前言
如果对MCP从未了解过 请看上篇文章《MCP详细介绍以及IDE和Spring AI中应用》
一.基于Stdio传输协议开发MCP Server
1.搭建项目
1.1创建父模块(父子工程管理)
删除一些不需要的文件比如src
1.2引入依赖版本管理
<properties>
<maven.compiler.source>你的jdk版本</maven.compiler.source>
<maven.compiler.target>你的jdk版本</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>1.0.1</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>1.3创建子模块
1.4完善配置pom文件
<dependencies>
<!--mcp-server -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.5.3</version>
</plugin>
</plugins>
</build>目前不需要先配置yml文件
1.5建立包路径和启动类
2.开发MCP Server
以开发获取用户信息的MCP Server为例
2.1定义用户实体
import lombok.Data;
@Data
@AllArgsConstructor
public class UserInfo {
public String name;
public Integer age;
public String sex;
public String address;
}2.2定义工具
为了简化方便直接在内存中放入用户信息了(实际业务中可以连接数据库等第三方组件)
import com.lyw.mcp.enity.UserInfo;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
@Service
public class UserService {
//存储用户信息
static Map<String, UserInfo> userInfoMap = new HashMap<>();
static {
userInfoMap.put("zhangsan", new UserInfo("zhangsan", 15, "男", "北京"));
userInfoMap.put("lisi", new UserInfo("lisi", 16, "男", "上海"));
userInfoMap.put("wangwu", new UserInfo("wangwu", 17, "男", "广州"));
userInfoMap.put("zhaoliu", new UserInfo("zhaoliu", 18, "女", "深圳"));
userInfoMap.put("sunqi", new UserInfo("sunqi", 19, "女", "香港"));
userInfoMap.put("zhaoba", new UserInfo("zhaoba", 20, "女", "澳门"));
}
@Tool(description = "获取用户信息")
public String getUserInfo(@ToolParam(description = "用户名称") String name){
if (userInfoMap.containsKey(name)) {
return userInfoMap.get(name).toString();
}
return "用户信息不存在";
}
}2.3暴漏工具
import com.lyw.mcp.service.UserService;
import org.springframework.ai.tool.ToolCallbackProvider;
import org.springframework.ai.tool.method.MethodToolCallbackProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ToolsConfig {
@Bean
public ToolCallbackProvider getToolCallbackProvider(UserService userService) {
return MethodToolCallbackProvider.builder()
.toolObjects(userService) //注入工具对象
.build();
}
}2.4添加配置文件yml
spring:
ai:
mcp:
server:
name: user-info # MCP Server 名称标识
version: 0.0.1 # MCP Server 版本号
main:
web-application-type: none # 禁用Web容器(Tomcat)
banner-mode: off # 关闭Spring Boot启动横幅2.5打jar包
3.客户端调用
以antigravity为例(cursor, trae, qoder等其他IDE同理)
如有不懂antigravity下载登录以及使用MCP Server的请看上篇文章
3.1mcpjson文件的配置
{
"mcpServers": {
"user-info": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dlogging.pattern.console=",
"-jar",
"你的jar包路径(windows用户注意路径用\\)"
]
}
}
}刷新之后就可以看到user-info服务了
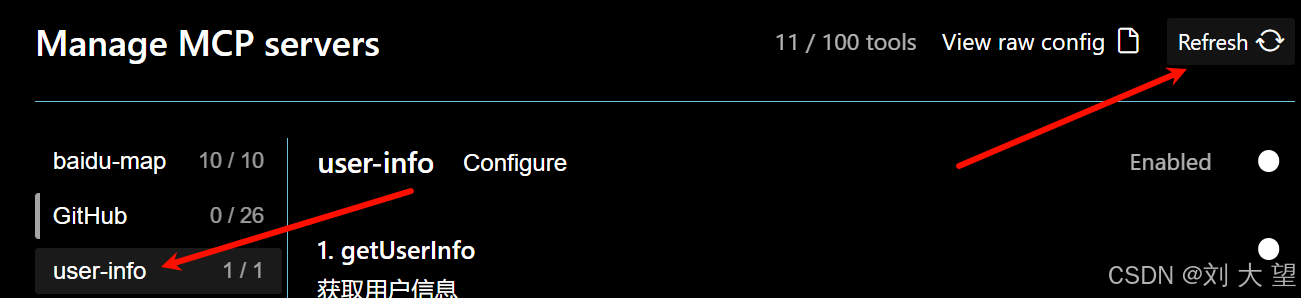
3.2结果演示

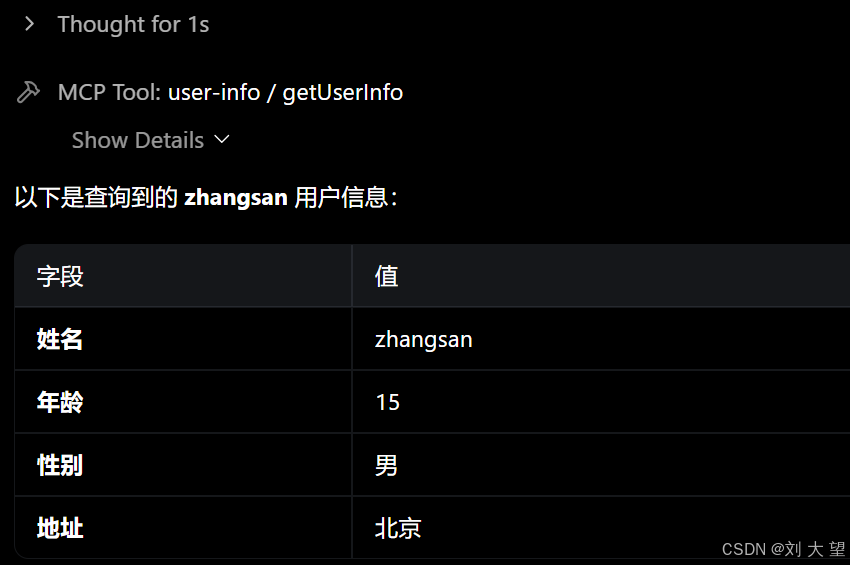
3.3Spring AI调用MCP服务
基础的项目搭建以及引入依赖 配置配置文件 测试代码编写等请看上篇文章《MCP详细介绍以及IDE和Spring AI中应用》中的六.MCP使用中5.Spring AI 接入 MCP服务
在上述开发完的代码基础上 只需在mcp-servers-config.json文件中配置上述mcpjson中的代码
3.4启动服务测试结果

二.基于SSE传输协议开发MCP Server
1.搭建项目
1.1创建模块
1.2引入依赖
<dependencies>
<!--mcp-server -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.5.3</version>
</plugin>
</plugins>
</build>1.3配置文件
server:
port: 9090
spring:
ai:
mcp:
server:
name: user-info # MCP Server 名称标识
version: 0.0.1 # MCP Server 版本号2.项目迁移
把上述Stdio的代码完全可以迁移过来本项目
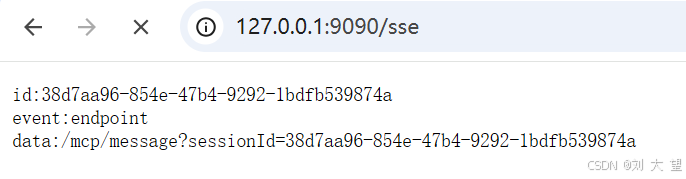
3.启动项目简单连接测试
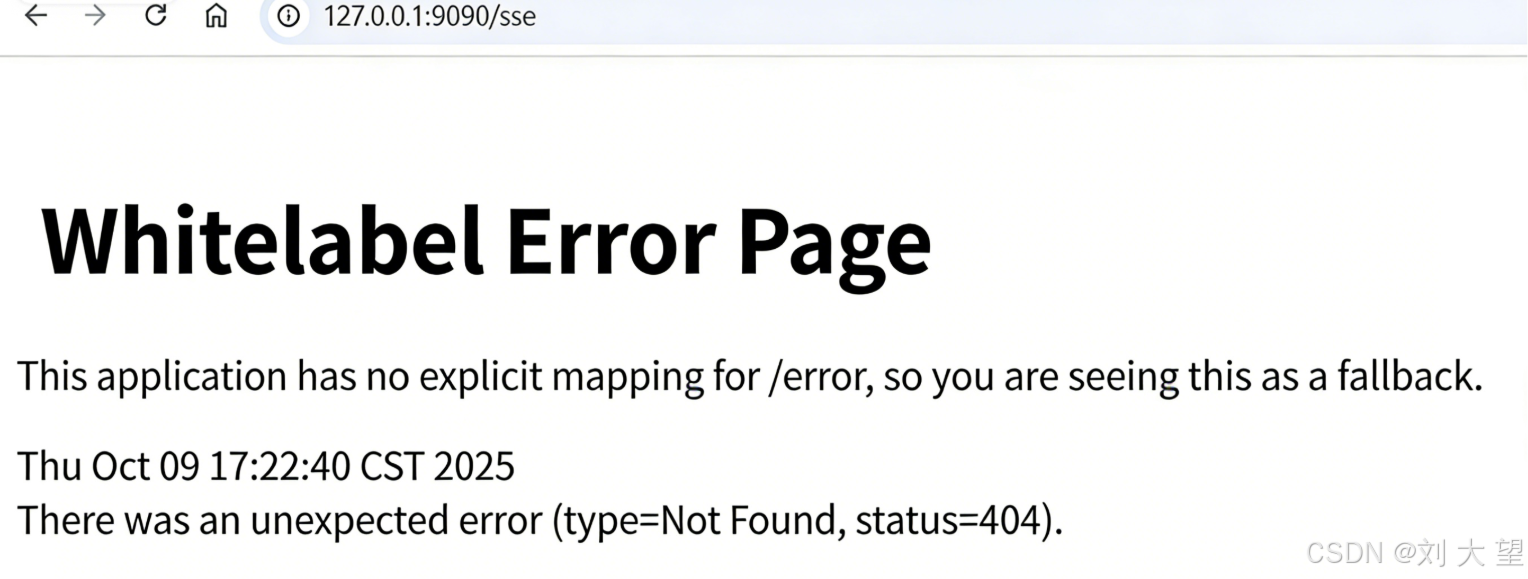
访问此URL http://127.0.0.1:9090/sse
出现以结果 代表成功
4.客户端调用
还是以antigravity和Spring AI 为例
4.1在antigravity中调用mcp server
在mcp_json文件中配置以下代码(可以删除或者注释掉刚才配置的代码)
"user-info": {
"url": "http://127.0.0.1:9090/sse"
}刷新 出现以下结果就添加成功
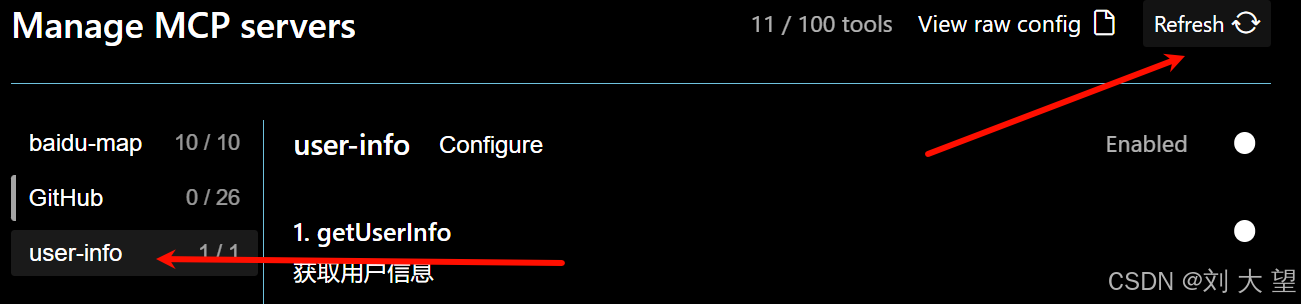
4.2antigravity中MCP 调用测试
保证后端服务不要关闭

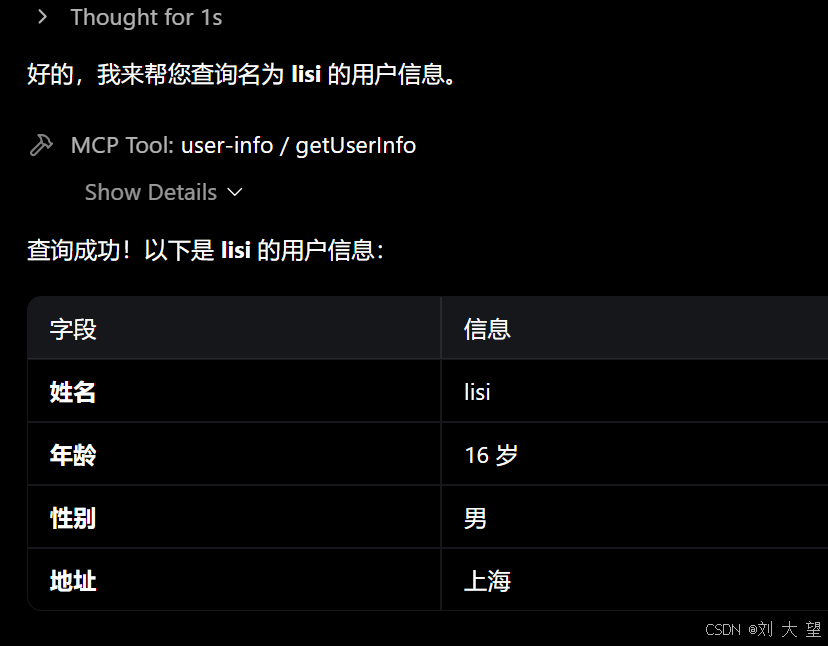
4.3Spring AI的方式调用MCP服务
还是再在上述stdio的项目(mcp-client-demo)基础上修改配置yml文件
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY}
mcp:
client:
request-timeout: 60000
# stdio:
# servers-configuration: classpath:/mcp/mcp-servers-config.json
sse:
connections:
user-info:
url: http://127.0.0.1:9090/sse4.4启动并且测试服务

三.补充
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>上述两个依赖 上者仅支持stdio 下者同时支持stdio和sse
此外还有一个starter依赖 如下
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>支持sse和stdio(但需要额外配置如下介绍)
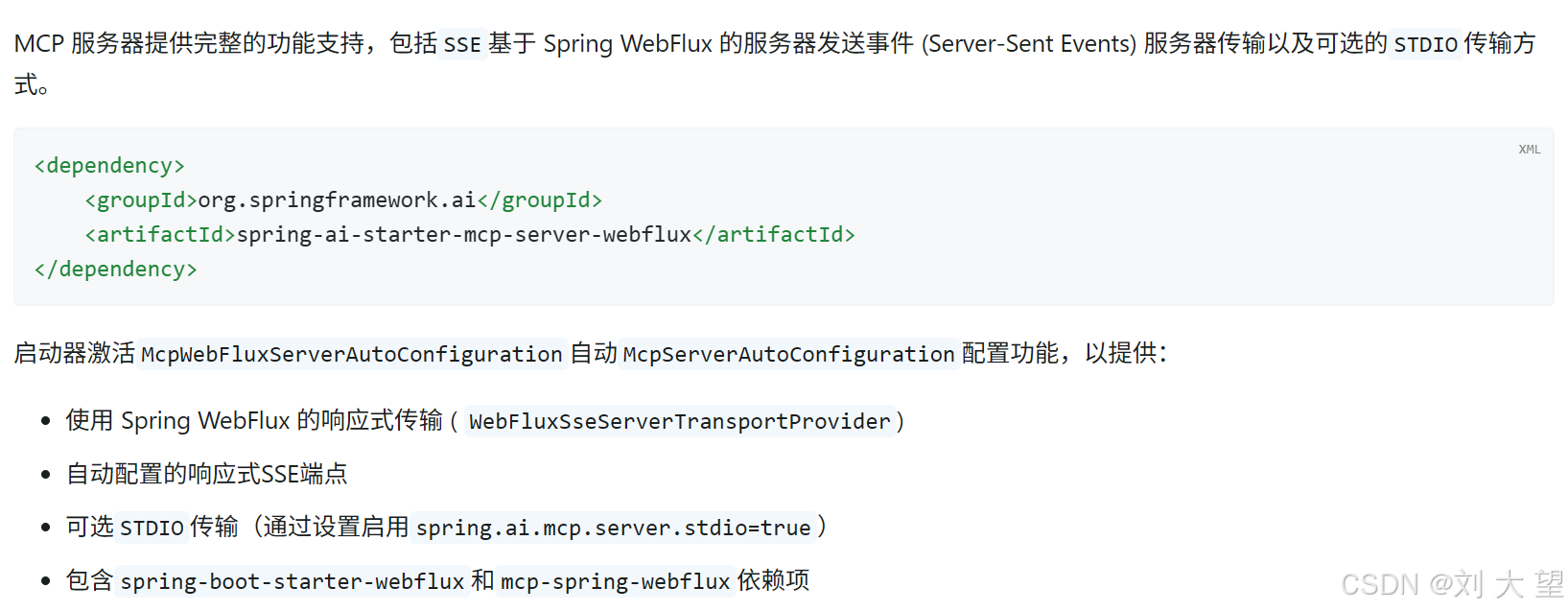
但如果用户在使用 spring-boot-starter-web构建的项目中添加 spring-ai-starter-mcp-server-webflux,就会导致 MCP 端点(例如 /sse)无法正常工作。 如下图
这是因为项目中同时存在
org.springframework.web.servlet.DispatcherServlet和org.springframework.web.reactive.DispatcherHandler,Spring Boot 默认优先考虑前者。可以通过设置
spring.main.web-application-type=reactive来解决
spring:
ai:
mcp:
server:
name: user-info
version: 0.0.1
main:
web-application-type: reactive #添加此配置BUG具体介绍请参考 以下链接
https://github.com/spring-projects/spring-ai/pull/3511
其他更多详细的关于spring ai关于mcp的介绍以及使用 参考以下链接
https://docs.spring.io/spring-ai/reference/1.0/api/mcp/mcp-overview.html
四.MCP部署
1.部署方式
MCP 支持多种传输方式,而不同的协议决定了不同的部署策略.
- 本地部署:适合于 Stdio 传输方式 (进程间通信)
- 远程部署:适合于 SSE, WebFlux SSE 传输方式 (基于 SSE 协议的通信)
sse也支持本地但是没必要 sse是通过http client调用的 部署远程更为合适
2.本地部署
本地部署其实就是我们上面案例中的部署方式,把 MCP Server 的代码进行打包,然后将其部署在主项目可以访问的路径。
比如把项目打包成 jar 包,然后把 jar 包上传到 MCP Client 能访问的路径,在配置文件中写清楚怎么启动它(比如用 java -jar xxx.jar 命令),主项目就能通过标准输入输出(stdio)跟它通信了。
这种方式比较简单粗暴,适合小项目,或者 demo 等不需要复杂的网络接口,也不用搞什么微服务,直接本地跑起来就行。
但问题来了:如果你有 5 个、10 个这样的 MCP 服务,是不是每个都得单独打包、上传、配一遍?那为什么不直接在主项目里多写几个工具调用,非要使用 MCP 的方式呢?
所以这种方式,虽然简单,但不够灵活,扩展性差,管理起来会比较麻烦。
3.远程部署
MCP服务远程部署与部署后端项目的流程是一样的,需要在服务器上部署服务。部署完成后就可以通过http调用。
作为 Java 开发者,更推荐使用远程部署,将MCP Server 注册为服务。
比如使用Nacos、Consul或者Eureka将 MCP Server 注册为微服务,然后由 API Gateway 统一暴露接口。
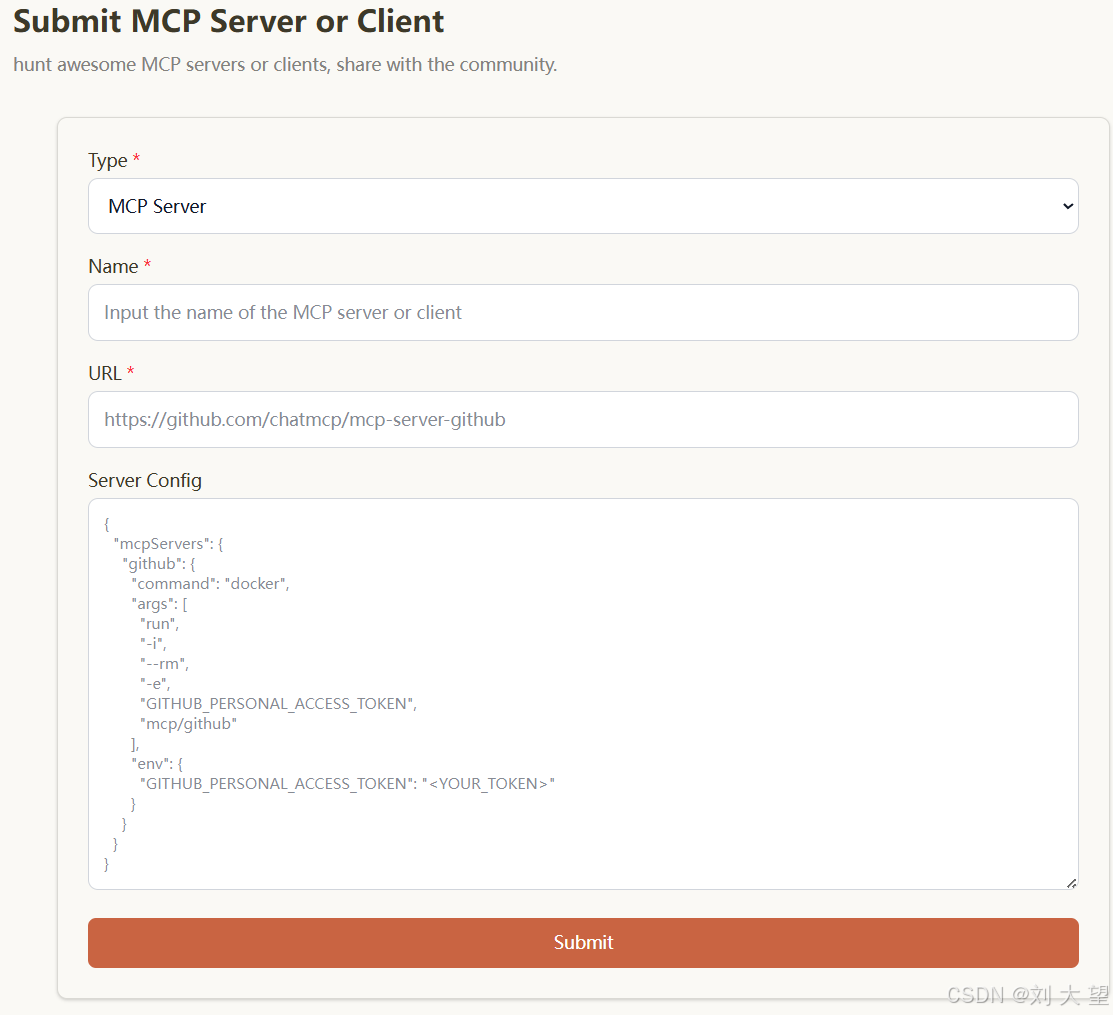
4.提交到平台
MCP服务部署好之后,还可以提交到各种MCP开源社区,让其他人也能使用你的MCP服务。
每个平台的提交规则不同,按各个平台要求操作即可。
大多数的MCP Server都是由python, ts/js开发的
五.MCP推荐
1.Playwright
Playwright MCP Server 是一个基于 Playwright 构建的 Model Context Protocol 服务实现,它作为 AI 模型与浏览器自动化之间的桥梁,使大语言模型能够通过标准化协议直接操作网页内容。
Playwright 是一个由 Microsoft 开发的自动化测试工具,它可以:
- 控制浏览器(Chrome、Firefox、Safari)
- 自动点击、输入、截图、爬取网页
- 模拟真实用户操作
参考链接:https://github.com/microsoft/playwright-mcp
这个一般的AI IDE都会有内置的浏览器子代理 像antigravity有browser_subagent 共工具
1.1安装 Playwright MCP Server
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}2.Fetch
MCP Fetch 是一个网页内容抓取服务器,使大型语言模型能够:
- 从互联网检索网页内容
- 将 HTML 转换为易读的 Markdown 格式
- 分块读取长网页
参考链接:https://github.com/modelcontextprotocol/servers/tree/main/src/fetch
2.1安装
"mcpServers": {
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}上述两个MCP Server都能在MCP社区搜索到
2.2使用两个MCP Server
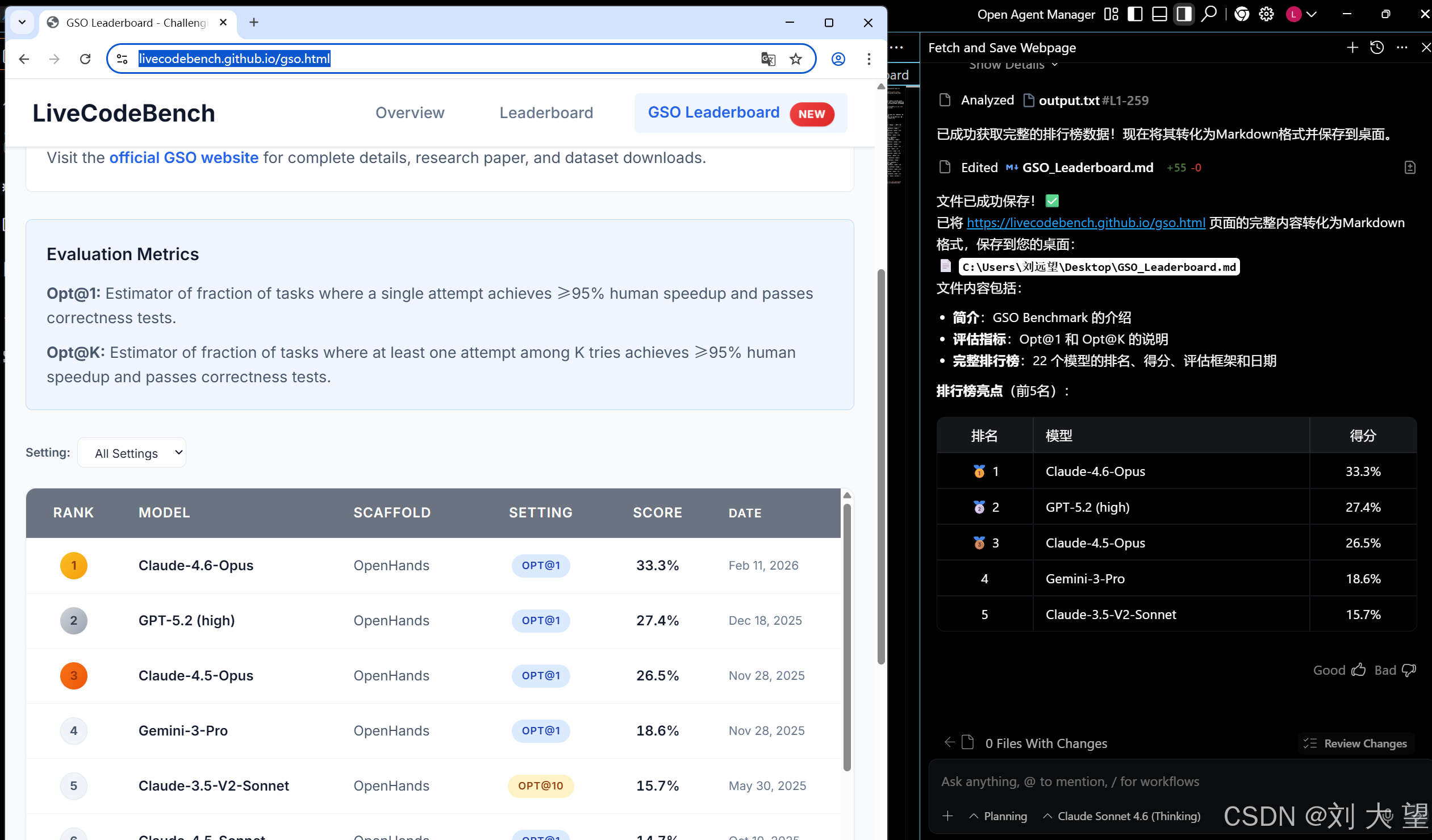
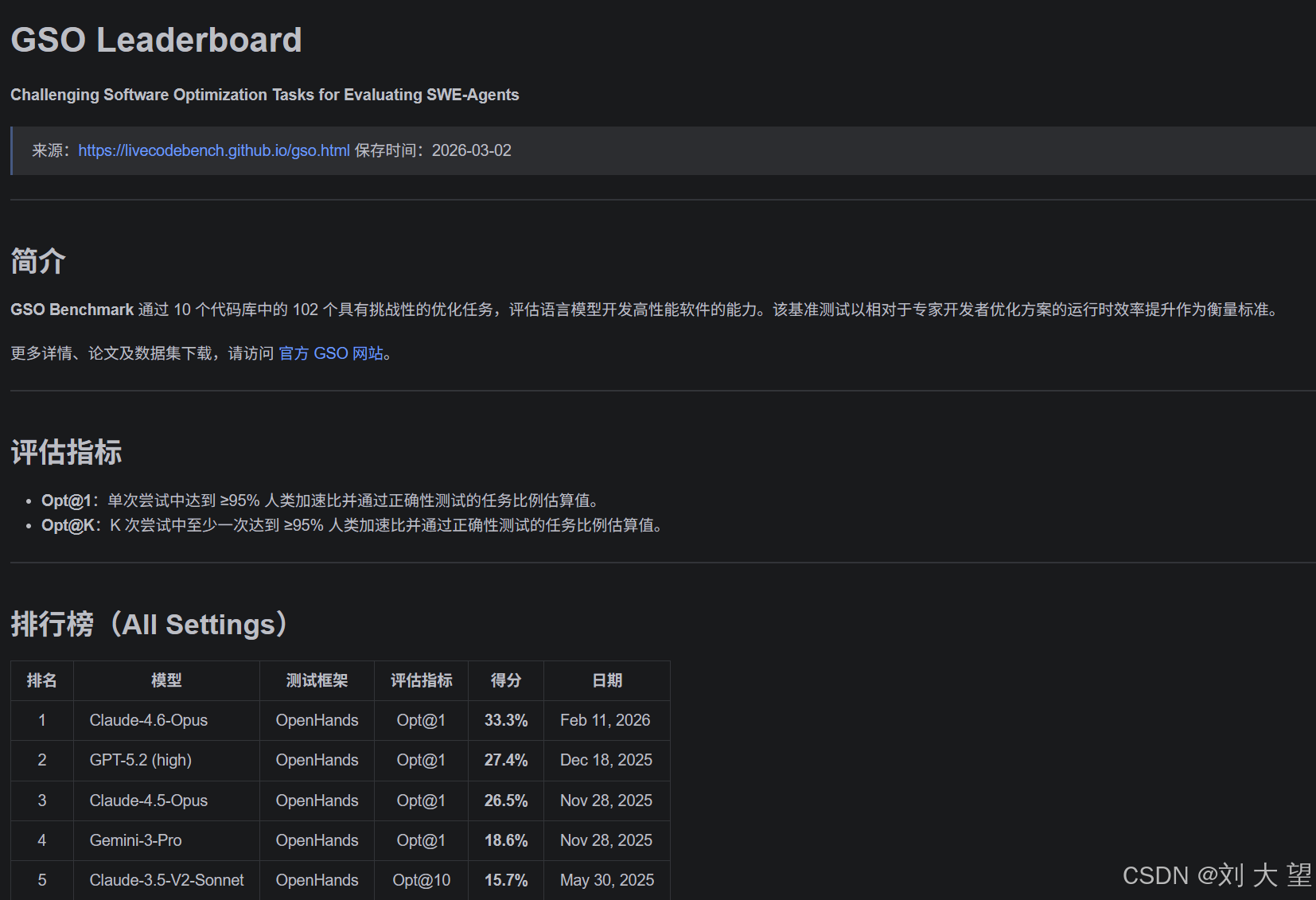
提示词
打开浏览器 搜索https://livecodebench.github.io/gso.html这个链接 然后将内容转化为markdown格式保存到我的桌面上
结果
更多好用的MCP Server可以去MCP 社区 也可以通过短视频搜索的方式推荐好用的MCP 总之建议使用官方的 使用个人MCP Server之前要确定没有恶意代码