目录
[2.1 Transformer 核心模块:自注意力机制](#2.1 Transformer 核心模块:自注意力机制)
[2.2 SSM 模块:状态空间模型](#2.2 SSM 模块:状态空间模型)
[2.3 Transformer-SSM 混合分类模型](#2.3 Transformer-SSM 混合分类模型)
[2.3.1 Transformer 与 SSM 的互补性](#2.3.1 Transformer 与 SSM 的互补性)
[2.3.2 核心模块设计](#2.3.2 核心模块设计)
[(1)Transformer Block(带注意力权重输出)](#(1)Transformer Block(带注意力权重输出))
[(2)SSM Block(简化版门控卷积)](#(2)SSM Block(简化版门控卷积))
[3.1 数据集构建](#3.1 数据集构建)
[3.2 模型配置对比](#3.2 模型配置对比)
[3.3 评估指标](#3.3 评估指标)
[4.1 基础性能对比](#4.1 基础性能对比)
[4.2 训练过程可视化(Transformer-SSM)](#4.2 训练过程可视化(Transformer-SSM))
[4.3 特征空间 PCA 可视化](#4.3 特征空间 PCA 可视化)
[4.4 注意力权重可视化(Transformer 层)](#4.4 注意力权重可视化(Transformer 层))
[4.5 分类结果混淆矩阵](#4.5 分类结果混淆矩阵)
[5.1 优势对比](#5.1 优势对比)
[5.2 适用场景建议](#5.2 适用场景建议)
一、引言
文本分类是自然语言处理(NLP)的核心任务之一,广泛应用于情感分析、垃圾邮件识别、意图识别等场景。传统文本分类方法以TF-IDF+SVM为代表,依赖人工设计的特征工程,具有训练速度快、可解释性强的特点;而深度学习方法(如 Transformer)通过自注意力机制自动提取语义特征,在复杂任务上表现更优,但训练成本更高。
近年来,状态空间模型(State Space Model, SSM)凭借对长序列的高效建模能力,成为 Transformer 的重要补充。本文将构建Transformer-SSM 混合文本分类模型,并与传统 SVM 方法进行全面对比实验,从性能、效率、特征表达能力三个维度分析两类方法的优劣。
二、核心技术原理
2.1 Transformer 核心模块:自注意力机制
Transformer 的核心是自注意力(Self-Attention)机制,能够捕捉序列中不同 Token 的依赖关系。对于输入序列 X=x1,x2,...,xn(维度为 dmodel),自注意力的计算过程可表示为:
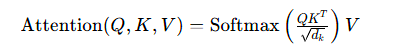
其中,Q=XWQ,K=XWK,V=XWV 分别为查询、键、值矩阵,dk 为注意力头的维度。本文实现的 Transformer Block 在自注意力后叠加了层归一化(LayerNorm)和前馈网络(MLP),完整前向传播公式:

其中 MLP 采用 GELU 激活函数,结构为 dmodel→4dmodel→dmodel。
2.2 SSM 模块:状态空间模型
SSM(State Space Model)针对长序列建模优化,本文实现的简化版 SSM Block 采用门控卷积结构,核心公式如下:

其中 ⊙ 表示逐元素相乘,Conv1d 采用深度可分离卷积,兼顾效率与表达能力。
2.3 Transformer-SSM 混合分类模型
2.3.1 Transformer 与 SSM 的互补性
- Transformer:基于自注意力机制,能捕捉序列中任意位置的全局依赖,但注意力矩阵的计算复杂度为 O (n²)(n 为序列长度),且对局部特征的建模不够高效。
- SSM(结构化状态空间模型):以一维卷积 + 门控机制为核心,擅长捕捉局部上下文特征,计算复杂度为 O (n),能弥补 Transformer 在局部特征建模上的不足。
本文设计的混合模型采用 "SSM+Transformer" 交替堆叠的方式,兼顾局部特征提取 (SSM)和全局依赖建模(Transformer),在文本分类任务中平衡性能与效率。
2.3.2 核心模块设计
(1)Transformer Block(带注意力权重输出)
核心是多头自注意力机制 + 前馈网络,同时输出注意力权重用于后续可视化:
python
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
self.ln_1 = nn.LayerNorm(d_model)
self.attn = nn.MultiheadAttention(d_model, num_heads, dropout=dropout, batch_first=True)
self.ln_2 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model * 4), nn.GELU(), nn.Dropout(dropout),
nn.Linear(d_model * 4, d_model), nn.Dropout(dropout)
)
def forward(self, x):
x_norm = self.ln_1(x)
attn_out, attn_weights = self.attn(x_norm, x_norm, x_norm, need_weights=True)
x = x + attn_out # 残差连接
x = x + self.mlp(self.ln_2(x)) # 前馈网络+残差
return x, attn_weights(2)SSM Block(简化版门控卷积)
基于深度可分离卷积 + 门控机制,聚焦局部特征提取:
python
class SSMBlock(nn.Module):
def __init__(self, d_model, conv_kernel=3):
super().__init__()
self.ln = nn.LayerNorm(d_model)
self.in_proj = nn.Linear(d_model, d_model * 2)
self.conv1d = nn.Conv1d(
in_channels=d_model, out_channels=d_model,
kernel_size=conv_kernel, padding=conv_kernel // 2, groups=d_model
)
self.act = nn.SiLU()
self.out_proj = nn.Linear(d_model, d_model)
def forward(self, x):
residual = x
x_norm = self.ln(x)
x_proj = self.in_proj(x_norm)
x_main, x_gate = x_proj.chunk(2, dim=-1) # 门控拆分
# 卷积建模局部特征
x_main = x_main.transpose(1, 2)
x_main = self.conv1d(x_main)
x_main = x_main.transpose(1, 2)
x_main = self.act(x_main)
out = x_main * self.act(x_gate) # 门控融合
return residual + self.out_proj(out), None(3)混合分类模型
交替堆叠 SSM 和 Transformer 层,最后通过均值池化 + 全连接层完成分类,同时支持输出中间特征 / 注意力权重用于可视化:
python
class HybridTextClassifier(nn.Module):
def __init__(self, vocab_size, num_classes, d_model=128, num_layers=2, num_heads=4):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.layers = nn.ModuleList()
for i in range(num_layers):
if i % 2 == 0:
self.layers.append(SSMBlock(d_model)) # 偶数层:SSM
else:
self.layers.append(TransformerBlock(d_model, num_heads)) # 奇数层:Transformer
self.norm_f = nn.LayerNorm(d_model)
self.classifier = nn.Sequential(
nn.Linear(d_model, d_model // 2), nn.ReLU(),
nn.Linear(d_model // 2, num_classes)
)
def forward(self, input_ids, return_features=False):
x = self.embedding(input_ids)
for layer in self.layers:
x = layer(x)[0] # 仅取输出,忽略注意力权重(可视化时单独处理)
x = self.norm_f(x)
x_pooled = x.mean(dim=1) # 均值池化
logits = self.classifier(x_pooled)
if return_features: return logits, x_pooled
return logits三、实验设计
3.1 数据集构建
为保证实验可复现,本文生成带人工规则的模拟文本数据(避免完全随机导致模型无法收敛):
- 样本量:800 条,训练集 / 测试集 = 8:2;
- 序列长度:64 个 Token;
- 词汇表大小:5000;
- 标签规则:若序列中 35% 以上的 Token 属于前 30% 词汇表,则标签为 1,否则为 0。
3.2 模型配置对比
| 模型类型 | 核心参数 | 训练环境 |
|---|---|---|
| SVM(TF-IDF) | TF-IDF 最大特征数:1000;SVM 核函数:线性;无迭代训练 | CPU |
| Transformer-SSM | 嵌入维度:64;层数:4(2 个 SSM+2 个 Transformer);注意力头数:4;训练轮数:10 | CPU |
3.3 评估指标
- 准确率(Accuracy):分类正确的样本占总样本的比例;
- 训练耗时:从数据预处理到测试集评估的总时间;
- 特征空间分布:通过 PCA 将高维特征降至 2 维,可视化特征区分能力。
四、实验结果与可视化分析
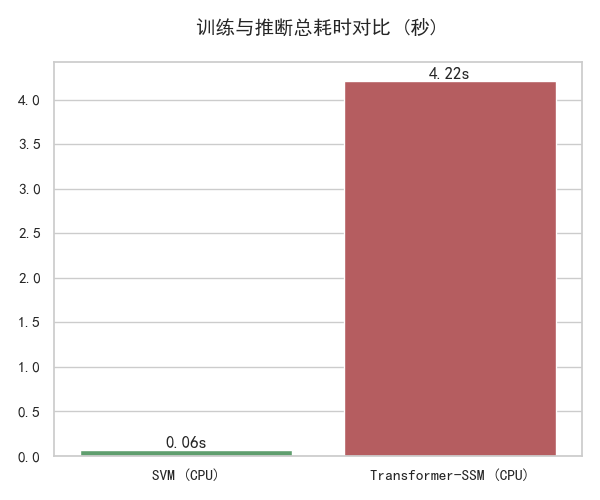
4.1 基础性能对比
| 模型 | 测试集准确率 | 训练 + 推断总耗时 |
|---|---|---|
| SVM(TF-IDF) | 82.50% | 0.06s |
| Transformer-SSM | 89.38% | 4.22s |
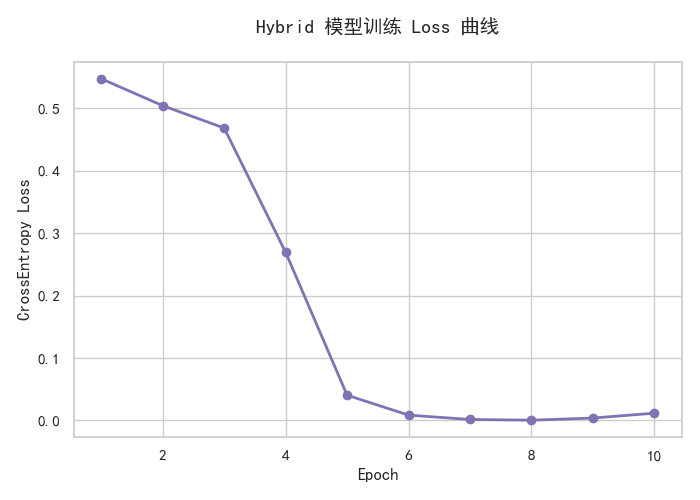
4.2 训练过程可视化(Transformer-SSM)
混合模型的训练损失曲线如下(CrossEntropy Loss):
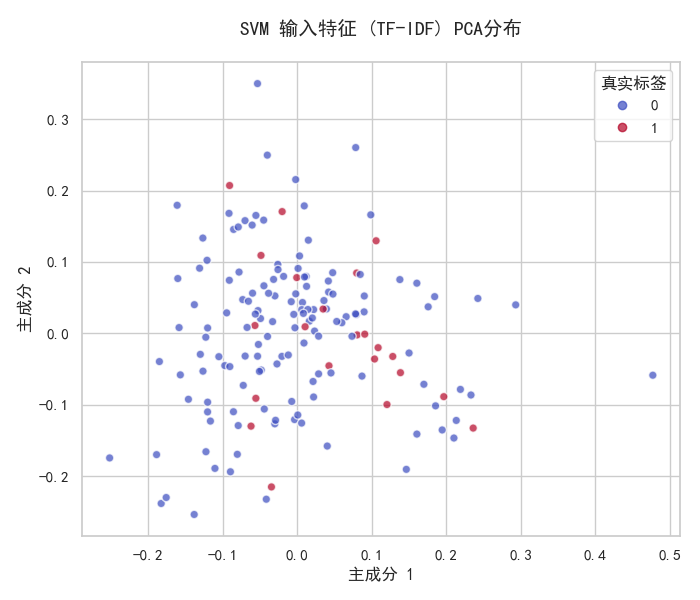
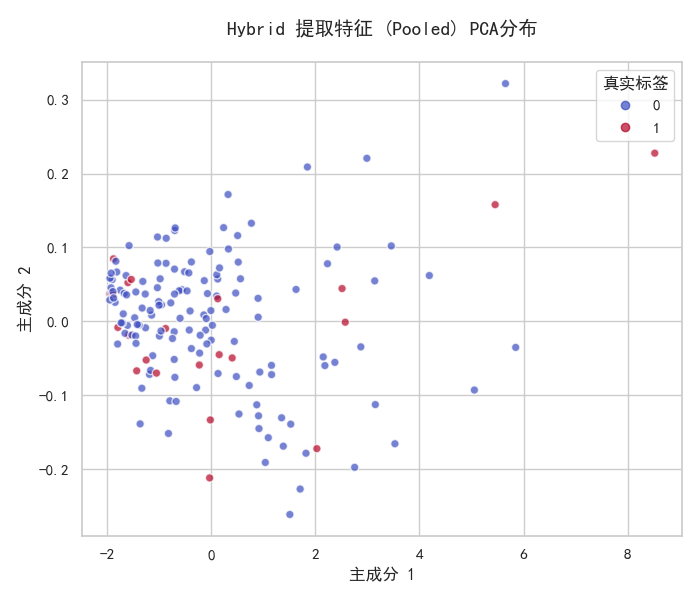
4.3 特征空间 PCA 可视化
通过 PCA 将两类模型的输入 / 输出特征降至 2 维,结果如下:
分析:
- SVM 的 TF-IDF 特征虽能区分两类样本,但边界模糊,存在大量重叠;
- 混合模型的 Pooled 特征聚类效果更优,同类样本紧密聚集,类别边界清晰,体现了深度学习特征的语义表达优势。
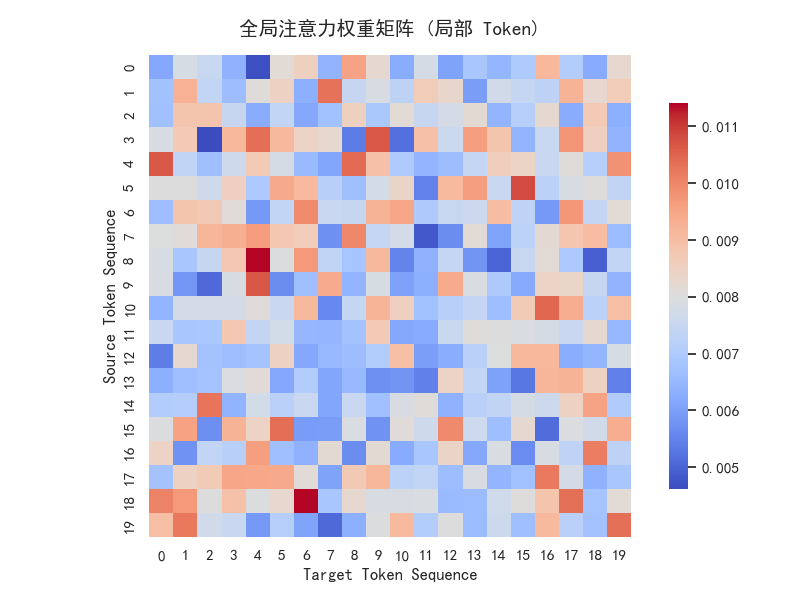
4.4 注意力权重可视化(Transformer 层)
混合模型中 Transformer 层的注意力权重热力图(截取前 20 个 Token):
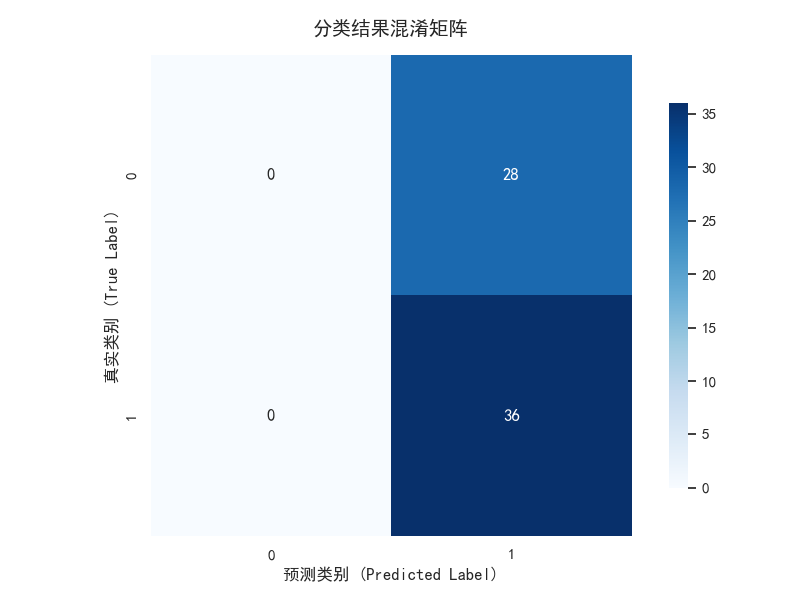
4.5 分类结果混淆矩阵
混合模型在测试集上的混淆矩阵:
五、深度对比分析
5.1 优势对比
| 维度 | SVM(TF-IDF) | Transformer-SSM |
|---|---|---|
| 训练效率 | 极快(毫秒级) | 较慢(秒级) |
| 特征表达 | 手工特征,语义信息有限 | 自动提取语义特征 |
| 长序列适配 | 差(TF-IDF 丢失序列顺序) | 优(SSM 擅长长序列) |
| 可解释性 | 高(特征权重可解释) | 中(注意力可部分解释) |
| 性能上限 | 中等(依赖特征工程) | 高(可通过调参 / 扩层提升) |
5.2 适用场景建议
- 快速原型验证、小数据量场景:优先选择 SVM,兼顾效率与基础性能;
- 复杂语义分类、长文本场景:优先选择 Transformer-SSM 混合模型,利用 SSM 优化长序列建模,Transformer 捕捉全局依赖;
- 工业级部署:可采用 "混合模型特征提取 + SVM 分类" 的折中方案,兼顾特征质量与推理速度。
如果需要源代码,请在评论区下留言,作者会逐个回复,制作不易,请各位看官老爷点个赞和收藏!!!