一、操作环境
| 系统 | gpu型号 | 英伟达驱动 | cudpython | python |
|---|---|---|---|---|
| ubuntu-22.04 | A100 | 570.153.02 | 12.8 | 3.10 |
二、基础环境配置(相当于给服务器"装基础软件")
注释:这里还需安装英伟达驱动和cuda可以翻看我之前博客 python环境也需要大家提前准备好
cs
1.更新软件商店的货品清单
sudo apt update
2.安装常用工具(相当于给工人配工具箱)
apt install -y build-essential cmake openssh-server net-tools htop nvme-cli
# build-essential:代码编译工具
# cmake:项目构建工具
# openssh-server:远程登录服务
# net-tools:网络诊断工具
# htop:任务管理器
# nvme-cli:SSD硬盘管理工具
3.禁用开源驱动 Nouveau
sudo vim /etc/modprobe.d/blacklist.conf
添加一下内容
blacklist nouveau
options nouveau modeset=0
4.保存后执行
sudo update-initramfs -u
sudo reboot
5.重启后验证是否禁用成功(无输出即成功)
lsmod | grep nouveau三、配置高速网络(相当于铺设专用高速公路)
1.安装网卡组件
cpp
1.安装RDMA通信组件
sudo apt install -y rdma-core ibverbs-utils infiniband-diags
2.验证InfiniBand状态:
ibstatus # 应该看到"LinkUp"状态2.进行单机8卡通信测试(相当于测试8个工人之间的协作效率)
cs
1.下载测试工具包
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
2.编译测试程序(需要MPI支持,相当于指挥多个GPU的指挥系统)
make MPI=1 MPI_HOME=自己的mpi_home目录
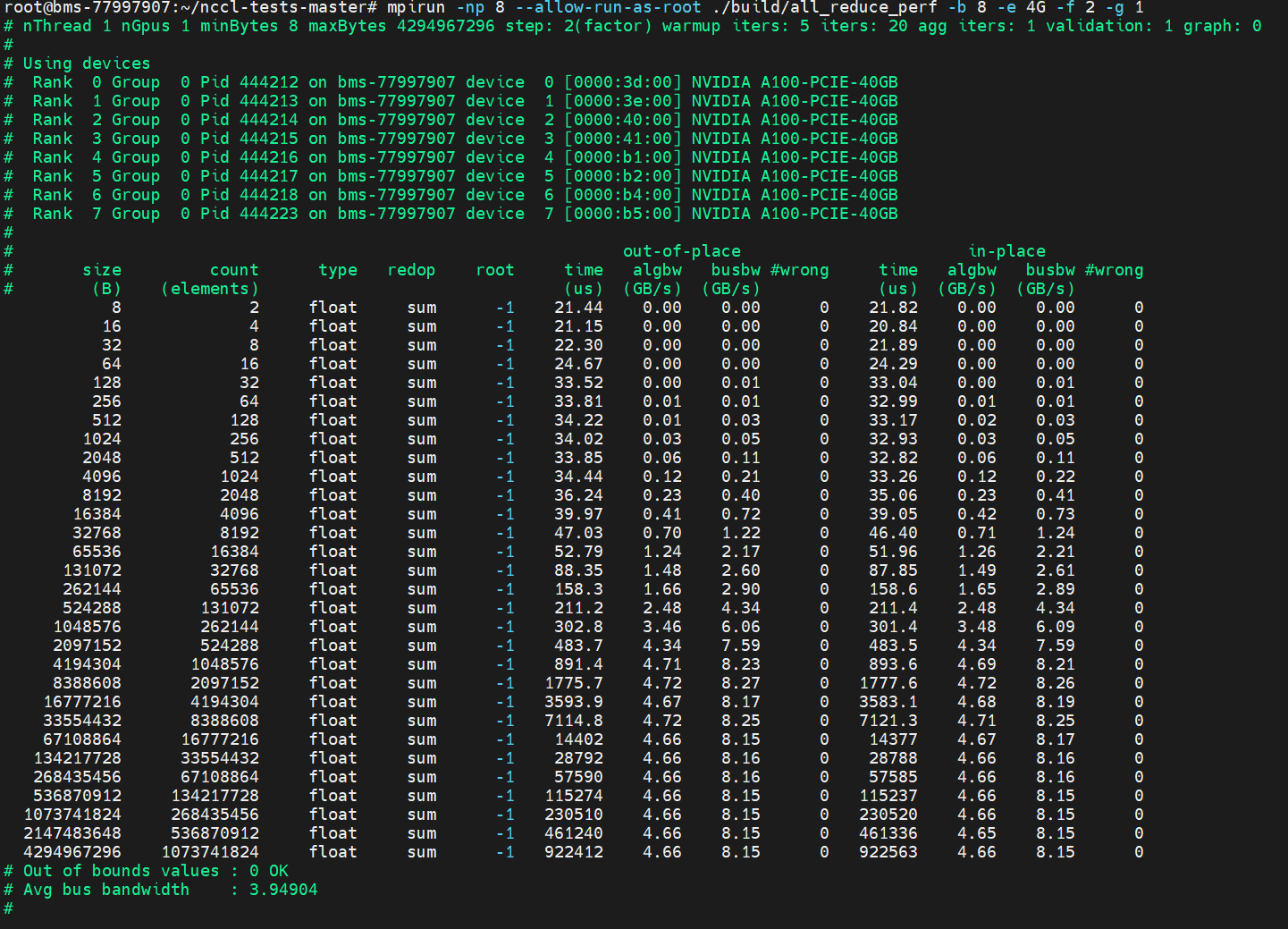
3.运行测试(测试所有GPU之间的数据交换速度)
# -np 8:使用8个进程(对应8张GPU)
mpirun -np 8 --allow-run-as-root ./build/all_reduce_perf -b 8 -e 4G -f 2 -g 1
# 参数说明:
# -b 8:从8MB数据量开始测试
# -e 4G:最大测试到4GB数据量
# -f 2:每次数据量翻倍
# -g 1:每个进程使用1个GPU出现以下显示表示成功
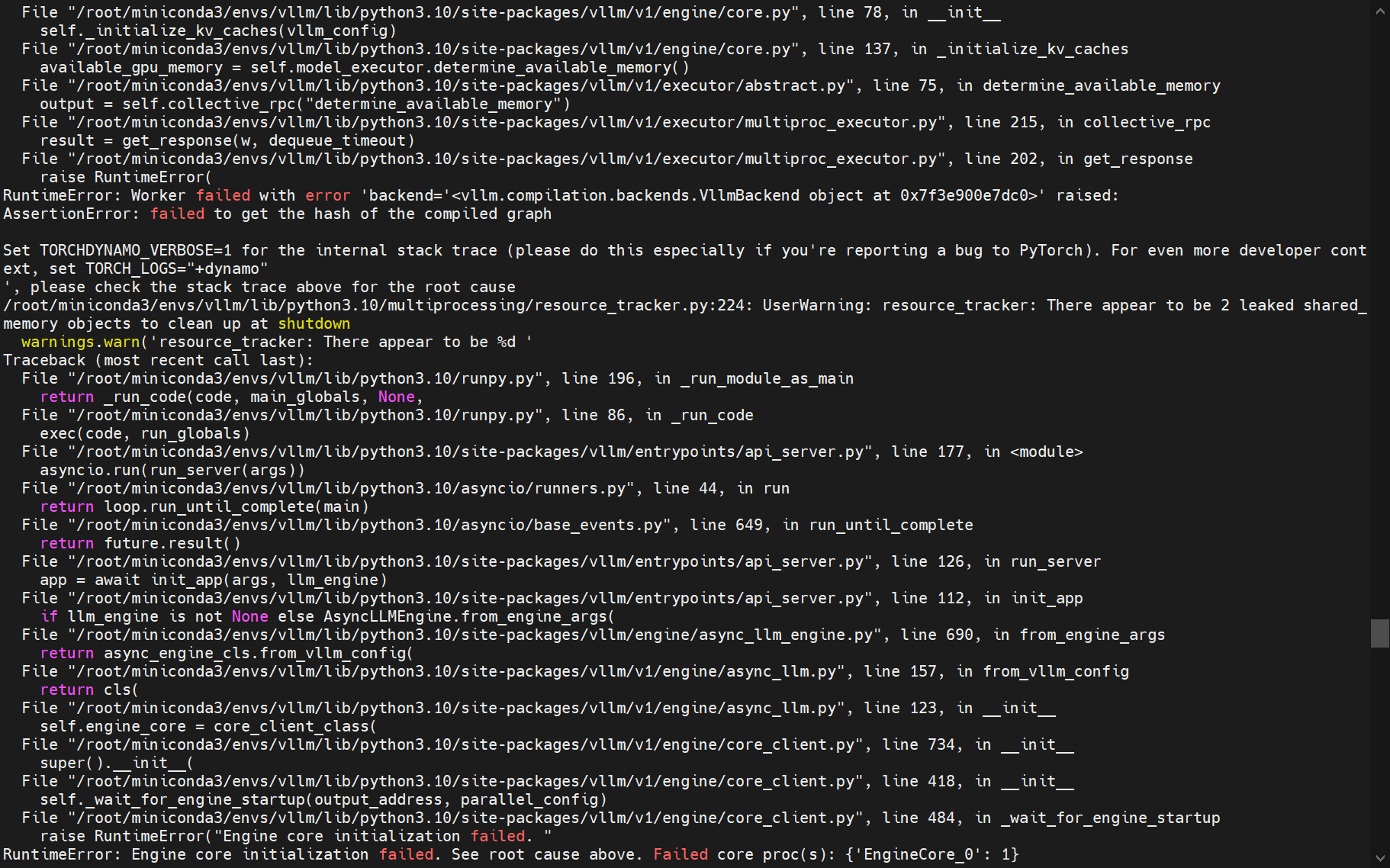
四、nccl-tests编译问题解决
1.如果在安装过程中遇到找不到nccl.h文件解决方案
进入英伟达官网安装提示安装libnccl-dev和libnccl2。官网链接:Log in | NVIDIA Developer
我这里采用的网络安装方式(系统版本是22.04的)根据官网提示根据自身需求选择匹配的安装方式
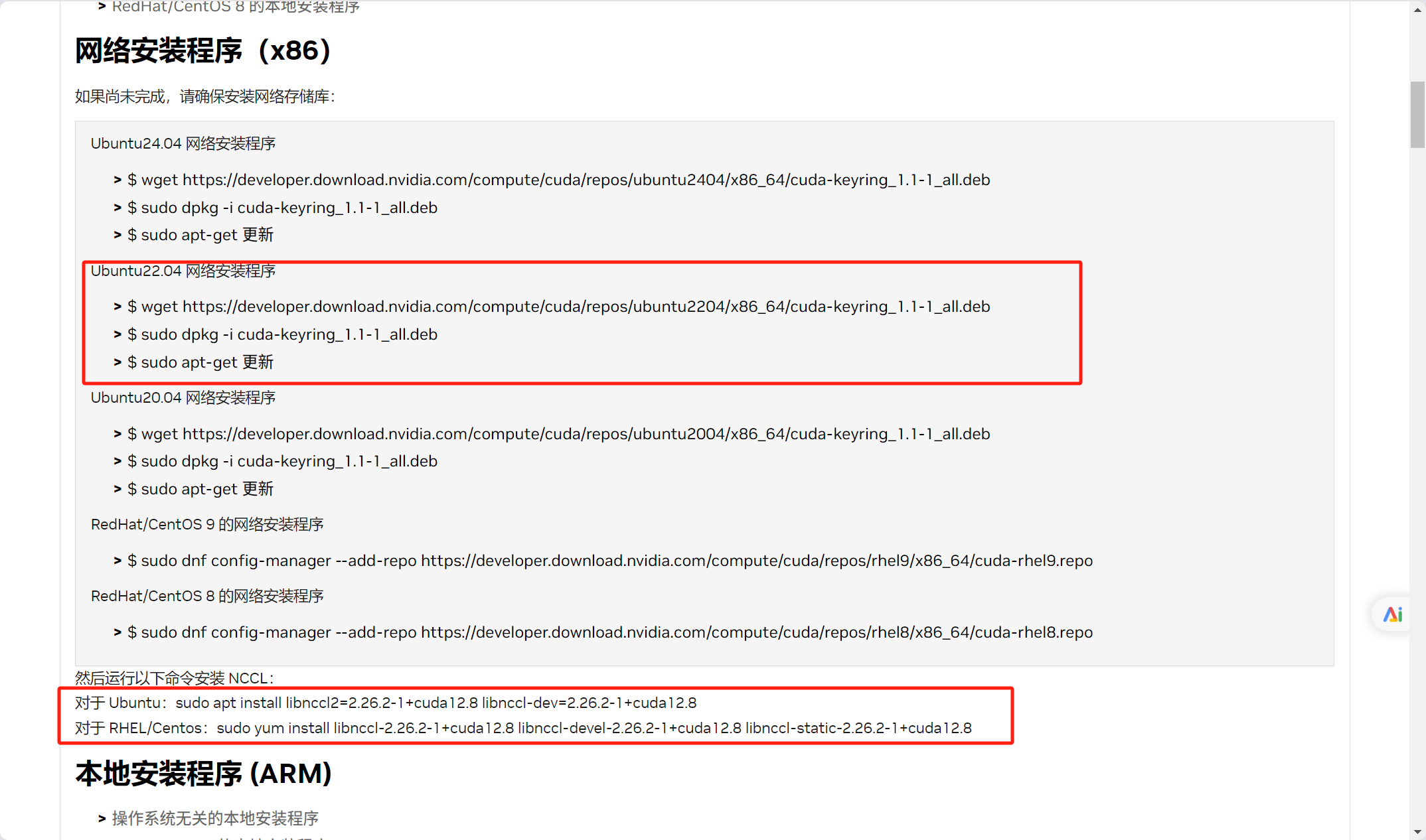
2.如果在安装过程中遇到找不到mpi.h文件解决方案
cs
1.安装对应组件
apt-get install openmpi-bin openmpi-common libopenmpi-dev
2.验证安装
mpicc --version
3.重新编译 我的mpi_home目录在/usr/lib/x86_64-linux-gnu/openmpi
make MPI=1 MPI_HOME=/usr/lib/x86_64-linux-gnu/openmpi五、GPU压力测试(相当于让GPU做极限体能测试)
cs
1.下载测试工具
git clone https://github.com/wilicc/gpu-burn
cd gpu-burn
2.编译程序
make
3.运行测试(让所有GPU满载运行1小时)
./gpu_burn -d 3600
# 观察输出:所有GPU应该显示"OK",温度会逐渐升高但不超过安全阈值六、安装conda(Python环境管理器)和推理引擎
cpp
# 第一步:安装conda(Python环境管理器)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b
添加环境变量
export PATH="/root/miniconda3/bin:$PATH"
source ~/.bashrc
初始化conda
首次使用 Conda 时,建议初始化(会自动修改终端配置文件,方便直接使用 conda 命令)
conda init bash # 执行后关闭当前终端,重新打开即可生效
# 第二步:创建专用环境
conda create -n vllm python=3.10 -y
conda activate vllm
# 第三步:安装推理引擎
pip install vllm七、下载模型
可以去魔搭社区去寻找阿里通义千问模型当然大家后期也可以在社区寻找其他模型。网站链接:ModelScope魔搭社区
注释:社区提供了多种下载方式,个人不太建议git clone方式下载很容易失败。如果是个人买的云服务器建议nohup方式运行否则容易因为带宽打满会出现ssh断开情况
cpp
在下载前,请先通过如下命令安装ModelScope
pip install modelscope
下载完整模型库
modelscope download --model Qwen/Qwen3-32B八、运行模型
cs
直接运行命令支持模型部署完毕
vllm server "/root/qwen3/" --tensor-parallel-size 8
参数解析:
tensor-parallel-size 设置显卡数量根据自己的环境修改
/root/qwen3 是我自己模型的存放路径根据自己的去修改
验证模型是否可用
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "user", "content": "你好"}
],
"max_tokens": 512,
"temperature": 0.7,
"stream": false
}'九、运行模型特别注意
我运行模型报错经排查是版本不兼容问题在安装vllm的时候会自动安装torch torchvision torchaudio三个插件
可以运行命令查看我们的torch版本和兼容的cuda版本
运行这两条命令发现我们的torch和兼容的cuda是12.6版本而我们的cuda是12.8版本
(vllm) root@bms-77997907:~# python -c "import torch; print(torch.__version__)"
2.7.0+cu126
(vllm) root@bms-77997907:~# python -c "import torch; print(torch.version.cuda)"
12.6解决方案
cpp
1.卸载原有版本
pip uninstall torch torchvision torchaudio
2.安装兼容cuda12.8版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
3.再次运行查看是否兼容cuda12.8版本
(vllm) root@bms-77997907:~# python -c "import torch; print(torch.__version__); print(torch.version.cuda)"
2.7.0+cu128
12.8
发现输出12.8代表兼容12.8版本重新运行我们的大模型