Elasticsearch 数据写入核心流程
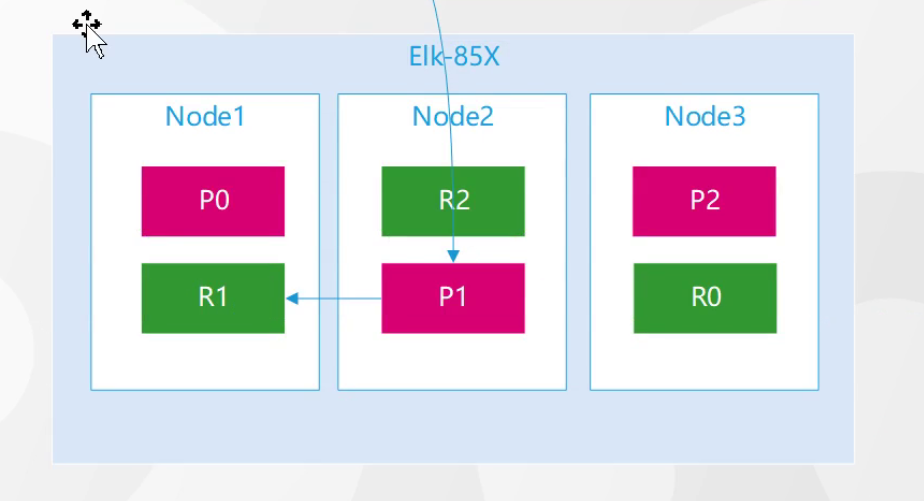
- 路由分片 :根据文档 ID(或自定义 routing)计算归属的主分片,确定数据要写入的分片位置;
- 请求转发:接收请求的协调节点,将写入请求转发到主分片所在的节点;
- 主分片写入 :
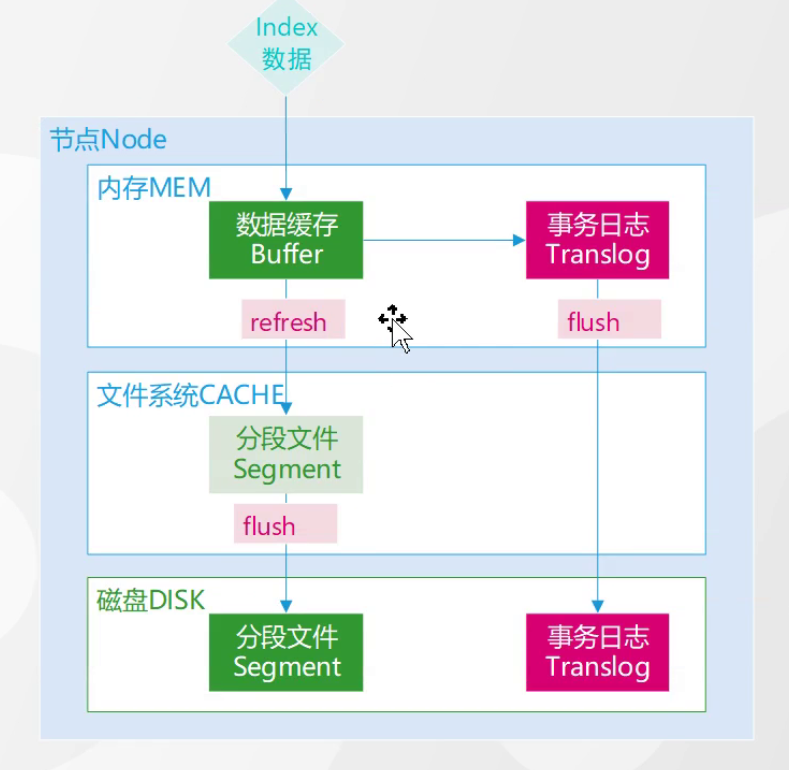
- 先写Translog(事务日志,追加写入磁盘,保证数据不丢失);
- 再写内存缓存(Memory Buffer),此时数据暂不可查询;
- 副本同步:主分片将写入请求同步到所有副本分片,副本分片重复「写 Translog + 内存缓存」操作,全部同步成功后反馈给主分片;
- 返回响应:主分片向协调节点返回成功,协调节点最终告知客户端写入完成;
- 刷新(Refresh) :默认 1 秒一次,将内存缓存中的数据生成不可变的 Segment(倒排索引段) 写入文件系统缓存,数据从此可被查询;
- 刷盘(Flush) :当 Translog 达到阈值 / 超时(默认 512MB/30 分钟),触发 Flush:
- 执行 Refresh 清空剩余内存缓存;
- 将所有 Segment 从文件系统缓存刷到磁盘(持久化);
- 清空 Translog;
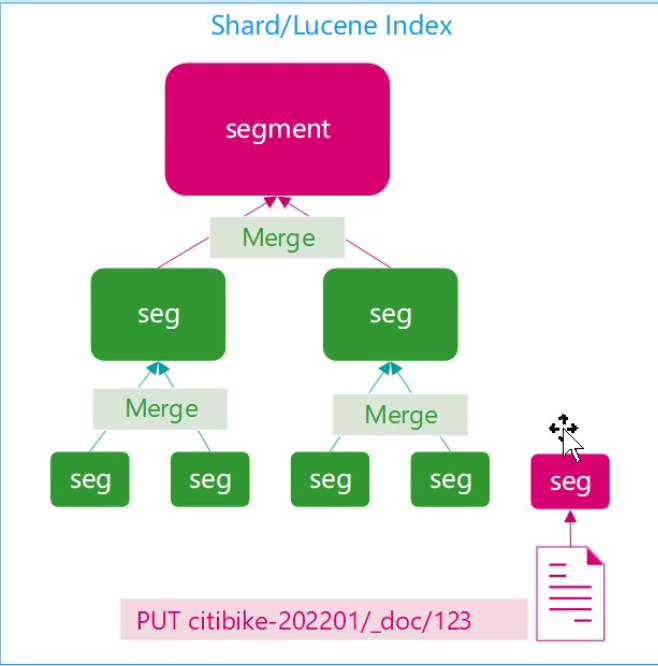
- 合并(Merge):后台异步合并多个小 Segment 为大 Segment,优化查询性能,合并后删除原小 Segment。
索引数据的写入方式:
单条写入:
PUT <index_name>/_doc/<doc_id>
{
<json源数据>
}同时我们也可以使用_create API,如果数据存在,就会创建失败,如果不存在就会创建.
PUT <index_name>/_create/<doc_id>
{
"json格式source数据"
}也可以使用post进行写入,并且使用post进行插入的时候,是可以不用指定id的
如果不指定id,就是直接进行插入操作
POST<index_name>/_doc
{
<json源数据>
}也可以指定id,这个就和PUT的操作是一样的了
POST <index_name>/_doc/<doc_id>
{
<json源数据>
}插入数据的一些参数:
refresh:时候再插入数据时,立即执行refresh操作,默认是1S,不执行refresh操作的话不可以立即查询的到
routing:执行数据具体写入到哪个分片中
wait_for_active_shards:等到多少个副本分片同步之后,向用户反馈执行结果
Elasticsearch 中 version + version_type 组合说明表
表格
| 组合使用方式 | 核心逻辑 | 适用场景 | 示例(HTTP 请求) |
|---|---|---|---|
version=N + internal |
ES 内置版本号,仅当文档当前版本等于 N 时执行操作(N 为正整数,ES 自增) | 普通并发控制,避免脏写(默认组合) | PUT /my_index/_doc/1?version=5&version_type=internal(仅版本 5 时更新) |
version=N + external |
自定义版本号,仅当指定版本 N 大于 文档当前版本时执行(N 可为时间戳 / 业务号) | 业务自定义版本,严格控制 "新版本覆盖旧版本" | PUT /my_index/_doc/1?version=1711234567890&version_type=external(时间戳版本) |
version=N + external_gte |
自定义版本号,仅当指定版本 N 大于等于 文档当前版本时执行 | 重试场景,允许相同版本重复执行操作 | PUT /my_index/_doc/1?version=1711234567890&version_type=external_gte(允许同版本更新) |
version是版本号数值 ,version_type是版本校验规则,两者必须配合使用才生效;- 若仅传
version不传version_type,ES 会默认使用internal规则; - 新增文档(文档不存在)时:
internal规则下version无效(ES 自动初始化为 1);external/external_gte规则下,version会被设为文档初始版本号。
批量写
使用_bulk API进行批量的写入。
POST _bulk
{"index":{"_index":"index_test","_id":1}}
{"name":"lihua","age":11,"class":"class01"}
{"index":{"_index":"index_test"}}
{"name":"lihua","age":11,"class":"class02"}LogStash工具进行数据写入
敬请期待
数据的删除
这里需要注意的是es使用的是标记删除,等到下次写入到磁盘的时才会真正的删除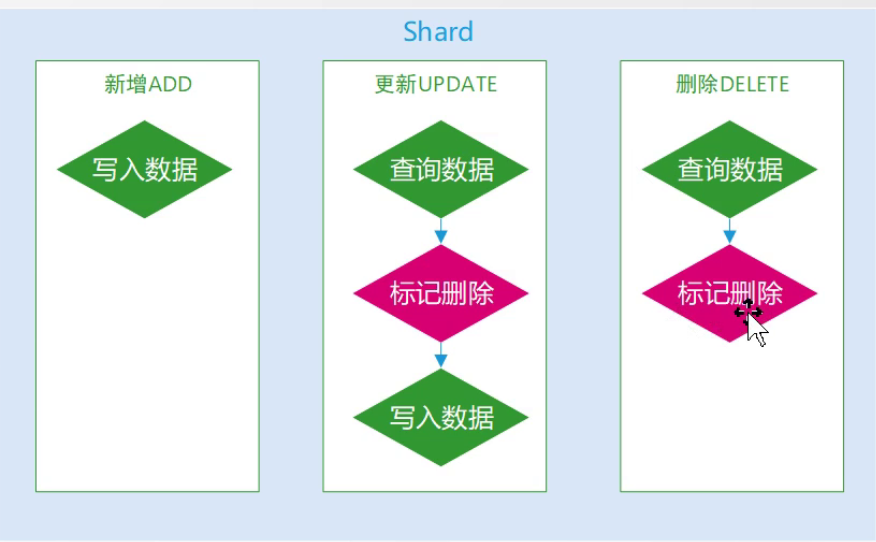
批量删除
通过bulk API进行删除
POST _bulk
{"delete":{"_index":"index_test","_id":"1"}}条件删除
wait_for_completion 参数核心含义
wait_for_completion 是 Elasticsearch 中用于控制长耗时操作是否同步等待完成 的布尔型参数,常见于 _reindex、_snapshot、_restore、delete_by_query 等 API 中。
✅ 两种取值与行为
表格
| 取值 | 含义 | 适用场景 |
|---|---|---|
true(默认) |
请求会阻塞客户端,一直等到操作完全完成后才返回结果。 | 操作耗时较短、需要立即获取最终结果的场景。 |
false |
请求会立即返回,同时生成一个后台任务 ID,操作在集群后台异步执行。 | 操作耗时很长(如大批量重索引、快照备份),避免客户端长时间挂起超时。 |
我们在进行大批量的条件删除,通过参数设置
对于条件删除使用的API是:
POST index_test/_delete_by_query?wait_for_completion=false
{
"track_total_hits":true,
"query":{
"match":{
"name":"lihua"
}
}
}
查询条件删除的结果,这种异步删除的方式是比较推荐的
GET _tasks/XvLWaMoHSNKblvuPicgA0A:116667