****论文题目:****Deep digital twin-powered large vision-language model for multi-scenario industrial fault diagnosis(面向多场景工业故障诊断的深度数字双动力大视觉语言模型)
****期刊:****Advanced Engineering Informatics(AEI 2026,工程技术+人工智能 Top)
****摘要:****数据驱动的深度学习技术已广泛应用于工业健康监测和维护中。然而,传统的诊断方法往往受到特定场景的限制和智能能力不足的影响。近年来发展起来的大规模视觉语言模型(LVLMs)为智能故障诊断提供了一种先进的人机交互模式。本研究通过提出故障诊断通用语言模型(FDGLM)框架,将lvlm的应用扩展到工业故障诊断,实现了跨多个工况和数据集的智能诊断。首先,利用先进的数字孪生技术,生成高质量的振动样本来支持模型训练。使用短时傅里叶变换(STFT)对这些样本进行处理,生成增强的时频谱图,从而解决了FDGLM训练的大规模数据需求。随后,采用低秩自适应策略对预训练的视觉模型进行微调,结合交叉熵损失和环损失,共同提高识别工业故障时频特征的判别能力和鲁棒性。接下来,使用领域特定的文本指令对语言模型进行微调,以实现视觉和文本模式之间的深度对齐,从而支持因果故障分析和维护决策。最后,在四个不同的数据集上进行了交叉条件和跨数据集实验。结果显示,在相同条件下的诊断准确率为0.995,在不同条件下为0.890,在跨数据集场景下为0.947,同时也展示了专业水平的会话诊断能力。实验结果证实,FDGLM提供了适用于工业应用的可靠诊断,与现有框架相比,微调开销最小,性能优越。提出的框架代表了工业设备健康管理的下一代解决方案。
深度数字孪生赋能大型视觉语言模型:面向多场景工业故障诊断的 FDGLM 框架
一、背景:工业故障诊断面临的三重困境
工业设备的健康监测与预测性维护,长期以来依赖数据驱动的深度学习方法。然而,随着工业场景日益复杂,现有方法暴露出三个根本性瓶颈。
第一重困境:跨场景泛化能力差。 现有深度学习模型往往在特定工况(固定转速、固定负载)下训练,一旦工况变化或切换到不同设备,诊断精度会因"域偏移"而大幅下滑。一个在 1797 rpm 下训练好的模型,未必能正确诊断 1730 rpm 下的故障,更难以迁移到完全不同型号的轴承。
第二重困境:工业数据极度稀缺。 大型视觉语言模型(LVLM)的训练需要海量高质量样本,但工业设备故障发生概率低、复现代价高昂,真实故障数据严重不足。以 CWRU 和 HUST 数据集为例,每个健康状态的有效数据仅约 10 秒,按 1024 点不重叠分段,每类仅能得到 117--250 个样本,远不足以训练大模型。
第三重困境:通用大模型缺乏工业领域知识。 论文通过实验对比了 Qwen 3、DeepSeek-V3.1 和 GPT-5 三款主流通用 LVLM 在轴承时频图诊断中的表现(见图 16):Qwen 3 只能检测到异常频率分量,无法判断故障类别;DeepSeek-V3.1 甚至无法识别输入为振动信号时频图;GPT-5 虽能识别内圈故障,但缺乏故障机理解析和故障严重程度量化能力。这说明通用 LVLM 在工业专有场景存在明显短板,亟需领域定制化方案。

二、解决思路:FDGLM 框架全景
为系统解决上述问题,论文提出了 FDGLM(Fault Diagnosis General Language Model) 框架。整体由三个模块构成:
- 深度数字孪生模块:解决数据稀缺问题,生成大规模高质量孪生信号
- 信号预处理模块:将一维振动信号转化为二维时频谱图,适配视觉模型输入
- 大型视觉语言模型模块:通过两阶段 LoRA 微调,实现精准故障诊断与自然语言交互
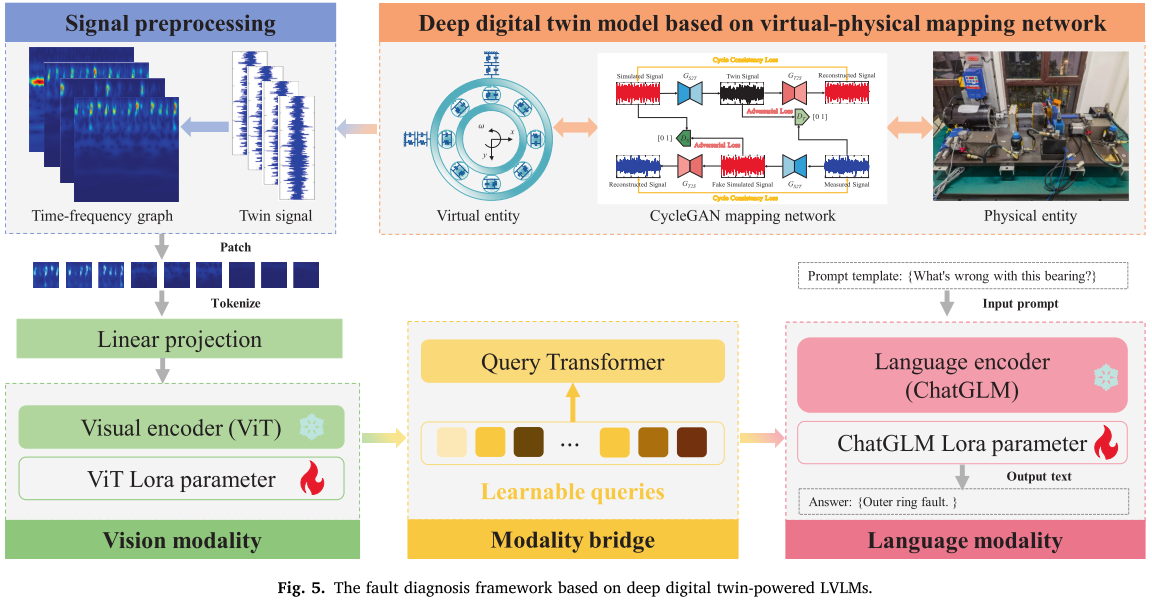
整个诊断流程闭环如下:数字孪生生成孪生信号 → STFT 转时频谱图 → ViT 提取视觉特征 → Q-Former 跨模态桥接 → ChatGLM-6B 输出诊断结论与维护建议。
三、深度数字孪生:让虚拟信号无限逼近真实
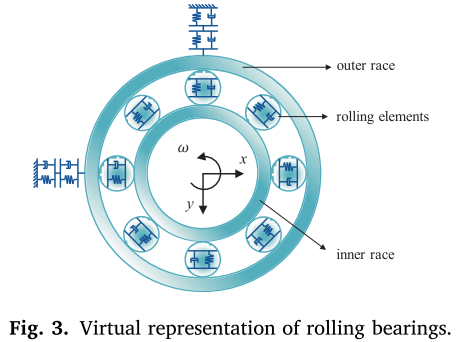
3.1 虚拟实体建模
论文采用六自由度动力学模型 对滚动轴承进行虚拟建模,涵盖内圈、外圈和轴承座三个子结构,共计六个自由度(见图 3)。模型整合了滚动体非线性接触、润滑膜阻尼和缺陷效应三类关键因素,通过 Hertz 接触理论建立运动方程,并利用 Runge-Kutta 方法进行数值求解,最终生成各健康状态下的加速度仿真信号。
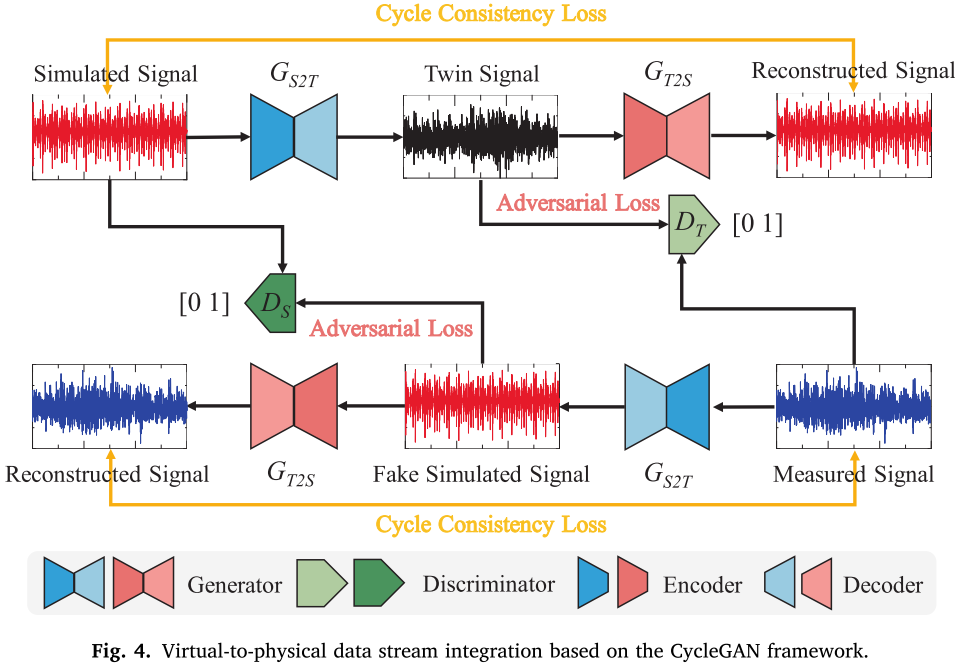
3.2 虚实映射网络:CycleGAN
仅靠仿真信号还不够,因为仿真信号缺乏环境噪声、制造公差等真实因素,与实测信号存在分布差距。为此,论文引入基于 CycleGAN 的双向虚实映射网络(见图 4),通过一对镜像对称的生成器-判别器,以对抗损失与循环一致性损失(比例为 0.1:1)联合优化,将仿真信号转化为高保真"孪生信号"。
效果如何? 论文通过三维度验证(见图 10、图 11 ,见表 2):
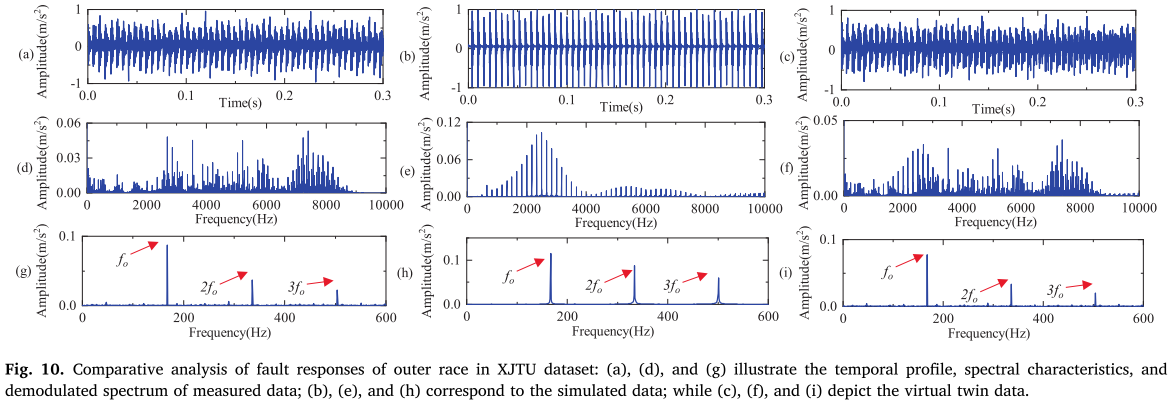
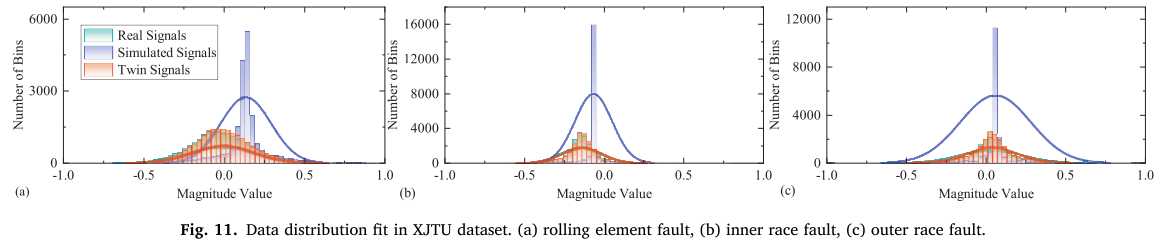
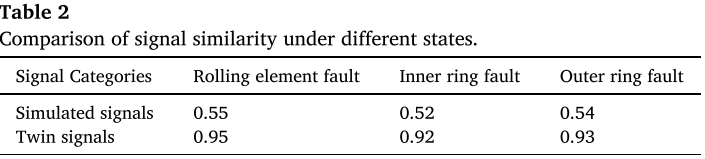
- 时域:孪生信号保留了与真实信号一致的周期冲击规律
- 包络谱:故障特征频率及其谐波清晰对齐
- Pearson 相关系数 :仿真信号与真实信号的相关系数约为 0.5,而孪生信号与真实信号的相关系数超过 0.92,大幅缩小了虚实分布差距
四、两阶段渐进式微调:从通用到专用
FDGLM 的核心训练策略是两阶段 LoRA 微调,分别针对视觉编码器和语言编码器进行渐进式域适应。
4.1 为什么用 LoRA?
大型模型从头训练或全参数微调的计算代价极高。LoRA(低秩适应)通过在预训练权重矩阵旁插入低秩分解矩阵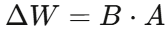 (其中
(其中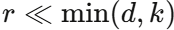 ),仅更新极少量参数即可实现性能接近全参微调的效果(见图 2 )。FDGLM 将 LoRA 矩阵分别注入 ViT 的第 0、13、26、38 层和 ChatGLM-6B 的第 0、13、27 层,全框架可训练参数仅 0.86M,总参数量 72 亿的大模型得以在消费级 GPU 上高效运行。
),仅更新极少量参数即可实现性能接近全参微调的效果(见图 2 )。FDGLM 将 LoRA 矩阵分别注入 ViT 的第 0、13、26、38 层和 ChatGLM-6B 的第 0、13、27 层,全框架可训练参数仅 0.86M,总参数量 72 亿的大模型得以在消费级 GPU 上高效运行。
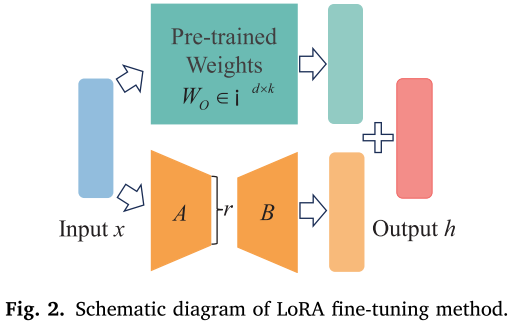
Fig. 2(LoRA 微调原理示意图)
4.2 第一阶段:视觉编码器微调
预训练的 ViT 在自然图像上表现优异,但振动信号时频图与自然图像在视觉特性上存在本质差异,需要专门适配。
本阶段冻结 ViT 全部预训练参数,仅更新插入的 LoRA 矩阵,联合使用两个损失函数:
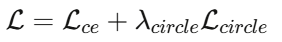
- 交叉熵损失 Lce:作为主分类损失,引导模型建立各健康状态的决策边界
- Circle 对比损失Lcircle:通过构造正负样本对,最大化同类相似度、最小化异类相似度,提升特征的判别性和跨工况鲁棒性
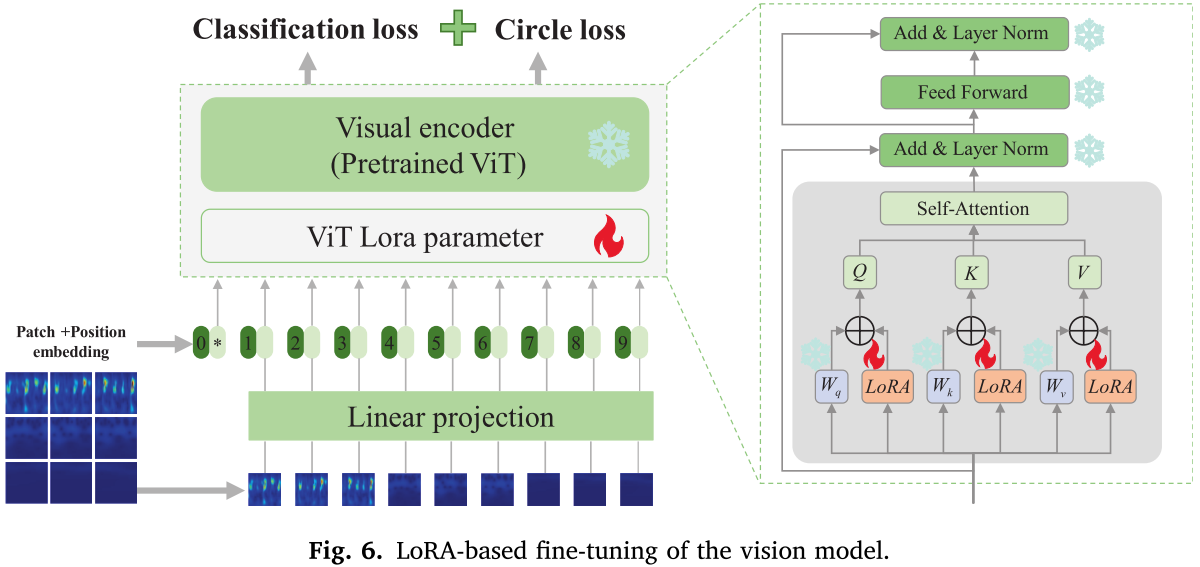
Fig. 6(视觉模型 LoRA 微调示意图)
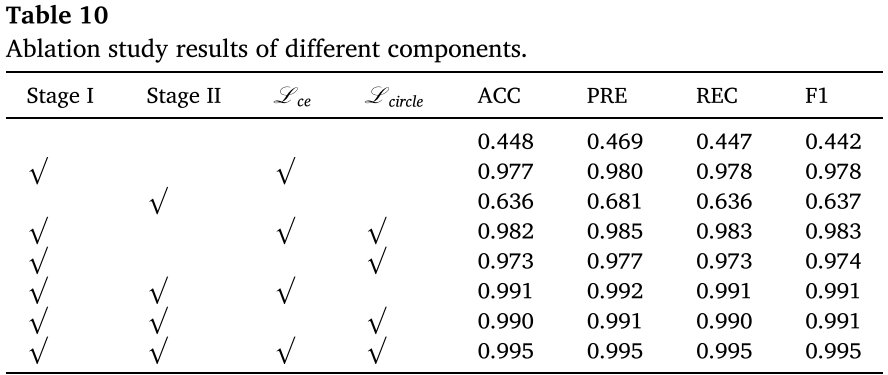
两种损失的协同效果在消融实验中得到验证(见表 10 ):单独使用 CE Loss 精度为 0.977,单独使用 Circle Loss 为 0.973,两者联合使用提升至 0.991,展现出明显的互补性。
4.3 跨模态桥接:Q-Former
第一阶段输出的视觉特征需要"翻译"为语言模型可理解的语义表示,这由 Q-Former(Query Transformer) 完成(见图 8)。Q-Former 通过一组可学习查询向量,以交叉注意力机制从冻结的 ViT 特征中抽取与诊断任务相关的语义信息,再经自注意力增强语义一致性,最终输出送入语言编码器。
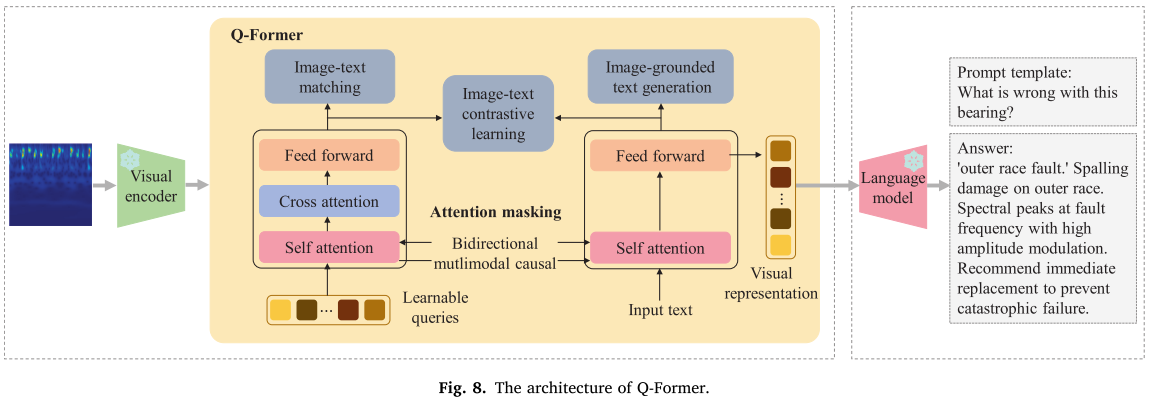
Fig. 8(Q-Former 架构图)
4.4 第二阶段:语言编码器微调
本阶段对 ChatGLM-6B 语言模型进行 LoRA 微调。输入为时频视觉 token(来自 Q-Former)与文本 token(如"What is the fault with the bearing?")的多模态拼接,优化目标为自回归损失:
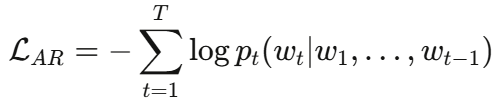
训练数据为自定义的图文对数据集,文本标签基于专家知识模板生成,包含诊断结果、健康状态描述和维护建议,也可借助 ChatGPT 辅助生成。
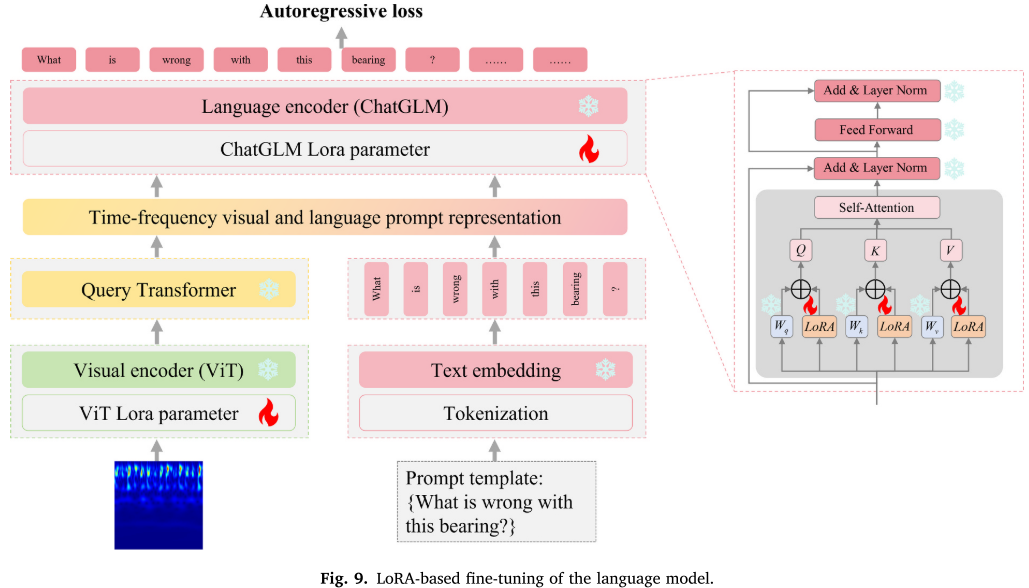
Fig. 9(语言模型 LoRA 微调示意图)
五、实验验证:三大场景全面评估
5.1 数据集配置
论文使用四个轴承数据集进行综合评估:
| 数据集 | 采样频率 | 轴承型号 | 特点 |
|---|---|---|---|
| CWRU | 12 kHz | SKF 6205 | 4 种工况,3 级故障深度 |
| HUST | 25.6 kHz | ER-16K | 多转速,三轴加速度计 |
| PU | 64 kHz | SKF 6203 | 人工损伤+加速寿命测试 |
| XJTU(自采) | 12 kHz | SKF 6207 | 12 种工况,4 类健康状态 |
每个健康类别通过数字孪生增广至 3000 个样本,振动信号经 STFT 转换为 1024 点时频谱图作为视觉输入。
5.2 场景一:单工况验证
在 XJTU 和 HUST 数据集上,FDGLM 与 SVM、MLP、DCNN、ResNet18、DenseNet121、VGG16、ViT、Swin-Transformer、ConvNeXt、ChatGLM2-6B-chat、VisualGLM 等 11 种方法对比。
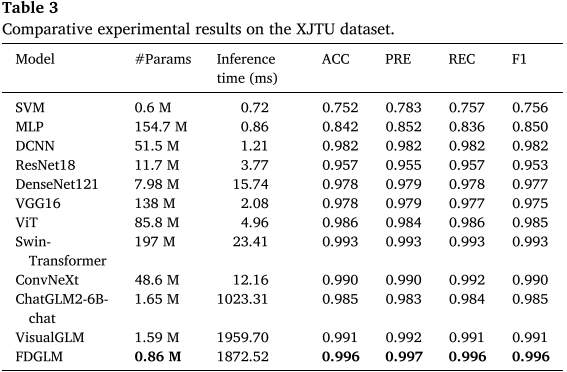
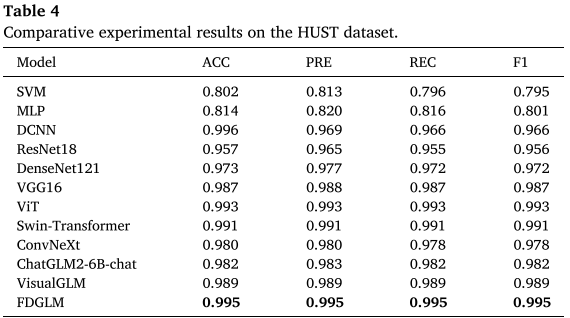
表 3 (XJTU 数据集对比结果)和 表 4(HUST 数据集对比结果)
关键结论:
- FDGLM 在 XJTU 数据集上达到 ACC=0.996、F1=0.996 ,在 HUST 数据集上达到 ACC=0.995、F1=0.995,均为最高
- 可训练参数仅 0.86M,远少于 ViT(85.8M 全参)等方法,却取得最佳性能
- 推理时延约 1872 ms,高于传统方法但在可接受范围内;未来可通过量化、剪枝进一步压缩
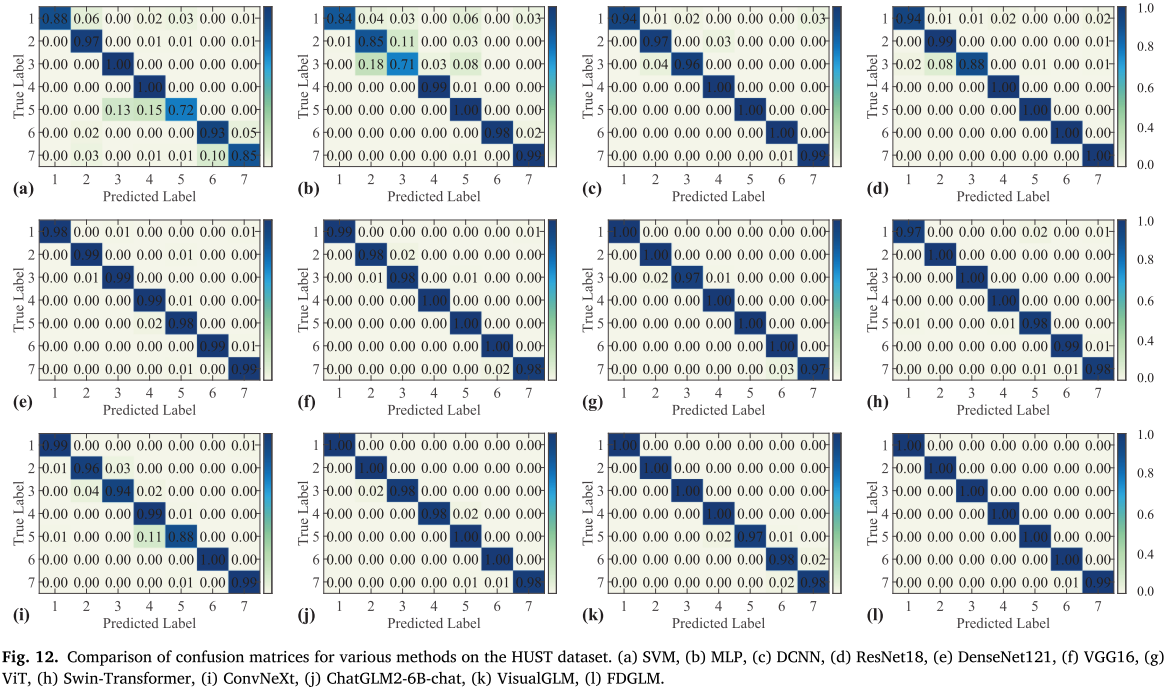
Fig. 12(混淆矩阵对比)
混淆矩阵显示,SVM 和 MLP 存在大量跨类误分,而 FDGLM 几乎完美分类,仅极少数同类别不同严重程度的样本出现误判------这也是所有方法共同的难点。
FDGLM 还具备通用 LVLM 所不具备的人机交互诊断界面 :用户输入时频图和自然语言提示,模型即可生成包含故障类型、机理分析和维护建议的完整诊断报告(见图 13、14、15)。
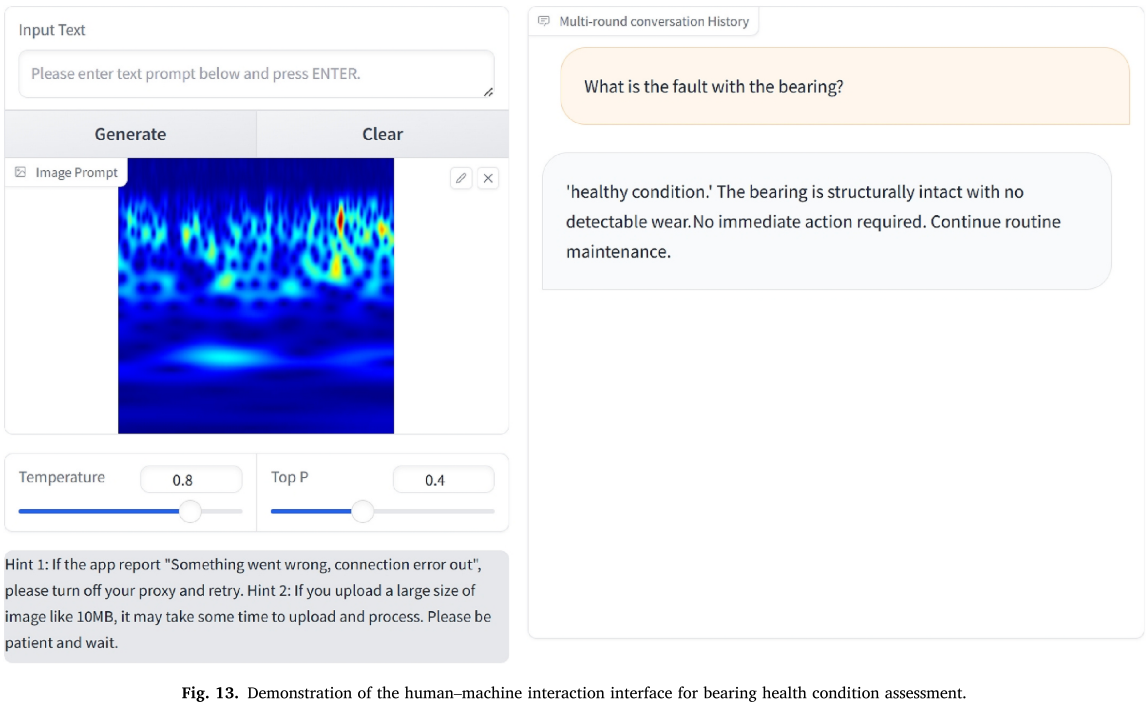


Fig. 13 (人机交互界面展示)和 Fig. 14、15(定性诊断案例)
5.3 场景二:跨工况验证
论文在 CWRU 和 HUST 数据集上各设计 4 个跨工况任务(3 个工况训练、1 个工况测试)。
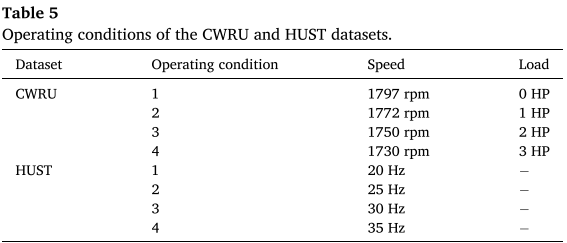
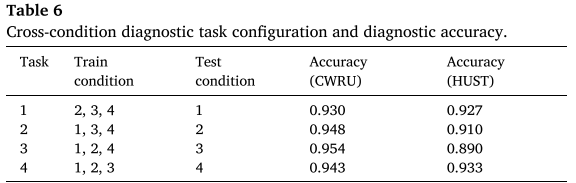
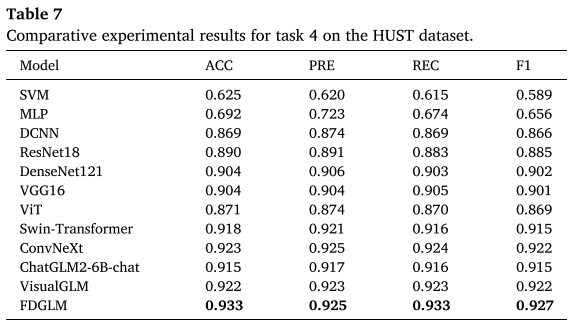
表 5、表 6 (工况配置与精度)和 表 7(HUST Task 4 对比结果)
关键数据:
| 数据集 | 任务 | 测试工况 | FDGLM 精度 |
|---|---|---|---|
| CWRU | Task 1--4 | 各单工况 | 93.0%--95.4% |
| HUST | Task 1--4 | 各单工况 | 89.0%--93.3% |
HUST Task 3(转速变化最大)精度最低(89.0%),但仍优于同场景下的 Swin-Transformer(91.6%)和 ConvNeXt(92.2%)。重要的是,FDGLM 无需修改模型架构或损失函数即可实现跨工况迁移,泛化能力源于 Circle Loss 训练出的条件不变特征表示。
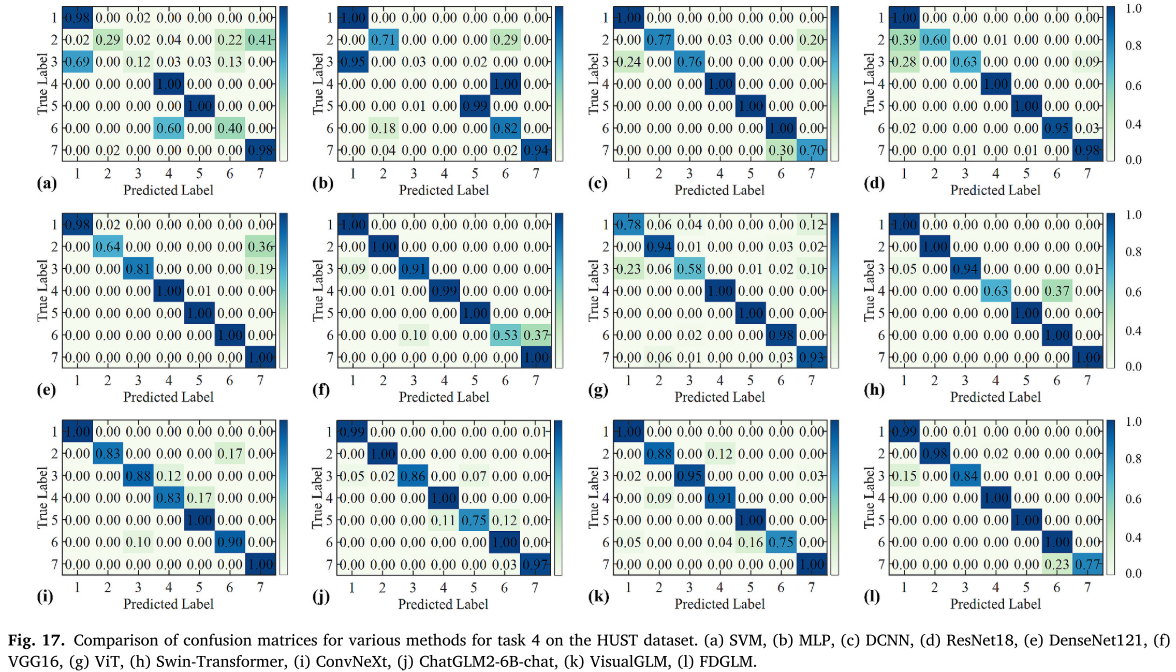
Fig. 17(跨工况混淆矩阵对比)
5.4 场景三:跨数据集验证
论文设计了四个跨数据集任务,确保训练集和测试集来自不同数据集,统一在三类健康状态(正常、内圈故障、外圈故障)上对齐。
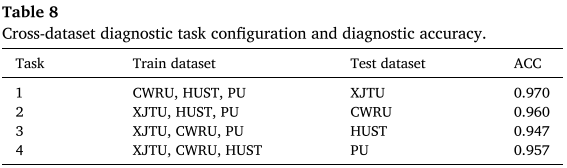
表 8(跨数据集任务配置与精度)
| 任务 | 训练集 | 测试集 | 精度 |
|---|---|---|---|
| Task 1 | CWRU+HUST+PU | XJTU | 0.970 |
| Task 2 | XJTU+HUST+PU | CWRU | 0.960 |
| Task 3 | XJTU+CWRU+PU | HUST | 0.947 |
| Task 4 | XJTU+CWRU+HUST | PU | 0.957 |
Task 3 精度最低(0.947),原因是 HUST 使用的 ER-16K 轴承型号与其他数据集的 SKF 系列存在较大分布差距。总体平均精度 95.9%,证明 FDGLM 具备强大的跨域故障特征提取和知识迁移能力。
六、超参数分析
6.1 LoRA 矩阵秩的影响
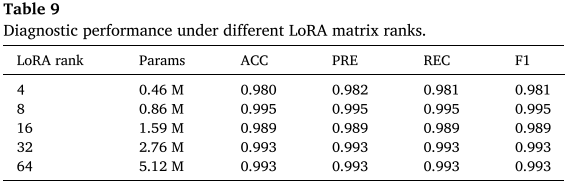
表 9(不同 LoRA rank 的诊断性能)
论文系统测试了 rank ∈ {4, 8, 16, 32, 64} 的性能表现:
| LoRA rank | 可训练参数 | 精度(ACC) |
|---|---|---|
| 4 | 0.46M | 0.980 |
| 8 | 0.86M | 0.995 |
| 16 | 1.59M | 0.989 |
| 32 | 2.76M | 0.993 |
| 64 | 5.12M | 0.993 |
结论:精度并非随 rank 单调增长。rank 超过 16 后,由于参数量增加引入过拟合风险,性能反而略有下降。rank = 8 在当前数据量和硬件条件下达到最优平衡,被全文采用。
6.2 训练数据量的影响
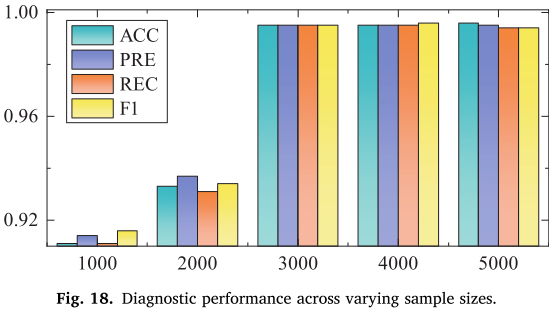
Fig. 18(不同样本量下的诊断性能折线图)
| 每类样本数 | ACC |
|---|---|
| 1,000 | 0.911 |
| 2,000 | 0.933 |
| 3,000 | 0.995 |
| 4,000 | 边际提升,统计不显著 |
| 5,000 | 边际提升,统计不显著 |
从 2000 到 3000 样本,精度出现显著跃升(+0.062);超过 3000 后趋于饱和。这说明深度数字孪生每类生成 3000 个样本是当前框架下的充分条件,无需更多真实数据。
七、消融实验
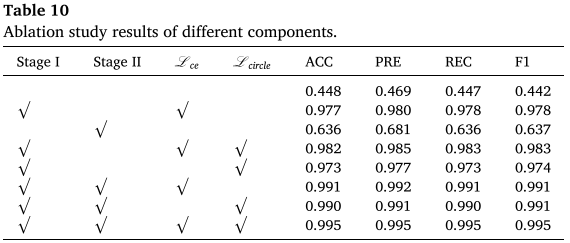
表 10(各组件消融结果)
论文系统验证了各核心组件的贡献,结论如下:
| 配置 | ACC |
|---|---|
| 无任何微调(直接使用预训练模型) | 0.448 |
| 仅微调语言模型(Stage II) | 0.636 |
| 仅 Stage I + CE Loss | 0.977 |
| 仅 Stage I + Circle Loss | 0.973 |
| Stage I(CE + Circle)+ Stage II | 0.995 |
关键发现:
- 视觉编码器微调(Stage I)是最关键的环节,跳过它直接微调语言模型会导致精度崩塌
- CE Loss 与 Circle Loss 缺一不可,联合使用比单独使用高出约 0.4--0.5 个百分点
- 在优化好的视觉编码器基础上再进行语言模型微调(Stage II),能进一步挖掘视觉语义与文本的深层对齐潜力
八、总结与展望
FDGLM 框架的核心贡献在于打通了"数据稀缺 → 大模型训练 → 多场景部署"的完整链路:
- 用深度数字孪生解决了工业标注数据匮乏的根本难题
- 用两阶段 LoRA 微调 + 双损失优化实现了视觉与语言的深度工业域适应
- 用Q-Former 跨模态桥接支持了超越标签输出的智能诊断对话
实验结果表明,FDGLM 在单工况(99.6%)、跨工况(91.5% 平均)、跨数据集(95.9% 平均)三大场景下均取得最优性能,且可训练参数仅 0.86M,具备实际工业部署的可行性。
未来方向,论文指出两个关键挑战:
- 少样本/零样本诊断:面对从未见过的故障类型(例如突发性故障),如何仅凭极少样本完成诊断
- 噪声鲁棒性:工业现场信号往往受到强烈干扰,设计专门面向大型模型的降噪方法是另一重要研究方向
FDGLM 代表着工业 PHM 领域从"分类器"向"智能诊断助手"演进的重要一步,为工业设备健康管理的下一代解决方案提供了有力参考。