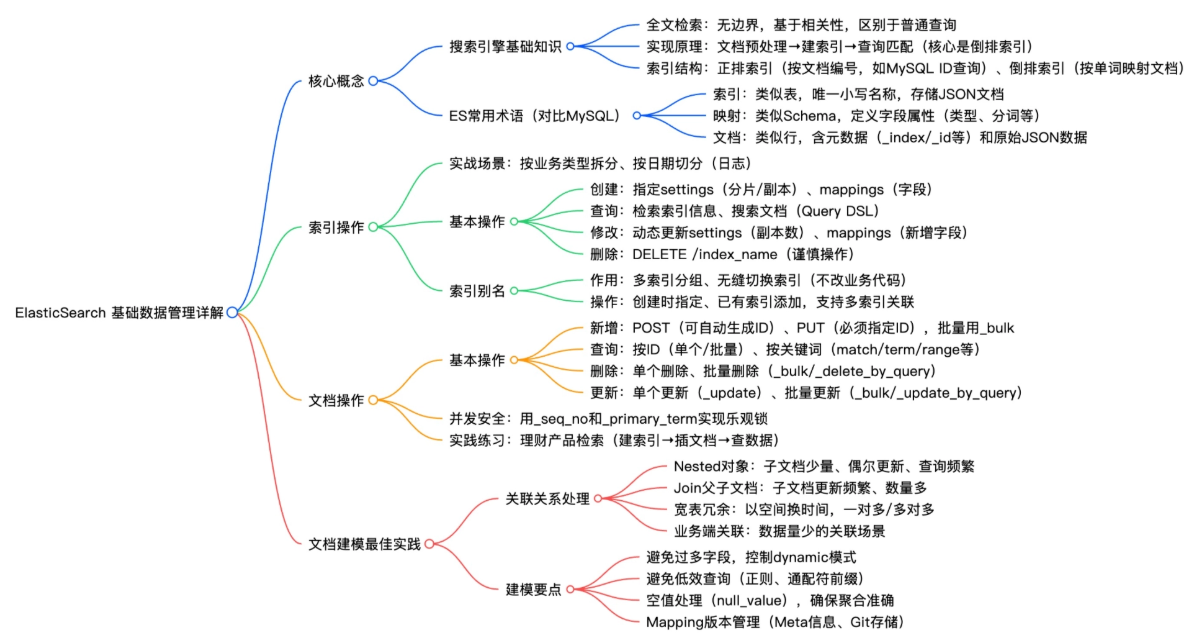
📚 ElasticSearch 基础数据管理详解
本文系统梳理 ElasticSearch(ES) 的核心概念、索引与文档操作、建模最佳实践,结合全文检索原理、实操命令与典型场景,兼顾理论深度 与工程落地,帮助开发者快速掌握 ES 数据管理能力。文末附思维导图建议,便于构建完整知识体系。
一、ElasticSearch 核心概念
1.1 全文检索基础
🔍 1.1.1 全文检索 vs 普通查询
- 普通查询 :基于明确条件(如
age BETWEEN 15 AND 25),结果精确但缺乏语义理解。 - 全文检索 :无固定边界,基于相关性排序,支持分词、同义词、模糊匹配等。
💡 示例:搜索 "Java 设计模式"
- MySQL 使用
LIKE '%Java设计模式%'→ 全表扫描,效率低- ES 利用倒排索引 → 秒级召回相关文档
⚙️ 1.1.2 全文检索实现原理
全文检索依赖 **倒排索引(Inverted Index)**,流程如下:
- 文档预处理:分词、去停用词、标准化
- 构建倒排索引:单词 → 文档 ID, 词频, 位置...
- 查询匹配:关键词匹配 + 相关性评分(如 TF-IDF、BM25)
- 结果排序返回
📊 1.1.3 正排索引 vs 倒排索引
| 类型 | 特点 | 适用场景 |
|---|---|---|
| 正排索引 | 按文档 ID 组织内容 | 精确查找(如 MySQL 主键查询) |
| 倒排索引 | 按词项组织文档列表 | 全文搜索、关键词召回 |
✅ ES 的高性能检索能力,核心在于倒排索引 + 分布式架构
1.2 ES 核心术语(类比 MySQL)
⚠️ 注意:ES 7.x+ 已移除
type概念,一个索引仅含一种文档类型。
| ES 概念 | 类比 MySQL | 说明 |
|---|---|---|
| Index(索引) | 表(Table) | 存储结构相似的 JSON 文档,名称必须小写 |
| Mapping(映射) | Schema(表结构) | 定义字段名、类型(text/keyword/date)、是否分词等 |
| Document(文档) | 行(Row) | 基本存储单元,JSON 格式,含 _source 原始数据 |
📌 文档元数据字段
_index:所属索引_id:唯一标识(可自定义或自动生成)_version:版本号(旧版乐观锁)_seq_no+_primary_term:7.x+ 并发控制核心
二、索引操作详解
2.1 索引设计实战场景
| 场景 | 说明 | 示例 |
|---|---|---|
| 按业务拆分 | 不同业务独立索引 | weibo_index,news_index |
| 按时间切分 | 日志类数据按天/月分片 | logs_202407,logs_202408 |
✅ 优势:隔离数据、提升查询性能、便于生命周期管理
2.2 索引基本操作(REST API)
✅ 创建索引
json
PUT /student_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": { "type": "text", "analyzer": "ik_max_word" },
"age": { "type": "integer" },
"enrolled_date": { "type": "date" }
}
}
}💡 可省略 settings/mappings,ES 自动推断(但不推荐生产环境使用)
🔍 查询索引
- 查看索引结构:
GET /student_index - 搜索文档:
GET /student_index/_search { "query": { "match": { "name": "John" } } }
🔧 修改索引
-
更新副本数:
jsonPUT /student_index/_settings { "number_of_replicas": 2 } -
添加新字段:
jsonPUT /student_index/_mapping { "properties": { "grade": { "type": "integer" } } }
⚠️ 无法修改已有字段类型,需重建索引(Reindex)
🗑️ 删除索引
DELETE /student_index❗ 删除不可逆!务必谨慎操作
2.3 索引别名(Alias)------ 解耦业务与物理索引
🎯 别名的核心价值
- 多索引统一查询 :如
logs_alias→logs_2024* - 无缝切换索引:无需改代码,切换底层索引
- **创建"视图"**:过滤特定数据子集
🛠️ 别名操作示例
-
创建时指定:
jsonPUT /new_index { "aliases": { "prod_alias": {} } } -
动态绑定:
jsonPOST /_aliases { "actions": [ { "add": { "index": "old_index", "alias": "prod_alias" } }, { "remove": { "index": "old_index", "alias": "prod_alias" } } ] }
✅ 读写建议:
- 查询可用别名
- 写入建议用物理索引名(避免路由歧义)
三、文档操作详解
3.1 文档基本特性
- 格式:JSON 对象
- 唯一标识:
_id(可自定义) - 存储位置:
_source字段(可关闭以节省空间)
3.2 核心文档操作
➕ 新增文档
| 方法 | 说明 |
|---|---|
POST /index/_doc |
自动生成 _id |
PUT /index/_doc/123 |
指定 _id,存在则覆盖 |
💡 批量插入:使用
_bulkAPI,支持index/create操作
🔍 查询文档
-
按 ID:
GET /index/_doc/123 -
批量:
GET /index/_mget { "ids": ["1", "2"] } -
条件查询(Query DSL):
json{ "query": { "match": { "describe": "每天收益到账消息推送" }, "range": { "annual_rate": { "gte": "3.0000%", "lte": "3.1300%" } } } }
📌 常用查询类型:
match_all:全量返回match:文本分词后匹配term:精确匹配(不分词)range:数值/日期范围
🗑️ 删除文档
- 单条:
DELETE /index/_doc/123 - 批量:
_bulk(多个delete) - 条件删除:
POST /index/_delete_by_query { "query": ... }
✏️ 更新文档
-
部分更新(推荐):
jsonPOST /index/_update/123 { "doc": { "age": 25 } } -
批量更新:
_update_by_query+ 脚本(如ctx._source.score += 10)
🔒 并发安全:乐观锁机制
ES 7.x+ 使用 _seq_no + _primary_term 实现乐观锁:
json
POST /index/_update/123?if_seq_no=10&if_primary_term=1
{ "doc": { "status": "processed" } }❌ 若版本不匹配 → 抛出
VersionConflictEngineException
四、文档建模最佳实践
4.1 关联关系处理方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Nested 嵌套对象 | 读取快,数据一体 | 更新整个文档,查询慢 | 子对象少、更新少、查询多 |
| Join 父子文档 | 父子独立更新 | 内存开销大,性能较低 | 子文档海量、频繁更新 |
| 宽表冗余 | 查询极快 | 存储浪费,更新复杂 | 一对多/多对多,容忍冗余 |
| 业务端关联 | 灵活简单 | 多次请求,延迟高 | 数据量小,关联简单 |
✅ 优先顺序建议:
Object(反范式) → Nested → Join → 业务端关联
4.2 建模黄金法则
-
控制字段数量
- Mapping 占用堆内存,避免"宽表爆炸"
- 设置
"dynamic": "strict"防止意外字段注入
-
避免低效查询
- 禁用前缀通配符(如
abc) - 拆分复合字段(如
version: "2.1.3"→major:2, minor:1, patch:3)
- 禁用前缀通配符(如
-
处理空值聚合
json"score": { "type": "integer", "null_value": 0 } -
Mapping 版本管理
- 在 mapping 中添加
"_meta": { "version": "1.2" } - 变更字段 = 重建索引 (使用
_reindexAPI)
- 在 mapping 中添加
🧠 总结与建议
- 索引设计:按业务/时间合理拆分,善用别名解耦
- 文档操作:批量优于单条,部分更新优于全量替换
- 关联建模 :ES 不是关系型数据库,优先反范式
- 性能意识:避免动态映射、通配符查询、大宽表
📌 配套建议 :绘制 ES 数据管理思维导图,涵盖
核心概念 → 索引生命周期 → 文档 CRUD → 建模策略 → 性能陷阱