摘要
作为 Flink 实时开发的核心基础,Window、Time+Watermark、State、Checkpoint 被称为 Flink 的四大基石。掌握这四大核心知识,是从 Flink 基础使用走向实战开发的关键,本文将从核心概念、解决问题、高频 API、极简 Demo四个维度做体系化整理,打造一份可直接用于开发查阅的速查手册,所有案例均基于 Flink DataStream API 实现,保证简洁、可运行、易复用。
一、Window:流到批的桥梁
流处理的核心是处理无界流 ,而实际业务中需要对无界流做分段统计 (如每分钟订单量、每 5 秒接口请求数),Window 就是实现流到批切分 的核心组件,是 Flink 实现聚合计算的基础。
1. Window 解决的核心问题
- 将无界连续的数据流 ,按照指定的时间 / 数据量规则 切分为有界的数据集
- 仅对每个有界数据集做聚合计算,实现流处理中的批量统计
- 解决无界流无法直接做聚合的核心痛点
2. 核心窗口分类:滚动窗口、滑动窗口
|-----------------------|----------------------------|-------------------------------------|------------------------------------------------------|
| 窗口类型 | 核心区别 | 核心参数 | 典型应用场景 |
| 滚动窗口(Tumbling Window) | 窗口之间无重叠、无间隔 ,数据仅属于一个窗口 | 窗口大小(window size) | 固定周期的独立统计(如每分钟 UV、每小时订单总额) |
| 滑动窗口(Sliding Window) | 窗口之间有重叠 ,数据可属于多个窗口 | 窗口大小(window size)+ 滑动步长(slide step) | 高频连续统计(如每 5 秒统计最近 30 秒的接口 QPS、每 1 分钟统计最近 5 分钟的商品点击量) |
极简 Demo:滚动窗口 + 滑动窗口基础使用
java
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class WindowBasicDemo {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. 构造测试数据:模拟实时数字流
DataStream<Integer> dataStream = env.socketTextStream("localhost", 9999)
.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String s) throws Exception {
return Integer.parseInt(s);
}
});
// 3. 滚动窗口:每10秒统计一次求和(无重叠)
DataStream<Integer> tumblingWindowStream = dataStream
.keyBy(x -> x % 2) // 按奇偶分区
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.sum(0);
// 4. 滑动窗口:每5秒统计最近10秒的求和(有重叠)
DataStream<Integer> slidingWindowStream = dataStream
.keyBy(x -> x % 2) // 按奇偶分区
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.sum(0);
// 5. 打印结果
tumblingWindowStream.print("滚动窗口结果:");
slidingWindowStream.print("滑动窗口结果:");
// 6. 执行任务
env.execute("Window Basic Demo");
}
}3. Window Function 窗口函数
窗口函数是窗口内数据的计算逻辑 ,即切分后的有界数据集如何做聚合,核心分为增量聚合函数 和全量聚合函数 ,是开发中必用的核心函数,高频 API 及特性整理如下:
|----------|-------------------------------------|------------------------|--------------------------|----------------------------------------------------------------------------------------|
| 函数类型 | 核心特性 | 优点 | 缺点 | 高频实现类 / API |
| 增量聚合函数 | 数据逐条进入 窗口时,实时更新聚合结果,窗口触发时直接输出结果 | 内存占用低、性能高,适合大数据量场景 | 无法获取窗口的元数据(如窗口开始 / 结束时间) | SumFunction/sum() MaxFunction/max() MinFunction/min() ReduceFunction AggregateFunction |
| 全量聚合函数 | 数据全部进入 窗口后,统一做聚合计算,窗口触发时输出结果 | 可获取窗口完整元数据、全量数据,支持复杂计算 | 内存占用高,需缓存窗口内所有数据 | ProcessWindowFunction(最通用) |
极简 Demo:增量聚合(ReduceFunction)+ 全量聚合(ProcessWindowFunction)
java
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class WindowFunctionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 构造测试数据
DataStream<Integer> dataStream = env.socketTextStream("localhost", 9999)
.map(Integer::parseInt);
// 1. 增量聚合:ReduceFunction 实现累加
DataStream<Integer> reduceStream = dataStream
.keyBy(x -> x % 2)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
});
// 2. 全量聚合:ProcessWindowFunction 实现求和(可获取窗口时间)
DataStream<String> processStream = dataStream
.keyBy(x -> x % 2)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<Integer, String, Integer, TimeWindow>() {
@Override
public void process(Integer key, Context context, Iterable<Integer> elements, Collector<String> out) throws Exception {
// 获取窗口元数据:开始/结束时间
long windowStart = context.window().getStart();
long windowEnd = context.window().getEnd();
// 全量数据求和
int sum = 0;
for (Integer e : elements) {
sum += e;
}
// 输出结果:key + 窗口时间 + 求和结果
out.collect("key:" + key + ",窗口开始:" + windowStart + ",窗口结束:" + windowEnd + ",求和结果:" + sum);
}
});
reduceStream.print("增量聚合(Reduce):");
processStream.print("全量聚合(Process):");
env.execute("Window Function Demo");
}
}二、Time + Watermark:解决流处理的乱序问题
Flink 的窗口计算依赖时间 触发,而实时数据流中存在数据乱序 (如数据产生时间是 10:00,到达 Flink 的时间是 10:05),如果直接按系统时间计算,会导致统计结果不准确。Time(时间语义) 定义了 Flink 的时间计算标准,Watermark(水位线) 是解决乱序数据的核心方案,两者结合是 Flink 实现精准实时计算的基础。
1. Time 三大时间语义
Flink 提供三种时间语义,开发中Event Time 是使用频率最高、最贴合业务实际的,三者核心区别通过表格整理,明确适用场景:
|-----------------------|------------------------------------------|------------------|--------------------------------------|------------------------------|--------------------------------------------|
| 时间语义 | 定义 | 计算依据 | 优点 | 缺点 | 适用场景 |
| 处理时间(Processing Time) | 数据到达 Flink 算子 的系统时间 | 算子所在机器的本地时间 | 无需额外配置、计算简单、性能最高 | 受网络延迟、机器时钟影响,统计结果不准确 | 对实时性要求极高、对准确性要求较低的场景(如临时监控、粗略统计) |
| 事件时间(Event Time) | 数据产生的时间 (由数据生产者携带,如日志的 timestamp 字段) | 数据本身的时间戳 | 贴合业务实际,统计结果精准,不受传输延迟影响 | 需要指定时间戳提取规则、配置 Watermark,略复杂 | 绝大多数业务场景(如订单统计、用户行为分析、商品点击量统计) |
| 摄入时间(Ingestion Time) | 数据进入 Flink 数据源 的时间 | Flink 数据源节点的系统时间 | 比 Processing Time 准确,比 Event Time 简单 | 仍受 Flink 内部处理延迟影响 | 无需精准事件时间、但需要比 Processing Time 更准确的场景(极少使用) |
核心结论 :实际开发中,优先使用 Event Time ,搭配 Watermark 解决乱序问题,是 Flink 实时计算的标准配置。
2. Event Time 的核心重要性
- 贴合业务实际 :统计的是数据实际产生 的时间维度,而非 Flink 处理的时间维度,结果更有业务价值;
- 解耦数据传输 与计算 :不受网络延迟、节点处理速度影响,即使数据乱序到达,也能精准统计;
- 支持数据回溯 :基于数据本身的时间戳,可重新计算历史时间段的结果,适合故障恢复、数据补算。
3. Watermark 核心概念
(1)Watermark 是什么?
Watermark(水位线)是Event Time 下的一种特殊的数据流标记 ,本质是一个时间戳 ,格式为Watermark(t),表示所有事件时间小于等于 t 的数据已经全部到达 Flink 。
(2)为什么需要 Watermark?
实时数据流中存在数据乱序 和数据延迟 ,如果直接按事件时间触发窗口,会出现 "窗口已触发,后续仍有该窗口的数到达" 的情况,导致统计结果缺失。Watermark 的核心作用是告诉 Flink 一个时间阈值 ,当 Watermark 到达窗口结束时间时,才触发窗口计算,从而兼容一定程度的乱序和延迟。
4. Watermark 解决的问题及实现原理
(1)解决的核心问题
- 处理Event Time 下的数据乱序,保证窗口计算的完整性 ;
- 定义数据延迟的容忍度 ,平衡计算的精准性 和实时性 ;
- 触发窗口的最终计算 ,避免因少量延迟数据导致窗口一直不触发。
(2)核心实现原理
- 从数据流中提取事件时间戳 ,为每条数据打上 Event Time;
- Flink 根据指定的水印生成策略 ,实时生成 Watermark(如 "允许数据延迟 3 秒",则 Watermark = 当前最大事件时间 - 3 秒);
- Watermark随着数据流 在算子间传递,是全局的时间标记;
- 当 Watermark 的时间戳大于等于窗口的结束时间 时,触发该窗口的聚合计算;
- 对于 Watermark 触发后到达的超延迟数据 ,可通过侧输出流(Side Output) 收集,避免数据丢失。
(3)Watermark 时序图
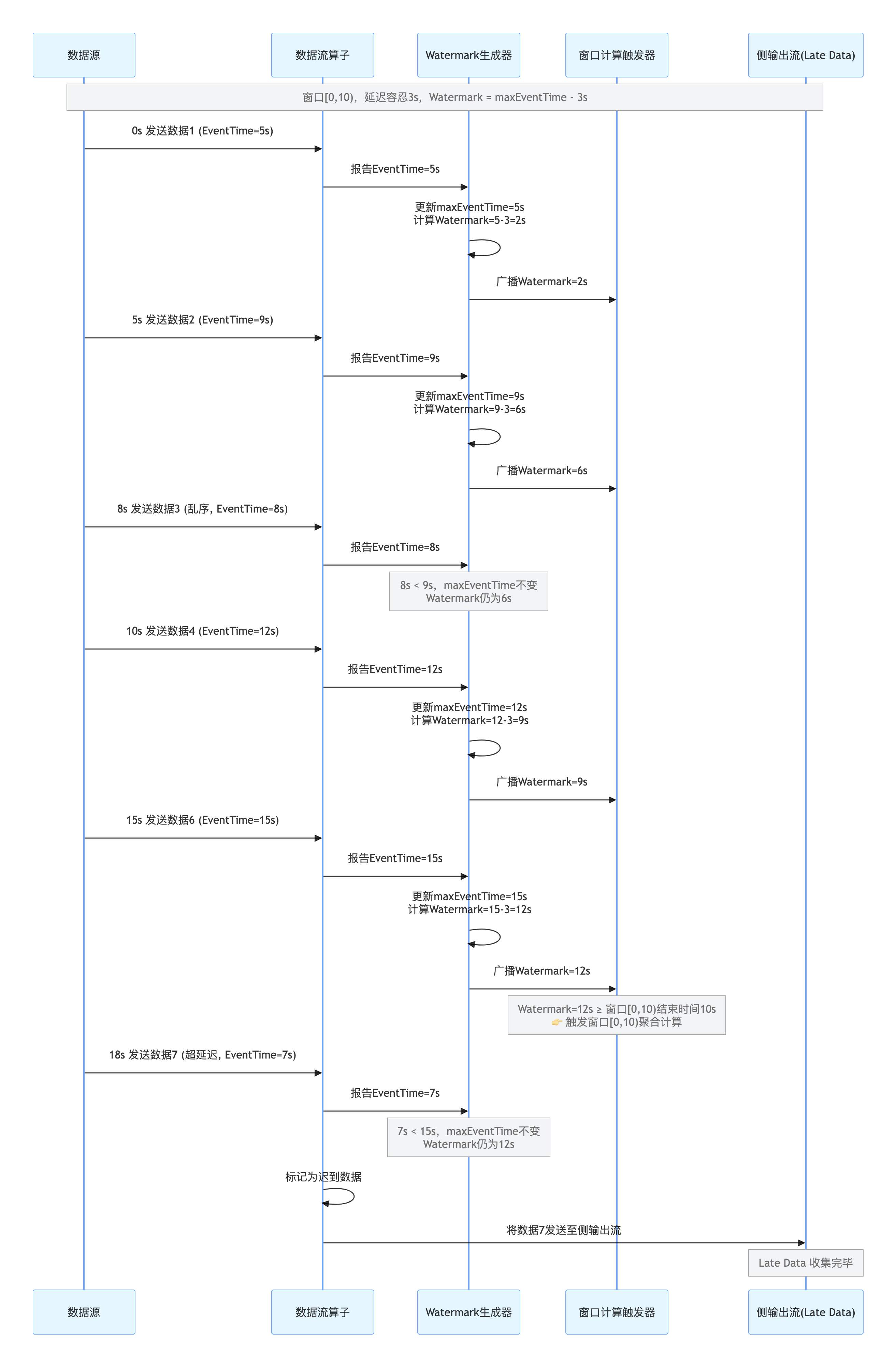
(4)多并行度下的 Watermark 传递机制
Flink 任务默认是多并行度的,每个并行子任务会独立生成 Watermark,当 Watermark 传递到下游算子 时,下游算子会取所有并行子任务中最小的 Watermark 作为当前的全局 Watermark,即 "水印对齐"。
核心原因 :保证所有并行子任务的乱序数据都被兼容,避免因某个子任务的水印超前导致其他子任务的延迟数据丢失。
5. Time + Watermark 极简核心 Demo
java
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import javax.annotation.Nullable;
// 测试数据格式:数字,事件时间戳(如:1,1719600000000)
public class TimeWatermarkDemo {
// 定义侧输出流标签,收集超延迟数据
private static final OutputTag<Integer> LATE_DATA_TAG = new OutputTag<Integer>("late-data") {};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 构造测试数据,提取事件时间
SingleOutputStreamOperator<MyData> dataStream = env.socketTextStream("localhost", 9999)
.map(new MapFunction<String, MyData>() {
@Override
public MyData map(String s) throws Exception {
String[] split = s.split(",");
return new MyData(Integer.parseInt(split[0]), Long.parseLong(split[1]));
}
})
// 2. 分配事件时间戳 + 生成Watermark(允许延迟3秒)
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<MyData>() {
private long maxEventTime = 0L;
private final long delayTime = 3000L; // 3秒延迟
@Override
public long extractTimestamp(MyData myData, long l) {
// 提取数据的事件时间戳
long eventTime = myData.getEventTime();
maxEventTime = Math.max(maxEventTime, eventTime);
return eventTime;
}
@Nullable
@Override
public Watermark checkAndGetNextWatermark(MyData myData, long l) {
// 生成Watermark:最大事件时间 - 延迟时间
return new Watermark(maxEventTime - delayTime);
}
});
// 3. 基于Event Time的滚动窗口,收集超延迟数据到侧输出流
SingleOutputStreamOperator<Integer> windowStream = dataStream
.keyBy(MyData::getNum)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.sideOutputLateData(LATE_DATA_TAG) // 收集超延迟数据
.sum("num");
// 4. 打印正常窗口结果和超延迟数据
windowStream.print("Event Time窗口结果:");
windowStream.getSideOutput(LATE_DATA_TAG).print("超延迟数据:");
env.execute("Time + Watermark Demo");
}
// 自定义数据实体
public static class MyData {
private Integer num;
private Long eventTime;
public MyData(Integer num, Long eventTime) {
this.num = num;
this.eventTime = eventTime;
}
public Integer getNum() {
return num;
}
public Long getEventTime() {
return eventTime;
}
}
}三、State:Flink 的有状态计算核心
Flink 是有状态的流处理框架 ,State(状态)是指 Flink 在计算过程中缓存的中间数据 ,比如窗口的聚合结果、数据流的去重标记、累计的计数等。有状态计算是 Flink 区别于其他流处理框架的核心特性,也是实现复杂实时计算的基础。
1. 有状态计算 vs 无状态计算
|----------|-------------------------------------|------------------|----------------------|-----------------------------|
| 计算类型 | 核心定义 | 特点 | 适用场景 | 示例 |
| 无状态计算 | 每个数据的计算结果仅依赖自身 ,不依赖任何中间数据,算子无缓存 | 计算简单、无内存占用、并行度高 | 简单的数据转换(如过滤、映射、格式转换) | 过滤掉空值数据、将字符串转为数字、日志字段提取 |
| 有状态计算 | 每个数据的计算结果依赖自身 + 中间状态 ,算子会缓存中间数据 | 支持复杂计算、结果连续、贴合业务 | 聚合统计、去重、限流、关联、累计计算 | 窗口求和、用户行为去重、接口 QPS 限流、累计订单量 |
2. State 核心分类
Flink 的 State 按作用范围 分为算子状态(Operator State) 和按键状态(Keyed State) ,其中Keyed State 是开发中使用频率 99% 的状态类型,两者核心特性、分类、高频 API 整理如下:
(1)核心分类对比
|----------------------|----------------------------------|-----------------|------------------------|-------------------------------------|--------------------------------------------------------------|
| 状态类型 | 作用范围 | 绑定对象 | 并行度扩展 | 适用场景 | 核心 API |
| 算子状态(Operator State) | 整个算子的所有并行子任务 | 算子(Operator) | 仅支持重分配 (如均匀拆分、广播) | 数据源的状态管理(如 Kafka Consumer 的 offset) | ListState UnionListState BroadcastState |
| 按键状态(Keyed State) | 算子的单个 Key 分区 ,不同 Key 的状态相互隔离 | Key(由 keyBy 指定) | 支持无缝扩展 ,按 Key 重新分区 | 绝大多数业务场景(聚合、去重、累计、关联) | ValueState ListState MapState ReducingState AggregatingState |
(2)Keyed State 细分类型(开发必用)
|------------|----------------------------|-------------------------------|-----------------------------------------------------|
| 细分类型 | 核心作用 | 特点 | 高频 API |
| ValueState | 存储单个值 ,适用于单值累计(如计数、求和) | 键值对形式,Key 为分区 Key,Value 为单个数据 | value()(获取值)update(T value)(更新值)clear()(清空状态) |
| ListState | 存储一个列表 ,适用于缓存多条数据 | 支持添加、遍历、清空列表 | add(T value)(添加数据)get()(获取列表)clear()(清空状态) |
| MapState | 存储一个键值对集合 ,适用于多维度累计 | 支持按 Key 增删改查,类似 Java 的 Map | put(K k, V v)(添加键值对)get(K k)(获取值)remove(K k)(删除键值对) |
3. State 极简核心 Demo(Keyed State - ValueState 实现累计计数)
java
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
// 实现:按Key累计计数,统计每个数字出现的次数
public class StateBasicDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 1. 构造测试数据
DataStream<Integer> dataStream = env.socketTextStream("localhost", 9999)
.map(Integer::parseInt);
// 2. 按Key分区,使用KeyedProcessFunction实现有状态计算
DataStream<String> stateStream = dataStream
.keyBy(x -> x)
.process(new KeyedProcessFunction<Integer, Integer, String>() {
// 定义ValueState,存储每个Key的累计计数
private ValueState<Integer> countState;
// 初始化状态
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>(
"countState", // 状态名称
Integer.class, // 状态类型
0 // 状态默认值
);
countState = getRuntimeContext().getState(descriptor);
}
// 处理每条数据
@Override
public void processElement(Integer value, Context ctx, Collector<String> out) throws Exception {
// 获取当前状态值(累计计数)
int currentCount = countState.value();
// 计数+1,更新状态
currentCount++;
countState.update(currentCount);
// 输出结果:Key + 累计计数
out.collect("数字:" + value + ",累计出现次数:" + currentCount);
}
});
// 3. 打印结果
stateStream.print("State累计计数结果:");
env.execute("State Basic Demo");
}
}核心要点 :Keyed State 必须在keyBy之后使用,通过open方法初始化状态,通过RuntimeContext获取状态实例,所有状态操作均为本地操作,性能极高。
四、Checkpoint & Savepoint:Flink 的容错与持久化核心
Flink 作为分布式流处理框架,运行过程中会遇到节点故障、网络中断、程序重启 等问题,Checkpoint 是 Flink 实现故障容错 的核心机制,而 Savepoint 是基于 Checkpoint 实现的手动持久化 机制,两者结合保证了 Flink 任务的高可用 和数据一致性 ,是生产环境必配的核心功能。
核心考察点 :Checkpoint 与 Savepoint 的原理区别 和使用场景 ,也是面试和开发中的高频考点,本文从原理、特性、使用、对比四个维度做体系化整理。
1. Checkpoint:分布式快照,实现故障容错
(1)Checkpoint 核心概念
Checkpoint(检查点)是 Flink 为有状态任务 生成的分布式快照 ,本质是将任务运行过程中的所有 State(状态) 按指定周期持久化到持久化存储 (如 HDFS、S3、本地文件),当任务发生故障时,可从最近的 Checkpoint 快照中恢复状态,继续计算,保证数据的Exactly-Once(精准一次) 语义。
(2)核心实现原理(极简版)
- 触发 :Flink JobManager 按指定Checkpoint 周期 ,向所有 Source 算子发送Checkpoint 触发指令 ;
- 快照 :Source 算子生成快照,将自身状态(如 Kafka offset)持久化到存储,然后将Checkpoint Barrier (检查点屏障)发送到下游算子;
- 屏障传递 :Checkpoint Barrier 随着数据流在算子间传递,下游算子接收到所有输入的 Barrier 后,生成自身状态的快照并持久化,再将 Barrier 发送到下一级算子;
- 确认 :当所有 Sink 算子完成快照并持久化后,向 JobManager 发送Checkpoint 完成确认 ;
- 恢复 :任务故障时,JobManager 选择最近的成功 Checkpoint ,通知所有算子从该快照中恢复状态,任务从故障点继续运行。
(3)核心作用
- 实现故障容错 :任务故障后无需重新计算全量数据,从 Checkpoint 恢复即可,减少数据丢失和重复计算;
- 保证数据一致性 :结合 Flink 的流控机制,实现 Exactly-Once 语义,确保数据处理精准一次;
- 支持任务重启 :生产环境中升级程序、调整并行度时,可基于 Checkpoint 无缝重启,不影响业务。
(4)生产常用配置
java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.CheckpointingMode;
public class CheckpointConfigDemo {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. 开启Checkpoint,设置周期为10秒(生产常用:10s-1min)
env.enableCheckpointing(10000);
// 2. 设置Checkpoint模式为Exactly-Once(精准一次,生产默认)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 3. 设置Checkpoint超时时间:1分钟(超时则本次Checkpoint失败)
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 4. 设置最大并行Checkpoint数:1(同一时间仅允许一个Checkpoint执行)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 5. 设置Checkpoint失败后,任务是否失败:false(生产常用,避免单个Checkpoint失败导致任务挂掉)
env.getCheckpointConfig().setFailOnCheckpointingErrors(false);
// 6. 设置持久化存储(如HDFS,生产必配,本地仅用于测试)
// env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop01:9000/flink/checkpoint");
}
}2. Savepoint:手动创建的持久化快照,实现任务灵活管理
(1)Savepoint 核心概念
Savepoint 是用户手动触发 的、基于 Checkpoint 机制实现的持久化快照 ,本质是一份特殊的 Checkpoint ,与 Checkpoint 不同的是,Savepoint 是手动管理 的,不会被 Flink 自动删除,主要用于任务的版本升级、并行度调整、集群迁移 等场景。
(2)核心实现原理
Savepoint 的实现原理与 Checkpoint完全一致 ,都是生成分布式快照并持久化状态,区别仅在于触发方式 和生命周期管理 :
- Checkpoint 由 Flink自动触发、自动管理 ,旧的 Checkpoint 会被新的覆盖 / 删除;
- Savepoint 由用户手动触发、手动管理 ,不会被 Flink 自动删除,需用户手动清理。
3. Checkpoint 与 Savepoint 核心对比
|----------|---------------------------------------------|---------------------------------------------|
| 对比维度 | Checkpoint | Savepoint |
| 触发方式 | 自动触发 ,按配置的周期自动执行 | 手动触发 ,由用户通过命令行 / API 执行 |
| 生命周期 | 由 Flink自动管理 ,新的 Checkpoint 会覆盖旧的,可配置保留数 | 由用户手动管理 ,不会被 Flink 自动删除,需手动创建 / 删除 / 恢复 |
| 核心目的 | 实现故障容错 ,任务故障时自动恢复,保证高可用 | 实现任务灵活管理 ,如版本升级、并行度调整、集群迁移 |
| 数据保留 | 保留近期的少量快照(生产常用:保留 3-5 个) | 长期保留,直到用户手动删除 |
| 触发时机 | 运行过程中持续触发 | 任务升级、重启、扩缩容前手动触发 |
4. Checkpoint 极简使用 Demo(整合 State,实现故障恢复)
java
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
// 整合Checkpoint + State,实现故障恢复后的累计计数不丢失
public class CheckpointStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// ========== Checkpoint 核心配置 ==========
env.enableCheckpointing(5000); // 5秒触发一次Checkpoint
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(30000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 配置持久化存储(本地测试,生产替换为HDFS)
env.getCheckpointConfig().setCheckpointStorage("file:///D:/flink/checkpoint");
// 1. 构造测试数据
DataStream<Integer> dataStream = env.socketTextStream("localhost", 9999)
.map(Integer::parseInt);
// 2. 有状态计算:累计计数
DataStream<String> resultStream = dataStream
.keyBy(x -> x)
.process(new KeyedProcessFunction<Integer, Integer, String>() {
private ValueState<Integer> countState;
@Override
public void open(Configuration parameters) throws Exception {
countState = getRuntimeContext().getState(
new ValueStateDescriptor<>("countState", Integer.class, 0)
);
}
@Override
public void processElement(Integer value, Context ctx, Collector<String> out) throws Exception {
int currentCount = countState.value();
currentCount++;
countState.update(currentCount);
out.collect("数字:" + value + ",累计次数:" + currentCount);
}
});
// 3. 打印结果
resultStream.print("Checkpoint+State 结果:");
env.execute("Checkpoint & State Demo");
}
}测试故障恢复 :运行程序后输入数字,累计计数正常增长,手动停止程序后重新运行,程序会从 Checkpoint 中恢复状态,累计计数不会从 0 开始,实现无丢失恢复。
五、四大基石核心总结
Flink 的四大基石是层层递进、相互依赖的核心体系,支撑了所有实时计算场景:
- Window :实现流到批的切分,是聚合计算的基础;
- Time + Watermark :为 Window 提供精准的时间触发机制,解决 Event Time 下的乱序问题;
- State :为 Window 和业务计算提供中间数据缓存,是有状态计算的核心;
- Checkpoint & Savepoint :为 State 提供持久化和故障恢复能力,保证任务的高可用和数据一致性。
📚 我的技术博客导航:点击进入一站式查看所有干货