****论文题目:****A triple domain adversarial neural network for bearing fault diagnosis(用于轴承故障诊断的三域对抗神经网络)
****期刊:****Mechanical Systems and Signal Processing
****摘要:****在实际生产中,旋转机械经常在不同的工况下运行,这使得基于传统深度学习模型的轴承故障诊断难以保证较高的准确性。为了提高滚动轴承在不同工况下故障诊断的有效性,提出了一种具有多尺度特征提取器、三分类器和自适应反向传播系数的三域对抗神经网络。具体来说,设计了一个由源分类器、目标分类器和领域分类器组成的三重分类器来实现分类损失。同时,提出了一种包含卷积模块和自注意力机制模块的多尺度特征提取器,用于样本转移和特征提取。此外,为了提高训练效果,还引入了一种可根据分布差改变其数值的自适应反向传播系数。因此,将多尺度特征提取器、三重分类器和自适应反向传播系数相结合,形成了一种有效的用于不同运行工况下轴承故障诊断的迁移学习模型,称为TDANN。最后,利用凯斯西储大学的CWRU轴承故障数据集和我们实验室PT500mini轴承故障试验台的PT轴承数据集验证了所提出的TDANN模型的可行性和有效性。在不同的噪声环境下,与其他智能模型相比,该模型具有更高的传递精度和更好的传递能力。
面向跨域轴承故障诊断的三重域对抗神经网络:TDANN 详解
一、背景:为什么轴承故障诊断在实际工业中这么难?
旋转机械(风力发电机、工业生产线等)的健康状态很大程度上取决于滚动轴承的运行状况。一旦轴承在高速运转中发生故障,轻则降低生产效率,重则引发严重安全事故。因此,准确、及时地识别轴承故障状态,是设备维护和生产安全的核心需求。
近年来,深度学习 在轴承故障诊断领域取得了显著进展。卷积神经网络(CNN)等模型能够自动提取振动信号中的有效特征,无需繁琐的人工特征工程。然而,这类方法都有一个隐含的前提假设:训练数据和测试数据来自相同的分布。
这个假设在实验室中很容易满足,但在真实工业场景中却几乎不成立。
论文作者指出了三个具体问题:
问题 1:跨数据集迁移极其困难
现实中,一台机器的振动数据往往与另一台在传感器类型、安装位置、机器配置上都存在巨大差异。即使是同一类型的轴承,在不同工况(负载、转速)下采集到的信号也服从不同的概率分布。
论文用一个清晰的实验数据说明了这一问题:将一个标准 CNN 模型直接从 CWRU 数据集迁移到 PT 数据集(两者均为轴承故障数据集,但采集设备、采样频率和工况均不同),平均诊断准确率仅有 22.18%。这与随机猜测(4类的话约 25%)相差无几,足以说明跨数据集的分布差异之大。
问题 2:目标域有标注样本被浪费了
现有的迁移学习方法(如经典的 DANN)主要关注边缘分布对齐 ------让源域和目标域的特征分布在整体上尽量接近。但在实际场景中,目标域通常存在少量有标注样本,这些宝贵的监督信息并未被有效利用,条件分布的对齐(即不同类别之间的边界对齐)因此被忽视了。
问题 3:固定反传系数限制了对抗训练的效果
对抗迁移学习中,反传系数 λ 控制着特征提取器在梯度反转时受到的"对抗强度"。传统方法将 λ 设为一个固定值,但随着训练进行,源域与目标域的特征分布差异是动态变化的------固定的 λ 无法跟上这种变化,导致训练不稳定或对抗强度不足。
二、方法:TDANN 的三大创新模块
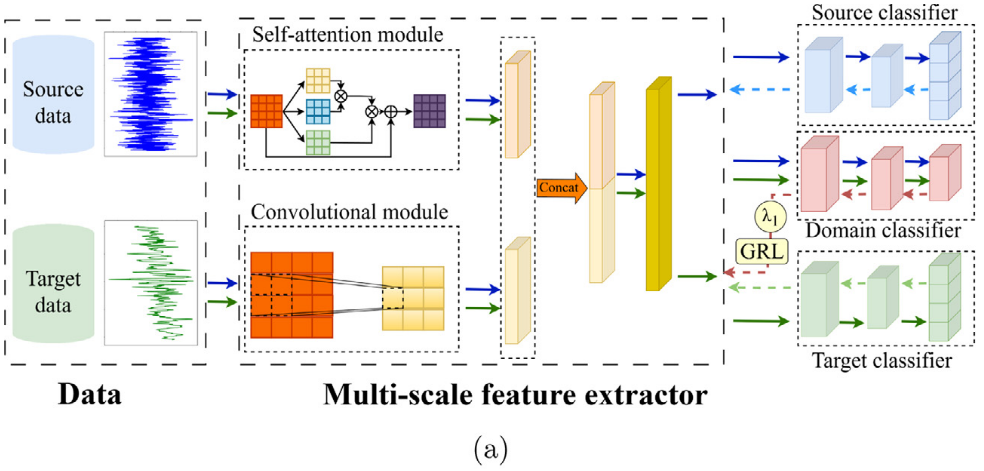
针对上述三个问题,论文提出了 TDANN(Triple Domain Adversarial Neural Network),由三个核心模块组成,结构如下所示。
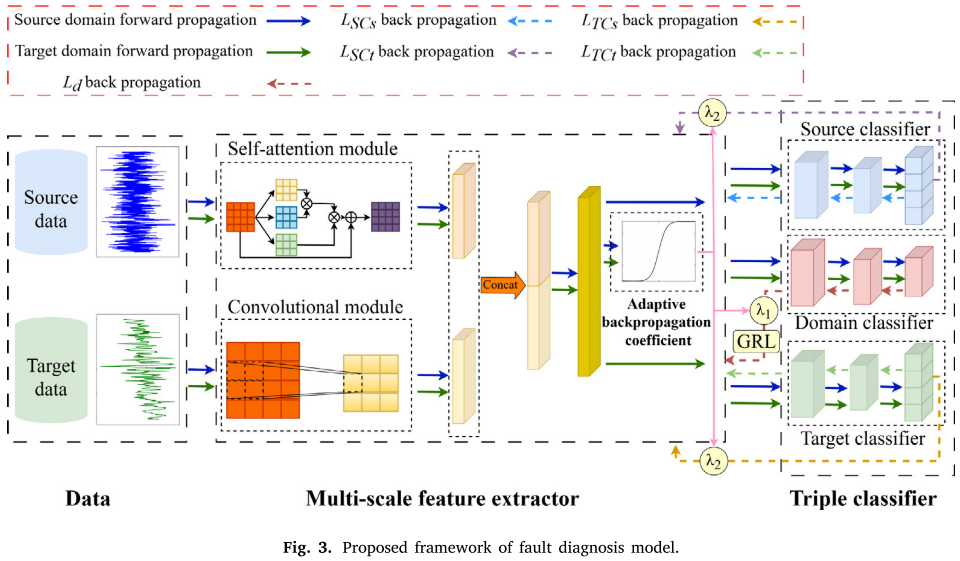
📌 此处配图:Fig. 3(论文框架图,Proposed framework of fault diagnosis model)
三个模块分别对应三个问题,下面逐一介绍。
2.1 多尺度特征提取器(Multi-Scale Feature Extractor)
对应问题: 如何提取更具迁移能力的特征,减小不同数据集之间的分布差异?
核心思路: 用卷积模块捕捉局部特征,用自注意力模块捕捉全局特征,最后由全连接层融合两者。
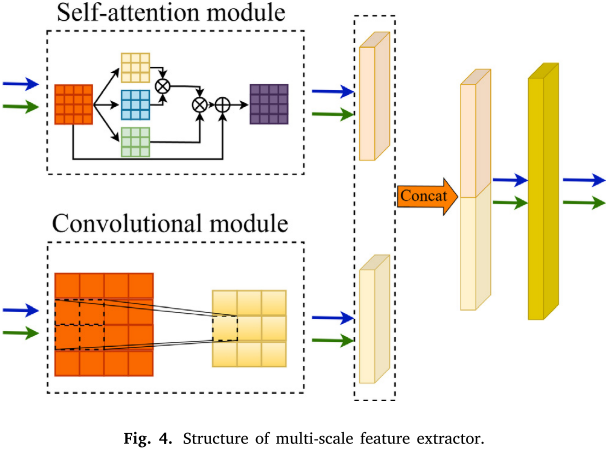
📌 此处配图:Fig. 4(多尺度特征提取器结构图,Structure of multi-scale feature extractor)
卷积模块(提取局部特征)
CNN 具有局部连接、参数共享和层次抽象等优良特性,擅长聚焦信号中的局部故障特征(如冲击脉冲)。论文中卷积模块的具体结构如下:
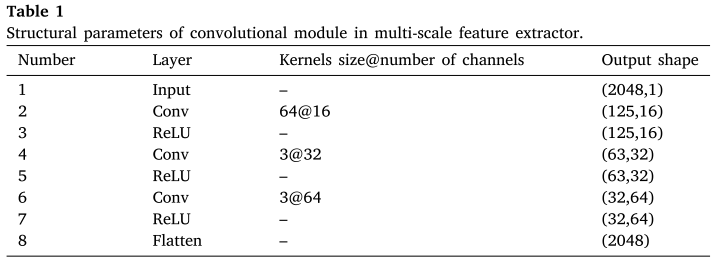
📌 此处配表:Table 1(卷积模块结构参数,Structural parameters of convolutional module)
卷积模块使用大核(kernel size = 64)第一层卷积,以大感受野优先提取宽范围局部特征,随后经过两个小核(3×1)卷积层逐步压缩,最终 Flatten 为 2048 维向量。
自注意力模块(提取全局特征)
自注意力能够基于序列中所有位置之间的相关性输出结果,具有极大的感受野,适合提取信号的全局依赖信息(如整体频率成分)。
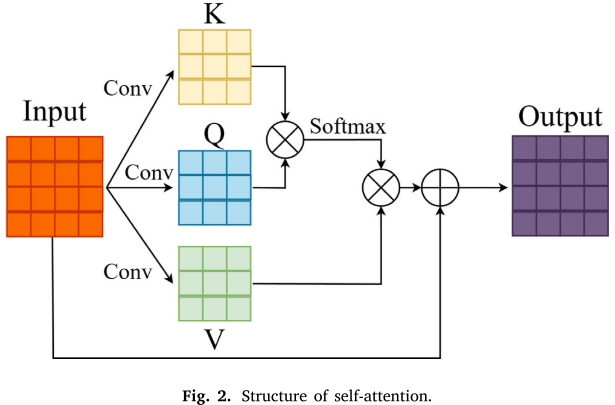
📌 此处配图:Fig. 2(自注意力结构,Structure of self-attention)
其数学形式为(论文公式 6):
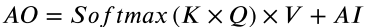
其中 K、Q、V 分别由三个独立的卷积层生成,AI 为残差输入,AO 为输出。这种带残差的设计保证了梯度的稳定传播。
融合
两个模块的输出经 Concat 操作拼接后,送入一个全连接层赋予不同权重进行融合,最终输出 4096 维的多尺度特征向量。
为什么需要"多尺度"? 单独依赖卷积模块可能忽略全局频率信息,单独依赖自注意力则可能忽略局部冲击脉冲。两者互补,才能提取出对迁移学习更友好的域不变特征。
2.2 三分类器(Triple Classifier)
对应问题: 如何同时对齐边缘分布和条件分布,并充分利用目标域有标注样本?
核心思路: 设计三个分类器(源分类器、目标分类器、域分类器),分别从不同角度监督特征提取器的对齐过程。
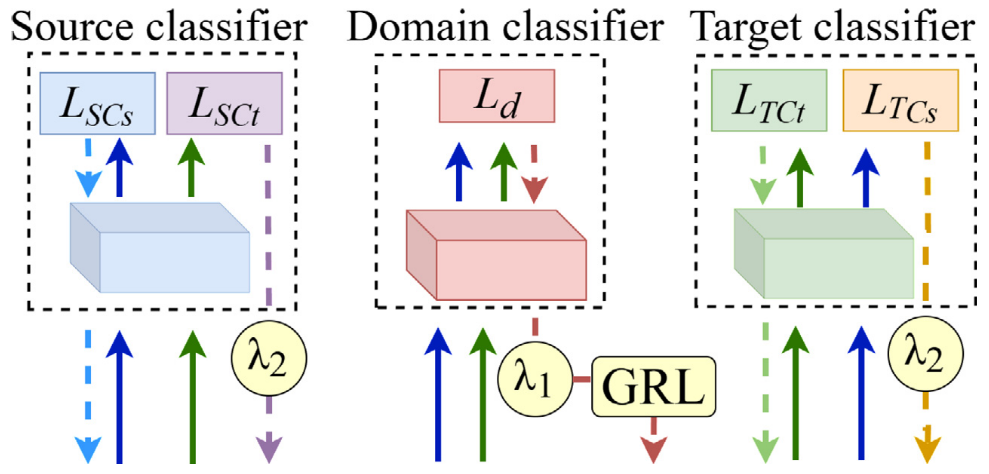
📌 此处配图:Fig. 5(三分类器结构图,Structure of triple classifier)
三个分类器的结构参数如下:
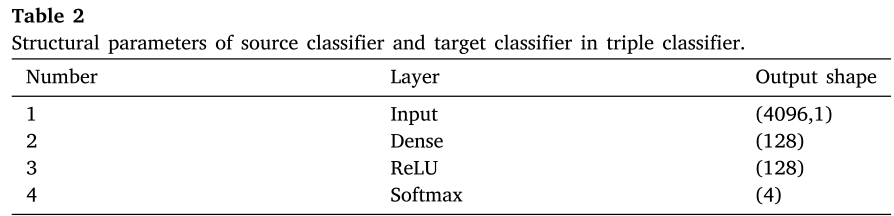

📌 此处配表:Table 2(源/目标分类器结构参数) Table 3(域分类器结构参数)
源分类器(Source Classifier)
源分类器在有标注的源域数据上训练,产生两个损失信号:
- L_SCs(公式 8):源分类器对源域特征的分类损失 → 保证源域分类准确。
- L_SCt(公式 9):源分类器对目标域特征的分类损失 → 反映迁移效果。当源域和目标域特征分布相近时,L_SCt 较小;反之较大。
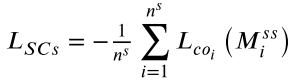
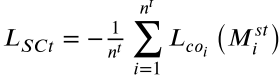
目标分类器(Target Classifier)
目标分类器利用少量有标注目标域样本 训练,产生两个损失信号: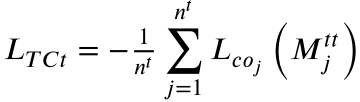
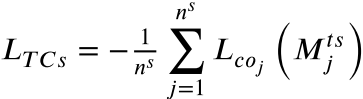
- L_TCt(公式 10):目标分类器对目标域特征的分类损失 → 保证目标域的分类边界准确。
- L_TCs(公式 11):目标分类器对源域特征的分类损失 → 与 L_SCt 对称,共同衡量迁移能力。
源分类器和目标分类器形成互补的条件分布对齐机制:源分类器从源域向目标域"推",目标分类器从目标域向源域"拉",双向驱动特征提取器学习对两个域都有效的条件分布表示。
域分类器(Domain Classifier)
域分类器通过梯度反转层(GRL) 与特征提取器形成对抗关系。其特殊之处在于:用 Wasserstein 距离代替交叉熵作为损失函数(论文公式 12):
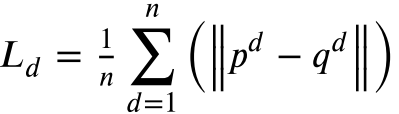
其中 pd 为域分类器对第 d 个样本的预测概率,qd 为真实域标签,|.|为 L1 范数。
相比于交叉熵损失,Wasserstein 距离能更稳定地量化两个概率分布之间的差异(即边缘分布对齐),尤其在分布差异较大时不容易发生梯度消失。
特征提取器的总更新损失
三个分类器的损失最终按照 Algorithm 1 Step 14 合并,用于更新特征提取器的参数:
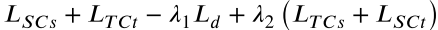
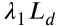 :通过 GRL 对抗域分类器,实现边缘分布对齐。
:通过 GRL 对抗域分类器,实现边缘分布对齐。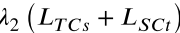 :利用交叉分类损失,实现条件分布对齐。
:利用交叉分类损失,实现条件分布对齐。
2.3 自适应反传系数(Adaptive Backpropagation Coefficient)
对应问题: 如何让对抗训练过程随分布差异动态调整,避免固定系数的局限性?
核心思路: 用源域和目标域特征的 L1 距离(近似 Wasserstein 距离)实时衡量当前分布差异,通过 tanh 函数将其映射到一个有界区间,作为动态系数。
论文公式(13)定义了两个自适应系数:
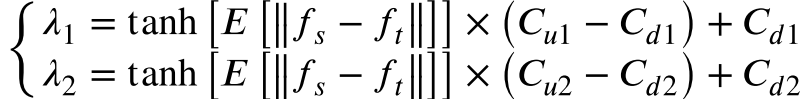
- λ1 控制 GRL 的梯度反转强度(边缘分布对齐的力度)。
- λ2 控制条件分布对齐损失的权重。
- 超参数由消融实验确定:C{u1}=1.25,C{d1}=0.09, C{u2}=0.9, C{d2}=0.125。
工作机制:
- 训练初期,两域特征分布差异大 →
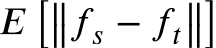 大 → tanh 趋近 1 → λ 趋近上限 → 对抗强度增大,加速对齐。
大 → tanh 趋近 1 → λ 趋近上限 → 对抗强度增大,加速对齐。 - 训练后期,分布差异逐渐缩小 → λ 趋近下限 → 对抗强度减弱,稳定收敛,避免过度对抗。
与固定系数相比,自适应系数使特征提取器和域分类器之间的对抗关系更加平稳,提升了训练效果和迁移性能。
三、训练算法
TDANN 的完整训练逻辑见 Algorithm 1:

📌 此处配图:Algorithm 1(TDANN 训练伪代码)
训练流程概括如下:
- 将源域和目标域数据同时送入多尺度特征提取器,分别得到特征向量 fs 和 ft。
- 根据公式(13)计算当前的自适应系数 λ1 和 λ2,更新 GRL 的梯度反转强度。
- 特征经过 GRL 送入域分类器,计算 Ld。
- 源域特征分别送入源分类器和目标分类器,计算$L{SCs} 和 L{TCs}。
- 目标域特征分别送入源分类器和目标分类器,计算 L{SCt} 和 L{TCt}。
- 用 Ld 更新域分类器参数;用 L{SCs} 和 L{TCt} 更新源/目标分类器参数。
- 用合并损失 ,更新多尺度特征提取器参数。
- 重复至收敛。
优化器使用 Adam,与经典 DANN 的训练范式保持一致。
四、实验设置
数据集
论文使用两个数据集搭建跨域迁移实验:
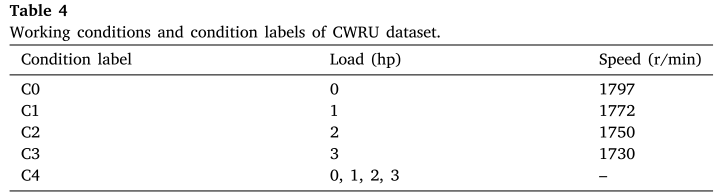
源域:CWRU 轴承故障数据集
- 美国凯斯西储大学提供的标准轴承故障基准数据集。
- 轴承型号:SKF6205 深沟球轴承;故障部位:滚珠、内圈、外圈。
- 采样频率:12 kHz;四种负载工况:0、1、2、3 hp。
- 工况标签如下:
📌 此处配表:Table 4(CWRU 数据集工况标签)
目标域:PT 轴承故障数据集(实验室自采)
- 来自 PT500mini 轴承故障试验台,包含背景噪声,更贴近真实工业场景。
- 轴承型号:PH205;故障宽度:0.3 mm;采样频率:48 kHz。
- 四种转速:500、1000、1500、2000 r/min。
- 工况标签如下:

📌 此处配表:Table 5(PT 数据集工况标签)
两个数据集均包含四类状态:正常(Normal)、内圈故障(Inner Race)、滚珠故障(Ball)、外圈故障(Outer Race)。数据划分如下:
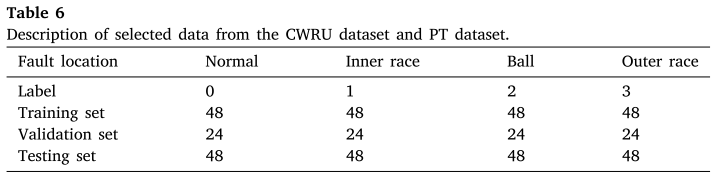
📌 此处配表:Table 6(实验数据集标签及划分)
对比方法
实验共设置 7 个对比模型:CNN、DANN、DMTL、LS-CNN+ETL,以及三个 TDANN 的消融变体------TDANN-M、TDANN-L、TDANN-AL。
三个消融变体的含义:
- TDANN-M:仅保留多尺度特征提取器,去掉三分类器和自适应系数(固定 λ1=0.1)。
- TDANN-L:仅保留三分类器和自适应系数,将多尺度特征提取器替换为普通卷积提取器。
- TDANN-AL:保留三分类器和自适应系数,去掉自注意力模块(只有卷积模块)。
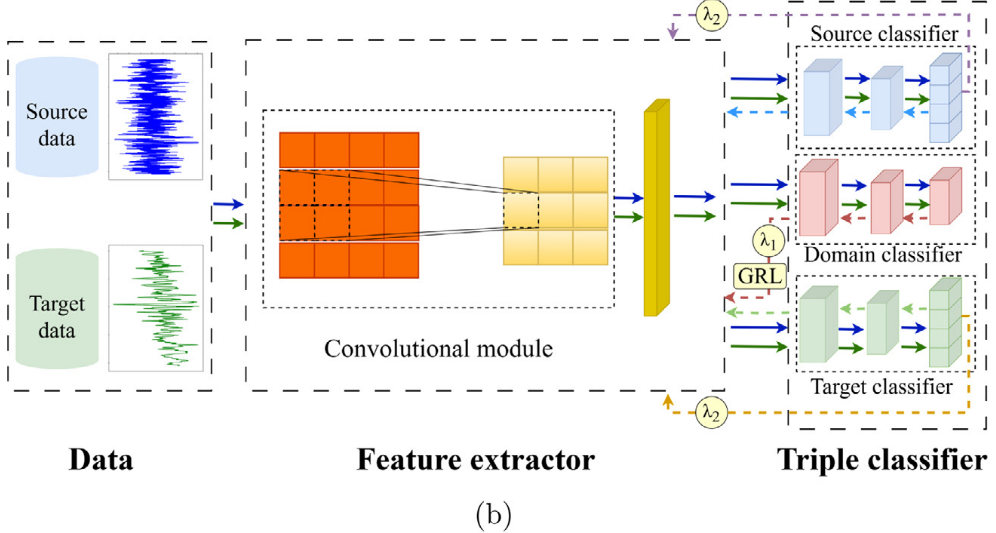
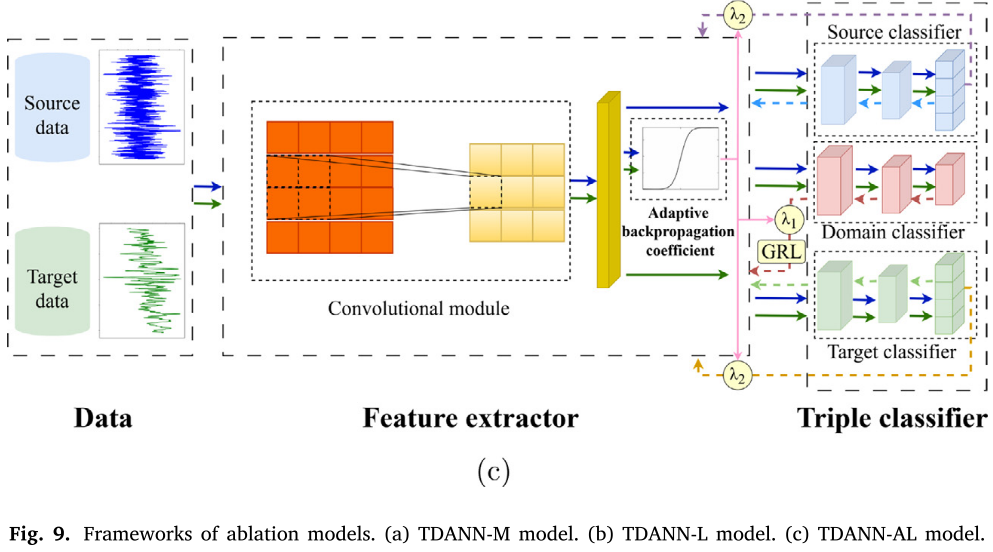
📌 此处配图:Fig. 9(消融模型结构图)
五、实验结果
5.1 跨工况诊断实验
16 个迁移任务(C0~C3 分别迁移至 N0~N3),每组实验重复 10 次取均值。
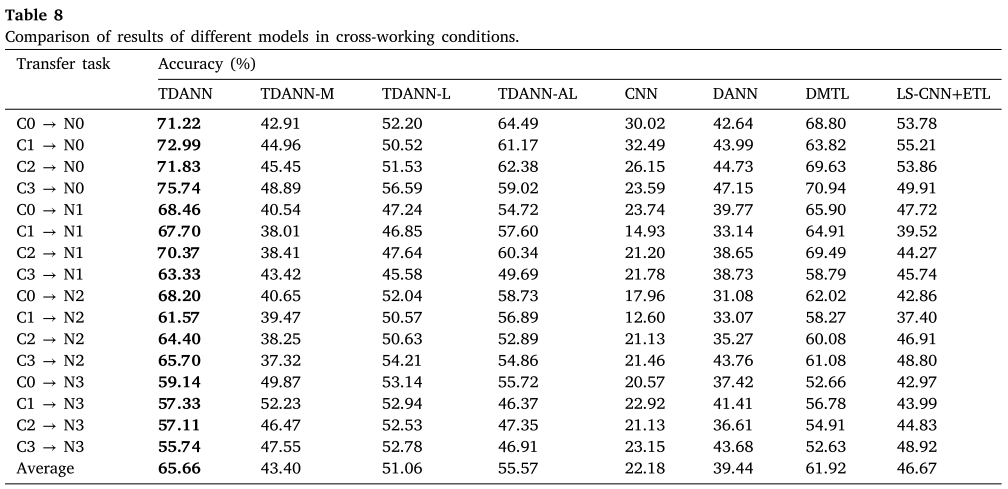
📌 此处配表:Table 8(不同模型在跨工况条件下的准确率对比)

📌 此处配图:Fig. 10(不同模型在不同迁移任务下的雷达图对比)
核心结论:
- TDANN 平均准确率 65.66%,在全部 16 个任务中均排名第一。
- 基础 CNN 直接迁移平均仅 22.18%,印证了跨数据集分布差异的严重性。
- 经典 DANN 平均 39.44%,引入对抗训练后有所提升,但仍与 TDANN 差距显著。
- 最优对比方法 DMTL 平均 61.92%,TDANN 超出约 3.74 个百分点。
- 注意到 C→N3(转速最高)的任务普遍最难,TDANN 在该组平均仍达 57.33%。
5.2 噪声环境下的诊断实验
向 CWRU 和 PT 数据集同时叠加高斯噪声(SNR = −4 dB 至 +2 dB),迁移任务选取 C4→N1(源域使用全部四种负载工况混合训练)。
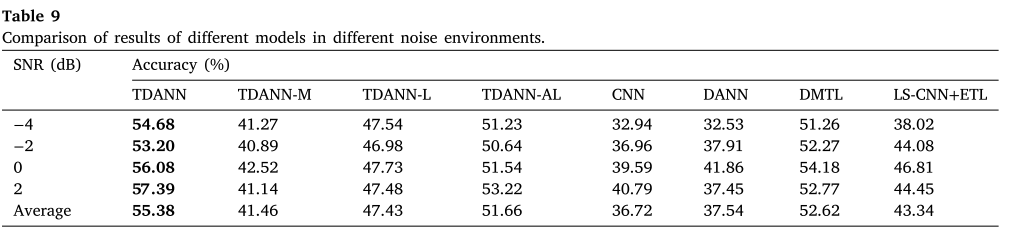
📌 此处配表:Table 9(不同模型在不同噪声环境下的准确率对比)
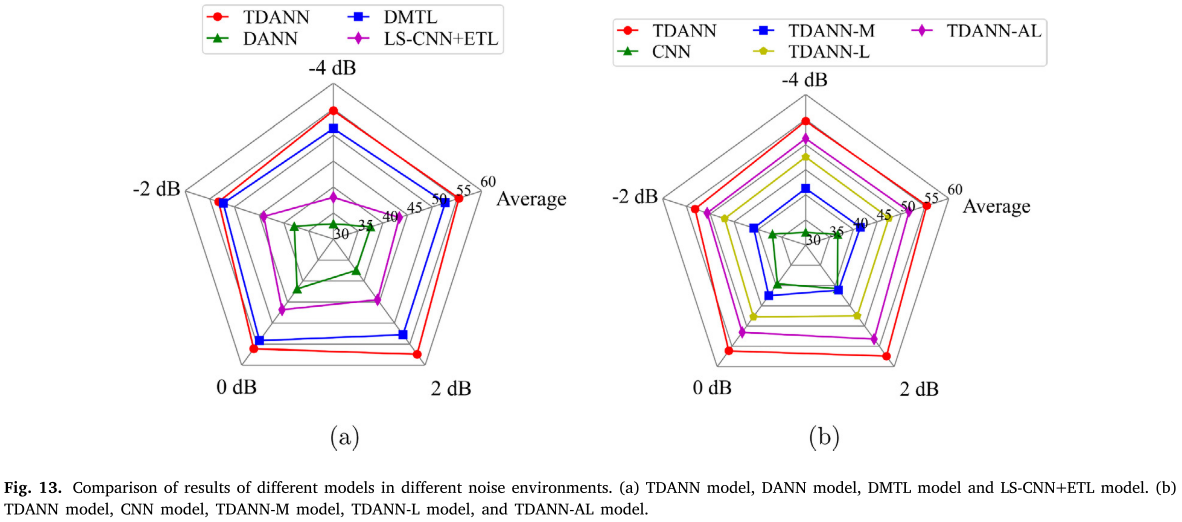
📌 此处配图:Fig. 13(不同模型在不同噪声环境下的雷达图对比)
核心结论:
- TDANN 在各 SNR 下均优于所有对比模型,平均准确率 55.38%。
- 最难条件(SNR = −4 dB)下,TDANN 仍达 54.68%,而 DANN 仅 32.53%。
- 噪声叠加后所有模型准确率有所下降,但 TDANN 的下降幅度最小,体现了较强的噪声鲁棒性。
5.3 消融实验分析
| 模型 | 平均准确率 (%) | 对比 TDANN 差距 |
|---|---|---|
| TDANN | 65.66 | --- |
| TDANN-AL(无多尺度提取器) | 55.57 | −10.09 |
| TDANN-L(无自适应系数) | 51.06 | −14.60 |
| TDANN-M(仅多尺度提取器) | 43.40 | −22.26 |
消融结果清楚地揭示了三个模块各自的贡献:
- 去掉三分类器(TDANN-M 对比 TDANN-AL):准确率从 55.57% 降至 43.40%,三分类器贡献最大。
- 去掉多尺度提取器(TDANN-L 对比 TDANN):准确率从 65.66% 降至 51.06%,说明多尺度提取是关键。
- 去掉自适应系数(TDANN-L 对比 TDANN-AL):准确率从 55.57% 降至 51.06%,自适应系数亦有明显贡献。
5.4 特征可视化(t-SNE)
论文使用 t-SNE 对迁移前后的特征分布进行可视化对比,直观展示 TDANN 的迁移效果。
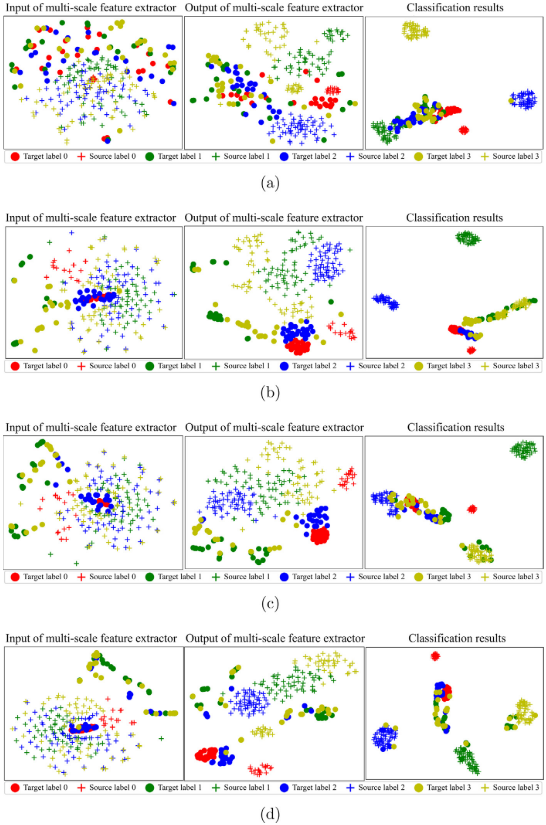
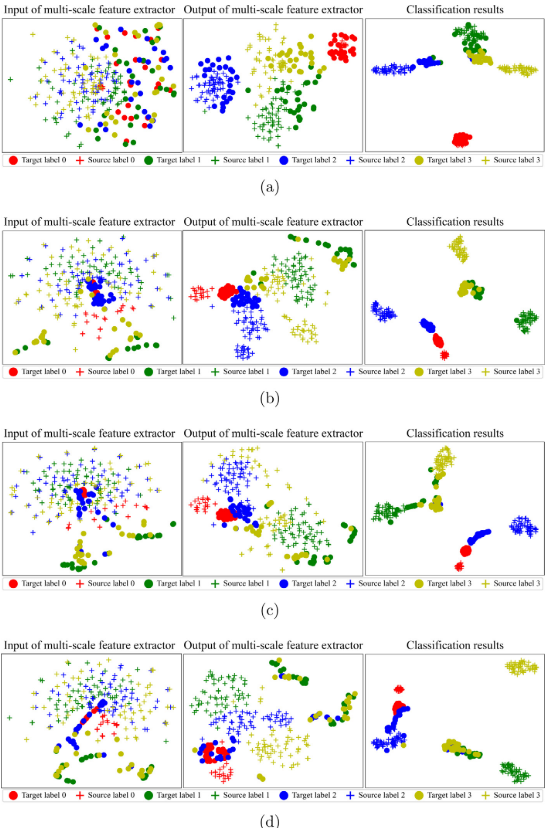
Fig. 11(DANN 模型在不同迁移任务下的 t-SNE 可视化)
Fig. 12(TDANN 模型在不同迁移任务下的 t-SNE 可视化)
从可视化结果可以看出:迁移前,源域("+"符号)和目标域("·"符号)的同类样本高度混杂;经 TDANN 的多尺度特征提取器转换后,相同标签的源域和目标域样本聚集得更为紧密,分类边界更加清晰。
六、论文的局限性与未来方向
论文在结论部分坦率地指出了 TDANN 的三点局限:
- 标签空间不匹配问题。 当源域和目标域的故障类别不完全重叠时,可能发生负迁移。
- 超参数调优负担。 自适应系数中的 Cu、Cd 四个边界值需要针对具体应用场景调优,在新场景下泛化性尚未得到充分验证。
- 泛化范围有限。 TDANN 目前仅在轴承数据集上验证,对其他类型旋转机械或非机械系统的适用性有待探索。
未来工作将着眼于:开发标签空间对齐机制处理故障类别不一致问题;引入自动超参数调优策略;将模型推广至更广泛的机械设备和故障场景。
七、总结
TDANN 是一个面向跨域、跨工况轴承故障诊断的迁移学习框架,其核心贡献在于:
| 创新模块 | 解决的核心问题 | 关键机制 |
|---|---|---|
| 多尺度特征提取器 | 特征提取能力不足,分布差异难以缩小 | 卷积(局部)+ 自注意力(全局)并行提取,全连接融合 |
| 三分类器 | 仅对齐边缘分布,条件分布和标注信息未充分利用 | 源/目标分类器对齐条件分布 + 域分类器(Wasserstein)对齐边缘分布 |
| 自适应反传系数 | 固定 λ 导致训练不稳定 | 基于特征 L1 距离动态计算 λ1 和 λ2,训练自适应调节对抗强度 |
在严格的跨数据集迁移实验中,TDANN 在 16 个跨工况任务上达到平均 65.66% 的诊断准确率,在 −4 dB 到 +2 dB 的噪声环境下保持平均 55.38% 的准确率,均优于所有对比基线方法,验证了三个创新模块的有效性和互补性。