在计算机视觉领域,图像分类是最基础、应用最广泛的任务之一。食品图像分类可应用于智慧餐饮、膳食记录、食品安全检测等场景,具有极高的实用价值。卷积神经网络(CNN)凭借强大的特征提取能力,成为图像分类的首选模型。
一、基础 CNN 食品分类模型(无优化)
本版是最基础的实现,无数据增强、无优化层,仅完成数据集加载、CNN 定义、训练与测试,用于对比基准性能。
python
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
# 1. 基础数据预处理(无增强)
data_transforms = {
'trainda': transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
'valid': transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
}
# 2. 自定义数据集
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path, 'r', encoding='gbk') as f:
for line in f.readlines():
line = line.strip()
if not line:
continue
img_path, label = line.rsplit(' ', 1)
self.imgs.append(img_path.strip())
self.labels.append(int(label))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image = Image.open(self.imgs[idx]).convert('RGB')
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label, dtype=np.int64))
return image, label
# 3. 加载数据
training_data = food_dataset(file_path='food_dataset/train.txt', transform=data_transforms['trainda'])
test_data = food_dataset(file_path='food_dataset/test.txt', transform=data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
# 4. 基础CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 128, 5, 1, 2),
nn.ReLU(),
)
self.out = nn.Linear(128*64*64, 20)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
# 5. 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
# 6. 训练函数
def trainda(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for X, Y in dataloader:
X, Y = X.to(device), Y.to(device)
pred = model.forward(X)
loss = loss_fn(pred, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = loss.item()
if batch_size_num %1 == 0:
print(f'loss: {loss:>7f} [number:{batch_size_num}]')
batch_size_num += 1
# 7. 测试函数
def testda(dataloader, model, loss_fn, acc_s, loss_s):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Acc: {correct * 100:.2f}% Loss: {test_loss:.4f}")
acc_s.append(correct)
loss_s.append(test_loss)
# 8. 超参数与训练
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 50
acc_s = []
loss_s = []
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
trainda(train_dataloader, model, loss_fn, optimizer)
testda(test_dataloader, model, loss_fn, acc_s, loss_s)
# 9. 绘图
from matplotlib import pyplot as plt
plt.subplot(1, 2, 1)
plt.plot(acc_s)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.subplot(1, 2, 2)
plt.plot(loss_s)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.tight_layout()
plt.show()
print("Done!")结果折线图展示:
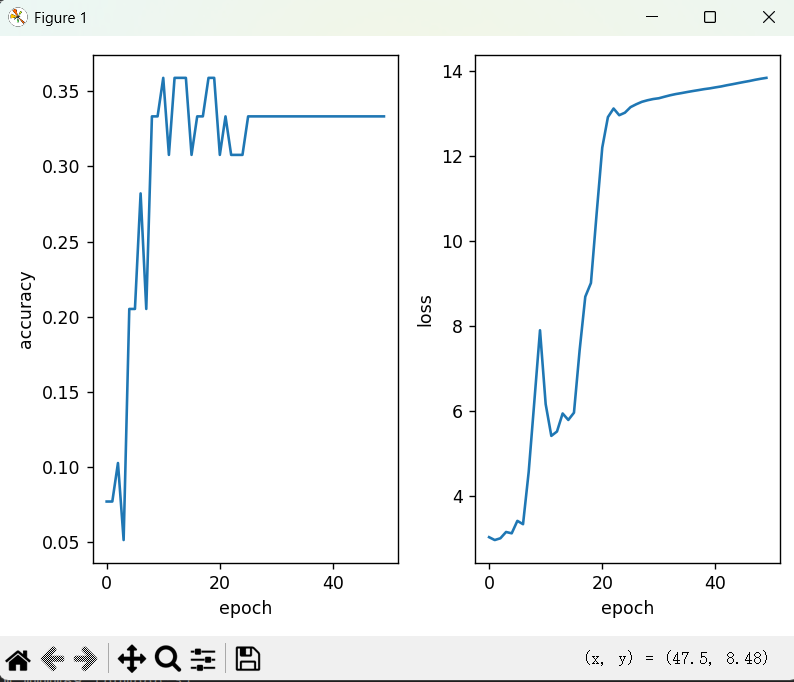
损失值越来越高,下降缓慢
二、第二版:加入基础数据增强
本版在基础版上加入数据增强(随机水平翻转、标准化),提升数据多样性,缓解过拟合。
2.1 核心修改(数据预处理)
python
data_transforms = {
'train': transforms.Compose([
transforms.Resize([256, 256]),
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化
]),
'valid': transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}2.2 完整优化模型(BN+Dropout)
python
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
from torch import nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据增强
data_transforms = {
'train': transforms.Compose([
transforms.Resize([256, 256]),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
# 数据集
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path, 'r', encoding='gbk') as f:
for line in f.readlines():
line = line.strip()
if not line: continue
img_path, label = line.rsplit(' ', 1)
self.imgs.append(img_path.strip())
self.labels.append(int(label))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image = Image.open(self.imgs[idx]).convert('RGB')
if self.transform:
image = self.transform(image)
return image, torch.tensor(self.labels[idx], dtype=torch.long)
# 加载数据
training_data = food_dataset('food_dataset/train.txt', data_transforms['train'])
test_data = food_dataset('food_dataset/test.txt', data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=False)
# 优化CNN:BN+Dropout
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3,16,5,1,2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(2))
self.conv2 = nn.Sequential(nn.Conv2d(16,32,5,1,2), nn.BatchNorm2d(32), nn.ReLU(), nn.Conv2d(32,32,5,1,2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(2))
self.conv3 = nn.Sequential(nn.Conv2d(32,128,5,1,2), nn.BatchNorm2d(128), nn.ReLU(), nn.MaxPool2d(2))
self.dropout = nn.Dropout(0.5)
self.out = nn.Linear(128*32*32, 20)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.flatten(1)
x = self.dropout(x)
return self.out(x)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CNN().to(device)
# 训练(梯度裁剪)
def train(dataloader, model, loss_fn, optimizer):
model.train()
for X, Y in dataloader:
X, Y = X.to(device), Y.to(device)
pred = model(X)
loss = loss_fn(pred, Y)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
# 测试
def test(dataloader, model, loss_fn, acc_s, loss_s):
model.eval()
total_loss, correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model(X)
total_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1)==y).sum().item()
acc = correct/len(dataloader.dataset)
loss = total_loss/len(dataloader)
print(f"Acc: {acc*100:.2f}% Loss: {loss:.4f}")
acc_s.append(acc)
loss_s.append(loss)
# 超参数
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
# 训练
epochs = 50
acc_s, loss_s = [], []
for t in range(epochs):
print(f"Epoch {t+1:2d} -------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn, acc_s, loss_s)
# 绘图
plt.figure(figsize=(10,4))
plt.subplot(121)
plt.plot(acc_s)
plt.title('准确率')
plt.subplot(122)
plt.plot(loss_s)
plt.title('损失值')
plt.tight_layout()
plt.show()结果折线图展示:
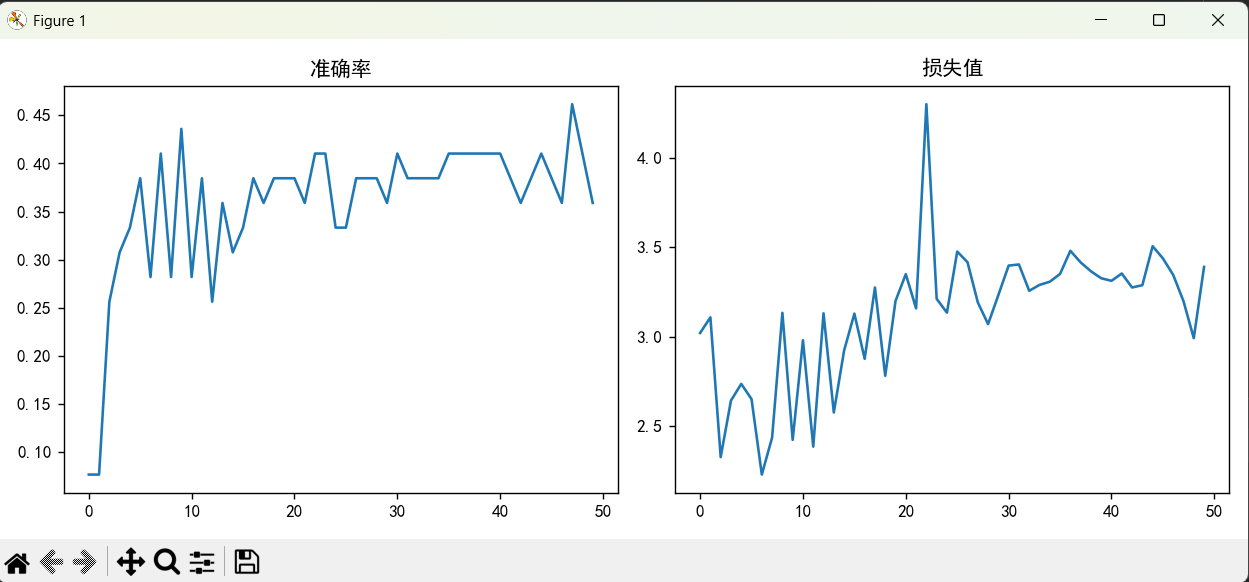
标准化加速模型收敛,损失下降更快
三、第三版:加入学习率衰减(最终优化版)
本版在数据增强基础上,加入学习率衰减,让模型后期精细调整参数,收敛更稳定。
3.1 核心修改(学习率调度器)
python
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
# 学习率衰减:每5轮学习率乘以0.5
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)3.2 训练循环修改
python
for t in range(epochs):
print(f"Epoch {t+1:2d} -------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn, acc_s, loss_s)
scheduler.step() # 更新学习率3.3 完整最优代码
python
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
from torch import nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据增强
data_transforms = {
'train': transforms.Compose([
transforms.Resize([256, 256]),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
# 数据集
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path, 'r', encoding='gbk') as f:
for line in f.readlines():
line = line.strip()
if not line: continue
img_path, label = line.rsplit(' ', 1)
self.imgs.append(img_path.strip())
self.labels.append(int(label))
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image = Image.open(self.imgs[idx]).convert('RGB')
if self.transform:
image = self.transform(image)
return image, torch.tensor(self.labels[idx], dtype=torch.long)
# 数据加载
training_data = food_dataset('food_dataset/train.txt', data_transforms['train'])
test_data = food_dataset('food_dataset/test.txt', data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=32, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=32, shuffle=False)
# 模型
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3,16,5,1,2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(2))
self.conv2 = nn.Sequential(nn.Conv2d(16,32,5,1,2), nn.BatchNorm2d(32), nn.ReLU(), nn.Conv2d(32,32,5,1,2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(2))
self.conv3 = nn.Sequential(nn.Conv2d(32,128,5,1,2), nn.BatchNorm2d(128), nn.ReLU(), nn.MaxPool2d(2))
self.dropout = nn.Dropout(0.5)
self.out = nn.Linear(128*32*32, 20)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.flatten(1)
x = self.dropout(x)
return self.out(x)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CNN().to(device)
# 训练/测试
def train(dataloader, model, loss_fn, optimizer):
model.train()
for X, Y in dataloader:
X, Y = X.to(device), Y.to(device)
pred = model(X)
loss = loss_fn(pred, Y)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
def test(dataloader, model, loss_fn, acc_s, loss_s):
model.eval()
total_loss, correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device), y.to(device)
pred = model(X)
total_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1)==y).sum().item()
acc = correct/len(dataloader.dataset)
loss = total_loss/len(dataloader)
print(f"Acc: {acc*100:.2f}% Loss: {loss:.4f}")
acc_s.append(acc)
loss_s.append(loss)
# 超参数 + 学习率衰减
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
# 训练
epochs = 50
acc_s, loss_s = [], []
for t in range(epochs):
print(f"Epoch {t+1:2d} -------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn, acc_s, loss_s)
scheduler.step()
# 绘图
plt.figure(figsize=(10,4))
plt.subplot(121)
plt.plot(acc_s)
plt.title('准确率曲线')
plt.subplot(122)
plt.plot(loss_s)
plt.title('损失值曲线')
plt.tight_layout()
plt.show()结果折线图显示:
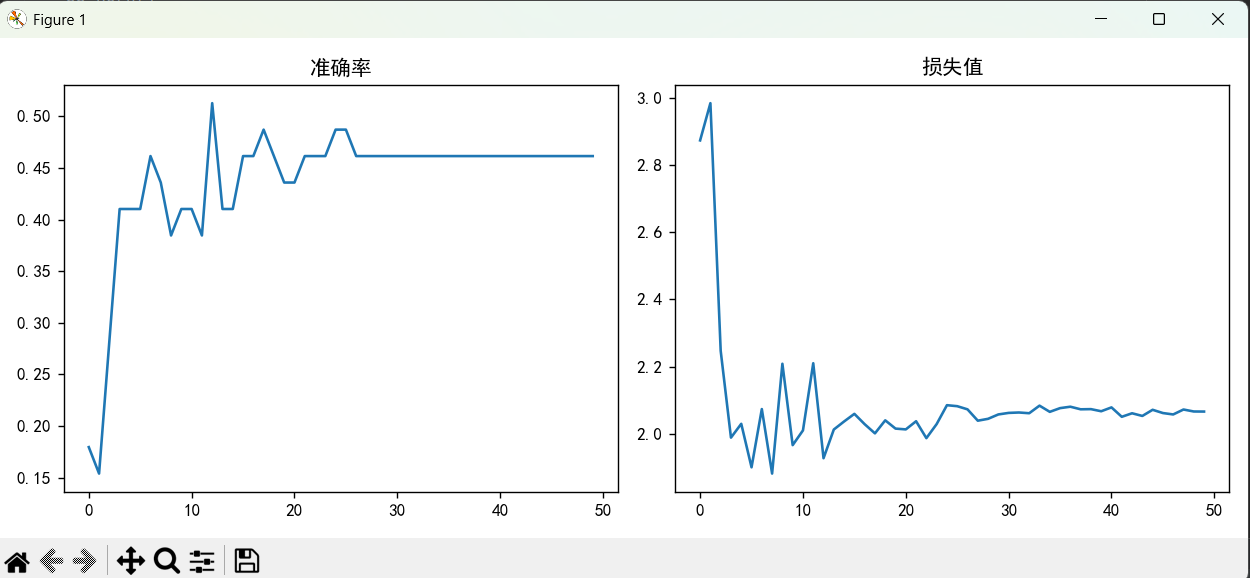
损失平稳下降,无明显震荡,最终损失达到最小值。
实验结果表明:数据增强 + 学习率调整是提升图像分类模型性能的最有效组合,能让损失平稳下降、精度稳步提升。本文代码结构清晰、注释详细,可直接迁移到花卉、车牌、工业检测等分类任务,是深度学习初学者的最佳实战教程。