一、核心基础:key group 分片模型
在理解并行度变更时如何迁移 RocksDB 状态之前,必须先理解 Flink 把状态组织成"key group"的原因------这是整个机制的数学根基。
Flink 不直接把 key 分配给 SubTask,而是先把全部 key 空间用 MurmurHash(key) % maxParallelism 映射到 [0, maxParallelism) 个 key group,再把这些 key group 连续地均分给各 SubTask。maxParallelism 是作业启动时固定的上界(默认 128,可配置),它在整个作业生命周期内永不变更。
并行度变化时,只有 key group 的分配关系在变,key group 本身和 key 到 key group 的映射均不变,这使得任意并行度调整都能通过切割/合并 key group 区间来完成,无需重新哈希任何一条数据。
二、RocksDB 中的状态组织方式
RocksDB 的每个 Column Family 对应一个 Flink State(如一个 ValueState<Long>)。每条记录的 Key 编码格式为:
[key_group (2B)] [key_serialized] [namespace_serialized]key group 字节放在最前面,这使得 RocksDB 的物理排列天然按 key group 有序------这是状态迁移能高效切割的物理基础。Checkpoint 写入 HDFS/S3 时,RocksDB 会为每个 key group 区间生成独立的 SST 文件集,每个文件都携带元数据标注它属于哪个 key group 范围。

三、扩容流程:并行度 p₁ → p₂(p₂ > p₁)
扩容是最常见的场景。原来每个 SubTask 管理较大的 key group 区间,扩容后每个 SubTask 只负责更小的区间,需要把原 SubTask 的 SST 文件"拆分"分发给多个新 SubTask。
关键点:这个拆分不需要重写任何 KV 数据 ------新 SubTask 直接下载包含目标 key group 范围的 SST 文件,然后在本地通过 IngestExternalFile 导入,Flink 的 KeyGroupRangeOffsets 元数据告诉 RocksDB 只扫描属于自己的 key group 前缀即可。

扩容时有一个很多人没意识到的细节:新 SubTask 下载的 SST 文件里包含的 key group 可能多于它需要的(因为原来的 SST 文件是按整个旧 SubTask 的 key group 范围打包的)。新 SubTask 会先把整个 SST 文件 ingest 进本地 RocksDB,读写时只操作自己 key group 范围内的前缀,多余的数据通过后台 compaction 逐步清理,不影响正确性和可用性。
四、缩容流程:并行度 p₁ → p₂(p₂ < p₁)
缩容与扩容是镜像关系:原来多个 SubTask 各持有一片 key group,现在要合并给更少的 SubTask。每个新 SubTask 需要从多个旧快照中分别下载对应的 SST 文件,然后合并导入同一个 RocksDB 实例。
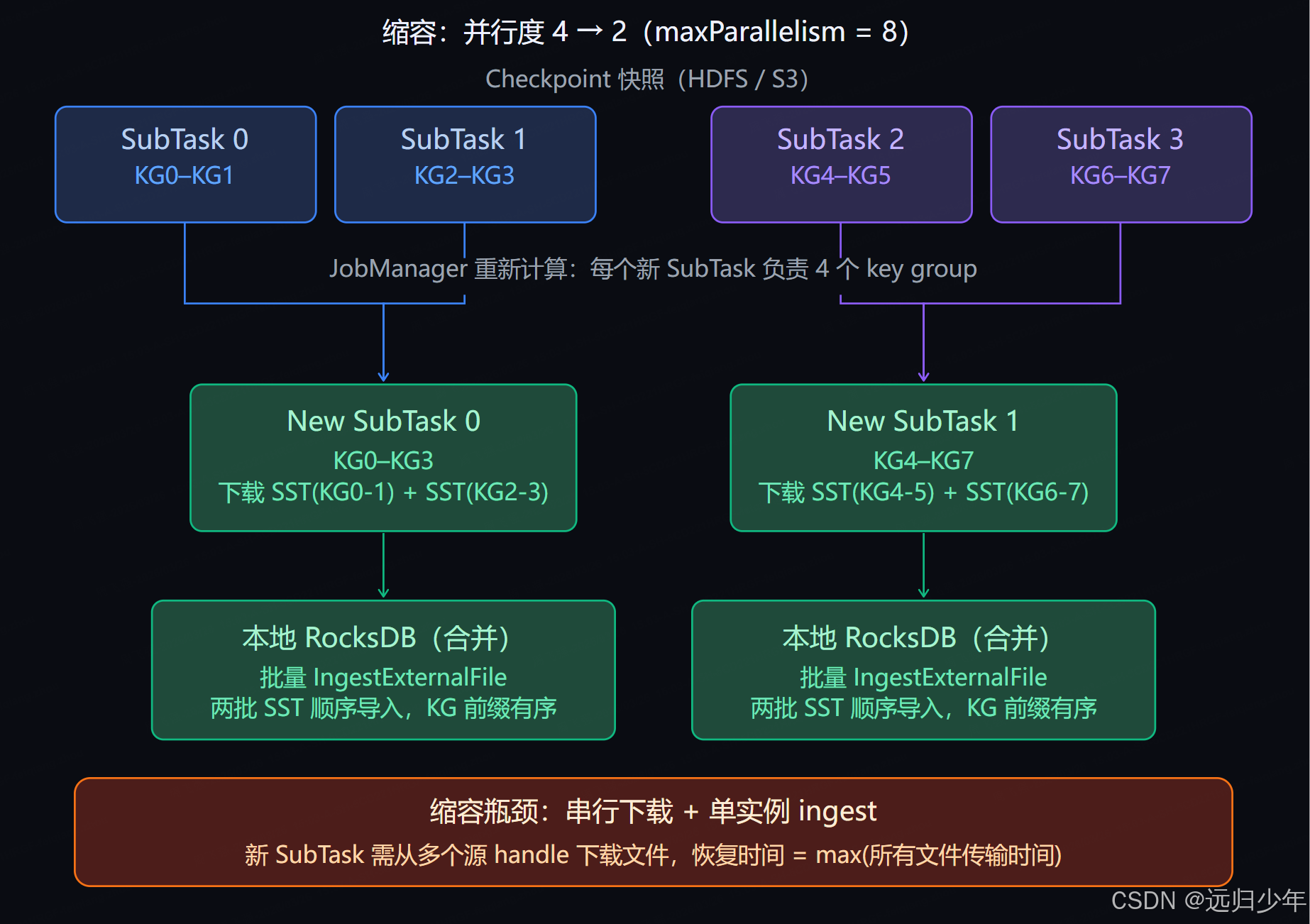
缩容和扩容有一个不对称之处值得特别注意:扩容时多个新 SubTask 可以并行 下载同一份 SST 文件(只读),互不干扰;而缩容时每个新 SubTask 需要串行地把多份来自不同旧 SubTask 的 SST 文件 ingest 到同一个 RocksDB 实例,存在单点聚合的串行瓶颈,状态越大、旧并行度越高,恢复时间就越长。
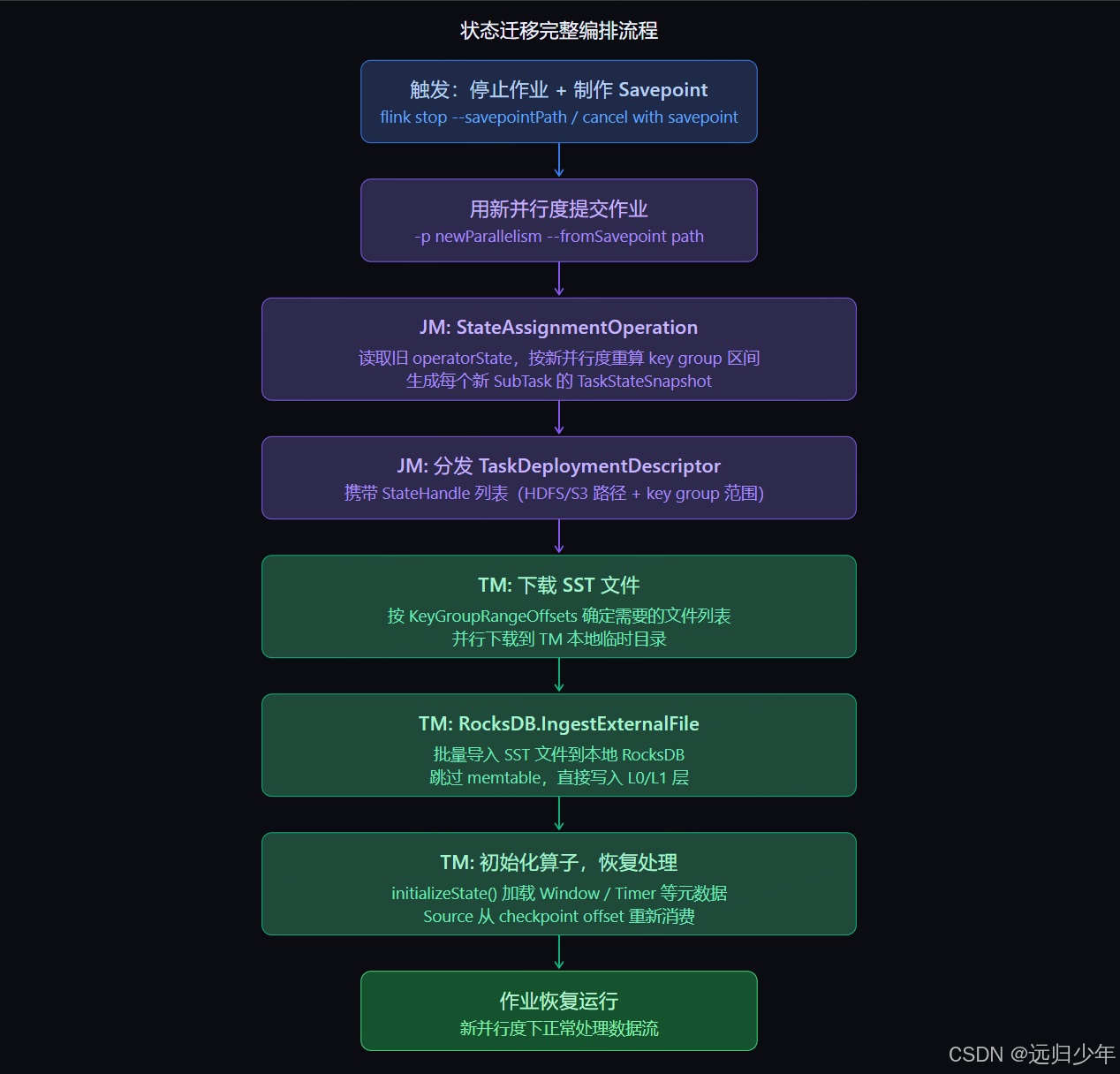
五、完整状态迁移编排流程
从 Savepoint/Checkpoint 触发到新 SubTask 完成状态加载,整个过程由 JobManager 的 CheckpointCoordinator 和 StateAssignmentOperation 协同编排。
六、增量 Checkpoint 下的特殊处理
增量 Checkpoint 使问题更复杂。增量模式下 RocksDB 只上传新增的 SST 文件,每次快照的 StateHandle 不是一个完整镜像,而是一棵 SST 文件的增量树。并行度变更时,JobManager 需要沿引用链回溯,找到覆盖目标 key group 范围所需的所有增量 SST 文件(可能跨越多个历史 Checkpoint),然后按从旧到新的顺序依次 ingest,让 RocksDB 的 compaction 把它们合并成最终一致的状态。
这就是为什么大状态 + 增量 Checkpoint + 高频调整并行度会显著拖慢恢复时间------每次都要重建完整的 SST 文件依赖链。
七、maxParallelism 约束与常见陷阱
这是生产中最容易踩的坑,值得单独说明:
maxParallelism 一旦在作业首次启动时确定(通过 env.setMaxParallelism(N) 或默认值 128),就永久固化在 Savepoint 元数据里 。如果用新的 maxParallelism 值重启作业,Flink 会拒绝从旧 Savepoint 恢复,因为整个 key group 分片方案已经失效。
java
env.setMaxParallelism(512); // 设置为预期最大并行度的 2--3 倍
env.setParallelism(4); // 实际并行度可以远低于 maxParallelism
// 调整并行度时只改这里,maxParallelism 保持不变
env.setParallelism(8);核心原则:maxParallelism 决定分片粒度上限,实际并行度必须 ≤ maxParallelism,并行度变更完全在这个范围内进行,不触碰 maxParallelism。
八、Operator State 的迁移策略
上述所有分析针对的是 KeyedState。OperatorState(如 Kafka Source 的 offset、ListState)没有 key group 概念,并行度变更时有两种策略:
ListState 使用 even split :把旧并行度的所有 ListState 条目收集到一起,按轮询方式均分给新的各 SubTask。UnionListState 使用 broadcast:每个新 SubTask 都获得全量的旧状态列表,自行决定使用哪部分(常用于广播配置)。
总结来看,Flink 并行度变更时的状态迁移能做到相对高效,根本原因在于三个设计决策的组合:key group 作为稳定的中间层屏蔽了 key 到 SubTask 的直接绑定;RocksDB 的 key_group 前缀排列使 SST 文件天然可按范围切割;以及 IngestExternalFile 绕过 memtable 直接写入 L0 层从而实现高速批量导入。这三者缺一不可。