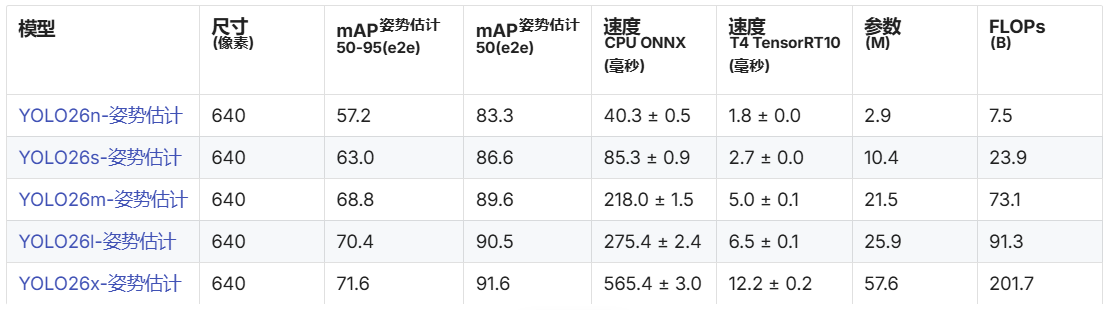
Ultralytics的YOLO26模型提供专门的姿势估计模型以支持姿势估计,其主要预训练模型及参数如下表所示,其中的"e2e" 代表端到端性能。
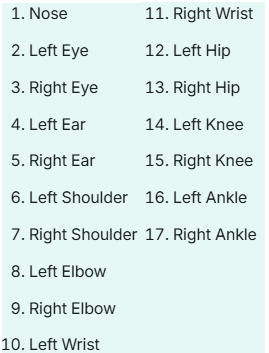
姿势估计模型的输出是一组点,这些点代表图像中对象上的关键点,通常还包括每个点的置信度分数。YOLO26的姿势估计模型的输出数据形状为N, K, D,其中N为从图片中检测到的人数,K为每个人体的关节/特征点数量(关键点),由于预训练模型采用COCO格式,K通常为17,每个关键点代表人体不同的部位,下图为每个索引与其对应身体关节的映射关系,D为每个关键点的属性,包括关键点的坐标x、y,以及置信度分数。不过将姿势估计模型转换为onnx格式后,其输出形状变为1,300,57的形式,具体解析方式后续再学习。
YOLO类的predict函数返回结果中,最重要的属性为keypoints,该属性中保存了从图像中检测出的所有人体的关键点信息,keypoints的主要属性如下图所示,详细说明见参考文献4。

最后是示例程序及程序运行效果,如下所示:
python
from ultralytics import YOLO
model = YOLO(r"E:\MyPrograms\Python\ultralytics\yolo26m-pose.pt")
results = model.predict(
source="longqi.jpg", # 图片路径
save=True, # 自动保存结果到 runs/pose/predict
show=True,
conf=0.5, # 置信度阈值
imgsz=640 # 输入图像尺寸
)
# 获取关键点
for result in results:
print(result.keypoints.xy)
print(result.keypoints.conf) 

1https://docs.ultralytics.com/zh/models/yolo26/
2https://docs.ultralytics.com/zh/tasks/pose/
3https://docs.ultralytics.com/zh/datasets/pose/coco/
4https://deepwiki.com/ultralytics/ultralytics/5.2-annotation-and-plotting-utilities