缓存击穿组件:SingleFlight
这里简单介绍一下 SingleFlight,由于这个在项目中使用到了,我简单介绍一下背景和优化思路,大家可以使用 GPT 扩展实现。
引言
SingleFlight的设计目的就是避免在高并发场景下,多个线程同时执行相同的长耗时操作。通过确保只有一个线程执行"重复"的任务(比如从缓存中读取数据或进行复杂计算),其余的线程都会等待结果,避免了重复的工作和资源浪费。 当并发量很大时,使用SingleFlight的效果就非常明显,它能显著减少不必要的重复计算。如果执行的操作非常耗时或资源消耗很大,那么SingleFlight的机制就特别有用,因为它能帮助集中处理计算任务,避免每个请求都进行一次重复的计算。 因此SingleFlight并不适用于所有场景。在并发量较低或计算操作非常快速的情况下,使用SingleFlight的开销可能反而不值得,反而增加了额外的复杂性。 因此在考虑何时使用SingleFlight时,主要可以从以下几个方面来评估:
- 并发量:如果你的应用会遇到大量并发请求,那么使用SingleFlight可以有效减少冗余的工作。
- 操作复杂度:如果操作本身非常耗时,比如从数据库或缓存读取数据、进行长时间计算等,那么SingleFlight的优势就非常明显。
- 业务场景:只有在"同一个key"对应的数据获取逻辑是重复的,且结果不会因为并发请求而发生变化时,SingleFlight才是适用的。
简介
SingleFlight是go语言中sync包中的一个东西。它用于确保在并发环境下某个操作(例如,函数调用)即使被多个goroutine同时请求,也只会被执行一次。这对于防止重复的、昂贵的操作(如数据库查询、HTTP请求等)被不必要地多次执行是非常有用的。
使用 sync.SingleFlight,可以确保对于同一个键的并发请求,在缓存失效的情况下,只有一个请求会去加载数据(例如从数据库中),而其他并发的请求会等待这个加载操作完成,并共享相同的结果。这样,即便缓存失效,也不会因为大量的并发请求而对数据库或后端服务产生压力。
具体来说,当缓存失效时,第一个到达的请求会触发数据加载的操作(如数据库查询),而其他同时到达的请求会等待这个操作的完成。一旦数据被加载,它会被返回给所有等待的请求,并重新被放入缓存中。这个过程 sync.SingleFlight 保证了数据加载函数只被调用一次,避免了不必要的重复处理。
SingleFlight主要提供以下功能:
- Do(key string, fn func() (interface{}, error)): 这是SingleFlight最核心的方法。当多个goroutine同时调用Do方法时,只有一个会真正执行传入的fn函数,其它等待这个函数执行完成。执行完成后,返回的结果和错误将会被返回给所有调用Do方法的goroutine。这里的key是用来区分不同操作的唯一标识。
- DoChan(key string, fn func() (interface{}, error)): 与Do类似,但它返回一个channel,你可以从这个channel中读取执行结果。
- Forget(key string): 这个方法用于清除SingleFlight中缓存的结果,以便于同一个key对应的函数在未来可以再次被执行。
- DupSuppressed() int64: 返回被SingleFlight机制抑制的重复调用次数。
SingleFlight的一个常见用途是缓存层,避免在缓存失效时由于缓存击穿而导致大量请求直接落到数据库。
如下是在写go语言的时候的使用SingleFight解决缓存击穿的代码。
Go
var g singleflight.Group
func getCachedData(key string) (data interface{}, err error) {
// 使用Do方法确保对于同一个key的请求,函数只会被执行一次
v, err, _ := g.Do(key, func() (interface{}, error) {
// 这里是实际的获取数据的操作,比如从数据库读取
return getDataFromDatabase(key)
})
return v, err
}
func getDataFromDatabase(key string) (interface{}, error) {
// 模拟数据库操作
// ...
return data, nil
}SingleFlight 缺点与优化
SingleFlight 是一种用于减少重复工作的工具,特别是在并发编程中处理类似缓存击穿这样的问题时。尽管它非常有用,但也有一些潜在的缺点和限制:
缺点
- 资源锁定:如果用于一个长时间运行的操作,SingleFlight 会阻止其他所有相关的请求,直到这个操作完成。这可能导致长时间的等待,特别是在操作非常耗时的情况下。
- 错误传播:如果共享的操作因为某些原因失败了,这个错误会被传播给所有等待的请求。在某些情况下,单独重试可能更合适。
- 内存压力:在高并发情况下,如果许多不同的键被请求,SingleFlight 结构可能占用大量内存。
- 不适合高变动数据:对于频繁变化的数据,使用 SingleFlight 可能不太有效,因为一旦数据被缓存,就需要等待旧数据失效才能获取新数据。
优化策略
- 设置超时:为 SingleFlight 中的操作设置合理的超时时间,可以防止一个慢操作阻塞其他请求过长时间。
- 错误重试机制:对于某些操作,特别是网络请求等,实现自动重试逻辑可能会有帮助,而不是直接将一个失败共享给所有请求。
- 限制并发数量:可以对 SingleFlight 正在进行的操作数量设置上限,以减少内存压力。
- 数据版本控制:对于频繁变化的数据,可以结合数据版本控制,确保即使在数据更新的时候也能获取到最新的数据。
然后这里我就点到为止,提供一个优化的思路以及缺点和优点,具体方案不方便透露,哈哈哈哈,不过我这里可以给大家推荐一个 Github 上基于这个的改造代码,主要实现了请求折叠功能,当时这个我也在代码中实现了,大家感兴趣可以看一下。
请求折叠版本 SingleFlight:https://github.com/Percygu/go_multisingleflight
然后我简单说一下其背景和原因。
SingleFlight 优化背景
面对多次相同的请求,我们可以使用singleflight来合并请求,最终只有一个请求生效,所有相同的请求都是返回的这次请求的结果,但是主要到这里的请求只是单个请求,也就是说并没有批量请求,而在现实中,我们却有很多批量请求的场景,比如获取商品列表,订单列表等等这样的批量查询请求。假设我们有三次批量请求,第一次查询id为1,2,3的商品,第二次查询id为1,3,4的商品,第三次查询id为1,4,5的商品,假设用singleflight,则会认为他们不是相同请求,所以请求不会合并,那么这样id为1的请求就会请求3次,所以针对这样的多个key的处理singleflight并不是合适的选择。
multisingleflight作为项目难点应用
凡是go语言项目,涉及到用到缓存的地方都可以在代码层面用multisingleflight来兜底,比如瑞吉外卖的商家列表查询,订单查询,卖家查询等地方。
- 问题:go语言官方提供的singleflight 只能针对单个key的请求做到有效的访问合并,针对多个key查询,其中有部分重复key的话,不能有效的降低请求的次数
- 难点:考虑到查询db耗时较大,性能不好,是有意对热点商品做一次redis缓存,但是但是在遇到例如 redis 抖动或者其他情况可能会导致大量的 cache miss 出现,这个时候大并发的请求可能会瞬间把后端DB压垮。
- 解决方案:采用go语言提供的singleflight 库,在代码层面做一次请求优化,利用singleflight 的幂等思想,就是将一组相同的请求合并成一个请求,实际上只会去请求一次,然后对所有的请求返回相同的结果,这样来减轻db的访问压力,避免瞬间瞬间把后端DB压垮
- 优化方案:在go 官方源码的基础改造出适用于批量查询的 multisingleflight
Go 中的 SingleFlight 是什么?
Go 语言的 golang.org/x/sync/singleflight 包提供了一种名为 SingleFlight 的并发抑制机制。它的核心作用是: 对于同一个键(key),无论有多少个并发的请求,只让其中一个请求去执行实际的函数,其他请求则等待这个函数执行完毕,并共享它的结果。
这在很多场景下都非常有用,最典型的就是 缓存击穿 问题:
-
一个缓存项过期了。
-
此时,大量并发请求同时涌入,都想要获取这个数据。
-
它们发现缓存中没有数据,于是全部穿透到后端的数据库或服务。
-
这会导致后端资源在短时间内压力剧增,甚至崩溃。
SingleFlight 就像一个聪明的门卫。当大量请求同时索要同一个数据时,它只放行第一个请求去"取回"数据,并让其他请求在门口排队等待。一旦第一个请求拿回了数据,门卫会把这份数据复制给所有正在等待的请求。这样,无论并发多高,对后端资源的实际请求永远只有一个。
用 Java 如何实现 SingleFlight?
在 Java 中,我们可以利用 java.util.concurrent 包下的工具来实现同样的效果。核心思想是使用一个 ConcurrentHashMap 来存储正在进行中的"请求",其 value 则是一个 CompletableFuture ,用来代表这个请求未来的结果。
下面是一个具体的 Java 实现示例:
java
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutionException;
import java.util.function.Supplier;
/**
* Go sync/singleflight 机制的 Java 实现。
*
* @param <K> Key 的类型
* @param <V> Value 的类型
*/
public class SingleFlight<K, V> {
// 使用 ConcurrentHashMap 来存储正在进行中的任务
// Key: 任务的唯一标识
// Value: CompletableFuture,代表任务的未来结果
private final ConcurrentHashMap<K, CompletableFuture<V>> inFlight = new ConcurrentHashMap<>();
/**
* 执行一个任务,如果同样 key 的任务正在执行,则等待其结果。
*
* @param key 任务的唯一标识
* @param supplier 实际执行任务的逻辑,它应该返回类型为 V 的结果
* @return 任务的结果
* @throws ExecutionException 如果任务执行过程中抛出异常
* @throws InterruptedException 如果线程在等待结果时被中断
*/
public V execute(K key, Supplier<V> supplier) throws ExecutionException, InterruptedException {
// 使用 computeIfAbsent 原子地检查并创建任务
// 如果 key 不存在,lambda 表达式会被执行,创建一个新的 CompletableFuture
// 如果 key 已存在,直接返回已存在的 CompletableFuture
CompletableFuture<V> future = inFlight.computeIfAbsent(key, k ->
CompletableFuture.supplyAsync(() -> {
try {
// 执行耗时的任务
return supplier.get();
} finally {
// 任务完成后,无论成功还是失败,都从 map 中移除
inFlight.remove(k);
}
})
);
// 等待并返回结果。
// 如果是第一个创建任务的线程,它会等待 supplyAsync 完成。
// 如果是后续加入的线程,它会等待已存在的 future 完成。
return future.get();
}
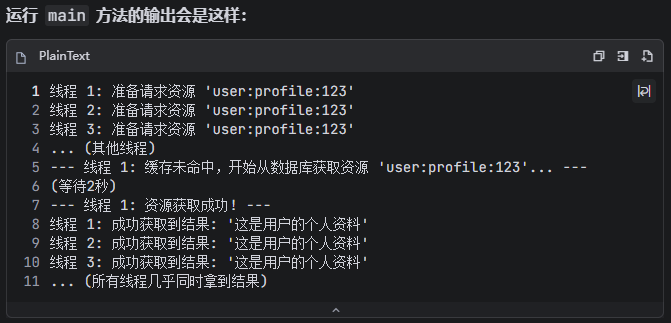
public static void main(String[] args) {
SingleFlight<String, String> singleFlight = new SingleFlight<>();
String resourceKey = "user:profile:123";
// 模拟 10 个并发线程请求同一个资源
for (int i = 0; i < 10; i++) {
int threadNum = i + 1;
new Thread(() -> {
System.out.printf("线程 %d: 准备请求资源 '%s'%n", threadNum, resourceKey);
try {
// 所有线程都使用同一个 key 调用 execute
String result = singleFlight.execute(resourceKey, () -> {
// 这个 lambda 表达式是实际的耗时操作
// 它只会被执行一次
System.out.printf("--- 线程 %d: 缓存未命中,开始从数据库获取资源 '%s'... ---%n", threadNum, resourceKey);
try {
// 模拟耗时2秒的数据库查询
Thread.sleep(2000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
System.out.printf("--- 线程 %d: 资源获取成功! ---%n", threadNum);
return "这是用户的个人资料";
});
System.out.printf("线程 %d: 成功获取到结果: '%s'%n", threadNum, result);
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
}