"在人工智能大模型时代,算力已不再是单纯的硬件指标,而是融合了算法智能与数据价值的新型生产要素。城市的竞争,正演变为一场围绕'算力-算法-数据'闭环效率的系统性竞赛。"
随着生成式AI与大语言模型(LLM)技术的爆发式演进,全球数字经济的底层逻辑正在被彻底重构。国家层面,"东数西算"工程与《算力基础设施高质量发展行动计划》等一系列顶层设计,将算力定位为继水、电、网之后的"第四大基础设施"。然而,在宏大的战略叙事之下,城市在迈向智能化的过程中却面临着一个尖锐而具体的现实困境:资源碎片化、供给非标化、价值孤岛化。
本文将深度解构《算力算法数据一体化供给的城市级AI大模型算力池》这一建设方案,从行业痛点的根源出发,层层剖析其背后的技术破局逻辑、架构设计哲学与业务赋能路径。我们将共同探讨,如何通过构建一个集约化、普惠化、自主可控的"城市级AI赋能中枢",打通从底层算力到顶层应用的价值链路,为城市治理体系和治理能力现代化提供坚实的数字底座。
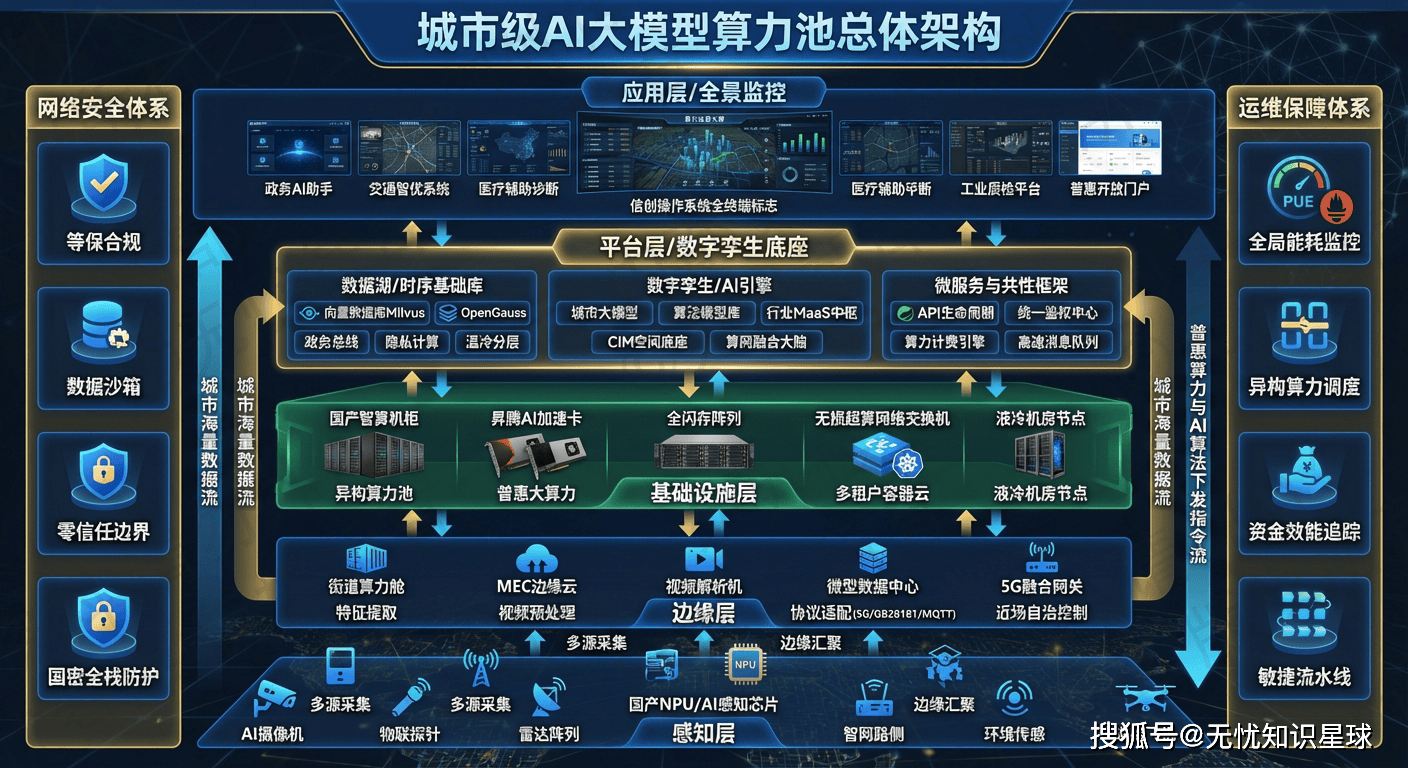
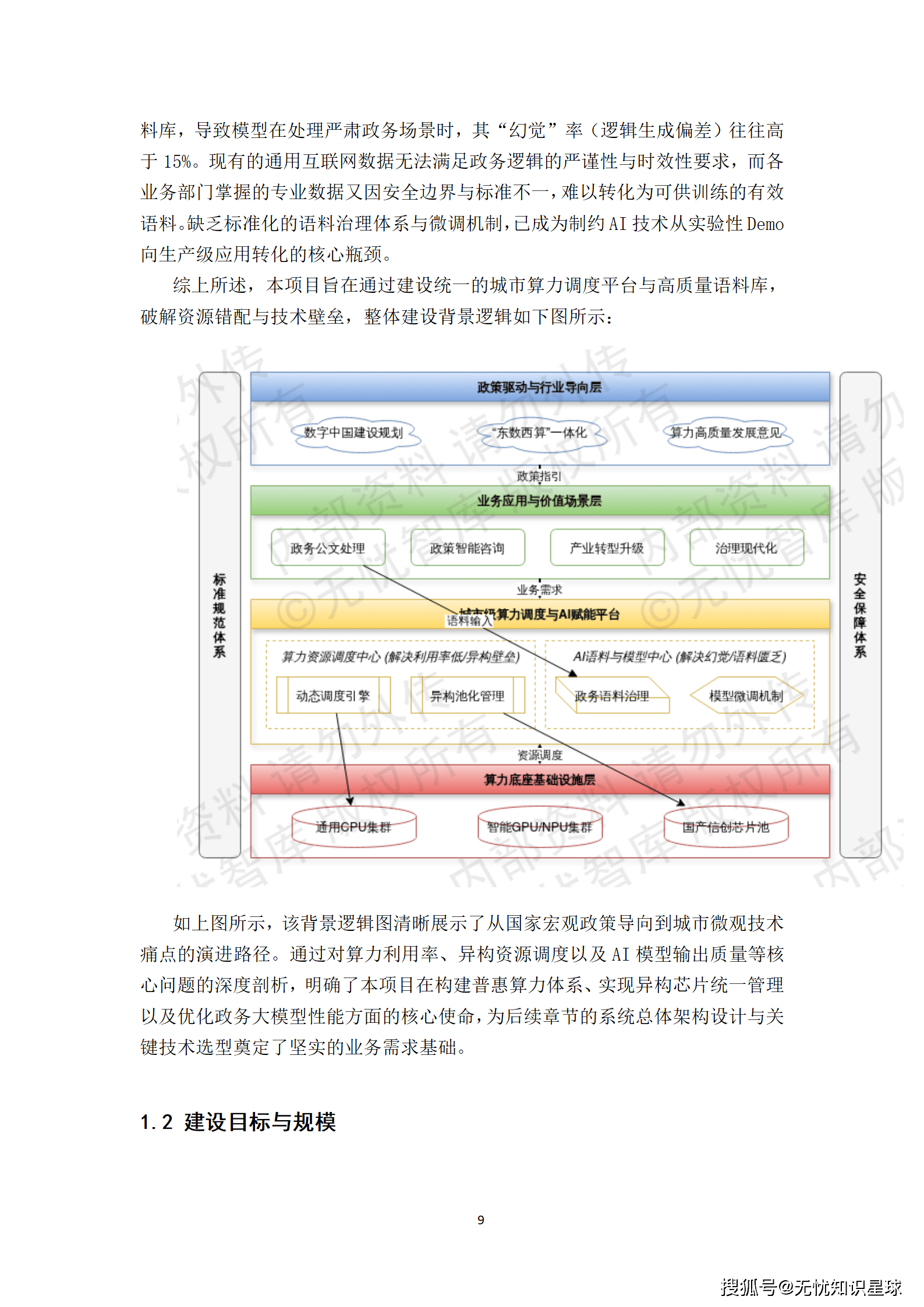
城市作为复杂巨系统的集合体,其数字化转型早已超越了简单的"上网"或"上云"阶段。当大模型成为新的通用技术范式时,城市管理者与产业开发者们却发现,手握海量数据与分散算力,却难以孵化出真正有价值的智能应用。这种"有数据无智能"、"有算力无效能"的尴尬局面,源于以下三个相互交织的核心痛点。
当前,城市的算力资源呈现出典型的"烟囱式"部署格局。政务云、各委办局私有云、企业数据中心各自为政,形成了一个个物理与逻辑上的算力孤岛。更致命的是,这些孤岛内部又因信创国产化浪潮而变得高度异构。
- 利用率低下:调研数据显示,多数存量算力资源的平均利用率不足30%。大量GPU/NPU在非峰值时段处于闲置状态,造成巨大的投资浪费。
- 生态割裂:NVIDIA GPU凭借CUDA生态占据主流,而华为昇腾、海光DCU等国产芯片则依赖各自的CANN、ROCm等软件栈。底层指令集、驱动程序与算子库的巨大差异,使得不同品牌的算力资源无法在逻辑层形成统一调度池。
- 调度失灵:传统的云计算调度器无法理解大模型训练对NVLink/RoCE等高速互联网络拓扑的强依赖性,导致跨节点通信延迟高企,严重拖累万亿参数规模模型的并行训练效率。
这种"局部过剩与全局短缺"并存的局面,不仅推高了全社会的AI创新成本,更从根本上制约了城市应对突发公共事件(如大规模视频流实时分析)所需的弹性算力保障能力。
如果说算力是引擎,那么算法就是驱动引擎的燃料。然而,当前的燃料供给体系存在严重的结构性失衡。
- "幻觉"率居高不下:通用大模型在处理政务公文、城市治理等严肃业务场景时,由于缺乏高质量的行业语料进行微调,其输出内容的"幻觉"率(即逻辑生成偏差)往往高于15%。这对于需要严谨性与时效性的政务服务而言是不可接受的。
- 语料治理缺失:各业务部门掌握着大量专业数据,但这些数据因安全边界、标准不一、质量参差等问题,难以转化为可供模型训练的有效语料。缺乏一个标准化的数据加工流水线,导致"数据富矿"无法开采。
- 开发门槛高企:中小企业与政务部门普遍缺乏开箱即用的行业大模型。他们不仅要面对高昂的算力成本,还需投入巨大精力进行环境搭建、框架适配和模型微调,这极大地抑制了AI技术的普惠化落地。
简言之,算法供给侧未能有效响应业务需求侧,造成了技术与场景之间的巨大鸿沟。
数据作为新时代的石油,其价值释放过程同样步履维艰。
- 链路未打通:从原始数据的采集、清洗、向量化到最终的模型微调,这条关键链路尚未实现自动化与工程化。数据科学家需要花费大量时间在繁琐的数据预处理工作上,而非核心的模型创新。
- 安全与隐私悖论:《数据安全法》与《个人信息保护法》等法规要求核心数据"不出域",但这与AI模型训练所需的海量数据汇聚形成了天然矛盾。如何在确保数据主权与隐私安全的前提下,实现数据价值的合规流转与协同计算,成为一个亟待解决的难题。
- 血缘不清:数据在跨部门共享过程中,缺乏完善的血缘追踪机制,导致数据流转路径不可审计、不可追溯,增加了数据滥用与责任界定的风险。
这三个维度的痛点相互强化,共同构成了城市迈向智慧化新阶段的系统性障碍。要破解这一困局,必须跳出单点优化的思维定式,从供给侧进行一场深刻的结构性改革。
面对上述困局,本方案提出的"算力算法数据一体化供给的城市级AI大模型算力池"并非简单的硬件堆砌或平台叠加,而是一场旨在重构城市AI生产力底层逻辑的供给侧结构化改革。其核心思想在于,将原本割裂的算力、算法、数据三大要素,通过一套深度耦合的工程化体系,整合为一个有机整体,形成"1+1+1>3"的协同效应。
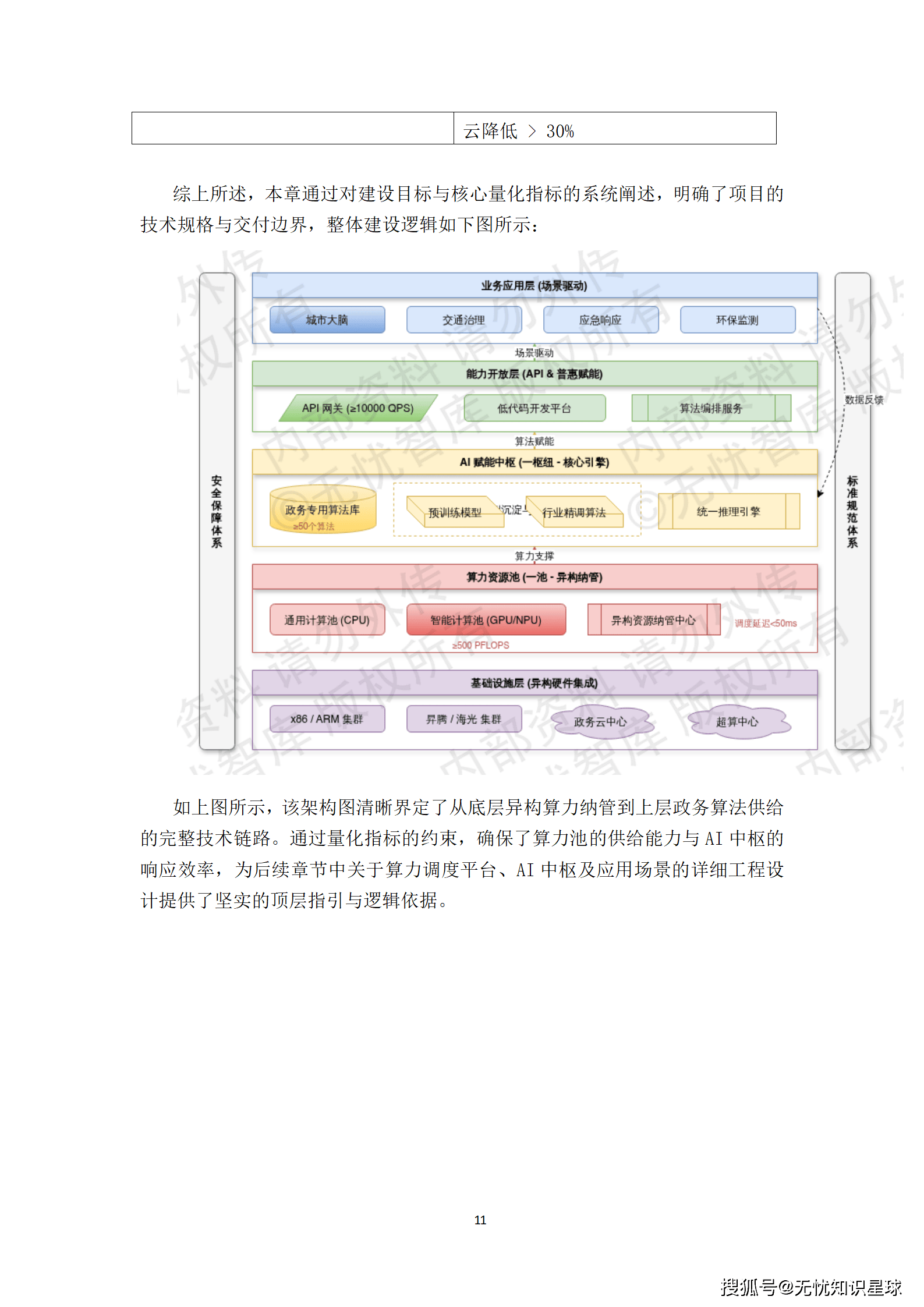
方案的顶层设计简洁而有力------"一池一枢纽"。
- "一池" :即全市异构算力池。通过部署先进的算力资源池化管理系统,实现对全市范围内所有存量及增量异构算力资源(涵盖x86、ARM、昇腾、海光等硬件架构)的100%纳管。其目标是屏蔽底层硬件差异,实现算力资源的标准化度量、动态切分与按需分配。
- "一枢纽" :即AI赋能中枢。作为城市大脑的算法引擎,该中枢集成不少于50个政务专用算法,并构建起从模型训练、精调到部署的标准化流程。它通过标准化API接口与低代码工具,将强大的AI能力以服务化的形式精准输送到千行百业。
"一池"是底座,"一枢纽"是引擎,二者共同构成了城市级AI大模型算力池的骨架。
该方案的战略定位清晰地锚定了三大核心价值:
- 普惠化:通过规模化集约建设和精细化能耗管控,实现普惠算力单价较主流商业云服务降低30%以上,有效降低全社会AI创新门槛。
- 自主可控:全栈信创适配,构建基于国产芯片与操作系统的算力底座,确保核心政务数据不出域,满足《数据安全法》与信创国产化要求。
- 高效率:支撑智慧政务、自动驾驶、工业仿真等高算力消耗场景,使城市大脑典型场景(如政务咨询、事件处置)的智能化准确率提升至95%以上,模型推理API并发响应能力突破10000 QPS。
这一定位直指当前市场痛点,既回应了国家战略关切,也满足了地方发展的实际需求。
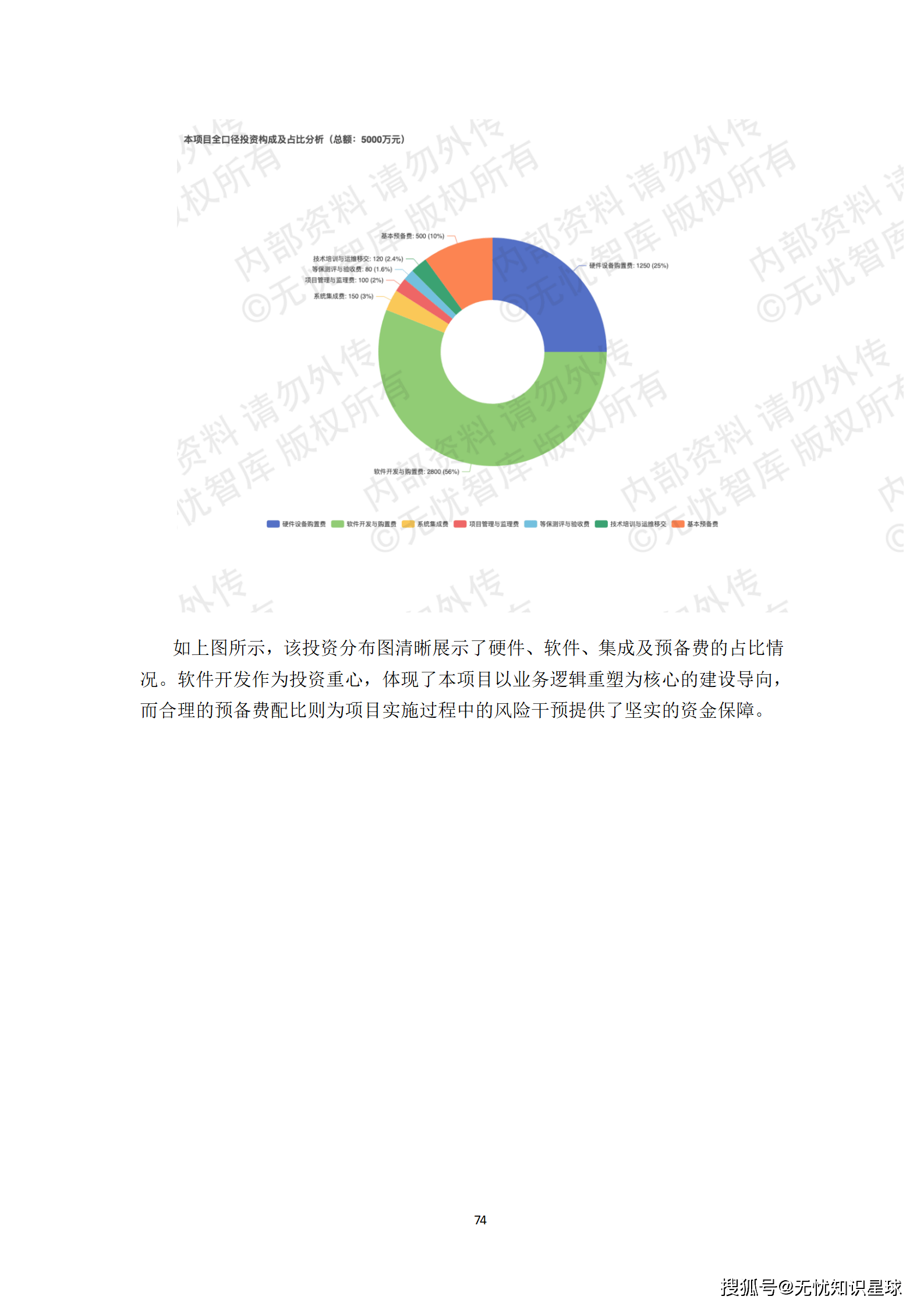
任何伟大的构想都需要精确的刻度来丈量。方案设定了极具挑战性但又切实可行的核心量化指标:

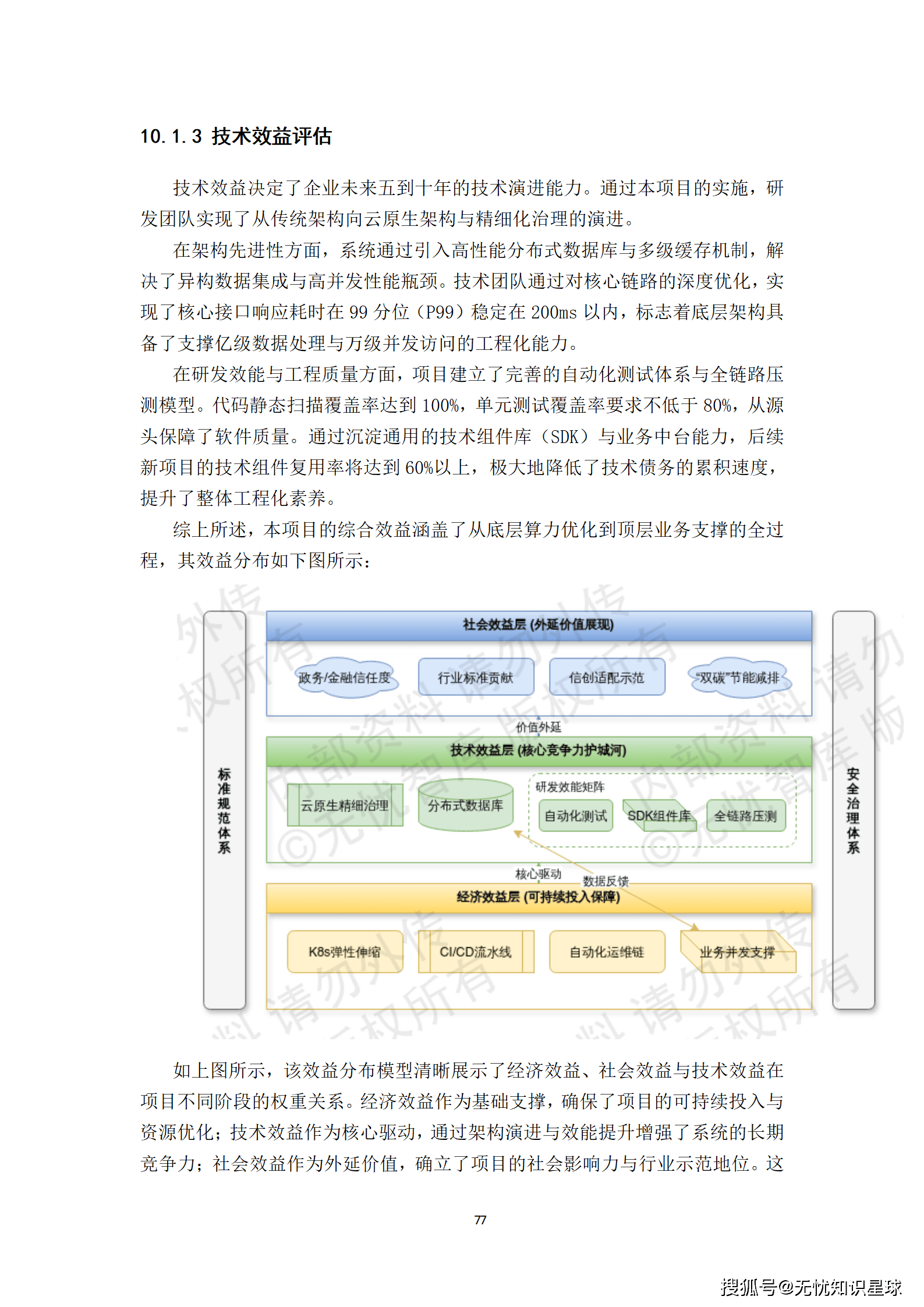
这些指标不仅是项目验收的基准,更是未来运营体系的核心KPI,确保了项目从建设期到运营期的无缝衔接。
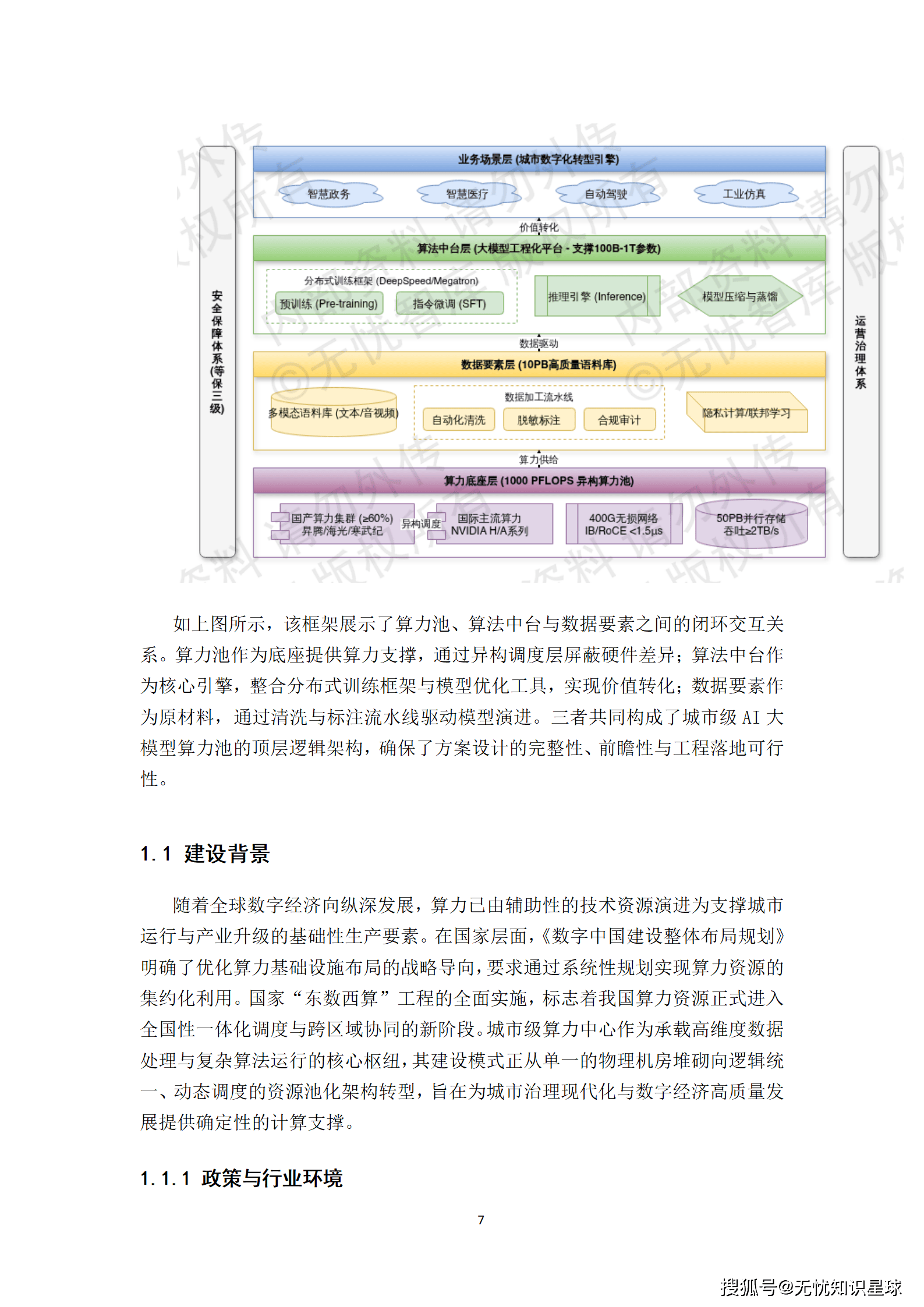
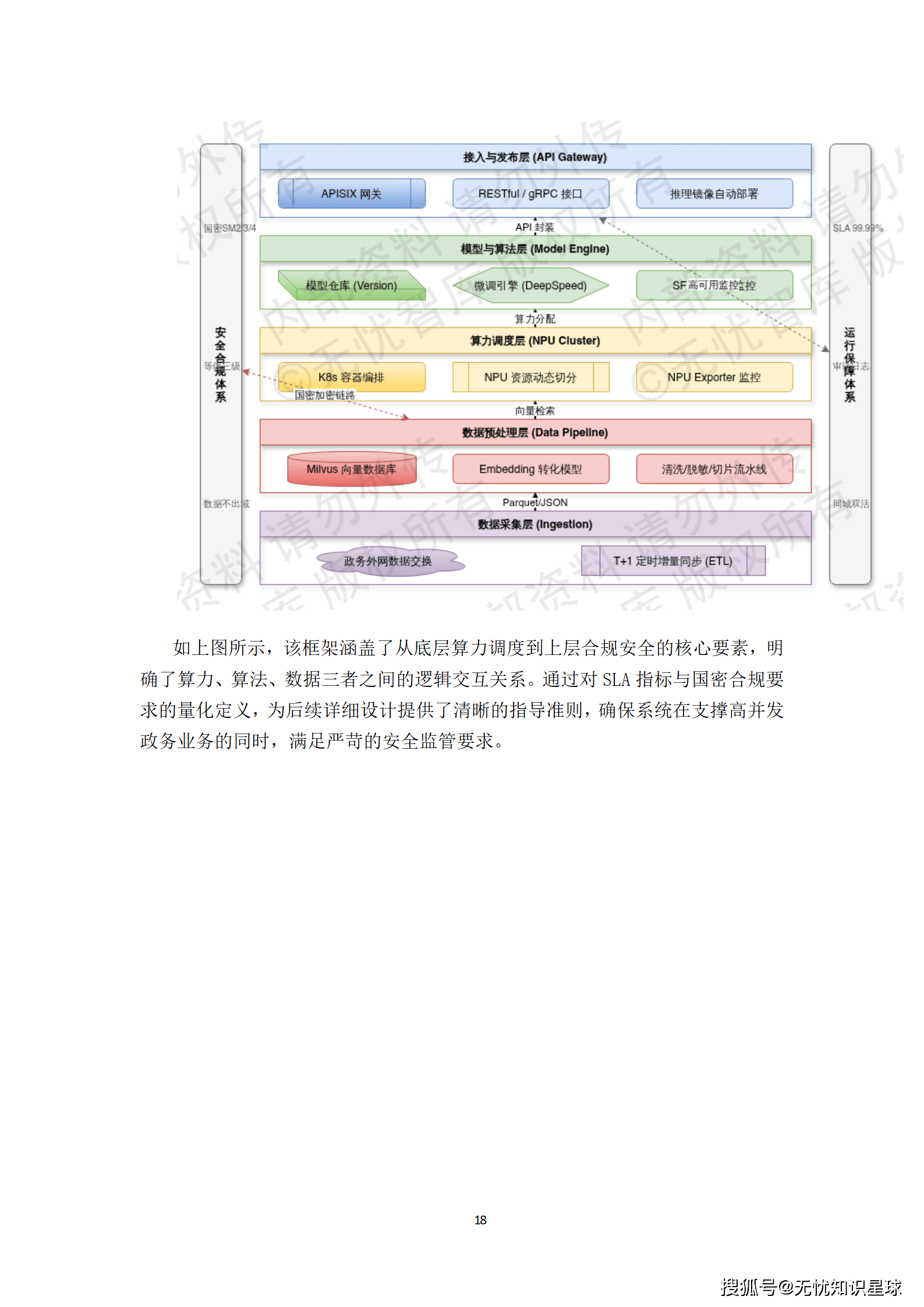
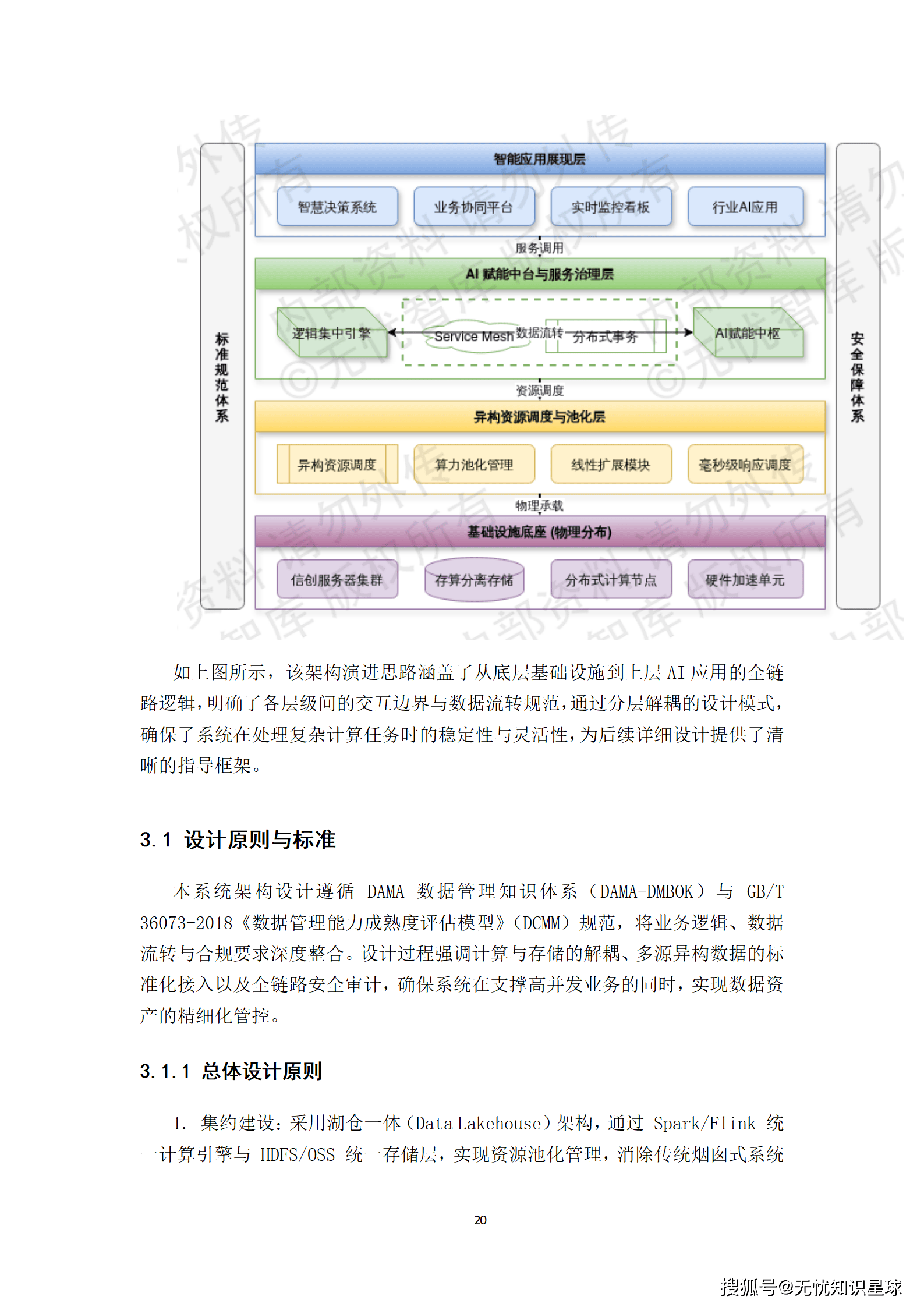
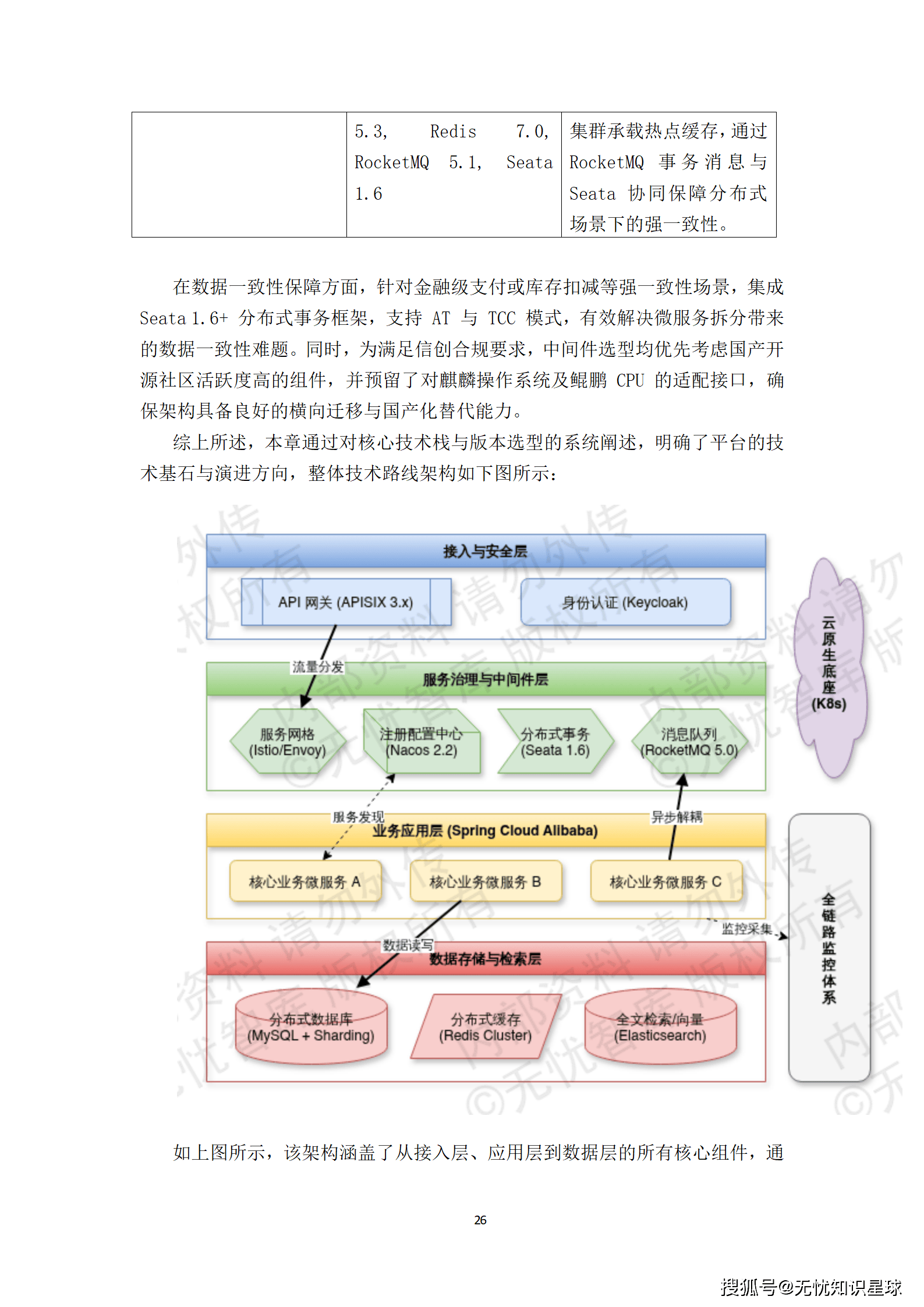
要实现"三位一体"的宏大目标,离不开一套兼具前瞻性与工程落地可行性的总体架构。该方案的架构设计遵循"存算分离、逻辑集中、物理分布"的演进原则,通过多维度的解耦机制,实现了资源的高效流转与统一管控。
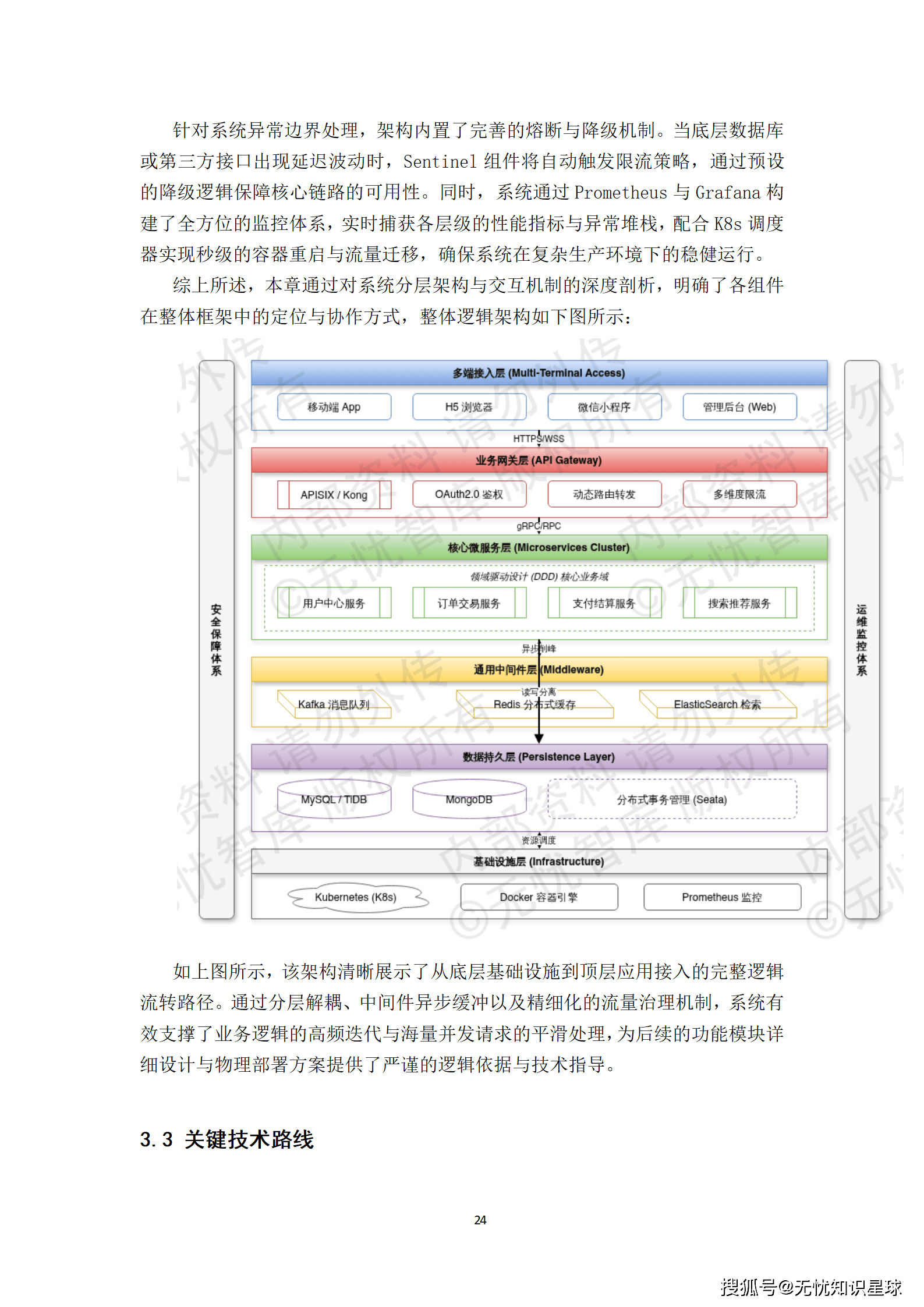
系统逻辑架构自底向上划分为六个清晰的层次:
- 基础设施层:依托Kubernetes集群实现计算与存储资源的池化管理,是整个系统的物理基石。
- 数据持久层:针对不同业务场景的读写特征,实施读写分离与分库分表策略,利用MySQL集群保障关系型数据的强一致性,并结合MongoDB处理非结构化高吞吐数据。
- 通用中间件层:整合Redis集群承担万级QPS的会话缓存与热点数据存储,同时部署Kafka阵列实现异步任务解耦与流量削峰。
- 核心微服务层:作为架构的中枢,基于领域驱动设计(DDD)原则将业务逻辑拆分为独立的限界上下文,各服务通过gRPC协议实现高性能同步调用。
- 业务网关层:由APISIX网关负责OAuth2.0安全校验、流量清洗与动态路由,是系统对外服务的统一入口。
- 多端接入层:面向最终用户提供Web、移动端等多种交互方式。
这种分层设计有效降低了模块间的耦合度,使得系统能够灵活应对业务的快速迭代与海量并发请求。
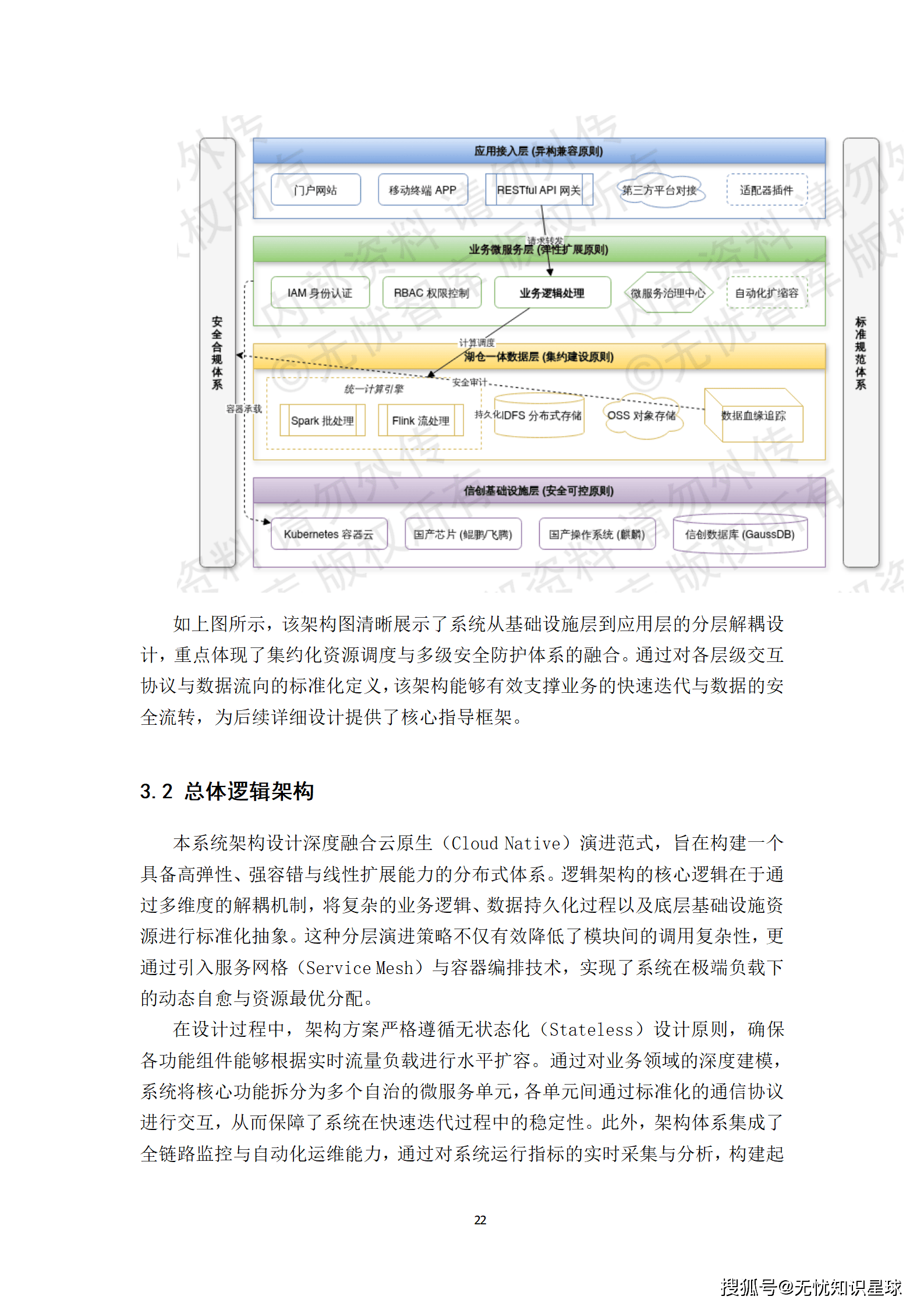
在技术选型上,方案严格遵循"成熟稳定、高并发支撑、微服务化、信创兼容"的核心原则。
- 云原生底座:全面拥抱Kubernetes、Istio Service Mesh、Spring Cloud Alibaba等云原生技术栈,构建具备高弹性、强容错与线性扩展能力的分布式体系。
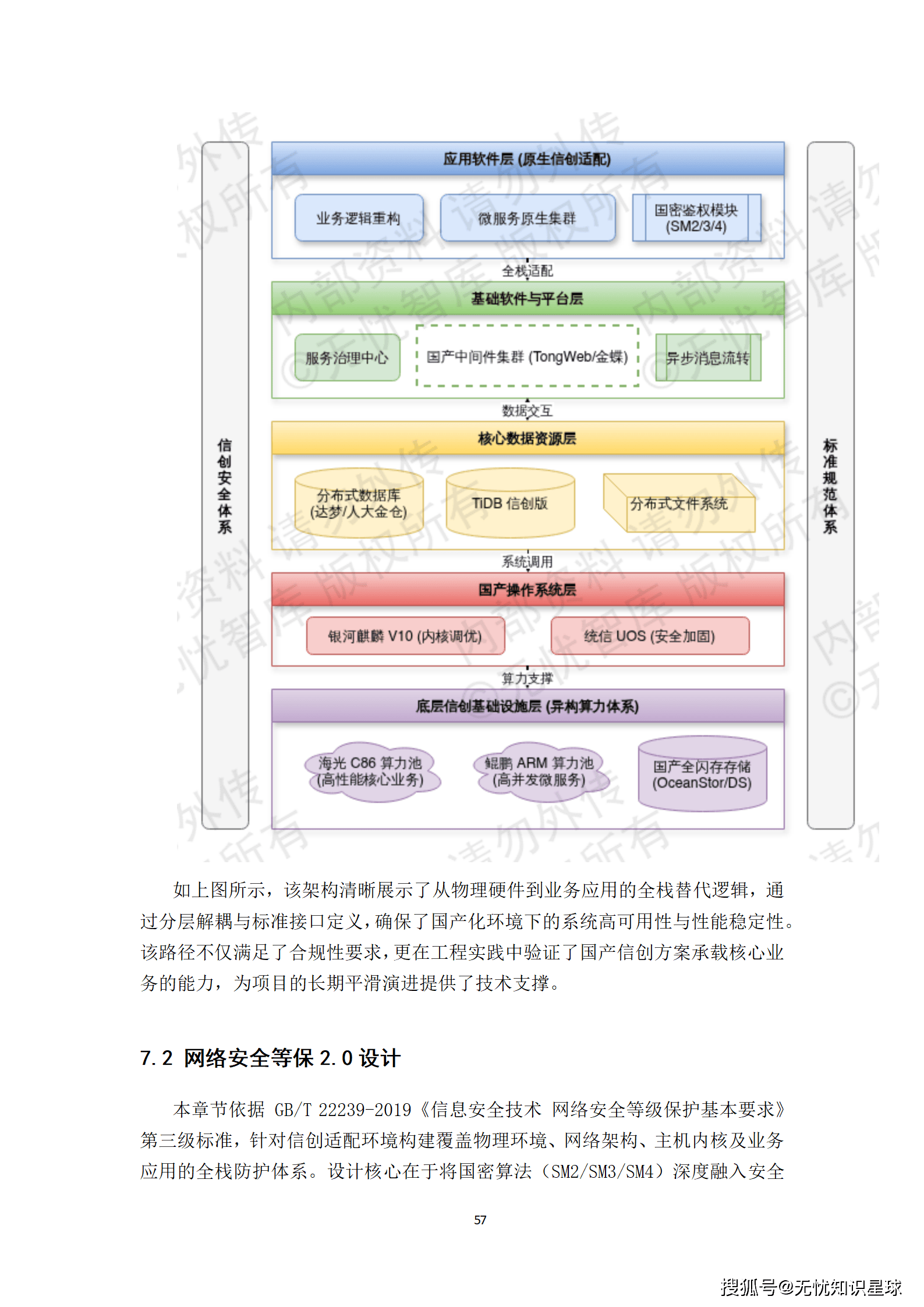
- 信创兼容:中间件选型均优先考虑国产开源社区活跃度高的组件,并预留了对麒麟操作系统及鲲鹏CPU的适配接口。例如,在数据库层面选用达梦DM8或人大金仓Kingbase,在中间件层面选用东方通TongWeb或金蝶AAS。
- 高可用保障:通过Seata分布式事务框架解决微服务拆分带来的数据一致性难题,并利用Sentinel组件实现完善的熔断与降级机制,确保系统在复杂生产环境下的稳健运行。
这套技术路线既保证了系统的先进性与高性能,又兼顾了国家战略安全与自主可控的要求。
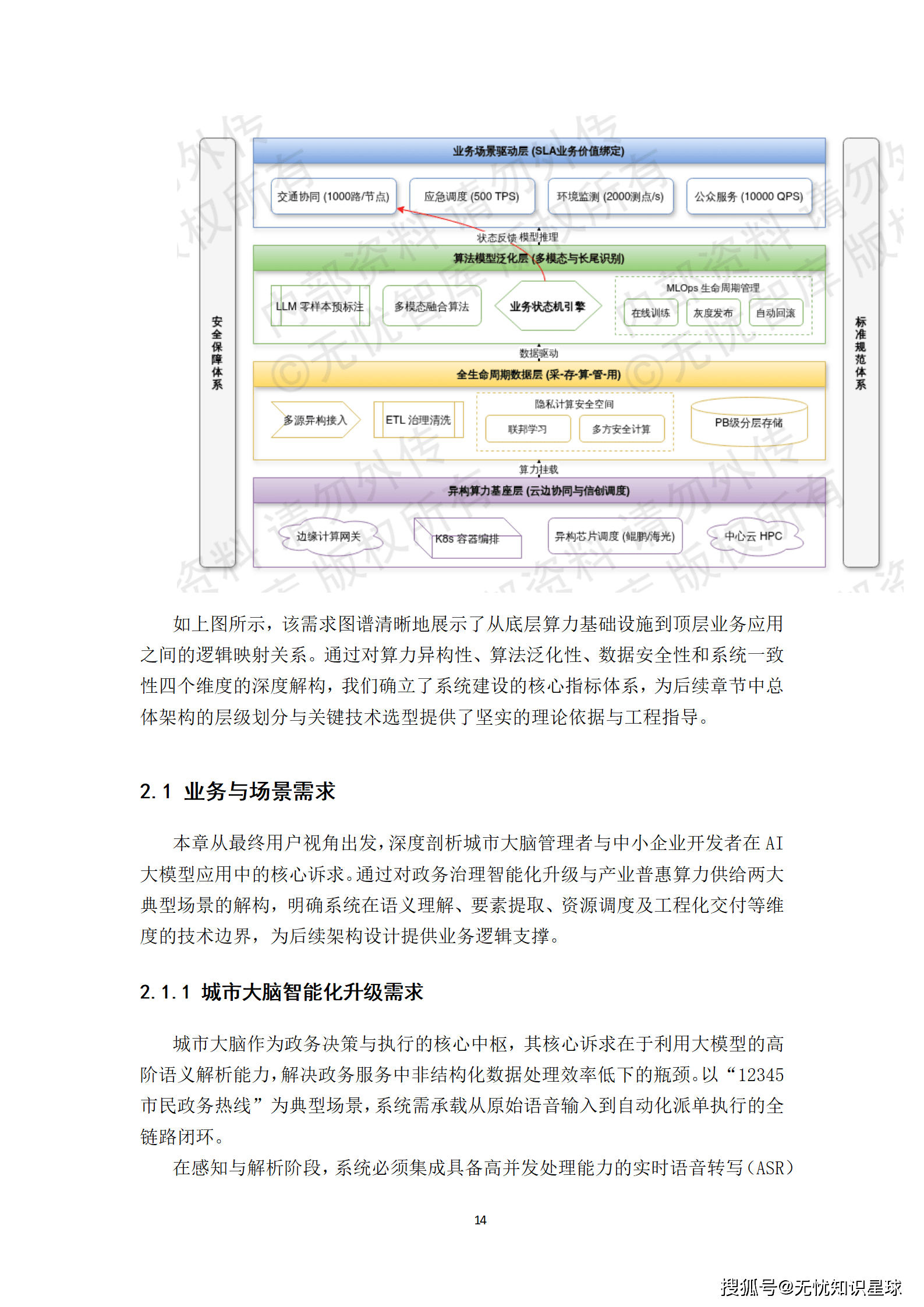
算力池化与调度系统是整个方案的基石,其设计的优劣直接决定了资源利用效率与业务支撑能力。本章将深入其内部,揭示其如何攻克异构资源整合、智能调度与精准计量等关键技术难题。
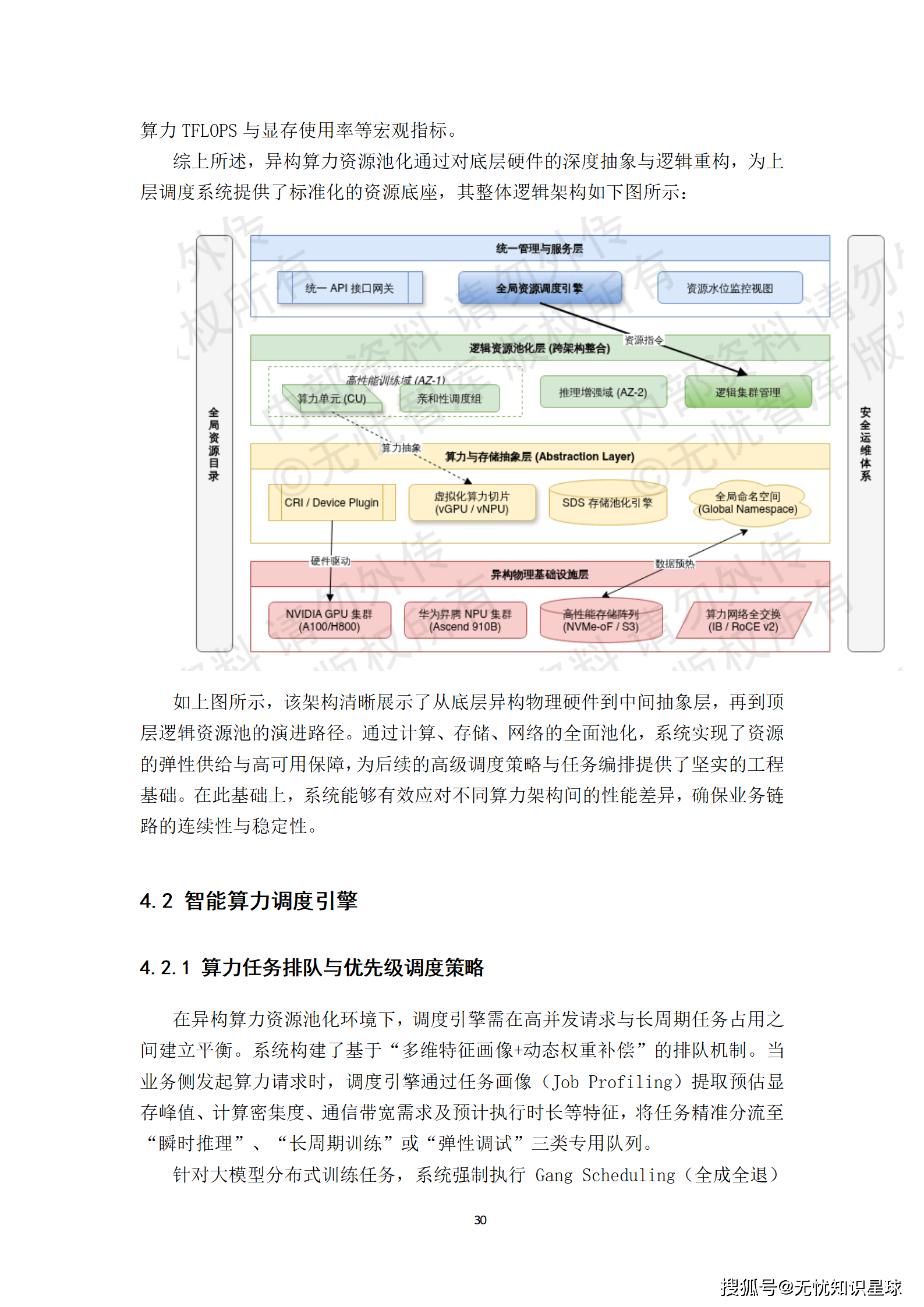
异构算力池化的本质,是对底层物理硬件进行深度抽象,构建一个逻辑统一的资源供给层。
- 算力抽象层(Compute Abstraction Layer):这是池化的核心。系统通过统一的容器运行时接口(CRI)与设备插件(Device Plugin)机制,将不同厂商的加速芯片(如NVIDIA GPU、华为昇腾NPU)的能力进行标准化封装。对于NVIDIA GPU,利用CUDA转发与多进程服务(MPS)技术实现算力的细粒度切分,支持从1%核心到整卡的弹性分配。对于国产NPU,则通过适配专属驱动栈与算子库,将其物理算力单元抽象为标准化的虚拟算力切片(vCompute),确保计算核心、显存容量及互联带宽的精准隔离。
- 存储与网络池化:采用软件定义存储(SDS)技术,将分布在不同机架、不同协议的存储设备整合为统一的数据卷空间,并通过RDMA全交换网络提供高达800Gbps的上行带宽,确保大规模分布式训练场景下的数据供给不因IO等待产生计算瓶颈。
通过这一系列抽象,上层应用无需关心底层硬件的具体型号与架构,只需按需申请标准化的算力资源即可。
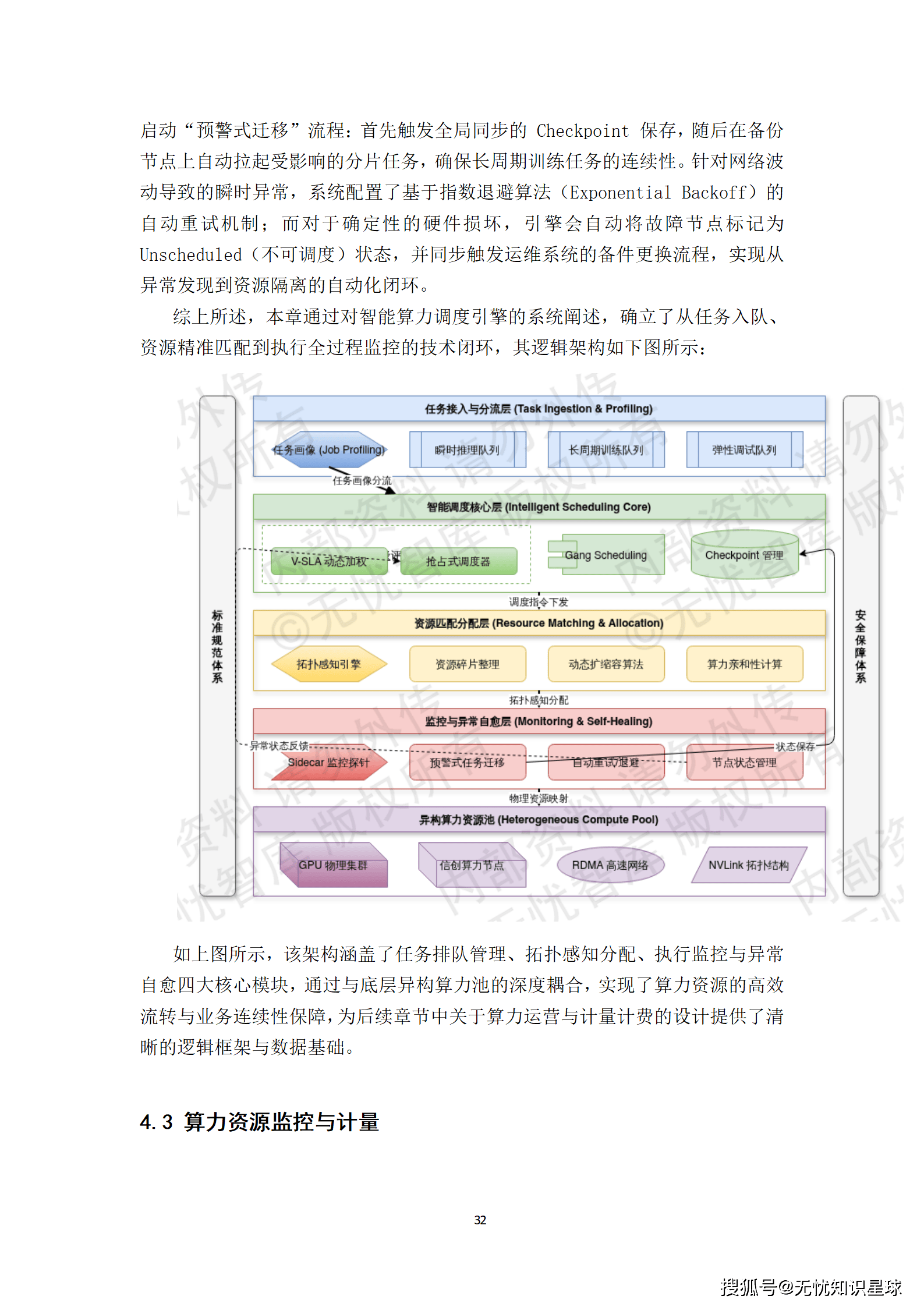
调度引擎是算力池的大脑,其决策的智能程度决定了资源的利用效率。
- 多维特征画像与动态权重补偿:当业务发起算力请求时,调度引擎会提取任务的预估显存峰值、计算密集度、通信带宽需求等特征,将其分流至"瞬时推理"、"长周期训练"或"弹性调试"等专用队列。
- 拓扑感知(Topology-Aware)调度:引擎会实时获取集群内各节点间的NVLink带宽、PCIe拓扑及跨机RDMA网络拥塞状态,优先将多卡协同任务部署在同一机柜或同一交换域内,以消除跨机通信延迟。
- Gang Scheduling与抢占式调度:对于大模型分布式训练任务,强制执行"全成全退"策略,避免资源碎片化。同时,为国家级科研等特高优先级任务提供"抢占式"调度能力,并配合Checkpoint机制实现被抢占任务的状态无损保存。
这种精细化的调度策略,确保了宝贵的算力资源能够被用在刀刃上。
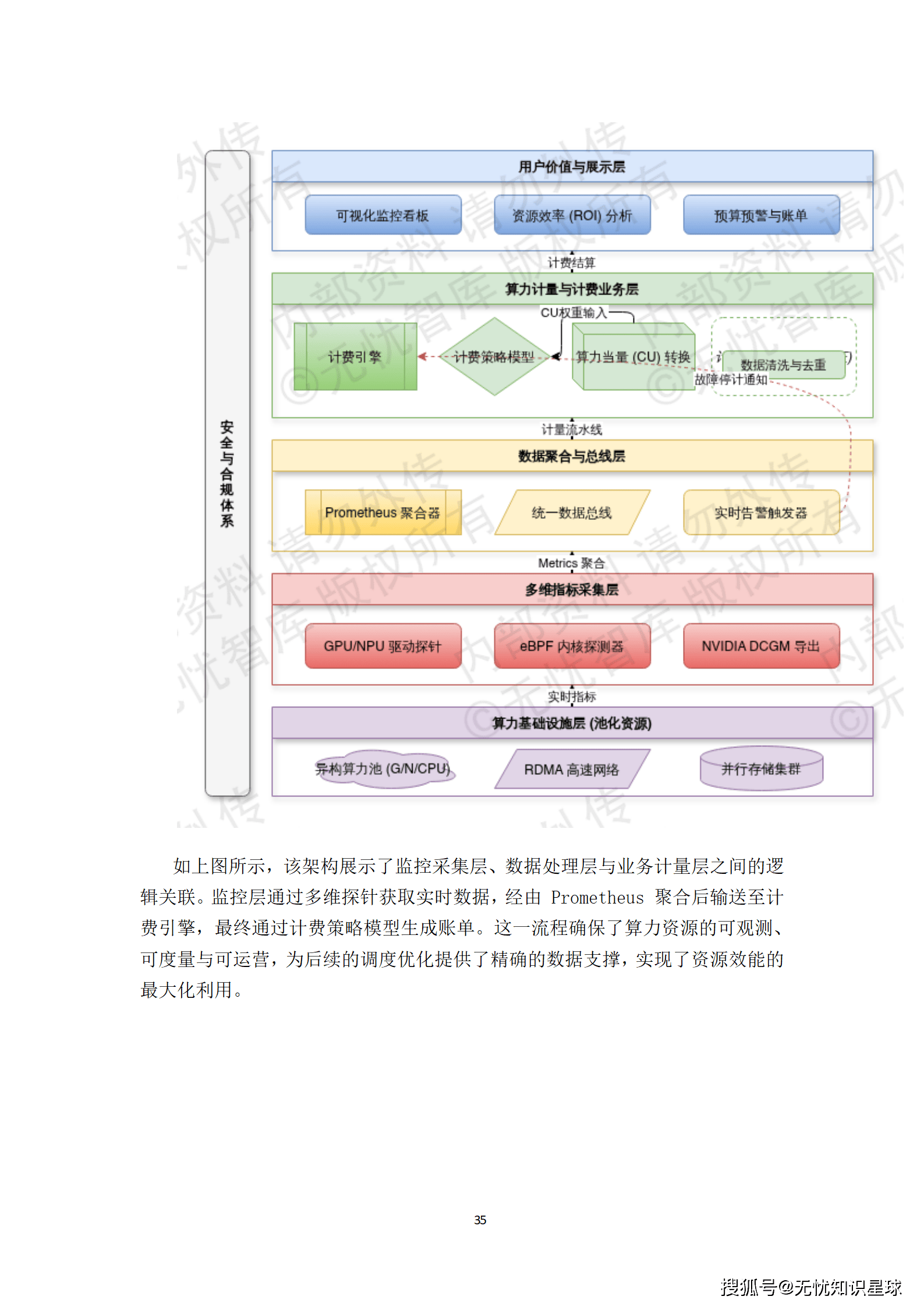
监控与计量是实现资源商业化运营与内部成本核算的基础。
- 全栈可观测性:基于Prometheus生态,系统构建了覆盖底层物理硬件、宿主机操作系统、容器运行时及应用负载的全链路监控体系。针对GPU/NPU,通过集成DCGM导出器或适配厂商驱动接口,实时采集显存占用、SM利用率等关键指标。
- 基于"算力当量"的动态计量模型:将CPU核心、内存容量、GPU算力百分比、显存配额及网络带宽进行加权聚合,抽象为标准化的算力单元(CU)。计费逻辑采用"预占+实计"的复合模式,既保障了资源确定性,又实现了按实际消耗结算的公平性。
- 监控与计量协同:当监控系统探测到硬件故障时,会立即通知计费模块停止对该失效任务的计费,保障用户经济利益。同时,通过关联K8s Namespace与租户ID,确保算力消耗精准追溯至具体项目组。
这套体系让算力资源变得"看得见、摸得着、算得清",为后续的普惠运营奠定了坚实基础。
如果说算力池是身体,那么算法供给与模型管理平台就是大脑。该平台旨在解决算法碎片化、模型复用率低等工程挑战,构建一个覆盖算法汇聚、生产、治理、赋能全链路的闭环体系。
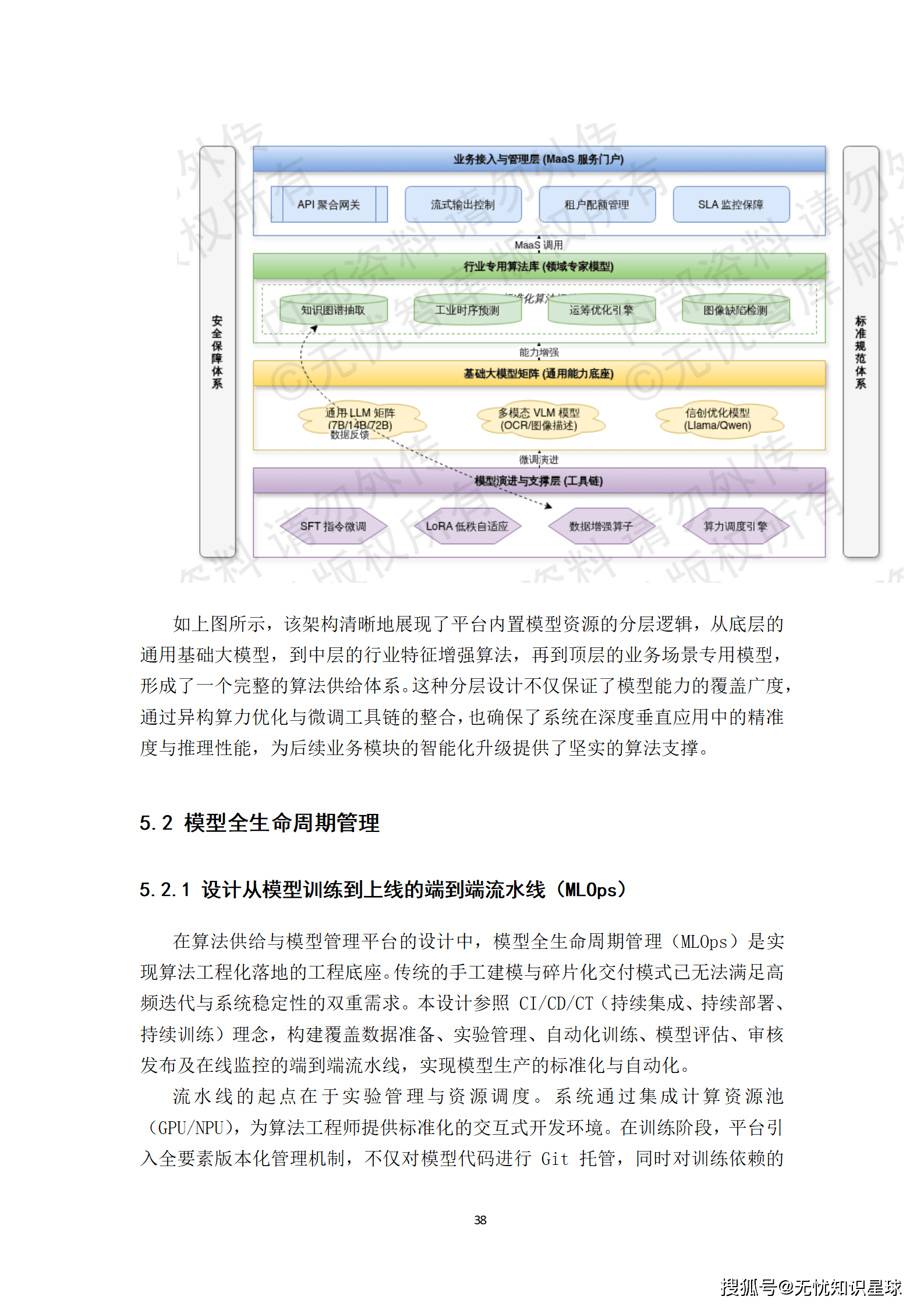
平台通过构建"通用-领域-专用"三层模型资源池,满足多样化的业务诉求。
- 通用大模型层:深度适配Llama 3、Qwen 2等主流开源架构,并针对国产化信创算力进行了底层算子级优化,提供具备万亿级Token预训练背景的通用认知能力。
- 行业专用算法层:沉淀了针对政务公文处理、金融风险建模、工业缺陷检测等场景的标准化组件,通过算子化封装实现业务逻辑的快速装配。
- "模型即服务"(MaaS)管理模式:针对大语言模型,构建统一的API聚合网关,支持流式输出、函数调用及插件化扩展。针对行业专用算法,采用Docker容器化封装与K8s编排技术,支持在工作流引擎中通过拖拽方式完成算法节点的逻辑组装。
这种分层设计,既保证了模型能力的覆盖广度,又确保了在深度垂直应用中的精准度。
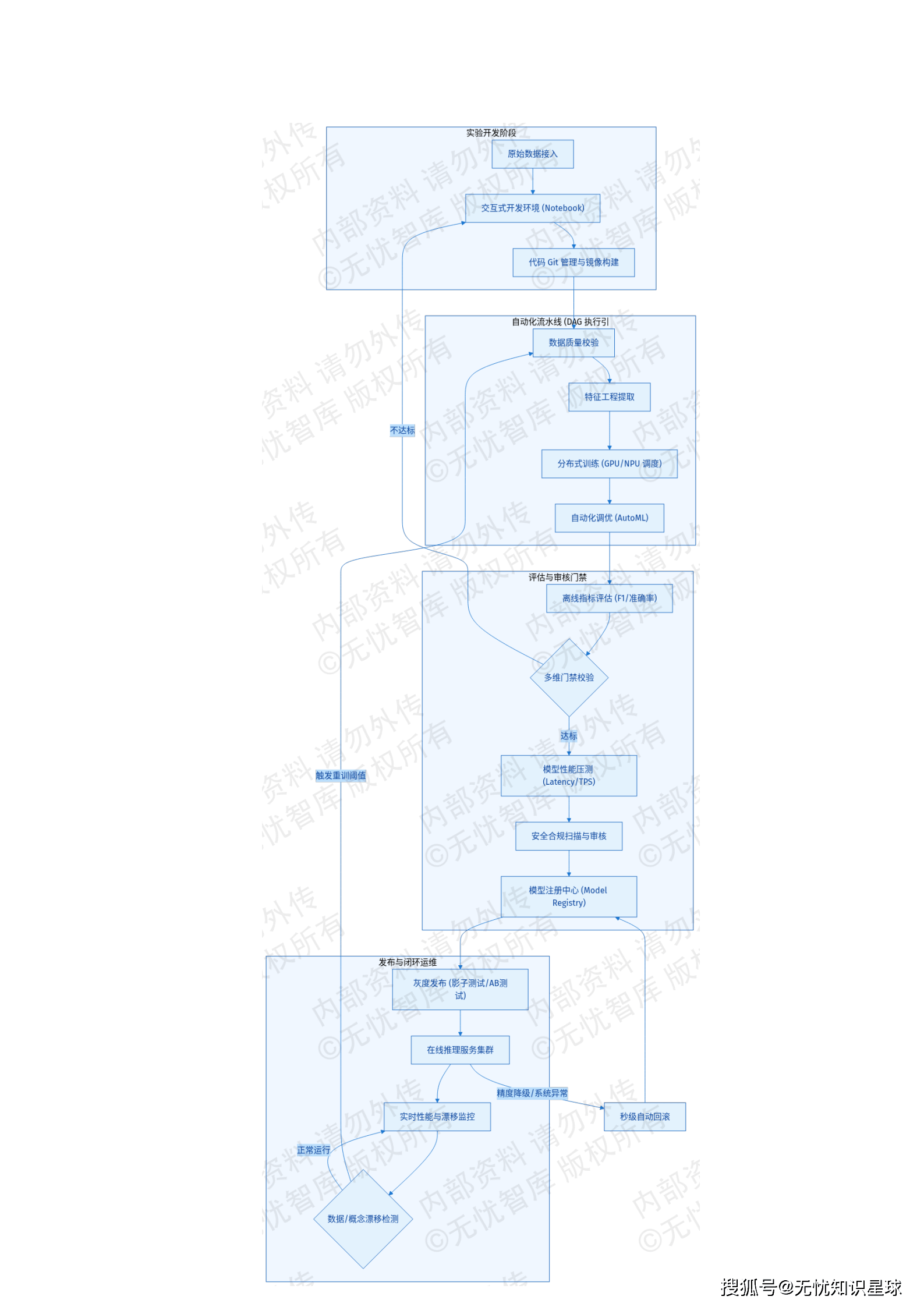
MLOps是实现算法工程化落地的工程底座。平台参照CI/CD/CT理念,构建了端到端的自动化流水线。
- 实验管理与版本化:对模型代码、超参数配置、基础镜像版本、数据切片进行元数据关联,确保任何模型均可回溯至原始训练现场。
- 自动化流水线(Pipeline):执行预定义的DAG任务,包含数据质量校验、特征工程、分布式训练、自动化调优及模型性能压测。
- 严密的发布策略:模型在进入生产环境前,需经过预发环境的影子测试或A/B测试,并通过SRE团队定义的灰度切流规则逐步引入生产流量。
- 数据漂移监测与持续训练(CT):通过对生产环境实时流量的特征统计,一旦检测到环境特征发生显著偏移,系统将自动触发持续训练流程,解决模型上线后的精度退化问题。
MLOps流水线将模型交付周期从周级缩短至小时级,显著提升了算法对业务变化的响应速度。
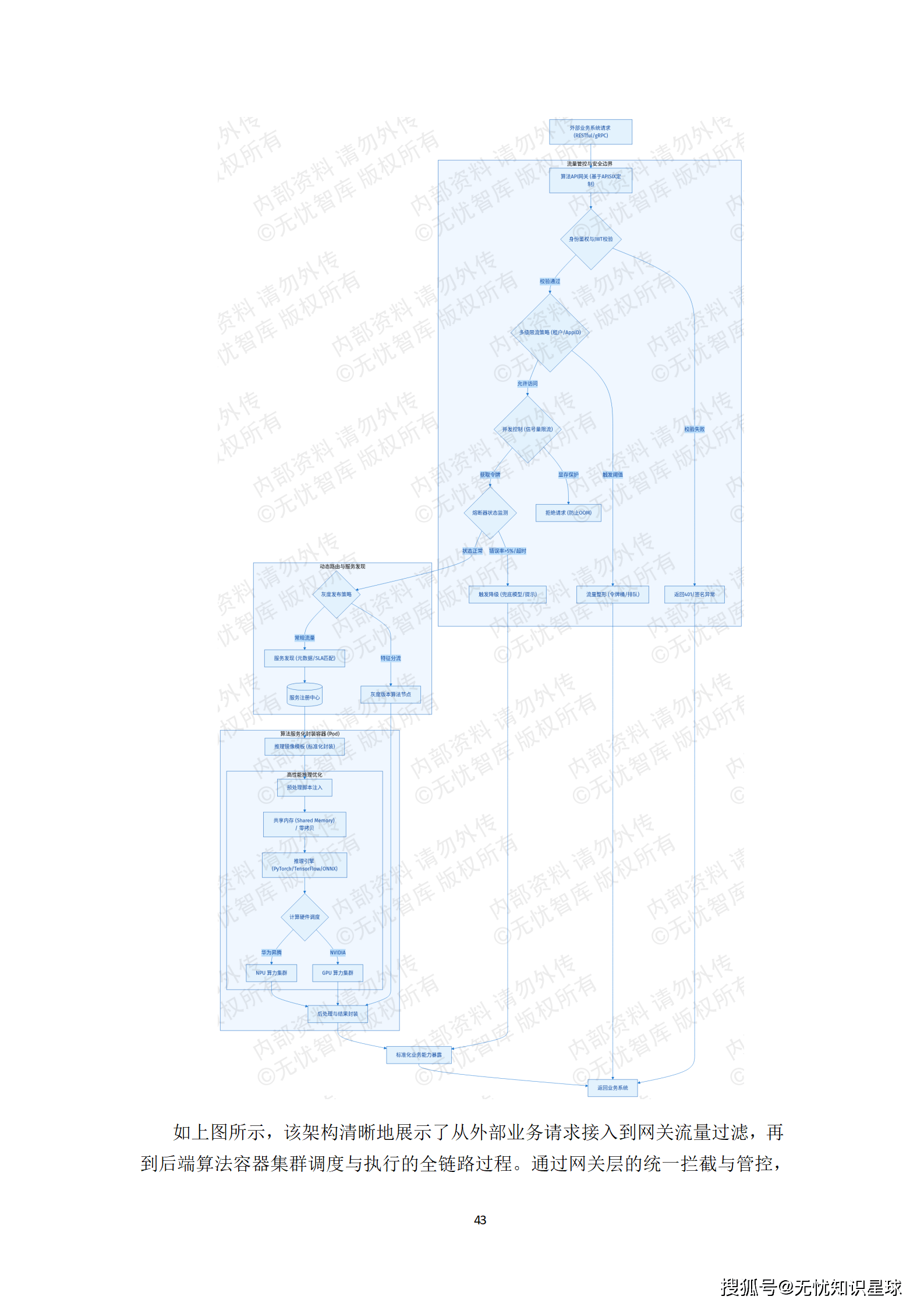
API网关是算法能力对外服务的唯一入口,承担着协议转换、身份鉴权、流量整形与安全防护的重任。
- 标准化服务化封装:利用推理镜像模板屏蔽PyTorch、TensorFlow等框架及NVIDIA GPU、华为昇腾NPU等硬件的底层差异。开发者仅需将模型权重注入指定目录,即可完成服务化部署。
- 多级流量管控:针对GPU显存固定的物理约束,网关采用令牌桶算法实施并发硬隔离,防止单一业务方过度挤占算力资源。同时,集成熔断降级逻辑,当后端节点异常时,自动切换至兜底模型或返回降级响应。
- 灰度发布与蓝绿部署:支持按流量比例、用户标签或地域维度进行精准分流,确保算法的平滑演进。
通过API网关,算法能力被转化为可度量、可管控、可运营的标准化服务。
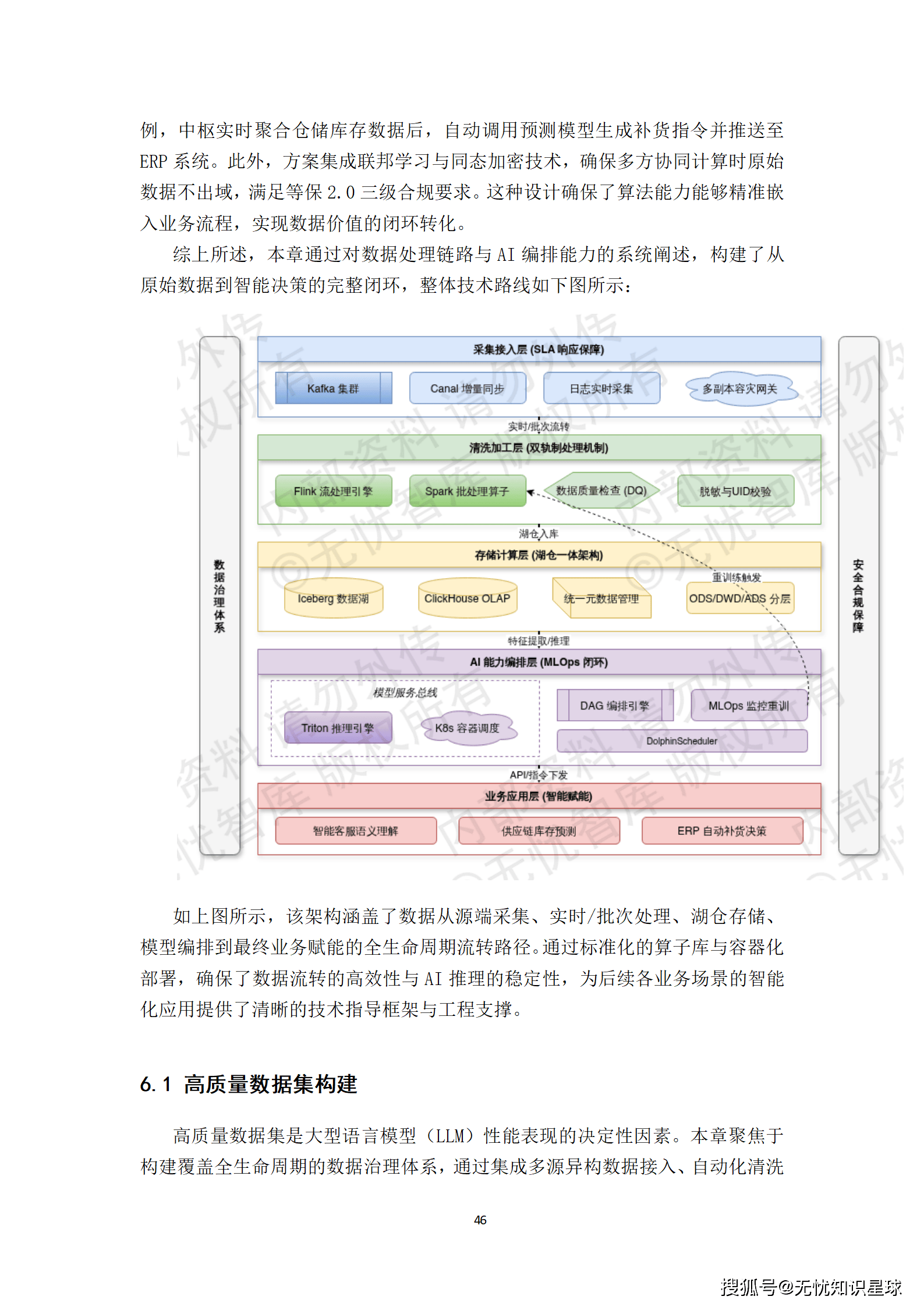
数据是AI的血液,高质量的语料则是大模型性能的决定性因素。本章将探讨如何构建一个覆盖全生命周期的数据治理体系,并通过AI赋能中枢将数据价值转化为业务决策。
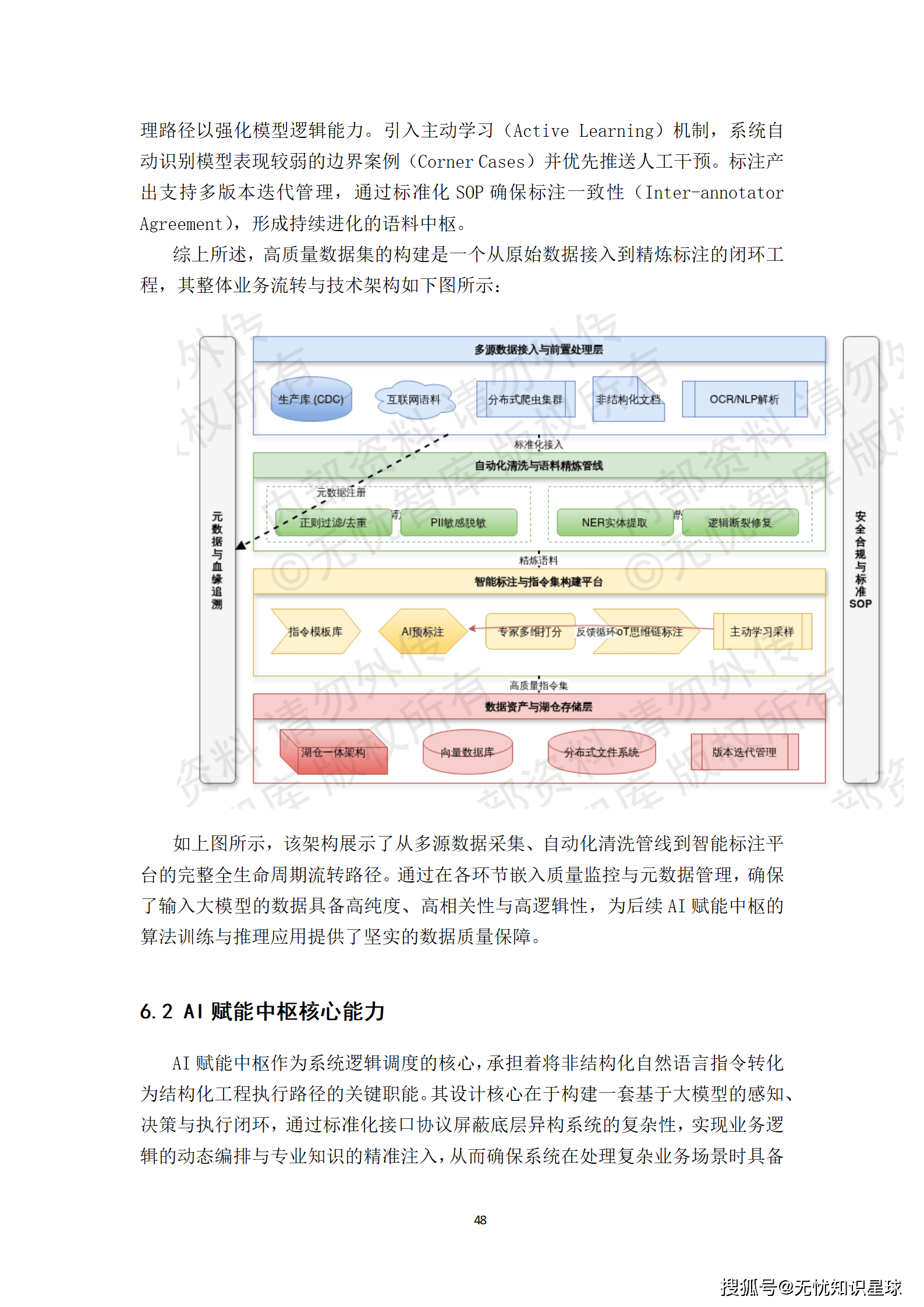
高质量数据集的构建是一个工程化的闭环过程。
- 多源数据接入与治理:依托湖仓一体架构,系统构建了涵盖结构化业务库、非结构化文档及实时流数据的全域接入矩阵。利用CDC技术实现生产库的无损准实时同步,并通过分布式爬虫集群定向采集外部研报与政策法规。
- 自动化清洗与语料精炼:采用"启发式规则+小模型过滤"的双层架构。通用清洗阶段利用MinHash/LSH算法进行语义级去重;领域增强阶段则通过NER技术提取行业关键术语,并利用LLM辅助修复逻辑断裂文本。
- 智能标注体系:建立"人工专家+AI辅助"的双环标注机制。首先利用预训练模型进行Pre-labeling,再由业务专家对指令遵循度、逻辑严密性进行多维打分。引入主动学习机制,系统自动识别模型表现较弱的边界案例并优先推送人工干预。
这套体系确保了输入大模型的数据具备高纯度、高相关性与高逻辑性。
AI赋能中枢的核心在于构建一套基于大模型的感知、决策与执行闭环。
- 复杂任务编排引擎:采用ReAct架构,将用户指令实时拆解为原子化的子任务序列。通过Function Calling机制,自动选择最优工具(如数据库查询插件、外部API)进行调用,实现与底层业务系统的深度协同。
- 知识增强与检索优化(RAG):为解决大模型的"幻觉"问题,构建了深度耦合业务私有数据的RAG体系。系统将企业内部的规章制度、技术规范进行多维向量化处理,并采用混合检索(Hybrid Search)模式,整合向量相似度与关键词倒排索引,显著提升召回结果的准确率。
- 执行监控与闭环反馈:对任务执行状态进行全链路监控,采用Reflection(反思)机制进行结果自检,并配置多级降级策略,在插件调用异常时自动尝试备选路径。
AI赋能中枢不再是简单的问答机器人,而是一个能够理解复杂业务、调用多方资源、并确保执行结果可靠的智能代理。
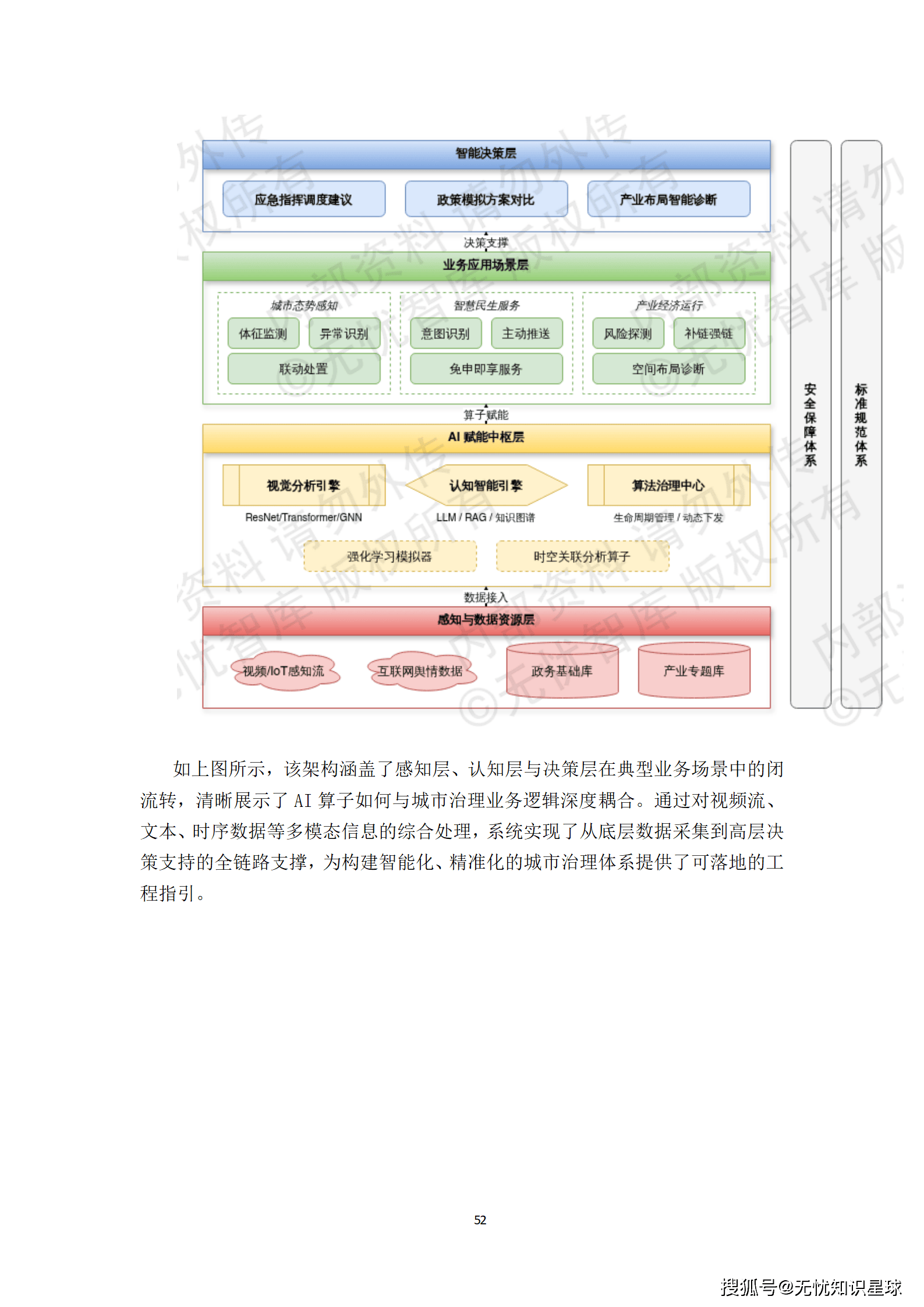
理论的价值最终要通过实践来检验。方案详细规划了三大典型赋能场景:
- 城市运行态势感知与智能预警:通过对全市视频监控流与IoT传感器数据的语义解析,实现汛期内涝、交通拥堵等场景的自动预警与应急调度。
- 智慧民生服务中的语义理解与精准推荐:基于LLM与知识图谱的融合架构,实现从被动响应向主动服务的转型,如为"专精特新"企业精准推送奖补政策。
- 产业经济运行的深度分析与决策辅助:通过构建产业链与供应链的动态演化模型,识别产业集群的结构性特征,模拟不同政策组合的拉动效果,为决策层提供量化对比方案。
这些场景清晰地展示了AI算子如何与城市治理业务逻辑深度耦合,实现了从底层数据采集到高层决策支持的全链路支撑。
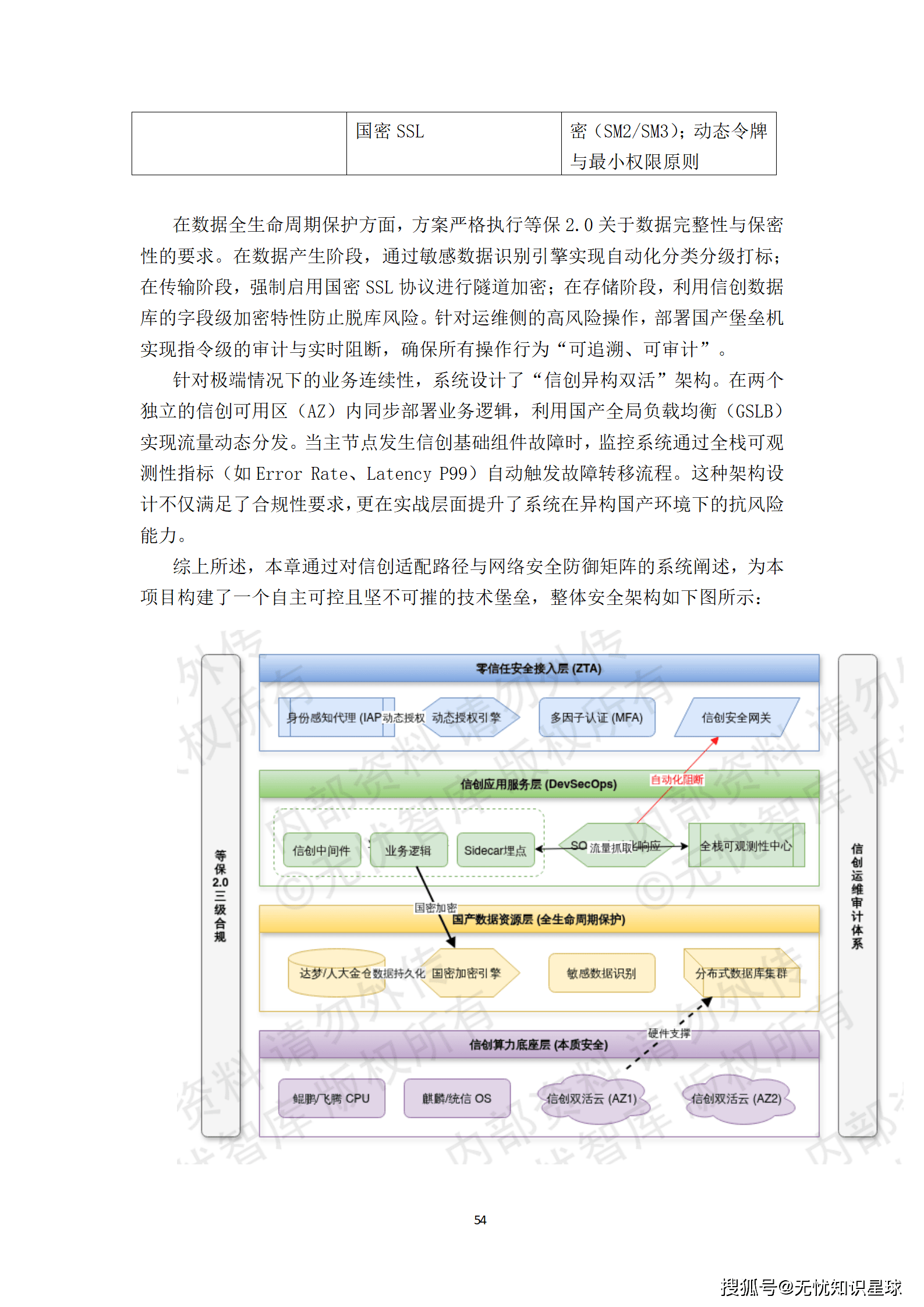
在当前复杂的国际环境下,安全与自主可控已成为项目建设的首要前提。方案构建了一套深度融合信创适配与网络安全的纵深防御体系。
信创适配并非简单的软硬件替换,而是基于国产底层架构的系统性重构。
- 双栈部署模式:采用"海光(C86架构)+鲲鹏(ARM架构)"的双栈部署。海光处理器利用其对x86指令集的高度兼容性,承载关键核心业务;鲲鹏处理器则凭借其多核高并发优势,构建大规模微服务集群。
- 深度耦合与性能对标:在操作系统层面,通过内核级参数调优,针对国产CPU的流水线特征进行指令集优化。在数据库层面,采用达梦DM8或人大金仓Kingbase,通过分布式事务强一致性协议实现PB级数据的毫秒级查询响应。
- 原生适配与平滑迁移:所有业务逻辑代码均基于国产开发框架进行编译,并通过信创适配实验室对每一个业务模块进行严苛压测,确保系统上线后性能衰减控制在10%以内。
这套方案确保了系统在极端外部环境下的业务连续性。
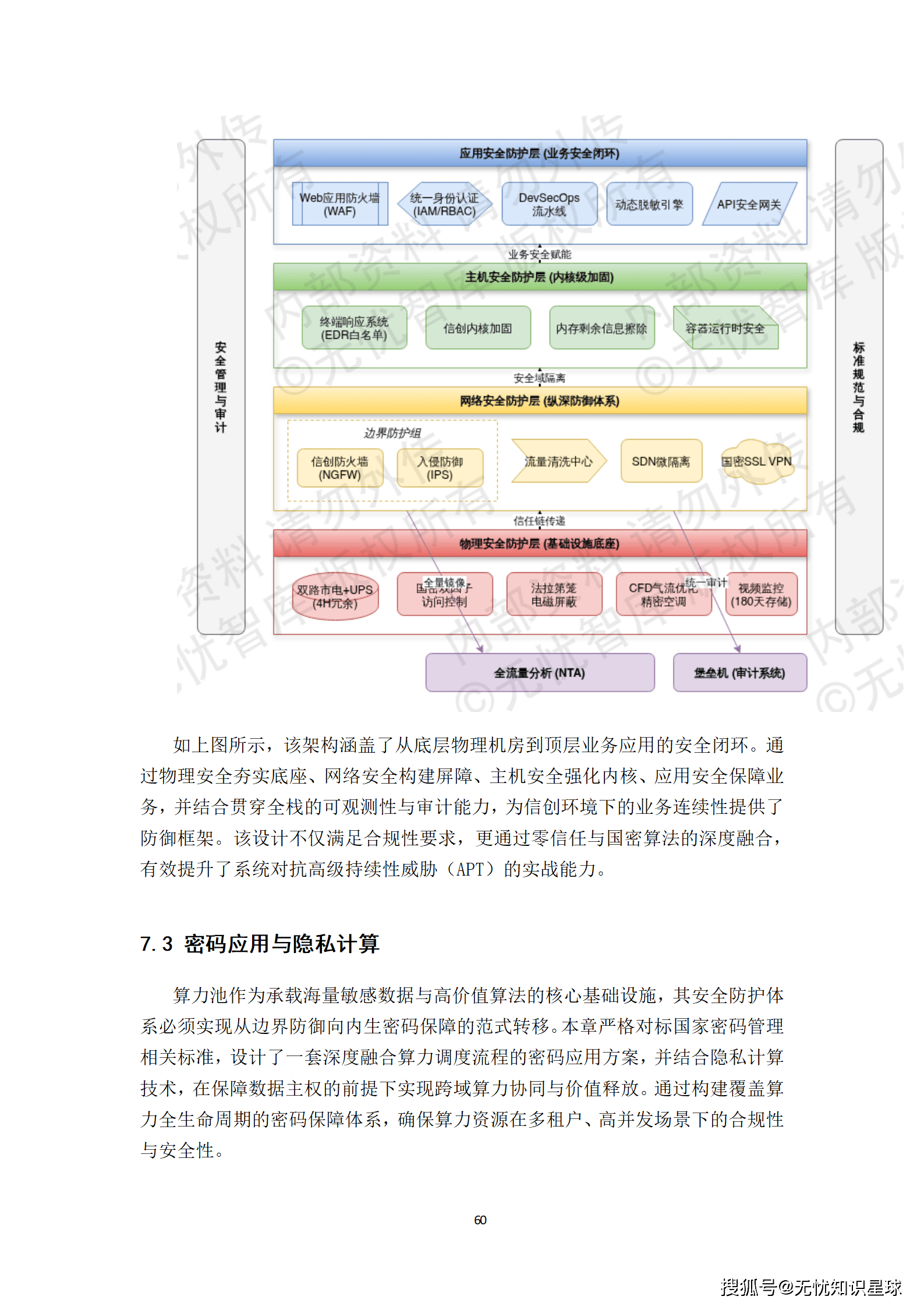
网络安全设计摒弃了传统的"边界围墙式"被动防护,转向以零信任为核心、以全栈可观测性为触角的动态防御体系。
- 物理安全:机房采用法拉第笼结构,并为核心数据处理单元配置电磁屏蔽机柜,防止国产化芯片在高速运算时的电磁信息泄露。
- 网络安全:依托SDN技术实现业务、管理与存储平面的逻辑隔离,并引入微隔离技术,默认执行"Deny All"访问控制策略。
- 主机与应用安全:部署基于"白名单"机制的终端安全响应(EDR)系统,并在CI/CD流水线集成静态代码扫描(SAST)与开源组件分析(SCA),实现安全左移。
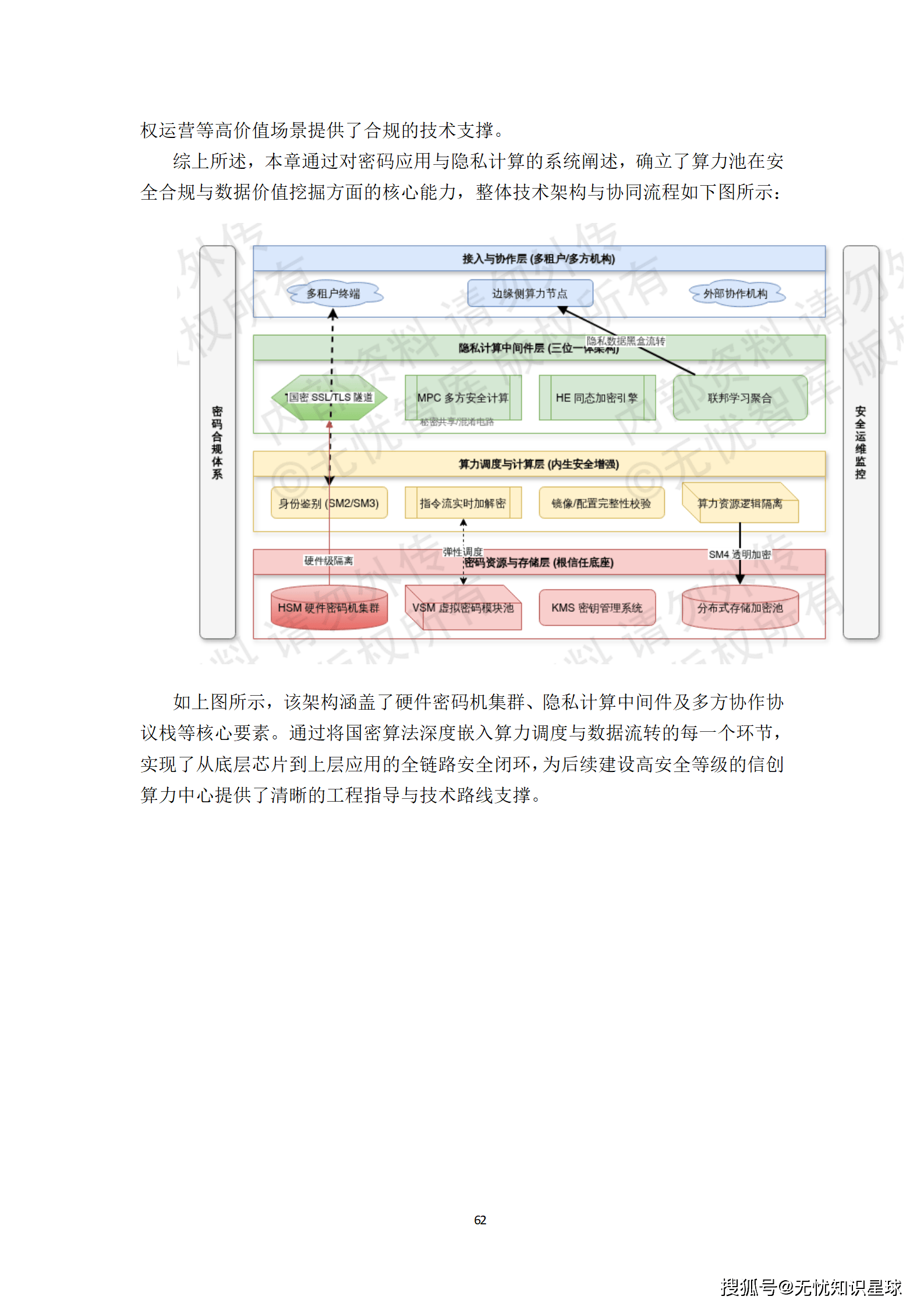
为解决数据共享与隐私保护的冲突,方案引入了隐私计算架构。
- 全链路密码保障:遵循GB/T 39786-2021三级标准,构建覆盖物理、网络、计算及数据层的全链路密码保障体系。通过部署信创硬件密码机(HSM)集群,支撑多租户环境下的密钥逻辑隔离。
- 隐私计算架构:整合可信执行环境(TEE)、多方安全计算(MPC)及同态加密(HE)技术。在跨机构协作场景中,原始数据被拆分为多个分片并分发至异构算力节点,确保单一节点无法还原完整信息,为金融风控、政务数据授权运营等高价值场景提供了合规的技术支撑。
这套安全体系不仅满足了合规性要求,更在实战层面提升了系统对抗高级持续性威胁(APT)的能力。
一个成功的项目,不仅在于其技术的先进性,更在于其能否建立起可持续的运营模式与繁荣的开发者生态。
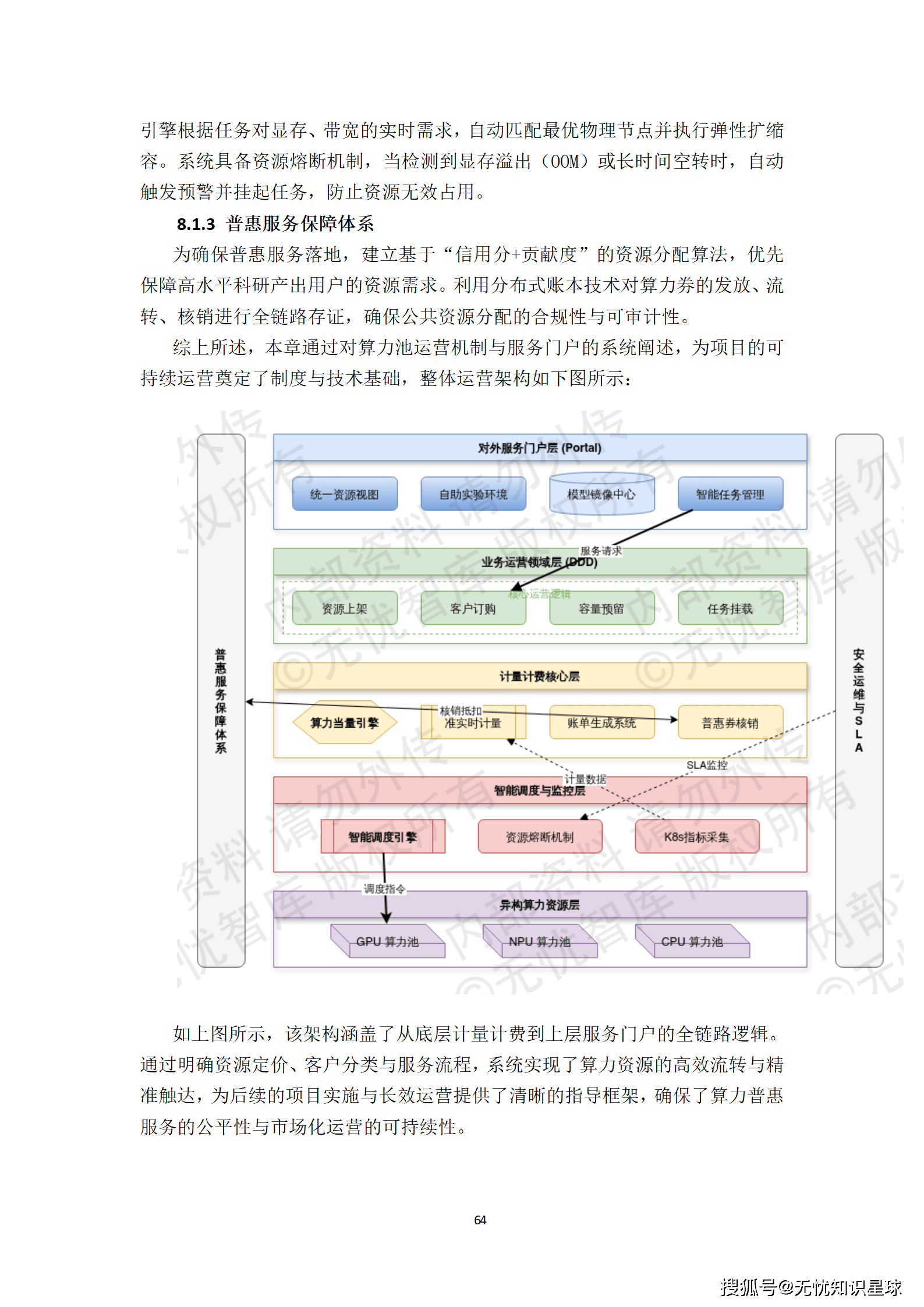
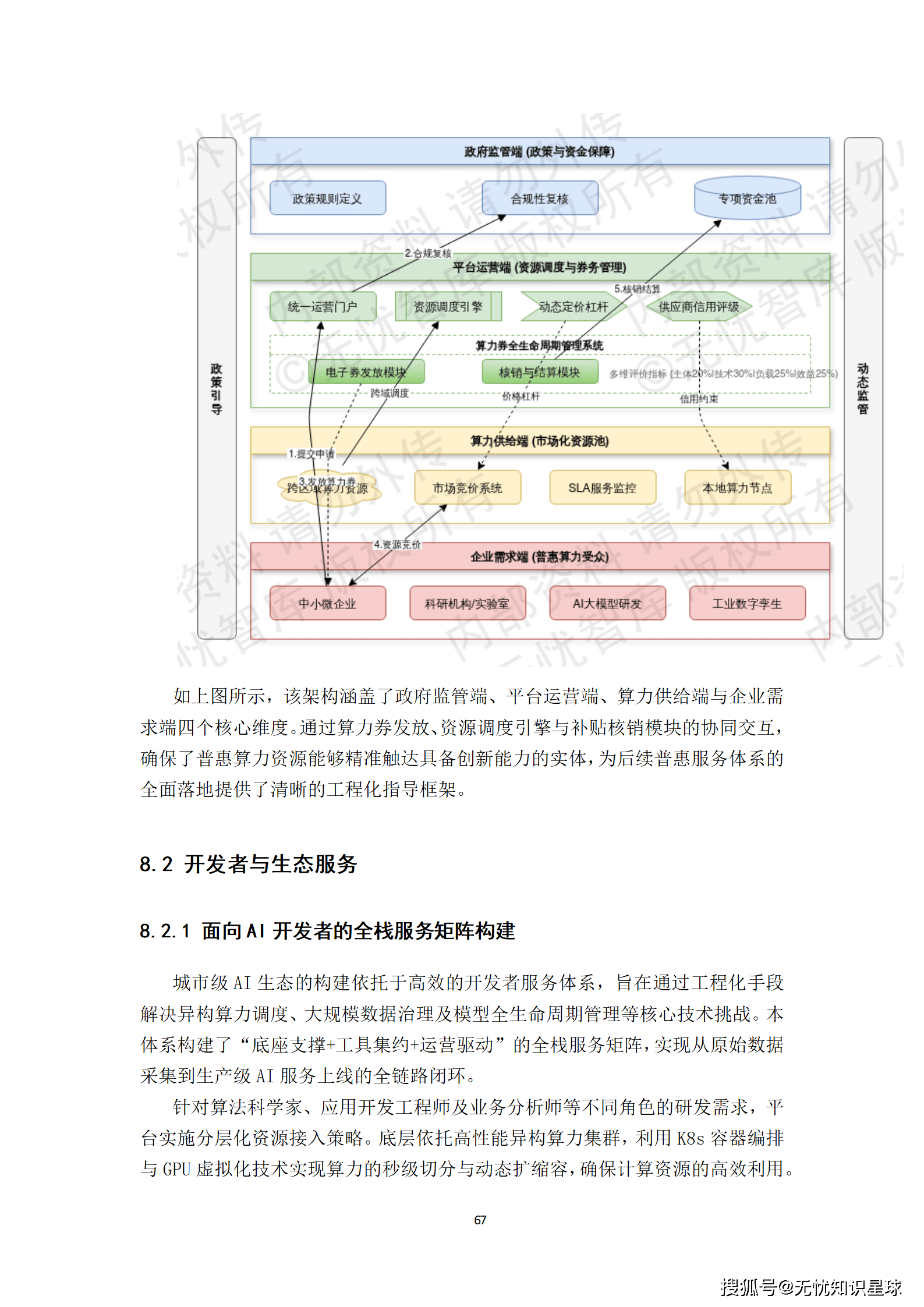
普惠算力运营机制的核心在于平衡公益属性与商业可持续性。
- "算力券"模式:由传统的"一次性建设补贴"转向"基于实际消耗的运行补贴"。企业或科研机构通过运营门户申请算力需求,审核通过后获得电子"算力券",在购买服务时直接抵扣。这种模式确保了财政资金的精准穿透与高效利用。
- 动态定价与竞价机制:运营平台实时监控各节点余量,通过价格杠杆调节需求峰谷。在非高峰时段,鼓励供应商提供低价甚至免费的测试算力,进一步降低初创企业的入场门槛。
- 算力消纳补偿机制:当本地算力供不应求需调用异地资源时,政府根据跨区域带宽成本及能效比给予额外补贴,确保用户侧感知到的算力价格保持平稳。
这套机制有效激发了市场活力,实现了资源的最优配置。
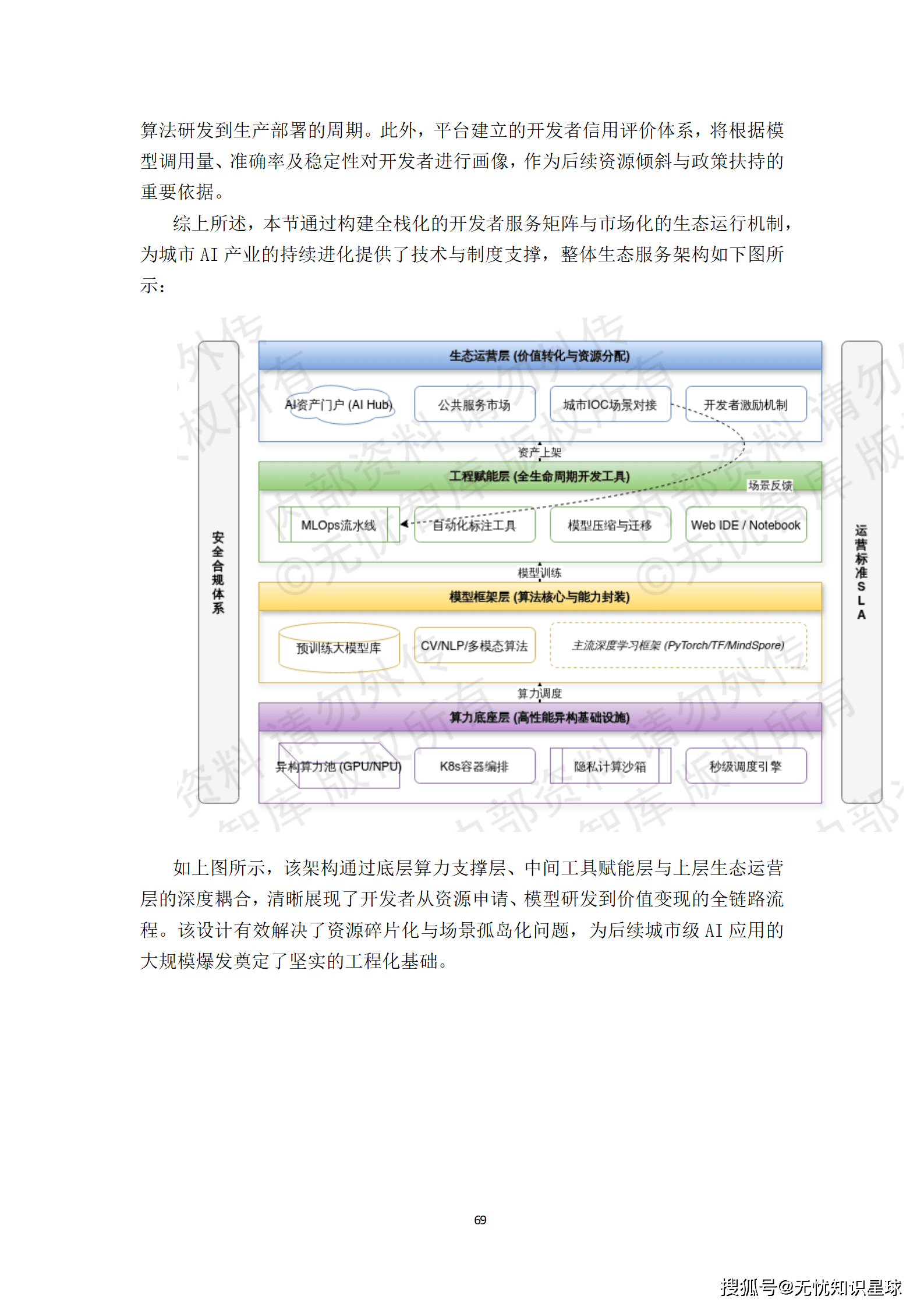
繁荣的AI生态离不开高效的开发者服务体系。
- 全栈服务矩阵:构建了"底座支撑+工具集约+运营驱动"的全栈服务矩阵。开发者可通过Web IDE与Notebook交互式环境,直接调用底层算力资源,规避了异构环境下的工程适配成本。
- AI资产门户(AI Hub):实现模型、算法组件、API接口及行业数据集的标准化封装。开发者在完成模型验证后,可将其发布至公共服务市场,通过分润机制或算力补贴获得激励。
- 生态激励与撮合:通过算力券发放、人工智能创新大赛等形式吸引初创团队与科研机构入驻。针对具备高商业价值的算法,开启"绿色通道",直接对接城市运行管理中心(IOC)等真实业务场景,缩短从算法研发到生产部署的周期。
这套服务体系有效解决了资源碎片化与场景孤岛化问题,为城市AI产业的持续进化提供了技术与制度支撑。
"算力算法数据一体化供给的城市级AI大模型算力池"的建设,绝非一个孤立的IT项目,而是城市迈向"智能体"(City Intelligence Body)新纪元的关键一步。
未来的城市,将不再仅仅是一个由道路、建筑和人口构成的物理空间,而是一个拥有强大感知、认知、决策与执行能力的有机生命体。这个生命体的"神经系统"就是遍布全域的物联网与5G/6G网络;其"大脑皮层"就是我们今天所构建的AI赋能中枢;而其赖以思考和行动的"血液"与"能量",正是由一体化算力池所提供的澎湃算力与高质量数据。
在这个新纪元里,城市治理将从"被动响应"走向"主动预见",产业发展将从"经验驱动"走向"数据智能驱动",民生服务将从"千人一面"走向"千人千面"。而这一切变革的基石,正是今天我们所探讨的,那个集约、普惠、安全、高效的"算力-算法-数据"三位一体的供给体系。
这场始于供给侧的深刻革命,终将重塑城市的未来面貌。