1. 图像变词序列
transformer只能处理序列,所以需要把图像变成"词序列"
怎么变?切patches!
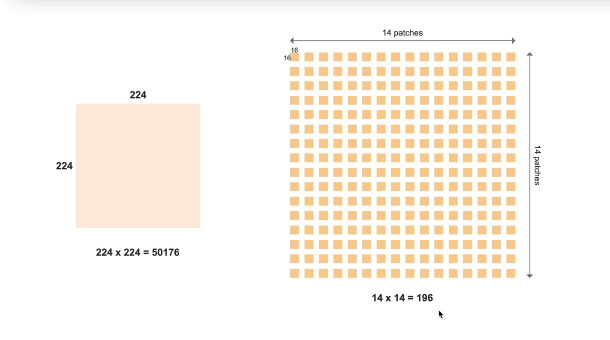
原始图像:224 × 224 = 50176 个像素 ↓ 切成 16×16 的小块(patch) ↓ 每行切 224/16 = 14 块 每列切 224/16 = 14 块 ↓ 总共:14 × 14 = 196 个patches每个patch变成"词向量"
一个patch:16×16 = 256 个像素 ↓ 展平 + 线性变换 → 512维向量(或其他维度) ↓ 变成一个"词"的embedding 196个patches → 196个"词"的序列 → 可以输入Transformer!
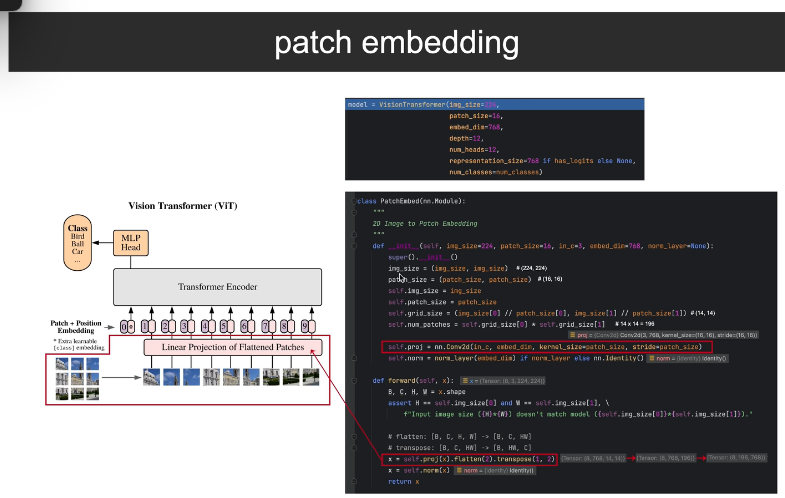
2. patch embedding
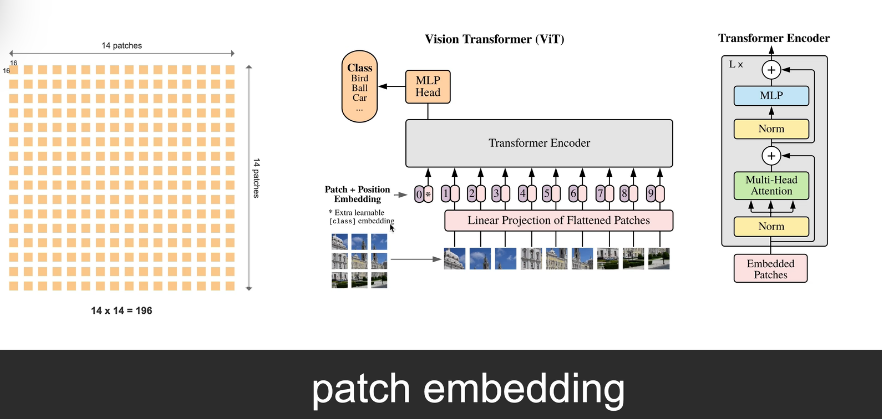
2.1 Linear Projection of Flattened Patches(粉色框)
一个patch:16×16×3 = 768个数字(RGB三通道展平)
↓
0.2, 0.5, 0.8, ..., 0.3 ← 768维向量
↓
乘 权重矩阵 W 768, 512
↓
0.1, -0.3, 0.7, ..., 0.2 ← 512维向量(patch embedding)
"Linear Projection" = 线性变换 = 全连接层 = 矩阵乘法

问:权重矩阵哪里来的?
权重矩阵 W 768, 512 是模型要学习的参数!
初始化:随机生成(比如正态分布)
训练:通过反向传播不断更新
最终:学会把"像素"变成"有意义的特征"
问:本来不就是768维吗?为啥还要统一?
切完patch后,每个patch确实都是768维(16×16×3=768)
但是!
768维太大了!
Transformer处理768维 × 196个token = 计算量爆炸
512维更合理,是人为设定的超参数(可以改,比如256、768都行)
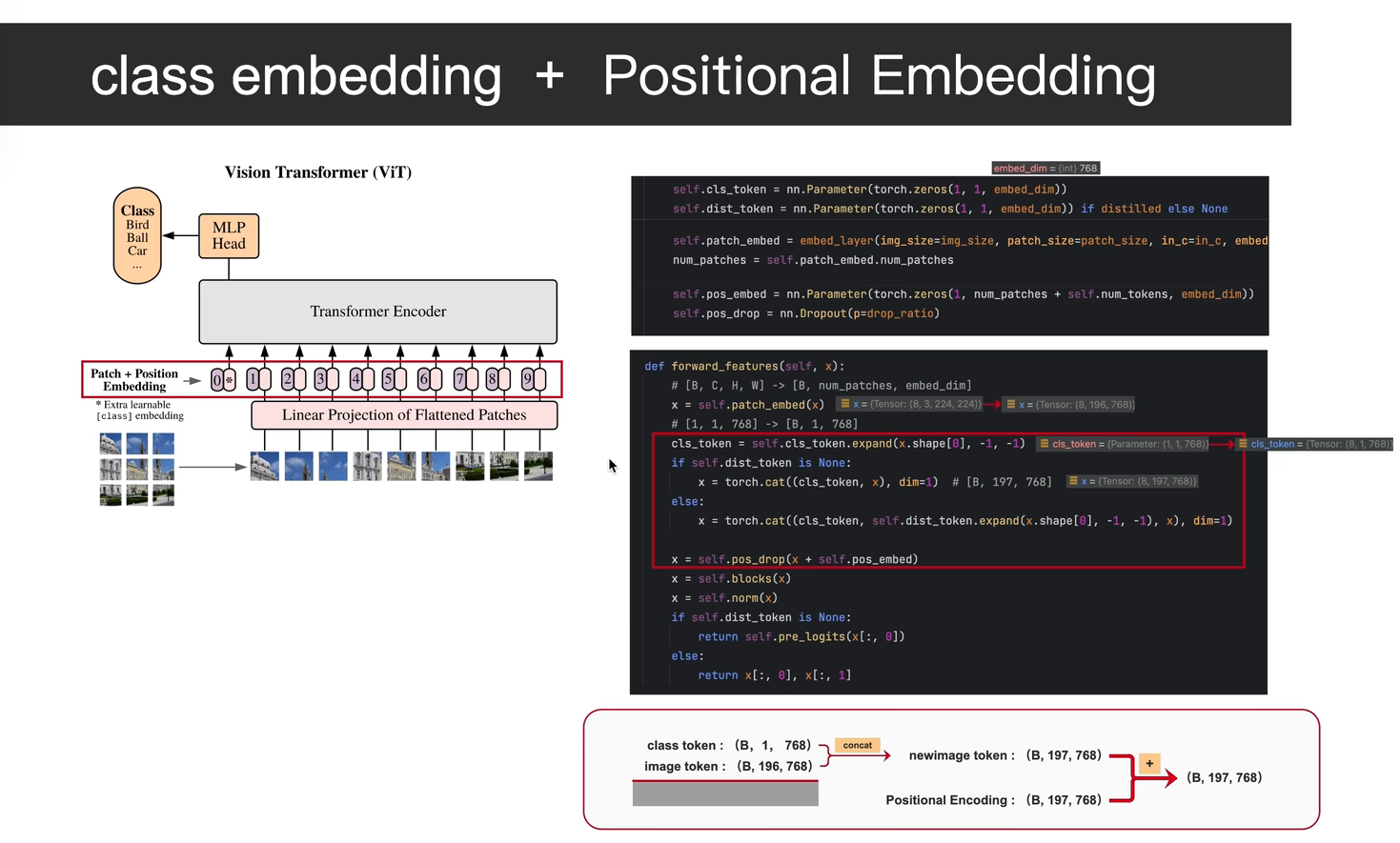
2.2"*Extra learnable class embedding"
**正确顺序:
- patch变成向量(196个)
- 加CLS(变成197个)
- 加位置编码(197个都加)**
CLS向量 + 位置0编码 → 第0个token
patch1向量 + 位置1编码 → 第1个token
patch2向量 + 位置2编码 → 第2个token
...
1 CLS是干啥的?

2.为啥需要cls?
Transformer输出197个向量,用哪个做分类?
patch1 patch2 ... patch196 ← 都只代表局部图像区域
↓ ↓ ↓
耳朵 鼻子 尾巴 ← 都不完整!
CLS的设计:
↓
法官 ← 听完所有人(所有patch)的陈述,做最终判决
CLS是一个额外加的可学习向量,放在第0位,通过Attention收集所有patch信息,专门用来做最终分类!它是token(序列中的一个角色),它的数值是学出来的参数! 🎯
3. 理解
CLS token = 一个特殊的"空容器"(可学习的向量),放在序列开头,训练后自动学会"收集所有patch的信息",最后用它做分类!
2.3 patch+position embedding
1. 为啥需要position embedding?
Transformer的本质问题 :Self-Attention是位置无关的!
打乱patch顺序,Self-Attention输出不变!
就像把句子"猫追老鼠"打乱成"老鼠猫追",模型觉得一样!但图像位置很重要:
眼睛应该在脸上面,不是在脚下面
天空在上方,地面在下方
2. position embedding是啥?
每个位置(1~196)对应一个可学习的向量:
位置1 → 0.1, -0.2, 0.5, ..., 0.3 ← 512维
位置2 → -0.3, 0.4, 0.1, ..., -0.2
位置3 → 0.5, 0.2, -0.1, ..., 0.4
...
位置196 → 0.2, -0.1, 0.3, ..., 0.5
这些向量也是模型学出来的!
position embedding的学习要求 ?
初始化:每个位置不一样就行
训练开始前,随机初始化:
位置1:0.1, -0.2, 0.5, ... ← 随机
位置2:-0.3, 0.4, 0.1, ... ← 随机,和位置1不同
...
位置196:0.2, -0.1, 0.3, ... ← 随机,和其他都不同
只要初始值不同,模型就能区分位置
训练后:自动学到位置关系
训练过程中,模型会发现:
位置1和位置2经常一起出现(相邻)
位置1和位置196很少相关(对角)
上面几行(位置1-14)都是天空
下面几行(位置183-196)都是地面
于是位置向量自动调整,让相邻位置的向量更相似!
3. 怎么加上去?
Patch Embedding(内容) Position Embedding(位置)
↓ ↓
0.5, -0.2, 0.3, ...\] + \[0.1, -0.2, 0.5, ...
↓ ↓
0.6, -0.4, 0.8, ... ← 相加后的最终输入
模型能"分析出位置"吗?
假设模型看到"猫耳朵"的patch:
它的内容向量 ≈ 0.8, 0.2, -0.5, ...(毛茸茸、三角形)
它的位置向量 ≈ 0.1, 0.4, 0.2, ...(左上角)
相加后 ≈ 0.9, 0.6, -0.3, ...
当Query去查其他Key时:
位置相近的patch,位置向量相似 → 点积大 → 注意力高
位置远的patch,位置向量不同 → 点积小 → 注意力低
结果:模型自然学会关注附近区域
位置向量只要初始不同,训练后自动学到"近邻相似、远邻不同",让模型知道谁和谁挨着!
4. 一些疑问?
4.1 位置向量:

4.2 patch怎么分配位置?
图像 14×14 = 196个patch
按空间顺序编号(行优先):
┌────┬────┬────┬────┐
│ 1 │ 2 │ 3 │... │ ← 第1行
├────┼────┼────┼────┤
│ 15 │ 16 │ 17 │... │ ← 第2行
├────┼────┼────┼────┤
│... │... │... │... │
└────┴────┴────┴────┘
patch(1,1) → 位置1的向量
patch(1,2) → 位置2的向量
...
patch(14,14) → 位置196的向量

空间相邻的patch,必须分配相邻的位置编号
加CLS + 加Position Embedding → 197个token
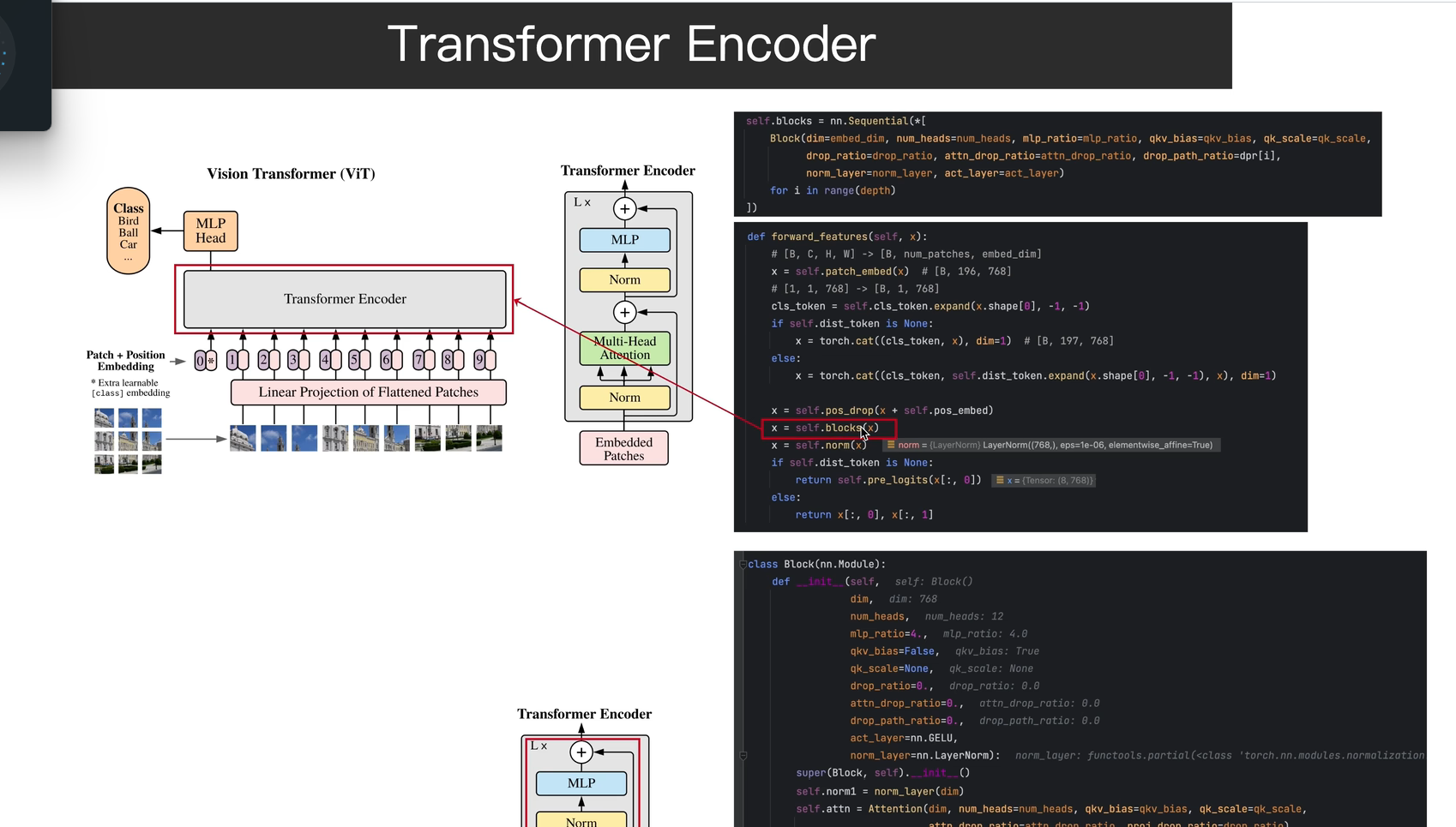
2.4 输入transformer encoder 处理
CLS\] + 196个patch(都加了位置编码)→ 197个token \[197, 512
↓
Transformer Encoder × L层
↓
输出197个向量 197, 512
↓
取第0个(CLS位置)→ MLP Head → 分类结果
transformer encoder 干啥?
每层重复:
Norm → Multi-Head Attention → 残差连接
Norm → MLP → 残差连接
作用:让每个token都"看"到所有其他token,融合全局信息
Token+Position之后 → 送进Transformer层层提炼 → 取CLS输出分类 🎯
MLP Head就是把CLS学到的全局特征,映射成具体类别概率的分类器! 🎯