一、查询
1、执行顺序
- 先找表、连接、过滤(FROM/JOIN/WHERE)
- 再分组、聚合(GROUP BY/HAVING)
- 最后开窗口计算排名 / 聚合(OVER())
- 再排序、分页
sql
SELECT 列1, 列2, 聚合函数(列)
FROM 表名
[JOIN 其他表 ON 关联条件]
WHERE 行过滤条件
GROUP BY 分组列
HAVING 分组过滤条件
ORDER BY 排序列 ASC/DESC
LIMIT 偏移量, 数量;语法:
- (inner) join连接'只保留两张表中匹配成功 的行(双方都有数据才保留)'两表通过外键逐一拼接,不会保留存在a表中,但b表中无匹配成功外键的值,left join 则只保留左表,不符合条件的行也会显示,显示null
- distinct 去重留下唯一
- IN不关心行数,只关心值是否存在
- like 模糊查询,%匹配任意字符长度,_匹配单个
常用函数
1、字符串类
CONCAT(列1, 列2) -- 字符串拼接
LENGTH(列) -- 长度
SUBSTRING(列, start, length) -- 截取
UPPER(列) / LOWER(列) -- 大小写转换
TRIM(列) -- 去空格
2、数值类
ROUND(数值, 位数) -- 四舍五入
CEIL(数值) -- 向上取整
FLOOR(数值) -- 向下取整
ABS(数值) -- 绝对值
3、条件类
IF(条件, 真值, 假值)
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
ELSE 默认值
END
2、exists的使用
查询要求中包含有没有的判断,使用exists结合select 1 进行判断,如果要展示的查询结果中只有外表,只需要在select 1 判断的时候将外表和内表进行结合,而要展示内外表时,在exists的外边使用join连接。
sql
#(9) 查询和" 01 "号的同学学习的课程完全相同的其他同学的信息
#关联内外两层表 sco.student_id = s.id
#exists(有结果) 返回ture || not exists(有结果) 返回false
#select 1 表示判断
select s.* from students s
where id != '01' # 排除自身id
#先查询课程总数一致的同学
and exists(select 1 from scores sco where sco.student_id = s.id group by sco.student_id
having count(distinct sco.course_id) = (select count(distinct course_id) from scores where student_id ='01'))
#课程总数一致后查询每一门的课程是否一致
and not exists(select 1 from scores sco where sco.student_id = s.id
and sco.course_id not in (select course_id from scores where student_id = '01'));EXISTS 是 "行相关子查询",它判断的是「当前这一行对应的学生」是否满足条件,而不是判断当前这一行本身。
s.id 是外层学生表的学生 ID!,也就是说
数据库对每一行都执行一次 EXISTS 判断:
判断 行 1(学生 1,01 课)
去查:学生 1 有没有 01 课 <60? → 有 → 这一行保留
判断 行 2(学生 1,03 课)
去查:学生 1 有没有 01 课 <60? → 依然有 → 这一行也保留!
- WHERE + 普通条件 :过滤当前行
- WHERE + EXISTS (关联外层学生 ID) :过滤整个学生,只要学生满足,他的所有行都保留
sql
select distinct s.id,s.name,s2.course_id, s2.score from students s join scores s2 on s.id = s2.student_id
where exists( select 1 from scores sco where sco.student_id = s.id and course_id = '01'
and score < 60) ;3、窗口函数
- 窗口函数 = 对一组行(窗口)进行计算,但不会把多行合并成一行
执行顺序:窗口函数是在 WHERE、GROUP BY、HAVING 之后才执行的!所以如果要查询窗口函数生成的表,需要将其作为子查询,嵌套查询。
语法:窗口函数() OVER ( PARTITION BY 分组列 ORDER BY 排序列 )
- OVER:标志这是窗口函数
- PARTITION BY:按什么分组(可选)
- ORDER BY:组内按什么排序(可选)
注意:
- 排名要全局,就不要写 PARTITION BY
- PARTITION BY 是分组内排名,不是全局排名,比如说公司工资排名,如果是部门单独排则需要使用,但是公司所有人进行排序,那么就不需要使用,如果使用,每个人都会成为单独的一组
函数:
- RANK () ------ 跳跃排名,eg:1 1 3 4
- DENSE_RANK () ------连续排名 eg: 1 2 2 3 4
- ROW_NUMBER () ------ 行号(永不重复)eg:1 2 3 4
- LAG(列值, 1, 0)------返回前n行的列的值,可以用来对比,比如说第二名和第一名的分差,使用原分-返回的
- LEAD(col, n, default)------返回后n行列的值
- FIRST_VALUE(col)------取窗口内第一行对应的列值
进阶函数
- NTILE(n)将数据平均分成 n 组,标记组号 1~n
sql
#按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺
SELECT
student_id,
course_id,
score,
ROW_NUMBER() OVER (
PARTITION BY course_id
ORDER BY score DESC
) AS single_rank
FROM scores;结果: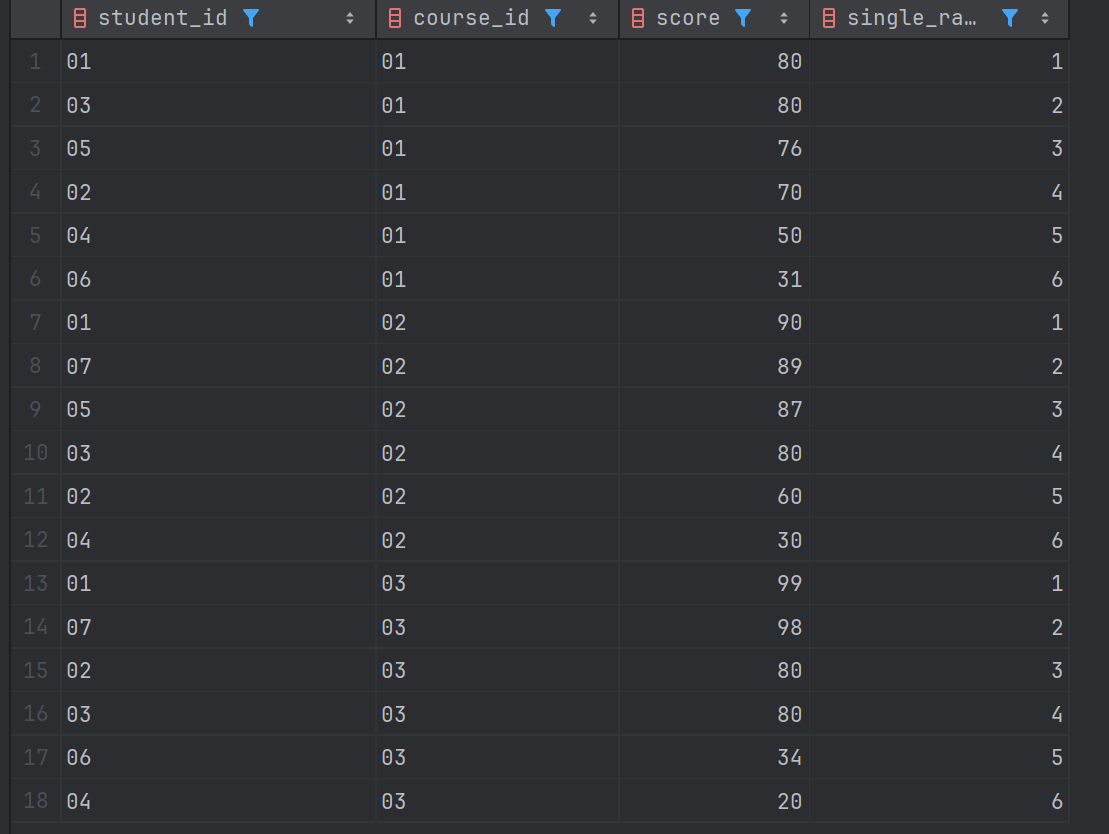
4、日期类
时间类型
DATE → 2025-01-01
DATETIME → 2025-01-01 12:30:45
TIMESTAMP → 2025-01-01 12:30:45(带时区)
sql
select curdate(); #输出当前日期
select curtime();#输出当前时间
select now();#日期+时间
select * from students where birth = CURDATE();时间查询
日期格式
DATE_FORMAT(date, '%Y-%m-%d') -- 转成 2026-03-29
DATE_FORMAT(date, '%Y年%m月%d日')
DATE_SUB(日期, INTERVAL n 单位) 日期减法,意思是:日期减去n后得到的日期DATE_ADD(日期, INTERVAL n 单位)日期加法
DATE_SUB(CURDATE(), INTERVAL 1 DAY) 当前日期减去1天,也就是昨天的日期
周yearweek()
月
month()
年
year()
嵌套使用查询
sql
# 查询下周过生日的学生
select *
from students as st
where week(st.birth) = week(date_add(now(), interval 7 day));二、增删改数据(DML)
增加
insert into 表名(字段)values(值)
删
delete from 表名 where 条件
drop user
DELETE 删数据,DROP 删表;DELETE 可回滚,DROP 不可回滚
改
update 表 set 字段=值 where 条件