开篇介绍:
hello 大家,我们又又见面啦,哈哈,那么在前面的博客中,我们了解了Linux系统的基础指令,权限的知识,那么我们接下来肯定就要开始着手于使用Linux系统干一些活了,比如写代码,哈哈哈,这谁不期待,谁不想,而想要在Linux系统终端里面直接写代码,就需要基础开发工具的帮助,最经典最好的就是vim,当然,我们不止介绍vim,还有其他的一些我也都会进行介绍。
所以话不多说,我们出发出发。
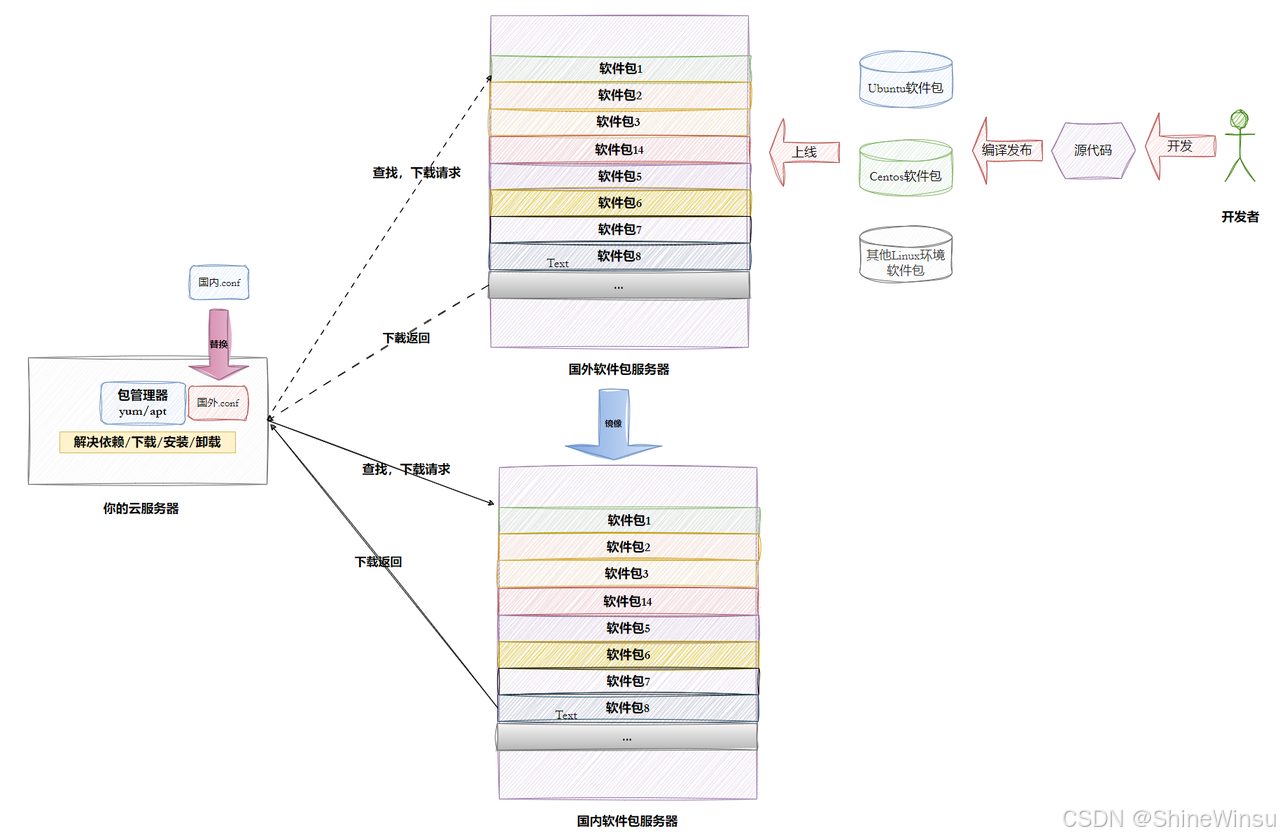
软件包管理器:
什么是软件包:
1. 软件包的定义
在 Linux 系统中,软件包是将常用软件提前编译好的可安装程序集合,类似 Windows 系统中的安装程序,可通过包管理器便捷获取和安装,避免了用户自行下载源代码编译的繁琐过程。
2. 软件包与包管理器的关系
软件包和包管理器的关系,如同 "App" 和 "应用商店" 的关系。包管理器负责从服务器获取、管理软件包的下载、安装、升级和卸载等操作。
3. 常见的 Linux 包管理器及适用发行版
- yum(Yellow dog Updater, Modified):是 Linux 下非常常用的包管理器,主要应用在 Fedora、RedHat、Centos 等发行版上,可自动解决软件依赖关系,方便用户管理软件包。
- apt(Advanced Package Tool):是 Ubuntu 发行版主要使用的包管理器,具备自动解决依赖关系、下载和安装软件包的功能,为 Ubuntu 用户提供了便捷的软件管理方式。
apt具体操作
因为我这个是使用的Ubantu的系统,所以我是用apt软件包管理器,但是呢,对于apt和yum,其实使用它们的指令是差不多的,所以大家也可以类比,我在这里介绍的是apt的一些相关指令。
查看软件包:
1. 命令格式与作用
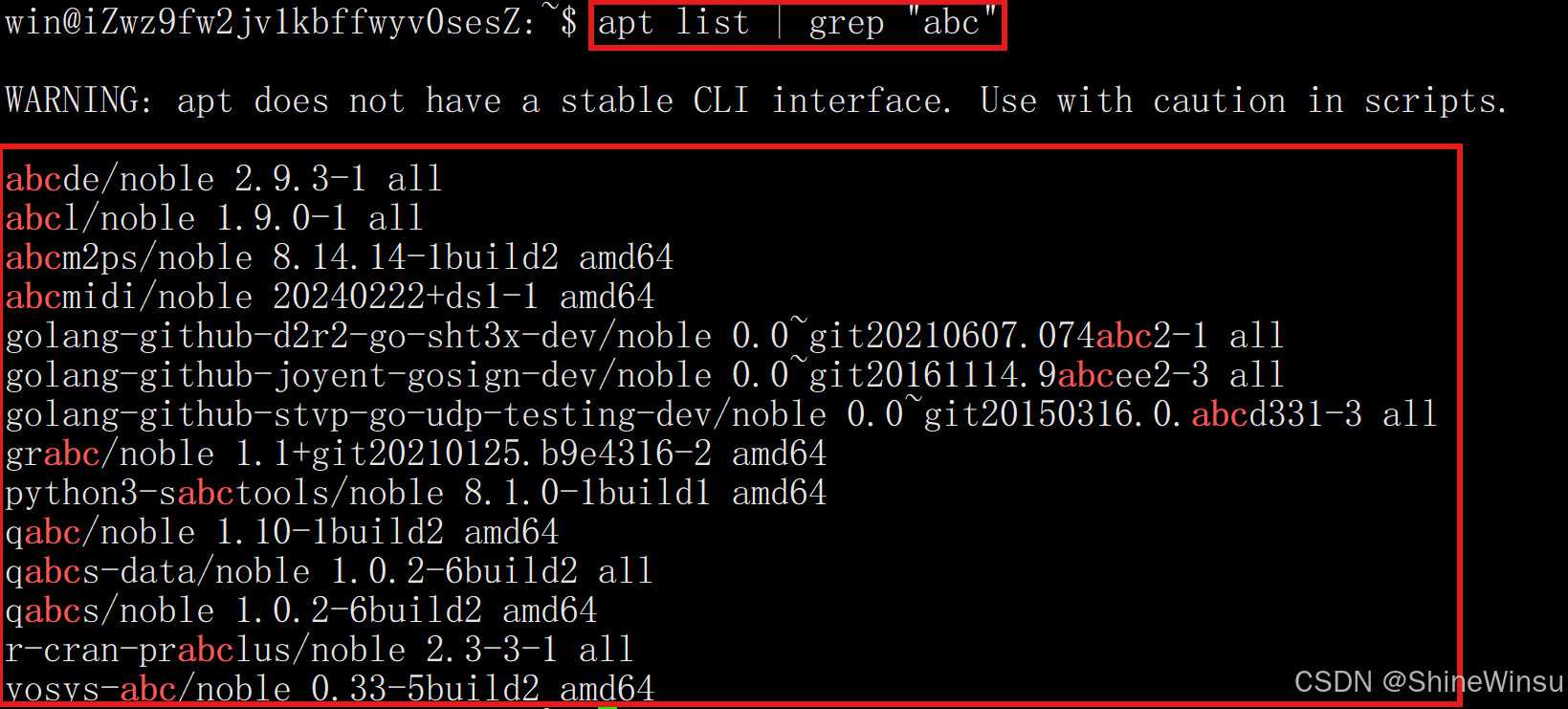
apt list:用于列出系统中已安装、可安装以及已过期的软件包,若不结合筛选,输出会非常冗长。
bash
apt list由于直接apt list内容非常庞大,而且我们还得去海底捞针般的查找我们想要的软件包,未免太过于麻烦,所以,我们就得依靠我们前面讲的grep指令去筛选含有我们指定字符的软件包
grep:是文本筛选工具,可根据指定关键词从apt list的输出中过滤出我们关注的软件包信息。
那么具体怎么用的,因为我们既需要apt list指令,但是同时又要grep指令,所以很明显,我们要使用管道|去把这两个命令结合起来,我们可以这么想,我们要先获取apt list指令的内容,然后呢,再用grep去把这些内容筛选一下,所以就得是
bash
apt list | grep "指定字符"这个应该很好理解。
2. 具体示例
示例 1:列出所有已安装的软件包
apt list --installed- 作用:罗列出系统中所有已经安装的软件包,包含软件包名称、版本、状态等信息。
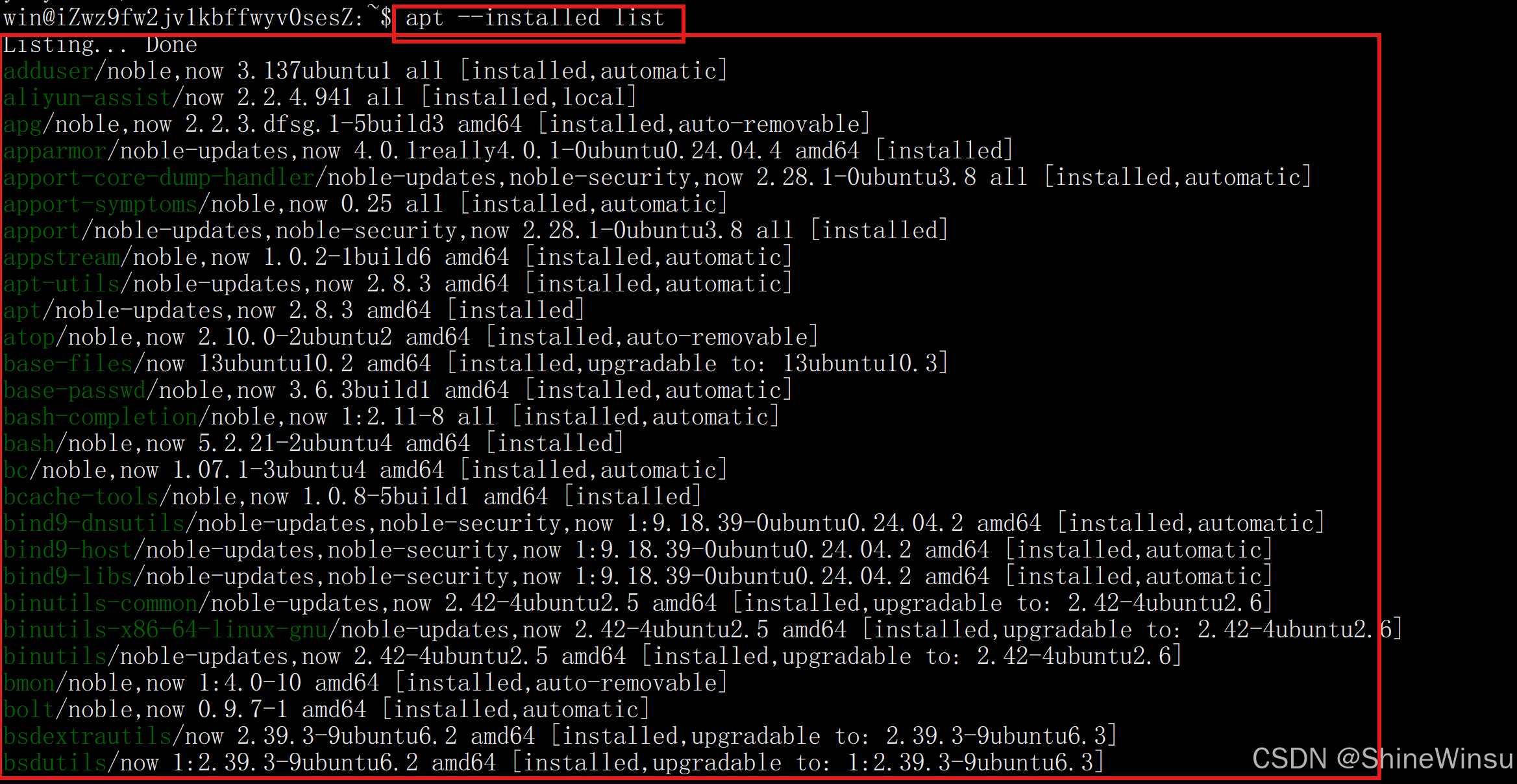
这里的--是长选项的意思。
示例 2:筛选包含 "nginx" 关键词的软件包
apt list | grep nginx- 作用:从
apt list的所有输出中,筛选出名称包含 "nginx" 的软件包,可快速查找与 Nginx 相关的软件包(如 Nginx 服务器本身、相关依赖包等)。
示例 3:筛选已安装且包含 "python" 的软件包
apt list --installed | grep python- 作用:先通过
--installed限定只列出已安装的软件包,再用grep python筛选出名称包含 "python" 的已安装软件包,方便查看系统中已安装的 Python 相关组件。
示例 4:筛选可安装的 "git" 相关软件包
apt list | grep git | grep -v installed- 作用:先筛选出包含 "git" 的软件包,再通过
grep -v installed排除已安装的,最终得到可安装的 Git 相关软件包,便于用户了解有哪些 Git 相关软件可安装。
表示含义:
我随便给大家一段,大家按照下面给的内容进行分析:
1. 软件包名称格式(apt 适配版)
Ubuntu 中 apt 管理的软件包名称格式简化为:主版本号。次版本号。源程序发行号 - 软件包发行号。架构(注:apt 包格式无需单独标注 "主机平台",架构信息直接体现适配性)
2. 架构标识与系统匹配
- amd64 后缀:对应 64 位 Ubuntu 系统,是当前主流架构(等同于 CentOS/RedHat 的 x86_64)。
- i386 后缀:对应 32 位 Ubuntu 系统,仅适用于老旧硬件或特殊需求场景。
- 核心原则:必须选择与当前 Ubuntu 系统位数一致的软件包,否则无法安装或运行异常。
3. 发行版版本标识
Ubuntu 软件包中通过版本号隐含系统适配性,常见标识规则:
- 包名中含 "bionic" 对应 Ubuntu 18.04 LTS。
- 含 "focal" 对应 Ubuntu 20.04 LTS。
- 含 "jammy" 对应 Ubuntu 22.04 LTS。
- 选择时需确认包的适配版本与当前 Ubuntu 系统版本一致,避免兼容性问题。
4. 软件源概念
最后一列显示的 "软件源" 名称(如 main、universe、multiverse、restricted),等同于 "应用商店" 的概念:
- main:官方支持的开源软件源,稳定性和安全性最高。
- universe:社区维护的开源软件源,软件数量更丰富。
- restricted:官方支持的非开源软件(如硬件驱动)。
- multiverse:非开源且无官方支持的软件,需谨慎使用。
这个大家不怎么需要了解,至少目前我们不怎么需要。
安装软件:
在 Ubuntu 中使用apt安装软件包的方法总结如下:
-
执行安装命令 :通过
apt install -y 软件包名称安装指定软件,例如安装lrzsz:bashapt install -y lrzsz(
-y参数可自动确认安装,无需手动输入 "y")
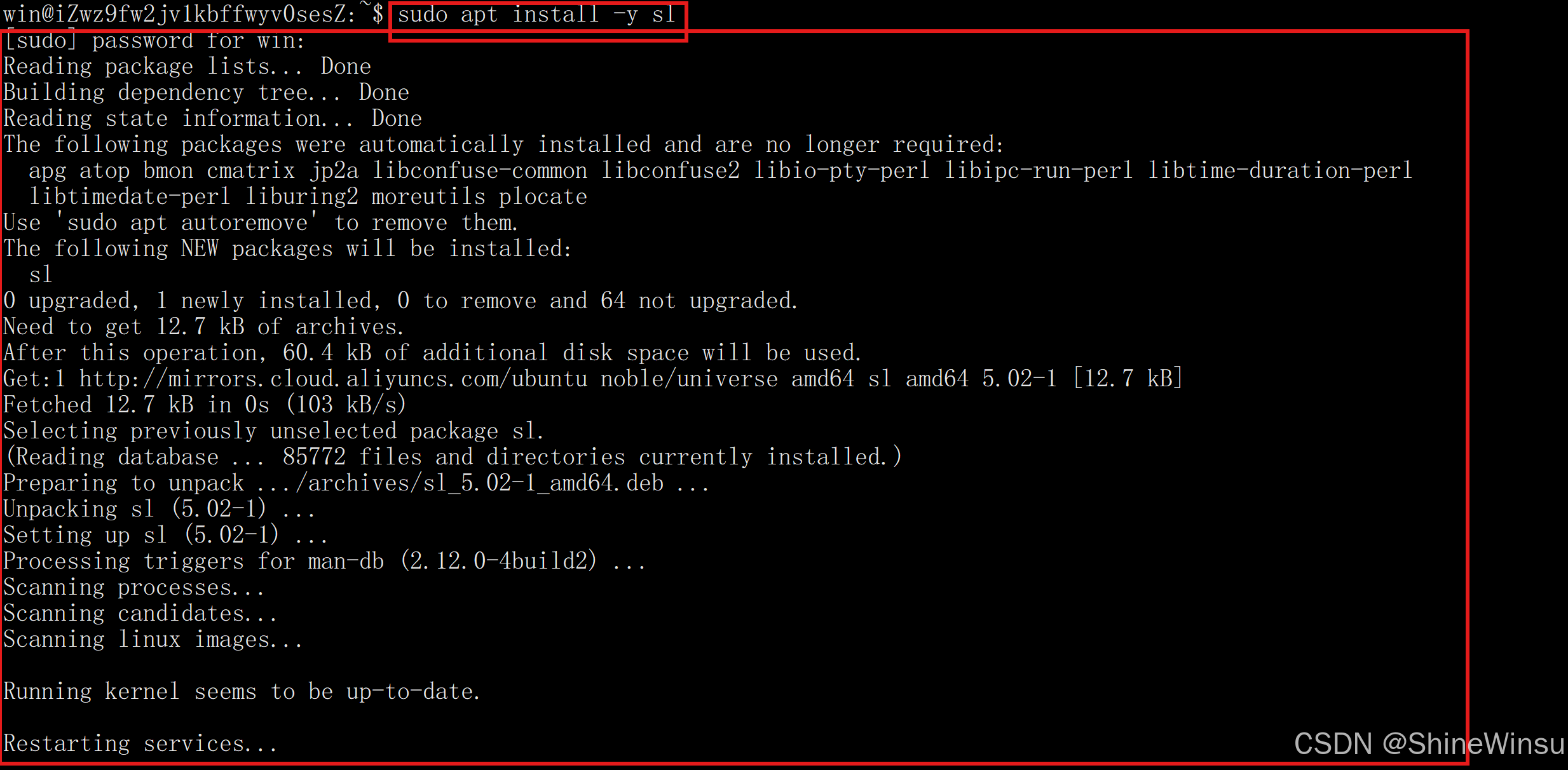
那么呢,如果我们是root用户,就可以直接使用上面的方式,但是要不是,是普通用户的话,我们就得使用sudo 命令,其实也就是在前面加个sudo罢了
bash
sudo apt install -y 软件包名字-
安装流程说明:
apt会自动识别并下载软件包所需的依赖。- 若安装过程无报错,或出现类似完成的提示信息,即表示安装成功。
-
注意事项:
- 安装需向系统目录写入内容,必须通过
sudo提升权限或切换到 root 账户。 - 同一时间只能进行一个
apt安装任务,同时执行多个会因冲突报错。 - 若出现报错,可通过搜索具体错误信息排查解决。
- 安装需向系统目录写入内容,必须通过
其实还是很简单很简单的。
使用apt的一些常用操作:
在 Ubuntu 系统中,使用apt命令安装软件的方法如下:
-
更新软件包列表:在安装软件包之前,首先需要更新本地的软件包列表,以确保获取到最新的软件包信息。使用命令:
sudo apt update
-
安装软件包 :使用
apt install命令来安装指定的软件包,命令格式为:
bash
sudo apt install package_name例如,要安装curl工具,可以执行以下命令:
sudo apt install curl如果要一次性安装多个软件包,可以将包名用空格分隔,如同时安装nginx和mysql-server:
sudo apt install nginx mysql-server- 安装特定版本的软件包:如果需要安装软件包的特定版本,可以在软件包名称后添加版本号,命令格式为:
bash
sudo apt install package_name=version_number例如,要安装redis的 4.0 版本,可以执行:
sudo apt install redis=4.0-
修复损坏的依赖关系:如果软件包的依赖关系被损坏,可以使用以下命令来修复:
sudo apt install -f
主要还是要掌握下载的命令就行了
删除软件:
这个其实就是简单的无边无际了
在 Ubuntu 系统中,使用apt删除软件包的操作非常简单,主要有以下两种常用方式:
方式 1:仅删除软件包(保留配置文件)
命令格式:
bash
sudo apt remove 软件包名称示例(删除lrzsz):
sudo apt remove lrzsz方式 2:删除软件包及配置文件(彻底卸载)
命令格式:
bash
sudo apt purge 软件包名称示例(彻底卸载lrzsz):
sudo apt purge lrzsz补充:清理残留依赖
若要清理因卸载软件而残留的无用依赖包,可执行:
sudo apt autoremove这些命令都需要sudo权限(你是普通用户的前提下),执行过程中apt会自动处理相关逻辑,操作十分便捷。
注意事项:
关于 yum / apt 的所有操作必须保证主机(虚拟机)网络畅通,可以通过 ping 指令验证
ping指令:
1. 作用
ping 指令用于检测主机之间的网络连通性,通过向目标主机发送数据包并接收响应,判断网络是否通畅、目标主机是否可达。
2. 基本用法
在终端中输入以下命令:
bash
ping 目标地址-
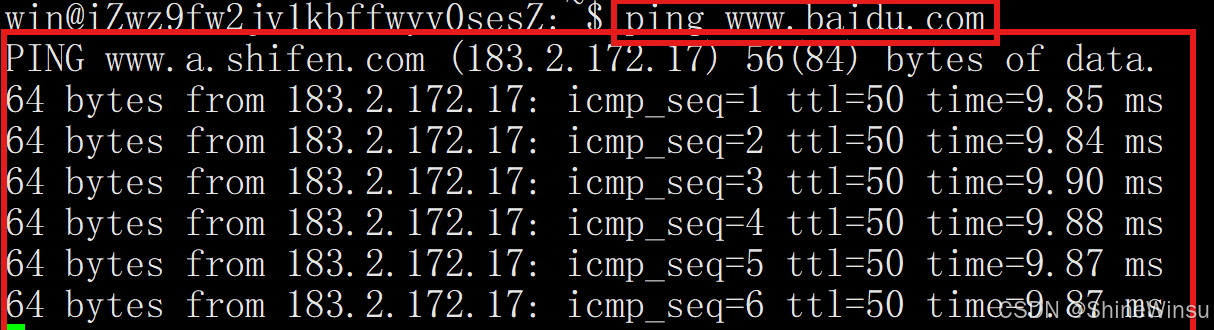
示例(检测与百度的连通性):
ping www.baidu.com -
执行后,会持续发送数据包并显示响应时间、丢包率等信息;若要停止,按
Ctrl + C即可。
3. 常见参数
-c <次数>:指定发送数据包的次数,例如ping -c 5 www.baidu.com表示只发送 5 次数据包。-s <大小>:指定发送数据包的大小(单位:字节),可用于测试网络在不同数据包大小下的表现。
还有一个安装源的我就不介绍了,大家百度一下就有很多。
vim编辑器:
OK大家,接下来要给大家介绍的就是我们的基础开发工具的重头戏了,vim编辑器,吼吼,前情提示一下,对于vim编辑器,它的操作是和我们之前的写代码方式差距挺大的,所以大家做好心理准备。
vim编辑器的介绍:
Vim 是一款功能强大的文本编辑器,是 Vi 编辑器的增强版,在 Linux 和类 Unix 系统中被广泛使用,也可在 Windows 等平台运行。
核心特点
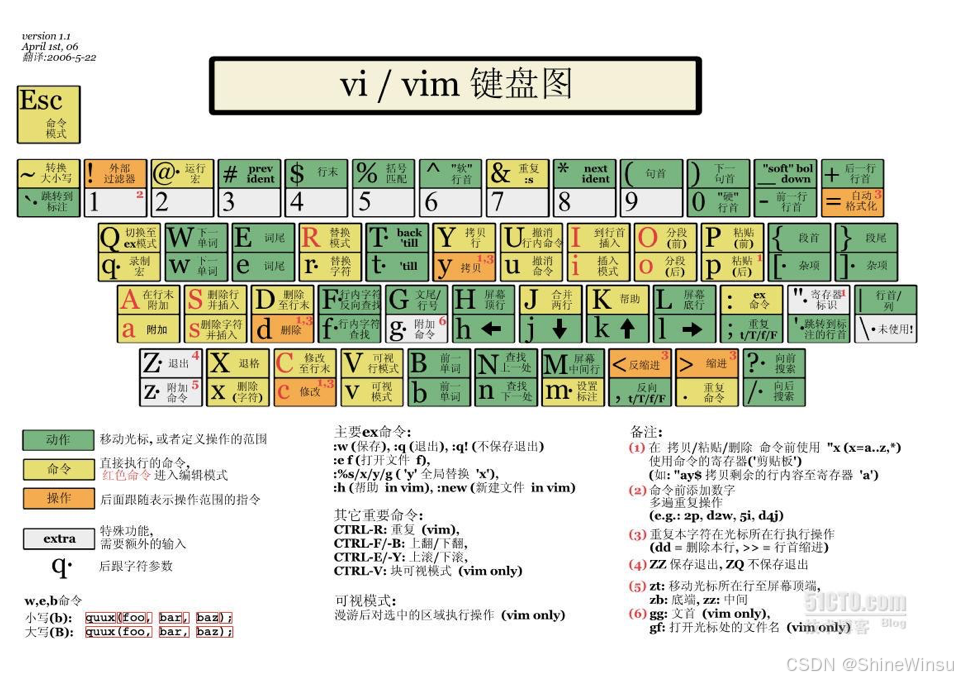
- 模式化编辑:包含普通模式(执行命令、移动光标)、插入模式(输入文本)、命令模式(执行保存、退出等操作)等多种模式,不同模式各司其职,精准满足编辑需求。
- 强大的命令集 :支持丰富的命令,可实现快速文本跳转、复制、粘贴、查找、替换等操作,例如在普通模式下按
/可快速查找文本,:%s/old/new/g可全局替换文本。 - 可扩展性:支持通过插件扩展功能,用户可根据需求安装代码补全、语法高亮、版本控制集成等各类插件,打造个性化编辑环境。
- 跨平台:可在多种操作系统上运行,保持操作习惯的一致性。
典型应用场景
- 系统配置文件编辑:在 Linux 系统中,常用于编辑如
/etc目录下的各类配置文件。 - 编程开发:支持多种编程语言的语法高亮,帮助开发者高效编写代码。
- 文本处理:可快速对大文本文件进行查找、替换、格式调整等操作。
反正大家只需要知道,vim是我们必须要掌握的一门工具,不会也得会,就是这么的简单。
vim的配置:
OK大家,我们知道,Linux系统里是自带vim编辑器的,但是呢,那个vim是在是太low了,要啥没啥,什么代码高亮显示,自动缩行,代码补全等等都是没有的,我们写起来是嘎嘎的不方便,所以,我们是需要对原生的vim进行配置的,那么配置一般是安装插件和创建一个.vimrc的文件(注意:这个文件是创建在自己的家目录下的,),在.vimrc文件里,我们可以对vim编辑器设置一些常用的属性,但是还是需要插件,那么这对我们来说,其实有点麻烦了,因为现在是互联网时代,所以我们可以直接用现成的,那么在这里我推荐一个一键配置的,下面是某位大佬的博客,大家可以按照他的博客进行操作:Vim的强大配置文件(一键配置)_vimrc配置文件下载-CSDN博客大家看着这篇博客就已经够够的了,所以我在这里就不进行多余的介绍,我们这里主要的是对vim常见快捷键以及模式的介绍。
接下来,我们进入对vim的关键介绍,大家,接下来的知识都是干货,希望大家严阵以待。
vim的模式以及对应快捷键:
那么vim其实是个多模式的编辑器,笼统算下来,是有12种模式的,大家先不必担心,因为对于我们日常操作来说,大家掌握四种模式即可:命令模式,插入模式,末行模式、视图模式,接下来我会进行逐一的介绍:
Vim 的核心优势在于模式化分工,每个模式都有明确的定位,所有操作均围绕 "高效编辑" 设计。以下是涵盖底层原理、细分命令、实战技巧的极致详细解析:
一、命令模式(Normal Mode)
核心定位
Vim 的 "控制中枢",默认启动模式,即用vim打开文件的时候就默认进入命令模式,所有非输入类操作(移动、编辑、模式切换)均在此触发。底层逻辑是 "命令 + 范围",即先指定操作范围,再执行命令(或反之)。
1. 光标移动(全维度精细控制)
| 操作维度 | 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|---|
| 单字符移动 | h/j/k/l,用上下左右箭头也可以,但是不推荐 |
左 / 下 / 上 / 右移动 1 字符;支持数字前缀(如 8h 左移 8 字符) |
替代方向键,手不离主键盘区,编辑代码时减少手腕移动,提升效率 |
| 单词级移动 | w/W |
跳转到下一个单词首(w 按 "字母 / 数字 / 符号" 拆分单词,W 按空白拆分) |
编辑代码时快速跳转到变量名、函数名开头,如 w 可从 int age=20; 的 i 跳到 a |
b/B |
跳转到上一个单词首(规则同 w/W) |
回退修改时常用,如编辑完 age 后,按 b 快速返回单词开头 |
|
e/E |
跳转到当前单词尾(规则同 w/W) |
需修改单词后缀时使用,如 printf() 按 e 可跳到 f 后,直接添加参数 |
|
| 行内精准定位 | 0(数字零) |
跳转到行首(包含行首空白字符) | 需修改行首缩进或添加注释时使用,如代码行 int a; 按 0 跳到最左侧空格处 |
^(caret 符号) |
跳转到行首非空白字符 | 直接定位到代码有效内容开头,避免手动跳过缩进,如 int a; 按 ^ 跳到 i 处 |
|
$(美元符号) |
跳转到行尾 | 补充行尾内容时使用,如 printf("hello") 按 $ 跳到 ) 后,添加 ; |
|
f{char}/F{char} |
行内向前 / 向后查找并跳转到指定字符 char(如 fa 找行内第一个 a) |
快速定位行内特定字符,如 f; 可直接跳到代码行末尾的分号处修改 |
|
t{char}/T{char} |
行内向前 / 向后查找并跳转到指定字符前一位(如 ta 到 a 前) |
需在特定字符前插入内容时使用,如 int num=10 按 t= 跳到 = 前,插入 const |
|
| 分页 / 屏幕移动 | Ctrl + f(forward) |
向前翻 1 整页 | 查看长文件(如配置文件、日志)时快速跳转,类似阅读器的 "下一页" |
Ctrl + b(backward) |
向后翻 1 整页 | 回退查看之前内容,如翻页后发现需要修改上一页代码,快速返回 | |
Ctrl + d(down) |
向前翻半页 | 精细翻页,避免整页跳转错过关键内容 | |
Ctrl + u(up) |
向后翻半页 | 同精细翻页需求,平衡效率与准确性 | |
zz/zt/zb |
当前行居中 / 置顶 / 置底显示 | 编辑长文件时,让当前操作行处于视野中央,减少视线移动,如修改第 50 行时按 zz 居中 |
|
| 行号跳转 | nG(如 15G) |
跳转到第 n 行 |
已知目标行号时直接跳转,如调试代码时,根据报错信息跳转到第 23 行,执行 23G |
gg |
跳转到文件首行 | 打开文件后快速定位到开头,如查看配置文件的头部注释 | |
G(大写) |
跳转到文件末行 | 查看文件结尾的版权声明、配置总结等,如 cat /etc/passwd 后用 G 看最后一个用户 |
|
| 跳转历史记录 | Ctrl + o(old) |
跳转到上一次跳转的位置("后退") | 多文件 / 多行跳转后回退,如从第 1 行跳到第 50 行,按 Ctrl+o 快速返回第 1 行 |
Ctrl + i(in) |
跳转到下一次跳转的位置("前进") | 回退后再前进,如 Ctrl+o 回退到第 1 行后,按 Ctrl+i 回到第 50 行 |
2. 文本编辑(删除 / 复制 / 粘贴 / 撤销 / 重复)
| 操作类型 | 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|---|
| 删除(剪切)(Delete) | x/nx |
删除光标处 1 个字符 /n个字符(如 3x 删除光标后 3 字符) |
小范围删除,如删除多余的逗号、括号,无需选中整行 |
X(大写) |
删除光标前 1 个字符 | 输入错误时回删,如误输入 intt a; 按 X 删除多余的 t |
|
| 在 Vim 中,剪切操作本质上是 "删除并暂存内容" | dd/ndd |
删除当前行 / 连续 n 行(如 4dd 删除当前行及以下 3 行) |
批量删除代码行,如删除调试用的 printf 语句,直接 dd 一行删除 |
------ 删除的内容会被保存到缓冲区,之后可通过粘贴命令(p/P)调出 |
d{motion} |
按范围删除(motion 为移动命令,如 d$ 删光标到行尾) |
灵活删除任意范围内容,如 dw 删光标到下一个单词首,d3w 删 3 个单词 |
| ,因此 "删除命令即剪切命令"。 | D |
等价于 d$,删除光标到行尾 |
快速清理行尾多余内容,如代码行 int a=10; // 临时变量 按 D 删到 ; 后 |
| 复制(Yank) | y/ny |
复制光标处 1 个字符 /n个字符 |
小范围复制,如复制变量名中的某个字符,用于修改其他变量 |
yy/nyy |
复制当前行 / 连续 n 行(如 5yy 复制 5 行) |
批量复制代码块,如复制函数定义的多行代码,粘贴到其他位置修改 | |
y{motion} |
按范围复制(如 y^ 复制光标到行首非空字符) |
精准复制任意范围,如 yw 复制 1 个单词,y3e 复制 3 个单词的尾部内容 |
|
Y |
等价于 yy,复制当前行 |
简化操作,无需按两次 y,快速复制单行 |
|
| 粘贴(Put) | p(小写) |
在光标后粘贴缓冲区内容 | 复制后在目标位置后方插入,如复制 int a; 后,在 int b; 前按 p,结果为 int a; int b; |
P(大写) |
在光标前粘贴缓冲区内容 | 复制后在目标位置前方插入,如在 int b; 后按 P,结果为 int b; int a; |
|
np/nP |
粘贴 n 次缓冲区内容(如 3p 粘贴 3 次) |
批量生成重复内容,如需要 3 个 printf("test\n");,复制 1 行后按 3p |
|
| 撤销 / 重做 | u(小写) |
撤销上一步操作,但是需要注意的是,如果保存并退出了文件,新进入文件后按u就不能撤销回原本,而要是仅保存没退出就可以 | 误操作后恢复,如误删行后按 u 撤销删除 |
Ctrl + r(redo) |
重做被撤销的操作 | 撤销后发现需要保留原操作,如 u 撤销删除后,按 Ctrl+r 恢复删除 |
|
U(大写) |
撤销当前行的所有修改 | 对某行多次修改后,快速恢复该行原始状态,无需多次按 u |
|
| 重复操作 | .(小数点) |
重复上一次修改类命令(删除、复制、替换等) | 批量执行相同操作,如按 dd 删除 1 行后,按 . 可连续删除多行,效率远超重复按 dd |
| 命令 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
r |
替换光标所在处的单个字符 | 适用于修改单个字符的场景,例如将 int a; 中的 a 改为 b,只需将光标移到 a 上,按 r 后输入 b 即可,操作完成后自动返回命令模式。 |
R |
持续替换光标经过处的字符,直到按 Esc 退出 |
适用于连续修改多个字符的场景,例如将 printf("hello") 改为 printf("world"),光标移到 h 上按 R,依次输入 world 即可批量替换,输入完成后按 Esc 回到命令模式。 |
3. 查找与替换(精准批量修改)
| 操作类型 | 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|---|
| 基础查找 | /pattern |
正向查找(从光标向下)字符串 pattern(如 /printf 找所有 printf),也可是单个字符 |
查找代码中重复出现的关键词,如调试时找所有 printf 语句 |
?pattern |
反向查找(从光标向上)字符串 pattern,也可是单个字符 |
查找光标上方的关键词,如在文件末尾找某个函数定义,无需向上翻页 | |
| 查找导航 | n(next) |
跳转到下一个匹配项(正向查找按向下,反向查找按向上) | 连续查看所有匹配内容,如 /printf 后按 n 依次跳转到每个 printf |
N(reverse next) |
跳转到上一个匹配项(与 n 方向相反) |
回退查看之前的匹配项,如跳过某个 printf 后,按 N 重新定位 |
|
| 查找优化 | :set hlsearch |
开启查找结果高亮 | 直观看到所有匹配项,避免遗漏,编辑完后可按 :set nohlsearch 关闭高亮 |
:set incsearch |
开启增量查找(输入关键词时实时匹配) | 减少输入错误,如查找 function 时,输入 /func 已能看到部分匹配结果 |
|
| 全局替换 | :%s/old/new/g |
全局(%)替换 old 为 new,g 表示每行替换所有匹配(不加 g 只替换每行第一个) |
批量修改关键词,如将代码中所有 name 改为 username,执行后直接完成全文件替换 |
:%s/old/new/gc |
带确认的全局替换(c=confirm),按 y 替换、n 跳过、a 全部替换、q 退出 |
不确定是否需要全部替换时使用,如替换 test 时,部分 test 是变量名需保留,逐确认 |
|
| 区间替换 | :n,m s/old/new/g |
替换第 n 行到第 m 行的内容(如 :10,20 s/debug/info/g) |
仅修改指定范围,如只替换函数内(10-20 行)的 debug 为 info,不影响其他部分 |
:'<,'> s/old/new/g |
替换选中的文本块(视图模式选中后按 : 自动生成该范围) |
精准替换局部内容,如选中某段代码,替换其中的 int 为 long |
|
| 正则替换 | :%s/^/\/\/ /g |
全局在行首添加 //(注释符),^ 表示行首 |
批量注释代码块,如快速注释 10-20 行,先选中(视图模式)再执行 :'<,'> s/^/\/\/ /g |
:%s/^\/\/ //g |
全局删除行首的 //(取消注释) |
取消批量注释,与上述命令对应,快速恢复代码可执行状态 |
4. 模式切换命令
- 进入插入模式:
i/I/a/A/o/O/s/S(详情见插入模式) - 进入末行模式:
:(冒号),光标会自动跳到底部命令行 - 进入视图模式:
v(字符视图)/V(行视图)/Ctrl + v(块视图)
二、插入模式(Insert Mode)
核心定位
唯一用于 "纯文本输入" 的模式,所有文字、代码录入均在此完成。底层逻辑是 "专注输入",屏蔽其他命令干扰,仅保留基本输入功能。
这里我们要知道是,在插入模式下无论按什么都会被当作字符插入,但是按上下左右箭头键是可以进行光标的移动,而且对于我们上面配置的版本,也是可以直接用鼠标进行移动的,这也是一个便利,但是如果我们想要复制粘贴之类的,就必须要在命令模式下才行,希望大家注意
1. 进入方式(命令模式下触发),直接按对应字符即可
| 命令 | 功能说明 | 实战场景 |
|---|---|---|
i(insert) |
在光标当前位置之前插入文本 | 补充中间内容,如 int a=10 光标在 a 后,按 i 插入 ge,变成 int age=10 |
I(Insert) |
在当前行的行首非空白字符前插入文本 | 给代码行添加修饰符,如 int a; 按 I 插入 const,变成 const int a; |
a(append) |
在光标当前位置之后插入文本 | 扩展末尾内容,如 printf("hello") 光标在 o 后,按 a 插入 world |
A(Append) |
在当前行的行尾插入文本 | 补充行尾内容,如 int a 按 A 插入 =20;,变成 int a=20; |
o(open) |
在当前行下方新建一行,并进入插入模式 | 新增代码行,如在 int a; 下方新建 int b;,直接按 o 输入即可 |
O(Open) |
在当前行上方新建一行,并进入插入模式 | 插入前置代码,如在 int b; 上方插入 int a;,按 O 输入更便捷 |
s(substitute) |
删除光标所在字符,然后进入插入模式 | 修改单个字符,如 intt a; 光标在第二个 t 上,按 s 改为 n,变成 int a; |
S(Substitute) |
删除当前整行内容,然后进入插入模式 | 重写某行代码,如 int old=5; 按 S 直接输入 int new=10; 替换整行 |
gi(go insert) |
跳转到上一次退出插入模式的位置,并重新进入插入模式 | 连续编辑同一位置,如编辑完某变量后切换模式,按 gi 快速回到原位置继续输入 |
2. 插入模式下的快捷操作(无需退出)
| 操作 | 功能说明 |
|---|---|
Ctrl + h |
删除光标前一个字符(等价于退格键) |
Ctrl + w |
删除光标前一个单词(按空白 / 符号拆分) |
Ctrl + u |
删除从光标到行首的所有内容 |
Ctrl + t |
缩进当前行(向右移动) |
Ctrl + d |
取消缩进当前行(向左移动) |
Ctrl + c |
等价于 Esc,快速退出插入模式,返回命令模式 |
Ctrl + v + 字符 |
插入特殊字符(如 Ctrl + v + 033 插入 ESC 字符) |
添加注释:
在 Vim 中添加注释的方法根据注释类型(单行注释、块注释)和操作效率(单个 / 批量)有所不同,以下是最常用的方法,覆盖主流编程语言的注释风格(如//、#、/* */等):
一、单行注释(最常用,如//、#、--)
适用于 C/C++/Java(//)、Python/Shell(#)、SQL(--)等语言,核心是在目标行开头添加注释符号。
| 操作场景 | 操作步骤 | 示例(以//注释为例) |
|---|---|---|
| 单个行添加注释 | 1. 命令模式下,光标定位到目标行2. 按 I 进入行首插入模式(非空白字符前)3. 输入注释符号(如// )4. 按Esc返回命令模式 |
给int a = 10;添加注释:光标在行上→按I→输入// →结果为// int a = 10; |
| 批量多行添加注释 | 1. 命令模式下按 V 进入行视图模式 2. 按 j/k 选中需要注释的多行 3. 按 : 进入末行模式,自动生成范围<,'> 4. 输入 s/^/\/\// (替换行首为// ),按回车 |
选中 3 行代码→末行模式输入:'<,'> s/^/\/\// →3 行均添加// 注释 |
| 批量多行添加注释(块视图) | 1. 命令模式下按 Ctrl + v 进入块视图模式2. 按 j 选中多行的行首列(纵向选中)3. 按 I 进入块插入模式4. 输入注释符号(如// )5. 按Esc,所有选中行首添加注释 |
块视图选中 3 行的第一列→输入// →按Esc→3 行首均添加// |
二、块注释(多行包裹,如/* */)
适用于 C/C++/Java 等支持/* */块注释的语言,核心是用/*开头、*/结尾包裹多行内容。
| 操作场景 | 操作步骤 | 示例 |
|---|---|---|
| 批量多行添加块注释 | 1. 命令模式下,光标定位到块注释的第一行2. 按 O 在上方插入新行,输入/*,按Esc3. 光标定位到块注释的最后一行4. 按 o 在下方插入新行,输入*/,按Esc |
给 3 行代码添加块注释:第一行上插/*,最后行下插*/,中间代码被包裹 |
| 带缩进的块注释(规范格式) | 1. 用块视图选中多行内容(Ctrl + v)2. 按 > 向右缩进 1 级(保持格式美观)3. 按上述方法添加/*和*/ |
选中代码块→缩进→添加/*和*/,结果:/* int a=10; int b=20;*/ |
三、取消注释的对应方法
| 注释类型 | 取消方法 | 示例 |
|---|---|---|
单行注释(///#) |
1. 行视图选中多行→末行模式输入 s/^\/\///(删除行首//)2. 块视图选中注释符号列→按d删除 |
选中带//的行→:'<,'> s/^\/\///→移除// |
块注释(/* */) |
1. 光标定位到/*行→dd删除 2. 光标定位到*/行→dd删除 |
直接删除首尾标记,保留中间代码 |
关键说明
- 替换命令中,
^表示 "行首",s/^/xxx/意为 "在每行开头添加 xxx"; - 注释符号含特殊字符(如
/)时,需用\转义(如//需写成\/\//); - 不同语言仅需替换注释符号(如 Python 用
#,则批量命令为:'<,'> s/^/# /)。
根据编程语言选择对应注释符号,结合视图模式或替换命令,可高效完成单 / 批量注释操作
总结核心用法:
OK大家,那么上面所说的方法,都太麻烦了说实话,我接下来给大家一个嘎嘎方便一键注释连续多行代码的方法:
第一步:按ctrl+v进入块视图模式
第二步:按hjkl选定你要注释的行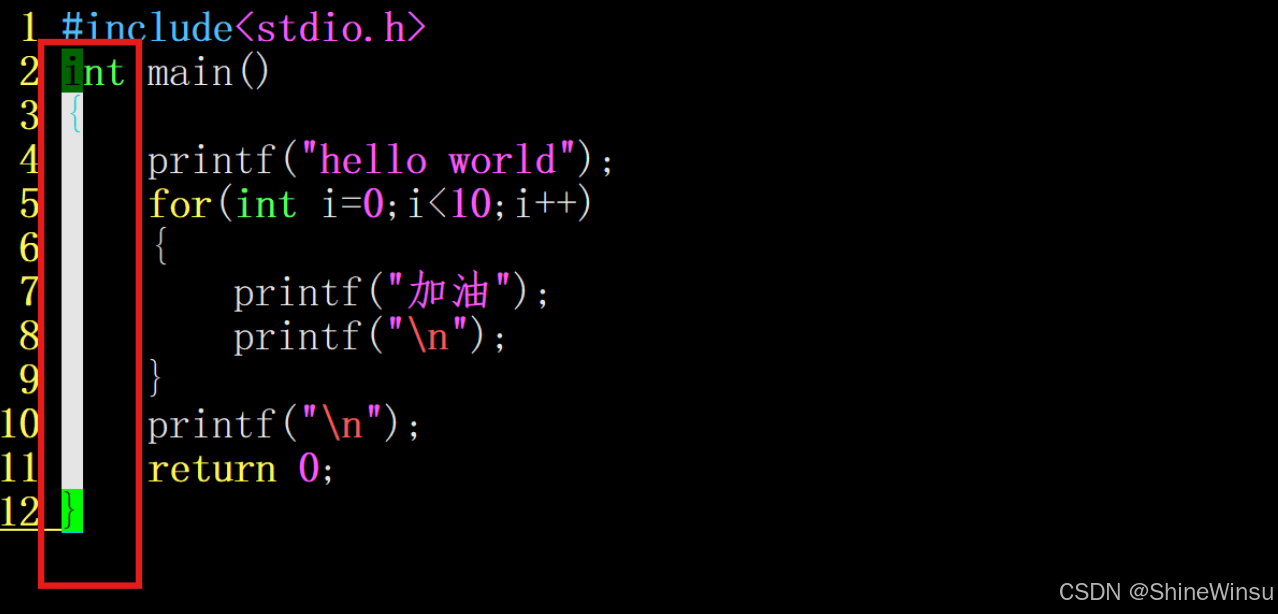
第三步:按shift+i,进入插入模式: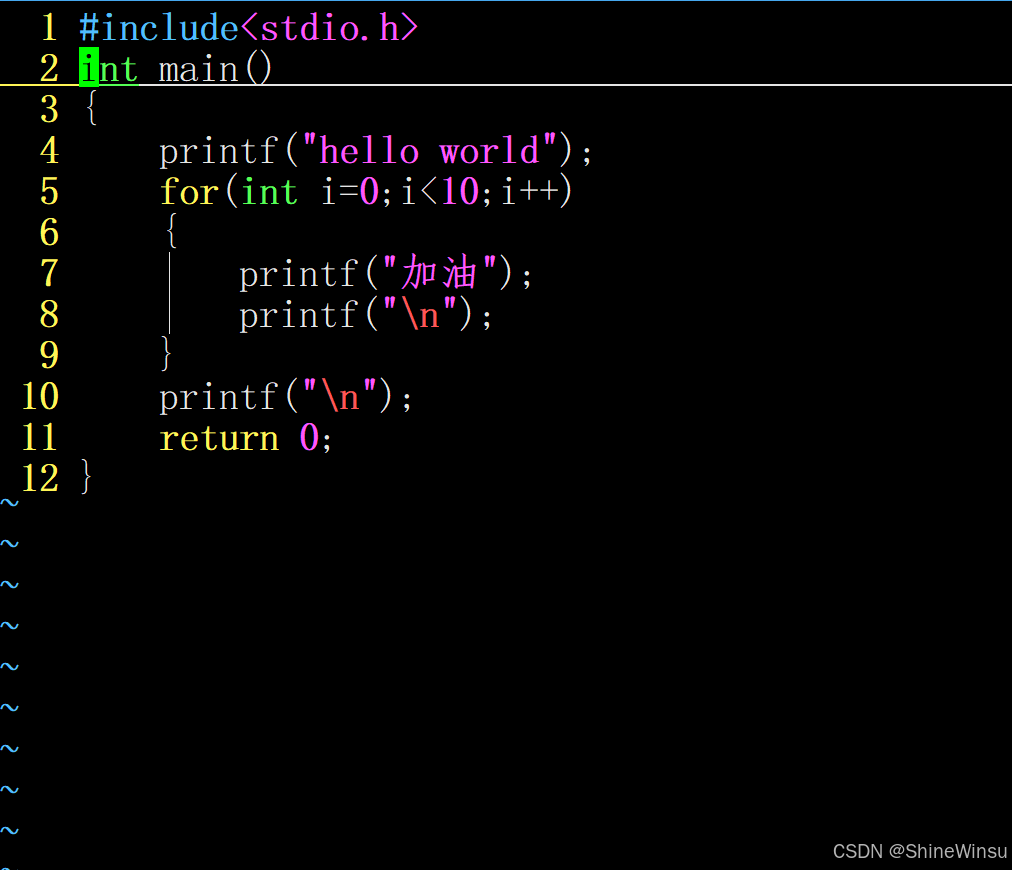 此时光标自动移到我们选中的第一行行首
此时光标自动移到我们选中的第一行行首
第四步:按//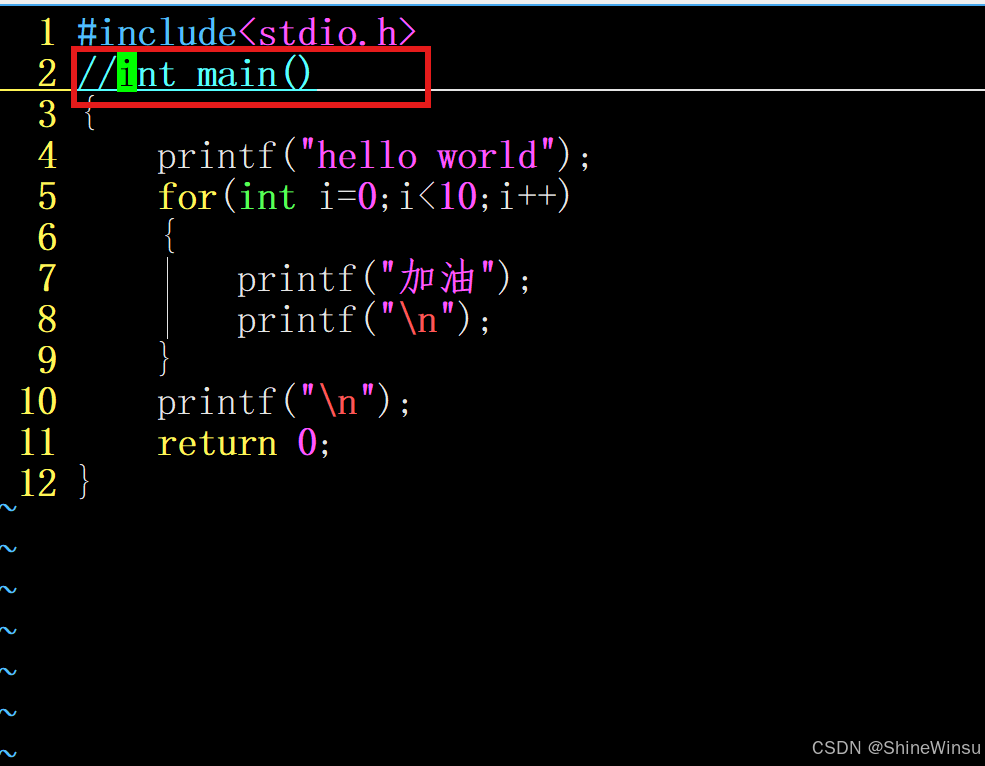
第五步:按esc按键,即可大功告成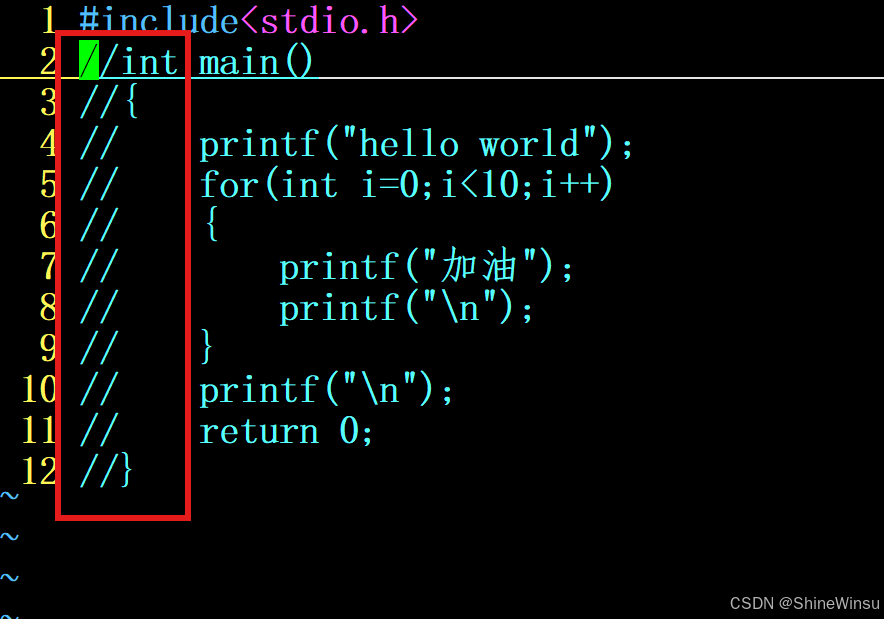
嘎嘎好使的一个操作
3. 退出方式
- 核心方式:按
Esc键(最常用,适配所有场景) - 快捷方式:按
Ctrl + c或Ctrl + [(适合键盘Esc键位置较远的情况)
三、末行模式(Command-Line Mode)
核心定位
Vim 的 "全局控制中心",用于执行文件管理、环境配置、外部命令调用等全局性操作。底层逻辑是 "指令驱动",通过输入结构化命令,触发 Vim 内部或系统级的全局功能,我们编辑完文件后的保存退出等操作,就是要在末行模式下进行的
1. 文件管理(核心操作)
前面的冒号都是需要的,输入冒号代表进入末行模式
| 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
:w |
保存当前缓冲区(文件) | 编辑过程中定期保存,避免意外退出丢失内容,如修改配置文件后先 :w 暂存 |
:w! |
强制保存当前文件(忽略只读属性) | 编辑系统只读文件(如 /etc/profile)时,sudo vim 打开后用 :w! 强制保存 |
:w 新文件名 |
将当前内容另存为指定文件 | 复制文件内容并修改,如基于 test.c 新建 test_v2.c,执行 :w test_v2.c |
:wa/:wall |
保存所有已打开的缓冲区(多文件编辑) | 同时编辑多个文件(如 vim a.c b.c),执行 :wa 一次性保存所有修改 |
:q |
退出 Vim(仅当文件未修改或已保存时生效) | 编辑完成且保存后,用 :q 正常退出 |
:q! |
强制退出 Vim,不保存任何修改 | 误打开文件或编辑错误时,用 :q! 放弃修改退出,避免污染原文件 |
:wq/:x |
保存当前文件并退出 Vim(两者功能一致,x 仅在文件修改时才保存) |
编辑完成后一站式操作,比 :w + :q 更高效 |
:wq! |
强制保存并退出 Vim(忽略只读限制) | 修改只读文件后,用 :wq! 强制保存并退出 |
:e 文件名 |
在当前 Vim 窗口中打开指定文件 | 无需退出 Vim 即可切换编辑文件,如编辑完 a.c 后,:e b.c 打开 b.c |
:e! |
放弃当前文件的所有修改,重新加载原始文件 | 编辑失误后快速恢复文件原貌,如误删多行代码后,:e! 还原原始内容 |
:r 文件名 |
将指定文件的内容读取并插入到当前光标位置 | 合并文件内容,如在 main.c 中插入 utils.c 的内容,执行 :r utils.c |
:r !命令 |
将系统命令的输出结果插入到当前光标位置 | 动态插入系统信息,如插入当前日期 :r !date,插入目录列表 :r !ls |
| 操作目的 | 命令 / 操作步骤 | 示例 | 补充说明 |
|---|---|---|---|
| 跳转到文件指定行 | 方式 1:命令模式按 : 进入末行模式,输入数字,按回车方式 2:命令模式直接输入数字 +G |
方式 1::15 回车方式 2:15G |
两种方式均能精准跳转,方式 2 无需进入末行模式,操作更快捷 |
那么大家可以想要在一个窗口同时编辑多个文件,那么这个时候,是可以在末行模式下使用:vs指令的:
:vs 要打开的文件名字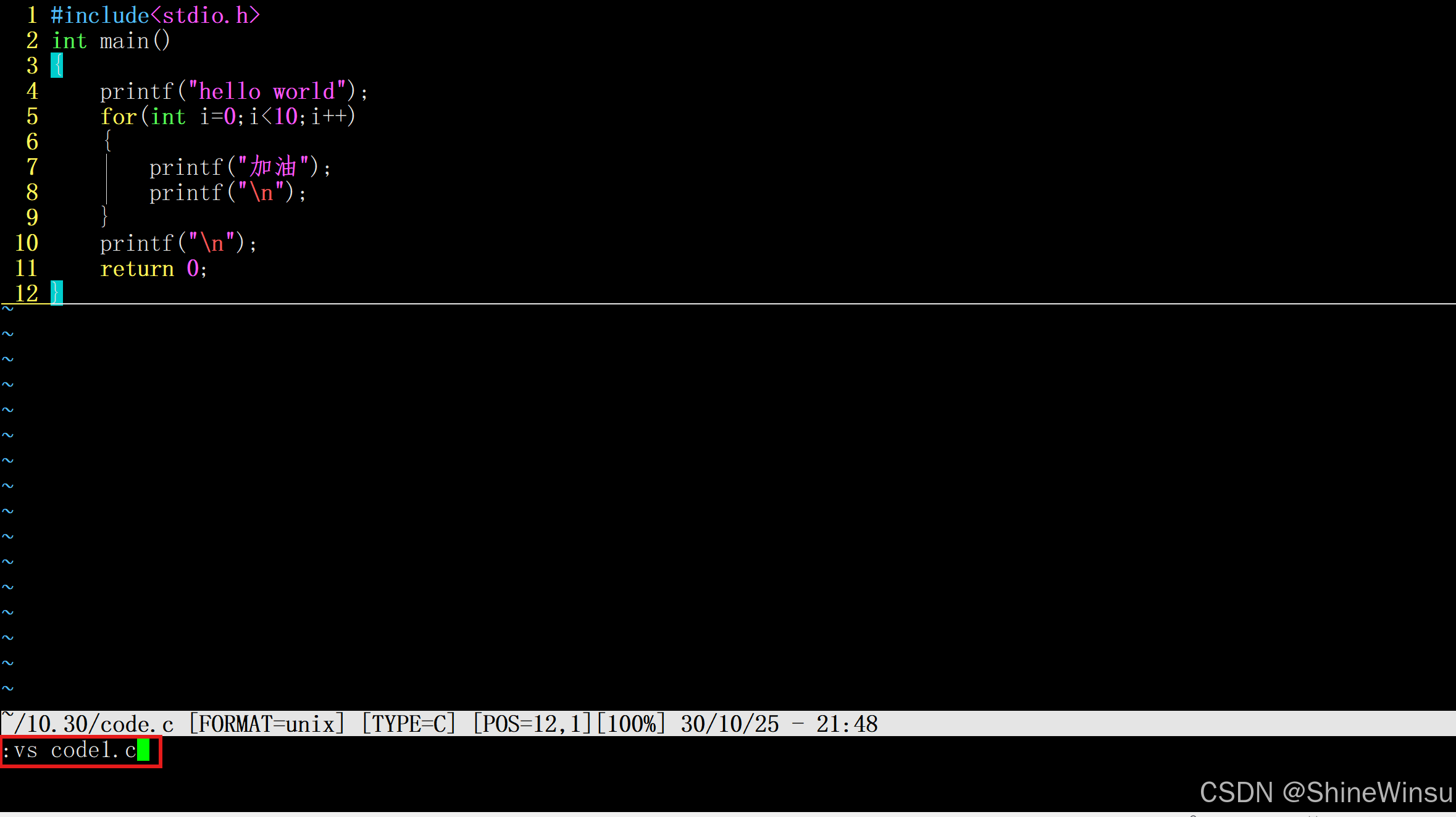
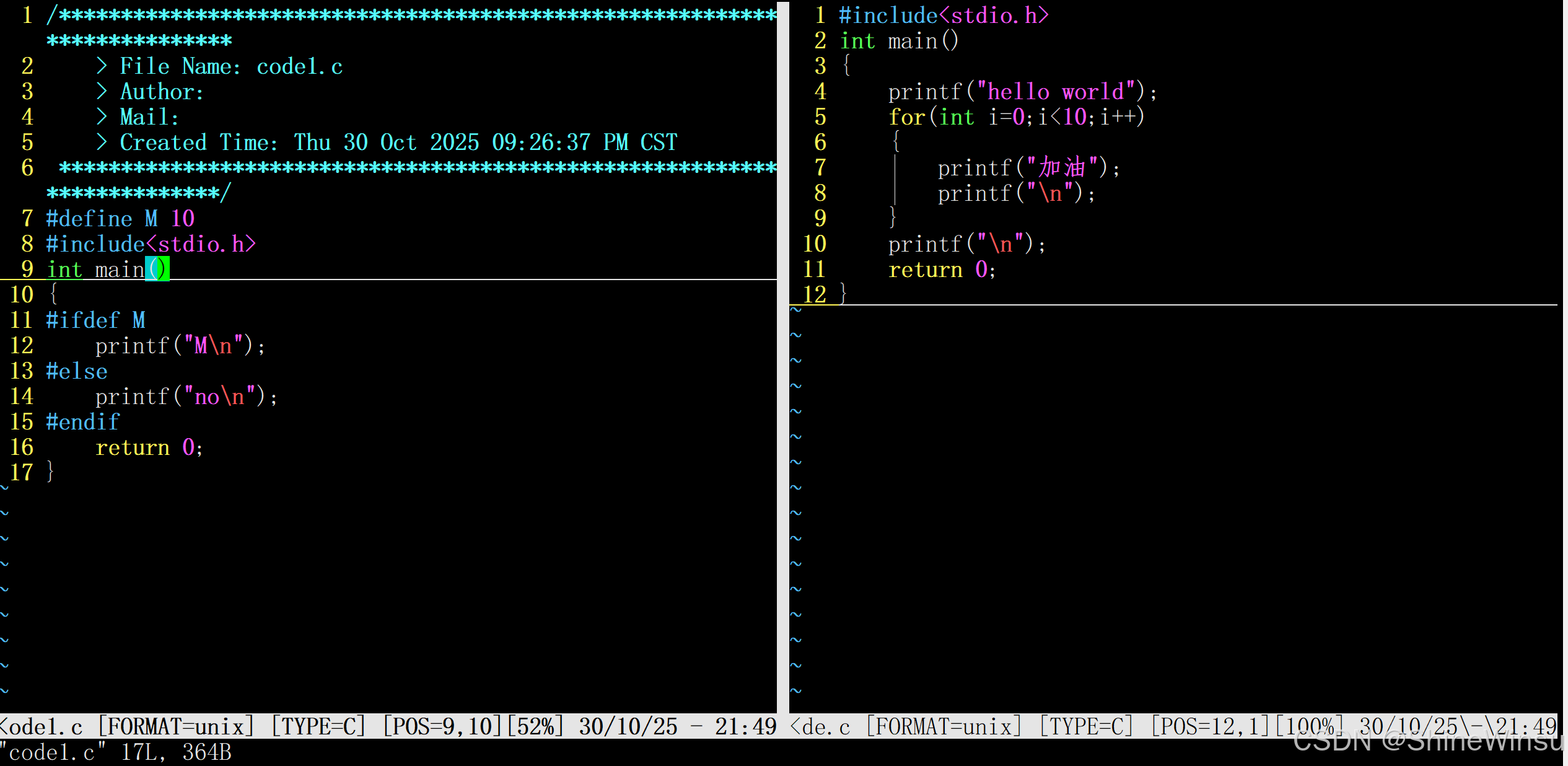
然后大家想要切换光标到不同的文件进行编辑的话,可以用鼠标,也可以使用ctrl+w进行切换
2. 缓冲区与标签页(多文件编辑进阶)
| 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
:ls/:buffers |
列出所有已打开的缓冲区(显示序号、状态、文件名) | 多文件编辑时查看所有打开的文件,如 :ls 显示 1: a.c 2: b.c,序号用于切换 |
:b 序号/:b 文件名 |
切换到指定序号或文件名的缓冲区 | 快速切换编辑文件,如 :b 2 或 :b b.c 切换到 b.c |
:bnext/:bn |
切换到下一个缓冲区 | 按顺序切换多文件,如编辑 a.c→b.c→c.c 时,连续按 :bn 依次切换 |
:bprev/:bp |
切换到上一个缓冲区 | 回退到上一个编辑文件,如 :bn 切换到 b.c 后,:bp 回到 a.c |
:bdelete 序号/:bd |
删除指定缓冲区(关闭对应文件) | 关闭不需要的文件,释放内存,如 :bd 2 关闭 b.c 对应的缓冲区 |
:tabnew/:tabnew 文件名 |
新建标签页(或新建标签页并打开指定文件) | 多文件分屏编辑,如 :tabnew a.c 新建标签页打开 a.c,:tabnew 新建空白标签页 |
:tabnext/:tabn |
切换到下一个标签页 | 标签页间快速切换,如 3 个标签页时,:tabn 循环切换 |
:tabprev/:tabp |
切换到上一个标签页 | 回退到上一个标签页,与 :tabn 配合使用 |
:tabclose/:tabc |
关闭当前标签页 | 关闭无用标签页,如编辑完 a.c 后,:%tabc 关闭当前标签页 |
:tabdo 命令 |
在所有标签页中执行指定命令 | 批量操作多标签页,如所有标签页保存 :tabdo w,所有标签页退出 :tabdo q |
3. 环境设置(临时 / 永久生效)
| 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
:set nu/:set number |
显示行号 | 编辑代码或配置文件时,行号便于定位(如调试报错提示第 15 行),执行后即时生效 |
:set nonu/:set nonumber |
隐藏行号 | 不需要行号时清理界面,如纯文本编辑时隐藏行号减少干扰 |
:set tabstop=4 |
设置制表符(Tab 键)宽度为 4 个空格 | 统一代码缩进风格,避免不同编辑器打开时格式错乱,C/C++ 开发常用配置 |
:set shiftwidth=4 |
设置自动缩进 / 手动缩进(>>/<<)的宽度为 4 个空格 |
与 tabstop 配合,确保缩进一致性,如 >> 批量缩进时每次移动 4 个空格 |
:set expandtab |
将 Tab 键输入自动转换为对应数量的空格 | 彻底避免制表符与空格混用,保证代码在所有编辑器中显示一致 |
:set noexpandtab |
关闭 Tab 键转空格功能,保留原始制表符 | 部分场景需要制表符(如 Makefile)时使用 |
:set autoindent/:set ai |
开启自动缩进(新行继承上一行的缩进) | 代码编辑时减少手动缩进操作,如 if() 后换行,新行自动缩进 4 个空格 |
:set smartindent/:set si |
开启智能缩进(根据语法自动调整缩进,如代码块、条件语句) | 进阶缩进功能,C/C++/Python 等语言开发时,{} 内自动多缩进一层,更贴合语法逻辑 |
:set syntax on |
开启语法高亮(关键词、字符串、注释等变色) | 代码编辑时区分不同语法元素,如 if/for 关键词变红,字符串变绿,降低出错概率 |
:set syntax off |
关闭语法高亮 | 纯文本编辑(如日志、笔记)时关闭,减少视觉干扰 |
:set hlsearch |
开启查找结果高亮 | 查找关键词时,所有匹配项同步高亮,便于快速浏览分布位置,如 /printf 后所有 printf 变红 |
:set nohlsearch |
关闭查找结果高亮 | 编辑完成后关闭高亮,清理界面 |
:set incsearch |
开启增量查找(输入查找关键词时实时匹配) | 减少查找错误,如查找 function 时,输入 /func 已实时显示匹配项,无需输完整个关键词 |
:set ignorecase/:set ic |
开启查找时大小写不敏感 | 模糊查找关键词,如 /printf 可匹配 printf/Printf/PRINTF |
:set noignorecase/:set noic |
关闭大小写不敏感,严格匹配大小写 | 需要精准查找时使用,如仅查找大写 PRINTF 时关闭该选项 |
:set cursorline |
高亮当前光标所在行 | 长文件编辑时快速定位光标位置,避免视线丢失,如修改第 100 行时,该行背景变色 |
:set nowrap |
关闭文本自动换行 | 代码编辑时避免一行代码被拆分成多行,保持代码结构清晰 |
:set wrap |
开启文本自动换行 | 纯文本阅读(如日志、文档)时使用,避免横向滚动 |
那么上面的第3部分这一些,我们都已经在前面的配置实现了,所以大家可以忽略
4. 执行外部命令
| 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
:! 系统命令 |
在 Vim 中执行系统 shell 命令,执行完成后返回 Vim | 无需退出 Vim 即可调用系统功能,如查看目录文件 :!ls,编译代码 :!gcc main.c -o main |
:!gcc main.c -o main && ./main |
编译并运行 C 程序 | 代码编辑完成后一站式测试,无需切换到终端,提升开发效率 |
:!cat /etc/passwd |
查看系统文件内容 | 快速查阅配置文件,如编辑 nginx.conf 时,:%!cat /etc/nginx/nginx.conf 参考原始配置 |
:!date |
查看当前系统时间 | 插入时间戳时使用,如 :r !date 将当前时间插入到文本中 |
:!sed -i 's/old/new/g' 文件名 |
调用 sed 命令批量修改外部文件 | 同时处理多个文件时,无需打开即可修改,如 :!sed -i 's/debug/info/g' utils.c |
5. 末行模式进阶操作
| 命令组合 | 功能说明 | 底层逻辑与实战场景 |
|---|---|---|
| :%s/dst/src/ | 在整个文件(%)中,将所有 "dst" 字符串替换为 "src" 字符串(每行仅替换第一个匹配) |
批量修改代码中的变量名、函数名,如将所有 "old_var" 改为 "new_var",执行后快速完成全文件替换 |
:g/pattern/d |
全局删除包含 pattern 的所有行 |
批量清理无用内容,如删除所有注释行 :g/\/\//d,删除所有空行 :g/^$/d |
:v/pattern/d |
全局删除不包含 pattern 的所有行 |
筛选需要的内容,如保留所有包含 printf 的行 :v/printf/d |
:set fileformat=unix |
设置文件格式为 Unix(换行符 \n) |
解决跨平台文件换行符问题,如 Windows 格式文件(\r\n)在 Linux 下显示乱码时使用 |
:set fileformat=dos |
设置文件格式为 DOS(换行符 \r\n) |
Windows 平台打开 Linux 格式文件时,避免换行符不识别的问题 |
:set fileencoding=utf-8 |
设置文件编码为 UTF-8 | 支持中文等多字节字符,避免中文乱码,编辑中文文档或代码注释时必备 |
:map <F5> :w<CR>:!gcc % -o %< && ./%<<CR> |
映射 F5 键为 "保存 + 编译 + 运行" 一键执行 | 代码开发时简化操作,按 F5 直接完成测试,无需重复输入编译命令 |
6. 模式切换
- 返回命令模式:按
Esc键或Ctrl + c,直接退出末行模式 - 进入插入模式:末行模式下无法直接进入,需先返回命令模式再触发插入命令
四、视图模式(Visual Mode)
核心定位
Vim 的 "可视化编辑模式",用于精准选中文本块,支持批量复制、删除、替换等操作。底层逻辑是 "选中即操作",先通过可视化方式界定范围,再执行编辑命令,比命令模式的 "盲操作" 更直观。
1. 字符视图模式(v,Character-wise Visual)
| 核心信息 | 详细说明 |
|---|---|
| 进入方式 | 命令模式下按 v(小写),光标变为高亮,进入字符级选中状态 |
| 选中文本方式 | 按 h/j/k/l 等移动命令,逐字符扩展选中范围;支持数字前缀(如 3l 选中右侧 3 字符) |
| 核心操作(选中后执行) | - 复制:按 y(复制选中字符块到缓冲区)- 删除:按 d(删除选中字符块)- 替换:按 c(删除选中字符并进入插入模式)- 大小写转换:按 u(小写)/U(大写) |
| 实战场景 | 选中部分单词或零散字符,如选中 int age=20; 中的 age,按 v 后 e 选中,再 c 改为 user_age |
| 退出方式 | 按 Esc 键返回命令模式,选中状态取消 |
2. 行视图模式(V,Line-wise Visual)
| 核心信息 | 详细说明 |
|---|---|
| 进入方式 | 命令模式下按 V(大写),当前行整体高亮,进入行级选中状态 |
| 选中文本方式 | 按 j/k 上下移动,逐行扩展选中范围;支持数字前缀(如 5j 选中当前行及下方 4 行) |
| 核心操作(选中后执行) | - 复制:按 y(复制选中所有行)- 删除:按 d(删除选中所有行)- 缩进:按 >>(向右缩进)/<<(向左缩进)- 注释:按 : 输入 s/^/\/\/ /g 批量添加注释 |
| 实战场景 | 批量处理多行代码,如选中 10-15 行函数代码,按 y 复制到其他文件,或按 >> 统一缩进 |
| 退出方式 | 按 Esc 键返回命令模式,选中状态取消 |
3. 块视图模式(Ctrl + v,Block-wise Visual)
| 核心信息 | 详细说明 |
|---|---|
| 进入方式 | 命令模式下按 Ctrl + v(Windows/Linux)/Ctrl + q(Mac),进入列级选中状态 |
| 选中文本方式 | 按 h/j/k/l 移动,选中矩形块区域;支持数字前缀(如 3j2l 选中 3 行 2 列的块) |
| 核心操作(选中后执行) | - 批量添加内容:按 I(大写),输入内容后按 Esc,选中列所有行前添加相同内容(如添加 // 注释)- 批量删除内容:按 d,直接删除选中的列块- 批量替换内容:按 c,删除选中块并进入插入模式,输入新内容后按 Esc 统一替换- 复制块:按 y,复制选中的列块 |
| 实战场景 | 1. 批量添加注释:选中多行代码的行首列块,按 I 输入 // 后 Esc,所有行前添加注释2. 批量删除列:选中表格中的某一列,按 d 直接删除3. 批量修改变量前缀:选中多行的 old_ 前缀列块,按 c 改为 new_ |
| 退出方式 | 按 Esc 键返回命令模式,选中状态取消 |
4. 视图模式进阶技巧
- 选中后取消部分选中:按
o(小写)切换选中块的 "起始 / 结束点",再移动光标调整范围 - 选中后查找:按
/或?查找关键词,选中范围会跟随光标扩展 - 多块选中:块视图模式下按
Ctrl + v后,按j/k选中多行,再按Shift + i批量插入内容
模式切换总览(核心逻辑)
- 所有模式 → 命令模式:按
Esc键(万能返回键) - 命令模式 → 其他模式:通过特定命令触发(
i/:/v等) - 其他模式间切换:需先返回命令模式,再切换到目标模式
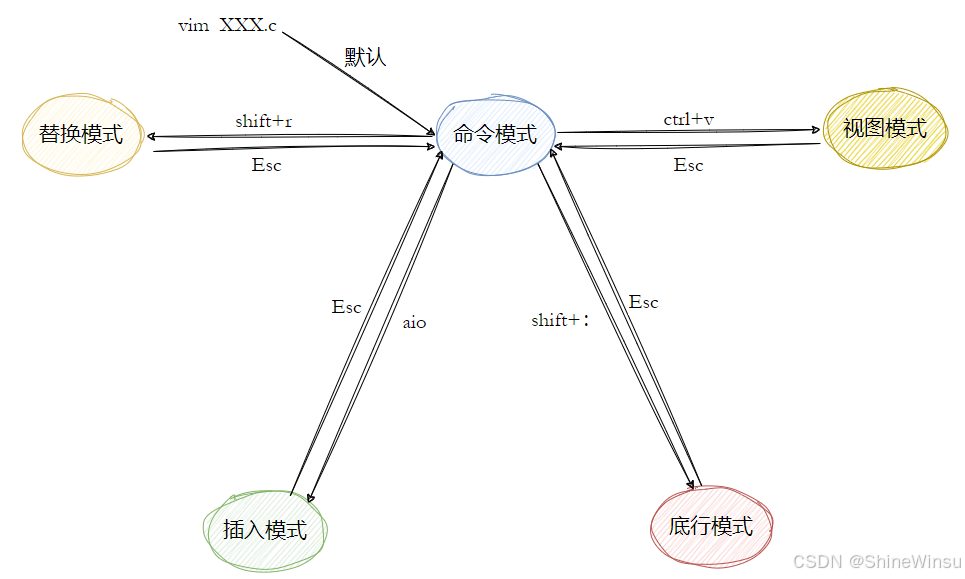
OK大家,到这里我对vim模式和对应指令的介绍就差不多了,我标红的那些是我们最常用的,希望大家能自己多去练习,熟能生巧,希望大家注意。
gcc/g++ 编译流程与链接、库知识全解析
一、编译流程四阶段(预处理→编译→汇编→链接)
| 阶段 | 功能说明 | GCC 选项 | 输出文件 | 实例操作 |
|---|---|---|---|---|
| 预处理 | 处理宏定义、头文件展开、去注释、条件编译等 | -E |
.i |
gcc -E hello.c -o hello.i(预处理后停止,生成纯代码文件) |
| 编译 | 检查语法错误,将 C 代码转换为汇编语言代码 | -S |
.s |
gcc -S hello.i -o hello.s(编译后停止,生成汇编代码) |
| 汇编 | 将汇编代码转换为机器可识别的二进制目标代码(.o 文件) |
-c |
.o |
gcc -c hello.s -o hello.o(汇编后停止,生成二进制目标文件) |
| 链接 | 合并多个目标文件 / 库文件,生成可执行文件或库文件 | 无(或 -o) |
可执行文件 | gcc hello.o -o hello(链接目标文件,生成可执行程序 hello) |
二、静态链接 vs 动态链接(多文件依赖的两种处理方式)
| 对比项 | 静态链接 | 动态链接 |
|---|---|---|
| 空间占用 | 每个可执行程序包含依赖库的完整副本,文件体积大 | 多个程序共享同一份库文件,节省磁盘 / 内存空间 |
| 更新难度 | 库更新后需重新编译链接所有依赖程序 | 库更新后,只需替换库文件,所有依赖程序自动生效 |
| 运行速度 | 无运行时链接开销,速度快 | 运行时需动态加载库,速度略慢(实际差异极小) |
| 依赖关系 | 可执行文件不依赖外部库,移植性强 | 依赖系统中的动态库,移植时需同时拷贝依赖的库文件 |
| 类比(网吧) | 自己带游戏安装包(每个游戏都是独立副本,占空间但无需网吧软件支持) | 网吧共享游戏软件(多人共用一份,省空间但依赖网吧系统) |
三、静态库 vs 动态库(代码复用的两种载体)
| 对比项 | 静态库(.a) |
动态库(.so/.dll) |
|---|---|---|
| 后缀 | Linux:.a;Windows:.lib |
Linux:.so;Windows:.dll |
| 链接时机 | 编译链接阶段,库代码被完整嵌入可执行文件 | 程序运行阶段,动态加载库代码 |
| 文件体积 | 可执行文件包含库代码,体积大 | 可执行文件仅含库的引用,体积小 |
| 依赖关系 | 无运行时依赖,移植性强 | 依赖系统中的动态库,缺失时程序无法运行 |
| 示例 | libmath.a(数学函数静态库,嵌入后程序独立运行) |
libc.so.6(C 标准库动态库,多个程序共享) |
四、库的作用与依赖查看
-
库的本质:封装好的代码模块(如
printf函数的实现),避免重复编写,实现代码复用。 -
C 标准库示例:
printf函数的实现位于libc.so.6动态库中,编译时 GCC 会自动链接该库。 -
查看依赖的动态库:使用
ldd命令,如ldd hello可列出可执行文件hello依赖的所有动态库:$ ldd hello linux-vdso.so.1 => (0x00007fffeb1ab000) libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000) /lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)
五、关键命令与实践总结
| 操作需求 | 命令 / 步骤详解 | 底层逻辑与实战场景 |
|---|---|---|
| 完整编译流程 | gcc hello.c -o hello一步执行预处理、编译、汇编、链接四个阶段,直接生成可执行文件hello。注意:被编译的源文件(hello.c)需放在-o选项之前,目标文件名(hello)放在-o之后,而要是我们不写-o选项的话(那么后面的文件名肯定也不能写了),系统是默认生成a.out文件的,即也是直接走完完整编译流程 |
底层逻辑:GCC 隐式依次执行四个编译阶段,无需手动分步操作,适合日常快速生成可执行程序。实战场景:开发小型 C 程序时,一行命令完成编译运行,提升效率。 |
| 查看预处理结果 | gcc -E hello.c -o hello.i执行预处理阶段后停止 ,生成.i文件;打开hello.i可查看宏替换、头文件展开、去注释后的纯代码。 |
底层逻辑:预处理是编译的第一步,处理#define(宏)、#include(头文件)、#if(条件编译)等以#开头的指令。实战场景:调试宏定义冲突、头文件重复包含问题时,通过查看hello.i的展开结果定位问题。 |
| 查看汇编代码 | gcc -S hello.c -o hello.s执行编译阶段后停止 ,生成.s汇编文件;打开hello.s可查看代码对应的汇编指令。 |
底层逻辑:编译阶段将 C 代码转换为汇编语言,是 "高级语言→机器语言" 的关键中间层,汇编代码直接对应 CPU 指令。实战场景:需对代码进行底层优化(如性能调优)、理解编译原理(如变量存储、函数调用的底层实现)时,分析.s文件。 |
| 验证动态链接 | file hello查看可执行文件的属性,若输出含dynamically linked,则为动态链接;若为statically linked则为静态链接。 |
底层逻辑:动态链接的可执行文件运行时依赖系统中的共享库(如libc.so),静态链接则将库代码嵌入自身。实战场景:确认程序的依赖方式,若需移植到无对应共享库的系统,需手动静态链接或同时拷贝依赖库。 |
大家主要是看关键命令这一块,关于上面的预处理、编译、汇编、链接,大家仅做掌握即可,
那么大家可能有点不太能记得,大家可以直接记,-ESc,iso,就是这么简单,esc大家肯定不陌生,iso其实就是虚拟机镜像文件的后缀,大家到了后期也会了解到,
然后下面我对关键命令这一块进行示例以及详细的讲解,毕竟因为我们会经常和它打交道。
直接完整编译:
那么上面说了,我们想要一行命令直接编译好我们的源文件的话,是**gcc hello.c -o hello一步执行预处理、编译、汇编、链接四个阶段,直接生成可执行文件hello。注意:被编译的源文件(hello.c)需放在-o选项之前,目标文件名(hello)放在-o之后,对于这个的理解,大家可以认为是,我们是要把hello.c这个文件,编译成为hello这个程序的,所以源文件就得在选项之前,而目标程序名就得在选项之后****,对了,大家在使用gcc或者g++之前,要记得先apt安装一下。**
那么我们来看看具体怎么操作:
首先我们要输入命令,记得是在-o后面跟上我们生成的程序名,那么执行完了之后,本目录下就会生成一个那个程序名:
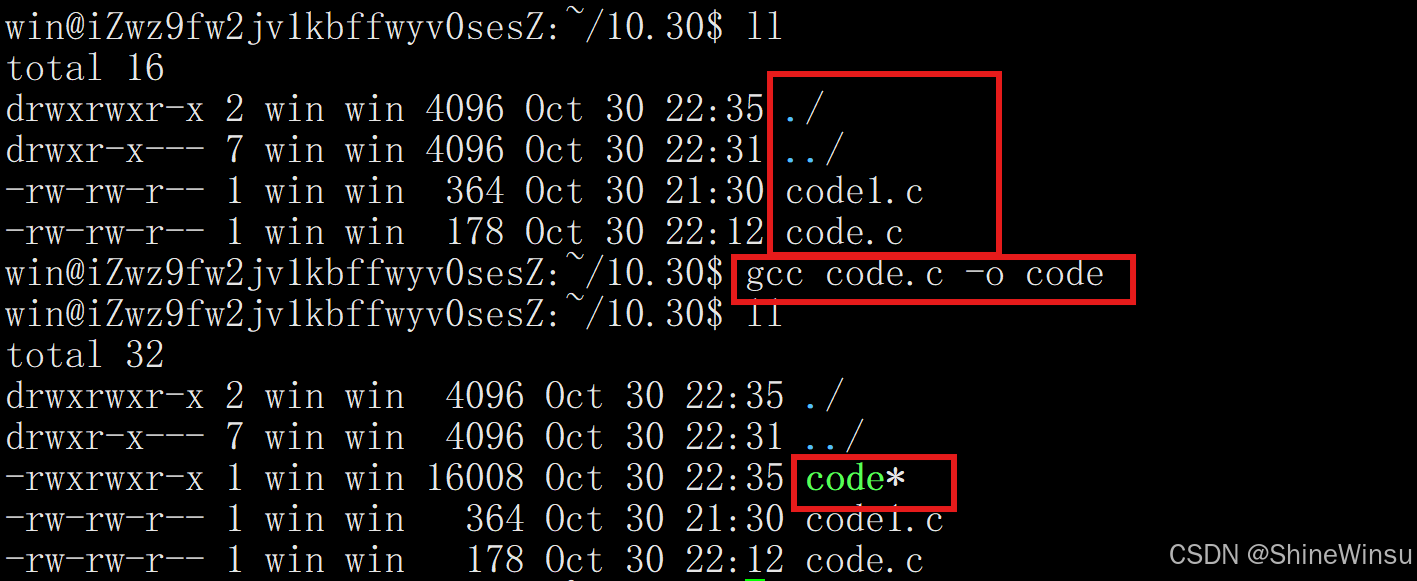
那么比如上图的code,就是我们的code.c编译形成的程序,那么我们怎么运行它呢?其实是很简单的:
目录名/程序名比如上面的code程序,因为它是在本目录下的,所以我们直接./code就行:
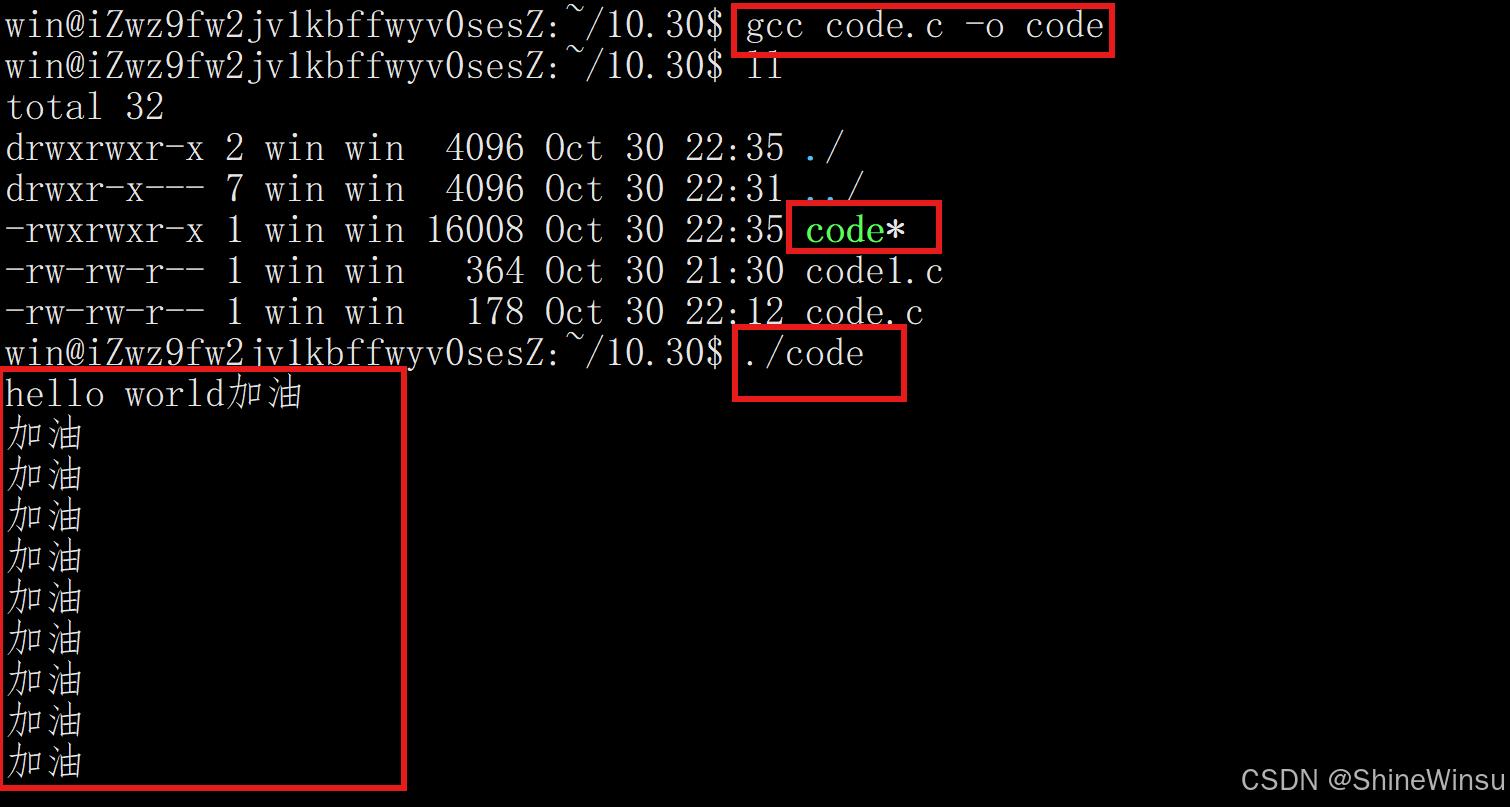
可以看到,就成功运行了。
那么上面的一套流程,就是我们运行我们所写的c文件或者c++文件的流程,希望大家自己熟悉熟悉。
而要是我们不写-o选项的话(那么后面的文件名肯定也不能写了),系统是默认生成a.out****文件的,即也是直接走完完整编译流程,这个我给大家补充一下:
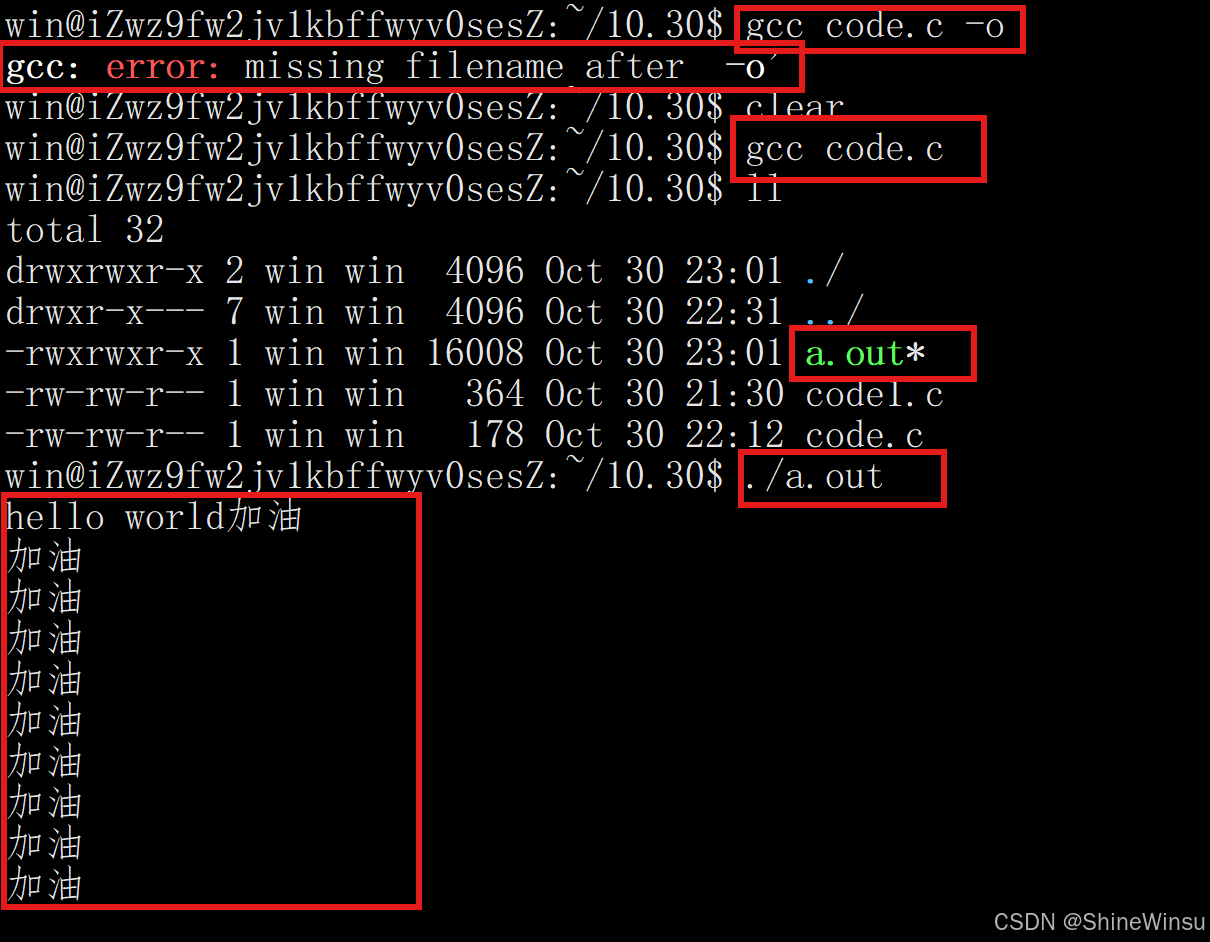
大家要注意是在不写-o选项的情况下的哦。
但是呢,大家注意,我们前面有说到连接的概念,那么其实在我们日常的工作中,我们一般是不会去把源文件直接就干成程序的,而是会让它先汇编为.o文件的,然后再去把这些.o文件链接为程序的,那么为什么我们要这样子呢?
| 原因分类 | 详细说明 | 实战价值 |
|---|---|---|
| 模块化开发需求 | 大型项目通常拆分多个源文件(如utils.c、main.c),每个文件对应一个功能模块。先编译成.o文件(如utils.o、main.o),可实现模块独立开发、独立测试,再通过链接整合为完整程序。 |
团队协作时,多人可同时开发不同模块,互不干扰;单个模块修改后,仅需重新编译该模块的.o文件,再链接即可。 |
| 编译效率优化 | 源文件编译成.o后,后续链接阶段无需重复编译未修改的文件。若直接编译成程序,每次修改任意一个源文件都要重新编译所有文件,耗时极长。 |
大型项目(如 Linux 内核、大型应用)通过这种方式将编译时间从 "小时级" 压缩到 "分钟级" 甚至 "秒级"。 |
| 代码复用性 | .o文件可被多个项目或程序共享 (如通用工具函数编译成tools.o,可在多个项目中直接链接使用),无需重复编译相同代码。 |
企业开发中,基础库(如加密模块、网络模块)编译成.o或静态库 / 动态库,供多个业务系统复用,大幅减少重复开发。 |
| 错误隔离与调试 | 编译阶段仅检查单个源文件的语法错误(生成.o时发现),链接阶段才处理模块间的依赖错误。若直接编译,一个模块的错误会导致整个编译流程失败,难以定位问题。 |
开发时可先确保每个模块的.o文件编译通过,再逐步排查链接阶段的依赖问题(如函数未定义、符号冲突),调试更高效。 |
| 链接灵活性 | 链接阶段可选择静态链接 或动态链接 ,还可整合第三方库(如-lssl链接 OpenSSL 库)。若直接编译,无法灵活调整链接策略。 |
需移植程序时,可选择静态链接(将库代码嵌入程序,不依赖系统库);需减小程序体积时,选择动态链接(共享系统库)。 |
那么具体是怎么操作的呢?我们看下面:
首先是针对单个文件的: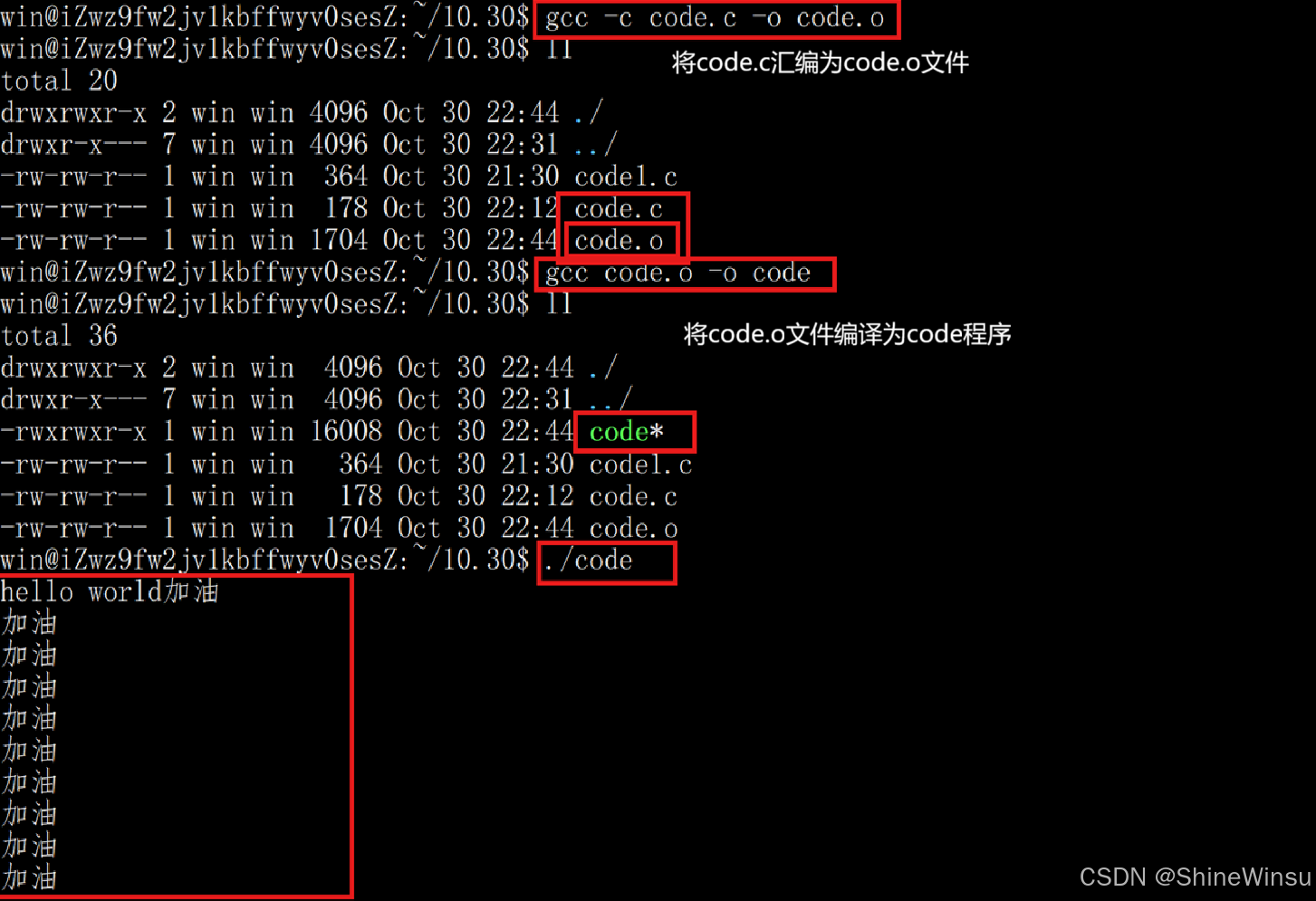 还是很简单的。
还是很简单的。
下面是针对多个文件的:
如果我们想这样子的话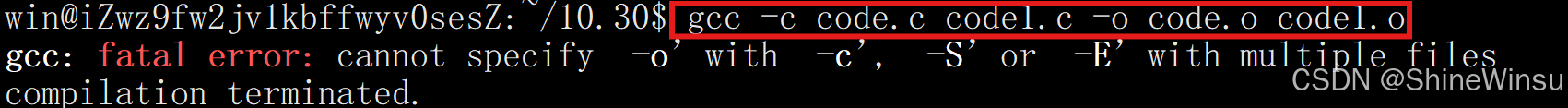 很明显,就会报错,那么怎么处理呢?
很明显,就会报错,那么怎么处理呢?
| 错误原因分析 | 解决方法 |
|---|---|
当使用-c(生成目标文件)、-S(生成汇编文件)、-E(生成预处理文件)时,若同时编译多个源文件并指定单个-o输出,GCC 无法为多个源文件分配同一个输出文件,因此报错。 |
1. 若需编译多个源文件并生成各自的中间文件:去掉-o选项,GCC 会为每个源文件生成同名中间文件(如a.c生成a.o)。示例:gcc -c a.c b.c(生成a.o和b.o) 2. 若需为每个源文件指定输出名:分别编译,逐个指定-o。示例:gcc -c a.c -o a.o``gcc -c b.c -o b.o |
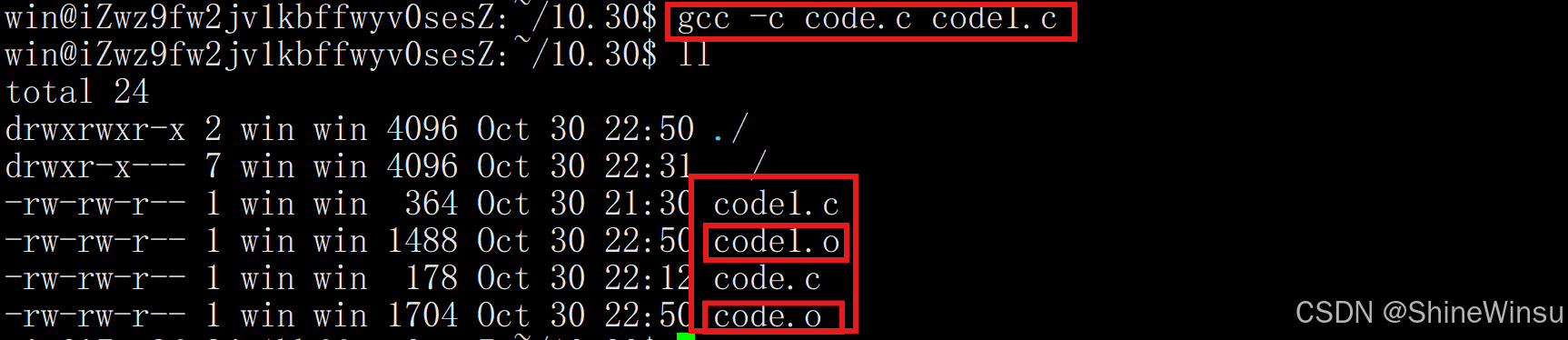
然后我们就可以将两个汇编文件(.o)进行链接生成统一为一个程序,即将两个文件进行合并: OK,可以看到,失败了,是因为我们两个源文件里都有main主函数,所以失败,但是,我的指令还是对的,所以,各位,不妨大家自己去试试吧,哈哈,我就不继续写了,没什么意义,还是需要大家自己去尝试,毕竟纸上得来终觉浅,绝知此事要躬行。
OK,可以看到,失败了,是因为我们两个源文件里都有main主函数,所以失败,但是,我的指令还是对的,所以,各位,不妨大家自己去试试吧,哈哈,我就不继续写了,没什么意义,还是需要大家自己去尝试,毕竟纸上得来终觉浅,绝知此事要躬行。
所以总结一下流程就是
一、单个文件的流程
-
编译生成.o 文件 :将单个源文件(如
hello.c)编译为二进制目标文件(.o),命令为:gcc -c hello.c -o hello.o作用:完成 "预处理→编译→汇编" 阶段,生成可复用的二进制目标文件。
-
链接生成可执行程序 :将
.o文件链接为可执行程序,命令为:gcc hello.o -o hello作用:整合目标文件与系统库,生成可直接运行的程序。
二、多个文件的流程
以a.c(模块 A)、b.c(模块 B)、main.c(主模块)为例:
-
分别编译每个源文件为.o 文件:
gcc -c a.c -o a.o gcc -c b.c -o b.o gcc -c main.c -o main.o作用:每个源文件独立编译,生成各自的二进制目标文件,实现模块解耦。
-
链接所有.o 文件为可执行程序:
gcc a.o b.o main.o -o program作用:整合所有模块的二进制代码,生成完整可执行程序。
这种 "先编译为.o 再链接" 的流程,核心优势是模块化开发、编译效率优化、代码复用 (单个.o可被多个项目共享),同时便于错误隔离与调试。
OK到了,这里,我们的本篇博客也就差不多结束啦各位
结语:以工具为翼,赴 Linux 开发之约
亲爱的读者朋友们,当你看到这里时,这篇关于 Linux 基础开发工具的博客也终于画上了圆满的句号。从开篇对 Linux 开发的满心期待,到一步步深入软件包管理器、vim 编辑器、gcc/g++ 编译工具的核心用法,我们一起走过了一段从 "初识" 到 "精通" 的探索之旅。此刻,或许你还在回味 vim 模式切换的巧妙,或许还在熟悉 gcc 编译的四阶段流程,又或许已经迫不及待地想要在终端里敲下第一行代码 ------ 无论你正处于哪个状态,都想先对你说一句:辛苦了,也恭喜你!你已经迈出了 Linux 开发路上最关键的一步。
回望整篇博客的内容,我们其实一直在搭建一个 "Linux 开发基础工具箱"。软件包管理器 apt 就像我们的 "工具采购站",让我们能便捷地获取开发所需的各类软件,无需纠结于源码编译的繁琐,一个命令就能搞定安装、更新与卸载;vim 编辑器则是我们的 "代码创作画布",模式化的设计看似复杂,实则暗藏高效编辑的玄机 ------ 命令模式的精准移动、插入模式的专注输入、末行模式的全局控制、视图模式的批量操作,再加上那些实用的注释技巧和快捷键,让我们能在终端里游刃有余地编写、修改代码;而 gcc/g++ 编译器与链接、库的知识,就是我们的 "代码转化引擎",从预处理的宏替换到编译的汇编生成,从汇编的二进制转换到链接的模块整合,我们学会了如何将一行行高级语言代码,变成能在 Linux 系统上运行的可执行程序,更理解了模块化开发、编译效率优化的核心逻辑。
这些知识点看似独立,实则环环相扣,构成了一个完整的 Linux 开发基础流程:用 apt 安装好 vim 和 gcc,用 vim 编写代码,用 gcc 将代码编译链接为程序,再通过调试优化不断完善 ------ 这正是无数 Linux 开发者日常工作的缩影。或许在学习过程中,你曾为 vim 的模式切换感到困惑,一次次按错 Esc 键;也曾为 gcc 的编译选项记混,分不清 - E、-S、-c 的区别;还曾对静态链接与动态链接的概念感到抽象,难以理解 "库" 的本质。但请相信,这些困惑都是学习路上的必经之路,就像我们刚开始学用电脑时,也会分不清鼠标左键和右键的功能,熟练之后便会形成肌肉记忆。
我至今还记得自己第一次用 vim 写代码时的场景:明明想进入插入模式却误按了其他键,导致代码乱码;好不容易写完代码,却忘了末行模式的保存命令,急得满头大汗;编译时因为少写了 - o 选项,生成了默认的 a.out 文件,却不知道如何运行。但正是这些 "小失误",让我对这些工具的理解越来越深。所以,当你在实践中遇到问题时,不必焦虑,也不必气馁 ------ 这正是你在消化知识、形成自己理解的过程。多敲几遍命令,多试几次模式切换,多分析几次编译报错的原因,慢慢就会发现,vim 的快捷键越来越顺手,gcc 的编译流程越来越清晰,那些曾经看似复杂的知识点,都会在实践中变得豁然开朗。
在这里,想特别提醒大家:Linux 开发的核心魅力,就在于 "亲手掌控每一个细节"。apt 让我们学会了自主管理软件,vim 让我们摆脱了图形界面的束缚,gcc 让我们理解了代码从编写到运行的底层逻辑,而静态链接与动态链接、多文件编译的知识,则让我们具备了开发复杂项目的基础。这些能力不仅能帮助你完成简单的代码编写,更能培养你解决问题的逻辑思维 ------ 当你遇到编译报错时,能通过错误信息定位是语法问题还是链接问题;当你需要优化项目时,能根据需求选择静态链接或动态链接;当你与团队协作时,能通过模块化开发提高工作效率。这些思维能力,远比记住几个命令更为重要。
或许你会问:学会了这些基础工具,接下来还能做什么?答案是:无限可能。你可以用 vim 编写 Shell 脚本,自动化处理日常工作;可以用 gcc 编译 C/C++ 项目,开发系统工具或应用程序;可以深入学习 Makefile,实现项目的自动化编译;还可以探索 Git 版本控制,参与开源项目的协作。Linux 的世界广阔而精彩,这些基础工具就像一把把钥匙,能为你打开更多未知的大门。而我们今天所学到的,正是打开这些大门的第一步。
在学习技术的道路上,没有捷径可走,唯有 "坚持" 与 "实践"。vim 的快捷键需要反复练习才能熟练,gcc 的编译流程需要多次尝试才能吃透,链接与库的知识需要结合实例才能理解。希望你能把这篇博客当作一个起点,而不是终点 ------ 在未来的日子里,多给自己一些时间,多动手实践,把这些工具真正变成自己的 "拿手好戏"。当你某天能够不看手册就熟练使用 vim 编写代码,能够根据项目需求灵活运用 gcc 的编译选项,能够轻松处理多文件的链接问题时,你会发现,自己已经完成了从 "Linux 新手" 到 "合格开发者" 的蜕变。
还要记得,技术学习从来都不是一个人的旅程。如果在实践中遇到问题,不妨多查阅官方文档,多逛逛技术论坛,多和身边的开发者交流 ------ 或许别人的一句提醒,就能让你茅塞顿开。同时,也希望你能保持好奇心和求知欲,Linux 系统的迭代永不停歇,新的工具和技术也在不断涌现,唯有保持学习的热情,才能在技术的浪潮中不被淘汰。
最后,再次感谢你抽出时间阅读这篇博客,陪伴我一起探索 Linux 基础开发工具的奥秘。或许这篇博客的内容还有不足之处,或许有些知识点讲解得还不够透彻,但我始终希望,它能为你在 Linux 开发的路上提供一些帮助,为你点亮一盏明灯。
愿你带着今天所学的知识,在 Linux 的世界里大胆探索、勇敢实践,用终端里的一行行命令,编写属于自己的代码故事;愿你在遇到困难时不轻易放弃,在收获成果时不骄傲自满,始终保持对技术的敬畏与热爱;愿你在未来的开发路上,既能仰望星空,也能脚踏实地,一步步成为自己想要成为的开发者。
Linux 的世界,未来可期;而你的潜力,更是无限。现在,就打开终端,敲下第一行命令,开始你的 Linux 开发之旅吧!我们下次再见~