🚀 本文收录于Github:AI-From-Zero 项目 ------ 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
知识工程和知识图谱有什么区别?如何构建完整的知识体系?
by @Laizhuocheng
一、简介
想象一下你是一家电商公司的技术负责人,老板让你做一个"智能导购系统"------用户问"有没有适合学生党、续航久的轻薄本",系统能精准推荐商品并解释为什么。
你会怎么做?
如果只想到知识图谱,你可能会直接回答:"建个图谱,把商品、品牌、属性连起来,然后做查询。"
但如果懂得知识工程,你会意识到:这只是一个复杂的系统工程的冰山一角。你需要先理解业务需求,设计知识模型,从多个数据源抽取商品信息,处理不同来源的数据冲突,选择合适的存储方案,设计推理规则,最后才是构建应用。
知识图谱和知识工程的本质区别:知识图谱是知识的"容器",它解决的是"用什么格式存储知识"的问题;而知识工程是一套完整的方法论和工程体系,它解决的是"如何从零开始构建一个完整的知识智能系统"的问题。
就像数据库和数据库系统开发的关系------数据库只是存储数据的容器,但你要构建一个完整的业务系统,需要考虑需求分析、数据建模、ETL流程、查询优化、应用集成等全链路问题。
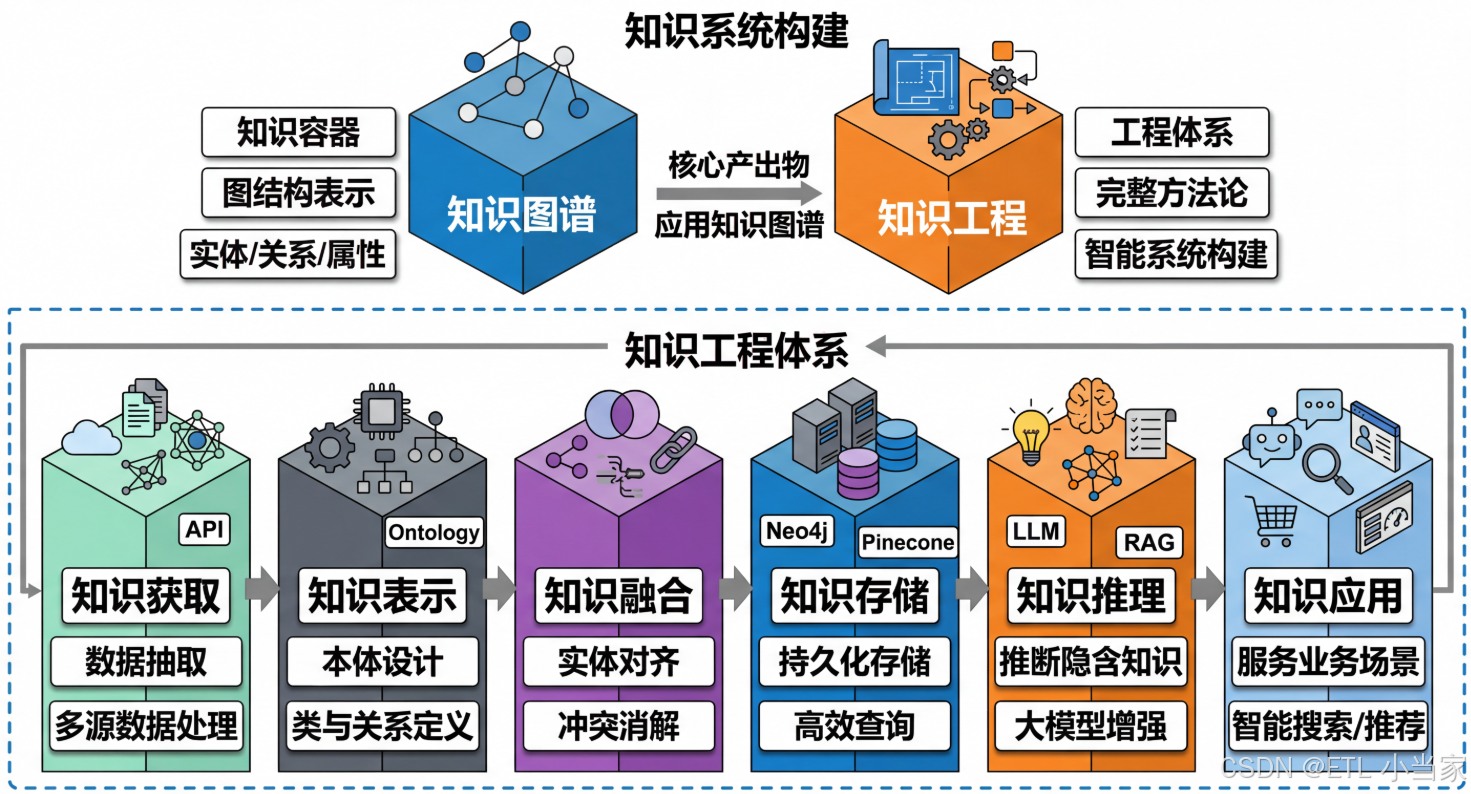
二、什么是知识工程和知识图谱?
知识图谱:知识的"容器"
知识图谱 (Knowledge Graph)是一种用图结构表示知识的数据模型。
- 节点:实体(如"苹果公司"、"iPhone 15")
- 边:关系(如"生产"、"发布于")
- 属性:附加信息(如"价格"、"发布时间")
它解决的核心问题是:用什么格式存储知识。
知识图谱只是知识工程的核心产出物之一,就像代码编译后的可执行文件,只是整个软件工程的一个环节。
知识工程:构建知识的"方法论"
知识工程 (Knowledge Engineering)是一套完整的方法论和工程体系,目标是从零开始构建一个能理解和应用知识的智能系统。
它包含的不仅是存储,还有:
- 如何从数据中提取知识(知识获取)
- 如何组织和建模知识(知识表示)
- 如何保证知识的质量和一致性(知识融合)
- 如何高效存储和查询知识(知识存储)
- 如何让知识"活起来"(知识推理)
- 如何把知识应用到实际业务(知识应用)
知识工程的范畴远大于知识图谱,它回答的是:如何从零开始构建一个完整的知识智能系统。
历史脉络:从专家系统到知识图谱
理解两者的差异,需要了解知识工程的发展历程:
| 时代 | 核心技术 | 知识表示形式 | 特点 |
|---|---|---|---|
| 1980年代 | 专家系统 | if-then规则 | 人工编码专家经验,成本高、更新慢 |
| 1990年代 | 本体工程 | 本体(Ontology) | 用类、属性、关系定义知识结构 |
| 2000年代 | 语义Web | RDF、OWL | 标准化知识表示,追求机器可理解 |
| 2012年至今 | 知识图谱 | 图数据库 | 大规模数据驱动,强调应用落地 |
关键转折点:2012年Google正式提出"Knowledge Graph",把知识图谱从学术概念变成了工业界的标准。从此,知识图谱成为了知识工程最显性的产出,很多人开始混淆两者。
三、知识工程如何工作
知识工程不是一个线性流程,而是一个迭代优化的闭环系统。每个阶段的输出会反馈到前面的阶段,持续改进整体质量。
知识获取:从数据到三元组
目标:从各种数据源中抽取结构化的知识。
数据源类型:
| 数据源类型 | 例子 | 抽取方法 |
|---|---|---|
| 结构化数据 | 数据库表、Excel | 直接映射成三元组 |
| 半结构化数据 | HTML、XML、JSON | XPath、CSS选择器解析 |
| 非结构化数据 | 新闻文本、用户评论 | 命名实体识别(NER)、关系抽取 |
| 多模态数据 | 图片、视频 | 图像理解、视频分析 |
技术手段:
- 结构化数据:直接转换
- 半结构化数据:规则解析
- 非结构化数据:用NER模型和关系抽取模型
- 大模型增强:用GPT-4、Claude等做few-shot学习,快速适配新领域
知识表示:设计知识的"类定义"
目标:把零散的三元组组织成结构化的知识模型。
什么是本体?
本体(Ontology)是知识的"类定义",它规定了:
- 实体有哪些类型(类)
- 每个类型有哪些属性
- 类之间是什么关系(继承、组合)
- 属性有什么约束(数据类型、取值范围)
为什么本体设计很重要?
- 可复用性:定义好的类可以被多个实体共享
- 可扩展性:新增实体类型只需继承已有类
- 推理基础:本体中的约束规则是后续推理的前提
- 语义一致性:避免不同人对同一概念理解不同
知识融合:处理多源知识的冲突
目标:整合来自不同数据源的知识,解决实体重复、属性冲突、数据不一致等问题。
核心挑战:
假设你从两个数据源获取商品信息:
| 数据源 | 商品名称 | 价格 | 库存 |
|---|---|---|---|
| 电商平台 | Apple iPhone 15 Pro Max 256G 深空黑 | 9999元 | 100件 |
| 第三方价格监测 | 15PM黑色大杯 | 10199元 | 120件 |
问题来了:
- 这两条记录是不是同一个商品?(实体对齐)
- 价格不一样,信哪个?(冲突消解)
- 库存也不一样,怎么办?(数据融合)
技术手段:
- 实体对齐:计算字符串相似度、属性相似度、上下文相似度,综合打分判断是否相同实体
- 冲突消解:按数据源可信度加权、按时效性选择、人工审核关键冲突
实体对齐的难点:
- 不同数据源对同一实体的表述差异巨大
- "苹果"可能是水果,也可能是公司
- 需要结合多维特征做综合判断
知识存储:选择合适的"数据库"
目标:把融合后的知识持久化,支持高效查询。
存储方案对比:
| 存储类型 | 代表产品 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 图数据库 | Neo4j, JanusGraph | 复杂关系查询快,直观易用 | 数据导入慢,大规模数据成本高 | 探索式分析、路径查询 |
| 三元组存储 | Jena, Virtuoso | 符合语义Web标准,SPARQL查询 | 学习成本高,复杂查询性能一般 | 语义搜索、标准化应用 |
| 向量数据库 | Pinecone, Milvus | 语义相似度搜索快 | 关系查询能力弱 | 语义检索、推荐系统 |
| 混合存储 | 图+向量 | 兼顾关系和语义 | 架构复杂,维护成本高 | 高端应用、RAG系统 |
技术选型建议:
选择图数据库(如Neo4j):
- 查询模式复杂(如"找所有买了iPhone又买了AirPods的用户")
- 需要频繁做路径分析
- 数据量不是特别大(<1亿节点)
选择向量数据库:
- 主要需求是语义检索
- 需要支持模糊匹配
- 和大模型结合做RAG
知识推理:让知识"活起来"
目标:基于已有知识推断隐含知识,补全缺失信息。
推理类型:
1. 基于规则的逻辑推理
prolog
% 规则定义
is_high_end_phone(X) :-
phone(X),
price(X, P),
P > 5000.2. 基于图结构的推理
已知:
- 用户A 购买过 iPhone
- iPhone 属于 高端手机
- 高端手机 的用户 是 高消费人群
推理:
- 用户A 是 高消费人群3. 基于嵌入的推理(知识图谱嵌入)
使用TransE等嵌入模型,通过向量运算预测缺失关系。
2025年趋势:结合大模型做推理增强。把知识图谱作为外部知识库,让大模型在生成答案时进行事实校验和逻辑推理,这就是RAG架构的核心思路。
知识应用:价值变现的环节
目标:把构建好的知识服务于具体业务场景。
应用场景:
| 场景 | 应用方式 | 例子 |
|---|---|---|
| 智能搜索 | 查询理解和结果排序优化 | 用户搜"续航久的轻薄本",系统理解"续航"、"轻薄"是关键属性 |
| 个性化推荐 | 基于实体关系做协同过滤 | 用户买了iPhone,推荐AirPods(配件关系) |
| 智能问答 | 自然语言转图谱查询 | "苹果公司什么时候成立的?" → 查询(Apple, founded_at) |
| 决策支持 | 基于规则的推理 | "这个用户适合推荐高端手机吗?" → 推理用户画像 |
| Agent智能体 | 知识作为外部工具 | 商品导购Agent调用知识库做推荐 |

四、知识工程和知识图谱的优缺点
| 优势 | 劣势 |
|---|---|
| 知识工程全流程系统化:覆盖从获取到应用的完整生命周期 | 实施复杂度高:需要多学科知识(NLP、数据库、图算法) |
| 知识工程可扩展性强:支持增量更新和持续优化 | 知识获取成本高:尤其非结构化数据需要大量标注 |
| 知识图谱结构化表达:清晰直观,易于理解和维护 | 知识图谱构建门槛高:需要本体设计和数据建模能力 |
| 知识图谱查询效率高:图遍历比多表JOIN快几个数量级 | 知识图谱存储成本高:相比关系数据库占用更多空间 |
| 支持复杂推理:基于规则和图结构做多步推理 | 质量依赖数据源:垃圾进垃圾出,数据质量决定效果 |
| 可解释性强:推理路径可视化,结果易于验证 | 实时更新难:大规模知识图谱的实时更新挑战大 |
五、知识工程的实际应用与发展趋势
实际应用场景
1. 电商商品知识体系
业务背景:某电商平台要构建商品知识体系,支撑智能搜索和推荐。
知识工程实践:
-
知识获取:
- 结构化数据:从ERP系统导入商品基本信息
- 半结构化数据:爬取商品详情页的HTML
- 非结构化数据:从用户评论中抽取产品属性和情感
- 专家知识:类目运营整理的品牌词典、属性定义
-
知识表示:
- 定义本体:商品 → 实物商品/虚拟商品 → 手机/电脑/服装...
- 属性约束:手机有"屏幕尺寸"、"摄像头像素";服装有"尺码"、"材质"
- 关系定义:品牌-生产-商品、商品-属于-类目、商品-配件-商品
-
知识融合:
- 实体对齐:解决"iPhone 15"和"苹果15"的指代问题
- 冲突消解:价格以官方旗舰店为准,库存取各渠道最大值
- 质量评估:人工抽检10%的商品信息,准确率要求>95%
-
知识存储:
- 选择Neo4j图数据库,支持复杂关系查询
- 建立索引:商品名称、品牌、类目等字段加索引
-
知识推理:
- 规则推理:"高端手机"定义为价格>5000且品牌是苹果/华为/三星
- 嵌入推理:用TransE模型预测商品之间的相似度
- 用户画像推理:购买过iPhone的用户标记为"高消费人群"
-
知识应用:
- 智能搜索:用户搜"拍照好的手机",系统理解"拍照"是关键属性
- 个性化推荐:基于用户历史购买和商品关系做推荐
- 智能问答:用户问"华为最新款手机是什么?",查询知识图谱返回Mate 60 Pro
效果:搜索相关性提升30%,推荐点击率提升25%,客服问答准确率提升40%。
2. 医疗知识问答系统
业务背景:某医院要构建医疗知识库,辅助医生诊断和患者咨询。
知识工程实践:
-
知识获取:
- 结构化数据:从医院信息系统导入药品、检查项目、疾病编码
- 非结构化数据:从医学文献、临床指南中抽取疾病-症状-治疗关系
- 专家知识:邀请资深医生审核关键知识
-
知识表示:
- 定义医学本体:疾病、症状、药品、检查项目、科室
- 属性定义:疾病有"发病率"、"易感人群";药品有"适应症"、"副作用"
- 关系定义:疾病-症状-症状、疾病-治疗-药品、药品-禁忌-疾病
-
知识融合:
- 实体对齐:解决"心肌梗死"和"心梗"、"MI"的指代问题
- 冲突消解:不同文献对同一疾病的说法不一致,以权威指南为准
- 质量评估:所有医疗知识必须经过专家审核才能上线
-
知识应用:
- 医生辅助诊断:输入症状,系统推荐可能疾病和检查项目
- 患者智能问答:回答"高血压患者能吃布洛芬吗?"等常见问题
- 用药安全检查:开药时自动检查禁忌症和相互作用
效果:医生诊断效率提升20%,患者咨询自助解决率提升60%,用药错误率降低40%。
3. 企业智能客服系统
业务背景:某企业要构建智能客服知识库,回答常见问题。
知识工程实践:
-
知识获取:
- 结构化数据:从CRM系统导入产品信息、客户信息
- 半结构化数据:从帮助文档、FAQ中提取问答对
- 非结构化数据:从历史客服对话中抽取常见问题和答案
-
知识表示:
- 定义企业本体:产品、客户、订单、服务
- 关系定义:产品-购买-客户、订单-包含-产品、服务-关联-产品
-
知识应用:
- 智能问答:用户问"怎么退货?",查询知识库返回流程说明
- 个性化回复:结合用户订单信息,提供个性化建议
- 多轮对话:基于对话历史,推理用户意图
效果:客服响应速度提升50%,人工客服工作量减少60%,用户满意度提升25%。
4. 金融风控知识体系
业务背景:某金融机构要构建风控知识库,识别潜在风险。
知识工程实践:
-
知识获取:
- 结构化数据:从风控系统导入企业信息、股东信息、财务数据
- 非结构化数据:从新闻、公告中抽取风险事件
- 专家知识:风控专家总结的风险规则
-
知识推理:
- 关联挖掘:发现企业之间的隐藏关联(股东、担保、交易)
- 风险传播:通过关联网络传播风险评分
- 规则预警:根据风险规则自动预警
-
知识应用:
- 风险识别:识别高风险企业和个人
- 授信决策:辅助信贷审批决策
- 监控预警:实时监控风险变化
效果:风险识别准确率提升30%,不良贷款率降低20%,审批效率提升40%。
当前局限性
数据质量和覆盖度的矛盾:
- 问题:追求高质量就要人工审核,但更新跟不上业务变化
- 后果:知识库陈旧,应用效果差
- 解决方案:分层处理,核心知识走严格审核流程,长尾知识允许自动化获取但标注置信度
本体设计过度复杂:
- 问题:一开始就设计非常复杂的本体,包含大量细节
- 后果:开发周期长,难以维护,实际应用用不到
- 解决方案:遵循"最小可行本体"原则,根据应用需求逐步扩展
知识更新机制不完善:
- 问题:知识库构建完就不管了,数据逐渐过时
- 后果:应用效果越来越差,最终被废弃
- 解决方案:建立知识更新流程,定期检查和更新过期知识
发展与演进
知识工程的范式转变:
知识工程正在经历三个重要转变:
1. 从人工到自动
- 过去:靠专家访谈、人工编码规则
- 现在:用NLP模型自动抽取知识
- 未来:大模型做端到端的知识获取
2. 从静态到动态
- 过去:知识库构建完就不变了
- 现在:定期更新,增量维护
- 未来:实时更新,持续学习
3. 从孤立到融合
- 过去:知识工程和机器学习是两套体系
- 现在:开始结合(如RAG)
- 未来:深度融合,知识驱动+数据驱动统一
2025年的技术趋势:
大模型+知识图谱的深度结合:
传统的RAG是"检索+生成",现在发展为"检索+推理+生成":
用户问题 → 大模型理解意图 → 知识图谱检索相关实体和关系
↓
大模型基于检索结果+推理规则生成答案
↓
知识图谱做事实校验 → 返回最终答案优势:
- 大模型负责语义理解和流畅表达
- 知识图谱保证事实准确性和可追溯性
- 推理规则增强逻辑严谨性
知识工程的MLOps化:
知识工程正在借鉴机器学习的MLOps理念:
- 知识版本控制:用Git管理本体定义,追踪知识变更
- 知识质量监控:建立自动化测试,检测知识冲突和错误
- 知识持续集成:新知识上线前自动验证质量
- 知识A/B测试:对比不同知识版本对应用效果的影响
多智能体协作中的知识共享:
在多Agent系统中,知识工程要解决:
- 共享知识库:多个Agent如何访问和更新同一知识库
- 知识同步:Agent本地缓存和中心知识库的一致性
- 知识权限:不同Agent能看到的知识范围不同
六、总结与思考
知识图谱和知识工程的本质区别在于:知识图谱是知识的"容器",解决的是"用什么格式存储知识"的问题;而知识工程是一套完整的方法论和工程体系,解决的是"如何从零开始构建一个完整的知识智能系统"的问题。知识工程包含知识获取、知识表示、知识融合、知识存储、知识推理、知识应用等全流程,是一个迭代优化的闭环系统。
总结:知识工程的核心不是技术,而是如何让知识真正创造价值。技术只是工具,理解业务需求、设计合理的知识模型、建立可持续的更新机制,才是知识工程成功的关键。
思考:知识的价值不在于它的数量,而在于它能否被有效利用。知识工程的真正挑战不是如何存储更多的知识,而是如何让知识在正确的时间、以正确的方式、传递给正确的人。当机器不仅能记住知识,还能理解知识之间的关联,我们才能真正实现从"数据驱动"到"知识驱动"的跨越,让人工智能从感知智能走向认知智能。