VMware安装
Ubuntu 安装
bash
# 创建 hadoop 专门用户
sudo useradd -m hadoop -s /bin/bash
# 为 hadoop 用户设置密码,之后需要连续输入两次密码
sudo passwd hadoop
# 为 hadoop 用户增加管理员权限,将 hadoop 添加到 sudo 管理组
sudo adduser hadoop sudo
# 切换当前用户为用户 hadoop
su hadoop
# 更新 hadoop 用户的 apt ,方便后面的安装
sudo apt updateSSH 安装
bash
sudo apt update
# 安装 SSH client/server
sudo apt install -y openssh-server
sudo apt install -y openssh-client
cd ~/.ssh/
# 执行这条命令后,连按三次回车来确认配置
ssh-keygen -t rsa
# 加入授权
cat ./id_rsa.pub >> ./authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 检验是否配置成功
ssh localhost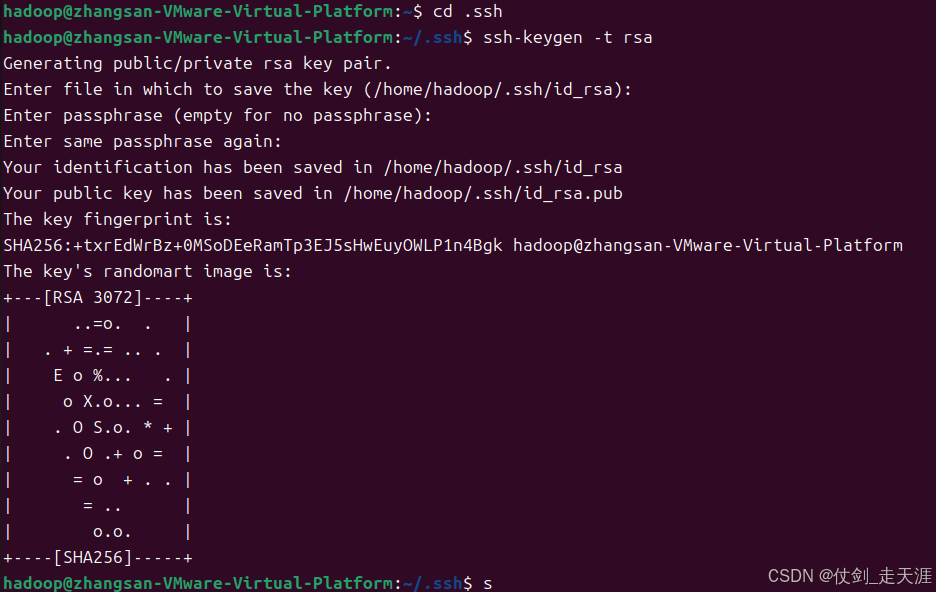
pdsh 安装
pdsh 是一个 "基于 SSH 的批量远程执行工具",专门用来 同时在多台机器上运行 shell 命令。
bash
# 更新软件源 + 直接安装pdsh(官方源自带,不用编译)
sudo apt update && sudo apt install -y pdsh
# pdsh 默认用老协议 rsh,我们要强制它只用 SSH
# 永久设置 pdsh 默认使用 SSH 协议
echo "export PDSH_RCMD_TYPE=ssh" >> ~/.bashrc
# 让配置立即生效
source ~/.bashrc
# 测试是否配置成功
pdsh -w localhost date
Java 安装
bash
# 进入 Downloads 目录
cd Downloads/
# java 下载
wget https://download.java.net/java/GA/jdk18/43f95e8614114aeaa8e8a5fcf20a682d/36/GPL/openjdk-18_linux-x64_bin.tar.gz
# 解压
tar -xzvf openjdk-18_linux-x64_bin.tar.gz -C ~/java/
# 验证一下是否安装成功
cd ~/java/jdk-18/bin
./java -version
# 配置环境变量
vi /etc/profile
# 在文件末尾添加
export JAVA_HOME=/home/hadoop/java/jdk-18 # 这里必须写绝对路径,不能用 ~
export PATH=$JAVA_HOME/bin:$PATH
# 更新
source /etc/profile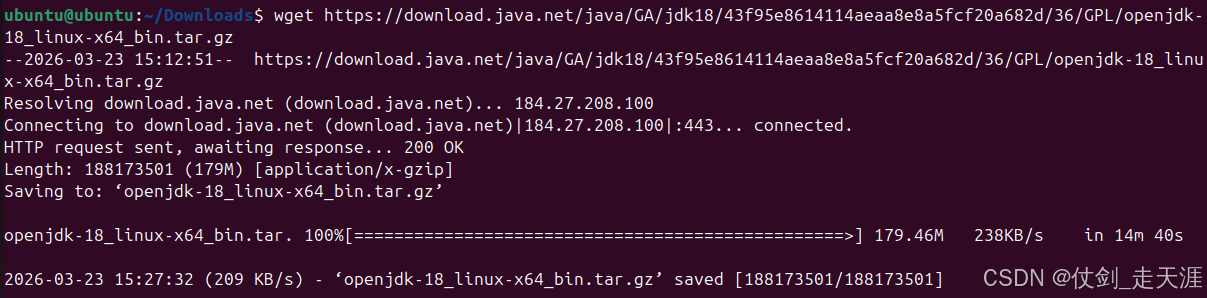
查看版本号,验证一下是否安装成功

Hadoop 安装
bash
# Hadoop 安装
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
# 直接解压到当前用户目录
tar -zxvf hadoop-3.3.5.tar.gz -C ~/hadoop/
# 配置环境变量
vi /etc/profile
# 在文件末尾添加
export HADOOP_HOME=/home/hadoop/hadoop/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 更新
source /etc/profile
# 查看是否设置成功
hadoop version

Hadoop 测试案例
Hadoop 官方自带的 WordCount 经典测试案例 ,用来验证 Hadoop 安装是否成功、能不能正常跑 MapReduce 任务!
bash
# 创建一个文件夹 用来存放要处理的原始数据文件
mkdir input
# 把配置文件复制到 input 里
# 用这些 XML 文件 当测试数据,让 Hadoop 去统计里面的单词
cp ./hadoop-3.3.5/etc/hadoop/*.xml input
# 运行官方示例
# 把结果写到 output 文件夹
hadoop jar ./hadoop-3.3.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'
# 查看运行结果
cat output/*
# 在 HDFS 分布式文件系统里,强制删除名为 output 的文件夹
hdfs dfs -rm -r -f outputHadoop 单机配置
bash
cd /home/hadoop/hadoop-3.3.5/
# Hadoop 的临时工作目录
mkdir tmp
# 存放 NameNode 元数据(文件目录树)
mkdir tmp/name
# 存放 DataNode 真实数据块
mkdir tmp/data
# 让 Hadoop 能随便读写,不报错
chmod 777 tmp tmp/name tmp/data配置 JAVA_HOME
修改 hadoop-3.3.5/etc/hadoop/hadoop-env.sh 这个文件

修改 hadoop-3.3.5/etc/hadoop/core-site.xml 这个文件
- 临时文件就放我刚创建的 tmp 文件夹里!
- HDFS 访问地址是本机 9000 端口
XML
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-3.3.5/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改 hadoop-3.3.5/etc/hadoop/hdfs-site.xml 这个文件
-
dfs.replication=1 ==》单机模式,副本数 = 1(不用备份)
-
dfs.namenode.name.dir ==》NameNode 元数据存在 tmp/dfs/name
-
dfs.datanode.data.dir ==》 DataNode 真实数据存在 tmp/dfs/data
XML
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-3.3.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-3.3.5/tmp/dfs/data</value>
</property>
</configuration>以上是单机本地运行需要配置的内容。
如果要配置成伪分布,则需要继续配置mapred-site.xml、yarn-site.xml。
给 HDFS 分布式文件系统 初始化、格式化!
bash
hdfs namenode -format格式化只需要执行 1 次!!!
千万不要重复执行!!!
重复格式化会导致集群无法启动,数据全部丢失!
启动 HDFS
Hadoop 用户进入 /home/hadoop/hadoop-3.3.5 目录
bash
# 启动
sbin/start-dfs.sh**启动 Hadoop 分布式存储系统!**会自动启动:
- NameNode(总管)
- DataNode(存数据)
- SecondaryNameNode(辅助)

hadoop守护程序日志输出将写入 HADOOP_LOG_DIR目录(默认为 HADOOP_HOME/logs)
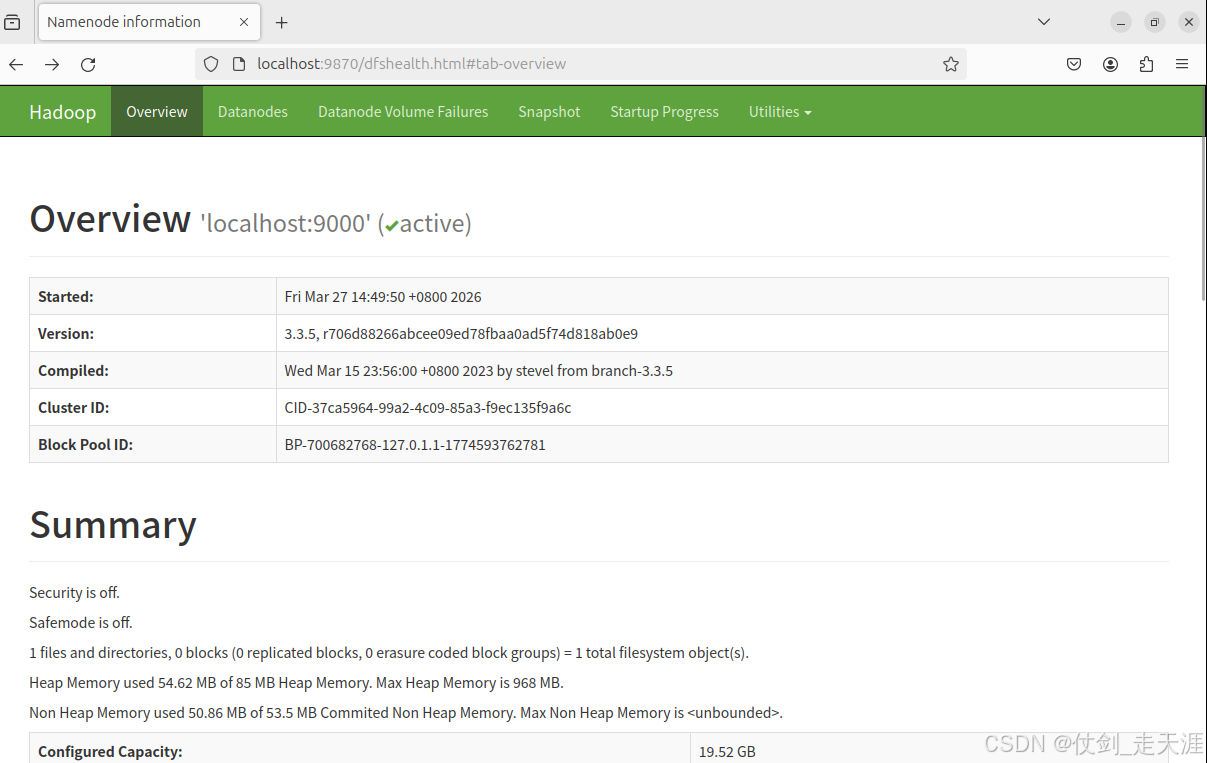
Web 界面查看 HDFS 状态
bash
http://localhost:9870打开浏览器,可视化看 Hadoop 状态:
- 存了多少数据
- 有多少节点
- 健康状态
这是管理 Hadoop 最方便的页面!
创建 HDFS 目录
bash
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop上传文件到 HDFS
把本地的配置文件上传到 Hadoop 分布式存储里
让 Hadoop 可以读取并处理。
bash
hdfs dfs -mkdir input
hdfs dfs -put etc/hadoop/*.xml input运行 MapReduce 测试任务
bash
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'查看分布式文件系统上的输出
bash
hdfs dfs -cat output/*
记得删除输出文件
bash
hdfs dfs -rm -r -f output停止 HDFS

bash
# 进入 Hadoop 安装目录(如果不在的话)
cd /home/hadoop/hadoop-3.3.5
# 停止 HDFS 所有守护进程
sbin/stop-dfs.sh验证服务是否停止
bash
jps如果看不到 NameNode、DataNode、SecondaryNameNode 等进程,就说明服务已经完全停止了
