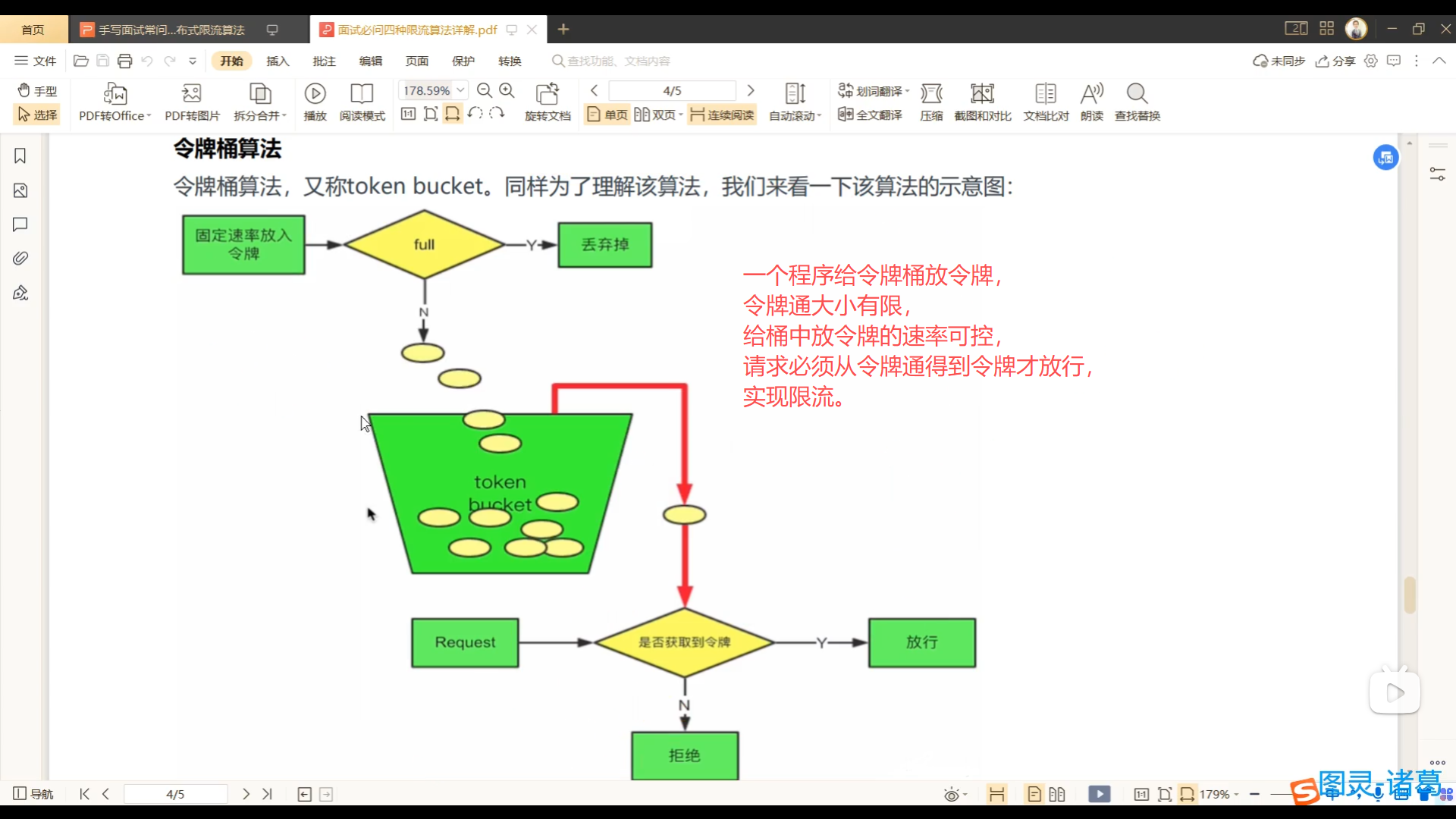
限流的方法,Redis 计算器限流算法、滑动时间窗口限流算法、漏漏桶限流算法、令牌桶限流算法,Java 开发
一、参考资料
【Java手写4种分布式限流算法(Sentinel限流/Redis计算器限流/滑动时间窗口/漏桶限流/令牌桶限流)1天学会,让你面试少走99%的弯路!】 https://www.bilibili.com/video/BV1yPA5e7ERU/?share_source=copy_web\&vd_source=855891859b2dc554eace9de3f28b4528
二、推荐使用 Redis 简单计数器限流算法
01、限制 1 秒内允许 100 个请求
其它的限流算法实现起来比较有难度,而且使用简单计数器限流算法满足大部分系统的需求,除非你国内顶级的淘宝这样的系统,需要顶级的完善的限流算法。
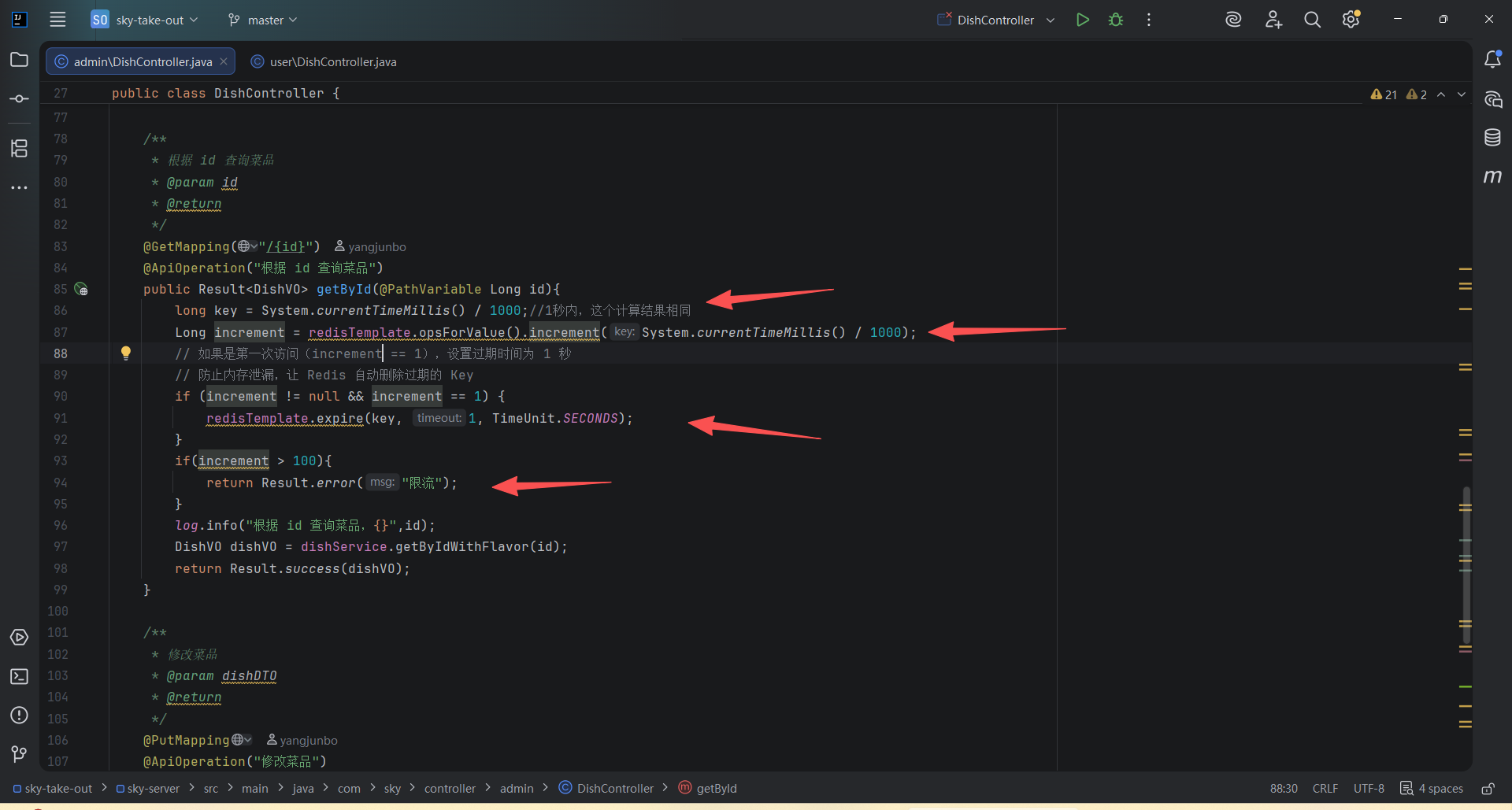
三、AI 回答,上图简单计算器限流算法能用吗
这段代码从语法上是正确的,能跑通,但在实际生产环境中存在严重的逻辑缺陷。
简单来说:你实现的是**"全局限流"(所有用户共享一个额度),而不是通常需要的"单接口/单用户限流"**。
以下是详细的分析和改进建议:
❌ 当前代码存在的 3 个主要问题
1. 限流范围错误(最严重的问题)
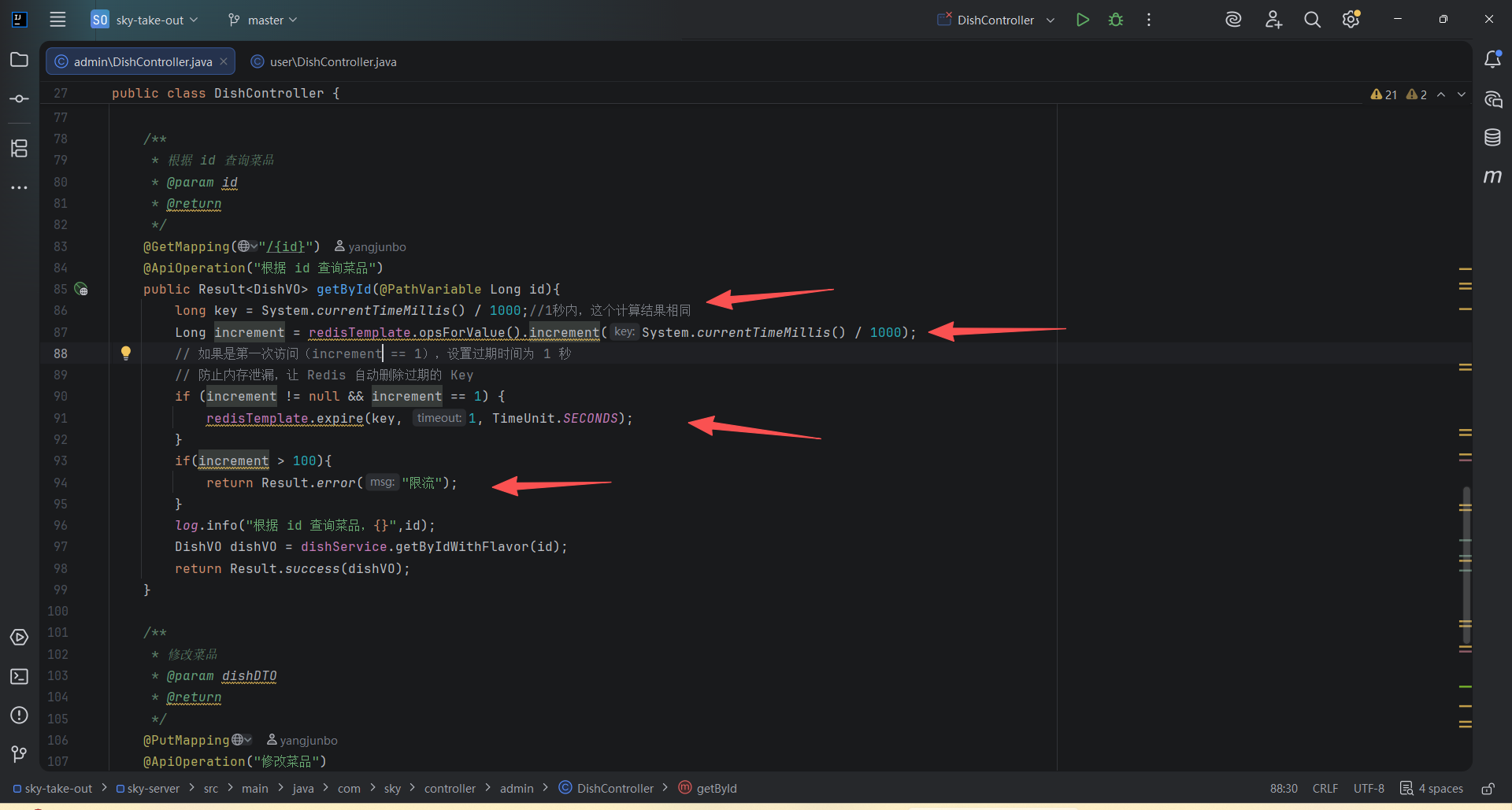
- 你的逻辑 :Key 是
System.currentTimeMillis() / 1000(即当前秒数,例如1712345678)。 - 后果 :这是一个全局计数器 。
- 假设你有 1000 个用户。
- 前 100 个用户访问成功。
- 第 101 个用户访问时,计数器变成 101,直接返回"限流"。
- 结果:剩下的 900 个用户全部无法访问。
- 通常需求 :我们通常希望每个用户 (或每个 IP)每秒能访问 100 次,而不是所有用户加起来每秒只能访问 100 次。
2. 时间窗口边界问题("突刺"现象)
- 你的逻辑 :使用
当前秒数作为 Key。 - 后果 :Redis 的 Key 会在每秒切换一次。
- 场景 :假设在
12:00:01.900(第 1 秒末)来了 100 个请求,计数器满了。 - 紧接着 :在
12:00:02.100(第 2 秒初)又来了 100 个请求。 - 结果 :在短短 200 毫秒的时间差内,实际上处理了 200 个请求(第 1 秒的 100 个 + 第 2 秒的 100 个)。这违背了"每秒限流 100"的初衷。
- 场景 :假设在
3. Key 的过期时间(内存泄漏风险)
- 问题:你没有设置 Key 的过期时间(TTL)。
- 后果 :虽然 Key 是秒级的,看起来好像会自动"失效"(因为下一秒 Key 变了),但 Redis 中会永久保留历史秒的 Key(如
1712345670,1712345671...)。随着时间推移,Redis 会存储数亿个无用的 Key,导致内存爆满。
✅ 改进方案
如果你只是想简单修复代码,使其符合"单用户限流",可以这样改:
方案一:基于用户的固定窗口限流(修复版)
将 Key 绑定到用户 ID 或 IP 上,并设置过期时间。
java
@GetMapping("/{id}")
public Result<DishVO> getById(@PathVariable Long id, HttpServletRequest request) {
// 1. 获取用户唯一标识(例如 IP 地址,或者从 Token 中解析出的 userId)
String ip = request.getRemoteAddr();
// 2. 构造 Redis Key:固定前缀 + 用户标识 + 当前秒数
// 这样不同用户的计数是隔离的
String key = "rate_limit:dish:" + ip + ":" + (System.currentTimeMillis() / 1000);
// 3. 自增
Long count = redisTemplate.opsForValue().increment(key);
// 4. 如果是第一次访问(count == 1),设置过期时间为 1 秒
// 防止内存泄漏,让 Redis 自动删除过期的 Key
if (count != null && count == 1) {
redisTemplate.expire(key, 1, TimeUnit.SECONDS);
}
// 5. 判断是否超限
if (count != null && count > 100) {
return Result.error("限流:访问过于频繁");
}
log.info("根据 id 查询菜品,{}", id);
DishVO dishVO = dishService.getByIdWithFlavor(id);
return Result.success(dishVO);
}方案二:使用 Redisson(推荐,生产级)
手动实现限流容易出 Bug(如上面的边界问题)。在生产环境中,强烈建议使用 Redisson 框架提供的 RRateLimiter,它实现了标准的令牌桶算法 或漏桶算法,更加平滑和精准。
引入依赖 (Maven):
xml
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.20.0</version> <!-- 选最新版本 -->
</dependency>代码实现:
java
@Autowired
private RedissonClient redissonClient;
@GetMapping("/{id}")
public Result<DishVO> getById(@PathVariable Long id, HttpServletRequest request) {
String ip = request.getRemoteAddr();
// 获取限流器对象,Key 绑定 IP
RRateLimiter rateLimiter = redissonClient.getRateLimiter("rate_limit:dish:" + ip);
// 设置限流规则:每秒允许 100 个请求(令牌桶容量 100, refill 速率 100/s)
// 只需要设置一次即可,实际项目中通常放在初始化代码块中
rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.SECONDS);
// 尝试获取许可
if (rateLimiter.tryAcquire()) {
// 获取成功,执行业务
log.info("根据 id 查询菜品,{}", id);
DishVO dishVO = dishService.getByIdWithFlavor(id);
return Result.success(dishVO);
} else {
// 获取失败,限流
return Result.error("限流:访问过于频繁");
}
}📌 总结
你的原始代码:
- 能不能跑? 能。
- 对不对? 不对。它是全局限流,且没有设置过期时间。
- 建议: 至少加上 用户/IP 标识 作为 Key 的一部分,并加上
expire设置。如果项目允许,请使用 Redisson。
四、只需要设置一次即可,实际项目中通常放在初始化代码块中,怎么操作
这其实就是利用 Spring 的特性,在应用启动时只运行一次配置逻辑。最推荐的做法是写一个配置类,配合 @PostConstruct 注解,这样既符合 Spring 的规范,又能确保在 Bean 创建好后立即执行。
以下是具体的操作步骤和代码示例:
🛠️ 核心思路
- 创建一个专门的配置类(例如
RedissonConfig)。 - 注入
RedissonClient。 - 使用
@PostConstruct注解标记一个初始化方法。 - 在该方法中调用
trySetRate。
💻 代码实现
java
import org.redisson.api.RateIntervalUnit;
import org.redisson.api.RRateLimiter;
import org.redisson.api.RateType;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
@Configuration
public class RedissonRateLimiterConfig {
@Autowired
private RedissonClient redissonClient;
/**
* 这个方法会在 RedissonConfig 这个 Bean 创建完成后自动执行
* 且只会执行一次
*/
@PostConstruct
public void initRateLimiter() {
// 1. 定义限流器的 Key(注意:这里定义的是"限流规则模板"的 Key,
// 实际业务中每个用户会有独立的 Key,但规则是共享的,所以配置一次即可)
String limiterKey = "rate_limit:dish:";
// 2. 获取限流器对象
RRateLimiter rateLimiter = redissonClient.getRateLimiter(limiterKey);
// 3. 尝试设置限流规则
// 参数说明:
// RateType.OVERALL: 限流总量(所有实例共享配额,如果是集群模式)
// 100: 速率(每秒允许 100 个请求)
// 1: 时间间隔
// RateIntervalUnit.SECONDS: 时间单位
boolean isSet = rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.SECONDS);
if (isSet) {
System.out.println("✅ 限流规则初始化成功:100次/秒");
} else {
System.out.println("ℹ️ 限流规则已存在,跳过初始化");
}
}
}💡 为什么要这样做?
性能优化
trySetRate 虽然是一个轻量级操作,但它仍然涉及网络通信(向 Redis 发送命令)。
- 如果不放在初始化中 :每次用户请求接口时都调用一次
trySetRate,会造成不必要的网络开销。 - 放在初始化中 :应用启动时设置一次,后续请求直接使用
tryAcquire()即可,速度极快。
幂等性
Redisson 的 trySetRate 是幂等的。
- 第一次调用:在 Redis 中写入配置。
- 后续调用:发现配置已存在,直接忽略。
所以即使你的服务重启了多次,或者有多个实例(在 Kubernetes 或 Docker 中),这个逻辑也是安全的。
⚠️ 进阶:如果是微服务集群怎么办?
如果你的应用部署了多个实例(例如 3 台服务器),上面的代码会在每台服务器启动时各执行一次 trySetRate。这通常没有问题,因为 trySetRate 会检查是否已存在。
但如果你希望更严谨 ,或者限流规则是动态配置在数据库/Nacos 中的,可以使用 Spring 的事件监听:
java
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.event.EventListener;
import org.springframework.stereotype.Component;
@Component
public class RateLimiterInitializer {
@Autowired
private RedissonClient redissonClient;
// 监听应用完全启动就绪的事件
@EventListener(ApplicationReadyEvent.class)
public void initOnStartup() {
// 这里写初始化逻辑
// 可以在这里从数据库读取动态的限流数值(比如 200 次/秒),而不是写死 100
RRateLimiter rateLimiter = redissonClient.getRateLimiter("rate_limit:dish:");
rateLimiter.trySetRate(RateType.OVERALL, 200, 1, RateIntervalUnit.SECONDS);
}
}📌 总结
对于你的场景,直接使用 @PostConstruct 是最简单、最标准的做法。把它放在一个单独的 Config 类里,保持代码整洁。
五、笔记总结
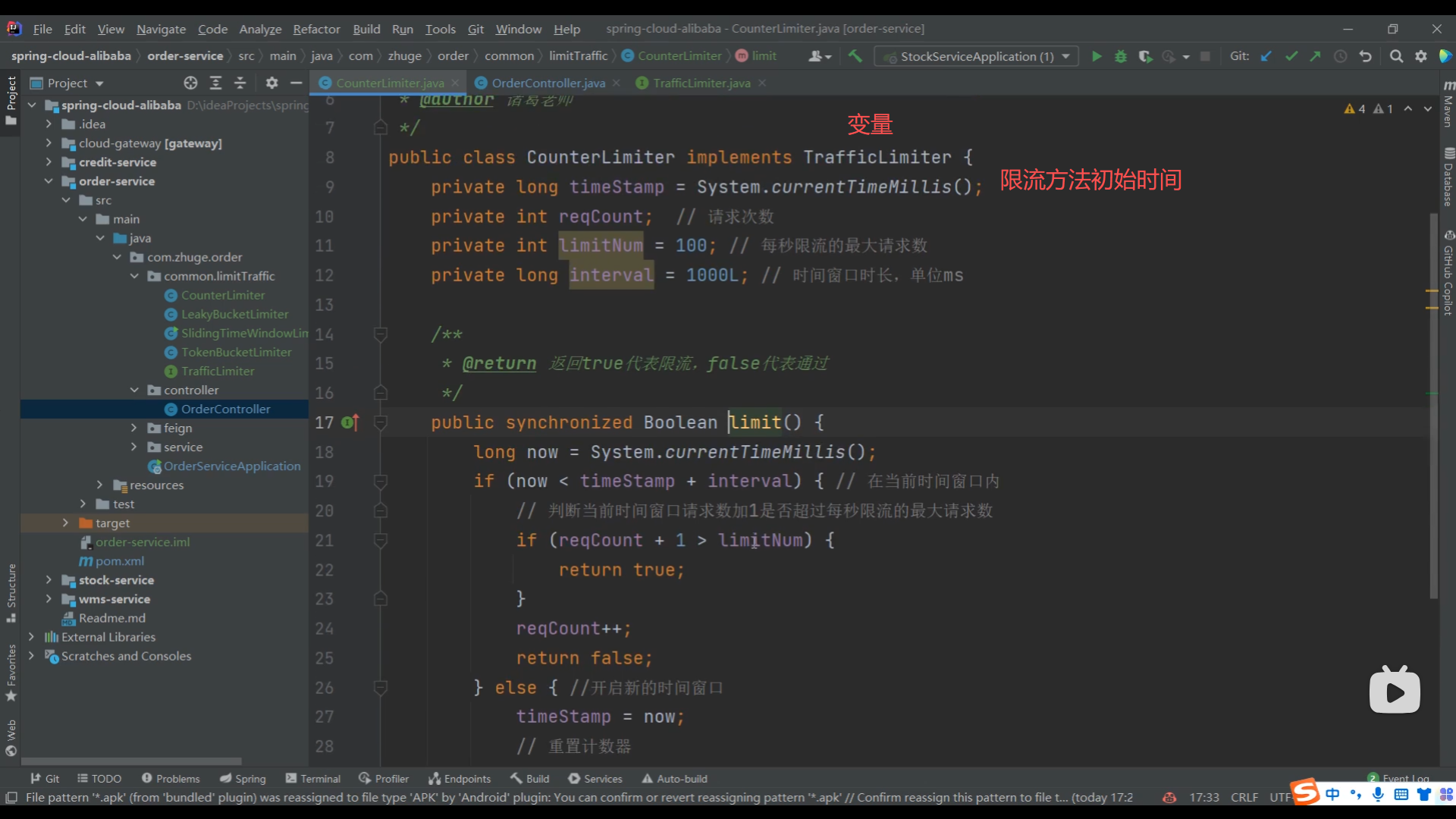
04、简单计数器限流算法实现
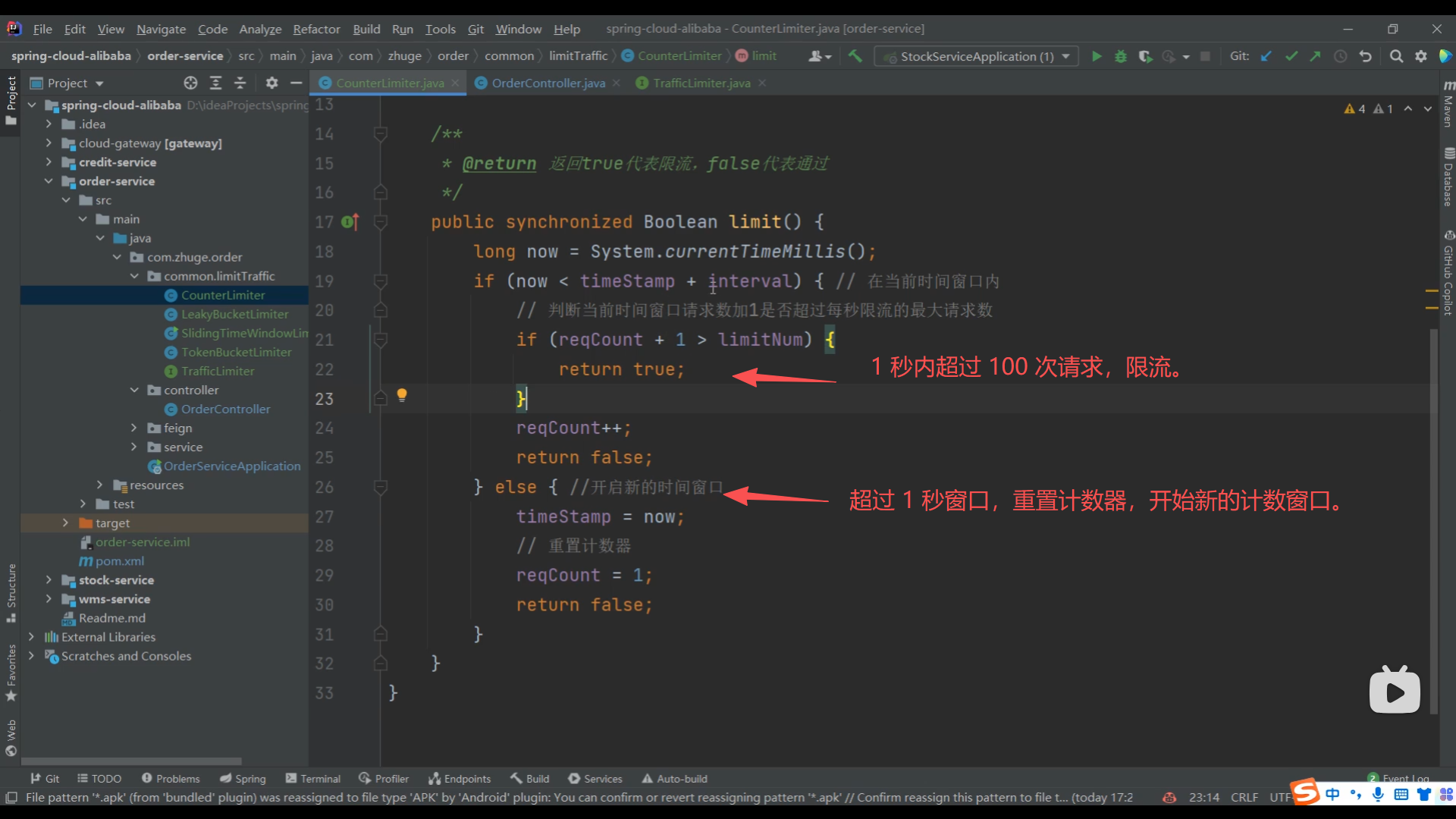
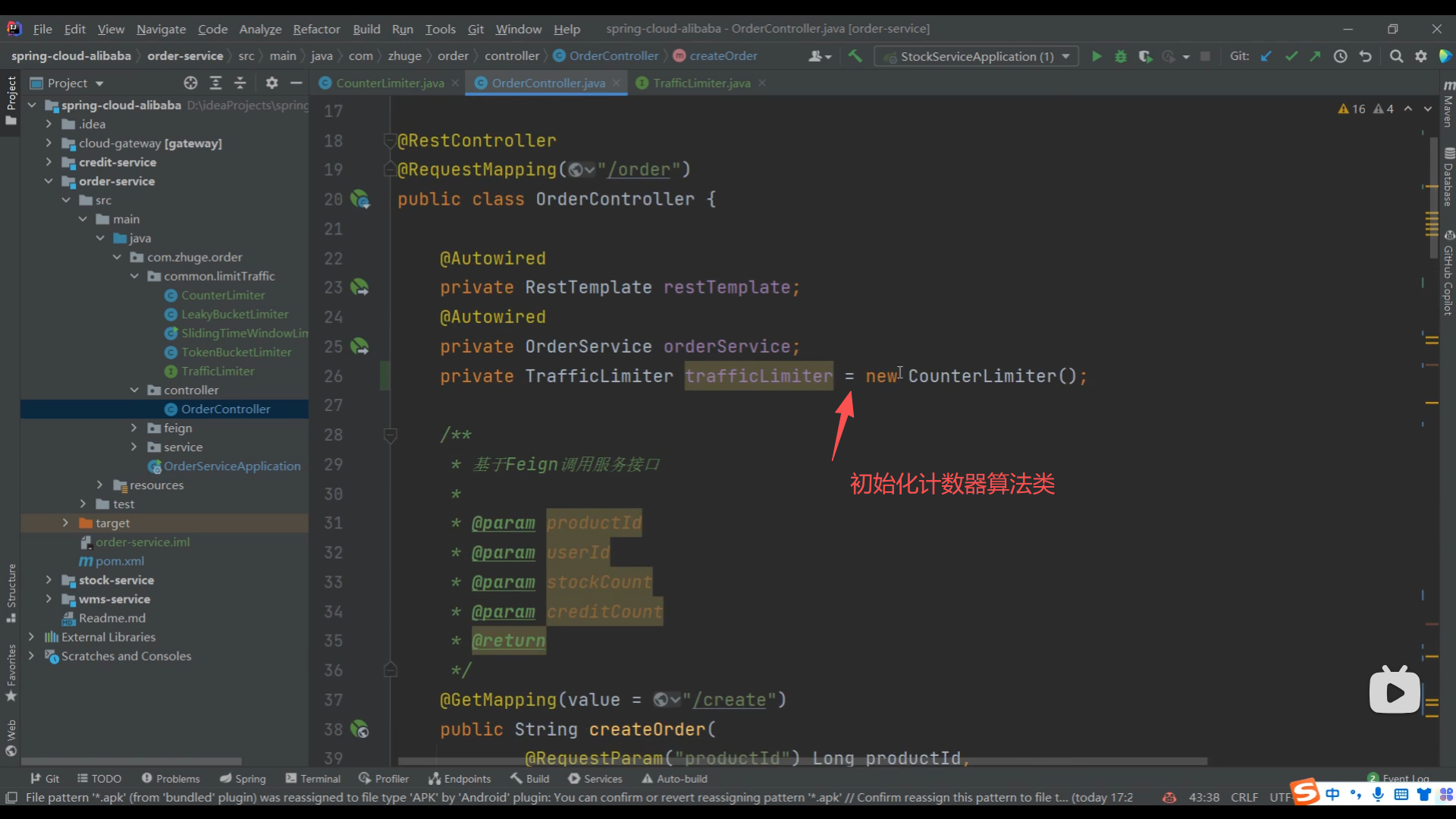
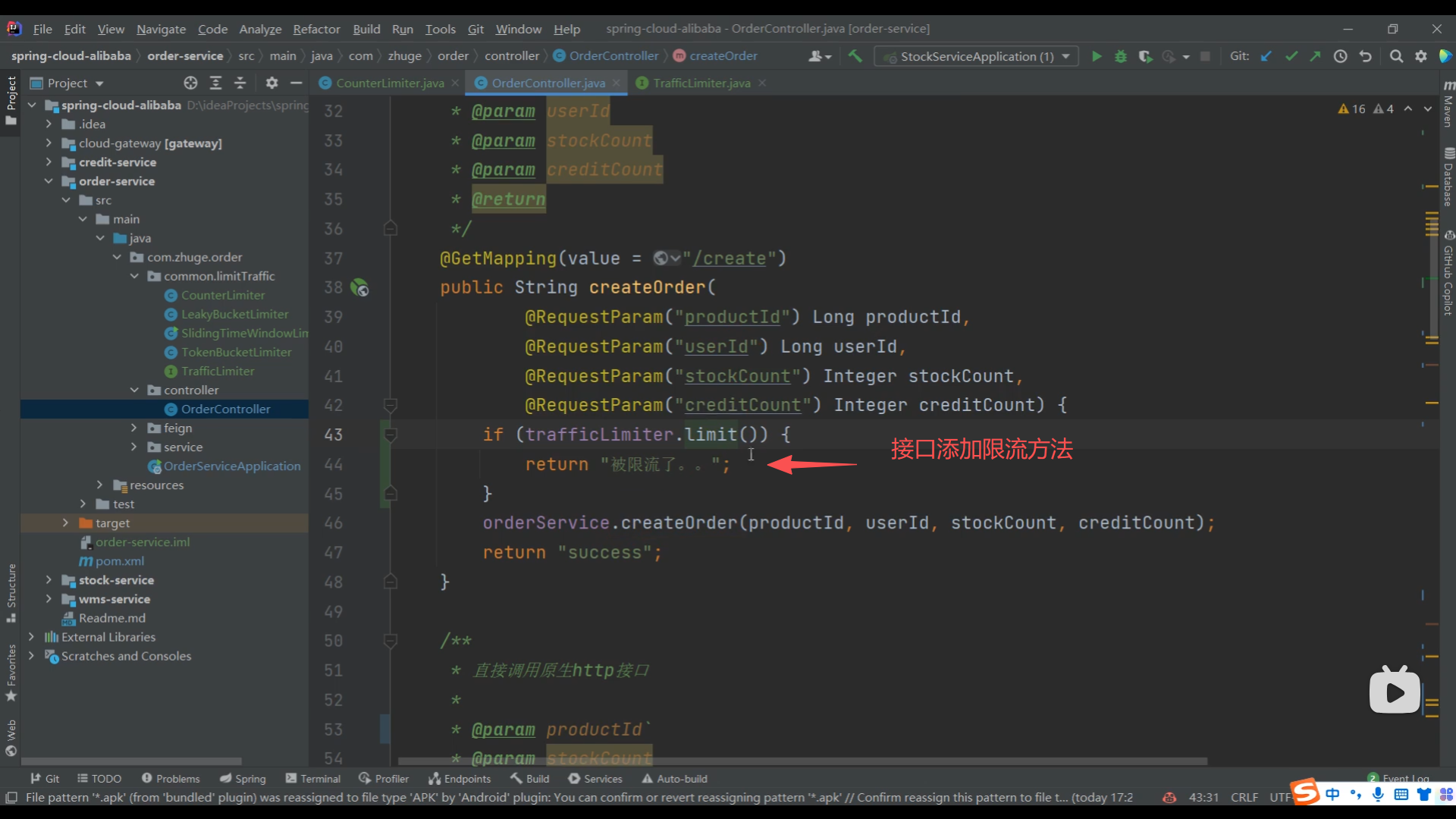
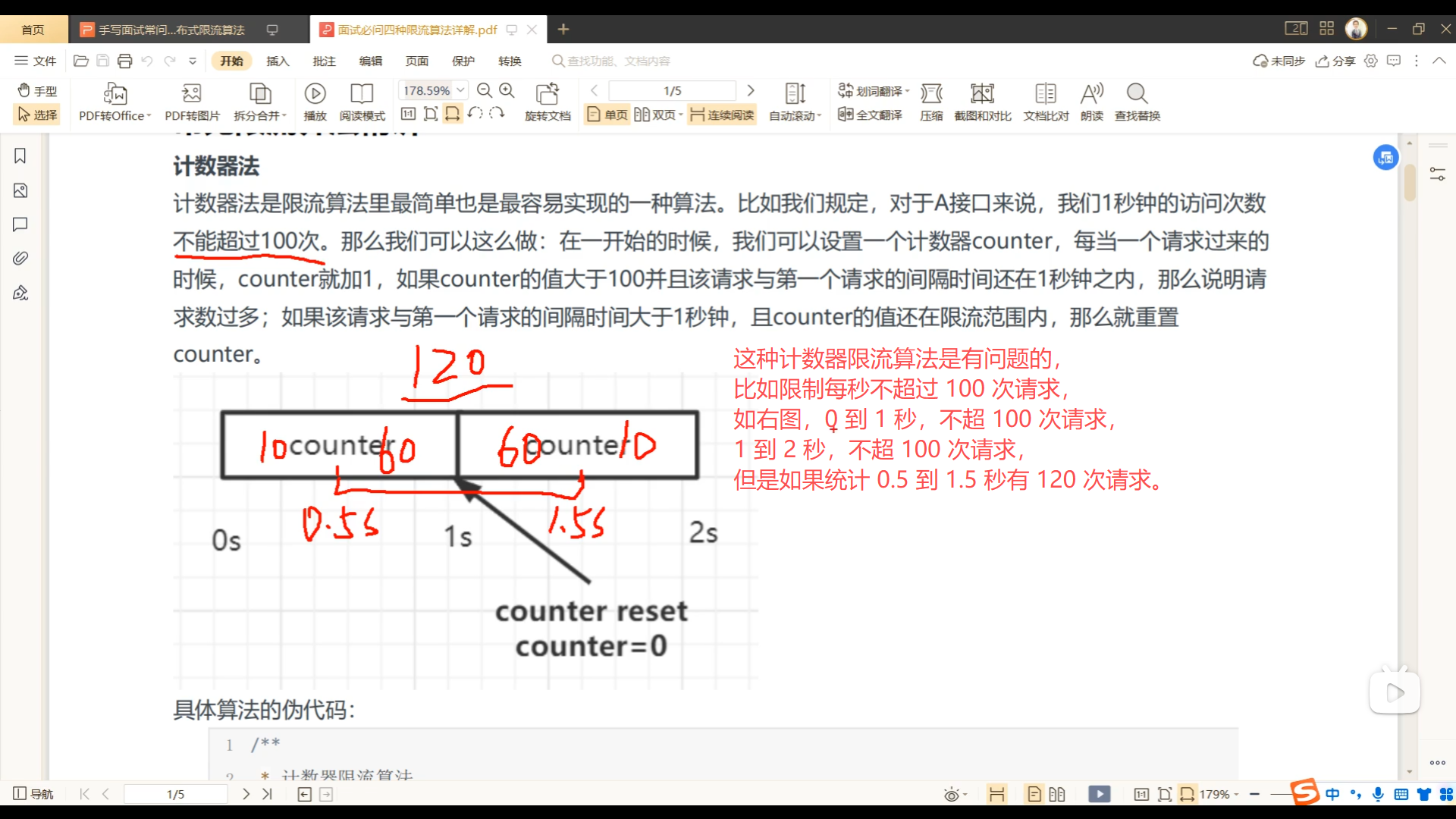
05、Redis 简单计数器限流算法实现
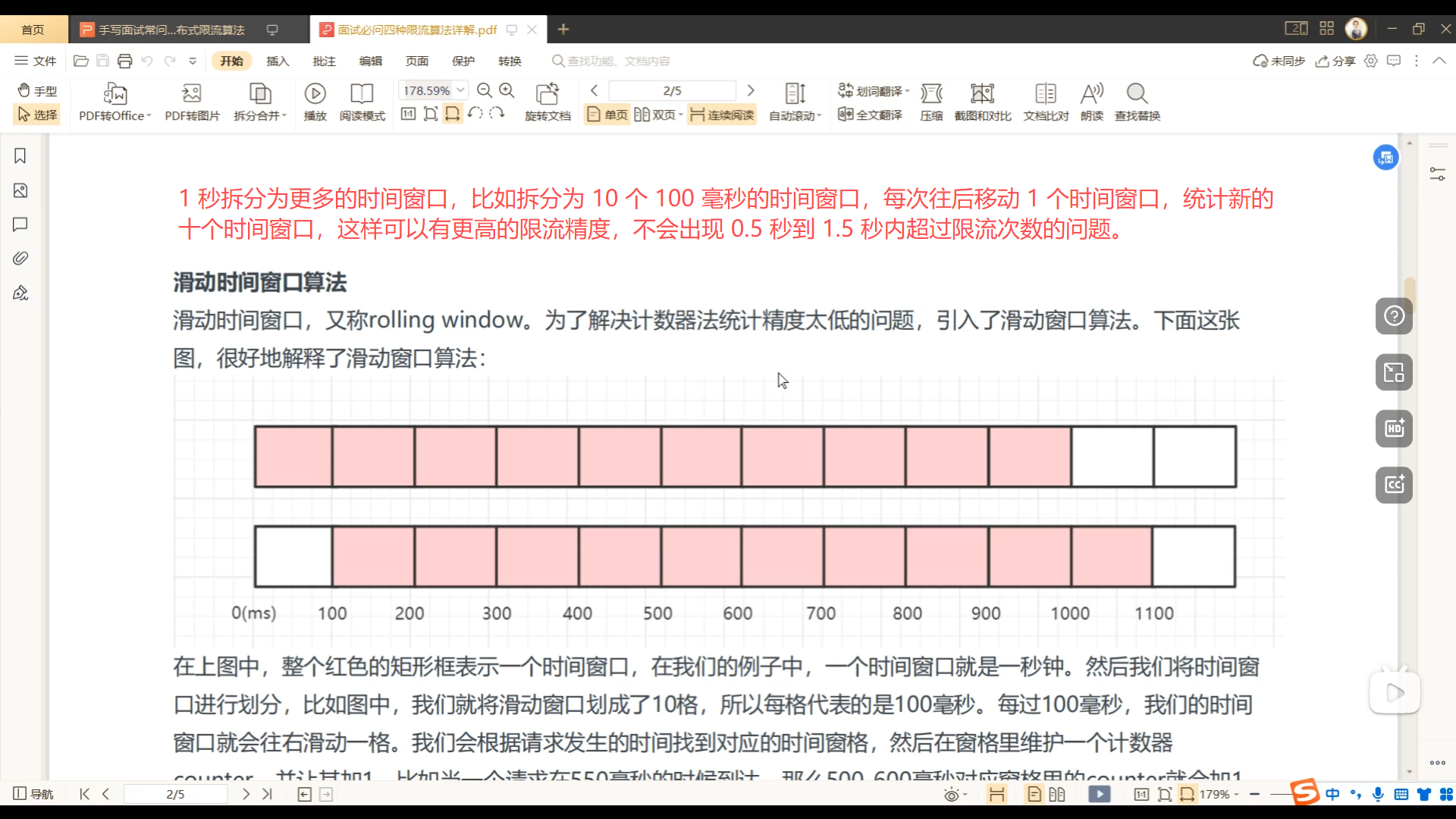
06、滑动时间窗口限流算法实现
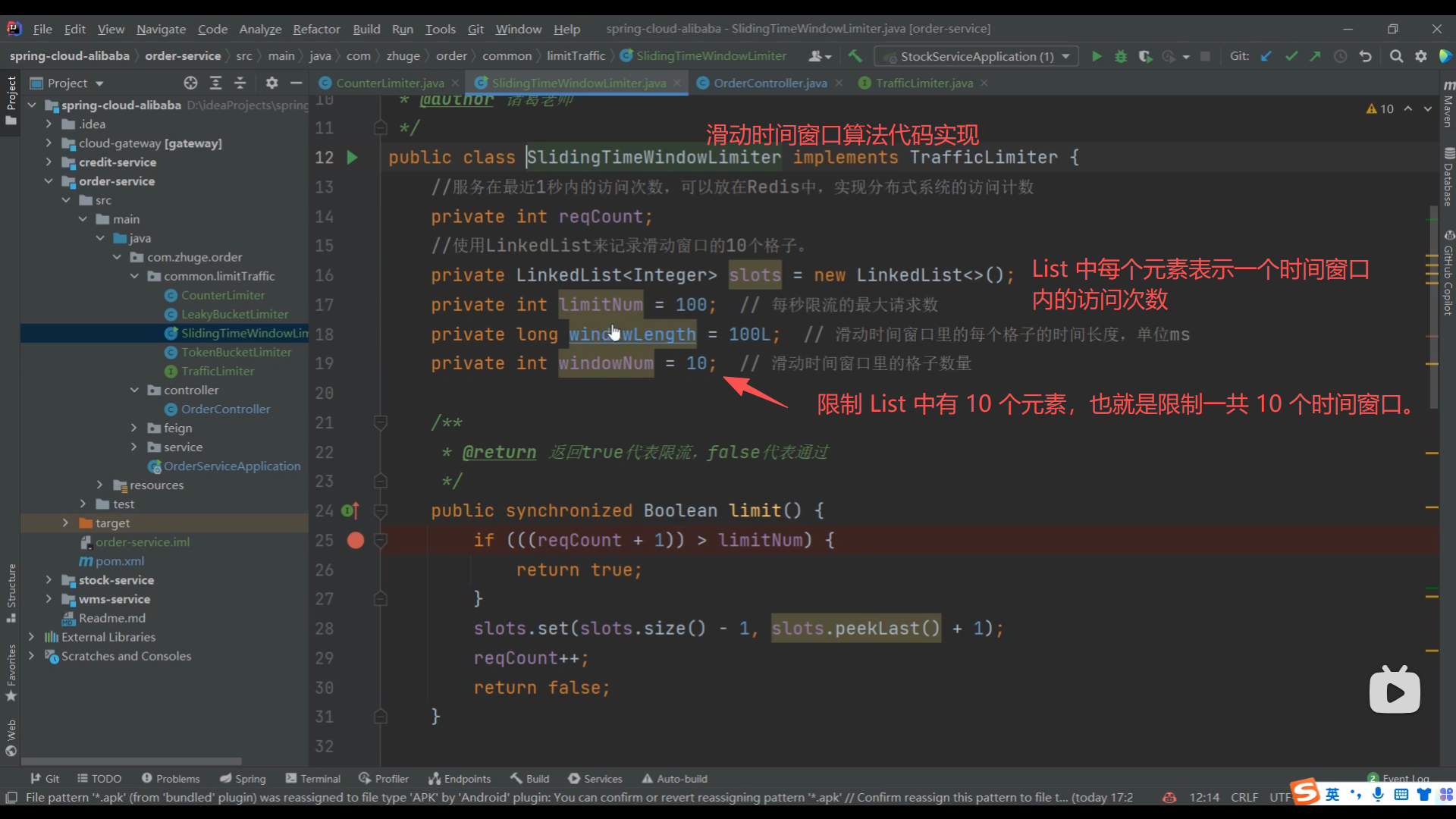
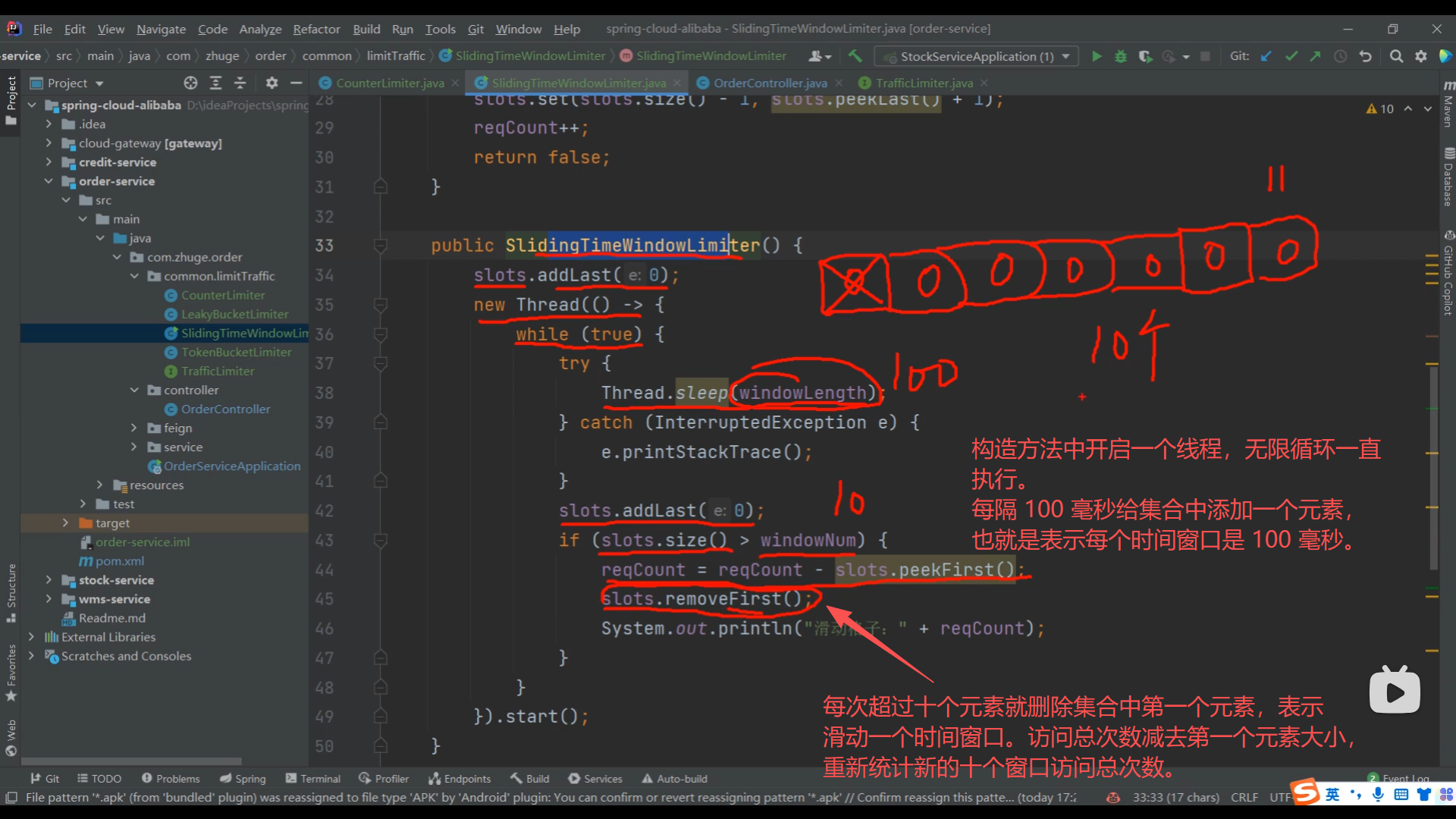
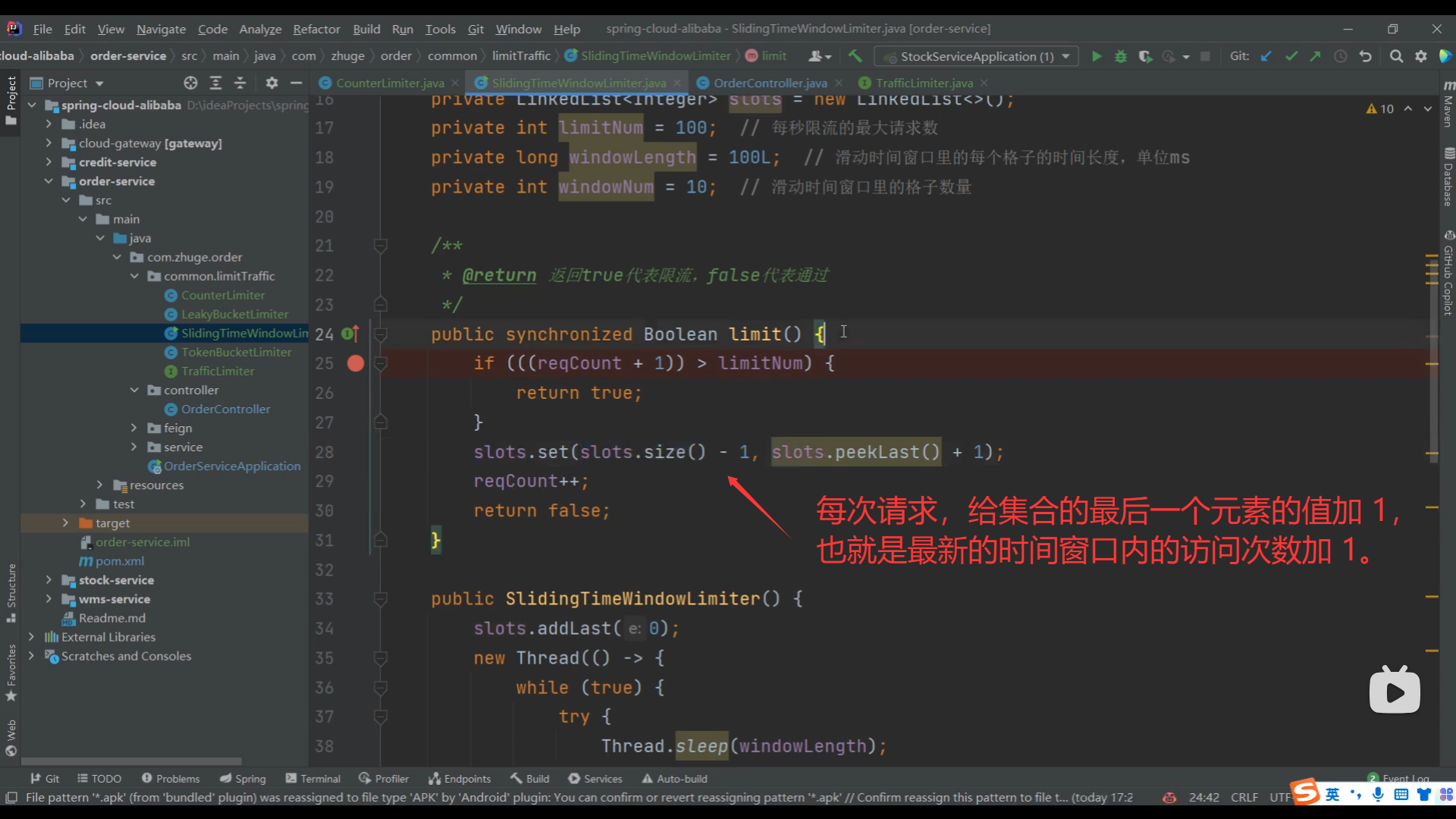
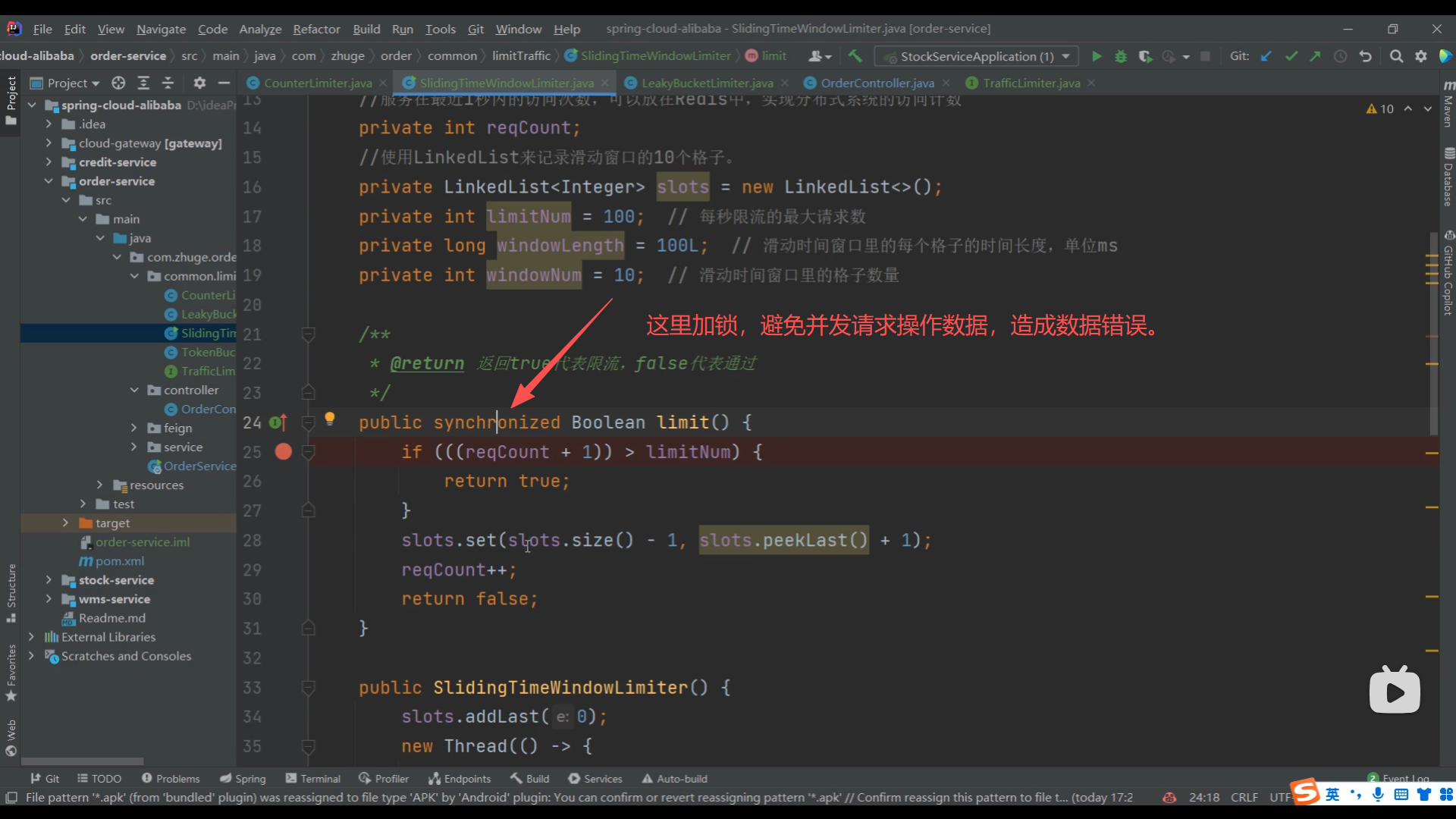
07、滑动时间窗口算法高并发冲突问题
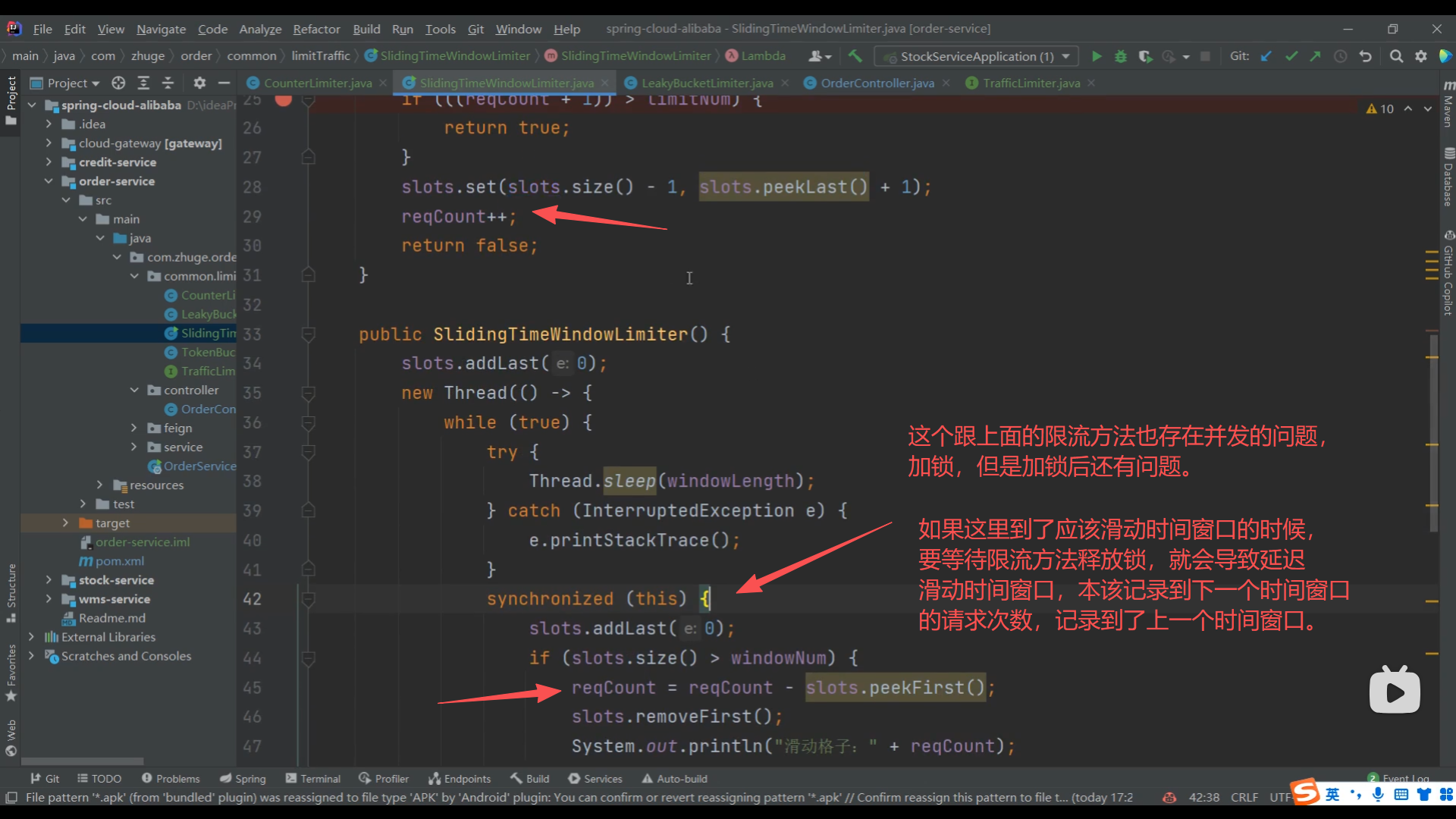
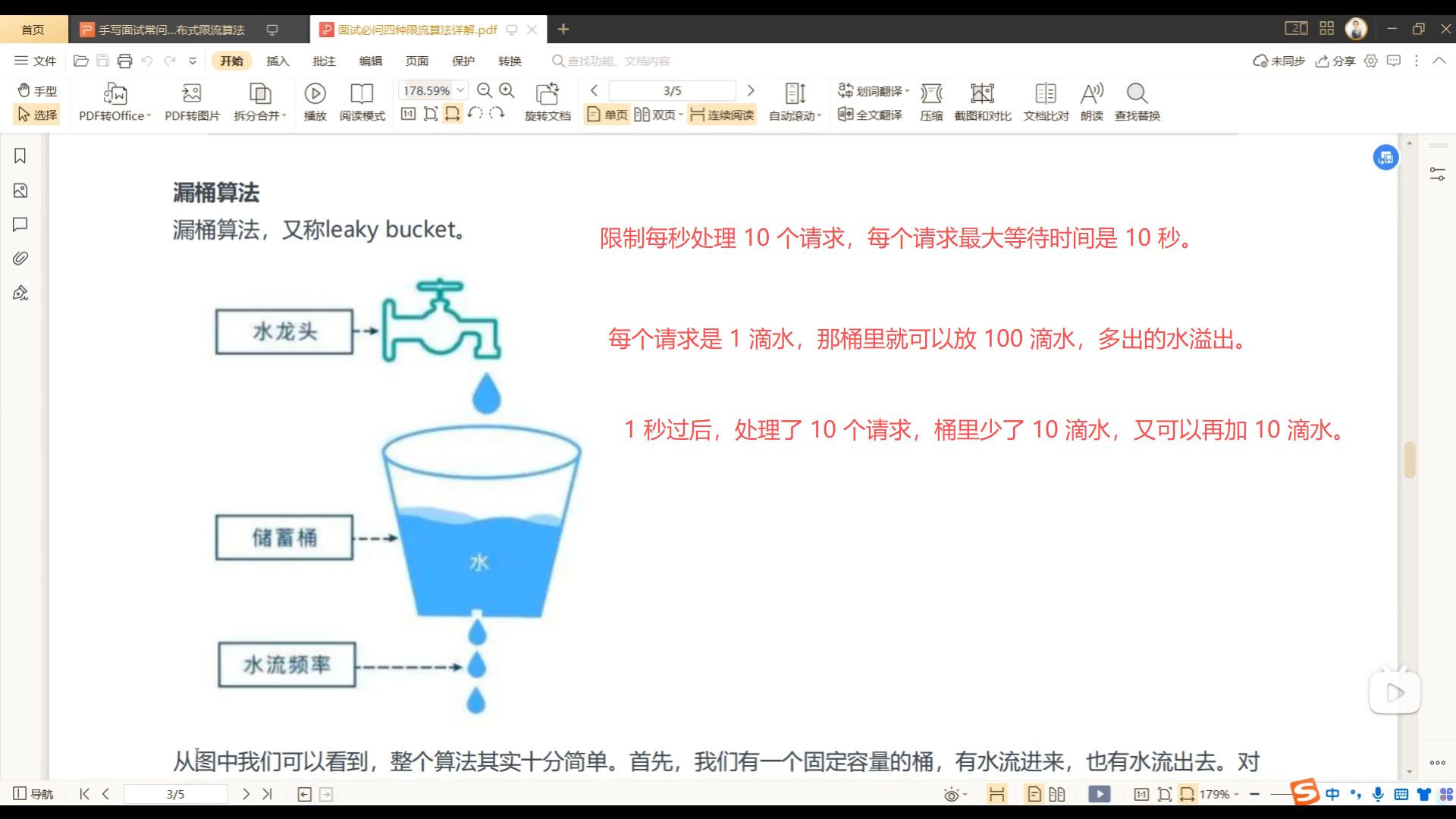
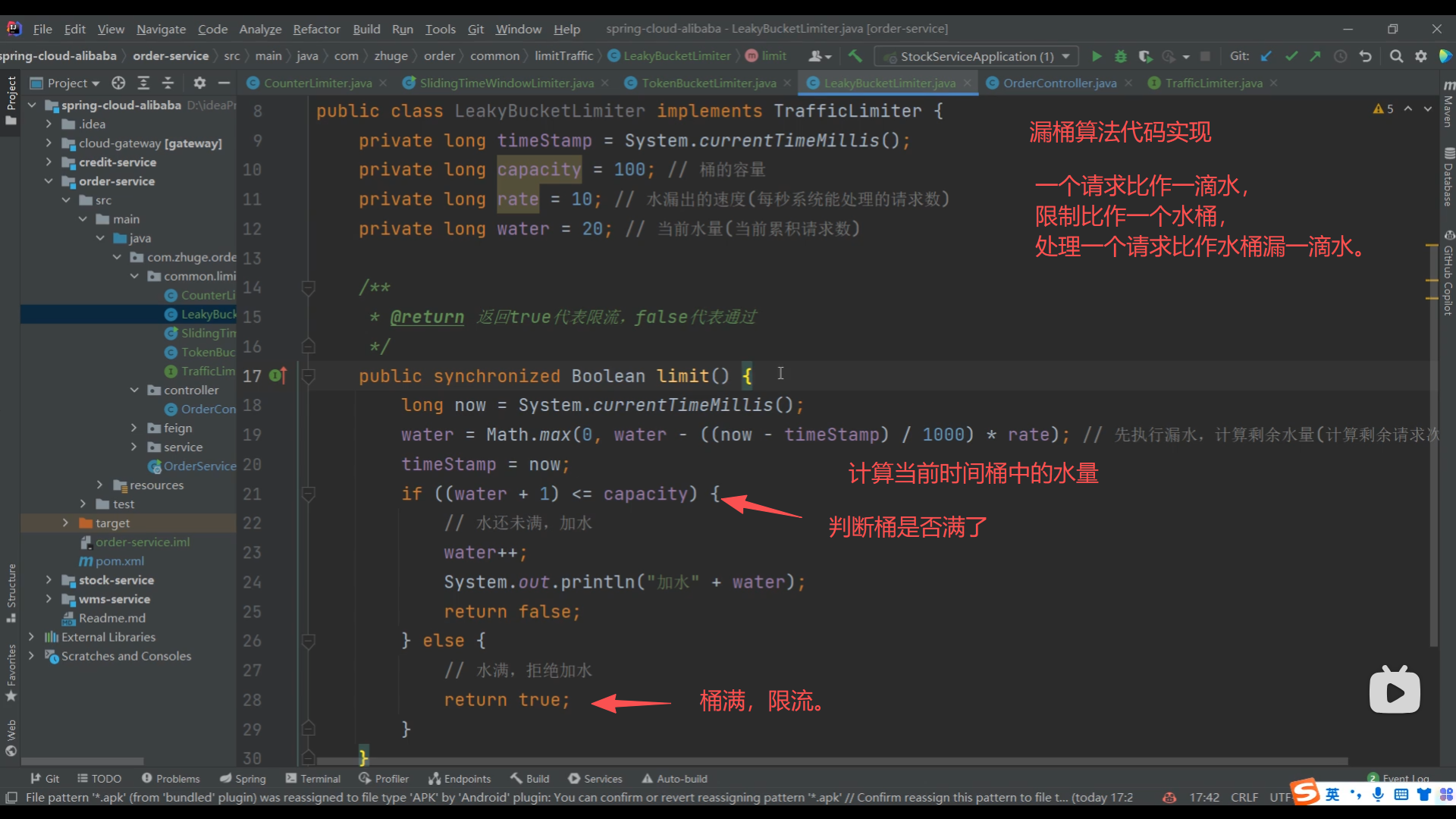
08、漏桶算法限流方法实现
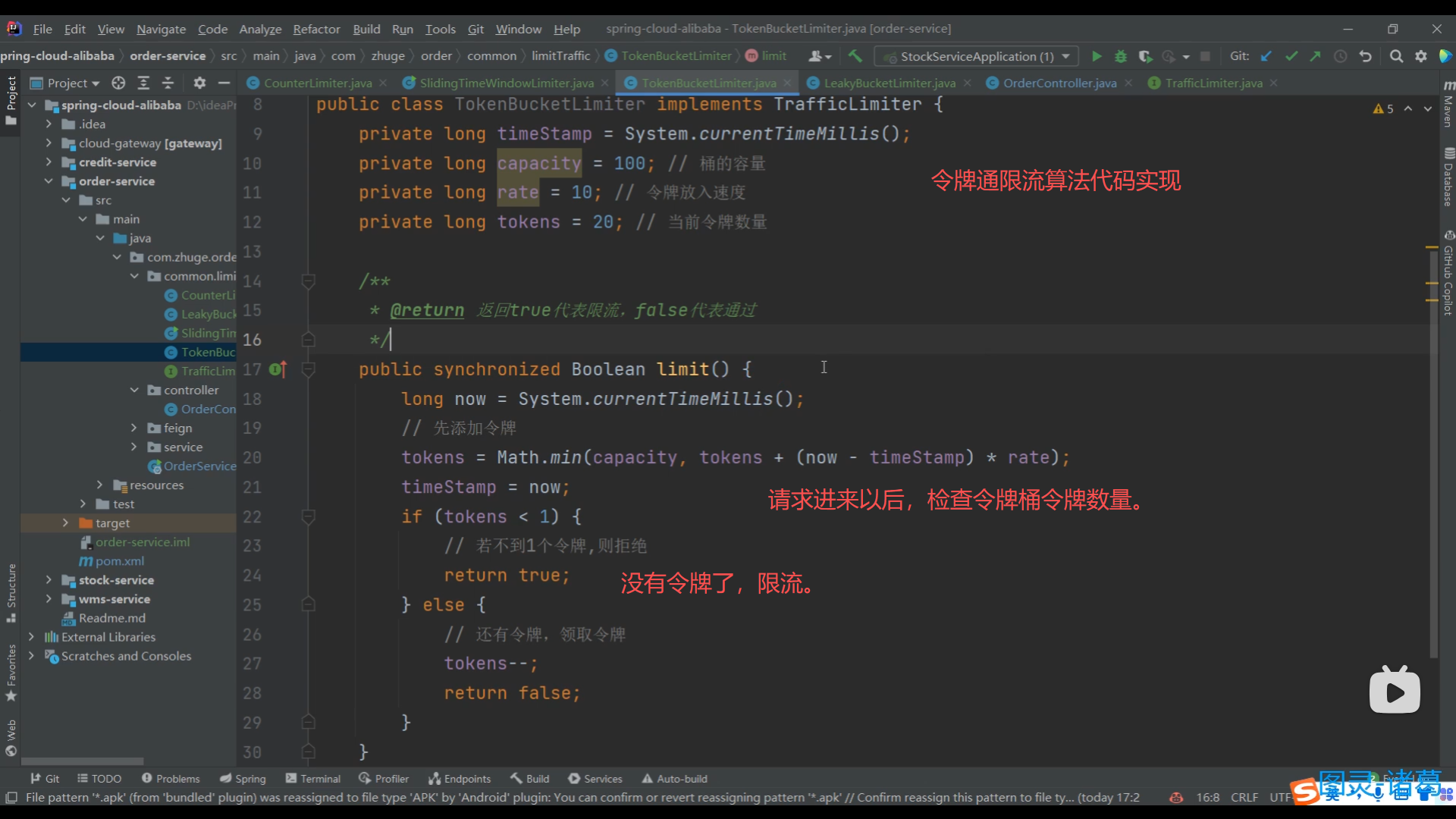
09、令牌通限流算法实现