网络数据采集概述
爬虫(Crawler)也常被称作网络蜘蛛(Spider),是一类按照预设规则,自动访问网络站点并提取目标数据的自动化程序或脚本代码,目前被广泛应用于互联网搜索引擎与各类数据采集场景中。我们日常使用网页时,除了直观可见的文本内容,页面中还包含大量超链接,网络爬虫正是依托这些超链接,不断获取新的网页地址,进而持续完成全网数据采集工作。也正是因为这种遍历式的采集逻辑,如同爬虫、蜘蛛在网络空间中漫游,这类程序也被赋予了形象化的别称。
爬虫的应用领域
理想状态下,各类互联网内容提供商(ICP)都应开放专属API接口,对外共享允许获取的公开数据,这种场景下无需使用爬虫程序。国内头部电商平台(淘宝、京东等)、主流社交平台(微博、微信等)均提供了官方API接口,但这类接口往往会对抓取数据范围、请求频率做出严格限制。对绝大多数企业而言,实时获取行业数据、竞品数据是维持市场竞争力的核心环节,而自主数据积累又是多数企业的短板,这种情况下,通过合规爬虫获取公开数据,并从中挖掘商业价值信息,就成为了企业补齐数据短板的重要途径。
爬虫的实际应用场景十分广泛,以下为几类核心应用方向,感兴趣的读者可进一步深入探究:
-
搜索引擎
-
新闻聚合
-
社交应用
-
舆情监控
-
行业数据采集
爬虫合法性探讨
坊间常流传"爬虫写得好,牢饭吃到饱"的说法,那么开发、使用爬虫程序究竟是否涉及违法?我们可以从以下几个维度客观解读:
-
网络爬虫领域仍处于规范逐步完善阶段,目前行业内已通过Robots协议(网络爬虫排除标准)形成了基础的行业自律规范,但对应的法律法规仍在持续建立与完善中,该领域现阶段仍属于法律监管的灰色地带。
-
遵循"法不禁止即为许可"的原则,若爬虫仅获取网页前端展示的公开信息,而非后台私密敏感数据,且未触碰法律禁止条款,无需过度担忧法律风险;毕竟当前大数据产业发展速度,远超相关法律法规的完善速度。
-
执行数据爬取时,需严格遵守目标站点Robots协议,同时合理控制爬虫请求频率,避免对站点服务器造成压力;使用采集数据时,必须尊重平台知识产权,Web 2.0时代下,即便内容由用户生成,平台也投入了大量运营成本,且用户注册发布内容时,平台通常已获取数据所有权、使用权与分发权,违反相关规则极易产生法律纠纷且败诉风险极高。
-
编写爬虫程序时,做好身份隐匿是必要操作,同时要杜绝一切可能破坏对方服务器等动产的行为,避免被举证追责。
-
切勿在GitHub、Gitee等公网代码托管平台开源、展示爬虫代码,这类行为极易给自己带来不必要的法律与安全麻烦。
Robots协议
绝大多数网站都会配置robots.txt文件,该协议属于行业君子协议,并非具备强制约束力的法律条款。我们以淘宝的robots.txt文件为例,直观解读站点对爬虫的限制规则。
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
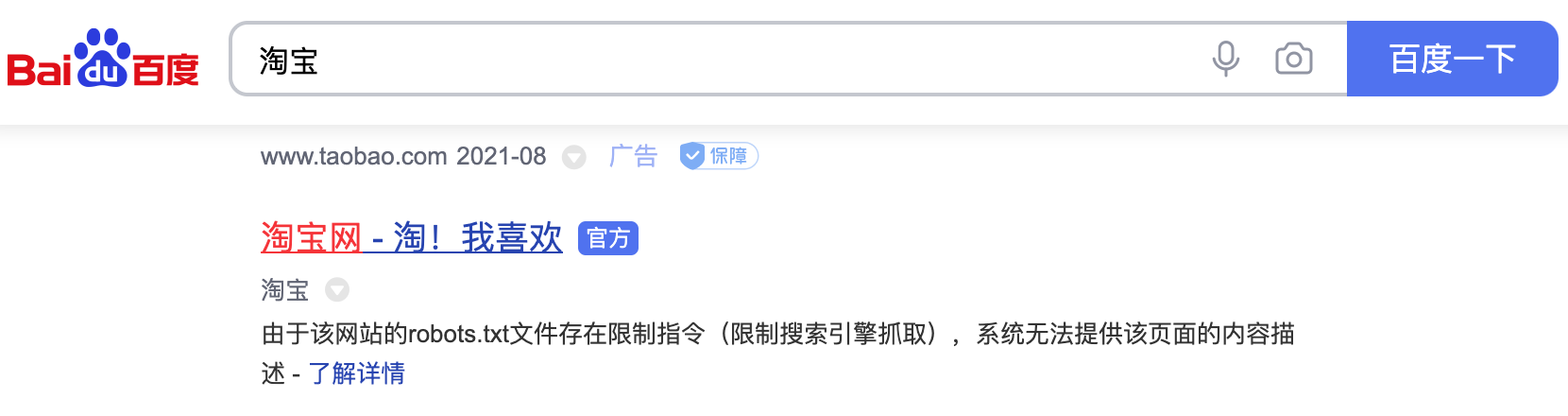
Disallow: /从上述配置可以看出,淘宝明确禁止百度爬虫抓取站内任何资源,这也是百度搜索"淘宝"时,结果页会提示"由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统无法提供该页面的内容描述"的原因。百度作为主流搜索引擎,表面遵守了淘宝的Robots协议,因此用户无法通过百度检索到淘宝内部商品信息。
图1. 百度搜索淘宝的结果
以下是豆瓣网的robots.txt文件,大家可以自行解读,分析其对爬虫的具体限制:
User-agent: *
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /forum/
Disallow: /new_subject
Disallow: /service/iframe
Disallow: /j/
Disallow: /link2/
Disallow: /recommend/
Disallow: /doubanapp/card
Disallow: /update/topic/
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap: https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
Disallow: /subject_search
Disallow: /amazon_search
Disallow: /search
Disallow: /group/search
Disallow: /event/search
Disallow: /celebrities/search
Disallow: /location/drama/search
Disallow: /j/超文本传输协议(HTTP)
正式学习爬虫开发前,我们先回顾超文本传输协议(HTTP)相关知识,日常网页内容是浏览器解析HTML(超文本标记语言)生成的,而HTTP正是承载HTML数据传输的核心应用层协议。HTTP与多数应用层协议一致,构建于TCP(传输控制协议)之上,依托TCP可靠传输特性,实现Web应用间的数据高效交互。根据维基百科定义,HTTP最初设计目的,就是提供发布、接收HTML页面的标准方式,也是浏览器与Web服务器之间数据传输的核心载体。想要深入了解HTTP协议细节、发展历程,可阅读《HTTP 协议入门》《互联网协议入门》《图解 HTTPS 协议》等优质文章系统学习。
下图是使用开源协议分析工具Ethereal(WireShark前身),抓取的访问百度首页时的HTTP请求与响应报文,该工具可捕获网络适配器传输的全量数据,能清晰展示从物理链路层到应用层的完整协议数据。
图2. HTTP请求
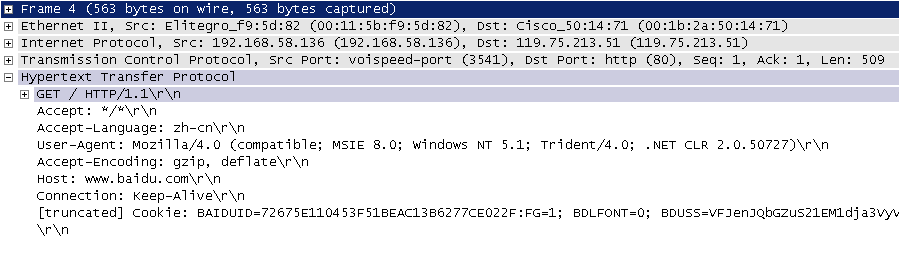
HTTP请求主要由请求行、请求头、空行、消息体四部分组成,若无数据向服务器传输,消息体为非必需模块。请求行包含请求方法(GET、POST等)、资源路径、协议版本三类信息;请求头由多组键值对构成,记录浏览器信息、编码方式、语言偏好、缓存策略等参数;请求头末尾通过空行与消息体分隔。

图3. HTTP响应
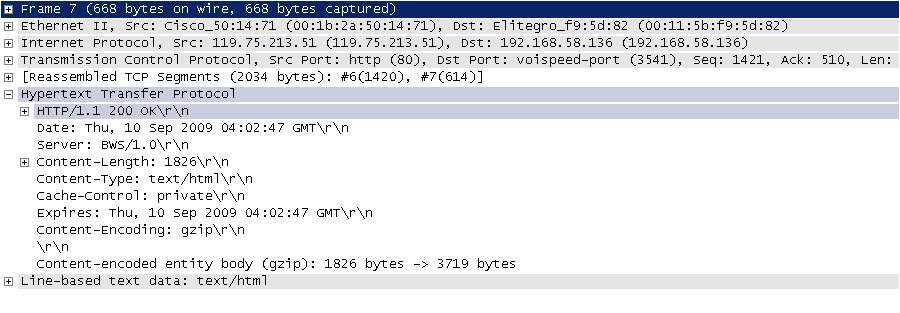
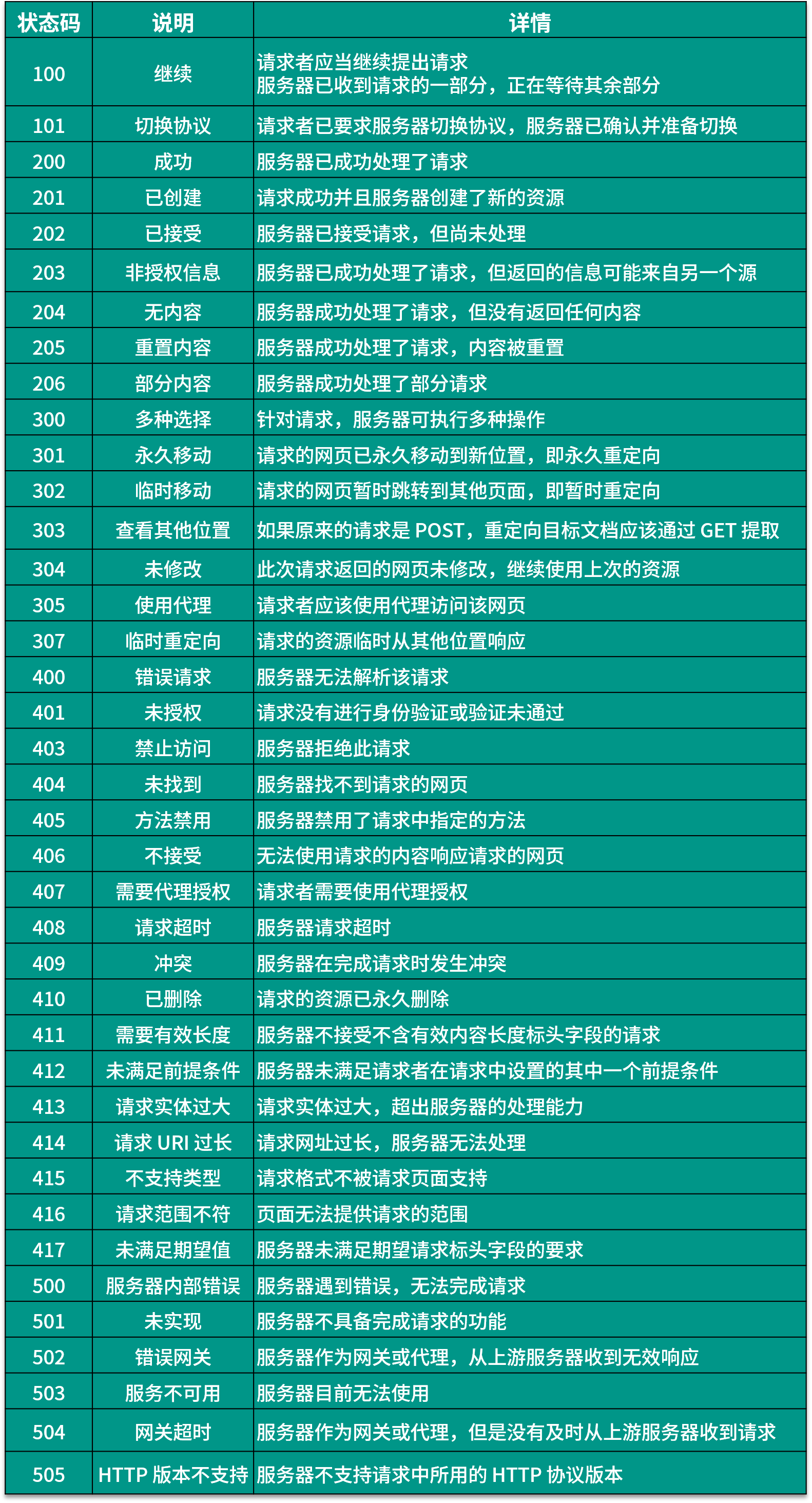
HTTP响应主要由响应行、响应头、空行、消息体四部分组成,其中消息体是服务器返回的核心数据,格式可能为HTML页面、JSON数据、二进制文件等。响应行包含协议版本与响应状态码,常见状态码含义如下表所示。
相关工具
以下为几款爬虫开发必备辅助工具,熟练使用能大幅提升开发与调试效率:
- Chrome Developer Tools:谷歌浏览器自带开发者工具,核心常用模块如下:
• 元素(Elements):查看、修改HTML元素属性、CSS样式、绑定监听事件,支持CSS实时修改实时生效,便捷完成页面调试。
• 控制台(Console):执行临时JavaScript代码、查看JS对象、输出调试日志与异常信息,是专属的JS代码交互式运行环境。
• 源代码(Sources):查看页面HTML、JS、CSS源码,支持JS代码断点调试、单步执行,是前端与爬虫调试的核心模块。
• 网络(Network):监控完整HTTP请求、响应报文,查看网络连接、请求参数、响应结果等全量信息。
• 应用(Application):查看浏览器本地存储数据,包含Cookie、Local Storage、Session Storage等,也是爬虫模拟登录的核心调试模块。
-
Postman:功能全面的API调试与RESTful请求工具,可灵活模拟各类HTTP请求,自定义请求参数、请求头,直观查看服务器响应结果,是爬虫接口调试的利器。
- HTTPie:轻量化命令行HTTP客户端,操作简洁、输出格式清晰,适合快速发起HTTP请求测试。
安装命令:pip install httpie使用示例:`http --header https://movie.douban.com/
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Tue, 24 Aug 2021 16:48:00 GMT
Keep-Alive: timeout=30
Server: dae
Set-Cookie: bid=58h4BdKC9lM; Expires=Wed, 24-Aug-22 16:48:00 GMT; Domain=.douban.com; Path=/
Strict-Transport-Security: max-age=15552000
Transfer-Encoding: chunked
X-Content-Type-Options: nosniff
X-DOUBAN-NEWBID: 58h4BdKC9lM`
- builtwith库:Python第三方库,可快速识别目标网站所使用的技术栈,辅助爬虫针对性适配站点架构。
安装命令:pip install builtwith使用示例:`import ssl
import builtwith
ssl._create_default_https_context = ssl._create_unverified_context
print(builtwith.parse('http://www.bootcss.com/'))`
- python-whois库:Python第三方库,可查询网站域名所有者、注册信息,辅助了解站点归属。
安装命令:pip3 install python-whois使用示例:`import whois
print(whois.whois('https://www.bootcss.com'))`
爬虫的基本工作流程
基础爬虫主要包含三大核心模块:数据采集(网页下载)、数据处理(网页解析)、数据存储(有效信息持久化);更高级的爬虫为提升效率,会引入并发、分布式采集技术,同时配套调度器(分配线程/进程执行任务)、后台管理程序(监控爬虫状态、校验采集结果)等模块。
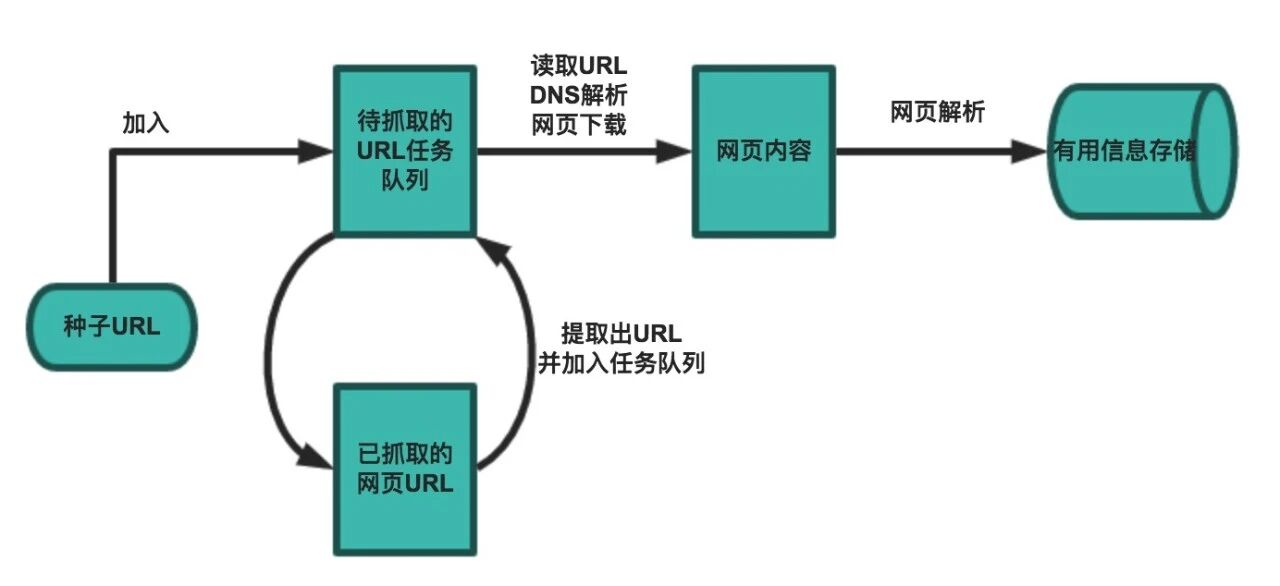
常规情况下,爬虫的完整工作流程包含以下步骤:
-
设定采集目标,确定种子页面(起始页面),发起请求并下载网页。
-
服务器访问失败时,按照预设重试次数,自动发起重试请求。
-
按需配置User-Agent、代理IP,隐匿真实请求身份,避免被站点拦截。
-
对下载的网页进行编码解码处理,提取目标数据信息。
-
通过正则表达式、标签匹配等方式,从页面中抽取新的链接地址。
-
对抽取的链接去重、校验,循环执行页面下载与数据解析操作。
-
将清洗后的有效数据持久化存储,方便后续数据分析与使用。
国内直接使用顶级AI工具
谷歌浏览器访问:
https://www.nezhasoft.cloud/r/vMPJZr
