Qwen3.5 架构学习笔记
一、核心差异
从 Qwen2.5 3B 到 Qwen3 4B,再到 Qwen3.5 4B,模型架构经历了从标准纯文本密集型 Transformer 向原生多模态(支持视觉/视频)、混合架构(线性注意力/Mamba 与全注意力交替)及引入多 Token 预测(MTP)的演进。
二、核心参数与架构对比
| 核心参数维度 | Qwen2.5 (3B) | Qwen3 (4B) | Qwen3.5 (4B) |
|---|---|---|---|
| 模型架构类型 | Qwen2ForCausalLM (纯文本) | Qwen3ForCausalLM (纯文本) | Qwen3_5ForConditionalGeneration (多模态混合) |
| 支持模态 | 纯文本 | 纯文本 | 文本、图像 (Image)、视频 (Video) |
| 注意力机制 | 全局注意力 (Full Attention) | 全局注意力 (Full Attention) | 混合注意力 (3层线性/Mamba + 1层全注意力) |
| 隐藏层维度 (Hidden Size) | 2048 | 2560 | 2560 |
| 中间层维度 (FFN Size) | 11008 | 9728 | 9216 |
| 网络层数 (Hidden Layers) | 36 层 | 36 层 | 32 层 (Text) + 24 层 (Vision) |
| 注意力头数 (Q / KV) | 16 / 2 | 32 / 8 | 16 / 4 |
| 词表大小 (Vocab Size) | 151,936 | 151,936 | 248,320 |
| 最大上下文长度 | 32,768 (32K) | 40,960 (40K) | 262,144 (262K) |
| 位置编码 (RoPE) | 标准 RoPE | 标准 RoPE | M-RoPE (多模态交错旋转位置编码) |
| MTP (多 Token 预测) | 无 | 无 | 有 (mtp_num_hidden_layers: 1) |
| 视觉编码器配置 | 无 | 无 | ViT 架构 (1024 隐藏层, 16×16 Patch, 时空合并) |
三、对比表格详解
A. 架构底层逻辑的突变 --- 注意力机制
- Qwen2.5 3B & Qwen3 4B:传统 Transformer,每层均为标准全注意力(Full Attention)。随上下文长度增加,计算量呈平方级增长,显存压力大。
- Qwen3.5 4B :引入混合架构 。
layer_types中呈现规律性的[线性, 线性, 线性, 全局]分布,且配置出现了mamba_ssm_dtype,结合了 Mamba/状态空间模型(线性复杂度)与传统 Transformer 的优势,在保持强推理能力的同时解决了超长文本的显存瓶颈。
B. 多模态的原生支持 --- Vision & Video
- 前两代是纯文本大语言模型。
- Qwen3.5 4B 变为"大一统"的条件生成模型,内部嵌套了强大的视觉塔(Vision Config),支持图像和视频特征提取(
temporal_patch_size代表对视频时间轴的理解),并引入image_token_id和video_token_id,使模型能够像阅读文字一样直接"看"图和视频。
C. 上下文长度与位置编码
- 上下文大幅提升 :Qwen3.5 将最大上下文从 32K/40K 直接拉升到 262K,得益于混合注意力架构。
- M-RoPE 机制 :处理图片和视频时,传统 1D 文本位置编码不足,需要 2D(图像)乃至 3D(视频)的位置编码。M-RoPE (
mrope_interleaved) 将不同模态的位置信息优雅融合。
D. 词表扩展
- Qwen2.5 和 Qwen3 词表维持在 151,936。
- Qwen3.5 4B 扩大到 248,320,新增的约 10 万 Token 用于:
- 容纳多模态特殊占位符和视觉特征
- 大幅优化多语言(尤其是小语种)的编码效率
E. 多 Token 预测 (MTP)
- 配置中
mtp_num_hidden_layers: 1表明模型推理时不仅预测下一个词,而是可能同时预测多个词(类似前瞻解码),实际部署中可成倍提升文本生成吞吐速度、降低延迟。
F. 参数重分配
- 从 3B 到 4B,模型"宽度"(Hidden Size 从 2048 增至 2560)变大,可存储更多知识。
- Qwen3.5 中,为给多模态模块(24 层视觉编码器)腾出参数预算,文本端层数从 36 层缩减至 32 层,FFN 中间层维度也有所收缩。
四、Qwen3.5 架构详细说明
4.1 特征融合:视觉 Embedding 注入文本序列
整体思路: 输入序列中,图片/视频位置用特殊占位符 token(image_token_id / video_token_id)预留。推理时,视觉编码器输出的 embedding 被「原地填充」到这些占位符对应的位置,之后文本和视觉 token 共同进入语言模型。
输入 token 序列: [文字] [文字] [<img>] [<img>] [<img>] [文字]
↑ ↑ ↑
占位符(由 image_token_id 标记)
视觉编码器输出: [img_emb_0] [img_emb_1] [img_emb_2]
融合后的 embeds: [文字emb] [文字emb] [img_emb_0] [img_emb_1] [img_emb_2] [文字emb]第一步:调用视觉编码器,得到图像 embedding
python
if pixel_values is not None:
image_outputs = self.get_image_features(pixel_values, image_grid_thw, return_dict=True)
image_embeds = image_outputs.pooler_output # 取池化后的特征
image_embeds = torch.cat(image_embeds, dim=0) # 多图拼成一条
image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype)pixel_values 是原始图像像素,经过 ViT 编码后输出视觉特征向量,维度与文本 hidden_size 对齐,才能无缝拼接。
第二步:定位占位符位置,生成布尔 mask
python
image_mask, _ = self.get_placeholder_mask(
input_ids, inputs_embeds=inputs_embeds, image_features=image_embeds
)get_placeholder_mask 扫描 input_ids,找出所有值等于 image_token_id 的位置,返回一个与 inputs_embeds 同形的布尔张量 image_mask(True = 该位置是图片占位符)。
第三步:原地填充 ------ masked_scatter
python
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)masked_scatter 是 PyTorch 的高效原地写操作:把 image_embeds 中的元素,按顺序填入 inputs_embeds 里所有 image_mask == True 的位置。视频的处理完全对称:
python
if pixel_values_videos is not None:
video_outputs = self.get_video_features(pixel_values_videos, video_grid_thw, return_dict=True)
video_embeds = video_outputs.pooler_output
video_embeds = torch.cat(video_embeds, dim=0).to(inputs_embeds.device, inputs_embeds.dtype)
_, video_mask = self.get_placeholder_mask(
input_ids, inputs_embeds=inputs_embeds, video_features=video_embeds
)
inputs_embeds = inputs_embeds.masked_scatter(video_mask, video_embeds)注意
get_placeholder_mask返回两个值:(image_mask, video_mask),图像分支只取第一个,视频分支只取第二个。
4.2 M-RoPE --- 多模态 3D 位置编码
为什么需要 M-RoPE?
标准 RoPE 给每个 token 分配一个整数位置(0, 1, 2, ...),对纯文本完全够用。但图像/视频本质是二维/三维结构:一张图被切成 H×W 个 patch,一段视频是 T×H×W 个 patch。如果强行展平成 1D 序列编号,空间关系就丢失了。
M-RoPE 的解法是:把每个 token 的位置分拆成 3 个独立整数(T, H, W),分别用于旋转编码的三份头维度。文本 token 的三维位置相同(退化为 1D),视觉 token 保留真实的 2D/3D 坐标。
维度划分(head_dim=32):
T 轴 → 头维度 [0 .. 10] (11 维)
H 轴 → 头维度 [11 .. 21] (11 维)
W 轴 → 头维度 [22 .. 31] (10 维)
合计 → 11 + 11 + 10 = 32 ✓
空间合并(spatial_merge_size=4):
原始 ViT patch 数 = 256
合并后 LLM 实际看到的 token 数 = 64
压缩比 = 64 / 256 = 0.25compute_3d_position_ids --- 入口函数
该函数是 M-RoPE 的调度层,核心是决定「是重新计算位置,还是复用缓存」。
第一步:判断是否满足 M-RoPE 计算条件
python
past_key_values_length = 0 if past_key_values is None else past_key_values.get_seq_length()
can_compute_mrope = (
input_ids is not None
and mm_token_type_ids is not None # 必须有模态类型标记
and (image_grid_thw is not None or video_grid_thw is not None) # 必须有视觉输入
)mm_token_type_ids 是与 input_ids 等长的整数序列,标记每个位置属于哪种模态:0=文本, 1=图像, 2=视频。没有它就无法区分各 token 应分配哪种坐标。
第二步:首次计算(Prefill 阶段,尚无缓存)
python
if can_compute_mrope and (self.rope_deltas is None or past_key_values_length == 0):
position_ids, rope_deltas = self.get_rope_index(
input_ids,
image_grid_thw=image_grid_thw,
video_grid_thw=video_grid_thw,
attention_mask=attention_mask,
mm_token_type_ids=mm_token_type_ids,
)
self.rope_deltas = rope_deltas # 缓存偏移量,供后续增量推理复用rope_deltas 记录了"视觉 token 展开后,位置序列比原始 token 序列多出多少个位置"。这个偏移量一旦计算好就固定不变,后续 Decode 阶段直接加上去即可。
第三步:增量推理(Decode 阶段,每次只有 1 个新 token)
python
elif self.rope_deltas is not None:
batch_size, seq_length, _ = inputs_embeds.shape
if attention_mask is not None:
# 从 attention_mask 中还原 token 的真实位置(跳过 padding)
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids = position_ids.masked_fill(attention_mask == 0, 0)
# 三份坐标轴(T/H/W)初始值相同,后续由 delta 区分
position_ids = position_ids.view(1, batch_size, -1).repeat(3, 1, 1).to(inputs_embeds.device)
else:
position_ids = torch.arange(past_key_values_length, past_key_values_length + seq_length)
position_ids = position_ids.view(1, 1, -1).expand(3, batch_size, -1).to(inputs_embeds.device)
# 加上预计算的偏移量,还原真实的 3D 位置
delta = self.rope_deltas.repeat_interleave(batch_size // self.rope_deltas.shape[0], dim=0)
position_ids = position_ids + delta.to(device=inputs_embeds.device)第四步:回退(纯文本输入,无视觉信息)
python
else:
position_ids = None # 退回由 cache_position 处理,等同于标准 RoPEget_rope_index --- 核心计算函数
负责遍历整个序列,逐段分配 3D position_ids。
第一步:视频帧拆分预处理
python
if video_grid_thw is not None:
# 原始 video_grid_thw shape: (num_videos, 3),每行是 [T, H, W]
# 按 T 帧数展开:一个 T=5 的视频 → 5 行 [1, H, W]
video_grid_thw = torch.repeat_interleave(video_grid_thw, video_grid_thw[:, 0], dim=0)
video_grid_thw[:, 0] = 1Qwen3.5 用时间戳 token(<t1>, <t2>...)分隔视频帧,每帧在序列中是独立的一段视觉区域。因此需要把一个多帧视频的 grid 拆成逐帧的单独 grid,才能按时间戳位置一一对应。
第二步:初始化输出容器
python
position_ids = torch.zeros(3, batch_size, seq_length, dtype=..., device=...)
# shape: (3, B, L) ------ 3 对应 T/H/W 三个坐标轴
grid_iters = {
1: iter(image_grid_thw) if image_grid_thw is not None else None, # 图像队列
2: iter(video_grid_thw) if video_grid_thw is not None else None, # 视频帧队列
}grid_iters 是两个迭代器,遍历序列时每遇到一块图像/视频区域就 next() 取下一个 grid 描述。
第三步:按模态逐段填充位置
python
for batch_idx, current_input_ids in enumerate(input_ids):
input_token_type = mm_token_type_ids[batch_idx]
# 用 itertools.groupby 把 [0,0,1,1,1,0,2,2] 压缩为连续段
# 结果形如:[(0, 0, 2), (1, 2, 5), (0, 5, 6), (2, 6, 8)]
# 模态 起始 结束
input_type_group = [...]
current_pos = 0 # 当前"光标"位置(在位置空间中递增)
for modality_type, start_idx, end_idx in input_type_group:文本段:三轴坐标相同,线性递增
python
if modality_type == 0:
text_len = end_idx - start_idx
# 三轴 (T/H/W) 分配相同的 1D 位置,退化为标准 RoPE
llm_pos_ids_list.append(
torch.arange(text_len).view(1, -1).expand(3, -1) + current_pos
)
current_pos += text_len视觉段:调用 get_vision_position_ids 生成 2D/3D 坐标
python
else:
grid_thw = next(grid_iters[modality_type]) # 取出这块视觉区域的 [T, H, W]
vision_position_ids = self.get_vision_position_ids(
current_pos, grid_thw, 1, spatial_merge_size, device=...
)
llm_pos_ids_list.append(vision_position_ids)
# 位置光标推进:取 H、W 中较大值除以合并尺寸
# 图像 token 在位置空间中只"占用"一行的宽度(视觉 token 共享 T 轴起点)
current_pos += max(grid_thw[1], grid_thw[2]) // spatial_merge_size第四步:计算 rope_delta 并写回
python
llm_positions = torch.cat(llm_pos_ids_list, dim=1).reshape(3, -1)
position_ids[:, batch_idx, ...] = llm_positions
# rope_delta = 位置空间的最大值 + 1 - 实际 token 数
# 代表"视觉展开后位置编号超出 token 数量的偏移"
mrope_position_deltas.append(llm_positions.max() + 1 - len(current_input_ids))4.3 混合解码器层 (Hybrid Decoder Layer)
层类型分配逻辑
每 4 层为一个周期,前 3 层用线性注意力(低成本),第 4 层用全注意力(高精度),平衡效率与能力:
python
interval_pattern = kwargs.get("full_attention_interval", 4)
self.layer_types = [
"linear_attention" if bool((i + 1) % interval_pattern) else "full_attention"
for i in range(self.num_hidden_layers)
]
# 生成结果: [线性, 线性, 线性, 全局, 线性, 线性, 线性, 全局, ...]
# i=0: (0+1)%4=1 → True → linear
# i=1: (1+1)%4=2 → True → linear
# i=2: (2+1)%4=3 → True → linear
# i=3: (3+1)%4=0 → False → full ✓Qwen3_5GatedDeltaNet --- 线性注意力层详解
__init__:参数定义
① 维度定义
python
self.num_v_heads = config.linear_num_value_heads # Value 头数
self.num_k_heads = config.linear_num_key_heads # Key 头数(通常 < Value 头数)
self.head_k_dim = config.linear_key_head_dim # 每个 K 头的维度
self.head_v_dim = config.linear_value_head_dim # 每个 V 头的维度
self.key_dim = self.head_k_dim * self.num_k_heads
self.value_dim = self.head_v_dim * self.num_v_heads注意 K 头数可以少于 V 头数,后续 forward 中会用 repeat_interleave 补齐(类似 GQA 的做法)。
② 因果卷积(局部依赖提取)
python
self.conv_dim = self.key_dim * 2 + self.value_dim # Q+K+V 全部进卷积
self.conv1d = nn.Conv1d(
in_channels=self.conv_dim,
out_channels=self.conv_dim,
kernel_size=self.conv_kernel_size,
groups=self.conv_dim, # 深度可分离:每个通道独立卷积,计算量极低
padding=self.conv_kernel_size - 1, # 因果填充,确保不看到未来 token
bias=False,
)卷积的作用是在线性注意力之前,给 Q/K/V 注入短程局部上下文(类似 Mamba 的 conv1d 前置步骤),弥补线性注意力不善于捕捉局部细节的弱点。
③ Mamba 离散化参数
python
self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads)) # 时间步偏置
A = torch.empty(self.num_v_heads).uniform_(0, 16)
self.A_log = nn.Parameter(torch.log(A)) # 遗忘衰减的对数值A_log 控制记忆的衰减速率(g = -exp(A_log) * softplus(a + dt_bias)),每个 head 独立学习自己的遗忘节奏。存 log 是为了保证 exp 后的值永远为正,数值更稳定。
④ 四个输入投影
python
self.in_proj_qkv = nn.Linear(hidden_size, key_dim*2 + value_dim) # Q + K + V 合并投影
self.in_proj_z = nn.Linear(hidden_size, value_dim) # 门控信号 z
self.in_proj_b = nn.Linear(hidden_size, num_v_heads) # β:写入强度
self.in_proj_a = nn.Linear(hidden_size, num_v_heads) # α:衰减控制(输入相关)相比标准 Transformer 只有 Q/K/V 三个投影,这里多了 z(输出门)、b(beta,控制本 token 对记忆的写入程度)、a(与 dt_bias 一起计算动态遗忘率 g)。
forward:推理流程
第一步:判断推理阶段,加载缓存
python
use_precomputed_states = (
cache_params is not None
and cache_params.has_previous_state
and seq_len == 1 # seq_len==1 意味着 Decode 阶段(逐 token 生成)
)
if cache_params is not None:
conv_state = cache_params.conv_states[self.layer_idx] # 卷积的滑动窗口状态
recurrent_state = cache_params.recurrent_states[self.layer_idx] # 线性注意力的记忆矩阵线性注意力的 KV Cache 不是存所有历史 K/V(那样会随序列增长),而是压缩成一个固定大小的「记忆矩阵」recurrent_state,shape 为 (B, H, k_dim, v_dim)。
第二步:投影 + 因果卷积
python
mixed_qkv = self.in_proj_qkv(hidden_states) # (B, L, key_dim*2 + value_dim)
mixed_qkv = mixed_qkv.transpose(1, 2) # → (B, channels, L),Conv1d 要求这个顺序
z = self.in_proj_z(hidden_states) # 门控信号,不经过卷积
b = self.in_proj_b(hidden_states) # β,每个 head 一个标量
a = self.in_proj_a(hidden_states) # α,用于计算遗忘率Decode 阶段(seq_len == 1):用滚动更新替代重新卷积
python
if use_precomputed_states:
# causal_conv1d_update 只更新滑动窗口,不重新处理整段序列
mixed_qkv = self.causal_conv1d_update(mixed_qkv, conv_state, ...)Prefill 阶段(seq_len > 1):并行处理整段序列
python
else:
if cache_params is not None:
# 保存卷积窗口的末尾状态,供下一步 Decode 用
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
cache_params.conv_states[self.layer_idx] = conv_state
# 优先用 CUDA 融合实现;若不可用则回退到标准 Conv1d + silu
if self.causal_conv1d_fn is not None:
mixed_qkv = self.causal_conv1d_fn(x=mixed_qkv, weight=..., bias=..., activation=...)
else:
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])第三步:拆分 Q/K/V,计算动态参数
python
mixed_qkv = mixed_qkv.transpose(1, 2) # 转回 (B, L, channels)
query, key, value = torch.split(mixed_qkv, [key_dim, key_dim, value_dim], dim=-1)
query = query.reshape(B, L, num_k_heads, head_k_dim)
key = key.reshape(B, L, num_k_heads, head_k_dim)
value = value.reshape(B, L, num_v_heads, head_v_dim)
beta = b.sigmoid() # β ∈ (0,1):控制写入记忆的强度,0=不写,1=全写
# 遗忘率 g:负值取 exp 后 < 1,确保记忆是衰减的而不是增长的
# fp16 下 A_log.float() 防止 -exp(A_log) 溢出为 -inf
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias)若 V head 数多于 K head 数,用 repeat_interleave 扩展 Q/K(等价于 GQA 的反向操作):
python
if self.num_v_heads // self.num_k_heads > 1:
query = query.repeat_interleave(num_v_heads // num_k_heads, dim=2)
key = key.repeat_interleave(num_v_heads // num_k_heads, dim=2)第四步:线性注意力核心计算
python
# Prefill:chunk 模式,并行处理整段,利用矩阵分块减少复杂度
if not use_precomputed_states:
core_attn_out, last_recurrent_state = self.chunk_gated_delta_rule(
query, key, value, g=g, beta=beta,
initial_state=None,
output_final_state=(cache_params is not None),
use_qk_l2norm_in_kernel=True, # 对 Q/K 做 L2 归一化,稳定训练
)
# Decode:recurrent 模式,用上一步保存的记忆矩阵逐 token 更新
else:
core_attn_out, last_recurrent_state = self.recurrent_gated_delta_rule(
query, key, value, g=g, beta=beta,
initial_state=recurrent_state, # 传入上一步的记忆矩阵
output_final_state=(cache_params is not None),
use_qk_l2norm_in_kernel=True,
)
# 更新 KV Cache 中的记忆矩阵
if cache_params is not None:
cache_params.recurrent_states[self.layer_idx] = last_recurrent_state第五步:门控归一化 + 输出投影
python
core_attn_out = core_attn_out.reshape(-1, head_v_dim)
z = z.reshape(-1, head_v_dim)
core_attn_out = self.norm(core_attn_out, z) # RMSNorm + 门控(z 充当输出门)
core_attn_out = core_attn_out.reshape(B, L, -1)
return self.out_proj(core_attn_out) # 投影回 hidden_sizez 作为门控信号与 core_attn_out 一起送入 RMSNormGated,相当于用输入自适应地"筛选"注意力输出的哪些维度应该被保留,类似 LSTM 的输出门。
torch_recurrent_gated_delta_rule --- 记忆矩阵更新原理
这是线性注意力的数学核心。把整个机制类比成一块「可读写的记忆黑板」S(shape k_dim × v_dim):
每步做三件事:
1. 遗忘:S = S * g_t (按 head 独立衰减旧信息)
2. 检索:m = k_t @ S (用当前 key 从黑板上读出相关内容)
3. 纠错写入:
delta = (v_t - m) * β_t (v_t 是真实值,m 是读到的,差值是误差)
S = S + k_t ⊗ delta (把纠正量写回黑板,outer product)
4. 读取输出:out_t = q_t @ S (用 query 从更新后的黑板上读取)
python
def torch_recurrent_gated_delta_rule(...):
# ── 预处理 ──────────────────────────────────────────────────
if use_qk_l2norm_in_kernel:
query = l2norm(query, dim=-1, eps=1e-6) # Q/K 归一化,防止内积爆炸
key = l2norm(key, dim=-1, eps=1e-6)
# 统一转 float32,防止 fp16 累积误差
query, key, value, beta, g = [x.transpose(1,2).contiguous().to(torch.float32)
for x in (query, key, value, beta, g)]
scale = 1 / (query.shape[-1] ** 0.5) # 缩放因子,对齐 softmax 注意力的量级
query = query * scale
# ── 初始化记忆矩阵 ──────────────────────────────────────────
# S 的 shape:(B, num_heads, k_dim, v_dim)
# 可理解为:每个 head 独立维护一个 k_dim × v_dim 的"联想记忆"
last_recurrent_state = (
torch.zeros(B, num_heads, k_dim, v_dim)
if initial_state is None else initial_state
).to(value)
# ── 逐 token 更新 ────────────────────────────────────────────
for i in range(sequence_length):
q_t = query[:, :, i] # (B, H, k_dim)
k_t = key[:, :, i] # (B, H, k_dim)
v_t = value[:, :, i] # (B, H, v_dim)
g_t = g[:, :, i].exp().unsqueeze(-1).unsqueeze(-1) # (B, H, 1, 1)
beta_t = beta[:, :, i].unsqueeze(-1) # (B, H, 1)
# 步骤 1:遗忘旧记忆
last_recurrent_state = last_recurrent_state * g_t
# 步骤 2:从记忆中检索
# last_recurrent_state * k_t.unsqueeze(-1) 相当于 S * k^T(broadcast 乘法)
# .sum(dim=-2) 沿 k_dim 收缩,等价于 k @ S
kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2) # (B, H, v_dim)
# 步骤 3:Delta Rule 纠错写入
delta = (v_t - kv_mem) * beta_t # (B, H, v_dim)
# k_t.unsqueeze(-1) * delta.unsqueeze(-2) = outer product k ⊗ delta
# shape: (B, H, k_dim, 1) * (B, H, 1, v_dim) → (B, H, k_dim, v_dim)
last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
# 步骤 4:用 Q 读取输出
# 同理,q @ S
core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2)
return core_attn_out.transpose(1,2).to(initial_dtype), last_recurrent_state为什么叫 "Delta Rule"? 这是源自神经网络早期的 Widrow-Hoff 学习规则:
W += lr * (target - prediction) * input。这里的(v_t - kv_mem)正是预测误差,beta_t是学习率,k_t是输入。模型相当于在每个前向步骤里对记忆矩阵做一次在线梯度更新。
4.4 Vision-Language Alignment --- 视觉 Patch 嵌入
Qwen3_5VisionPatchEmbed 解决的问题:把一段原始像素映射成视觉 token embedding。
① __init__:定义 3D 卷积核
python
kernel_size = [self.temporal_patch_size, self.patch_size, self.patch_size]
# T(时间帧数) H(高度块大小) W(宽度块大小)
self.proj = nn.Conv3d(
in_channels=self.in_channels, # 输入通道数(如 RGB=3)
out_channels=self.embed_dim, # 输出维度 = LLM hidden_size(对齐文本)
kernel_size=kernel_size,
stride=kernel_size, # stride = kernel_size → 无重叠切割(不重叠的 patch)
bias=True,
)stride=kernel_size 意味着卷积核恰好不重叠地扫描整个输入,每个 patch 独立输出一个 embedding,类似把图像/视频切成规则的小砖块再各自编码。
② forward:执行 patch 切割与嵌入
python
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# hidden_states 输入已预处理为一个大 batch:(N_patches, C*T*H*W)
# 先 reshape 回 5D(卷积需要的格式)
hidden_states = hidden_states.view(
-1, # N_patches(自动推断)
self.in_channels, # C
self.temporal_patch_size, # T
self.patch_size, # H
self.patch_size, # W
)
# 3D 卷积:(N, C, T, H, W) → (N, embed_dim, 1, 1, 1)
# 因为 stride=kernel_size,输出的空间维度全部为 1
hidden_states = self.proj(hidden_states.to(dtype=target_dtype))
# 压平为 (N, embed_dim),即 N 个视觉 token,每个维度 embed_dim
return hidden_states.view(-1, self.embed_dim)输入示意(单帧图像,patch_size=16,图像 224×224):
原始图像:(3, 224, 224)
切成 patch:14×14 = 196 个 patch,每个 (3, 16, 16)
reshape 后:(196, 3, 1, 16, 16) ← temporal=1(单帧)
Conv3d 后:(196, embed_dim, 1, 1, 1)
view 后: (196, embed_dim) ← 196 个视觉 token ✓4.5 静态编译注意事项
以下依赖库无法用于静态图导出 (如 torch.onnx.export):
python
if is_causal_conv1d_available():
from causal_conv1d import causal_conv1d_fn, causal_conv1d_update
else:
causal_conv1d_update, causal_conv1d_fn = None, None
if is_flash_linear_attention_available():
from fla.modules import FusedRMSNormGated
from fla.ops.gated_delta_rule import chunk_gated_delta_rule, fused_recurrent_gated_delta_rule
else:
chunk_gated_delta_rule, fused_recurrent_gated_delta_rule = None, None
FusedRMSNormGated = None导出前须强制走纯 PyTorch 备用实现 (
torch_recurrent_gated_delta_rule+ 标准nn.Conv1d)。底层 NPU 只支持最基础的加减乘 (*)、求和 (.sum) 及标准卷积算子。
4.6 Vision Attention --- 变长序列处理
Qwen3_5VisionAttention.forward 中使用了 Flash Attention 的变长序列变体(Varlen Flash Attention):
python
if is_flash_attention_requested(self.config):
# cu_seqlens 示例(3 张图,长度分别为 196, 256, 144):
# cu_seqlens = [0, 196, 452, 596]
# 差分后 = [196, 256, 144],即每张图的 token 数
max_seqlen = (cu_seqlens[1:] - cu_seqlens[:-1]).max()
attn_output, _ = attention_interface(
...
cu_seq_lens_q=cu_seqlens,
...
)不同图片/视频帧的 patch 数量不同(分辨率不同),如果用 padding 对齐再计算注意力,padding 位置白白消耗算力。
cu_seqlens让 Flash Attention 知道每段序列的真实边界,直接跳过 padding,显存和计算量都最优。
4.7 混合注意力机制参考框架图
from : Qwen3-Next
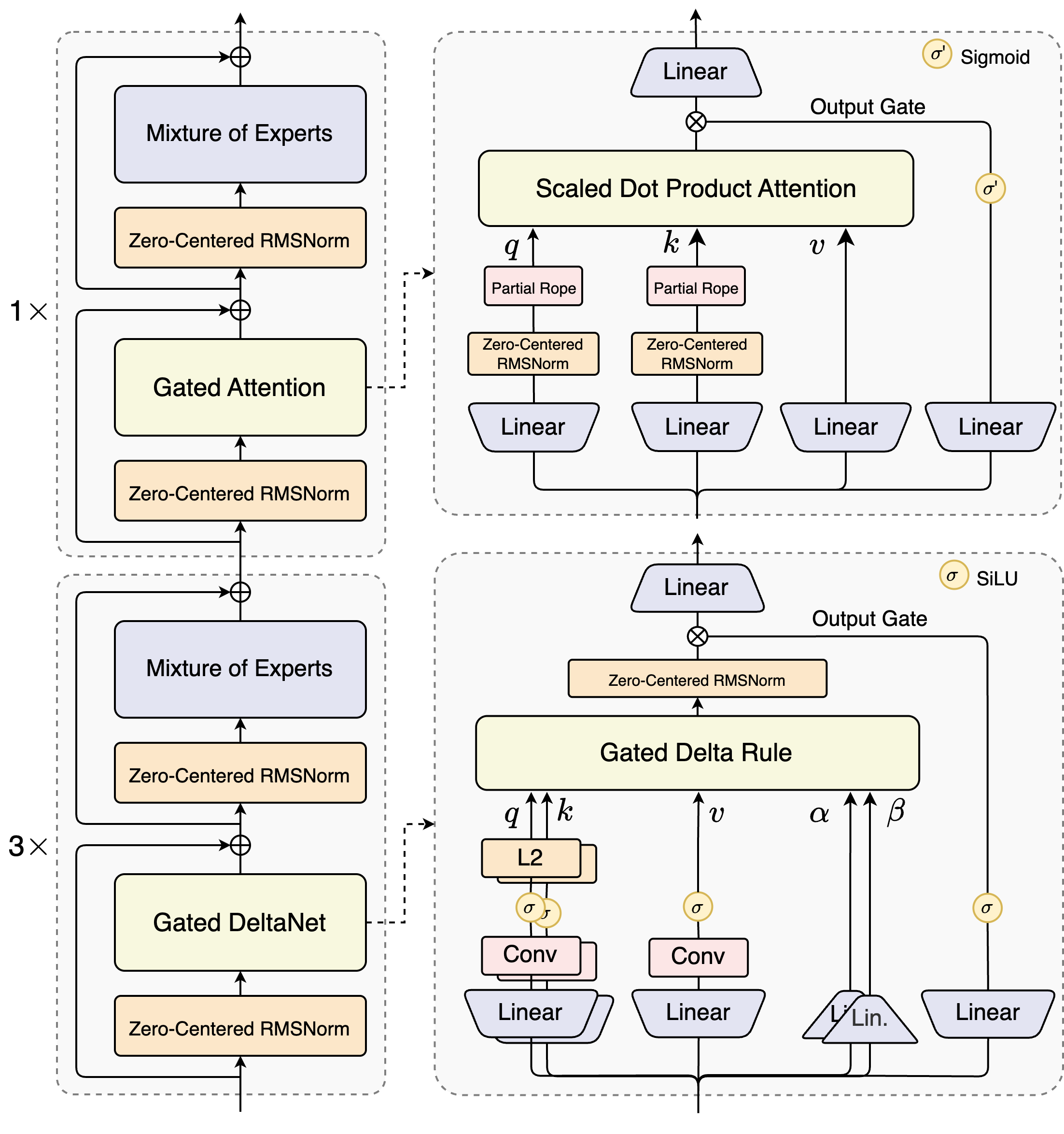
五、参考资料
-
[DeepSeek MTP 论文 (arXiv:2312.00752
)](https://arxiv.org/pdf/2312.00752 )
扩展阅读 --- 其他增加上下文长度的方向:
-
Dynamic Attention --- arXiv:2407.02490(https://arxiv.org/pdf/2407.02490
) -
Google Infini-Attention --- arXiv:2404.07143(https://arxiv.org/pdf/2404.07143
)