟合非线性关系。
例如:从 x 扩展到
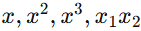 。
。 -
减小正则化参数 λ
λ 越大,模型越简单;λ 越小,模型越灵活。高偏差时适当减小 λ,释放模型表达能力。
高方差(过拟合)的应对方法
-
增加训练数据
更多数据有助于模型学习真实规律,减少对噪声的过拟合。这是缓解高方差最有效的手段之一。
-
减少特征数量
去除冗余或不相关的特征,降低模型复杂度。常用方法包括特征选择或 PCA 降维。
-
增大正则化参数 λ
增大 λλ 会加强对模型权重的惩罚,抑制模型过于复杂,从而减少过拟合。
六、核心直觉总结
-
模型太笨(高偏差) :需要提升模型复杂度
→ 增加特征 / 添加多项式 / 减小 λ
-
模型太聪明(高方差) :需要限制模型复杂度
→ 增加数据 / 减少特征 / 增大 λ
七、实际调参流程
当模型效果不理想时,建议按以下步骤进行:
-
绘制学习曲线,观察训练误差与验证误差的变化趋势;
-
根据误差表现判断当前模型处于高偏差还是高方差状态;
-
按照对应策略进行模型调整:
-
高偏差 → 提升模型复杂度(增加特征、多项式、减小 λ)
-
高方差 → 降低模型复杂度(增加数据、减少特征、增大 λ)
-
八、总结
-
核心原则:高偏差需要提升模型复杂度,高方差需要降低模型复杂度。
-
高偏差应对方法:增加特征、添加多项式、减小 λ
-
高方差应对方法:增加数据、减少特征、增大 λ