目录
[1. String](#1. String)
[2. Hash](#2. Hash)
[3. List](#3. List)
[4. Set](#4. Set)
[5. Zset](#5. Zset)
[6. 类型补充](#6. 类型补充)
[1. Streams](#1. Streams)
[2. Geospatial](#2. Geospatial)
[3. Hyperloglog](#3. Hyperloglog)
[4. Bitmaps](#4. Bitmaps)
[5. Bitfield](#5. Bitfield)
[6. Scan](#6. Scan)
官方文档:Redis - The Real-time Data Platform
Redis与MySQL的区别
MySQL:数据存储于硬盘中,速度慢,通过"表"来存储数据,是"关系型数据库";
Redis:数据存储于内存中,速度快,但是存储空间有限,通过"键值对"来存储数据,是"非关系型数据库"
Redis:在内存中存储数据的中间件,作为数据库,用于数据缓存,在分布式系统中可以大展拳脚。
1. String
常见全局命令:
1)set key value:创建键值对
2)get key:查看键对应的值
3)keys pattern:查看匹配规则的key
4)exists key:判定key是否存在
5)del key:删除指定的key
6)expire key seconds:给key设置过期时间
7)ttl key:查询key的过期时间
8)type key:查询key对应的value类型
SET key value expiration EX seconds \| PX milliseconds \[NX\|XX
NX:如果key不存在才设置;如果key存在,则不设置(返回nil)
XX:如果key存在才设置(相当于更新key的value);如果key不存在则不设置(返回nil)
注意:GET 只支持字符串类型的value,其他类型使用GET获取会报错
MSET key1 value1 key2 value2 ...:一次性设置多个键值对
MGET key1 key2 ...:一次性获取多个键值对
SETNX / SETXX / SETPX
SETNX:不存在才设置,存在则设置失败
SETEX:设置的同时指定超时时间,单位秒
PSETEX:设置的同时指定超时时间,单位毫秒
键值对的运算操作:
incr key:value + 1
incrby key number:value + n
decr key:value - 1
decrby key number:value - n
incrbyfloat key number: value +/- 小数
APPEND key value:如果key已经存在且是一个string,将value追加到原有string后面;如果key不存在则等同于set命令,返回值为string的长度。
注意:汉字在utf-8字符集中,占3个字节。
在启动redis客户端时加上 --raw(redis-cli --raw) ,就可以使redis客户端能够自动把二进制数据尝试翻译成汉字。
Ctrl+S:冻结当前画面
Ctrl+Q:解除冻结
GETRANGE key start end:左闭右闭,类似于substring。例如:getrange key 0 -1:获取全部 string。
SETRANGE key offset value:从 offset 偏移量开始替换,替换成 value,返回值是替换后字符串的长度;针对不存在的key也可以操作,不过会把offset之前的内容填充成0x00。
STRLEN key:获取字符串的长度,单位字节
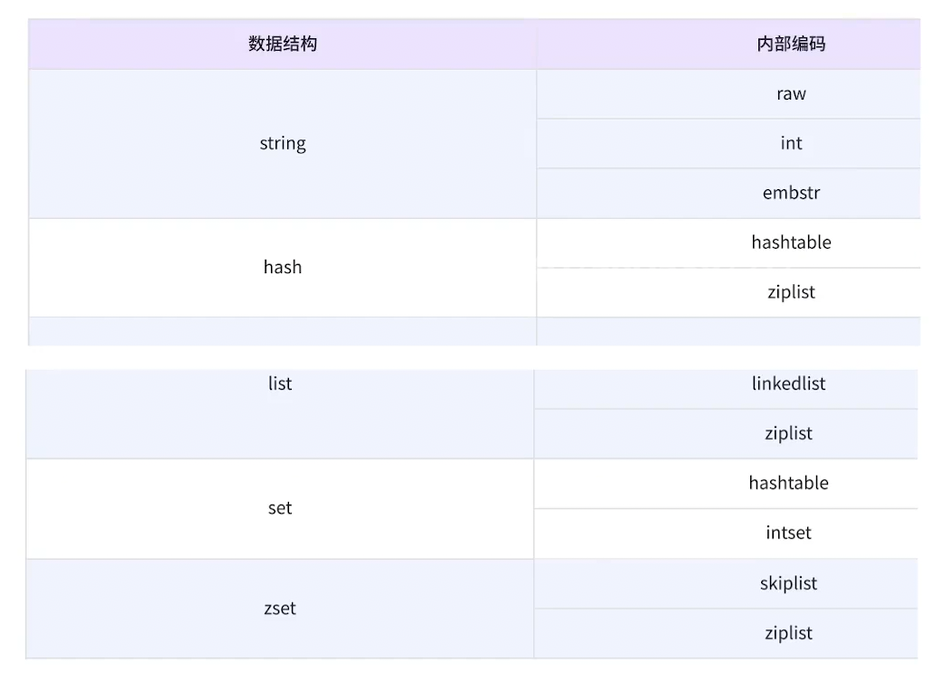
String编码方式:
int:8个字节的长整型
embstr:小于等于39个字节的字符串
raw:大于39个字符的字符串
整数当做int来存储,小数当做字符串来存储。
注意:Redis 不擅长数据统计。
2. Hash
常见全局命令:
hset key field value field value ...,返回值是设置成功的键值对的个数
hget key field:获取哈希表
hmget key field ...:一次查询多个value
hexists key field:返回值1表示存在,0表示不存在
hdel key field ...:返回值是本次操作删除的字段个数
hkeys key:获取hash中key的所有field字段
hvals :获取hash中所有的value值
hgetall key:获取hash中所有的field和value
hscan:遍历hash,但是属于"渐进式遍历"
HLEN key:获取hash的元素个数,不需要遍历 O(1)
HSETNX key field value:不存在时候才能设置成功,存在则设置失败
HINCRBY key field n:运算操作
HINCRBYFLOAT key field n:运算操作
HSTRLEN key field:计算长度
3. List
List链表
1)list中的元素是有序的;
2) list中的元素可以重复。
增加:
LPUSH key element ...:头插链表元素,可一个或多个,返回值为list的长度;如果key已经存在,且key对应的value类型,不是list,则lpush命令就会报错。
LRANGE key start stop:查看list中指定范围的元素,左闭右闭;如果下标超出范围,Redis会尽可能获取到给定区间的元素。
LPUSHX key element ...:头插链表元素,key不存在l则直接返回。
RPUSH key element ...:尾插链表元素,可一个或多个,返回值为list的长度。
RPUSHX key element ...:尾插链表元素,key不存在l则直接返回。
删除:
LPOP key count:头删list元素,一次删count个(Redis 5 以上支持)
RPOP key count:尾删list元素,一次删count个(Redis 5 以上支持)
LINDEX key index:给定下标,获取到对应的元素;如果下标非法,返回nil。
LINSERT key <before|after> pivot value:在基准值pivot前或后插入新元素value,返回值是新list的长度。
LLEN key:获取list长度。
LREM key count element: 在key中从前往后删除count个值为element的元素,count值为负数时从后往前删,返回值为成功删除元素的个数。
LTRIM key start stop:保留start和stop区间内的元素,左闭右闭。
LSET key index element:根据下标修改元素。
阻塞版本命令:
BLPOP key ... timeout :不存在该元素则在timeout时间内一直阻塞;
BRPOP key ... timeout:同上。
注意:如果命令中设置了多个key,那么会从左向右进行键遍历,知道有个键对应的列表中可以弹出元素,命令立即返回。
返回的结果是一个二元组,包括当前的数据来自哪个key,以及取到的数据是什么。
timeout单位是秒,从Redis 6 开始超时时间允许设定成小数。
4. Set
Set集合
集合中的元素是无序的;
集合中的元素不能重复。
SADD key member ...:给集合中添加元素,返回值为添加成功元素的个数。
SMEMBERS key:获取集合中的所有元素。
SISMEMBER key member:判定当前元素是否在集合中。
SPOP key count:随机删除count个元素,不写count就是随机删除一个,返回值为成功删除的元素。
SRANDMEMBER key count:随机获取集合中的count个元素,但不会删除。
SMOVE source destination member:将源Set中的member删除,插入目的Set中。
如果目的Set中已经有member,插入后不会有效果;如果源Set中没有member,返回0表示移动失败。
SREM key member ...:一次删除一个或多个member,返回值为删除成功的元素个数 。
交集(inter)
SINTER key ...:求交集,返回值为交集的元素,O(N*M),N是最小集合元素个数,M是最大集合元素个数。
SINTERSTORE destination key ...:直接把算好的交集放到destination这个key对应的集合中,返回值为交集的元素个数。
并集(union)
SUNION key ...:求并集,返回值为并集的元素 O(N),N是总的元素个数。
SUNIONSTORE destination key ...:直接把算好的并集放到destination这个key对应的集合中,返回值为并集的元素个数。
差集(diff)
SDIFF key ...:求差集,返回值为差集的元素,O(N),N是总的元素个数
SDIFFSTORE destination key ...:直接把算好的差集放到destination这个key对应的集合中,返回值为差集的元素个数
Set应用场景:
1)使用Set保存用户的"标签"
用户画像:Set方便计算交集,很容易找到两个用户之间的公共标签,基于这样的标签可以衍生出"用户关系"。
2)使用Set计算用户间的共同好友
如QQ推荐可能认识的好友。
3)使用Set统计UV
互联网衡量用户规模的指标主要是两方面:
PV:Page View,用户每次访问该服务器都会产生一个PV;
UV:User View,每个用户访问服务器都会产生一个UV,但是同一个用户的多次访问只算成一条,所以需要Set进行去重。
5. Zset
Zset 有序集合
1.有序(升序/降序)
给Zset中的member引入了一个属性:分数(score),浮点类型;
排序的时候就是依照分数score大小进行升序/降序;
既可以通过member找到对应的score,也可以通过score找到对应的member。
2.唯一
member唯一,score可以相同,不同member的score相同时,按照member的字典序排列。
ZADD key NX\|XX GT\|LT CH INCR score member score member ...:新增元素,返回值为新增元素的数量,O(logn),n为有序集合中元素个数
NX|XX:XX只更新存在的,不添加新元素;NX只添加新元素,不更新存在的。
如果不加NX|XX选项:member不存在,添加新member,member已存在,更新对应的score。
LT|GT:LT只更新比当前score小的score;GT只更新比当前score大的score,这个选项不会阻止添加新元素。
CH:让命令的返回值从"新增元素的数量"变为"新增元素数量 + 更新元素数量"。
INCR:针对现有元素的score进行运算,此时只能对一组score member进行计算,如 zadd key incr 1 zhangsan,返回值为修改后的score。
ZRANGE key start stop withscores:类似LRANGE,查看有序集合中的元素详情,默认升序。
ZREVRANGE key start stop withscores:查看有序集合中的元素详情,默认降序。
ZRANGEBYSCORE key start stop withscores:按照分数查找元素,指定分数作为区间
注意:这个命令可能会在6.2版本后弃用,合并到ZRANGE中。
ZCARD key:获取zset中元素的个数。
ZCOUNT key min max:返回分数在min和max之间的元素个数,左闭右闭,想不包含边界值就加上括号(,如 zcount key (1 (10,意为返回1和10之间的数,不包含1和10。O(logn)。
min和max可以写成浮点数,也支持 -inf(负无穷大)+inf(正无穷大)。
ZPOPMAX key count:删除并返回分数最高的count个元素,如果存在score相同的最大值,按照member的字典序删除一个,O((logN)*count)。
BZPOPMAX key ... timeout:ZPOPMAX的阻塞版本,timeout单位是秒,支持小数形式,返回值为key,member,score,O(logN)。
ZPOPMIN key count:删除并返回分数最低的count个元素,如果存在score相同的最小值,按照member的字典序删除一个,O((logN)*count)。
BZPOPMIN key ... timeout:ZPOPMIN的阻塞版本,timeout单位是秒,支持小数形式,返回值为key,member,score,O(logN)。
ZRANK key member:获取member元素的排名,O(logN)。
ZREVRANK key member:获取member元素的排名,反着算,O(logN)。
ZSCORE key member:查询指定member元素的分数,O(1)。
ZREM key member ...:删除元素,O(logN * M),N为整个有序集合的个数,M为要删除member的个数,返回值为删除成功元素的个数。
ZREMRANGEBYRANK key start stop:使用下标描述的范围进行删除,O(logN + M),N为整个有序集合的个数,M为start-stop区间中的元素个数,返回值为删除成功的元素。
ZREMRANGEBYSCORE key min max:按照分数删除指定范围的元素。
ZINCRBY key increment member:给指定member修改分数内容,同时移动元素位置保持有序,支持小数和负数。
ZINTER,ZUNION,ZDIFF 从Redis 6.2开始支持
ZINTERSTORE destination numkeys key key ... WEIGHTS weight \[weight ...] AGGREGATE \
: numkeys说明后续有几个有序集合参与运算;
weight为不同有序集合对应的权重,最终分数为权重*score再求和;
aggregate中给了三种处理member相同,score不同的情况时,交集最终的分数如何合并,默认是SUM。
ZUNIONSTORE destination numkeys key key ... WEIGHTS weight \[weight ...] AGGREGATE \
:同上。
zset编码方式:ziplist skiplist
zset应用场景:
1) 微博热搜
2)游戏天梯排行
3)成绩排行
6. 类型补充
1. Streams
模拟实现事件传播的机制。
2. Geospatial
存储坐标(经纬度),并根据坐标(半径、矩形区域)查找。
GEOADD
GEOSEARCH
3. Hyperloglog
估算Set集合中的元素个数,误差0.81%左右,即记录当前集合中有多少个不同的元素。
不存储元素的内容,但是能够记录"元素的特征",从而知道新增元素时,是一个已存在的元素还是第一次出现的元素。
PFADD
PFCOUNT
4. Bitmaps
位图,使用比特位表示整数,存储了元素内容,本质上还是一个集合,是Set类型针对整数的特化版本。
SETBIT
GETBIT
5. Bitfield
位域,可以理解成一串二进制序列(字节数组),把这个字节数组中的某几位,赋予特定的含义,并且可以进行读取/修改/算术运算相关操作。
6. Scan
keys *:一次性获取Redis中所有的key,这个操作很危险,可能会阻塞Redis服务器;
渐进式遍历:每执行一次命令,只获取其中一小部分,多次遍历获得全部的key。
SCAN cursor MATCH pattern COUNT count TYPE type:
cursor是光标,光标设置为0,表示从头开始获取;
count限制这一次遍历能获取到几个元素,默认是10,但是返回个数不一定是count,不精确;
type指定这次遍历想获取什么类型的key;
如scan 0 count 3,返回值的前半部分说明下次光标从哪里开始遍历,后半部分是这次遍历到的key中的内容。
注意:如果遍历过程中键有所变化(增加、修改、删除),可能导致遍历时键的重复遍历或者遗漏。