目录
- [L 1 L_{1} L1和 L 2 L_{2} L2正则化的区别](#L 1 L_{1} L1和 L 2 L_{2} L2正则化的区别)
- 从数学的角度上解释L1能够进行特征选择
L 1 L_{1} L1和 L 2 L_{2} L2正则化的区别
数学定义与惩罚方式:
L1正则化在损失函数中添加权重的绝对值之和:
J L 1 = J + λ ∑ i = 1 n ∣ w i ∣ J_{L1} = J + \lambda \sum_{i=1}^n |w_i| JL1=J+λi=1∑n∣wi∣
L2正则化添加权重的平方和:
J L 2 = J + λ ∑ i = 1 n w i 2 J_{L2} = J + \lambda \sum_{i=1}^n w_i^2 JL2=J+λi=1∑nwi2
其中, J J J是原始损失函数, λ \lambda λ是正则化系数, w i w_i wi是模型参数。
| 特性 | L1 正则化 (Lasso) | L2 正则化 (Ridge) |
|---|---|---|
| 惩罚项 | 权重的绝对值之和: λ ∑ \lambda \sum λ∑ | 权重平方之和: λ ∑ w i 2 \lambda \sum w_{i}^{2} λ∑wi2 |
| 等高线形状 | 菱形(L1-ball) | 圆形(L2-ball) |
| 主要作用 | 特征选择(产生稀疏解) | 防止过拟合(权重平滑衰减) |
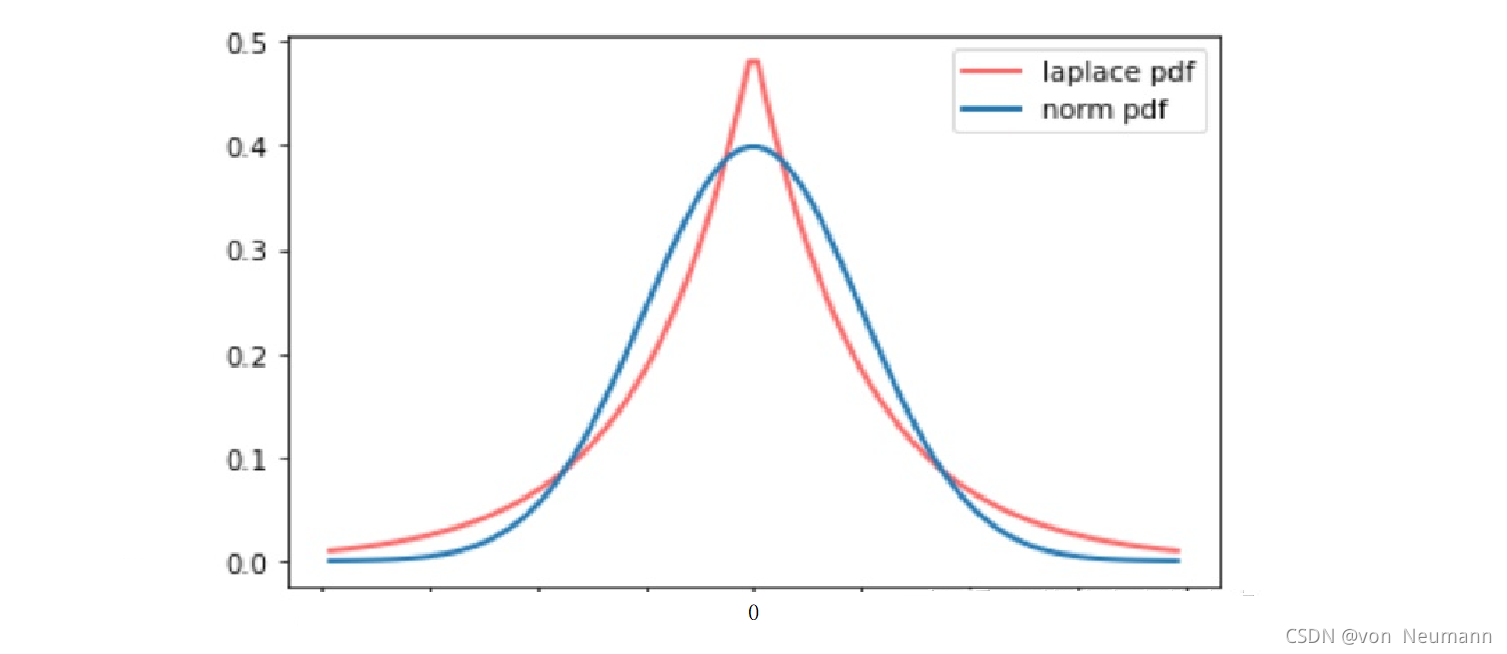
| 数学先验 | 假设参数服从拉普拉斯分布 | 假设参数服从高斯分布 |
- 拉普拉斯分布:允许在任意一点 μ \mu μ处设置概率质量的峰值: f ( x ∣ μ , γ ) = 1 2 γ e − ∣ x − μ ∣ γ f(x|\mu,\gamma)=\frac{1}{2\gamma}e^{-\frac{|x-\mu|}{\gamma}} f(x∣μ,γ)=2γ1e−γ∣x−μ∣
- 高斯分布: f ( x ∣ μ , σ ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x|\mu,\sigma)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^{2}}{2\sigma^{2}}} f(x∣μ,σ)=2π σ1e−2σ2(x−μ)2
从数学的角度上解释L1能够进行特征选择
在数学上的根本区别在于对参数空间约束形状的不同。
从几何直观和导数特性两个角度来解释:
几何直观(等高线切点)
想象一个二维参数空间 ( ω 1 , ω 2 ) (\omega_{1},\omega_{2}) (ω1,ω2),其中目标函数:原始损失函数(如 Log Loss)的等高线通常是一组围绕中心最优解的椭圆。
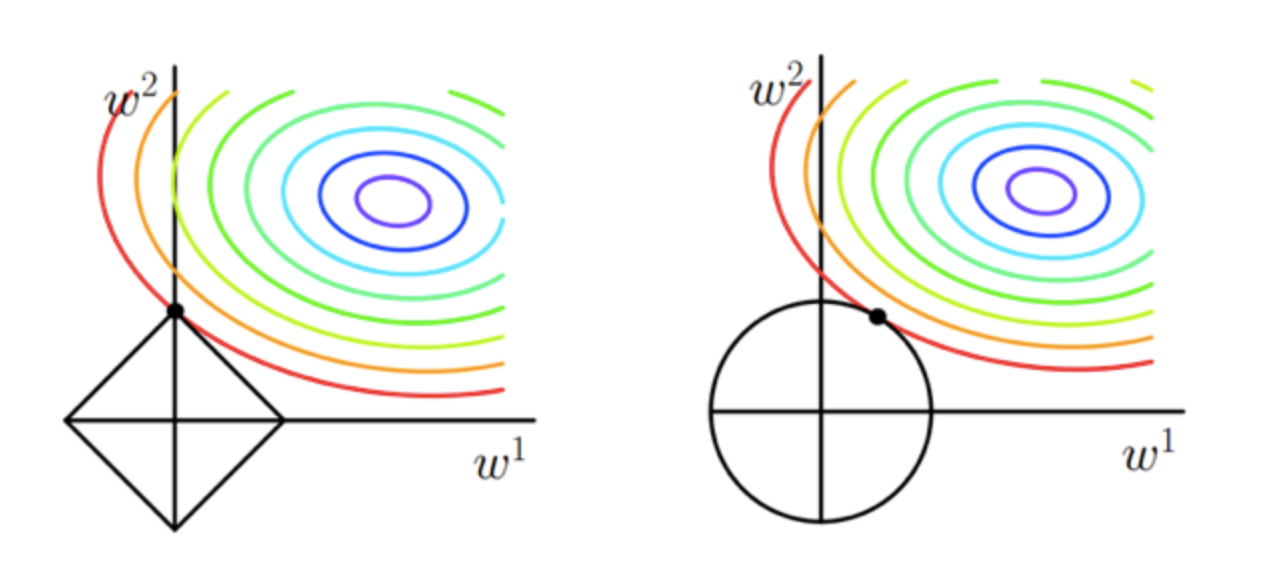
约束区域:
- L2 的约束区是一个圆。椭圆等高线与圆相切时,切点落在坐标轴(即或为 0)的概率极低。因此,L2 倾向于让权重变小但不为 0。
- L1 的约束区是一个带尖角的菱形。椭圆等高线在扩张时,极大概率首先触碰到菱形的顶点。而菱形的顶点全部位于坐标轴上,例如 ( ω 1 , 0 ) (\omega_{1},0) (ω1,0)或者 ( 0 , ω 2 ) (0,\omega_{2}) (0,ω2)。
结论:一旦切点落在坐标轴上,对应的特征权重就变成了0,实现了自动的特征剔除。
B. 导数特性(梯度下降的角度)
观察两种正则化项对梯度更新的影响:
- L_{2}正则化:### L1和L2正则化的数学形式
梯度更新规则的差异
-
L1正则化的梯度更新
L 1 L_{1} L1的导数: ∂ ∂ ω ( λ ∣ ω ∣ ) = λ s i g n ( ω ) \frac{\partial }{\partial \omega}(\lambda|\omega|)=\lambda sign(\omega) ∂ω∂(λ∣ω∣)=λsign(ω),梯度更新规则为:
w i ← w i − η ( ∂ J ∂ w i + λ ⋅ sign ( w i ) ) w_i \leftarrow w_i - \eta \left( \frac{\partial J}{\partial w_i} + \lambda \cdot \text{sign}(w_i) \right) wi←wi−η(∂wi∂J+λ⋅sign(wi))只要 ω ! = 0 \omega != 0 ω!=0,它的梯度始终是一个常数。 这意味着即使 ω \omega ω已经很小了,它依然受到一个恒定的"推力"向 0 迈进。一旦跨过 0 点,权重就会由于惩罚项的震荡或截断算法(如坐标下降法)被锁定在 0。
-
L2正则化的梯度更新
L 2 L_{2} L2的导数: ∂ ∂ ω ( λ ω 2 ) = 2 λ ω \frac{\partial }{\partial \omega}(\lambda \omega^{2})=2\lambda \omega ∂ω∂(λω2)=2λω,梯度更新规则为:
w i ← w i − η ( ∂ J ∂ w i + 2 λ w i ) w_i \leftarrow w_i - \eta \left( \frac{\partial J}{\partial w_i} + 2\lambda w_i \right) wi←wi−η(∂wi∂J+2λwi)当很小时,梯度也变得极小。这意味着越接近 0,更新越慢,很难真正减小到 0。
总结:L1更易产生稀疏解的原因
-
梯度更新的动态特性
L1的梯度更新中, sign ( w i ) \text{sign}(w_i) sign(wi)对所有权重施加固定的 ± λ \pm \lambda ±λ扰动。当 w i w_i wi接近零时,若原始梯度 ∂ J ∂ w i \frac{\partial J}{\partial w_i} ∂wi∂J的绝对值小于 λ \lambda λ,权重会被直接推向零(因正负抵消)。而L2的更新与 w i w_i wi成正比,接近零时梯度衰减,难以精确归零。
-
几何解释
L1正则化的约束区域是菱形(高维下为多面体),最优解容易落在顶点(某些维度为零)。L2的约束区域是球形,最优解通常在光滑边界,非零概率更高。