前言
来了来了,接下来读到的这篇是计算机视觉领域非常重要的论文,之后有许多重要的视觉论文都有应用其中的思想。
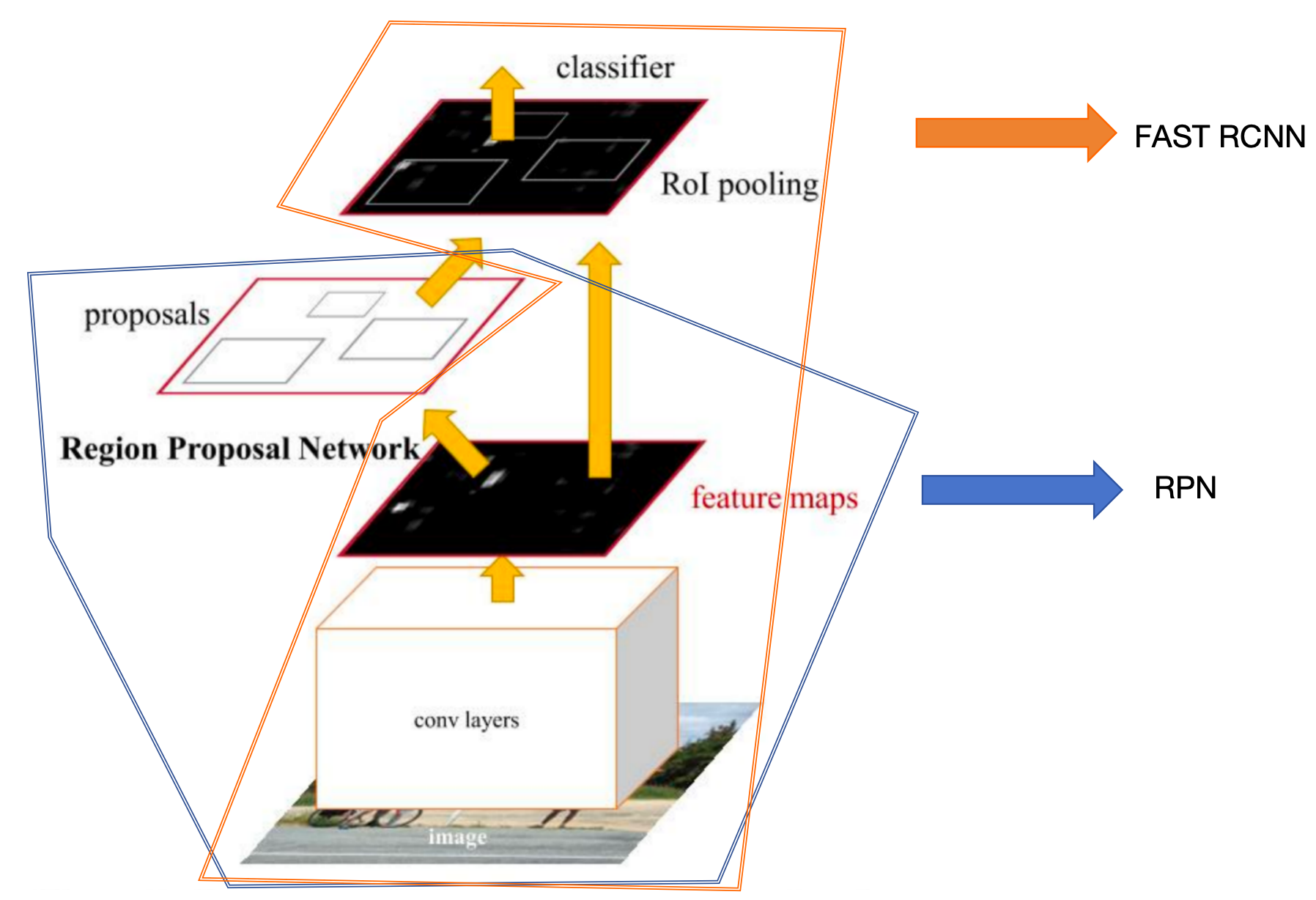
Faster RCNN其实就是用RPN替换了SS算法,如果没有看过Fast RCNN建议先了解
Fast RCNN传送门
Faster R-CNN
摘要
In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection.
RPN是与检测网络共享全图的卷积特征,以此是无成本的。
简介
目前区域提议的方法都很慢,如SS和Edge Boxes。
提出了一个解决方案PRN,这个网络共享卷积层,达到减少工作量和计算时间
提出了锚框
相关工作
研究目前的方法
目标提议
- 基于超像素分组方法
- 基于滑动窗口方法
用于目标检测的深度网络
R-CNN、OverFeat和MultiBox
更快的R-CNN
简单分为两个模块,一是负责生成候选区域,二是对这些候选区进行检测。
对于这两个模块,开发了利用共享特征对两个模块进行联合训练的算法
区域提议网络
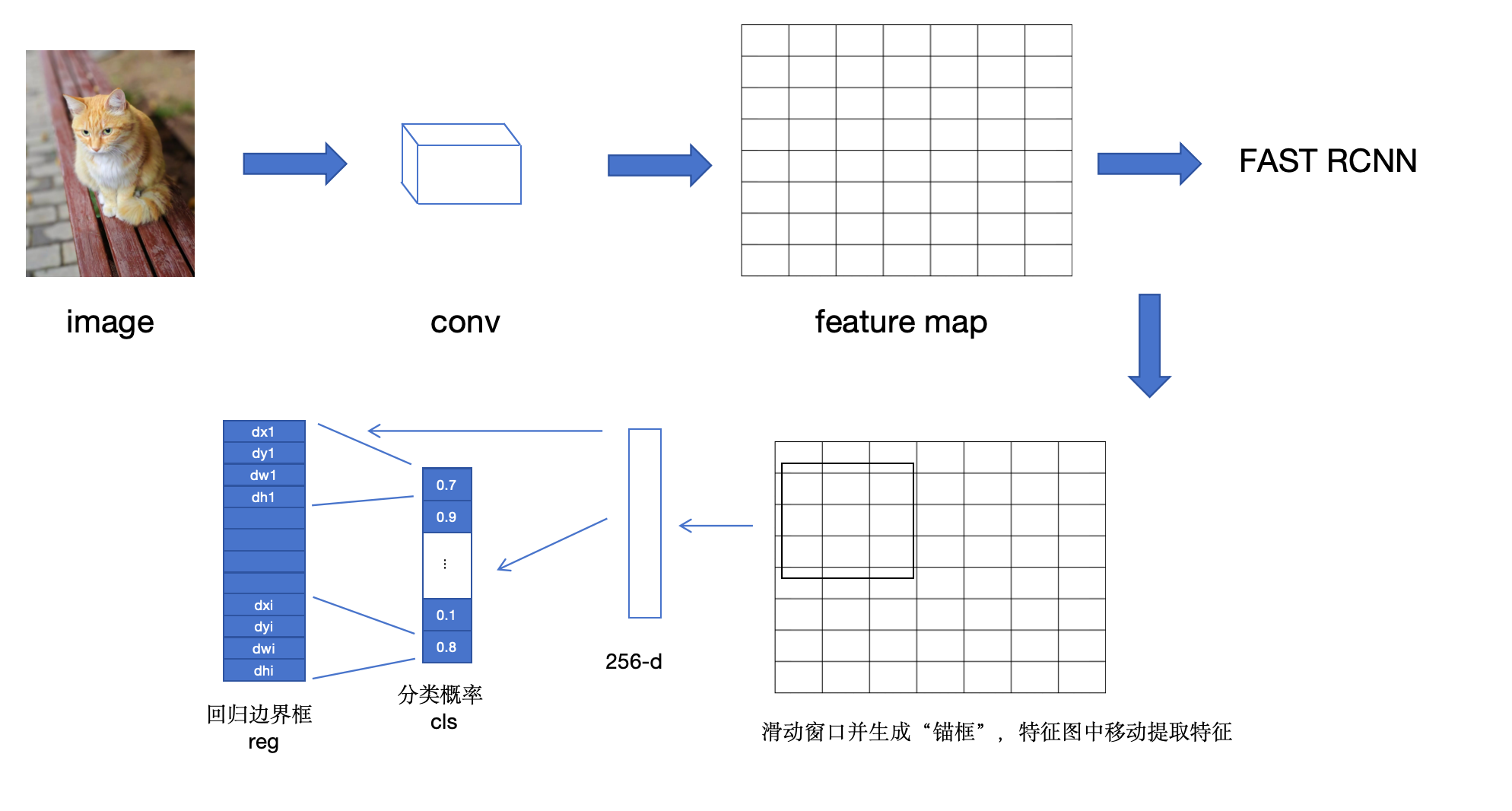
简称RPN,将任意尺寸的图像作为输入,输出一组矩阵目标提议,并每个提议都带有置信度分数。
为了生成区域建议,将在最后一个共享卷积层输出的卷积特征图上滑动一个小型网络。
每个滑动窗口被映射到一个低维特征(ZF为256-d,VGG为512-d)。这些特征送入两个并行的全连接层,分类和边界框。
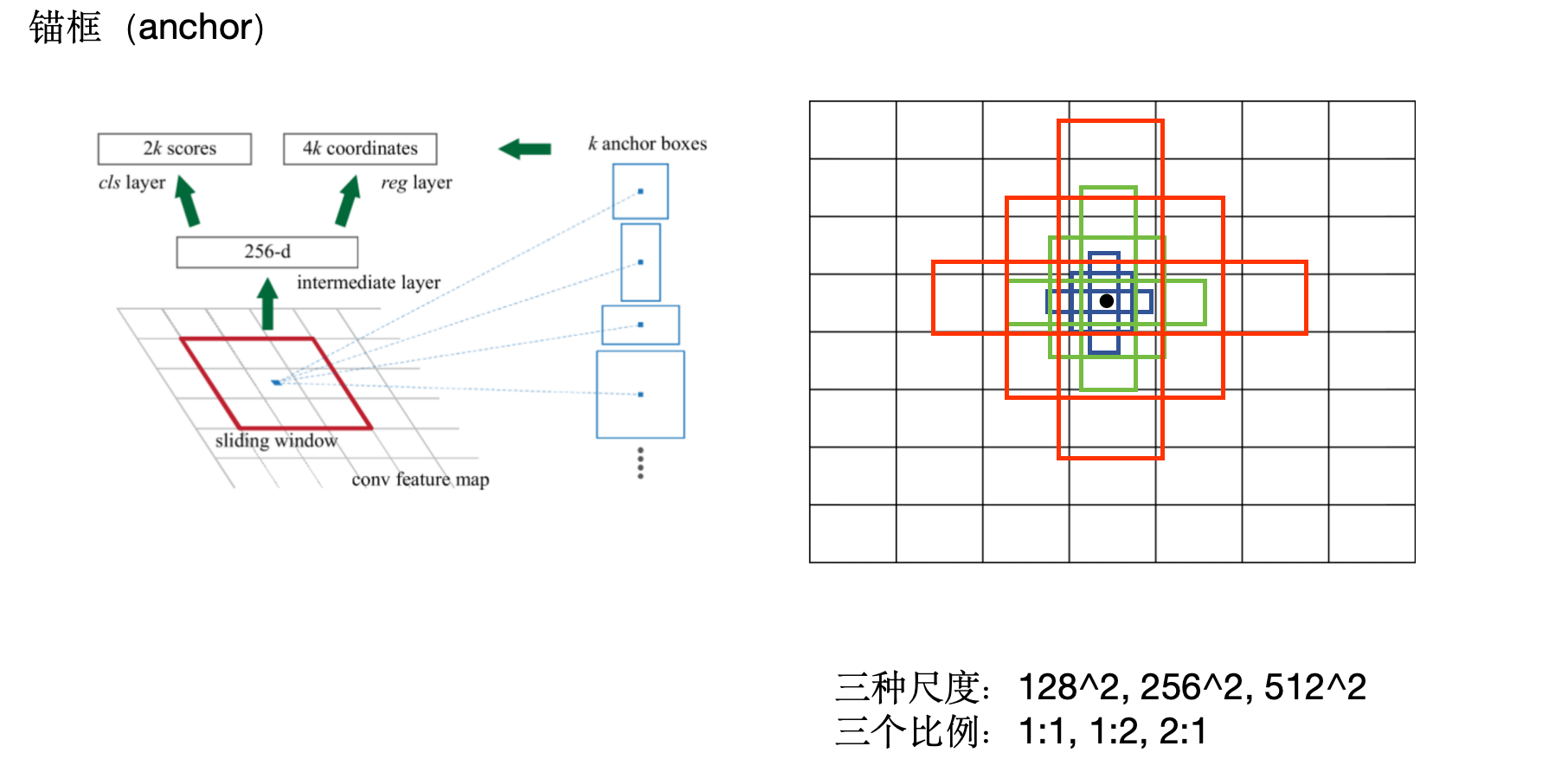
锚点
就是在每个滑动窗口基础上,生成多个不同大小比例的框
平移不变性:如果目标平移了,提议也随之平移。而且是在共享的特征上平移,在锚框生成数k=9和VGG-16的情况下,输出层的参数是(512 * (4 + 2) * 9)。
损失函数
正标签分给两类锚框:
- 与真实边界框有最高交并比(IOU)重叠的锚点
- 一个与目标交并比重叠大于0.7的任何真实框
非正锚框与所有的真实框交并比均低于0.3,则为负标签
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i\},\{t_i\}) = {1\over N_{cls}}{\sum_i}{L_{cls}(p_i,p^*i)} + \lambda {1\over N{reg}} \sum_i {p^*i L{reg}(t_i,t^*_i)} L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
下面是对于RPN损失函数的解释:
i i i 是一个mini-batch中锚框的索引
p i p_i pi 是第i个anchor预测为对象的概率
p i ∗ p^*i pi∗ 是正样本为1,负样本为0
t i t_i ti是一个向量,预测第i个anchor的边界框回归参数
t i ∗ t^*i ti∗是第i个anchor对应的真实框
L c l s L{cls} Lcls用 s m o o t h L i smooth{L_i} smoothLi
通过 N c l s N_{cls} Ncls、 N r e g N_{reg} Nreg和 λ \lambda λ归一化
λ \lambda λ默认为10
N c l s N_{cls} Ncls是一个最小批次中的所有样本数量为256
N r e g N_{reg} Nreg是anchor位置的个数(不是anchor个数)约为2400
对于边界框回归,有
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a , t w = log ( w / w a ) , t h = log ( h / h a ) , t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = log ( w ∗ / w a ) , t h ∗ = log ( h ∗ / h a ) t_x=(x-x_a)/w_a, t_y=(y-y_a)/h_a,\\ t_w=\log(w/w_a),t_h=\log(h/h_a),\\ t^*_x=(x^*-x_a)/w_a,t^*_y=(y^*-y_a)/h_a,\\ t^*_w=\log(w^*/w_a),t^*_h=\log(h^*/h_a) tx=(x−xa)/wa,ty=(y−ya)/ha,tw=log(w/wa),th=log(h/ha),tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha)
变量 x x x, x a x_a xa和 x ∗ x^* x∗为别是预测框、锚框和真实框,( y y y、 w w w、 h h h同理)
训练RPN
该RPN采用反向传播与随机下降(SGD)实现端对端训练。
"以图像为中心"的采样策略。
每个小批量样本均来自单张图像,其中包含大量正负样本锚点。容易偏向负样本。(如一张图片只有两三个目标,其他非目标就会很多,这就是负样本)。所以论文改为随机采样256个锚点,平衡正负样本的数量。
通过均值为0、标准差为0.01的正态分布中随机抽取权重来初始化。用于提取特征的卷积层(如 VGG-16 的前几层)并没有随机初始化,而是加载了在 ImageNet 数据集上已经训练好的权重。
ZF Net:这是一个较浅的网络,参数量较小,所以作者更新所有层的参数。
VGG-16:这是一个很深的网络,参数量巨大。为了节省显存(Conserve memory),作者只更新了从 conv3_1 层开始往后的层。
前 60,000 次迭代:学习率为 0.001(大步走,快速接近最优解)。
后 20,000 次迭代:学习率降为 0.0001(小步走,精细调整,防止震荡)。
总迭代次数:80,000 次(mini-batches)。
交替训练 (Alternating training)
理解: 这是一种迭代式训练方法。先训练一个模块,用其输出训练另一个模块,然后用更新后的另一个模块重新初始化第一个模块并再次训练,如此交替进行,使两个模块逐渐适应彼此并收敛到共享特征。
翻译:
在这个解决方案中,我们首先训练 RPN,然后使用它生成的候选区域去训练 Fast R-CNN。
接着,用经过 Fast R-CNN 调优后的网络(主要指共享的卷积层权重)来初始化 RPN 网络(即替换掉 RPN 原有的初始化权重)。
然后重复这个过程(即用更新后的共享层再次训练 RPN,再用新的 RPN 候选区域训练 Fast R-CNN)。
这个方案被用于本文的所有实验中。 (作者最终选择的方法)