文章目录
前言
- 做二叉树题目一般都可以想到使用dfs来解题,也就是使用了递归算法,但仍要主动地将自己的思路往"大问题--->相同子问题"上去引导,这样更好地展开递归的思路。因为解二叉树问题惯性地上来就使用dfs,反而忽略了递归子问题的算法思路。
一、求根节点到叶节点数字之和
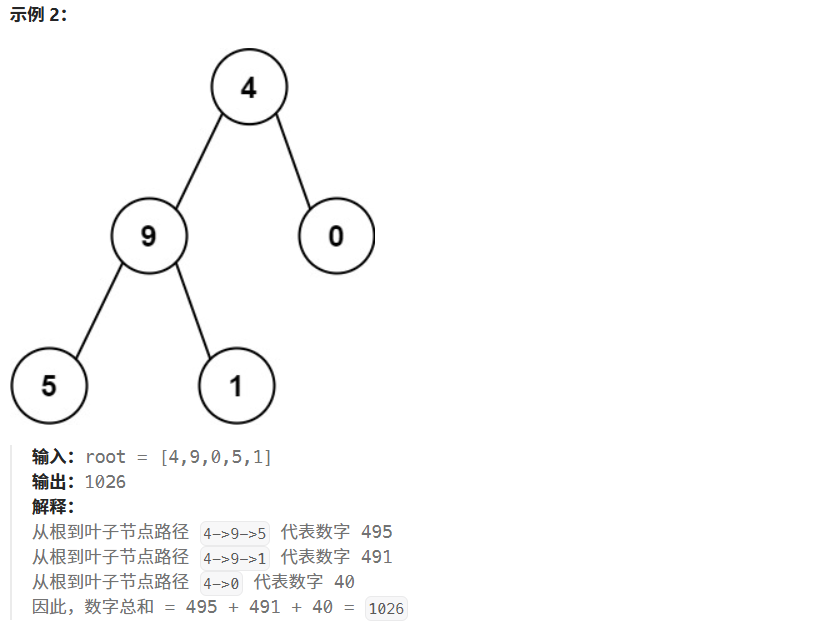
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。
解题思路
-
代表性二叉树路径问题,将所有路径所代表的数字进行加和。
-
在多路径问题中定位到每个路径进行数据的处理,一看多路径问题就会想是不是要使用多个变量维护每个路径的信息啊?其实不是,就是利用正常的二叉树的dfs来遍历每个路径,利用"回溯--->再换个方向继续深搜"来达到切换路径的目的。
-
将数字的信息一层一层地往下传,直到叶子节点便可得到一条路径所代表的数字,然后再通过"回溯--->再换个方向继续深搜"来达到切换路径的目的,去计算下一条路径的数字。
-
本题不仅要求得到每条路径的信息,还要进行所有信息的加和,所以函数头设计为"每一层递归返回该root下所有路径所代表的数字之和",这是个非常好的一个设计。
代码实现及解析
java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
class Solution {
public int sumNumbers(TreeNode root) {
int preSum=0;
return dfs(root,preSum);
}
public int dfs(TreeNode root,int preSum){//返回该以root为根节点的树所包含的所有路径的数字之和
preSum=preSum*10+root.val;//到了本递归(也就是该root节点),更新该路径的数字
//递归出口:
if(root.left==null&&root.right==null) return preSum;//root是叶子节点,它所包含的所有路径的数字就是preSum
//root不是叶子节点:
int ret=0;
//那么root树所包含的所有路径的数字之和就是它左子树和右子树所包含的路径的数字之和
if(root.left!=null)
ret+=dfs(root.left,preSum);
if(root.right!=null)
ret+=dfs(root.right,preSum);
return ret;
}
}总结
复习解题思路和代码实现及解析以前一般是只往下递归,在回溯的过程才进行结果的整合。而本题在递归的过程中就在一层一层地整合信息并往下传递了,在回溯的过程中再一层一层地处理信息,这种递归算法要熟记
二、验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 严格小于 当前节点的数。
节点的右子树只包含 严格大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
解题思路
- 利用二叉搜索树中序遍历的性质解题,在中序遍历的过程中逐个比较相邻节点值的大小
代码实现及解析
java
class Solution {
long prve=Long.MIN_VALUE;//记录中序遍历过程中上一次遍历到的节点值,用于进行比较判断是否符合二叉搜索树特性
public boolean isValidBST(TreeNode root) {
if(root==null) return true;//遇到空节点(递归出口),return true;
//中序遍历:
boolean left=isValidBST(root.left);
if(left==false) return false;//if已经查出左子树不是二叉搜索树,直接剪枝:return false
if(root.val<=prve) return false;//如果查出当前节点已不符合条件,直接return false
prve=root.val;//走到这一步说明合格,更新prev
boolean right=isValidBST(root.right);
if(right==false) return false;//if已经查出右子树不是二叉搜索树,直接剪枝:return false
return true;//走到这一步说明没有问题,return true
}
}总结
全局变量的优势: 不定义为全局变量,就要对这个变量进行传参,那就涉及到对这个变量的各种维护。而如果定义为全局变量,那每次递归都可以直接使用那一个变量 在本题中,我们需要prve变量全程跟随遍历过程来记录上一节点的val以便进行比较,就使用的全局变量。复习解题思路和代码实现的大致思路
三、二叉树的所有路径
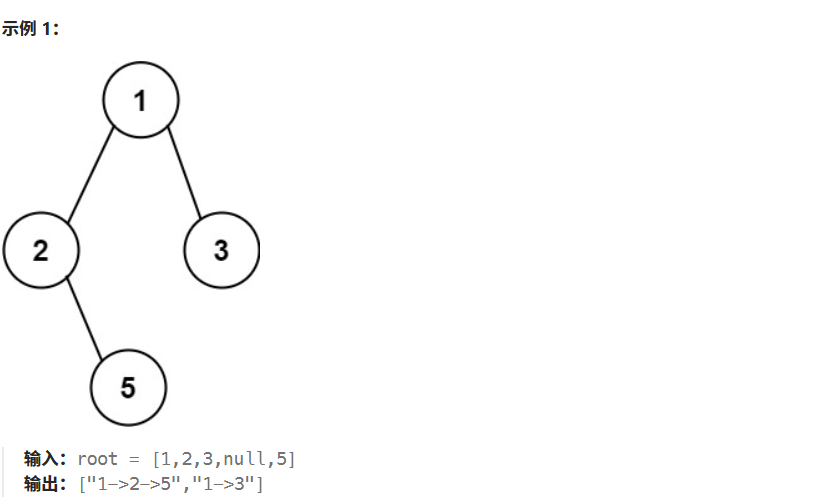
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
解题思路
- 和第一题一样,每层递归都会进行信息的传递,并进行数据的处理。一层一层地进行字符串的拼接,最终得到答案。
代码实现及解析
java
class Solution {
List<String> ret;//定义为全局变量,方便所有函数进行使用
public List<String> binaryTreePaths(TreeNode root) {
ret=new ArrayList<>();
dfs(root,new StringBuilder());
return ret;
}
void dfs(TreeNode root,StringBuilder path){
StringBuilder newPath=new StringBuilder(path);//一定不能直接对path进行append操作,不然无法进行"恢复现场"
newPath.append(root.val);
if(root.left==null&&root.right==null){//遇到叶子节点,可以直接add
ret.add(newPath.toString());
return;
}
newPath.append("->");//不是叶子节点,加上"->"继续往下走
if(root.left!=null) dfs(root.left,newPath);
if(root.right!=null) dfs(root.right,newPath);//可以看出整个过程是一个前序遍历
}
}总结
复习解题思路和代码实现及解析注意本题中回溯过程所体现的"恢复现场"操作(很常用):递归在回溯的时候path是要变回去的,不能带着下一层的信息(也就是拼接过的字符)继续使用,不然会对别的路径造成干扰,这就叫做"恢复现场"。那么本题中回溯操作就已经完成了"恢复现场",因为StringBuilder是当做参数进行传递的,回溯到上一层使用的就是上一层的path,所以path在往下传递的时候才不允许对引用类型StringBuilder直接进行操作,要在创建一个新的StringBuilder,不然还是污染了上一层的path信息当然本题也可以将path设计为全局变量,有时甚至更方便。如果path为全局变量就需要我们在回溯时手动进行"恢复现场"操作,比如本题回溯时我们要手动进行path的remove(更新)