一个完整的 BERT 文本分类系统,涵盖数据加载、模型训练、验证评估、模型保存、API 部署和前端展示。代码采用模块化设计,支持多卡训练(accelerate),每 100 个 batch 验证一次并保存最优模型。后续计划加入 TensorBoard 日志、单元测试和 Docker 部署
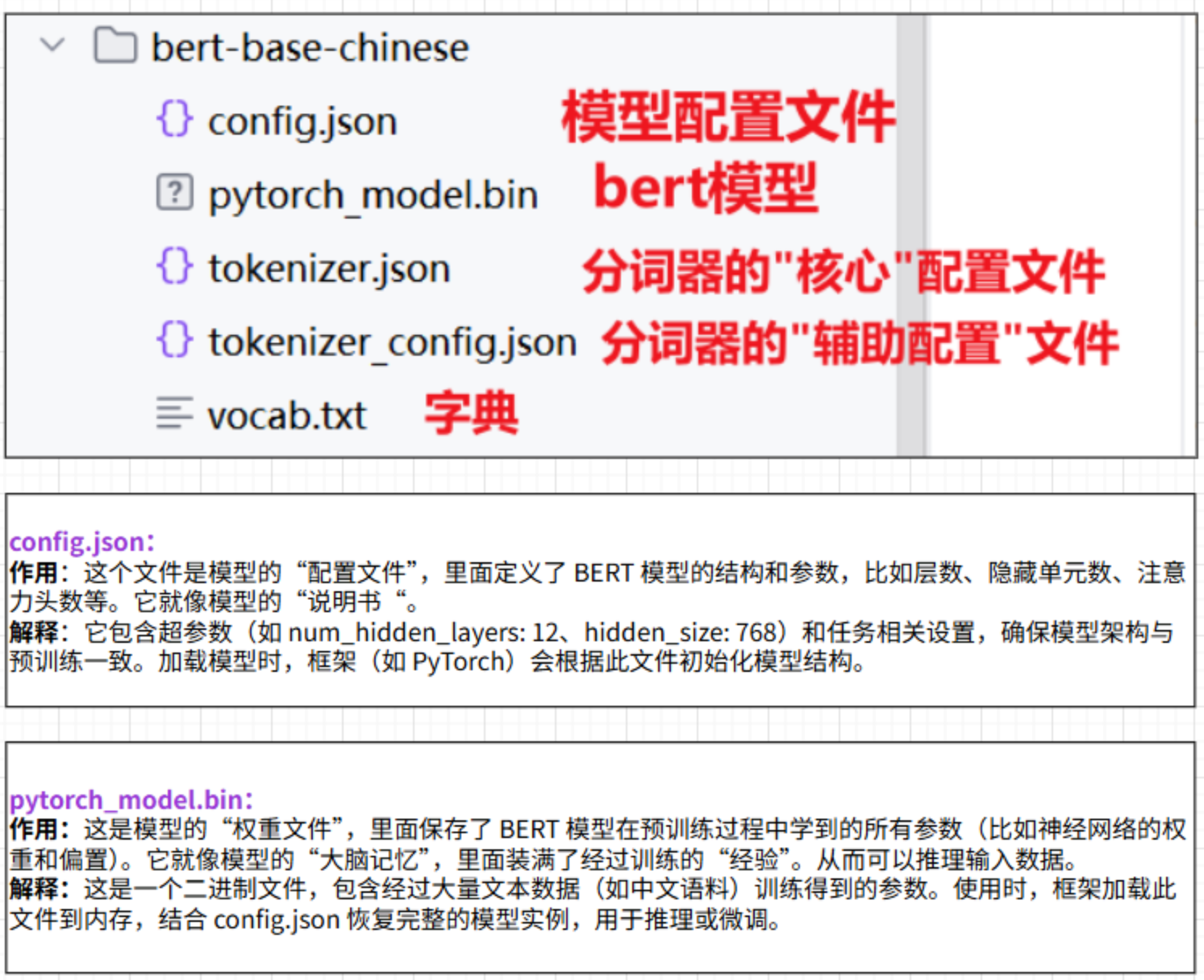
config文件实现文件统一分发,包括文件路径和bert模型超参以及bert模型的bert_model 预训练bert模型
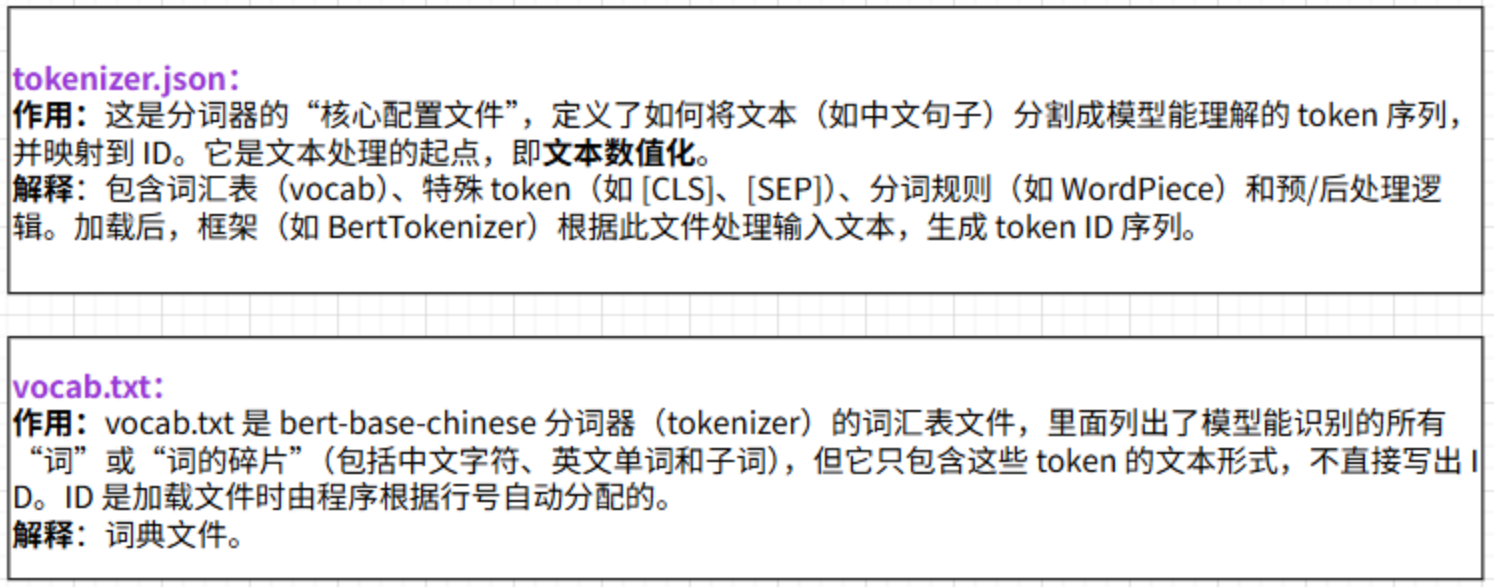
tokenizer bert分词器
bert_config bert模型配置
hidden_size bert模型输出
utils实现文件加载封装,dataset封装,dataloader封装,dataloder自定义方法处理
BertClassifier类实现bert模型➕输出头结构全参微调
模型训练与评估实现
dataloader加载
模型加载
optimizer优化器加载
crossEntropyLoss损失函数加载
accelerator实现训练加速,实现多卡并行
模型训练
前向传播
损失计算
梯度清零
反向传播
参数更新
调用验证函数实现模型验证 并保存验证后优秀的模型
计算评估指标,打印评估报告
封装推理方法
基于flask实现后端接口api服务
基于streamlit 实现前端服务
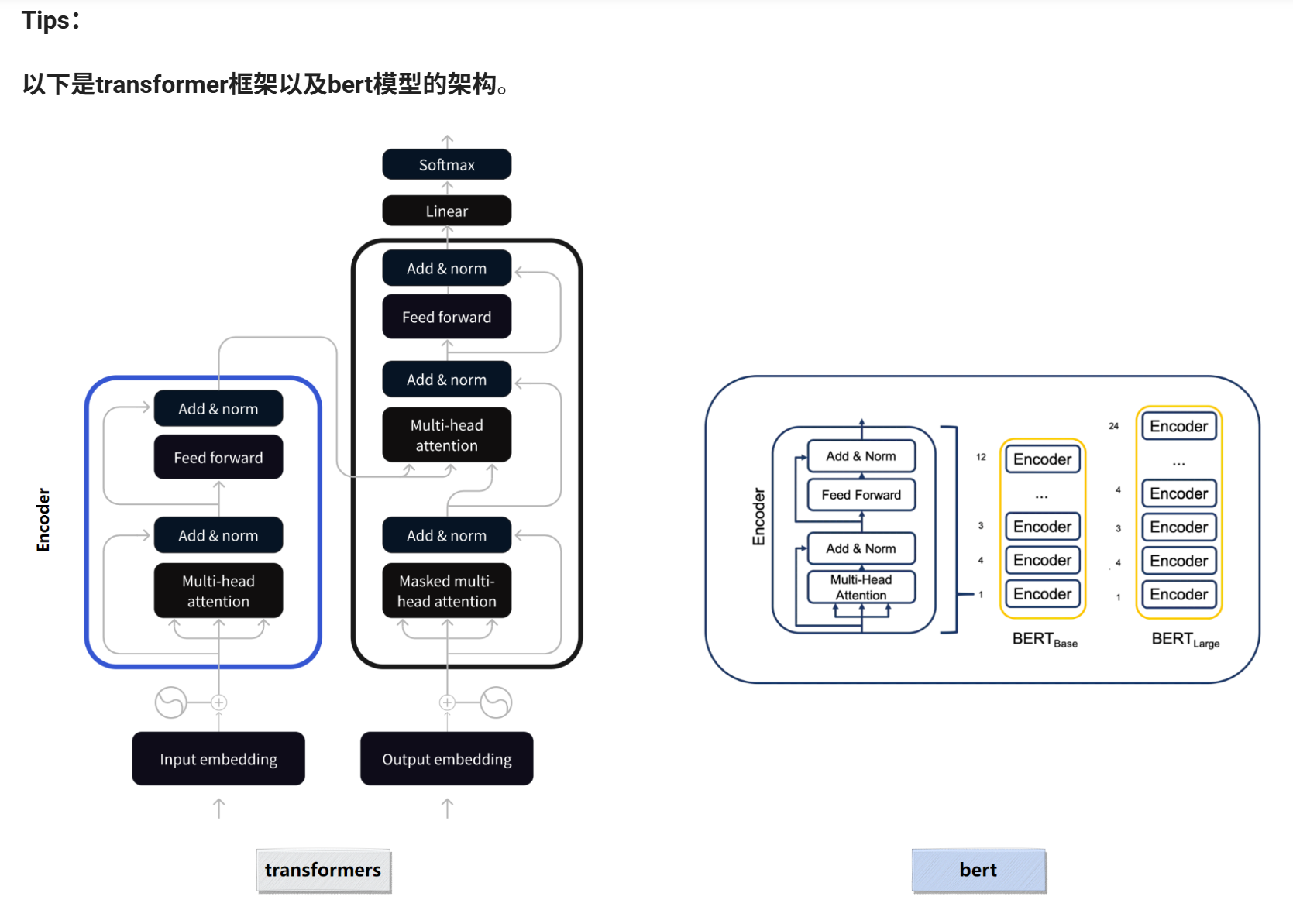
Bert模型介绍
python
"""
bert的模型结构:(输入样本数 batch_size为2 )
=========================================================================================================
Layer (type:depth-idx) Output Shape Param #
=========================================================================================================
BertModel [2, 768] --
├─BertEmbeddings: 1-1 [2, 128, 768] --
│ └─Embedding: 2-1 [2, 128, 768] 16,226,304
│ └─Embedding: 2-2 [2, 128, 768] 1,536
│ └─Embedding: 2-3 [1, 128, 768] 393,216
│ └─LayerNorm: 2-4 [2, 128, 768] 1,536
│ └─Dropout: 2-5 [2, 128, 768] --
├─BertEncoder: 1-2 [2, 128, 768] --
│ └─ModuleList: 2-6 -- --
│ │ └─BertLayer: 3-1 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-2 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-3 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-4 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-5 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-6 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-7 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-8 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-9 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-10 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-11 [2, 128, 768] 7,087,872
│ │ └─BertLayer: 3-12 [2, 128, 768] 7,087,872
├─BertPooler: 1-3 [2, 768] --
│ └─Linear: 2-7 [2, 768] 590,592
│ └─Tanh: 2-8 [2, 768] --
=========================================================================================================
"""
config文件统一分发
config文件实现
文件路径 / 模型超参数 / bert_model / tokenizer / bert_config / hidden_size
等统一管理与分发
python
import torch
import datetime
from transformers.models import BertModel, BertTokenizer, BertConfig
# 获取当前日期
# current_date = datetime.datetime.now().date().strftime("%Y%m%d")
# print('current_date--->', current_date)
class Config(object):
def __init__(self):
"""
配置类,包含模型和训练所需的各种参数。
"""
self.model_name = "bert" # 模型名称
self.data_path = "../../01-data" # 数据集的根路径
self.train_path = self.data_path + "/train.txt" # 训练集
self.dev_path = self.data_path + "/dev3.txt" # 少量验证集,快速验证
self.test_path = self.data_path + "/test.txt" # 测试集
self.class_path = self.data_path + "/class.txt" # 类别文件
self.class_list = [line.strip() for line in open(self.class_path, 'r', encoding='utf-8')]
self.model_save_path = "../save_models/bertclassifier_model.pt" # 模型训练结果保存路径
# 模型训练+预测的时候
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 训练设备,如果GPU可用,则为cuda,否则为cpu
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 2 # epoch数
self.batch_size = 32 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "../bert-base-chinese" # 预训练BERT模型的路径
self.bert_model = BertModel.from_pretrained(self.bert_path)
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.bert_config = BertConfig.from_pretrained(self.bert_path)
self.hidden_size = 768 # BERT模型的隐藏层大小
# self.hidden_size = self.bert_config.hidden_size # BERT模型的隐藏层大小
if __name__ == '__main__':
conf = Config()
print(conf.class_list)
print(conf.bert_config)
inputs = conf.tokenizer.convert_tokens_to_ids(["你", "好", "中国", "人"])
print(inputs)utils封装
数据加载load_data方法封装
TextDataset 构建dataset类封装
build_dataloader数据集构建方法封装
collate_fn构建数据加载自定义函数封装
python
import torch
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
from config import Config
# 实例化config类对象
conf = Config()
# todo:加载数据集
def load_data(path):
"""
加载数据集, 进行格式转换
:param path: 原始文件路径
:return: [(句子1, 标签1), (句子2, 标签2), ...]
"""
# todo:1-初始化空列表
data_list = []
# todo:2-加载数据集
with open(path, 'r', encoding='utf-8') as f:
# todo:3-按行处理数据
for line in tqdm(f, desc='加载数据...'):
# 去掉末尾换行符
line = line.strip()
# print('line--->\n', line)
# 如果line为空, 跳出当前循环
if not line:
continue
# 使用\t分割符进行分割处理
# 返回列表, 进行列表拆包操作
text, label = line.split('\t')
# print('text--->\n', text)
# print('label--->\n', label)
# 将句子和标签以元组形式保存到列表中
data_list.append((text, int(label)))
return data_list
# todo:构建dataset类
class TextDataset(Dataset):
# todo:1-init初始化方法
def __init__(self, data):
self.data = data
# todo:2-len方法
def __len__(self):
return len(self.data)
# todo:3-getitem方法
def __getitem__(self, item):
# 获取当前行样本的x和y部分
x = self.data[item][0]
# print('x--->\n', x)
y = self.data[item][1]
# print('y--->\n', y)
return x, y
# todo:构建数据加载, 自定义函数
def collate_fn(batch):
# print('batch--->\n', batch)
# 获取批次的x和y数据保存到对应列表中
texts = [item[0] for item in batch]
labels = [item[1] for item in batch]
# print('texts--->\n', texts)
# print('labels--->\n', labels)
# 通过分词器对象对x进行数据处理
inputs = conf.tokenizer(texts, padding=True, return_tensors='pt')
# print('inputs--->\n', inputs)
input_ids = inputs['input_ids'].to(conf.device)
attention_mask = inputs['attention_mask'].to(conf.device)
# 对y转换成张量对象
labels = torch.tensor(labels, device=conf.device)
# 返回x和y张量对象
return input_ids, attention_mask, labels
def build_dataloader():
# 加载数据集
train_data = load_data(conf.train_path)
test_data = load_data(conf.test_path)
dev_data = load_data(conf.dev_path)
# print(train_data[:10])
# print(test_data[:10])
# print(dev_data[:10])
# 实例化dataset对象
train_dataset = TextDataset(train_data)
# print('train_dataset--->', train_dataset)
# print(len(train_dataset))
# print(train_dataset[0])
test_dataset = TextDataset(test_data)
dev_dataset = TextDataset(dev_data)
# 实例化数据加器对象
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=conf.batch_size,
shuffle=True,
collate_fn=collate_fn)
test_dataloader = DataLoader(dataset=test_dataset,
batch_size=conf.batch_size,
shuffle=False,
collate_fn=collate_fn)
dev_dataloader = DataLoader(dataset=dev_dataset,
batch_size=conf.batch_size,
shuffle=False,
collate_fn=collate_fn)
return train_dataloader, test_dataloader, dev_dataloader
if __name__ == '__main__':
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 循环遍历数据加载对象
for input_ids, attention_mask, labels in train_dataloader:
print('input_ids--->\n', input_ids)
print('attention_mask--->\n', attention_mask)
print('labels--->\n', labels)
exit()Bert模型➕输出头结构全参微调
python
# 模型搭建: bert训练模型结构+输出头结构
# 全参微调(适用于小模型) -> 修改bert预训练模型的所有参数
import torch
import torch.nn as nn
from config import Config
from utils import build_dataloader
# 实例化config类对象
config = Config()
# 创建自定义模型类
class BertClassifier(nn.Module):
# init方法
def __init__(self):
super().__init__() # 调用父类方法
# 预训练模型bert结构
self.bert = config.bert_model
# 下游任务的输出层结构
# in_features: 上一层(预训练模型)的输出维度
# out_features: 类别数
self.fc = nn.Linear(in_features=config.hidden_size,
out_features=config.num_classes)
# forward方法
def forward(self, input_ids, attention_mask):
# 获取bert预训练模型的输出(特征提取/语义向量表示) 全参微调,不进行冻结
# return_dict=False: 返回一个元组(last_hidden_state, pooler_output)
# pooler_output: (batch_size, hidden_dim) -> 对句子中最后一层隐层cls值进行了一次池化处理(线性映射) 句子语义表示
last_hidden_output, pooled_output = self.bert(input_ids=input_ids, attention_mask=attention_mask,
return_dict=False)
# print('last_hidden_output--->\n', last_hidden_output.shape, last_hidden_output)
# print('pooled_output--->\n', pooled_output.shape, pooled_output)
# 计算文本类别预测结果
# output: (32, 10)
output = self.fc(pooled_output)
# print('output--->\n', output.shape, output)
return output
if __name__ == '__main__':
# 实例化数据加载器对象
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 实例化模型对象
model = BertClassifier().to(config.device)
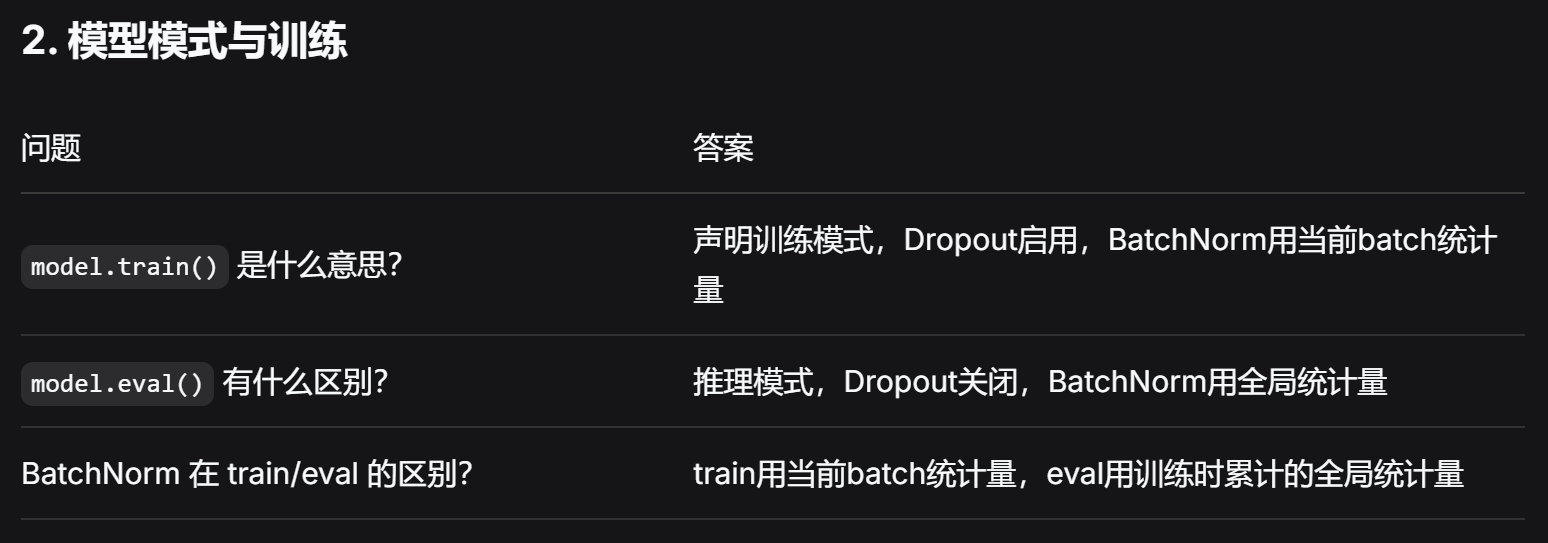
model.train()
# print('model--->\n', model)
# 循环遍历数据加载器对象
for input_dis, attention_mask, labels in train_dataloader:
# 调用模型进行进行训练
output = model(input_dis, attention_mask)
# 预测标签下标
pred_labels = torch.argmax(input=output, dim=-1)
print('pred_labels--->\n', pred_labels)
print('labels--->\n', labels)
exit()模型训练与评估
python
import torch
import torch.nn as nn
from torch.optim import AdamW
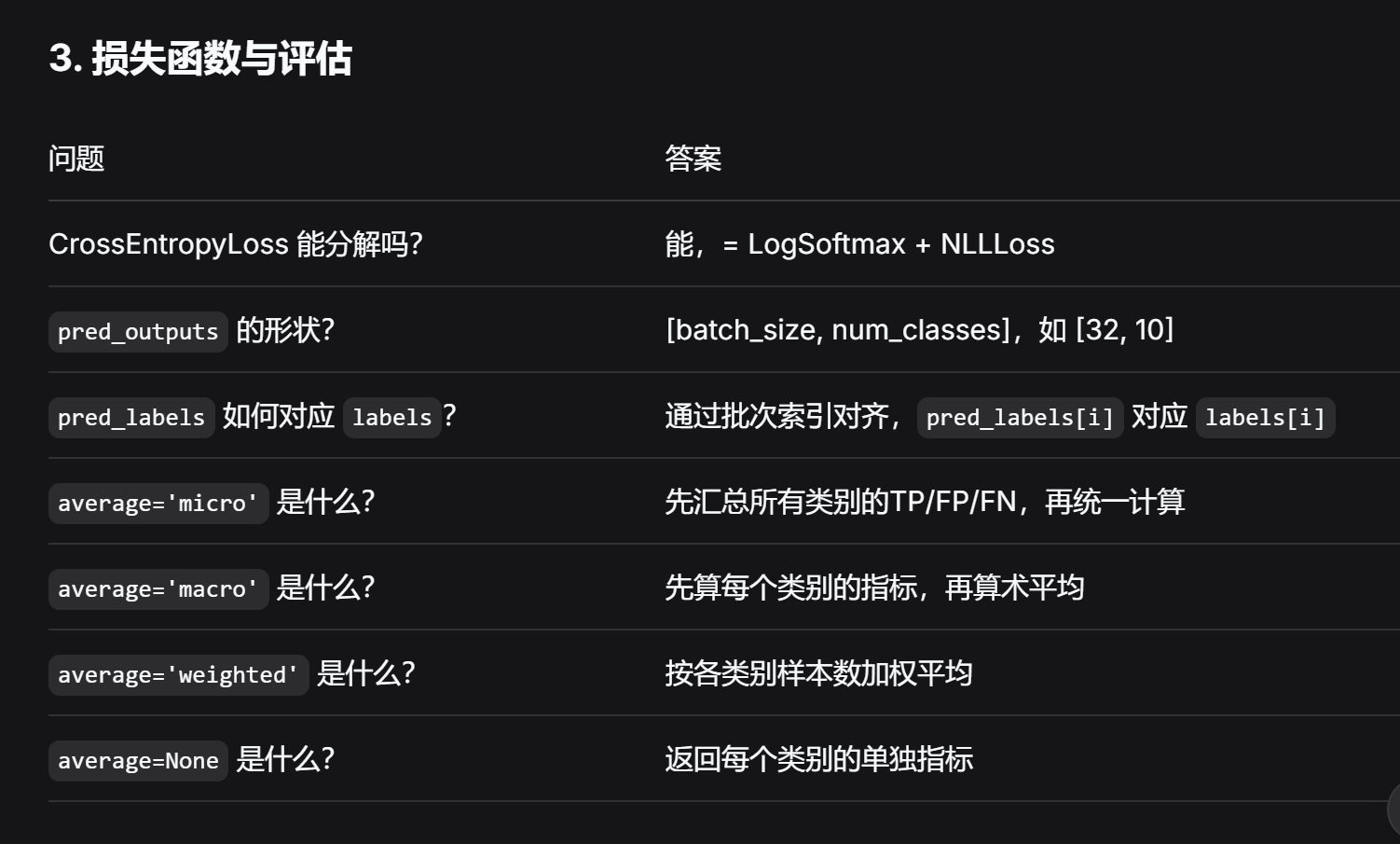
# 评估指标 分类报告 f1分数 准确率 精确率 召回率
from sklearn.metrics import classification_report, f1_score, accuracy_score, precision_score, recall_score
from tqdm import tqdm
from config import Config
from utils import build_dataloader
from bert_classifier_model import BertClassifier
from accelerate import Accelerator
# 忽略的警告信息
import warnings
warnings.filterwarnings("ignore")
# 实例化config类对象
config = Config()
# todo:1-训练函数
def model2train():
# 构建数据加载器对象
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 获取config对象的属性
epochs = config.num_epochs # 训练轮次
device = config.device # 设备
learning_rate = config.learning_rate # 学习率
model_save_path = config.model_save_path # 模型保存路径
accelerator = Accelerator()
# 实例化自定义模型对象
model = BertClassifier().to(device)
model.train()
# 实例化优化器 损失器
optimizer = AdamW(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader,
dev_dataloader,
model,
optimizer)
# 模型训练
# 初始化最佳模型的f1分数, 默认为0
best_dev_f1 = 0.0
# 双层循环
for epoch in range(epochs):
total_loss = 0.0
total_iters = 0
# 预测标签和真实标签存储列表
pred_labels_list, true_labels_list = [], []
for batch, (input_ids, attention_mask, labels) in tqdm(enumerate(train_dataloader, start=1),
desc=f"Bert Classifier Training Epoch {epoch + 1}/{epochs}...."):
# 前向传播
pred_output = model(input_ids, attention_mask)
# print('pred_output--->\n', pred_output.shape, pred_output)
# 损失计算
loss = criterion(pred_output, labels)
# print('loss--->\n', loss)
total_loss += loss.item() # 累加损失
total_iters += 1 # 累加批次数
avg_loss = total_loss / total_iters # 平均损失
# 梯度清零
optimizer.zero_grad()
# 反向传播
# loss.backward()
accelerator.backward(loss)
# 参数更新
optimizer.step()
# 获取预测标签下标
pred_labels = pred_output.argmax(dim=-1)
# print('pred_labels--->\n', pred_labels)
# 将预测标签下标和真实标签下标保存到列表中
pred_labels_list.extend(pred_labels.tolist())
true_labels_list.extend(labels.tolist())
# print('pred_labels_list--->\n', pred_labels_list)
# print('true_labels_list--->\n', true_labels_list)
# 打印训练信息
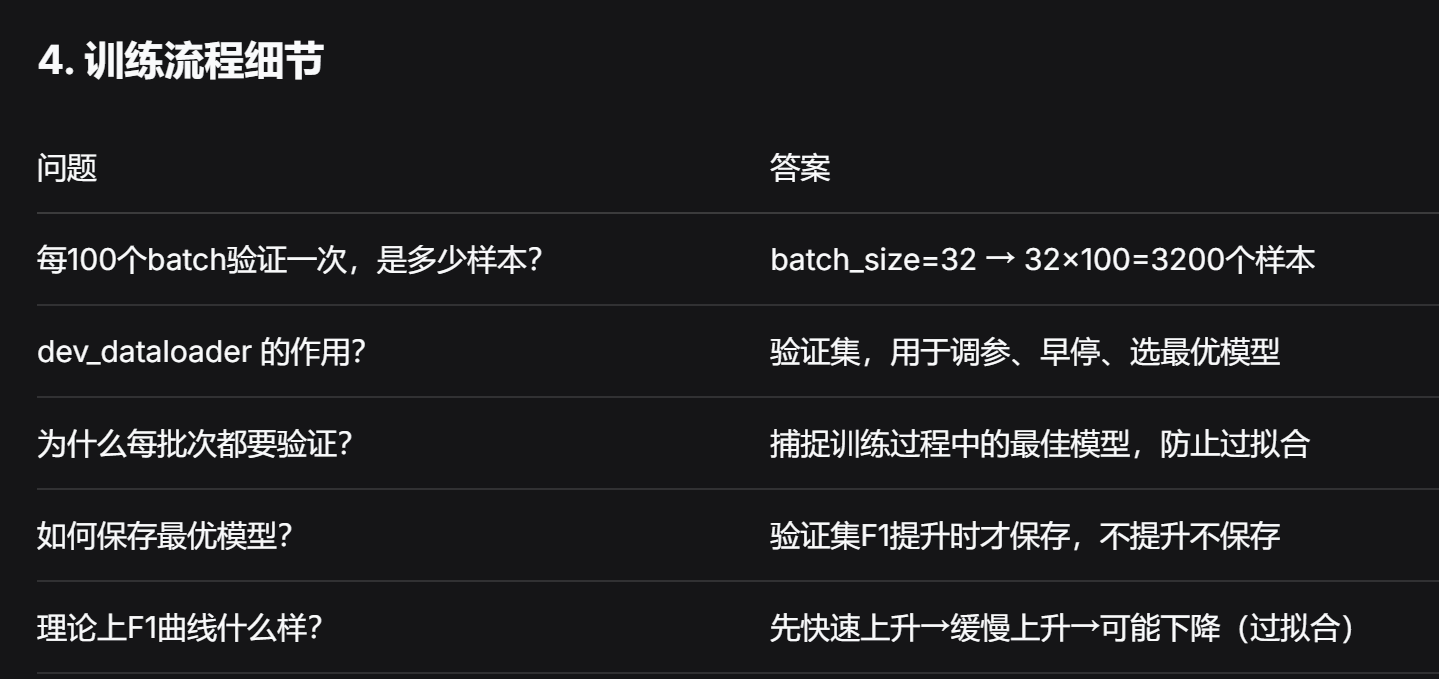
if batch % 100 == 0:
print(f"Epoch {epoch + 1}/{epochs}")
print(f"Train Loss: {avg_loss:.4f}")
# 调用验证函数实现模型验证
report, f1score, accuracy, precision = model2dev(model, dev_dataloader)
print(f"Dev f1score: {f1score}")
print(f"Dev accuracy: {accuracy}")
# 保存模型, 基于最高f1分数进行保存
if f1score > best_dev_f1:
# 更新最佳f1分数
best_dev_f1 = f1score
torch.save(model.state_dict(), model_save_path)
print(f"Saved model to {model_save_path}")
# 打印每轮分类评估报告
train_report = classification_report(true_labels_list, pred_labels_list, labels=config.class_list, output_dict=True)
print('train_report--->\n', train_report)
# todo:2-验证函数, 一边训练一边验证模型效果
def model2dev(model: BertClassifier, dataloader):
# 模型切换成推理模式
model.eval()
# 准备两个列表, 保存预测标签和真实标签
pred_labels_list, true_labels_list = [], []
# 循环遍历集数据加载器对象
for input_ids, attention_mask, labels in tqdm(dataloader, desc="Bert Classifier Evaluating..."):
with torch.no_grad():
# 模型预测
logits = model(input_ids, attention_mask)
# print('logits--->\n', logits.shape, logits)
# 获取预测标签下标
pred_labels = torch.argmax(logits, dim=-1)
# 将预测标签下标和真实标签下标保存到列表中
pred_labels_list.extend(pred_labels.tolist())
true_labels_list.extend(labels.tolist())
# 计算评估指标
report = classification_report(true_labels_list, pred_labels_list)
f1score = f1_score(true_labels_list, pred_labels_list, average='micro')
accuracy = accuracy_score(true_labels_list, pred_labels_list)
precision = precision_score(true_labels_list, pred_labels_list, average='micro')
# 返回评估指标
return report, f1score, accuracy, precision
if __name__ == '__main__':
model2train()
# 1. 加载测试集数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 2. 初始化 BERT 分类模型
model = BertClassifier()
# 3. 加载预训练模型权重
model.load_state_dict(torch.load(config.model_save_path))
# 4. 将模型移动到指定设备
model.to(config.device)
# 5. 在测试集上评估模型
test_report, f1score, accuracy, precision = model2dev(model, test_dataloader)
# 6. 打印测试集评估结果
print("Test Set Evaluation:")
print(f"Test F1: {f1score:.4f}")
print("Test Classification Report:")
print(test_report)模型推理func封装
python
import torch
from bert_classifier_model import BertClassifier
from config import Config
import time
# 初始化配置
conf = Config()
device = conf.device
tokenizer = conf.tokenizer
model_save_path = conf.model_save_path
# 实例化模型对象
model = BertClassifier().to(device)
# 加载最优模型
model.load_state_dict(torch.load(model_save_path))
model.eval()
# 推理函数
def predict(data):
"""
:param data: dict类型 {text: xxxxxxxxx}
:return: dict类型 {text: xxxxxxxxx, pred_class: xxx}
"""
# 获取文本数据 原始x
text = data['text']
# print('text--->\n', text)
if not text.strip():
print('文本为空')
return {'text': text, 'pred_class': None}
# 通过分词器进行数据处理
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs['input_ids'].to(device)
attention_mask = inputs['attention_mask'].to(device)
# 调用模型进行预测
with torch.no_grad():
# 开始时间
start_time = time.time()
# 模型预测
logits = model(input_ids, attention_mask)
# print('logits--->\n', logits)
# 获取预测标签下标
pred_label = torch.argmax(logits, dim=-1)
# print('pred_label--->\n', pred_label)
# 获取标签名
pred_class = conf.class_list[pred_label.item()]
# print('pred_class--->\n', pred_class)
print('预测耗时--->\n', (time.time() - start_time) * 1000)
return {'text': text, 'pred_class': pred_class}
if __name__ == '__main__':
# 测试输入
sample_data = {"text": "中华女子学院:本科层次仅1专业招男生"}
result = predict(sample_data)
print('result--->\n', result)基于flask的后端接口api
python
from flask import Flask, request, jsonify
from predict_fun import predict
import warnings
warnings.filterwarnings('ignore')
# todo:1-创建app对象
app = Flask(__name__)
# todo:2-创建路由
@app.route('/predict', methods=['POST'])
def predict_api():
# 获取前端数据
data = request.get_json()
print('data--->\n', data)
# 判断是否有数据, 没有收集异常信息
if not data or 'text' not in data:
# 状态码: 2xx->请求成功 3xx->重定向 4xx->请求端报错 5xx->服务端报错
return jsonify({'error': 'Missing text field in JSON'}), 400
# 调用模型预测接口实现预测
result = predict(data)
print('result--->\n', result)
# 返回json结果
return jsonify(result)
if __name__ == '__main__':
# 启动服务端
app.run(host='0.0.0.0', port=8000, debug=True)flask api测试
python
# 不要求掌握
import requests
import time
# 定义预测接口地址
url = 'http://127.0.0.1:8000/predict'
# 构造请求数据
data = {'text': "中国人民公安大学2012年硕士研究生目录及书目"}
start_time = time.time()
try:
# 发送post请求, 获取响应对象
response = requests.post(url, json=data)
print('response--->\n', response)
# 耗时
duration = (time.time() - start_time) * 1000 # ms
print(f'耗时: {duration:.2f}ms')
# 判断状态码是否为200, 如果是, 获取响应数据
if response.status_code == 200:
result = response.json()
print('result--->\n', type(result), result)
print('预测结果--->\n', result['pred_class'])
# 如果不是, 获取错误信息
else:
error = response.json()['error']
print(print(f"请求失败: {response.status_code}, {error}"))
except Exception as e:
print(f"请求出错: {str(e)}")基于streamlit前端服务
python
import streamlit as st
import requests
import time
# todo:1-设置页面标题
st.title('文本分类系统')
# todo:2-创建输入框
data_text = st.text_area('请输入预测文本:', "中国人民公安大学2012年硕士研究生目录及书目")
# todo:3-创建预测按钮
if st.button('预测'):
# todo:4-调用模型推理接口实现预测
start_time = time.time()
try:
# 构造请求数据
data = {'text': data_text}
url = 'http://127.0.0.1:8000/predict'
# 发送post请求, 获取响应对象
response = requests.post(url, json=data)
duration = (time.time() - start_time) * 1000
# 判断状态码是否为200
if response.status_code == 200:
result = response.json()
# todo:5-显示预测结果
st.success(f"预测结果: {result['pred_class']}")
st.info(f"请求耗时: {duration:.2f}ms")
else:
st.error(f"请求失败: {response.json()['error']}")
except Exception as e:
st.error(f"请求出错: {str(e)}")
# todo:6-页面提示内容
st.write("请确保 Flask API 服务已在 localhost:8000 运行")项目细节