本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(22) -AI知识库Agent平台(1)- 项目启动及基础搭建
前言
在上一篇内容中,我们已经完成了整个项目的环境底座搭建:
- 成功配置并连接了 Azure OpenAI 服务。
- 实现了文本向量生成与大模型对话功能。
- 同时完成了 Milvus 向量数据库的连接验证。
本文开始,我们正式进入 RAG 架构的核心环节 ------文档处理与向量入库。
这一步是 AI 知识库能够理解并应用文档知识的关键,我们会将本地的文本文件,转化为向量数据并存储到 Milvus 中,让静态的文档变成 AI 可以快速检索、调用的知识资源。
核心目标
核心工作分为四步:
- 读取本地文档内容
- 对长文本进行智能分段处理
- 调用 Azure Embedding 模型生成向量
- 将文本片段与对应向量存入 Milvus 向量库
完成这一步后,我们的系统就具备了知识录入的能力,这是 AI 能够基于文档回答问题的前提
核心流程
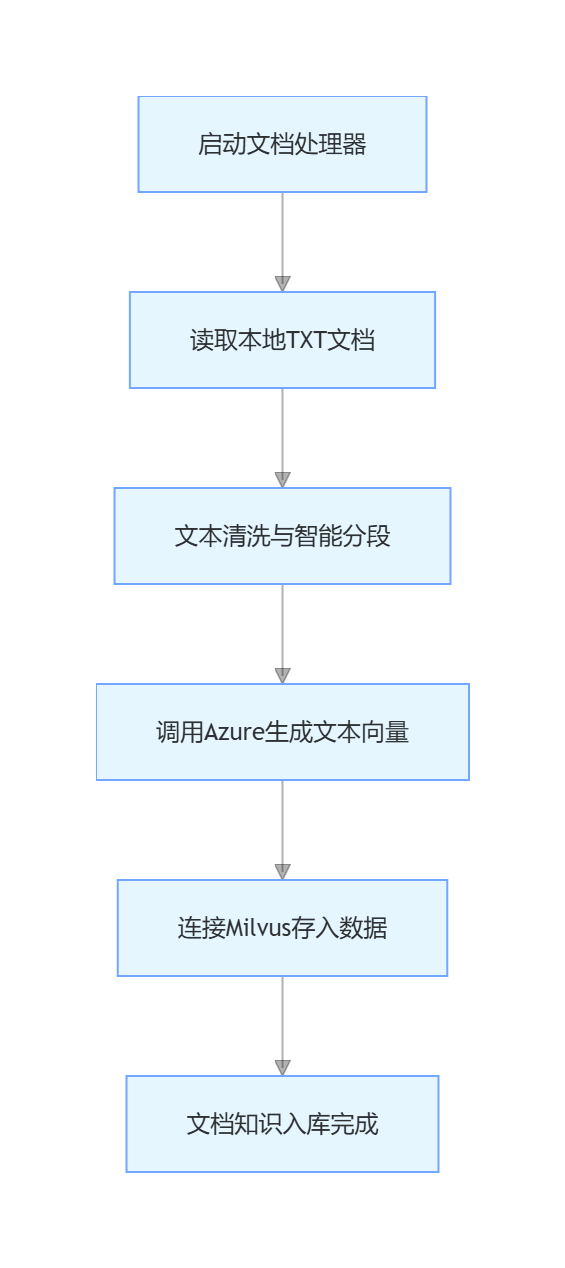
简单来说,就是把人类能看懂的文字,转换成 AI 能理解、能检索的向量数据,永久存储在向量库中。
向量库简介
向量库就像给每段文字做一张独一无二的 "语义身份证",把文字变成一串数字。它能快速算出两段文字的意思像不像,比普通数据库快得多、准得多,专门用来给 AI 找相关知识。简单说,向量库就是AI 的高效记忆仓库。
Milvus 是一款专为向量数据设计的开源数据库,专注于高效存储和快速检索 AI 生成的向量。它能在海量数据中快速找到语义相似的内容,是构建检索、推荐、RAG 知识库系统的主流底层工具。
代码实现
我们新建一个文档处理模块,基于上一篇已经封装好的 Azure 客户端和 Milvus 客户端进行开发,无需重复编写基础连接代码。
- 文档处理核心代码
新建文件 document_processor.py:
python
import os
import re
from typing import List
from utils.logger import logger
from llm.azure_llm import AzureLLM
from storage.milvus_client import MilvusStorage
class DocumentProcessor:
def __init__(self):
# 复用前一初始已经初始化的AI客户端与向量库客户端
self.llm = AzureLLM()
self.milvus = MilvusStorage()
def load_text_file(self, file_path: str) -> str:
"""读取本地文本文件,兼容UTF-8与GBK编码"""
try:
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
except:
with open(file_path, "r", encoding="gbk") as f:
return f.read()
def split_text(self, text: str, max_chunk_size: int = 500) -> List[str]:
"""智能文本分段:按标点拆分,保证段落语义完整"""
# 清理多余换行符
text = re.sub(r"\n+", "\n", text)
# 按照句号、问号、换行符等分割句子
sentences = re.split(r"(?<=[。!?;\n])", text)
chunks = []
current_chunk = ""
# 拼接句子,控制单段长度
for sentence in sentences:
if len(current_chunk) + len(sentence) <= max_chunk_size:
current_chunk += sentence
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence
# 添加最后一段内容
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
def process_and_store(self, file_path: str):
"""文档处理主流程:读取→分段→向量化→入库"""
logger.info(f"开始处理文件:{file_path}")
# 读取文档内容
text = self.load_text_file(file_path)
logger.info("文件读取完成")
# 文本分段处理
chunks = self.split_text(text)
logger.info(f"文本分段完成,共计 {len(chunks)} 个段落")
# 批量生成向量并入库
for index, chunk in enumerate(chunks):
vector = self.llm.get_embedding(chunk)
self.milvus.insert(
text=chunk,
vector=vector,
source=file_path,
chunk_id=index
)
logger.info(f"第 {index+1} 段内容入库成功")
logger.info("✅ 全部文档处理完成,知识已存入向量库")
if __name__ == "__main__":
# 执行文档处理
processor = DocumentProcessor()
processor.process_and_store("test.txt")- 测试文档准备
在项目根目录新建 test.txt,写入任意你想要让 AI 学习的文本内容,比如:
企业AI知识库能够帮助团队快速检索内部文档与经验知识。
系统采用RAG技术架构,将文档分割为合理长度的片段,通过向量模型转化为数值向量。
用户提出问题时,系统会从向量库中匹配最相关的内容,结合大模型生成精准的回答。
向量数据库Milvus负责高效存储和检索向量数据,保证响应速度与检索精度。
运行与验证
确保第一天的 Milvus 服务保持运行,在cmd命令下导航到文件所在目录,执行命令:
python
python document_processor.py预期运行结果
文件读取完成
文本分段完成,共计4个段落
第1段内容入库成功
第2段内容入库成功
第3段内容入库成功
第4段内容入库成功
✅ 全部文档处理完成,知识已存入向量库
看到这个结果,代表第二天的功能已经完全实现。

可以用下面的Python代码查看向量数据库的内容,在根目录创建一个文件check_milvus.py:
python
from storage.milvus_client import MILVUS_CLIENT
def check_milvus_data():
# 集合名称
coll_name = "enterprise_knowledge_base"
# 查看集合是否存在
has_coll = MILVUS_CLIENT.client.has_collection(coll_name)
print("集合是否存在:", has_coll)
# 统计数据条数
count = MILVUS_CLIENT.client.query(
collection_name=coll_name,
filter="",
output_fields=["count(*)"]
)
print("数据总条数:", count)
# 查询前 5 条数据(查看真实文本)
res = MILVUS_CLIENT.client.query(
collection_name=coll_name,
filter="",
output_fields=["id", "text", "doc_name"],
limit=5
)
print("\n==== 前 5 条数据 ====")
for item in res:
print(f"ID: {item['id']}")
print(f"文档: {item['doc_name']}")
print(f"文本: {item['text'][:100]}")
print("-" * 50)
if __name__ == "__main__":
check_milvus_data()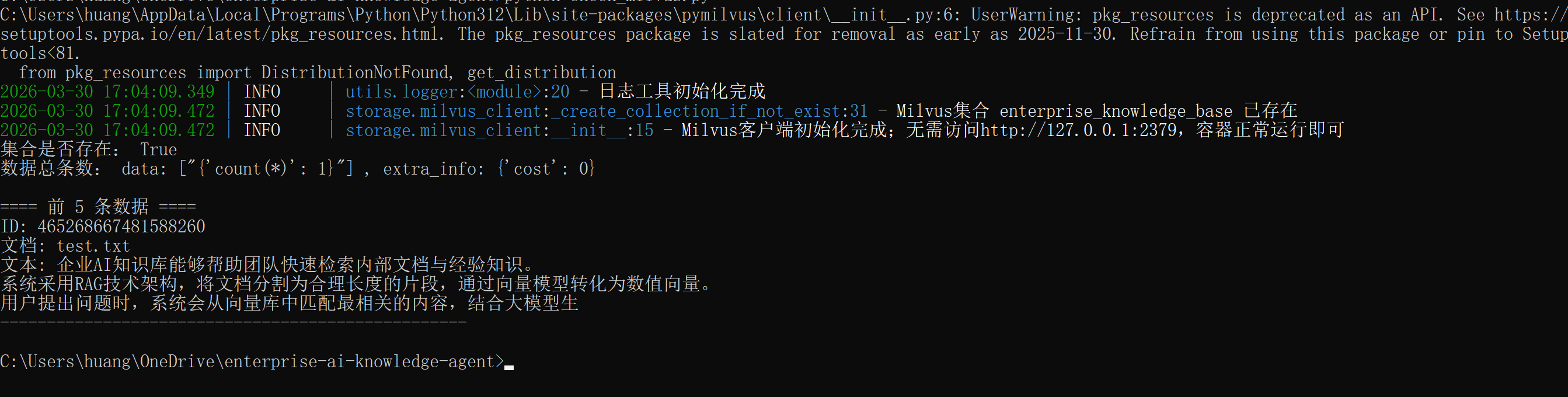
小结
- 文本分段的重要性
我们没有直接将整篇文档存入向量库,而是做了分段处理。合理的段落长度(500 字符左右)既能保证语义完整,又能让向量检索更精准,是 RAG 系统效果的关键。 - 向量的作用
每一段文本都会生成一个 3072 维的向量,这个向量是文本的语义特征表示,语义相似的文本,对应的向量在数学空间中距离更近。 - 架构复用价值
我们完全复用了第一天的 Azure OpenAI 和 Milvus 客户端,这是标准化项目开发的优势:基础服务只编写一次,后续所有功能都可以直接调用,大幅提升开发效率。 - 阶段成果
至此,我们已经完成了:基础环境搭建 + 服务连接验证 和 文档处理 + 文本向量化 + 向量库存储
系统已经具备了知识录入的能力,下一篇,我们将实现最核心的功能:用户提问 → 向量检索 → AI 回答,完成整个 RAG 系统的闭环。