CLIP
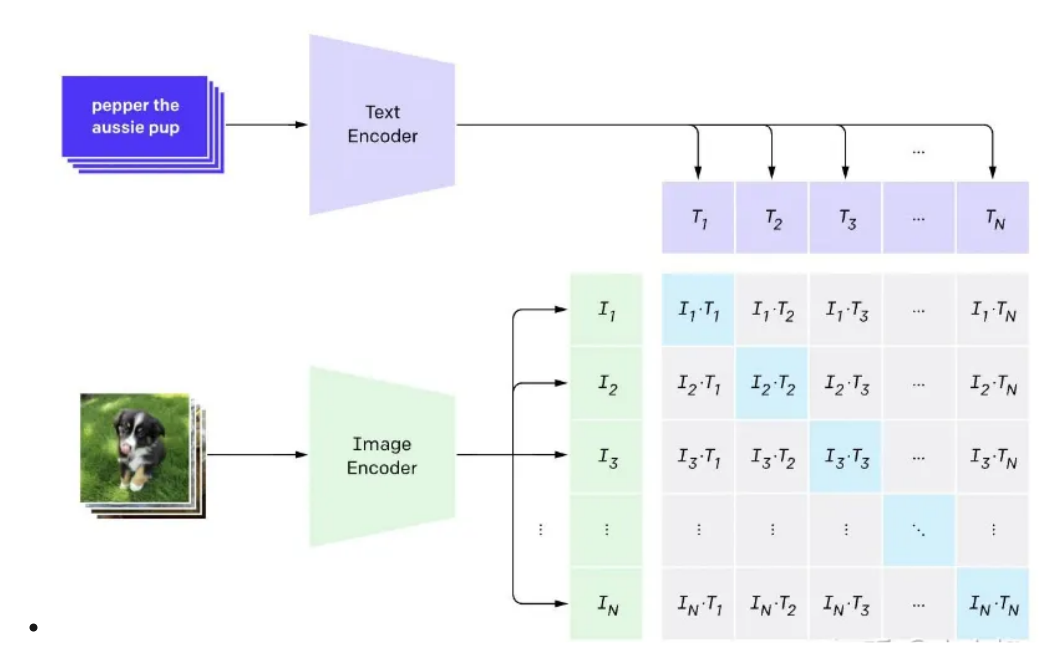
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布,是从自然语言监督中学习的一种有效且可扩展的方法。CLIP在预训练期间学习执行广泛的任务,包括OCR,地理定位,动作识别,并且在计算效率更高的同时优于公开可用的最佳ImageNet模型。
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
-
Text Encoder:用于将文本转换为低维向量表示-Embeding。
-
Image Encoder:用于将图像转换为类 似的向量表示-Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
采⽤对⽐学习的⽅式,通过图像 - 文本对的⼤规模数据训练,学习到通⽤ 的图像和⽂本联合嵌⼊空间。这种联合嵌⼊空间使得模型能够处理多种跨模态任务,如图像分类、文本到图像检索等。CLIP 的创新之处在于能够利⽤大量的图⽂对数据进行无督预训练,从而获得跨模态的通⽤表示。
BLIP
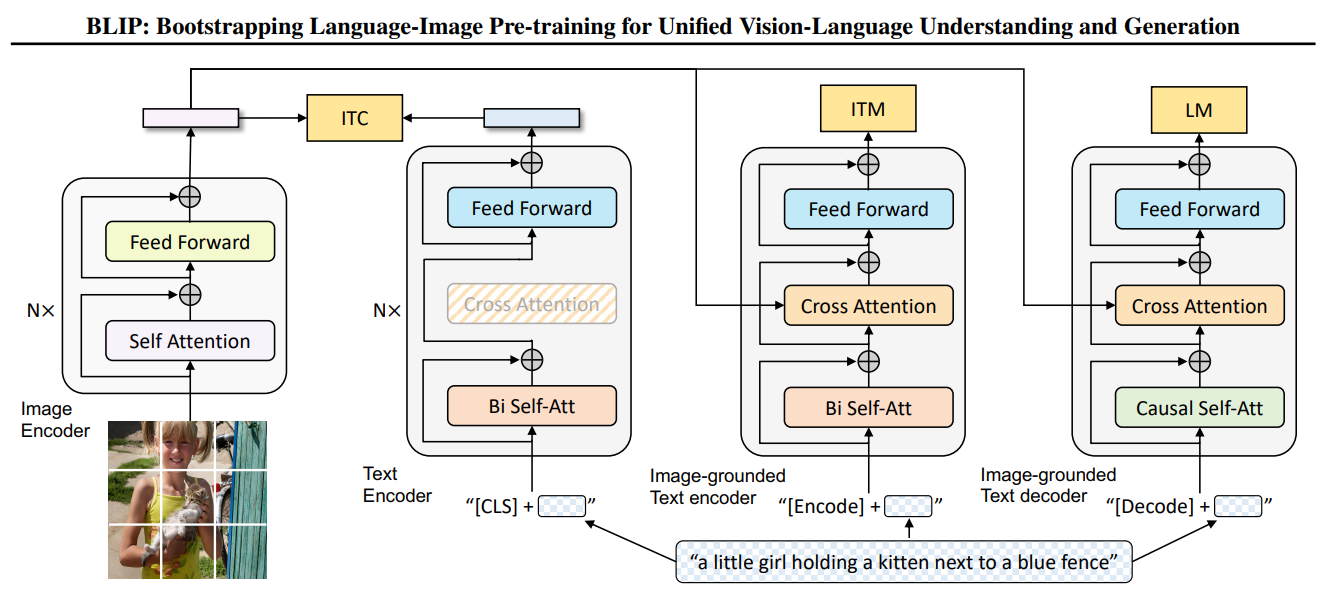
BLIP提出MED架构,是一个统一的多模态Transformer架构,一个能使用同一套参数在不同任务下切换模式的统一模型:
Unimodal Encoder: 用于Image-Text Contrastive (ITC)任务,分别编码图像和文本,对齐特征空间。
Image-grounded Text Encoder: 在文本Transformer中插入cross-attention,做Image-Text Matching (ITM)。
Image-grounded Text Decoder: 将双向自注意力改为因果自注意力,结合cross-attention生成文本(Language Modeling, LM)。
特点:
一套Transformer参数共享,根据任务切换mask和结构。
ViT作为图像编码器,BERT结构作为文本基底。
Mixture的含义:一套Transformer → 三种前向路径 → 不同mask/不同special tokens/是否开启cross-attention → 实现理解+生成任务统一。
结构细节与实现组件
(1) 图像编码器
ViT结构:Patch embedding → Transformer → [CLS]特征 + Patch特征
输出:[CLS] → 图像全局特征;Patch特征序列 → 提供给Cross-Attention
(2) Text Transformer
必须支持:
参数共享:embedding、transformer blocks统一
Self-Attention类型切换:
Encoder模式 → 双向mask;Decoder模式 → 因果mask
Cross-Attention可选:ITC不启用,ITM/LM启用
| 模式 | Text起始token | Self-Attention | Cross-Attention | 输出 |
|---|---|---|---|---|
| ITC | [CLS] |
Bi-SA | ✗ | [CLS] embedding → contrastive head |
| ITM | [ENC] |
Bi-SA | ✓ | [ENC] embedding → classifier |
| LM | [DEC] |
Causal-SA | ✓ | token概率分布 |
- forward时根据token判断模式(而不是写三份模型)。
- mask逻辑必须动态生成,保证Encoder与Decoder共享block。
- 同一batch支持多任务样本 → 输入序列混合
[CLS]/[ENC]/[DEC],loss分支根据起始token决定。 - 图像特征缓存:同一图像在ITC、ITM、LM三个loss中共用一次ViT输出,节省计算。
Llava
Llava1 的模型结构很简洁,CLIP 模型的视觉编码器 + 映射层 + LLM(Vicuna、LLama) ,利用 CLIP 模型的 Vison Encoder 结构对输入图片提取视觉特征,即转换为形状为 [N=1, grid_H x grid_W, hidden_dim] 的 feature map,然后通过一个映射层(线性层)将图像特征对齐到文本特征维度,即得到形状为 [N=1, grid_H x grid_W, embedding_dim] 的 image tokens embedding 向量,再然后将图片 tokens 向量和输入文本 tokens 向量 concat 后作为 LLM 的输入,生成回答文本。
LLaVA 模型架构如下图所示:
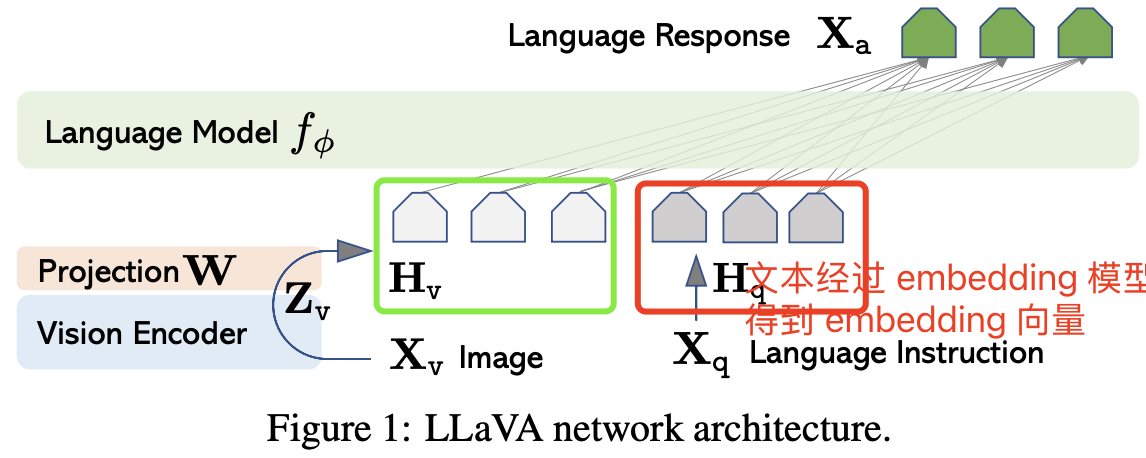
对于输入图像 Xv,采用预训练 CLIP 模型的视觉编码器 ViT-L/14(224²),其生成的视觉特征为 Zv=g(Xv),在作者的实验中,只用最后一个 Transformer 层之前和之后的网格特征。并使用一个简单的线性层将图像特征连接(映射)到词嵌入空间,通过一个可训练的投影矩阵 W 将 Zv 转换为语言嵌入标记 Hv,ZvZ 向量的最后一个维度就是 LLM 的词嵌入空间维度 embedding_dim。
LLaVA 多模态模型推理 pipline:
-
prompts 预处理;
-
视觉特征预处理;
-
视觉特征模型
clip推理; -
视觉特征和文本特征合并成一组 tokens;
-
语言模型 llama 推理。
CogVLM
CogVLM 之所以能取得效果的提升,最核心的思想是"视觉优先"。
之前的多模态模型通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的"附庸",效果自然有限。
而CogVLM在多模态模型中将视觉理解放在更优先的位置,使用5B参数的视觉编码器和6B参数的视觉专家模块,总共11B参数建模图像特征,甚至多于文本的7B参数量。
CogVLM 的结构如下所示: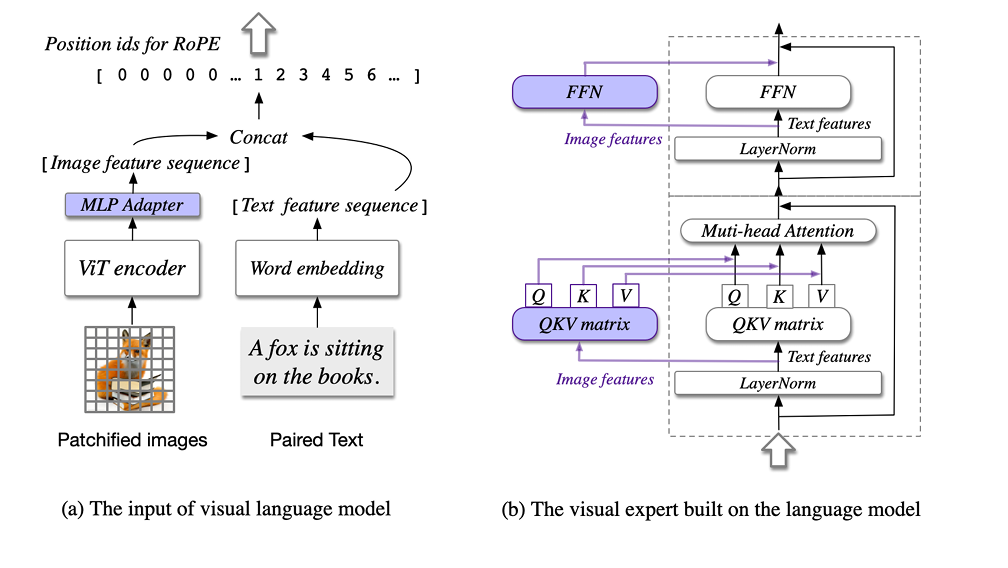
模型共包含四个基本组件:ViT 编码器,MLP 适配器,预训练大语言模型(GPT-style)和视觉专家模块。
**ViT编码器:**在 CogVLM-17B 中,我们采用预训练的 EVA2-CLIP-E。
**MLP 适配器:**MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同的空间。
预训练大语言模型: CogVLM 的模型设计与任何现有的 GPT-style的预训练大语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7B-v1.5 进行进一步训练;我们也选择了 GLM 系列模型和 Llama 系列模型做了相应的训练。
**视觉专家模块:**我们在每层添加一个视觉专家模块,以实现深度的视觉 - 语言特征对齐。具体来说,每层视觉专家模块由一个 QKV 矩阵和一个 MLP 组成。
模型在15亿张图文对上预训练了4096个A100*days,并在构造的视觉定位(visual grounding)数据集上进行二阶段预训练。在对齐阶段,CogVLM使用了各类公开的问答对和私有数据集进行监督微调,使得模型能回答各种不同类型的提问。