
文章信息

论文题目为《Efficient Multivariate Time Series Forecasting via Calibrated Language Models with Privileged Knowledge Distillation》,发表于数据工程领域的CCF-A会议IEEEICDE2025。该研究针对传统时间序列预测模型在跨变量依赖建模能力有限、难以利用外部知识以及预测性能受限等问题,提出了一种融合大语言模型与知识蒸馏的预测框架。


摘要

多变量时间序列预测(MTSF)致力于在给定历史数据的前提下预测未来观测值,在时间序列数据管理系统中扮演着关键角色。随着大语言模型的发展,近期研究通过文本提示调优的方式,将大语言模型的知识注入到多变量时间序列预测任务中。然而,大语言模型的部署在推理阶段往往面临效率低下的问题。为解决这一问题,文章提出了TimeKD,一个高效的多变量时间序列预测框架,该框架融合了校准语言模型与特权知识蒸馏技术。TimeKD的目标是:从所提出的跨模态教师模型中生成高质量的未来表征,并训练出一个高效的学生模型。受特权信息学习范式的启发,跨模态教师模型采用了带有真实标签提示的校准语言模型。此外,文章设计了一种减法式交叉注意力机制,用于对这些表征进行精细化处理。为训练出高效的学生模型,文章提出了一种创新的特权知识蒸馏(PKD机制),其中包含相关性蒸馏与特征蒸馏两个模块。PKD能够让学生模型复刻教师模型的行为,同时最小化二者的输出差异。在真实数据集上开展的大量实验,充分验证了所提TimeKD模型的有效性、高效性与可扩展性。

贡献

(1)文章是首个将特权知识蒸馏应用于时间序列预测的系统性研究。文章提出了TimeKD,一个基于校准语言模型的高效时序预测框架。
(2)文章构建了一个跨模态教师模型,该模型由校准语言模型和减法式交叉注意力机制组成,能够有效提取未来时序表征。
(3)文章提出了特权知识蒸馏(PKD),该方法包含基于特权信息的相关性蒸馏与特征蒸馏,能够让学生模型学习教师模型的行为模式,同时最小化二者的输出差异。
(4)文章在真实数据集上开展了大量实验,为所提TimeKD模型的有效性、高效性与可扩展性提供了充分的实验证据。

整体框架

TimeKD由跨模态教师模型和学生模型组成,并通过特权知识蒸馏将教师模型的知识迁移到学生模型,从而训练出一个高性能的学生模型。
①跨模态教师模型:该模型主要由校准语言模型(CLMs)**、**减法式交叉注意力(SCA)以及用于重建任务的特权Transformer编码器构成。真实值提示PGT和历史数据提示PHD作为特权信息,分别输入校准语言模型,以辅助生成有效的未来表征。减法式交叉注意力(SCA)的设计目的是去除未来时序表征中掺杂的文本信息。随后,文章将这些特征输入轻量级Pre-LNTransformer编码器,以重建时序真实值。
文章训练一个基于大语言模型(LLM)的跨模态教师模型,用于重建时间序列的真实值,以学习高质量的未来表示。
①校准语言模型:校准语言模型(CLMs)基于提示词的跨模态和模态内相关性,对大语言模型(LLMs)中的掩码多头自注意力机制进行修改。CLMs由分词器(tokenizer)、层归一化(layernormalization)、校准注意力机制、前馈网络(feed-forwardnetworks)以及最后一个token提取器组成,如图1所示。
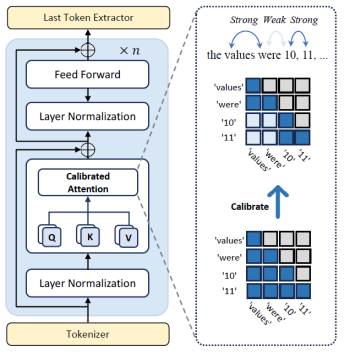
随后,文章设计了校准注意力机制(CalAtt),以增强LLM在处理多模态数据(如时间序列与文本)时的掩码多头自注意力(MMSA)能力。传统MMSA难以区分跨模态与模态内交互的重要性,导致表示纠缠。例如,如图4所示,原始注意力掩码(底部)在下三角区域呈现均匀分布。相比之下,校准注意力机制(顶部)增强了模态内交互,同时降低跨模态交互的权重(例如时间序列token"10"与文本token"were"之间的关系)。其形式如下:

②减法式交叉注意力:文章设计了一种减法式交叉注意力(SCA)机制,用于去除最后token表示中的文本信息,从而保留与时间序列预测最相关的表示。在SCA中,文章首先对真实值和历史数据进行层归一化和投影,随后计算通道级相似度矩阵:
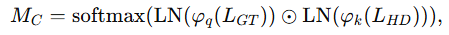
接着,通过M C 对L HD 进行逐通道加权聚合。最终,通过从L*GT*中减去融合后的信息,并经过层归一化和前馈网络,得到精炼后的真实值提示嵌入:
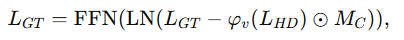
②学生模型:学生模型通过可逆实例归一化层(RevIN)处理历史数据,随后接入逆嵌入层。逆嵌入层独立嵌入每个变量的完整时序序列。接着,一种名为TSTEncoder(·)的时序Transformer编码器处理这些嵌入,以捕捉多变量间的长期时序依赖,从而预测时序真实值。
学生模型用于处理历史时间序列数据,整体结构包括:RevIN(归一化模块),倒置嵌入层(invertedembedding),时间序列Transformer编码器以及投影层(用于预测)给定历史时间序列数据。首先,模型通过RevIN 对输入进行归一化处理,目的是:缓解时间序列中的分布漂移问题 **。**然后,将归一化后的数据输入到倒置嵌入层中。其作用是:在不同变量之间建立更强的依赖关系。捕捉多变量时间序列的全局相关性。嵌入后的表示会送入一个Transformer编码器:其作用是捕获时间依赖关系以及变量之间的交互。
③特权知识蒸馏:该模块通过两种损失函数将教师模型的未来表征迁移到学生模型:相关性蒸馏损失和特征蒸馏损失**。** 相关性蒸馏损失用于对齐教师与学生模型中Transformer的特征相关性,引导学生模型模仿教师的行为模式;同时,特征蒸馏损失用于最小化教师与学生模型之间的输出差异。

实验

1.总体效果
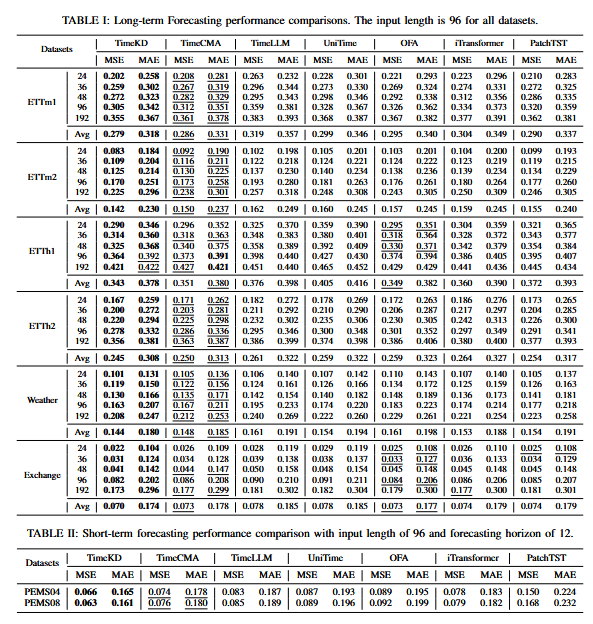
①长期预测性能对比:文章在表I中报告了各方法的MSE和MAE指标。优于现有方法的结果以下划线标出,最佳结果用粗体表示。主要观察如下:TimeKD在所有数据集和所有预测长度(FH∈{24,36,48,96,192})上都取得了最佳结果。相比当前最强基线方法,TimeKD在MSE和MAE上分别提升了9.11%和7.52%。这一提升归因于TimeKD的特权知识蒸馏机制,该机制利用校准后的LLM从文本模态中提取嵌入,并通过蒸馏将这些知识迁移到学生模型中。文章还观察到,在ETTm2数据集上的提升超过其他数据集,因为ETTm2具有更高的采样频率和更细粒度的数值记录。这说明TimeKD能够在高频数据场景下学习更鲁棒的表示。总体而言,基于LLM的方法在大多数情况下优于Transformer方法。这表明LLM具有更强的知识迁移能力。Transformer在所有数据集上的表现最差,尤其是在ETTh数据集(变量较少)上更明显,这与其结构简单、缺乏参数有关。TimeCMA在现有方法中表现较优,这得益于其能够捕捉抽象的全局时间趋势,以及通过跨模态对齐设计来获取更稳健的时间序列表示。
②短期预测性能对比:如表II所示,TimeKD在PEMS04和PEMS08数据集上取得了所有基线方法中的最佳性能。具体而言:在PEMS04数据集上:MSE降低10.81%;MAE降低10.26%;在PEMS08数据集上:MSE降低11.38%,MAE降低11.39%这些优异表现(TimeKD、TimeCMA、iTransformer)主要归因于:使用了倒置嵌入(invertedembedding),能够有效捕捉交通传感器之间的空间依赖关系。相比之下:Time-LLM、UniTime、OFA和PatchTST将每个传感器独立处理,未考虑空间交互关系因此,它们的性能相对较低
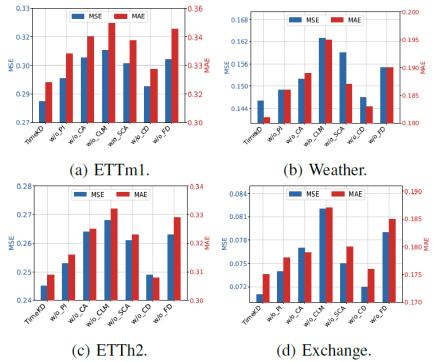
2.消融实验
为了分析TimeKD各个组成部分的作用(包括特权信息、校准注意力、语言模型、减法交叉注意力、相关性蒸馏和特征蒸馏),文章设计了以下消融版本:
lw/o_PI:去除特权信息(例如真实值提示),教师模型仅输入历史数据。
lw/o_CA:去除校准注意力,使用原始的多头注意力机制。
lw/o_CLM:去除校准语言模型,即教师模型不再使用LLM提取文本嵌入。
lw/o_SCA:去除减法交叉注意力,改为直接对嵌入进行减法操作。
lw/o_CD:去除相关性蒸馏,不再对齐特权Transformer与时间序列Transformer之间的注意力关系。
lw/o_FD:去除特征蒸馏,不再对齐教师与学生的特征表示。
实验结果(如图2所示)表明:在ETTm1、ETTh2、Weather和Exchange数据集上的平均结果显示,去除相关性蒸馏(CD)和特权信息(PI)会显著降低性能,说明它们对时间序列预测至关重要。当教师模型只使用历史数据(去掉真实值提示)时,TimeKD性能明显下降,说明:未来信息(作为特权知识)非常重要;在ETTm1数据集上:去除SCA后,MSE和MAE分别提升(变差)约8.2%和6.5%,说明SCA对性能提升有重要作用,同时:TimeKD相比w/o_CA分别提升8.9%(MSE)和8.4%(MAE)说明校准注意力(CA)有效

结论

本文提出了TimeKD,这是一种新颖的多变量时间序列预测(MTSF)框架,将校准语言模型与特权知识蒸馏相结合。TimeKD 由两个关键组成部分构成:跨模态教师模型和轻量级学生模型。在跨模态教师模型中,文章提出了校准语言模型和减法交叉注意力机制。校准语言模型利用大语言模型的预训练知识以及特权文本提示,提取鲁棒的未来表示;减法交叉注意力则用于净化表示,使其更好地对齐时间序列数据。此外,文章提出了一种创新的特权知识蒸馏方法,包括相关性蒸馏和特征蒸馏,用于将教师模型中的表示迁移到轻量级学生模型中。在来自不同领域的真实数据集上的大量实验结果表明,TimeKD 在有效性和效率方面均表现出色。