目录
[五、Agent 设计](#五、Agent 设计)
[5.1 角色提示词(System Prompt)](#5.1 角色提示词(System Prompt))
[5.2 动作决策流程](#5.2 动作决策流程)
[5.3 多模型分配](#5.3 多模型分配)
[坑1:AI 返回字符串 "null" 导致猎人永久卡死](#坑1:AI 返回字符串 "null" 导致猎人永久卡死)
[坑3:CORS 端口问题](#坑3:CORS 端口问题)
[werewolf/├── main.py # FastAPI 后端,API 路由,信息脱敏├── game_engine.py # 游戏状态机,规则引擎├── models.py # Pydantic 数据模型├── agent.py # AI Agent,Prompt 构建,LLM 调用├── ai_manager.py # Agent 进程管理,多模型分配├── human_client.py # 命令行真人客户端(调试用)└── src/ # React 前端 ├── pages/GameRoom.tsx # 游戏主界面 ├── pages/Lobby.tsx # 大厅页面 ├── services/api.ts # API 封装 └── hooks/useGameState.ts](# FastAPI 后端,API 路由,信息脱敏├── game_engine.py # 游戏状态机,规则引擎├── models.py # Pydantic 数据模型├── agent.py # AI Agent,Prompt 构建,LLM 调用├── ai_manager.py # Agent 进程管理,多模型分配├── human_client.py # 命令行真人客户端(调试用)└── src/ # React 前端 ├── pages/GameRoom.tsx # 游戏主界面 ├── pages/Lobby.tsx # 大厅页面 ├── services/api.ts # API 封装 └── hooks/useGameState.ts)
一、实验背景
狼人杀是一个经典的多人社交推理游戏。每位玩家被秘密分配身份------狼人或好人阵营------在有限的公开信息下,通过发言、投票、夜间行动来完成阵营目标。这个游戏天然具备 LLM Agent 研究所需的几个核心挑战:
- 信息不对称:每个玩家只知道自己的角色,无法看到他人的真实身份
- 欺骗与反欺骗:狼人需要伪装成好人,好人需要从发言中识别破绽
- 多轮推理:每一轮的死亡结果、投票行为都是新的线索,需要跨轮记忆
- 多智能体协作:狼人需要在队内达成共识,预言家需要在合适时机公布信息
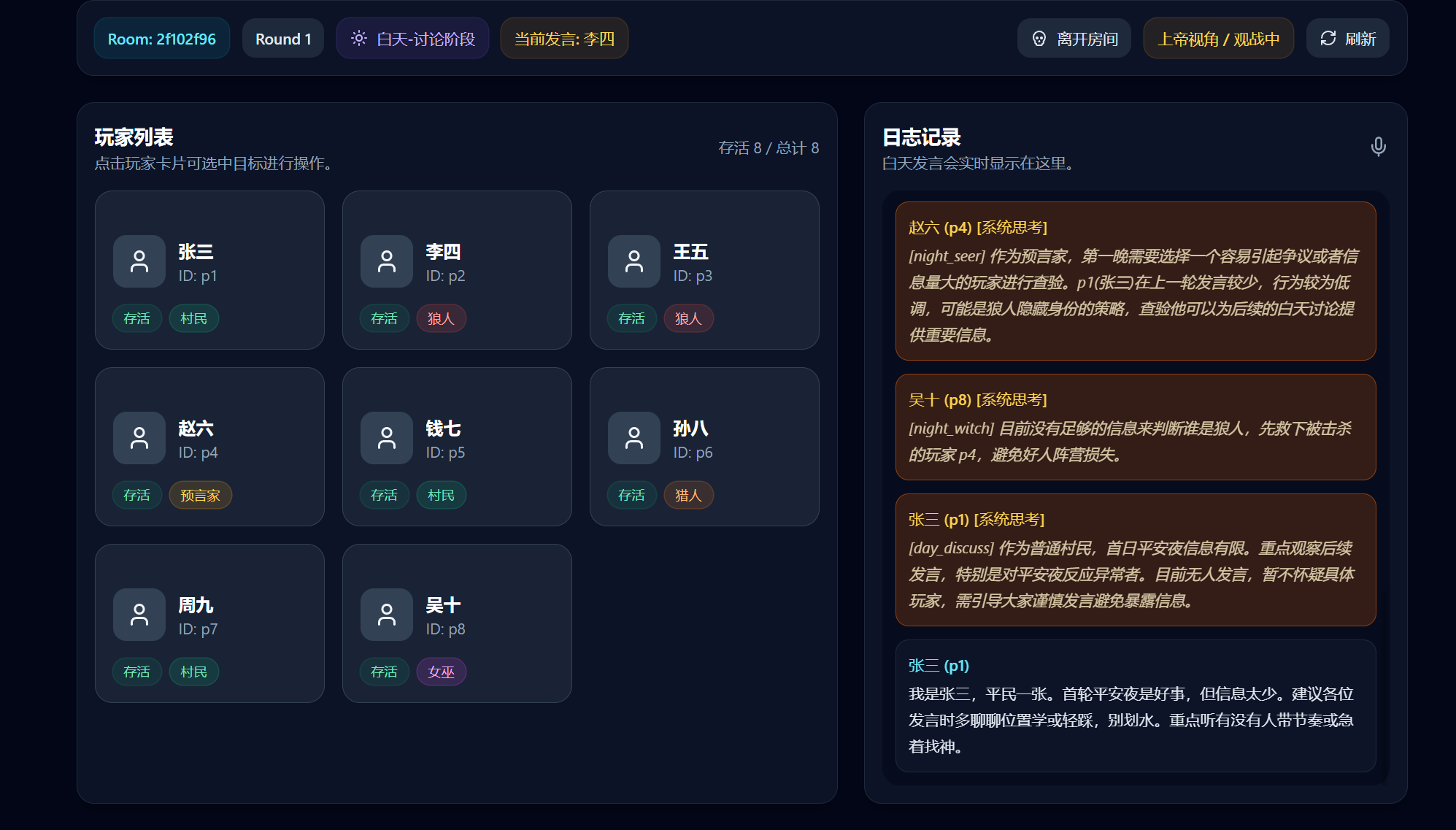
本项目构建了一个完整的真人+AI 混战 狼人杀系统,8 人局(2 狼人 + 1 预言家 + 1 女巫 + 1 猎人 + 3 村民),支持真人下场或纯 AI 观战两种模式。
二、系统架构
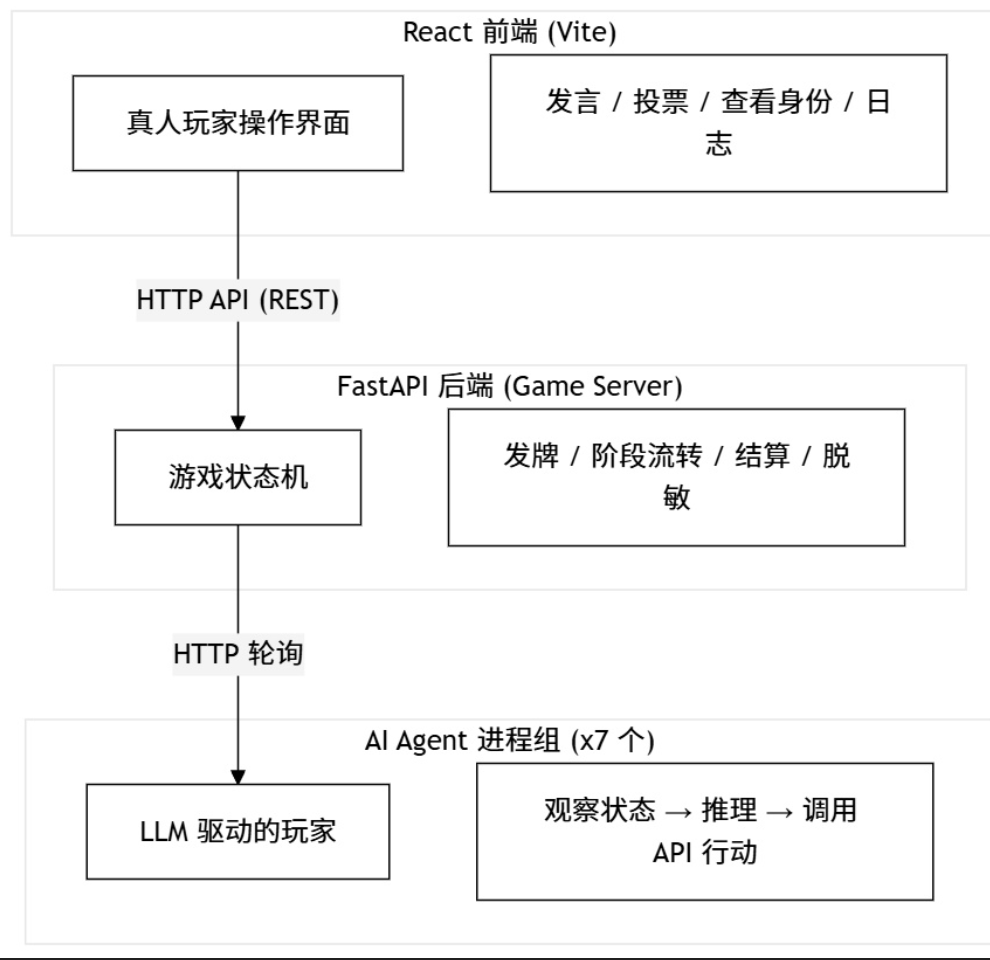
- 后端:FastAPI + Pydantic,维护游戏状态,严格控制信息权限
- 前端:React + Vite + Tailwind CSS,提供实时游戏界面
- Agent:独立 Python 进程,调用 SiliconFlow 的 LLM API,通过轮询后端状态决策
三、游戏状态机
游戏按以下阶段严格推进,每个阶段只接受对应的 API 调用:

关键设计:**猎人触发**是一个插入式阶段,无论猎人死于狼刀还是投票,都会在结算后插入
四、信息权限控制
这是平台最核心的工程设计。同一个 `/game/{room_id}/state` 接口,对不同角色返回不同内容:
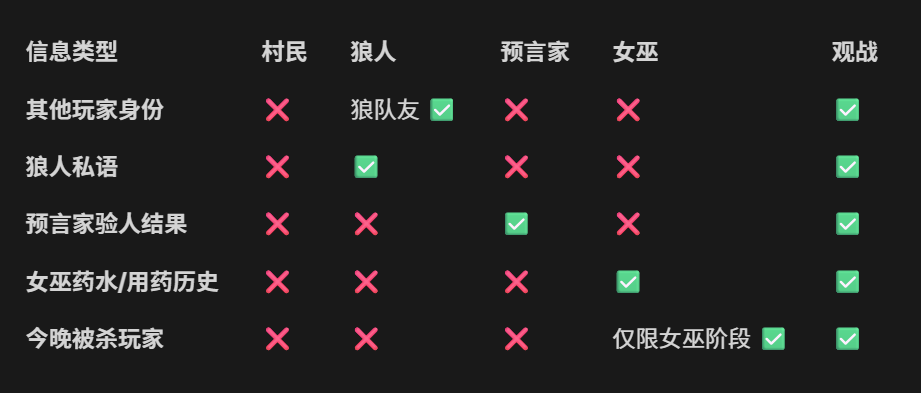
核心实现是后端的 get_masked_state`函数,在返回状态前根据请求者身份深拷贝并裁剪敏感字段:
python
def get_masked_state(engine, request_player_id):
# 观战/游戏结束 → 上帝视角,全部公开
if request_player_id == "spectator" or state.phase == GamePhase.GAME_OVER:
return state.model_dump()
# 隐藏其他玩家身份(除狼队互知)
for pid, p in raw["players"].items():
if pid != request_player_id and not (is_wolf and target_is_wolf):
p["role"] = None
# 各类敏感字段按角色过滤
if not is_seer:
raw["seer_history"] = {}
if not is_wolf:
raw["wolf_whispers"] = []
if not is_witch:
raw["witch_actions_history"] = []五、Agent 设计
5.1 角色提示词(System Prompt)
每个 Agent 在创建时注入对应角色的策略提示词,以狼人为例:
你是一名狼人,你的目标是消灭所有好人。白天你必须伪装成村民,发言要有逻辑、表现出对其他玩家的合理怀疑。 绝对不要主动暴露自己是狼人。如果有人声称预言家并指认你是狼人,立刻反咬对方是悍跳的假预言家,用"我是好人,对方在撒谎"的逻辑反击。 投票时优先跟随大多数人的票,避免成为异类引发怀疑...
5.2 动作决策流程
Agent 的每轮决策分三步:
- 观察:轮询后端获取当前游戏状态(已按角色脱敏)
- 推理:将状态格式化为 Prompt,调用 LLM,要求输出 JSON(含
thought推理链 + 行动参数) - 行动:解析 JSON,调用对应 API
python
{
"system": "角色系统提示词(策略指导)",
"user": """
=== 当前局面 ===
第 N 回合,阶段:day_discuss
存活玩家:p1(张三), p3(王五)[seer?]...
已死亡:p2(李四)[?]
历史发言记录(过往回合):
--- 第1回合 ---
[p1(张三)]: 我觉得p4有点可疑...
本回合发言记录:
[p3(王五)]: 我是预言家,昨晚验了p6是狼人!
请输出 JSON: {"thought": "推理...", "content": "发言内容"}
"""
}5.3 多模型分配
不同玩家分配了不同性能的模型,观察推理能力差异:
python
_MODEL_MAP = {
"p1": "Pro/deepseek-ai/DeepSeek-R1", # 推理模型,适合预言家/村民
"p2": "Pro/deepseek-ai/DeepSeek-R1",
"p3": "deepseek-ai/DeepSeek-V3",
"p4": "deepseek-ai/DeepSeek-V3",
"p5": "deepseek-ai/DeepSeek-V3",
"p6": "Qwen/Qwen2.5-72B-Instruct",
"p7": "Qwen/Qwen2.5-72B-Instruct",
"p8": "Qwen/Qwen2.5-72B-Instruct",
}六、狼人协作:共识驱动的击杀机制
我实现了一个投票共识机制:
每名狼人的私语不仅包含讨论内容,还携带一个 target_id 表明自己支持的击杀目标。每轮全员发言后检查所有狼人的目标是否一致:
- 一致 → 立即进入击杀阶段
- 不一致 → 继续讨论,最多 3 轮
- 3轮仍未统一 → 强制进入击杀阶段
前端的狼人频道会显示所有历史私语,清晰呈现共识达成过程
第1轮
狼A:我建议杀p3,他发言太积极了,很可能是预言家
狼B:同意,p3昨天的发言方向一直在试探我们,目标p3
→ 系统检测:目标一致(p3),进入击杀阶段
七、踩过的坑
坑1:AI 返回字符串 "null" 导致猎人永久卡死
猎人出局后,Agent 决定放弃开枪,LLM 返回了:
python
{"target_id": "null"}而非 {"target_id": null}。系统把 "null" 当作了一个合法的 player_id,调用 hunter_shoot("null") 报错,游戏陷入死循环。
解决方案:在 _clean_id 函数中显式处理字符串形式的空值:
python
if str(raw).strip().lower() in ("null", "none", "空", "无"):
return None坑2:预言家给狼人发"金水"(误判为好人)
发现 Agent 一夜查到某玩家是狼人,第二天白天发言时却说对方是好人。
根因:seer_result 每夜只存当晚结果,进入白天后被清空,LLM 没有历史上下文,只好凭空捏造。
解决方案:新增 seer_history: dict[str, str] 字段永久保存所有查验结果,并在预言家的每次 Prompt 中注入:
你的历史验人记录(真实结果,请如实运用):
p6(赵六) → 【狼人】
p2(李四) → 【好人】
坑3:CORS 端口问题
前端 Vite 每次启动可能使用不同的端口(5173~5176+),后端的 CORS 白名单写死了端口就会报 Network Error。
解决方案:改用正则匹配所有本地端口:
python
app.add_middleware(
CORSMiddleware,
allow_origin_regex=r"http://(127\.0\.0\.1|localhost)(:\d+)?",
...
)八、最终效果
- 游戏可稳定运行至结束,通常持续 3-5 个完整回合
- 狼人能合理伪装,白天发言不会主动暴露身份
- 预言家会在合适时机"跳出",公布验人信息并进行逻辑自证
- 村民能根据发言内容和投票行为做出有据可查的推理
- 游戏结束后弹窗公示胜利方及所有玩家真实身份
九、项目结构
werewolf/
├── main.py # FastAPI 后端,API 路由,信息脱敏
├── game_engine.py # 游戏状态机,规则引擎
├── models.py # Pydantic 数据模型
├── agent.py # AI Agent,Prompt 构建,LLM 调用
├── ai_manager.py # Agent 进程管理,多模型分配
├── human_client.py # 命令行真人客户端(调试用)
└── src/ # React 前端
├── pages/GameRoom.tsx # 游戏主界面
├── pages/Lobby.tsx # 大厅页面
├── services/api.ts # API 封装
└── hooks/useGameState.ts
十、总结与展望
本项目完整实现了一个真人+AI混战的狼人杀系统,验证了 LLM 在信息不对称多智能体博弈场景中的能力边界。
主要发现:
- LLM 在短期单轮推理上表现尚可,但跨轮记忆需要工程层面的显式支持(History Injection)
- 狼人的伪装策略整体有效,很少会主动暴露身份
- 预言家是关键角色,其记忆的准确性直接影响好人阵营的存活率
后续可探索方向:
- 引入向量数据库实现真正的 Agent 长期记忆,而非依赖 Prompt 注入
- 设计更复杂的角色(守卫、白痴、白狼王等)
- 记录多局对战数据,量化分析不同模型在欺骗/推理上的表现差异

本人目前在读本科,有相关问题欢迎添加微信与我交流vx:15735002648,或者有更好的意见可以提出