Agent架构师深度解析:LLM Agent核心组成与工程实践(工具调用+记忆存储+ReAct编排)
bash
mindmap
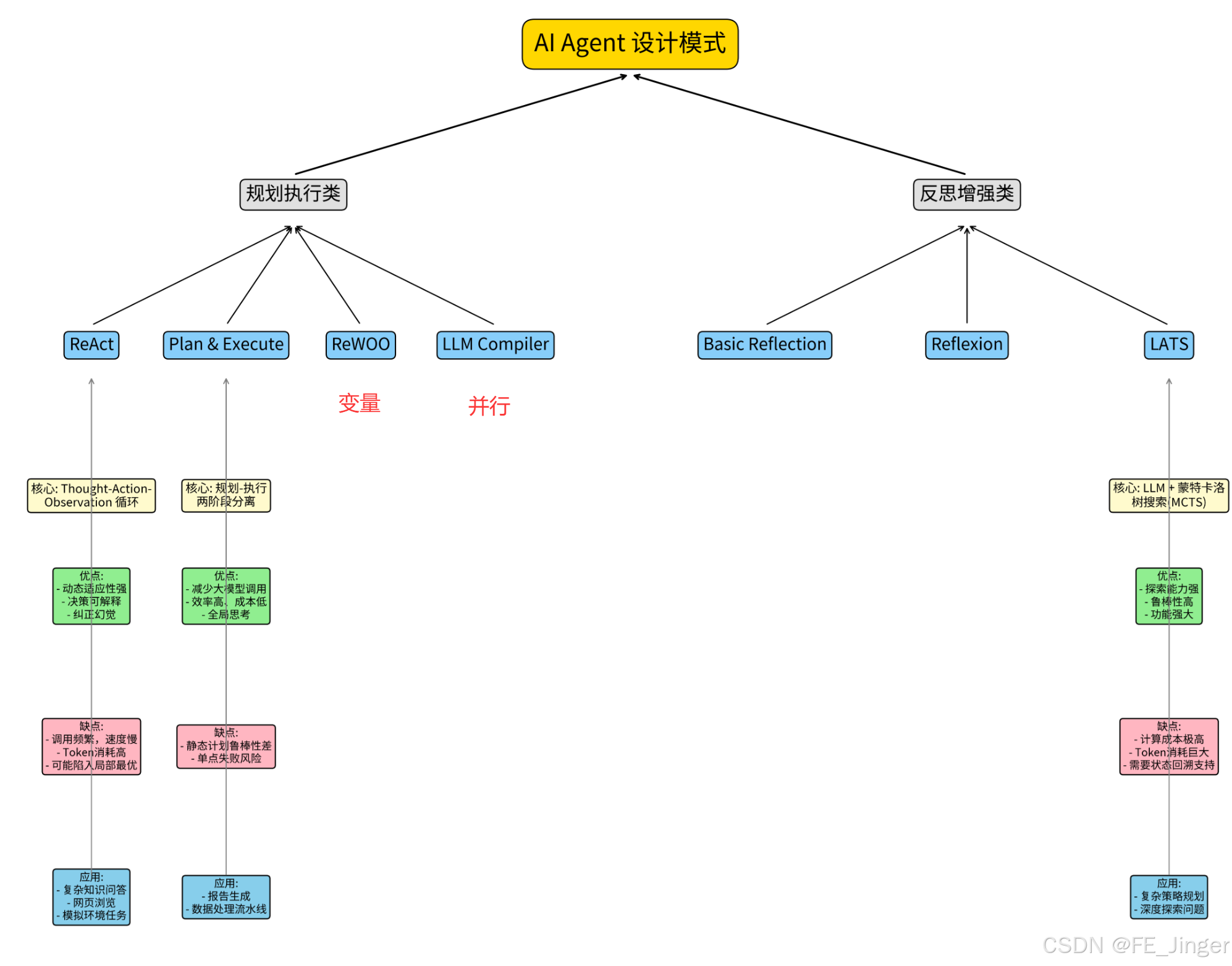
root((LLM Agent 四大模块协同与落地关键))
核心理念
LLM Agent落地:模块协同>技术先进
四大模块协同逻辑
LLM核心引擎「大脑」
记忆存储「知识库」
ReAct编排「规划师」
工具调用「手脚」
四大模块落地关键
LLM核心引擎
选择合适模型(GPT-4、Claude 3)
通过Prompt工程引导精准推理
工具调用
核心:精准、高效、净化
方案:动态加载、程序化编排、规范封装
解决:上下文污染、效率低下问题
记忆存储
核心:平衡Token消耗与信息精准度
支撑:上下文工程、RAG/Agentic RAG
目标:关键信息精准触达LLM
ReAct编排
核心:灵活动态决策
逻辑:观察→思考→行动→再观察
优势:打破硬编码,适应多变场景
补充关联
工具调用:MCP&SKILL规范封装
记忆存储:高质量Prompt五大要素
ReAct:与CoT本质区别(边做边想vs闭门思考)Agent=LLM+记忆存储+规划(ReAct 编排)+工具调用
1. 工具调用
问题 :上下文窗口溢出(token太多、中间不必要的结果返回污染) 执行效率低下 调用准确性(调那个)
解决:1. 工具搜索工具:按需动态加载,defer_loading 程序化 2. 工具调用:代码编排工具调用,中间结果不入上下文,allow_caller 3. 工具使用示例(如灾害模型MIL,值、类型给个具体示例)
MCP&SKILL MCP(JSON-RPC)
SKILL封装示例
2. 记忆存储Prompt:提示词工程,Prompt作用,提供上下(Context)、限定任务(Task)、设定规则(Constraints)、引导输出形式(Format)
一高质量Prompt
- 任务描述,明确告诉模型要做什么,
- 背景信息提供必要上下文
- 约束条件 长度、风格、格式等
- 示例(Few-shot)提供参考答案
- 输出格式 明确返回结构
- 上下文工程 Prompt = System (角色)+ Memory + History对话历史 + ToolResult +
UserQuery用户输入既要保证关键信息(Skills/Tools/Memory/Rule)精准触达,又要最小化Token消耗,同时过滤无关信息
- Skills:仅发送与用户问题匹配的1-2个技能精
简描述(≤50字),非匹配技能不发送;- Tools:仅发送需要调用的工具名称+入参格式,省略实现细节;
- Memory:短期记忆取最近3轮核心摘要(每轮≤100字),长期记忆仅加载相似度≥0.75的Top2信息;
- Rule:仅加载当前场景匹配的高优先级规则,非当前场景规则不加载。
LLM Agent 系统的核心瓶颈是上下文管理,其核心痛点包括 Token 限制导致的上下文溢出、多轮对话漂移(目标丢失)、工具调用 引发的上下文爆炸与污染、记忆检索不精准、记忆冲突及长任务无法持续等问题 。解决方案以 "记忆分层、上下文压缩、智能检索 "为核心,通过滑动窗口 保留近期对话、上下文总结压缩 冗余信息、RAG 实现精准记忆召回 、分层记忆 架构区分短期/ 长期 / 任务记忆,搭配上下文排序 与工具输出压缩等技术,构建以 Context Manager为核心的生产级架构,同时通过 Prompt Budget 规划、定期总结等最佳实践,在有限 Token 内为 LLM提供最有价值的上下文,支撑 Agent 稳定高效运行。
- RAG :先检索、再生成
Agentic RAG A g e n t i c R A G = R A G + P l a n n i n g + M e m o r y + T o o l U s e Agentic\ RAG = RAG + Planning + Memory + Tool\ Use Agentic RAG=RAG+Planning+Memory+Tool Use
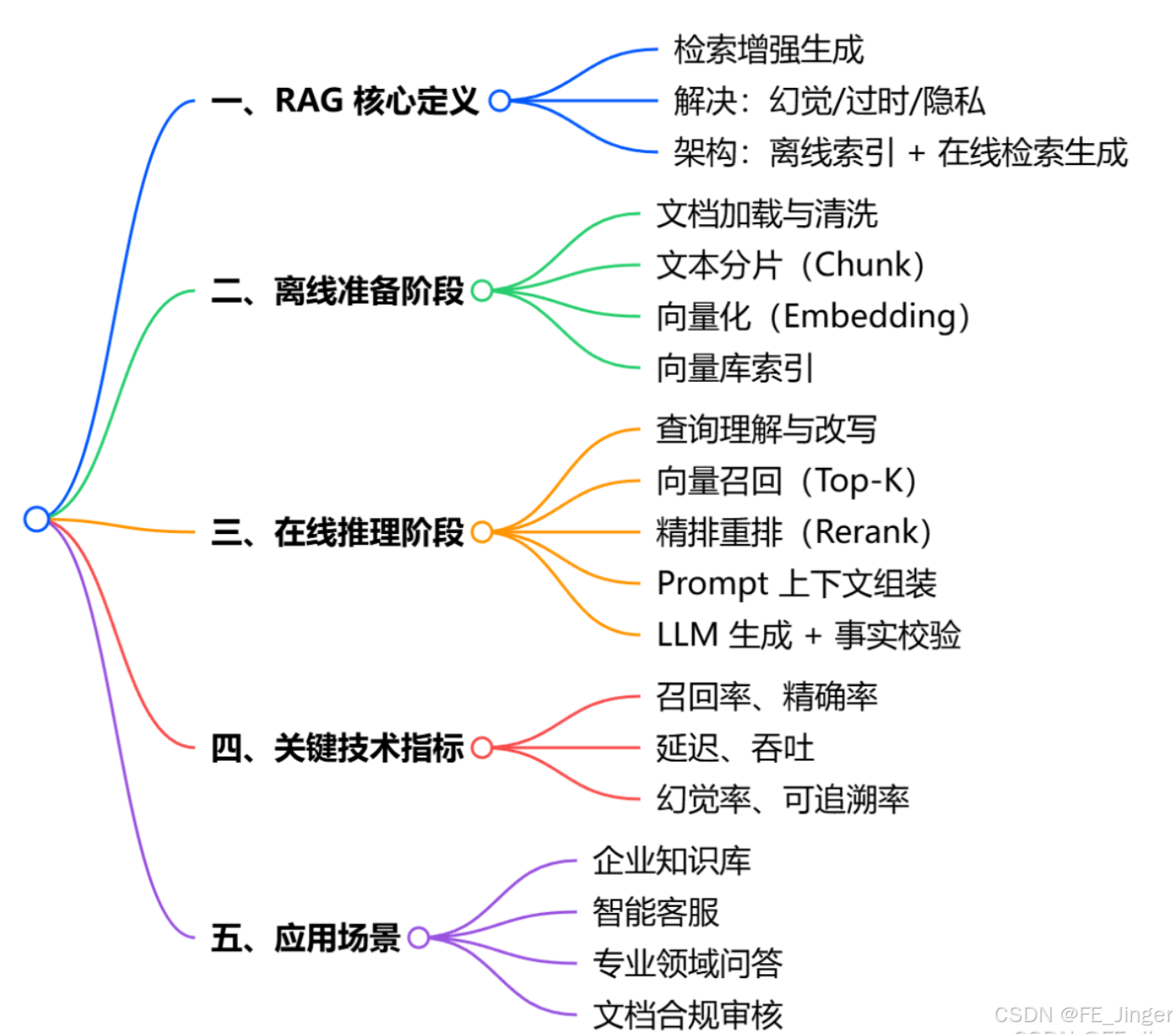

3.规划(ReAct)
ReAct(Observation+Reasoning+Action)
观察-思考-行动-再观察的循环,ReAct的优势就在于它能根据实际情况灵活应对,而不是遇到意外就卡住,打破硬编码,实现动态决策,适应变化的场景与纯粹的Chain-of-Thought(CoT)推理方法相比,
ReAct最本质的区别在于其将推理过程与外部世界进行了紧密结合。CoT仅依赖于模型内部知识进行逐步思考,这在处理需要最新信息或外部验证的任务时,极易陷入幻觉或错误传播。在实现层面,
剖析了 ReAct 的五个关键要素:
- 历史上下文:记录所有先前的思考、行动和观察。
- 当前环境信息:Agent 在当下接收到的外部信息。
- 语言模型:作为"大脑"负责推理和决策。
- 工具/动作:作为"手脚"执行具体操作。
- 观察结果:每次行动后的反馈,是下一轮推理的依据。
ReAct 不是一开始就知道所有步骤,而是根据每轮的观察结果,动态决定下一步该做什么。如果 Round 1
搜索失败了,它可能会尝试其他搜索关键词,或者换一个策略。这种灵活性正是 ReAct 的核心优势。
作为长期深耕Agent架构设计与工程落地的从业者,我始终认为:一个可落地、高可用的LLM Agent,绝非单纯的"LLM调用工具",而是由「LLM核心引擎+记忆存储+规划(ReAct编排)+工具调用」四大模块有机联动的闭环系统。这四大模块各司其职、相互支撑,共同解决Agent"能思考、能记忆、能行动、能适配"的核心需求。
今天,我将从架构师视角,拆解每个模块的核心痛点、落地方案与实践细节,结合实际工程案例,帮大家理清Agent的核心架构逻辑,避开落地过程中的常见坑,助力大家快速搭建生产级LLM Agent系统。
一、Agent核心定义:四大模块的协同闭环
在正式拆解前,我们先明确Agent的核心构成公式:
「Agent = LLM + 记忆存储 + 规划(ReAct 编排) + 工具调用」
这不是简单的模块叠加,而是一个动态协同的闭环:LLM作为"大脑"负责推理决策;记忆存储作为"知识库"负责留存上下文与历史信息;ReAct编排作为"规划师"负责动态规划任务步骤;工具调用作为"手脚"负责执行具体外部操作(如数据查询、模型调用、接口交互)。四个模块环环相扣,缺一不可------缺少记忆,Agent会"健忘";缺少规划,Agent会"盲目行动";缺少工具,Agent会"束手无策"。
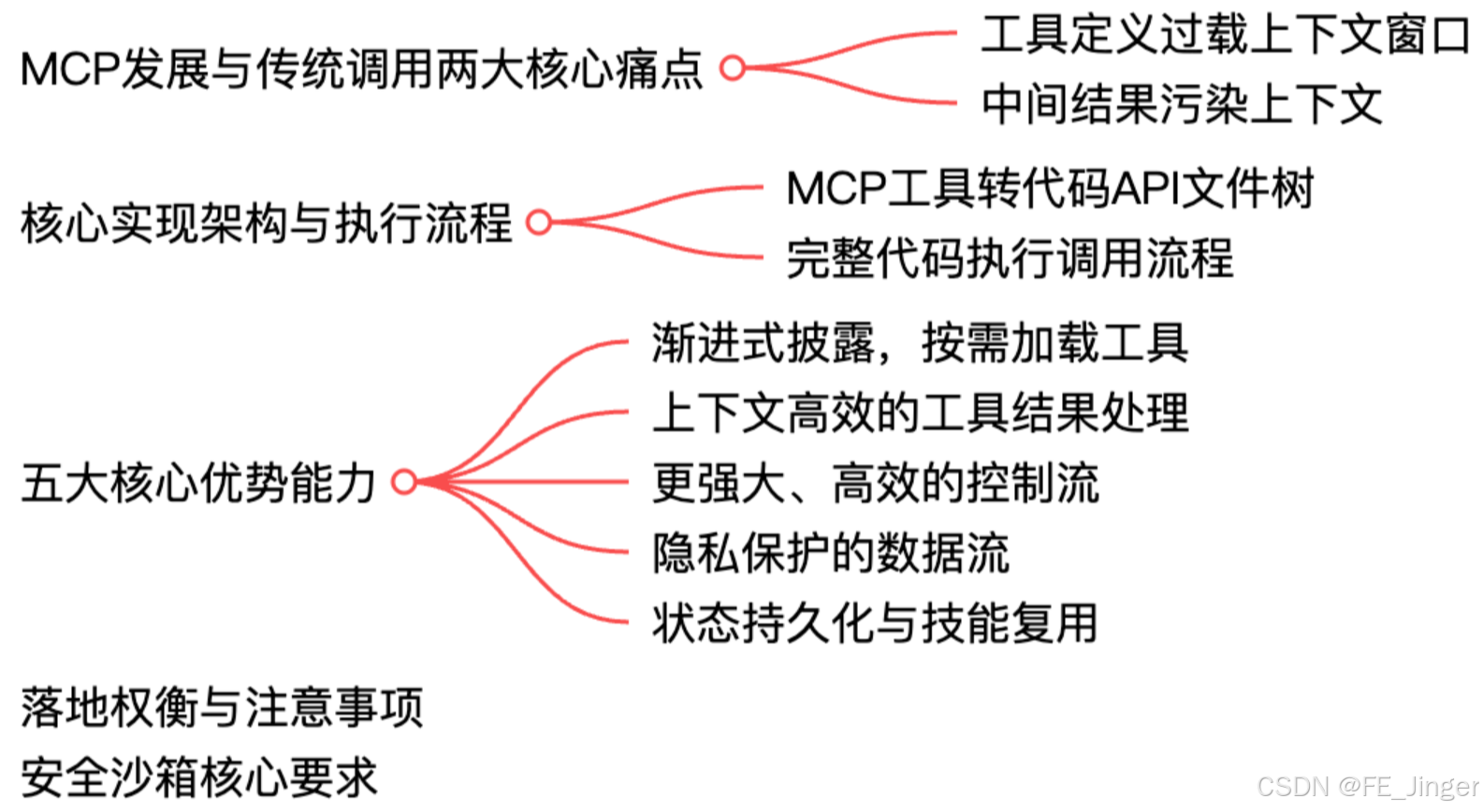
二、工具调用:Agent的"行动能力"落地,解决"能做什么"的问题
工具调用是Agent与外部世界交互的核心载体,也是Agent从"只能思考"到"能落地执行"的关键一步。但在工程落地中,工具调用很容易陷入"上下文污染、效率低下、调用不准"的困境,这也是我们架构设计中需要重点解决的问题。
2.1 工具调用的三大核心痛点
-
上下文窗口溢出:工具调用过程中,会产生大量中间结果、工具描述等冗余信息,这些信息如果全部存入上下文,很容易导致Token耗尽,出现上下文溢出问题;同时,不必要的中间结果还会污染上下文,影响LLM的推理决策。
-
执行效率低下:若所有工具一次性加载,会占用大量资源,且多数工具并非当前任务所需,导致Agent响应缓慢,执行效率低下。
-
调用准确性不足:面对多个工具时,LLM难以精准判断"当前任务需要调用哪个工具",容易出现调用错误、冗余调用的情况,影响任务落地效果。
2.2 工程级解决方案:精准调用、高效执行、净化上下文
针对上述痛点,我们结合实际落地经验,总结了三大核心解决方案,同时补充具体工具封装示例,方便大家直接复用。
方案1:工具搜索工具------按需动态加载,减少资源占用
采用"defer_loading"(延迟加载)机制,Agent在启动时不加载所有工具,而是根据用户当前任务需求,通过工具搜索工具动态匹配并加载所需工具。例如,当用户需要进行灾害模拟时,仅加载"灾害模型MIL工具",无需加载文档解析、数据可视化等无关工具,大幅降低资源占用,提升执行效率。
方案2:程序化工具调用------代码编排,净化上下文
通过代码编排实现工具调用的程序化管理,核心是"中间结果不入上下文"(allow_caller配置)。具体来说,工具调用的中间计算过程、临时结果由程序单独存储,仅将最终有效结果传入上下文,避免冗余信息污染,同时减少Token消耗。
方案3:工具使用示例------具象化落地,提升调用准确性
为LLM提供具体的工具使用示例,明确工具的输入值、参数类型、输出格式,帮助LLM精准理解工具用途,提升调用准确性。以灾害模型MIL工具为例,具体示例如下:
灾害模型MIL工具使用示例
工具名称:灾害模型MIL(地震灾害评估模型)
输入参数:
- 区域编码(type:string,示例:"330106",代表杭州市西湖区)
- 灾害类型(type:enum,可选值:"earthquake"、"flood"、"typhoon",示例:"earthquake")
- 震级(type:float,示例:5.2,单位:里氏震级)
输出结果:
{ "区域": "杭州市西湖区", "灾害类型": "地震", "震级": 5.2, "风险等级": "中风险", "影响范围": "5公里", "建议措施": "人员疏散", "建筑物排查", "应急物资调配" }
2.3 工具封装规范:MCP&SKILL落地实践
工具封装的规范性,直接影响Agent调用的稳定性和可维护性。我们在落地中采用"MCP(JSON-RPC)+ SKILL封装"的模式,统一工具调用接口,降低开发与维护成本。
MCP(JSON-RPC):统一调用接口
MCP(Method Call Protocol)基于JSON-RPC协议设计,是Agent与工具之间的统一调用接口,负责规范工具的调用方式、参数格式、返回结果,确保不同类型、不同功能的工具,都能被Agent统一调用。其核心优势在于"解耦"------Agent无需关注工具的内部实现,只需按照MCP协议发送调用请求,即可获取工具返回结果。
MCP接口示意图如下(可直接用于工程落地):
SKILL封装示例:标准化工具实现
SKILL是工具的具体实现载体,我们将每个工具封装为独立的SKILL模块,包含工具描述、输入输出定义、核心逻辑实现,确保工具的可复用性和可扩展性。以下是SKILL封装的实际示例,可直接参考封装规范:
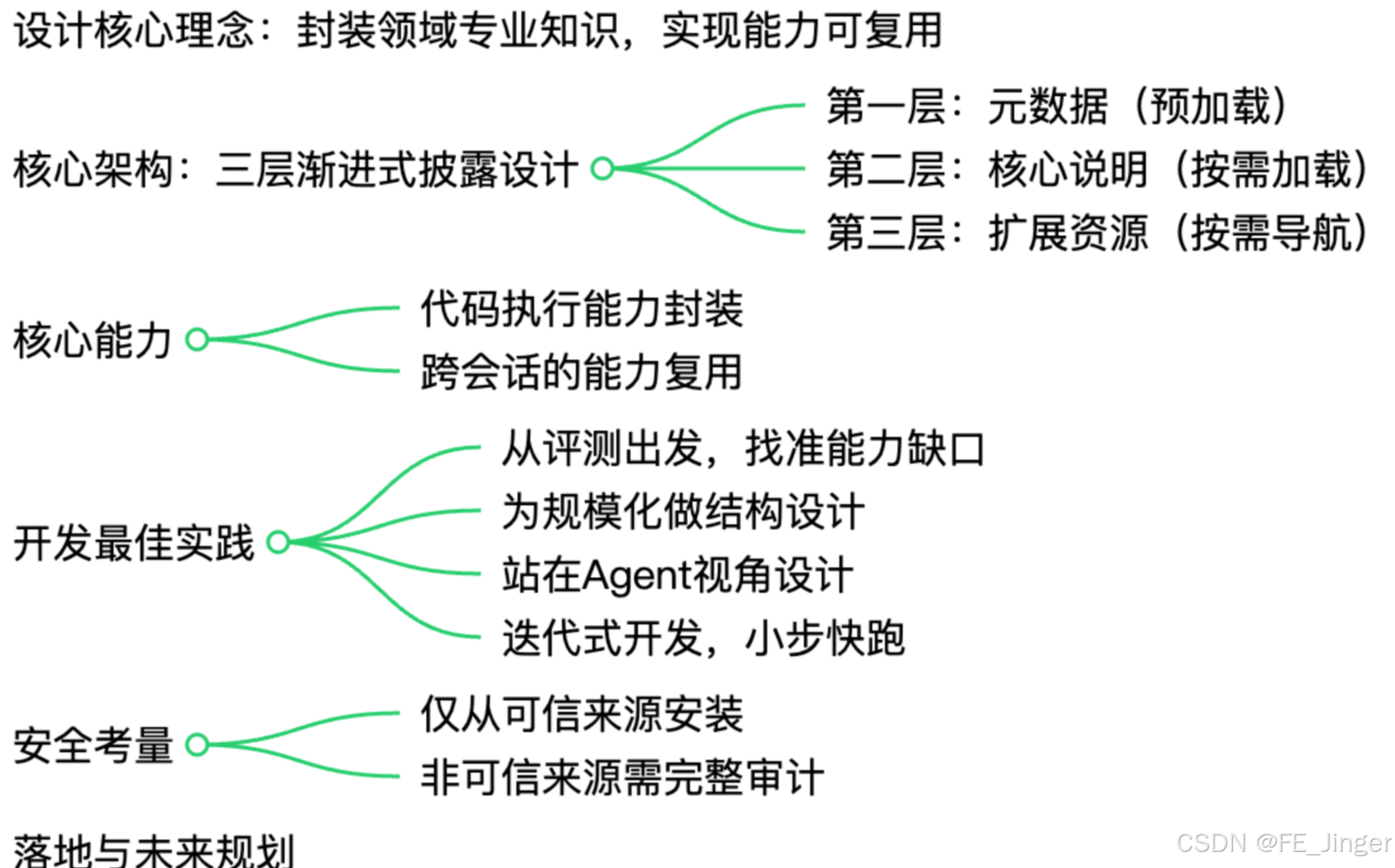
三、记忆存储:Agent的"记忆能力",解决"能记住什么"的问题
如果说工具调用是Agent的"手脚",那么记忆存储就是Agent的"大脑记忆"------没有记忆,Agent每次对话都是"全新开始",无法记住历史对话、用户偏好、任务上下文,更无法完成多步复杂任务。记忆存储的核心目标是:在最小化Token消耗的前提下,确保关键信息精准触达LLM 。
3.1 记忆存储的核心载体:提示词工程(Prompt Engineering)
Prompt是LLM与Agent之间的"沟通桥梁",也是记忆存储的核心载体。一个高质量的Prompt,不仅能为LLM提供必要的上下文,还能限定任务目标、设定规则、引导输出格式,直接影响Agent的推理效果。其核心作用可概括为4点:
-
提供上下文(Context):让LLM了解当前任务的背景、历史信息;
-
限定任务(Task):明确告诉LLM需要完成什么任务;
-
设定规则(Constraints):约束LLM的推理范围、输出风格;
-
引导输出形式(Format):明确LLM的返回结构,方便Agent后续处理。
Prompt的未来发展方向
随着Agent技术的发展,Prompt工程也在向"自动化、智能化"升级,核心方向有3个:
-
Prompt自动优化(Auto Prompting):通过算法自动生成、优化Prompt,减少人工干预;
-
与工具调用结合(Tool Use):Prompt中嵌入工具调用逻辑,引导LLM精准调用工具;
-
Agent化:让Prompt支持多步任务自动执行,实现"Prompt驱动Agent闭环"。
3.2 高质量Prompt的5大核心要素(必看落地指南)
结合上千次工程实践,我们总结出高质量Prompt的5大核心要素,缺一不可,直接套用即可提升LLM推理准确性:
- 任务描述:明确告诉模型要做什么,避免模糊表述;
- 背景信息:提供必要的上下文,帮助模型理解任务背景;
- 约束条件:明确长度、风格、格式等限制,避免模型输出不符合预期;
- 示例(Few-shot):提供1-2个参考答案,帮助模型快速理解任务要求;
- 输出格式:明确返回结构(如JSON、列表、段落),方便后续处理。
3.3 上下文工程:平衡Token消耗与信息精准度
上下文工程是记忆存储的核心,其核心公式为:
「Prompt = System(角色)+ Memory + History(对话历史)+ ToolResult(工具结果)+ UserQuery(用户输入)」
上下文工程的关键的是"取舍"------既要保证关键信息(Skills/Tools/Memory/Rule)精准触达LLM,又要最小化Token消耗,同时过滤无关信息。我们在落地中制定了以下4条核心规则,可直接复用:
-
Skills(技能):仅发送与用户问题匹配的1-2个技能精简描述(≤50字),非匹配技能不发送;
-
Tools(工具):仅发送需要调用的工具名称+入参格式,省略工具内部实现细节;
-
Memory(记忆):短期记忆取最近3轮核心摘要(每轮≤100字),长期记忆仅加载相似度≥0.75的Top2信息;
-
Rule(规则):仅加载当前场景匹配的高优先级规则,非当前场景规则不加载。
3.4 记忆存储的核心支撑:RAG与Agentic RAG
单纯的Prompt记忆的局限性------无法高效处理海量长期记忆,也无法实现记忆的精准检索。因此,我们引入RAG(检索增强生成)技术,作为记忆存储的核心支撑;同时,结合Agent的规划能力,升级为Agentic RAG,实现"检索-规划-记忆-行动"的闭环。
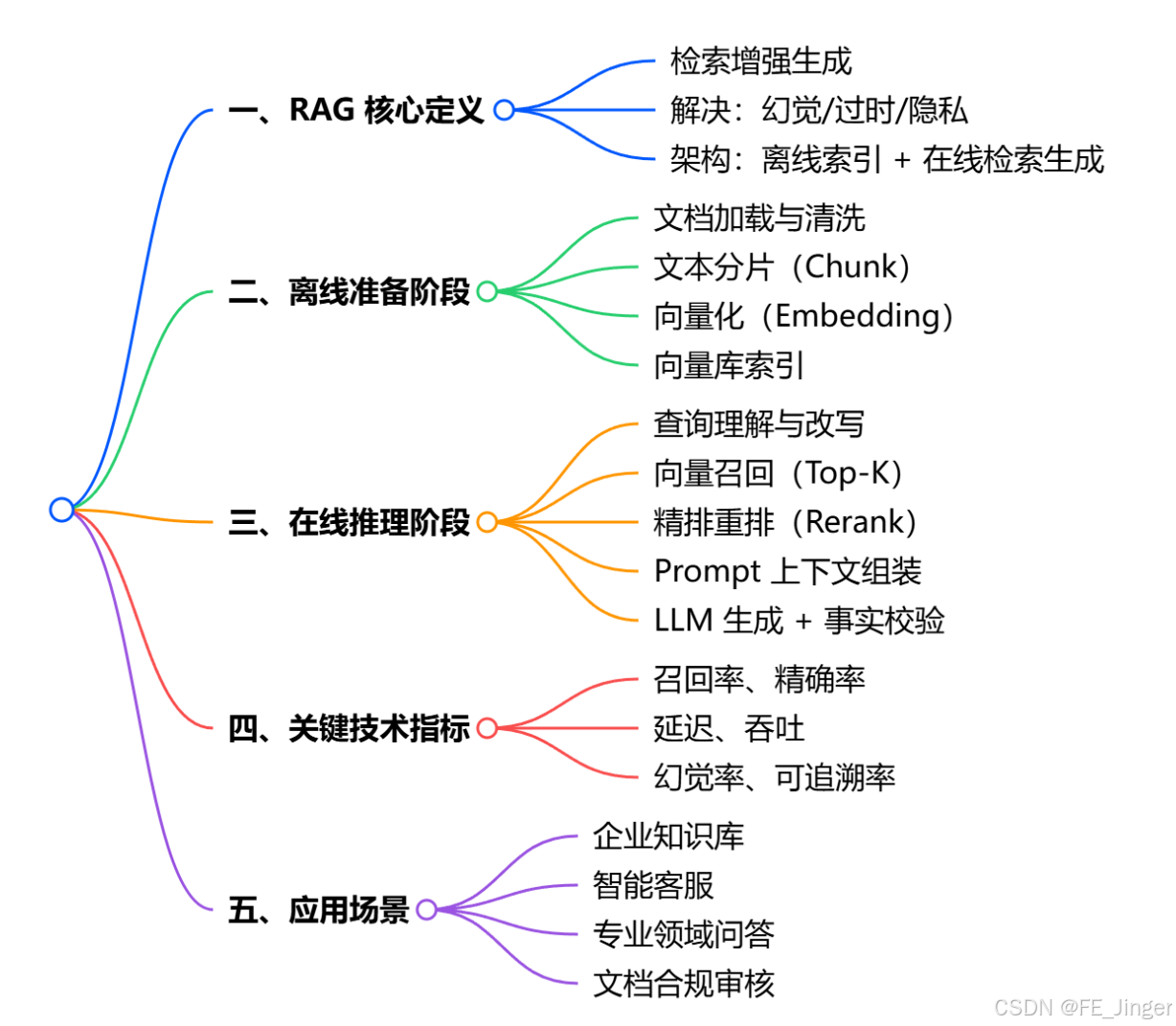
基础RAG:解决记忆检索精准度问题
RAG的核心逻辑是"先检索、再生成"------将海量长期记忆存入向量数据库,当Agent需要调用长期记忆时,通过用户查询关键词,检索出相似度最高的相关信息,再将其传入LLM,辅助推理决策。这种方式既能解决长期记忆存储问题,又能避免无关记忆占用Token,提升推理准确性。
RAG核心架构示意图如下:
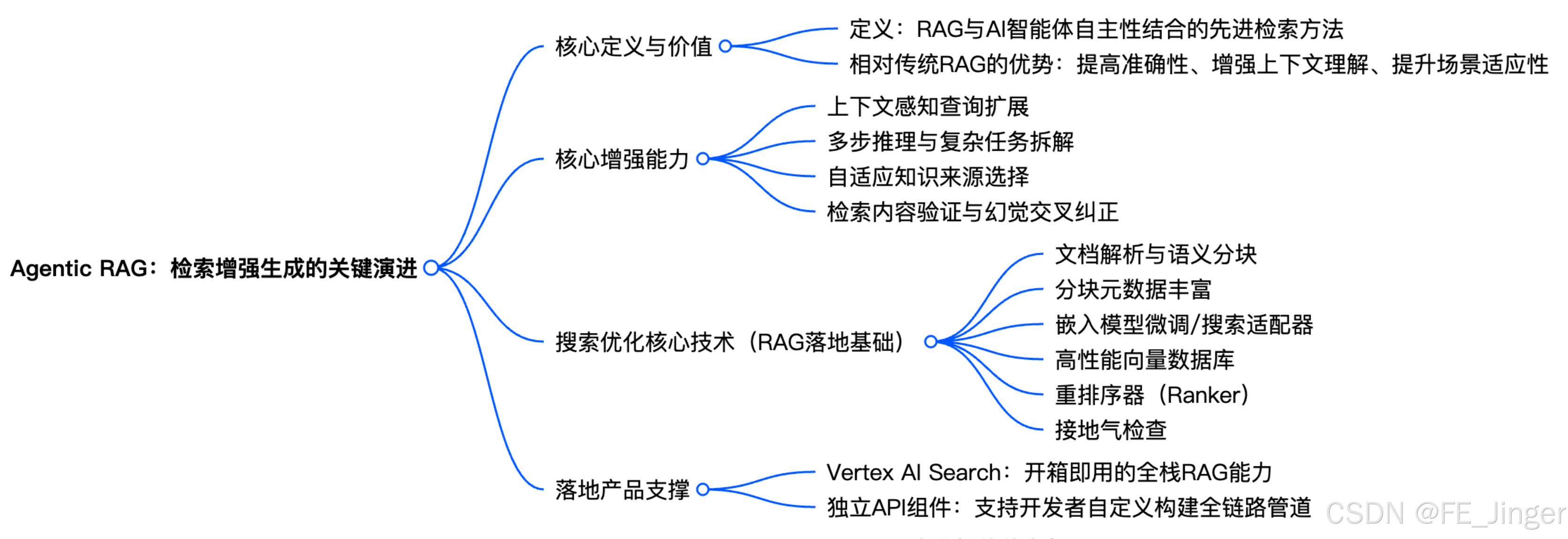
Agentic RAG:RAG与Agent的深度融合
基础RAG仅解决"检索"问题,无法实现检索后的规划与行动。而Agentic RAG则将RAG与Agent的规划、记忆、工具调用能力深度融合,其核心公式为:
「Agentic RAG = RAG + Planning + Memory + Tool Use」
Agentic RAG的优势在于:不仅能精准检索记忆,还能根据检索结果,动态规划任务步骤、调用工具执行、更新记忆,实现"检索-推理-行动-记忆更新"的闭环,适用于更复杂的多步任务。
Agentic RAG架构示意图如下:

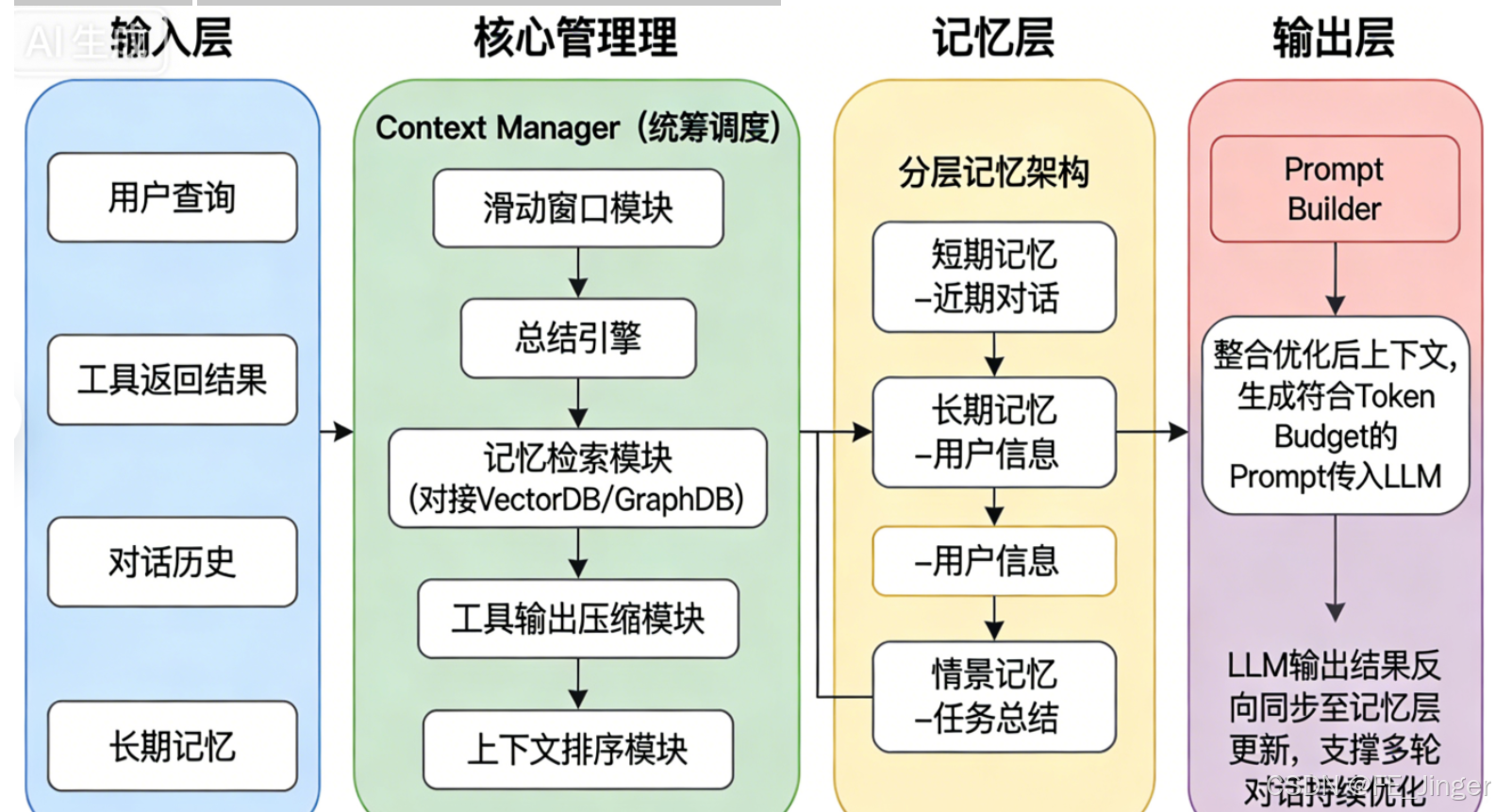
3.5 上下文管理的核心痛点与解决方案(延伸补充)
在记忆存储与上下文工程的落地中,我们不可避免会遇到上下文管理的核心痛点------这也是LLM Agent系统的核心瓶颈。结合我们的工程实践,总结如下核心痛点与解决方案,帮大家避开落地坑:
核心痛点:Token限制导致的上下文溢出、多轮对话漂移(目标丢失)、工具调用引发的上下文爆炸与污染、记忆检索不精准、记忆冲突及长任务无法持续等问题。
核心解决方案:以"记忆分层、上下文压缩、智能检索"为核心,通过滑动窗口保留近期对话、上下文总结压缩冗余信息、RAG实现精准记忆召回、分层记忆架构区分短期/长期/任务记忆,搭配上下文排序与工具输出压缩等技术,构建以Context Manager为核心的生产级架构。同时,通过Prompt Budget规划、定期总结等最佳实践,在有限Token内为LLM提供最有价值的上下文。
上下文管理核心架构示意图如下:
四、ReAct编排:Agent的"规划能力",解决"该怎么做"的问题
有了工具(手脚)和记忆(大脑记忆),Agent还需要"规划能力"------明确"先做什么、再做什么、遇到问题该怎么办"。ReAct(Observation+Reasoning+Action)编排模式,正是解决这一问题的核心方案,其核心逻辑是「观察-思考-行动-再观察」的循环,让Agent具备动态决策能力。
4.1 ReAct的核心逻辑:动态循环,灵活应对
ReAct的核心优势的在于"灵活性"------它不预设固定的任务步骤,而是让Agent根据每轮的观察结果,动态决定下一步行动。简单来说,Agent不是一开始就知道所有步骤,而是"走一步看一步":如果第一轮搜索失败,会尝试更换搜索关键词;如果工具调用失败,会检查参数或更换工具,打破硬编码限制,适应变化的场景。
ReAct的核心循环流程为:
「思考(Reasoning)→ 行动(Action)→ 观察(Observation)→ 再思考 → 再行动」
4.2 ReAct与CoT的本质区别(面试高频考点)
很多人会将ReAct与Chain-of-Thought(CoT,思维链)混淆,但二者有本质区别,作为架构师,必须明确二者的适用场景:
-
CoT(思维链):仅依赖LLM内部知识进行逐步思考,不与外部世界交互,适合不需要外部信息、仅需逻辑推理的任务(如数学计算、逻辑分析)。但在处理需要最新信息、外部验证的任务时,极易陷入幻觉或错误传播。
-
ReAct:将推理过程与外部世界紧密结合,通过"行动"获取外部观察结果,再基于观察结果调整推理方向,适合需要外部交互、动态决策的任务(如多步工具调用、复杂信息检索)。
简单总结:CoT是"闭门思考",ReAct是"边做边想"。
4.3 ReAct的五大核心实现要素(工程落地必看)
要实现ReAct编排,必须明确其五大核心要素,这也是我们工程落地中重点关注的细节,缺一不可:
-
历史上下文:记录所有先前的思考、行动和观察结果,为下一轮推理提供依据;
-
当前环境信息:Agent在当下接收到的外部信息(如工具返回结果、用户补充输入);
-
语言模型(LLM):作为"大脑",负责根据历史上下文和当前环境信息,进行推理决策,确定下一步行动;
-
工具/动作:作为Agent的"手脚",执行LLM决策的具体行动(如调用工具、查询信息);
-
观察结果:每次行动后的反馈(如工具返回结果、查询到的信息),是下一轮推理的核心依据。
ReAct编排核心流程示意图如下:
五、架构总结:Agent四大模块的协同落地关键
作为Agent架构师,我始终认为:LLM Agent的落地,不在于"技术多先进",而在于"模块协同多顺畅"。总结一下四大模块的协同逻辑与落地关键:
-
LLM核心引擎:作为"大脑",核心是选择合适的模型(如GPT-4、Claude 3),并通过Prompt工程引导其精准推理;
-
工具调用:核心是"精准、高效、净化",通过动态加载、程序化编排、规范封装,解决上下文污染、效率低下的问题;
-
记忆存储:核心是"平衡",通过上下文工程、RAG/Agentic RAG,在最小化Token消耗的前提下,确保关键信息精准触达;
-
ReAct编排:核心是"灵活",通过"观察-思考-行动"的循环,实现动态决策,让Agent适应复杂多变的场景。
最后,给大家一个落地建议:搭建Agent系统时,不要一开始就追求"大而全",可以先从"单一模块落地"开始(如先实现简单的工具调用+记忆存储),再逐步完善四大模块的协同,最终实现生产级LLM Agent的稳定运行。