论文信息
- 标题:Learning to Predict by the Methods of Temporal Differences
- 会议:Machine Learning 1988
- 单位:GTE Laboratories Incorporated
- 代码:本文提供核心Python实现
- 论文:http://incompleteideas.net/papers/sutton-88.pdf
一、引言:为什么我们需要"边看边学"的算法?
想象一下天气预报员的工作:周一预测周六是否下雨,周二更新预测,周三再更新...直到周六揭晓结果。传统的监督学习方法会怎么做?它会把周一到周五的所有预测都存起来,等到周六下雨了,再一次性修改这五天的模型参数。这就像学生考完试才知道答案,然后一次性修改所有错题的思路。
而**时序差分(Temporal Difference, TD)**学习则完全不同:它每天都会比较当天和前一天的预测差异,当天就更新模型。比如周一预测50%下雨,周二预测75%,TD算法立刻就会提高周一类似天气的下雨概率预测。这就像学生每做一道题就对照答案修改思路,而不是等到整张卷子考完。
这篇1988年由Richard S. Sutton(强化学习之父)发表的经典论文,首次系统地提出了TD学习的理论框架 ,证明了它的收敛性和最优性,并通过实验展示了它比传统监督学习方法更快、更准确、更省内存的优势。如今,TD学习已经成为强化学习的核心算法之一,从AlphaGo到自动驾驶,从推荐系统到游戏AI,都能看到它的身影。
二、TD方法与监督学习的本质区别
2.1 单步预测 vs 多步预测
首先我们需要明确两类预测问题:
- 单步预测:预测后立刻知道结果,比如预测明天的天气,后天就能验证。这类问题天然适合监督学习。
- 多步预测 :预测后需要经过多个步骤才能知道最终结果,但中间会不断获得新信息,比如预测一周后的天气、预测棋局的胜负、预测股票一年后的走势。现实世界中绝大多数预测问题都是多步预测。
TD方法的优势正是在多步预测问题上体现得淋漓尽致。
2.2 传统监督学习:Widrow-Hoff规则
监督学习的核心思想是最小化预测值与真实结果之间的误差。最经典的算法就是Widrow-Hoff规则(也叫LMS算法、delta规则):
Δwt=α(z−Pt)∇wPt\Delta w_t = \alpha (z - P_t) \nabla_w P_tΔwt=α(z−Pt)∇wPt
其中:
- Δwt\Delta w_tΔwt:t时刻权重向量的更新量
- α\alphaα:学习率(步长),控制每次更新的幅度
- zzz:序列的最终真实结果
- PtP_tPt:t时刻的预测值,是权重向量www和观测向量xtx_txt的函数
- ∇wPt\nabla_w P_t∇wPt:预测值PtP_tPt对权重向量www的梯度,表示每个权重对预测值的影响程度
通俗解释 :这个公式的意思是,"如果预测值比真实结果小,就沿着能让预测值变大的方向调整权重;如果预测值比真实结果大,就沿着能让预测值变小的方向调整权重"。
对于线性预测模型Pt=wTxtP_t = w^T x_tPt=wTxt(预测值是权重和观测的线性组合),梯度∇wPt=xt\nabla_w P_t = x_t∇wPt=xt,因此Widrow-Hoff规则简化为:
Δwt=α(z−wTxt)xt\Delta w_t = \alpha (z - w^T x_t) x_tΔwt=α(z−wTxt)xt
这个规则简单有效,但有一个致命缺点:必须等到序列结束,知道最终结果zzz后,才能计算所有时刻的更新量。这意味着我们需要存储整个序列的所有观测和预测,并且在序列结束时进行一次大规模计算。
2.3 TD(1):监督学习的增量实现
神奇的是,我们可以把最终误差z−Ptz-P_tz−Pt分解成一系列连续预测的差值之和:
z−Pt=∑k=tm(Pk+1−Pk)其中Pm+1=defzz - P_t = \sum_{k=t}^{m} (P_{k+1} - P_k) \quad \text{其中} \quad P_{m+1} \stackrel{\text{def}}{=} zz−Pt=k=t∑m(Pk+1−Pk)其中Pm+1=defz
代入Widrow-Hoff规则,经过简单的数学变换(交换求和顺序),我们可以得到一个完全等价的更新规则:
Δwt=α(Pt+1−Pt)∑k=1t∇wPk\Delta w_t = \alpha (P_{t+1} - P_t) \sum_{k=1}^{t} \nabla_w P_kΔwt=α(Pt+1−Pt)k=1∑t∇wPk
这个规则就是TD(1) 。它和Widrow-Hoff规则产生的权重更新完全相同,但有一个巨大优势:可以增量计算 。我们不需要存储整个序列,只需要维护一个累加和∑k=1t∇wPk\sum_{k=1}^{t} \nabla_w P_k∑k=1t∇wPk,每一步都可以立刻计算更新量。
定理1:在多步预测问题上,线性TD(1)算法与Widrow-Hoff算法产生的每序列权重更新完全相同。
这意味着,我们可以用TD(1)实现和监督学习完全一样的效果,但只需要1/M的内存和峰值计算能力(M是序列的最大长度)。
2.4 TD(λ)家族:更灵活的信用分配
TD(1)会给所有过去的预测同等程度的更新。但直觉上,越近的预测应该对当前的预测误差负更大的责任。比如,周五的预测错误应该比周一的预测错误得到更大的修正。
基于这个直觉,Sutton提出了TD(λ)家族 算法,引入了一个指数衰减的权重因子λ\lambdaλ(0≤λ≤10 \leq \lambda \leq 10≤λ≤1):
Δwt=α(Pt+1−Pt)∑k=1tλt−k∇wPk\Delta w_t = \alpha (P_{t+1} - P_t) \sum_{k=1}^{t} \lambda^{t-k} \nabla_w P_kΔwt=α(Pt+1−Pt)k=1∑tλt−k∇wPk
其中:
- λ\lambdaλ:衰减因子,控制过去预测的权重。λ=1\lambda=1λ=1时就是TD(1),λ=0\lambda=0λ=0时就是TD(0)
- λt−k\lambda^{t-k}λt−k:表示k时刻的预测对t时刻误差的贡献权重,时间越久远,权重越小
这个算法的巧妙之处在于,我们可以用一个叫做**资格迹(eligibility trace)**的变量ete_tet来增量计算累加和:
et+1=∇wPt+1+λete_{t+1} = \nabla_w P_{t+1} + \lambda e_tet+1=∇wPt+1+λet
通俗解释 :资格迹就像一个"功劳簿",记录了每个权重在过去对预测的贡献。当出现预测误差时,我们根据功劳簿上的记录来分配信用(或惩罚)。λ\lambdaλ越大,功劳簿记录的历史越长;λ\lambdaλ越小,功劳簿越只关注最近的贡献。
当λ=0\lambda=0λ=0时,资格迹et=∇wPte_t = \nabla_w P_tet=∇wPt,TD(0)的更新规则简化为:
Δwt=α(Pt+1−Pt)∇wPt\Delta w_t = \alpha (P_{t+1} - P_t) \nabla_w P_tΔwt=α(Pt+1−Pt)∇wPt
TD(0)是最简单的TD算法,它只更新前一个时刻的预测。和监督学习规则对比,我们会发现它们惊人地相似:唯一的区别是监督学习用最终结果zzz作为目标,而TD(0)用下一个时刻的预测Pt+1P_{t+1}Pt+1作为目标。
三、实验验证:TD方法真的更优吗?
3.1 游戏示例:直觉上的优势
我们先通过一个简单的游戏例子来理解为什么TD方法能学得更好。
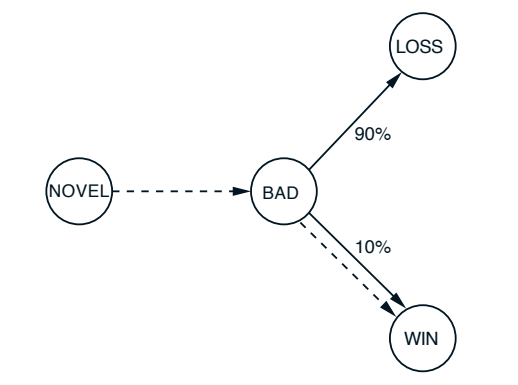
图1 游戏示例:监督学习的低效性(出处:Sutton 1988, Figure 1)
如图1所示,"坏"状态经过长期经验已经被证明有90%的概率导致失败,10%的概率导致胜利。现在我们遇到了一个从未见过的"新"状态,它转移到了"坏"状态,但最终却意外地获得了胜利。
- 监督学习会把"新"状态和"胜利"这个结果关联起来,认为"新"状态是好的
- TD方法会把"新"状态和"坏"状态关联起来,认为"新"状态也是坏的
显然,TD方法的结论更正确。因为"新"状态确实导致了一个大概率失败的局面,最后的胜利只是运气好。TD方法利用了中间状态的已知信息,过滤掉了最终结果中的随机噪声,而监督学习则完全被随机噪声误导了。
3.2 随机游走实验:定量的证明
为了严格验证TD方法的优势,Sutton设计了一个非常简单的动态系统------有界随机游走。

图2 有界随机游走生成器(出处:Sutton 1988, Figure 2)
如图2所示,所有游走都从中间状态D开始,每一步以50%的概率向左或向右移动。如果到达A状态,游走结束,结果z=0z=0z=0;如果到达G状态,游走结束,结果z=1z=1z=1。我们的目标是预测从每个状态出发最终到达G的概率。
这个问题的理想解是已知的:
- 状态B:1/6 ≈ 0.1667
- 状态C:1/3 ≈ 0.3333
- 状态D:1/2 = 0.5
- 状态E:2/3 ≈ 0.6667
- 状态F:5/6 ≈ 0.8333
Sutton进行了两个实验,比较了不同λ\lambdaλ值的TD(λ)算法和Widrow-Hoff监督学习算法(即TD(1))的性能。
实验1:重复呈现训练范式
在这个实验中,每个训练集被反复呈现给算法,直到权重收敛。结果如图3所示:
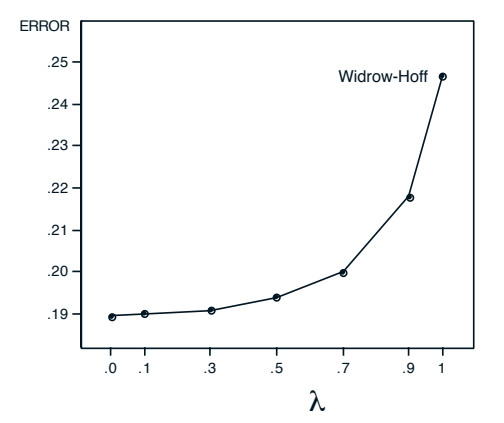
图3 重复呈现下的平均误差(出处:Sutton 1988, Figure 3)
结果分析:
- 所有λ<1\lambda < 1λ<1的TD算法都优于监督学习算法(λ=1\lambda=1λ=1)
- 性能随着λ\lambdaλ的减小而单调提升,在λ=0\lambda=0λ=0时达到最佳
- 这个结果颠覆了传统认知:Widrow-Hoff算法被认为是最小化训练集均方误差的最优算法,但TD(0)却取得了更好的泛化性能
原因在于:Widrow-Hoff算法只是最小化训练集上的误差,而TD(0)算法收敛到的是最大似然估计,也就是对未来数据最优的估计。
实验2:单次呈现训练范式
在这个实验中,每个训练集只被呈现一次,这更接近现实世界的在线学习场景。结果如图4和图5所示:
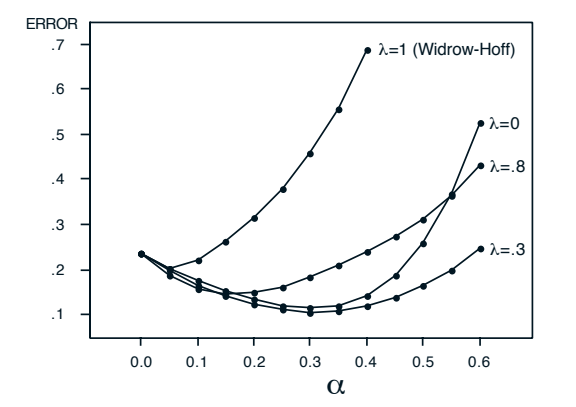
图4 单次呈现下的平均误差(出处:Sutton 1988, Figure 4)
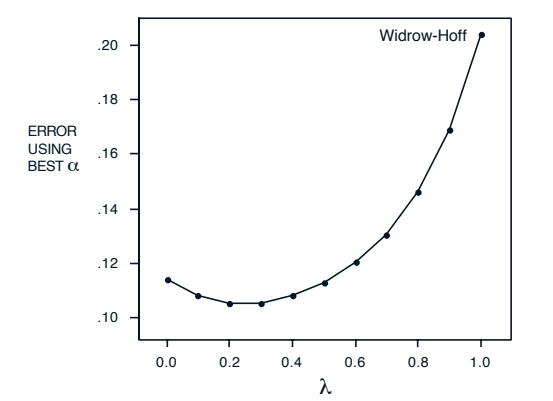
图5 最佳α值下的平均误差(出处:Sutton 1988, Figure 5)
结果分析:
- 同样,所有λ<1\lambda < 1λ<1的TD算法都优于监督学习算法
- 但这次最佳的λ\lambdaλ值不是0,而是大约0.3
- 原因是TD(0)的预测信息传播较慢:在单次呈现中,一个序列的结果只能影响前一个状态的预测,而λ>0\lambda>0λ>0的算法可以同时影响多个过去的状态
四、理论基础:TD方法为什么有效?
4.1 线性TD(0)的收敛性
Sutton首先证明了线性TD(0)算法在吸收马尔可夫过程(最终一定会结束的过程)上的收敛性。
定理2 :对于任意吸收马尔可夫链,任意初始状态分布,任意具有有限期望的结果分布,以及任意线性无关的观测向量集,存在一个ϵ>0\epsilon>0ϵ>0,使得对于所有0<α<ϵ0<\alpha<\epsilon0<α<ϵ和任意初始权重向量,线性TD(0)的预测值在期望意义下收敛到理想预测值:
limn→∞E{xiTwn}=E{z∣i}=(I−Q)−1hi\lim_{n \to \infty} E\{x_i^T w_n\} = E\{z | i\} = (I-Q)\^{-1} h_in→∞limE{xiTwn}=E{z∣i}=(I−Q)−1hi
其中:
- wnw_nwn:经过n个序列后的权重向量
- E{z∣i}E\{z | i\}E{z∣i}:从状态i出发的期望结果(理想预测)
- QQQ:非终端状态之间的转移概率矩阵
- hhh:向量,hih_ihi表示从状态i出发一步到达终端状态的期望结果
- III:单位矩阵
这个定理告诉我们,只要学习率足够小,线性TD(0)算法一定会收敛到正确的预测值。
4.2 线性TD(0)的最优性
更重要的是,Sutton证明了在重复呈现训练范式下,线性TD(0)收敛到的是最大似然估计,也就是对有限训练集来说最优的预测。
定理3 :对于任意观测向量线性无关的训练集,存在一个ϵ>0\epsilon>0ϵ>0,使得对于所有0<α<ϵ0<\alpha<\epsilon0<α<ϵ和任意初始权重向量,线性TD(0)在重复呈现训练范式下收敛到最优预测(最大似然估计):
limn→∞xiTwn=(I−Q\^)−1h\^i\lim_{n \to \infty} x_i^T w_n = (I-\\hat{Q})\^{-1} \\hat{h}_in→∞limxiTwn=(I−Q\^)−1h\^i
其中:
- Q^\hat{Q}Q^:从训练集中估计出的转移概率矩阵
- h^\hat{h}h^:从训练集中估计出的终端期望结果向量
而监督学习的Widrow-Hoff算法收敛到的只是最小化训练集均方误差的预测,这在一般情况下不等于最大似然估计,因此泛化性能更差。
4.3 TD方法作为梯度下降
和许多机器学习算法一样,TD方法也可以被看作是在权重空间中进行梯度下降,目标是最小化预测误差。
我们的目标是最小化期望平方误差:
J(w)=Ex{(E{z∣x}−P(x,w))2}J(w) = E_x\{(E\{z | x\} - P(x,w))^2\}J(w)=Ex{(E{z∣x}−P(x,w))2}
其中E{z∣x}E\{z | x\}E{z∣x}是给定观测x后的真实期望结果。梯度下降的更新规则是:
Δwt=−α∇wJ(wt)\Delta w_t = -\alpha \nabla_w J(w_t)Δwt=−α∇wJ(wt)
展开后得到:
Δwt=2α(E{z∣xt}−P(xt,w))∇wP(xt,w)\Delta w_t = 2\alpha (E\{z | x_t\} - P(x_t,w)) \nabla_w P(x_t,w)Δwt=2α(E{z∣xt}−P(xt,w))∇wP(xt,w)
监督学习用实际结果zzz来近似E{z∣xt}E\{z | x_t\}E{z∣xt},而TD(0)用下一个时刻的预测P(xt+1,w)P(x_{t+1},w)P(xt+1,w)来近似E{z∣xt}E\{z | x_t\}E{z∣xt}。
关键洞察 :我们的真正目标是让预测匹配期望结果 ,而不是训练集中的实际结果。实际结果包含了大量的随机噪声,而TD方法通过使用后续预测作为目标,有效地过滤了这些噪声,因此能获得更好的泛化性能。
五、TD方法的扩展
5.1 预测累积结果
TD方法不仅可以预测序列的最终结果,还可以预测累积结果,比如游戏中的总得分、任务的总时间、投资的总回报等。
对于累积结果问题,我们希望预测从t时刻开始的剩余累积成本:
zt=∑k=tmck+1z_t = \sum_{k=t}^{m} c_{k+1}zt=k=t∑mck+1
其中ck+1c_{k+1}ck+1是第k步到第k+1步之间产生的成本。对应的累积TD(λ)更新规则是:
Δwt=α(ct+1+Pt+1−Pt)∑k=1tλt−k∇wPk\Delta w_t = \alpha (c_{t+1} + P_{t+1} - P_t) \sum_{k=1}^{t} \lambda^{t-k} \nabla_w P_kΔwt=α(ct+1+Pt+1−Pt)k=1∑tλt−k∇wPk
这个规则和基本TD(λ)规则几乎完全相同,只是在误差项中多了一个即时成本ct+1c_{t+1}ct+1。
5.2 序列内权重更新
到目前为止,我们讨论的都是在序列结束后才更新权重。但实际上,TD方法可以在每一步观测后立刻更新权重,这就是序列内更新。
正确的序列内更新规则是:
wt+1=wt+α(P(xt+1,wt)−P(xt,wt))∑k=1tλt−k∇wP(xk,wt)w_{t+1} = w_t + \alpha (P(x_{t+1}, w_t) - P(x_t, w_t)) \sum_{k=1}^{t} \lambda^{t-k} \nabla_w P(x_k, w_t)wt+1=wt+α(P(xt+1,wt)−P(xt,wt))k=1∑tλt−k∇wP(xk,wt)
注意,这里所有的预测和梯度都是用更新前的权重wtw_twt计算的,这样可以避免权重更新本身引起的预测变化干扰学习过程。
5.3 固定间隔预测
TD方法还可以扩展到固定间隔预测问题,比如预测一周后的天气。关键是要把问题嵌入到一个更大的预测家族中:不仅预测7天后的天气,还要预测6天后、5天后...直到1天后的天气。这样就形成了重叠的预测序列,可以应用TD方法。
六、相关工作
6.1 Samuel的跳棋程序
最早的TD思想应用是Arthur Samuel在1959年开发的跳棋程序。这个程序通过比较连续两个棋局的评估值来更新评估函数,最终达到了人类大师水平。但Samuel的方法没有理论基础,也没有明确的TD误差概念。
6.2 反向传播与神经网络
反向传播算法解决了神经网络的结构信用分配问题(哪些权重应该对输出误差负责),而TD方法解决了时间信用分配问题(哪些时刻的预测应该对最终结果负责)。两者可以完美结合:用反向传播计算梯度,用TD方法计算误差。
6.3 Holland的桶队列算法
Holland的桶队列算法用于分类器系统中规则强度的更新,和TD(0)非常相似。但桶队列是基于因果关系分配信用(哪个规则触发了哪个规则),而TD方法是基于时间顺序分配信用。
6.4 自适应启发式评论家(AHC)
Sutton自己在1984年提出的自适应启发式评论家算法,是第一个明确使用TD误差的强化学习算法。它由两个部分组成:评论家(critic)使用TD方法学习价值函数,行动家(actor)根据评论家的评价学习选择动作。
七、TD学习的精彩应用案例
7.1 AI界的祖师爷:Samuel的跳棋程序
如果说TD学习有一个"鼻祖级"应用,那一定是Arthur Samuel在1959年开发的跳棋程序。这是历史上第一个能够通过自我对弈不断提升水平的AI程序,也是TD思想的首次成功实践。
Samuel的天才之处在于,他没有给程序灌输任何跳棋规则之外的知识,而是让程序自己和自己下棋,通过比较连续两个棋局的"好坏"来学习。具体来说,程序会给每个棋局一个评分,评分越高表示越有可能赢。当程序走完一步后,它会用新棋局的评分来更新旧棋局的评分------这正是TD(0)的核心思想!
这个程序最终打败了美国康涅狄格州的跳棋冠军,震惊了整个计算机界。要知道,这可是在1959年,计算机还像房子那么大,运算能力连现在的计算器都不如。Samuel的工作证明了:AI可以通过经验学习,而不需要人类专家的知识。
7.2 生物学中的TD学习:巴甫洛夫的狗
最神奇的是,TD学习不仅是一种计算机算法,它还是动物大脑学习的基本机制!Sutton在论文中就提到,TD学习可以完美解释经典条件反射现象------也就是著名的"巴甫洛夫的狗"实验。
在巴甫洛夫的实验中,每次给狗喂食前都会摇铃。经过多次重复后,狗只要听到铃声就会流口水。用TD学习的语言来解释:
- 最初,狗只对食物(最终奖励)有反应,TD误差很大
- 当铃声和食物多次同时出现后,狗学会了预测"铃声→食物",铃声本身开始产生TD误差
- 最终,狗听到铃声就会提前分泌唾液,因为它预测到食物即将到来
神经科学家后来发现,大脑中的多巴胺神经元的活动模式和TD误差几乎完全一致!当动物获得意外奖励时,多巴胺神经元会强烈放电(正TD误差);当预期的奖励没有出现时,多巴胺神经元会抑制放电(负TD误差)。这意味着,我们的大脑天生就在运行TD学习算法!
7.3 围棋界的独孤求败:AlphaGo与AlphaZero
2016年,AlphaGo打败了世界围棋冠军李世石,震惊了全世界。而AlphaGo的核心技术之一,就是用TD学习训练的价值网络。
AlphaGo有两个关键网络:策略网络(决定下一步走哪里)和价值网络(评估当前棋局的胜率)。价值网络就是通过TD学习训练的:程序和自己下完一盘棋后,用最终的胜负结果来更新每一步棋局的价值评估。
而AlphaZero则更进一步,它完全不需要人类棋谱,只通过自我对弈就能从零开始学会围棋。AlphaZero使用了更先进的TD(λ)算法,结合蒙特卡洛树搜索,最终达到了超越人类所有棋手的水平。它的成功证明了TD学习在复杂决策问题上的巨大潜力。
7.4 五人组队打Dota2:OpenAI Five
2019年,OpenAI开发的OpenAI Five在Dota2游戏中打败了世界冠军战队OG。这是AI首次在复杂的多人团队游戏中战胜人类职业选手。
Dota2是一个极其复杂的游戏:每局游戏有10名玩家,数百个英雄和物品,游戏时长通常超过40分钟。在这么长的时间尺度上进行信用分配是一个巨大的挑战------你怎么知道40分钟前的哪一步操作导致了最终的胜利或失败?
OpenAI Five使用了广义优势估计(GAE),这是一种结合了TD(λ)和优势函数的信用分配方法。它能够有效地把最终的胜负结果分配到每一步操作上,让AI学会复杂的团队协作策略。
7.5 自动驾驶中的预测:提前看到未来
自动驾驶汽车需要不断预测周围车辆、行人的未来运动轨迹,这正是一个典型的多步预测问题。如果用监督学习的方法,需要等到车辆实际行驶到那个位置才能更新模型,这显然太慢了。
而TD学习可以让自动驾驶系统"边开边学":每一秒钟,系统都会比较当前时刻和上一时刻的预测差异,立刻更新模型。这样,系统可以不断从实时驾驶数据中学习,预测能力会越来越准确。
7.6 你每天都在接触的TD学习:推荐系统
你有没有发现,抖音、淘宝、Netflix的推荐越来越懂你?这背后也有TD学习的功劳。
推荐系统的核心是预测用户对某个内容的"喜爱程度"。传统的监督学习方法会用用户的最终点击或购买作为标签,但这忽略了用户浏览过程中的大量信息。比如,用户在某个视频上停留了10秒就划走了,这本身就是一个重要的信号。
TD学习可以把用户的浏览过程看作一个序列,用用户的实时行为(停留时间、点赞、评论)来不断更新对用户兴趣的预测。这样,推荐系统可以更快地捕捉到用户兴趣的变化,推荐更精准的内容。
八、核心代码实现
下面是线性TD(0)算法在随机游走问题上的Python实现,完全复现了论文中的实验:
python
import numpy as np
import matplotlib.pyplot as plt
class RandomWalk:
"""有界随机游走环境"""
def __init__(self):
self.states = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
self.terminal_states = ['A', 'G']
self.non_terminal_states = ['B', 'C', 'D', 'E', 'F']
self.state_to_idx = {s: i for i, s in enumerate(self.non_terminal_states)}
self.true_values = np.array([1/6, 1/3, 1/2, 2/3, 5/6]) # 理想预测值
def reset(self):
"""重置环境到初始状态D"""
self.current_state = 'D'
return self.current_state
def step(self):
"""执行一步随机游走"""
if self.current_state in self.terminal_states:
return self.current_state, 0 if self.current_state == 'A' else 1, True
# 50%概率向左,50%概率向右
if np.random.rand() < 0.5:
next_state = self.states[self.states.index(self.current_state) - 1]
else:
next_state = self.states[self.states.index(self.current_state) + 1]
self.current_state = next_state
done = next_state in self.terminal_states
reward = 0 if next_state == 'A' else 1 if done else 0
return next_state, reward, done
class LinearTD0:
"""线性TD(0)算法"""
def __init__(self, n_features, alpha=0.1):
self.n_features = n_features
self.alpha = alpha
self.weights = np.zeros(n_features) # 初始权重为0
def get_features(self, state):
"""将状态转换为one-hot特征向量"""
features = np.zeros(self.n_features)
if state not in ['A', 'G']: # 终端状态没有特征
features[self.state_to_idx[state]] = 1
return features
def predict(self, state):
"""预测给定状态的价值"""
if state in ['A', 'G']:
return 0 if state == 'A' else 1
return np.dot(self.weights, self.get_features(state))
def update(self, state, next_state, reward):
"""根据TD误差更新权重"""
td_error = reward + self.predict(next_state) - self.predict(state)
self.weights += self.alpha * td_error * self.get_features(state)
# 实验参数
n_episodes = 100
alpha = 0.1
n_runs = 100 # 多次运行取平均
# 初始化环境和算法
env = RandomWalk()
td0 = LinearTD0(len(env.non_terminal_states), alpha)
td0.state_to_idx = env.state_to_idx
# 记录每次迭代后的RMS误差
rms_errors = np.zeros(n_episodes)
for run in range(n_runs):
td0.weights = np.zeros(len(env.non_terminal_states)) # 重置权重
for episode in range(n_episodes):
state = env.reset()
done = False
while not done:
next_state, reward, done = env.step()
td0.update(state, next_state, reward)
state = next_state
# 计算RMS误差
predictions = np.array([td0.predict(s) for s in env.non_terminal_states])
rms_error = np.sqrt(np.mean((predictions - env.true_values)**2))
rms_errors[episode] += rms_error
# 计算平均RMS误差
rms_errors /= n_runs
# 绘制结果
plt.figure(figsize=(10, 6))
plt.plot(rms_errors, label=f'TD(0), alpha={alpha}')
plt.xlabel('Episode')
plt.ylabel('RMS Error')
plt.title('TD(0) on Random Walk Problem')
plt.legend()
plt.grid(True)
plt.show()
print("最终预测值:", [td0.predict(s) for s in env.non_terminal_states])
print("理想预测值:", env.true_values)九、结论
这篇论文奠定了时序差分学习的理论基础,证明了TD方法相比传统监督学习方法的三大优势:
- 计算高效:可以增量计算,不需要等到序列结束,峰值计算量小
- 内存占用小:不需要存储整个序列,只需要维护资格迹变量
- 泛化性能好:收敛到最大似然估计,能更好地过滤随机噪声,对未来数据的预测更准确
Sutton的核心贡献在于,他把TD方法从复杂的强化学习系统中抽象出来,作为一种通用的预测学习方法进行研究。这不仅让我们理解了TD方法为什么有效,还极大地扩展了它的应用范围。从1959年Samuel的跳棋程序,到2016年的AlphaGo,再到今天的自动驾驶和推荐系统,TD学习已经深刻地改变了人工智能的发展轨迹。
正如Sutton在论文结尾所说:"大多数当前应用监督学习的问题,实际上都是预测问题,而时序差分方法在这些问题上可以发挥巨大优势。" 这句话在38年后的今天,依然闪耀着智慧的光芒。