什么是热点key问题?
热 key 问题指的是在某个瞬间,大量请求集中访问 Redis 里的同一个固定 key,这会造成缓存击穿,使得请求都直接涌向数据库,最终拖垮缓存服务和数据库服务,进而影响应用服务的正常运行。
像热点新闻、热点评论、明星直播这类读多写少的场景,很容易出现热点 key 问题。虽然 Redis 的查询性能比数据库高很多,但它也有性能上限,单节点查询性能一般在 2 万 QPS,所以对单个固定 key 的查询不能超过这个数值。
在服务端读取数据并进行分片切分(利用 Redis 的哈希槽)时,会在某个 Redis 节点主机 Server 上访问对应的 Key,如果对这个 Key 的访问量超过了该节点 Server 的承受极限,热点 Key 问题就会出现。
如何定义热key
热key的定义,通常以其接收到的Key被请求频率来判定,例如:
- QPS集中在特定的Key:Redis实例的总QPS为10,000,而其中一个Key的每秒访问量达到了7,000。那么这个key就算热key了。
- 带宽使用率集中在特定的Key:对一个拥有1000个成员且总大小为1 MB的HASH Key每秒发送大量的HGETALL操作请求。
- CPU使用时间占比集中在特定的Key:对一个拥有10000个成员的Key(ZSET类型)每秒发送大量的ZRANGE操作请求。
热key的危害
- 流量集中超网卡上限:热点 Key 请求过多,超过主机网卡流量上限,会使该节点服务器的其他服务无法运行。
- 打垮缓存分片服务:Redis 单点查询性能有限,热点 Key 查询超阈值会占用大量 CPU 资源,降低整体性能,严重时导致缓存分片服务崩溃(如 Redis 节点自重启),影响其他业务。
- 集群访问倾斜:在集群架构下,会出现某个数据分片被大量访问,其他分片空闲的情况,可能导致该分片连接数耗尽,新连接请求被拒。
- DB 击穿与业务雪崩:热 Key 请求超 Redis 承受能力致缓存击穿,缓存失效时大量请求直抵 DB 层,DB 性能弱,易引发雪崩,影响业务。在抢购或秒杀场景下,还可能因库存 Key 请求量过大造成超卖
如何发现热Key?
- 凭借业务经验预估:具有一定可行性,例如整点秒杀活动中,活动信息 key 和头部楼层秒杀商品信息 key 通常是热点 key。但并非所有热 key 都能准确预测,可借助商家历史活动数据分析作为参考。
- 业务侧自行监控收集:在操作 Redis 前添加代码进行数据统计并异步上报,类似日志采集,将 Redis 命令操作、结果、耗时等信息通过异步消息发送至采集消息队列。缺点是对代码有入侵性,可通过中间件集成在 Redis 二方包中。若有较好的 Daas 平台,可在 proxy 层监控,业务无感知,统一在平台查看监控。
- 使用 Redis 自带命令:
-
monitor 命令:能实时抓取 Redis 服务器接收的命令,可通过代码统计热 key,也有现成分析工具如 redis - faina。但在高并发下存在内存暴增隐患,且会降低 Redis 性能。
-
优点:这个方案的优点在于这个是 Redis 原生支持的功能,使用起来简单快捷。
-
缺点:monitor 非常消耗性能,单个客户端执行 monitor 就会损耗 50% 的性能!不推荐这个方式!
-
hotkeys 参数:Redis 4.0.3 提供此热点 key 发现功能,它是通过 scan + object freq 实现的。执行 redis - cli 时加 --hotkeys 选项即可。不过 key 较多时执行速度慢,且一般公司不允许直接连接 Redis 节点输入命令,多通过 Daas 平台查看热点 key 分析和监控 。
- 客户端收集:在操作 Redis 前添加统计 Redis 键值查询频次的逻辑,将统计数据发送到聚合计算平台计算,之后查看结果。
- 优点:对性能损耗较低。
- 缺点:成本较大,若企业没有聚合计算平台则需引入。
- 代理层收集 :利用有些服务在请求 Redis 前会先请求代理服务这一特点,在代理层统一收集 Redis 热 Key 数据。比如京东的JD-hotkey 、有赞的TMC中间件技术等
- 优点:客户端使用方便,无需考虑 SDK 多语言异构差异和升级成本高的问题。
- 缺点:需要为 Redis 定制代理层进行转发等操作,构建代理成本高,且转发存在性能损耗 。
如何解决热key
针对上面的Redis产生的原因以及危害,可以进行以下几个解决思路:
多级缓存
我之前自己写过一个简单的二级缓存框架(实现了本地缓存同步,注解操作多级缓存,监控内存使用情况等技术点),也是参考了阿里的jetcache开源框架,后面我会详细讲解。
解决热 key 问题主要靠加缓存,通过减少系统交互让用户请求提前返回,既能提升用户体验,又能减轻系统压力。缓存方式多样,可在客户端浏览器、就近 CDN、借助 Redis 等缓存框架以及服务器本地进行缓存。多种缓存结合使用便形成二级、三级等多级缓存,其目的是尽量缩短用户访问链路长度 。
如下图:
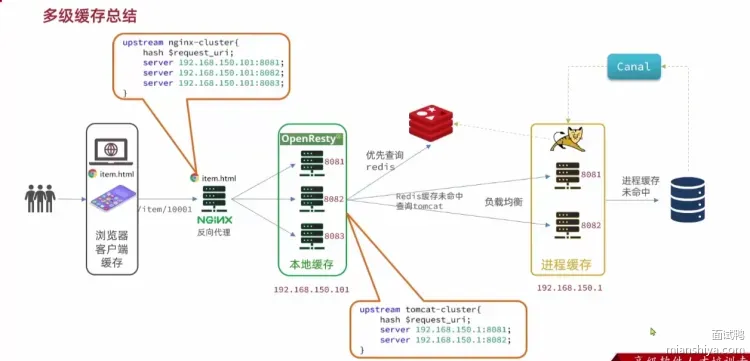
但通常应对热key时,二级缓存就是一种有效的解决方案。
使用本地缓存,如利用ehcache、GuavaCache、Caffeine等,甚至是一个HashMap都可以;在发现热key以后,把热key加载到系统的JVM中,针对这种热key请求,会直接从本地缓存中取,而不会直接请求redis;
本地缓存天然的将同一个key的大量请求,根据网络层的负载均衡,均匀分散到了不同的机器节点上,避免了对于固定key全部打到单个redis节点的情况,并且减少了1次网络交互;
当然,使用本地缓存不可避免的遇到的问题就是,对于要求缓存强一致性的业务来说,需要花费更多的精力在保证分布式缓存一致性上,会增加系统的复杂度;
热key备份
该方案旨在缓解 Redis 单点热 key 查询压力,具体做法是在多个 Redis 节点上备份热 key,避免固定 key 总是访问同一节点。通过在初始化时为 key 拼接 0 - 2N 之间的随机尾缀,使生成的备份 key 分散在各个节点上。在有热 key 请求时,随机选取一个备份 key 所在的节点进行访问取值,这样读写操作就不会集中于单个节点,从而有效减轻了单个 Redis 节点的负担,提升系统应对热 key 问题的能力。
流程如下:
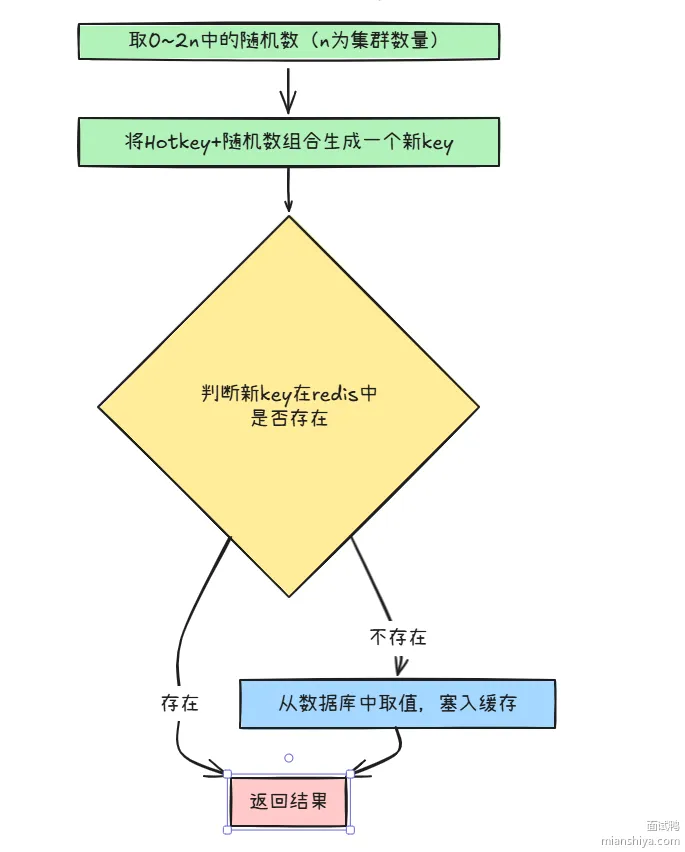
热key备份,是把一份数据全量复制到多个服务节点中,还有一种情况,我们可以使用热key拆分,两者主要的区别就是前者是一份数据全量复制多份 ,后者是一份数据拆分成多份。
热key拆分
将热 key 拆分成多个带后缀名的 key,分散存储到多个实例中。客户端请求时按规则算出固定 key,使多次请求分散到不同节点。以 "某抖音热搜" 为例,拆分成多个带编号后缀的 key 存储在不同节点,用户查询时根据用户 ID 算出下标访问对应节点。
虽用户可能只能获取部分数据,比如抖音中对于热点相关视频,可将其分散存储在不同节点并推送给不同用户,待热点降温后再汇总数据,挑选优质内容重新推送未收到的用户。此方法可缓解热 key 集中访问压力,提升系统性能和用户体验。
核心业务隔离
Redis 单点查询性能有局限,当热点 key 查询量超节点性能阈值,会致使缓存分片服务崩溃,该节点上所有业务的 Redis 读写均无法使用。
为避免热点 key 问题波及核心业务,应提前做好核心与非核心业务的 Redis 隔离,至少要将存在热点 key 的 Redis 集群与核心业务隔离开,如此可保障核心业务不受热点 key 引发的问题影响,确保核心业务的稳定性和可用性,提升系统整体的可靠性和容错能力。
手写多级缓存框架
功能实现
对于框架要实现的功能,首先进行一个分析:
- JSR107定义了缓存使用规范,spring中提供了基于这个规范的接口,所以我们可以直接使用spring中的接口进行Caffeine和Redis两级缓存的整合改造。
- 在分布式环境下,如果一台主机的本地缓存进行修改,需要通知其他主机修改本地缓存,解决分布式环境下本地缓存一致性问题。
- 通过Springboot中的Actuator功能对应用程序进行监控和管理, 通过Restful API请求来监管、审计、收集应用的运行情况,针对微服务而言它是必不可少的一个环节。
以上就是要实现的具体功能。接下来我们先了解下JSR107规范。
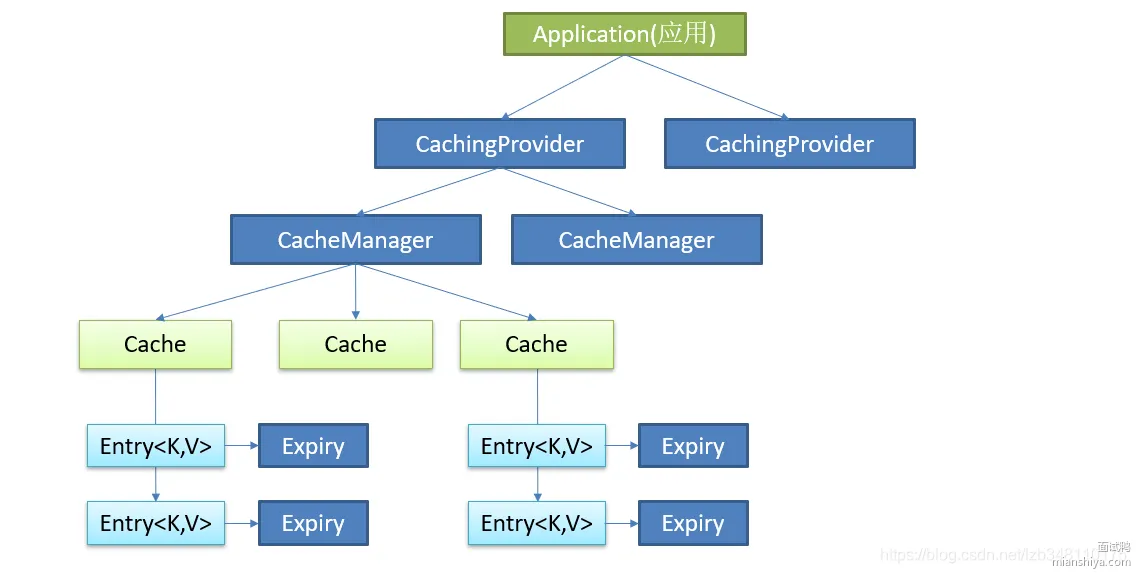
其中缓存规范定义了5个核心接口, 而我们在使用spring集成第三方的缓存时,只需要实现Cache和CacheManager这两个接口就可以了,下面分别具体来看一下。
Cache
在Cache接口中,定义了get、put、evict、clear等方法,分别对应缓存的存入、取出、删除、清空操作。不过我们这里不直接使用Cache接口,上面这张图中的AbstractValueAdaptingCache是一个抽象类,它已经实现了Cache接口,是spring在Cache接口的基础上帮助我们进行了一层封装,所以我们直接继承这个类就可以。
继承AbstractValueAdaptingCache
java
public class RedisCaffeineCahe extends AbstractValueAdaptingCache {
protected RedisCaffeineCahe(boolean allowNullValues) {
super(allowNullValues);
}
@Override
protected Object lookup(Object o) {
return null;
}
.....//后续等继承方法省略
}但是继承类实现构造方法,需要把redis和caffeine缓存的不同配置添加进来,通过添加配置属性实现构造方法,这样就可以通过构造方法生成特殊的缓存实例RedisCaffeineCahe。
java
@Slf4j
public class RedisCaffeineCache extends AbstractValueAdaptingCache {
@Getter
private final String name;
@Getter
//咖啡因缓存的相关配置
private final Cache<Object, Object> caffeineCache;
//Redis缓存的相关配置
private final RedisTemplate<Object, Object> stringKeyRedisTemplate;
private final String cachePrefix;
private final Duration defaultExpiration;
private final Duration defaultNullValuesExpiration;
private final Map<String, Duration> expires;
private final String topic;
private final Map<String, ReentrantLock> keyLockMap = new ConcurrentHashMap<>();
private RedisSerializer<String> stringSerializer = RedisSerializer.string();
private RedisSerializer<Object> javaSerializer = RedisSerializer.java();
public RedisCaffeineCache(String name, RedisTemplate<Object, Object> stringKeyRedisTemplate,
Cache<Object, Object> caffeineCache, CacheConfigProperties cacheConfigProperties) {
super(cacheConfigProperties.isCacheNullValues());
this.name = name;
this.stringKeyRedisTemplate = stringKeyRedisTemplate;
this.caffeineCache = caffeineCache;
this.cachePrefix = cacheConfigProperties.getCachePrefix();
this.defaultExpiration = cacheConfigProperties.getRedis().getDefaultExpiration();
this.defaultNullValuesExpiration = cacheConfigProperties.getRedis().getDefaultNullValuesExpiration();
this.expires = cacheConfigProperties.getRedis().getExpires();
this.topic = cacheConfigProperties.getRedis().getTopic();
}
......//后续继承方法,也需要根据不同的逻辑进行实现,暂略
}自定义配置
通过上面的实现案例中可以看到注入了很多属性,这些属性都是我们根据需要进行定义的,接下来就了解一下相关的属性信息,总共三个类,分别是
CaffeineConfigProp,RedisConfigProp,CacheConfigProperties。都是属性配置相关,前两个是两个不同缓存的配置,最后一个是缓存的配置汇总,多级缓存,主要就是把不同的缓存进行组合,通过继承实现接口实现多级缓存的各种操作逻辑。
java
@Data
public class CaffeineConfigProp {
/**
* 访问后过期时间
*/
private Duration expireAfterAccess;
/**
* 写入后过期时间
*/
private Duration expireAfterWrite;
/**
* 写入后刷新时间
*/
private Duration refreshAfterWrite;
/**
* 初始化大小
*/
private int initialCapacity;
/**
* 最大缓存对象个数,超过此数量时之前放入的缓存将失效
*/
private long maximumSize;
/**
* key 强度
*/
private CaffeineStrength keyStrength;
/**
* value 强度
*/
private CaffeineStrength valueStrength;
}
java
@Data
public class RedisConfigProp {
/**
* 全局过期时间,默认不过期
*/
private Duration defaultExpiration = Duration.ZERO;
/**
* 全局空值过期时间,默认和有值的过期时间一致,一般设置空值过期时间较短
*/
private Duration defaultNullValuesExpiration = null;
/**
* 每个cacheName的过期时间,优先级比defaultExpiration高
*/
private Map<String, Duration> expires = new HashMap<>();
/**
* 缓存更新时通知其他节点的topic名称
*/
private String topic = "cache:redis:caffeine:topic";
}
java
@Data
@ConfigurationProperties(prefix = "spring.cache.multi")
public class CacheConfigProperties {
private Set<String> cacheNames = new HashSet<>();
/**
* 是否存储空值,默认true,防止缓存穿透
*/
private boolean cacheNullValues = true;
/**
* 是否动态根据cacheName创建Cache的实现,默认true
*/
private boolean dynamic = true;
/**
* 缓存key的前缀
*/
private String cachePrefix;
@NestedConfigurationProperty
private RedisConfigProp redis = new RedisConfigProp();
@NestedConfigurationProperty
private CaffeineConfigProp caffeine = new CaffeineConfigProp();
}CacheManager
java
@Slf4j
public class RedisCaffeineCacheManager implements CacheManager {
private ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap<String, Cache>();
private CacheConfigProperties cacheConfigProperties;
private RedisTemplate<Object, Object> stringKeyRedisTemplate;
private boolean dynamic;
private Set<String> cacheNames;
//构造方法
public RedisCaffeineCacheManager(CacheConfigProperties cacheConfigProperties,
RedisTemplate<Object, Object> stringKeyRedisTemplate) {
super();
this.cacheConfigProperties = cacheConfigProperties;
this.stringKeyRedisTemplate = stringKeyRedisTemplate;
this.dynamic = cacheConfigProperties.isDynamic();
this.cacheNames = cacheConfigProperties.getCacheNames();
}
@Override
public Cache getCache(String name) {
Cache cache = cacheMap.get(name);
if (cache != null) {
return cache;
}
if (!dynamic && !cacheNames.contains(name)) {
return cache;
}
cache = new RedisCaffeineCache(name, stringKeyRedisTemplate, caffeineCache(), cacheConfigProperties);
Cache oldCache = cacheMap.putIfAbsent(name, cache);
log.debug("create cache instance, the cache name is : {}", name);
return oldCache == null ? cache : oldCache;
}
//生成caffeine缓存实例
public com.github.benmanes.caffeine.cache.Cache<Object, Object> caffeineCache() {
Caffeine<Object, Object> cacheBuilder = Caffeine.newBuilder();
doIfPresent(cacheConfigProperties.getCaffeine().getExpireAfterAccess(), cacheBuilder::expireAfterAccess);
doIfPresent(cacheConfigProperties.getCaffeine().getExpireAfterWrite(), cacheBuilder::expireAfterWrite);
doIfPresent(cacheConfigProperties.getCaffeine().getRefreshAfterWrite(), cacheBuilder::refreshAfterWrite);
if (cacheConfigProperties.getCaffeine().getInitialCapacity() > 0) {
cacheBuilder.initialCapacity(cacheConfigProperties.getCaffeine().getInitialCapacity());
}
if (cacheConfigProperties.getCaffeine().getMaximumSize() > 0) {
cacheBuilder.maximumSize(cacheConfigProaf
}
@Override
public Collection<String> getCacheNames() {
return this.cacheNames;
}
public void clearLocal(String cacheName, Object key) {
Cache cache = cacheMap.get(cacheName);
if (cache == null) {
return;
}
RedisCaffeineCache redisCaffeineCache = (RedisCaffeineCache) cache;
redisCaffeineCache.clearLocal(key);
}
}需要注意的上面代码中的有参构造方法通过给属性赋值,然后getCache方法中会生成RedisCaffeineCache的实例,RedisCaffeineCache这个实例中的方法就是定义如何具体操作缓存数据的。
两个核心类Cache,CacheManager的实现类都有,接下来就是通过配置生成实现类的Bean。
java
@Configuration(proxyBeanMethods = false)
@AutoConfigureAfter(RedisAutoConfiguration.class)
@EnableConfigurationProperties(CacheConfigProperties.class)
public class MultilevelCacheAutoConfiguration {
@Bean
@ConditionalOnBean(RedisTemplate.class)
public RedisCaffeineCacheManager cacheManager(CacheConfigProperties cacheConfigProperties,
@Qualifier("stringKeyRedisTemplate") RedisTemplate<Object, Object> stringKeyRedisTemplate) {
return new RedisCaffeineCacheManager(cacheConfigProperties, stringKeyRedisTemplate);
}
/**
* 可自定义名称为stringKeyRedisTemplate的RedisTemplate覆盖掉默认RedisTemplate。
*/
@Bean
@ConditionalOnMissingBean(name = "stringKeyRedisTemplate")
public RedisTemplate<Object, Object> stringKeyRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setHashKeySerializer(new StringRedisSerializer());
return template;
}
@Bean
public RedisMessageListenerContainer cacheMessageListenerContainer(CacheConfigProperties cacheConfigProperties,
@Qualifier("stringKeyRedisTemplate") RedisTemplate<Object, Object> stringKeyRedisTemplate,
RedisCaffeineCacheManager redisCaffeineCacheManager) {
RedisMessageListenerContainer redisMessageListenerContainer = new RedisMessageListenerContainer();
redisMessageListenerContainer.setConnectionFactory(stringKeyRedisTemplate.getConnectionFactory());
CacheMessageListener cacheMessageListener = new CacheMessageListener(redisCaffeineCacheManager);
redisMessageListenerContainer.addMessageListener(cacheMessageListener,
new ChannelTopic(cacheConfigProperties.getRedis().getTopic()));
return redisMessageListenerContainer;
}
}前两个Bean就是实现多级缓存相关的配置,第三个的话就是实现我们上面说的第二个功能。
- 在分布式环境下,如果一台主机的本地缓存进行修改,需要通知其他主机修改本地缓存,解决分布式环境下本地缓存一致性问题。
需要先了解下redis的pub/sub模式(发布订阅)。我们可以通过redis的发布订阅模式进行消息通知其他主机的本地缓存。
分布式下本地缓存一致
既然通过redis的发布订阅模式保证缓存一致,那就需要思考在什么时候会导致本地缓存不一致,毫无疑问就是操作缓存变动后,所以经过上面分析我们可以在操作缓存变动的同时发布消息通知其他主机进行缓存同步,把相关变动的缓存key通过topic发送到相应的服务器上,接下来我们进行代码实现:
java
/**
* @param message
* @description 缓存变更时通知其他节点清理本地缓存
* @author muzi
*
*/
private void push(CacheMessage message) {
/**
* 为了能自定义redisTemplate,发布订阅的序列化方式固定为jdk序列化方式。
*/
Assert.hasText(topic, "a non-empty channel is required");
byte[] rawChannel = stringSerializer.serialize(topic);
byte[] rawMessage = javaSerializer.serialize(message);
stringKeyRedisTemplate.execute((connection) -> {
connection.publish(rawChannel, rawMessage);
return null;
}, true);
// stringKeyRedisTemplate.convertAndSend(topic, message);
}在缓存进行put,evict,clear操作的时候都需要进行消息通知,通知其他服务器进行移除本地对应key的缓存,这样下次其他服务器本地查询缓存数据回因为不存在进行更新缓存。
java
@Override
public <T> T get(Object key, Callable<T> valueLoader) {
Object value = lookup(key);
if (value != null) {
return (T) value;
}
ReentrantLock lock = keyLockMap.computeIfAbsent(key.toString(), s -> {
log.trace("create lock for key : {}", s);
return new ReentrantLock();
});
try {
lock.lock();
value = lookup(key);
if (value != null) {
return (T) value;
}
value = valueLoader.call();
Object storeValue = toStoreValue(value);
put(key, storeValue);
return (T) value;
}
catch (Exception e) {
throw new ValueRetrievalException(key, valueLoader, e.getCause());
}
finally {
lock.unlock();
}
}
@Override
public void put(Object key, Object value) {
if (!super.isAllowNullValues() && value == null) {
this.evict(key);
return;
}
doPut(key, value);
}
@Override
public ValueWrapper putIfAbsent(Object key, Object value) {
Object prevValue;
// 考虑使用分布式锁,或者将redis的setIfAbsent改为原子性操作
synchronized (key) {
prevValue = getRedisValue(key);
if (prevValue == null) {
doPut(key, value);
}
}
return toValueWrapper(prevValue);
}
private void doPut(Object key, Object value) {
value = toStoreValue(value);
Duration expire = getExpire(value);
setRedisValue(key, value, expire);
push(new CacheMessage(this.name, key));
caffeineCache.put(key, value);
}
@Override
public void evict(Object key) {
// 先清除redis中缓存数据,然后清除caffeine中的缓存,避免短时间内如果先清除caffeine缓存后其他请求会再从redis里加载到caffeine中
stringKeyRedisTemplate.delete(getKey(key));
push(new CacheMessage(this.name, key));
caffeineCache.invalidate(key);
}
@Override
public void clear() {
// 先清除redis中缓存数据,然后清除caffeine中的缓存,避免短时间内如果先清除caffeine缓存后其他请求会再从redis里加载到caffeine中
Set<Object> keys = stringKeyRedisTemplate.keys(this.name.concat(":*"));
if (!CollectionUtils.isEmpty(keys)) {
stringKeyRedisTemplate.delete(keys);
}
push(new CacheMessage(this.name, null));
caffeineCache.invalidateAll();
}
@Override
protected Object lookup(Object key) {
Object cacheKey = getKey(key);
Object value = caffeineCache.getIfPresent(key);
if (value != null) {
log.debug("get cache from caffeine, the key is : {}", cacheKey);
return value;
}
value = getRedisValue(key);
if (value != null) {
log.debug("get cache from redis and put in caffeine, the key is : {}", cacheKey);
caffeineCache.put(key, value);
}
return value;
}发布实现了后,当然还需要订阅方法,也就是我们需要监听消息通知。
java
@Slf4j
@RequiredArgsConstructor
public class CacheMessageListener implements MessageListener {
private RedisSerializer<Object> javaSerializer = RedisSerializer.java();
private final RedisCaffeineCacheManager redisCaffeineCacheManager;
@Override
public void onMessage(Message message, byte[] pattern) {
/**
* 发送端固定了jdk序列户方式,接收端同样固定了jdk序列化方式进行反序列化。
*/
CacheMessage cacheMessage = (CacheMessage) javaSerializer.deserialize(message.getBody());
log.debug("recevice a redis topic message, clear local cache, the cacheName is {}, the key is {}",
cacheMessage.getCacheName(), cacheMessage.getKey());
redisCaffeineCacheManager.clearLocal(cacheMessage.getCacheName(), cacheMessage.getKey());
}
}以上就是分布式本地缓存一致的问题解决方案,当然可以思考下是否有更好的实现方案。
然后就是监控缓存相关信息的功能,这个该如何实现?学过SpringBoot的话就会了解其中有个actuate模块。
actuate模块
- 它是 Spring Boot 提供的一个用于监控和管理应用程序的模块。它提供了生产级别的功能,如端点(endpoints)来查看应用程序的各种运行时信息,包括健康检查、性能指标、环境信息等诸多内容。
- 主要功能 - 端点(Endpoints)
-
/health 端点
-
这个端点用于检查应用程序的健康状况。它返回一个包含应用程序健康信息的 JSON 对象。例如,它可以检查数据库连接是否正常、消息队列是否可用等。默认情况下,它会检查应用程序上下文(application context)中的各种健康指示器(HealthIndicator)。比如,如果应用程序连接了一个数据库,Spring Boot Actuator 会通过数据库连接池提供的健康检查机制来确定数据库连接是否健康。如果数据库连接正常,健康状态可能显示为 "UP",否则可能显示为 "DOWN"。
-
/metrics 端点
-
用于暴露应用程序的各种度量指标信息。这些指标包括 JVM 内存使用情况(如堆内存使用量、非堆内存使用量)、线程池信息(如活跃线程数、线程池最大线程数)、HTTP 请求统计信息(如请求次数、响应时间)等。例如,通过访问这个端点可以获取到应用程序在一段时间内处理的 HTTP 请求的平均响应时间,这对于性能优化和监控系统的负载情况非常有用。
-
/info 端点
-
可以用来展示应用程序的自定义信息。开发人员可以在配置文件(如 application.properties 或 application.yml)中设置一些关于应用程序的信息,比如应用程序的版本号、构建时间、作者信息等。当访问这个端点时,这些自定义信息就会以 JSON 格式返回,方便在运维过程中快速了解应用程序的基本情况。
- 自定义端点
- 除了使用 Spring Boot Actuator 提供的默认端点外,还可以自定义端点。通过创建一个带有
@Endpoint注解的 Java 类来定义一个新的端点。例如,可以创建一个端点来获取应用程序中某个特定业务模块的运行状态。在这个自定义端点类中,可以定义操作(使用@ReadOperation、@WriteOperation等注解)来返回或修改相关的状态信息。
- 安全考虑
- 由于 Spring Boot Actuator 端点暴露了应用程序的敏感信息,如应用程序的内部状态和配置细节,所以在生产环境中需要进行适当的安全配置。可以通过 Spring Security 等安全框架来保护这些端点,例如设置访问权限,只允许具有特定角色的用户访问某些敏感端点,如
/actuator/env端点(用于查看环境变量)。
- 与其他工具的集成
- Spring Boot Actuator 可以与各种监控和管理工具集成。例如,它可以很方便地与 Prometheus 集成,将应用程序的度量指标数据发送给 Prometheus 服务器,然后通过 Grafana 等工具进行可视化展示。这样运维人员就可以直观地看到应用程序的运行情况和性能指标变化趋势。
CacheMeterBinderProvider
SpringBoot中有一个函数式接口CacheMeterBinderProvider主要是一个与缓存计量(Cache Metering)相关的提供器(Provider)。代码类实现:
java
@NoArgsConstructor
public class RedisCaffeineCacheMeterBinderProvider implements CacheMeterBinderProvider<RedisCaffeineCache> {
@Override
public MeterBinder getMeterBinder(RedisCaffeineCache cache, Iterable<Tag> tags) {
return new CaffeineCacheMetrics(cache.getCaffeineCache(), cache.getName(), tags);
}
}这段代码是在一个与缓存度量和监控相关的上下文中,通过获取特定缓存实例和相关标记信息,创建并返回一个能够对该缓存进行性能指标度量的CaffeineCacheMetrics对象,从而实现对RedisCaffeineCache的有效监控。
Iterable<Tag> tags:第二个参数,类型为可迭代的Tag集合。Tag在这里可能是用于对度量数据进行分类或者标记的一种数据结构,通过传入不同的Tag,可以在后续的度量和监控过程中更方便地对数据进行筛选、分组和分析。
然后别忘把RedisCaffeineCacheMeterBinderProvider作为bean让spring进行管理
java
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ MeterBinder.class, CacheMeterBinderProvider.class })
public class RedisCaffeineCacheMeterConfiguration {
@Bean
public RedisCaffeineCacheMeterBinderProvider redisCaffeineCacheMeterBinderProvider() {
return new RedisCaffeineCacheMeterBinderProvider();
}
}简单的监测内存的功能已经初步实现,如果要实现可视化数据监控,还需要接入其他工具。
有赞TMC方案分析
架构分析
其实方案的核心只有两步:1. 系统持续监控热点key;2. 发现热点key时发出通知做相应处理;有赞出过一篇《有赞透明多级缓存解决方案(TMC)》,里头也有提到热点key问题,我们刚好借此说明;
介绍一个方案之前先来看看为什么要设计这个方案------即他是来解决哪些痛点的?
使用有赞服务的电商商家数量和类型很多,商家会不定期做一些"商品秒杀"、"商品推广"活动,导致"营销活动"、"商品详情"、"交易下单"等链路应用出现缓存热点访问的情况:
(1)活动时间、活动类型、活动商品之类的信息不可预期,导致缓存热点访问情况不可提前预知;
(2)缓存热点访问出现期间,应用层少数热点访问key产生大量缓存访问请求:冲击分布式缓存系统,大量占据内网带宽,最终影响应用层系统稳定性;
为了应对以上问题,需要一个能够自动发现热点并将热点缓存访问请求前置在应用层本地缓存的解决方案,这就是TMC产生的原因;以下是系统架构;
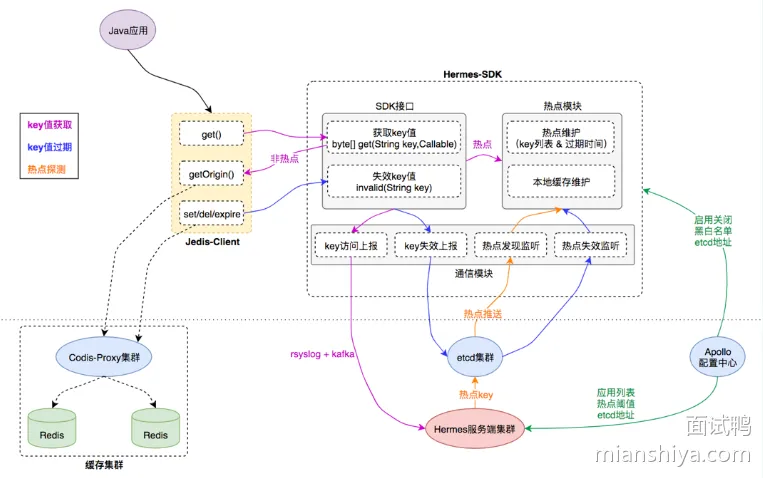
- Jedis-Client:Java应用与缓存服务端交互的直接入口,接口定义与原生Jedis-Client无异;
- Hermes-SDK:自研"热点发现+本地缓存"功能的SDK封装,Jedis-Client通过与它交互来集成相应能力;
- Hermes 服务端集群:接收Hermes-SDK上报的缓存访问数据,进行热点探测,将热点key推送给Hermes-SDK做本地缓存;
- 缓存集群:由代理层和存储层组成,为应用客户端提供统一的分布式缓存服务入口;
- 基础组件:etcd集群、Apollo配置中心,为TMC提供"集群推送"和"统一配置"能力;
监控热key
在监控热key方面,有赞用的是在客户端进行收集。在《有赞透明多级缓存解决方案(TMC)设计思路》中有一句话提到
"TMC 对原生jedis包的JedisPool和Jedis类做了改造,在JedisPool初始化过程中集成TMC"热点发现"+"本地缓存"功能Hermes-SDK包的初始化逻辑。"
也就说他改写了jedis原生的jar包,加入了Hermes-SDK包,目的就是做热点发现和本地缓存;
从监控的角度看,该包对于Jedis-Client的每次key值访问请求,Hermes-SDK 都会通过其通信模块将key访问事件异步上报给Hermes服务端集群,以便其根据上报数据进行"热点探测"。热点发现的流程如下:

通知系统做处理
在处理热key方案上,有赞用的是二级缓存;
有赞在监控到热key后,Hermes服务端集群会通过各种手段通知各业务系统里的Hermes-SDK,告诉他们:"老弟,这个key是热key,记得做本地缓存。" 于是Hermes-SDK就会将该key缓存在本地,对于后面的请求;Hermes-SDK发现这个是一个热key,直接从本地中拿,而不会去访问集群;通知方式各种各样,这篇文章文只是提供一个思路;
如何保证缓存一致性
再补充下有赞使用二级缓存时如何保证缓存一致性的;
- Hermes-SDK的热点模块仅缓存热点key数据,绝大多数非热点key数据由缓存集群存储;
- 热点key变更导致value失效时,Hermes-SDK同步失效本地缓存,保证本地强一致;
- 热点key变更导致value失效时,Hermes-SDK通过etcd集群广播事件,异步失效业务应用集群中其他节点的本地缓存,保证集群最终一致;
附上有赞原文链接:
今天这道题解虽然大体看来不难,但是由于之前我开发的多级缓存框架正好涉及到相关功能(热key收集,热key检测等功能)只是暂未开发,所以就搜了很多相关的成熟业务架构,比如有赞的TMC、阿里的jetcache、京东的hotkey等做了一些了解,顺带研究题解时做了笔记