在编程开发中,字符串模式匹配是非常基础且常用的操作,核心需求是在一个主字符串(str)中查找指定子字符串(pattern,模式串)的首次出现位置。本文将介绍两种经典的模式匹配算法 ------ 暴力匹配算法和 KMP 算法,通过 C 语言代码实现深入解析其原理、执行过程及优缺点,帮助大家理解两种算法的核心差异。
一、暴力匹配算法(BF 算法)
暴力匹配算法(Brute Force)也叫朴素匹配算法,是最简单的字符串模式匹配方法,核心思路是逐位比对,失配回溯,通过两层循环依次尝试主字符串中所有可能的起始位置,与模式串进行匹配。
1. 算法核心原理
- 设主字符串长度为
n,模式串长度为m,主字符串的匹配起始位置i从 0 开始,最大到n-m(超出后剩余字符不足以匹配模式串)。 - 模式串的比对指针
j从 0 开始,逐位比较str[i]和pattern[j]。 - 若字符相等,
i和j同时后移,继续比对下一位;若字符不相等,主字符串指针回溯 到本次起始位置的下一位(i = i - j),模式串指针j重置为 0,重新开始匹配。 - 若模式串指针
j遍历完所有字符(j == m),说明匹配成功,返回本次匹配的起始位置(i - j);若主字符串遍历完仍未匹配,返回 - 1。 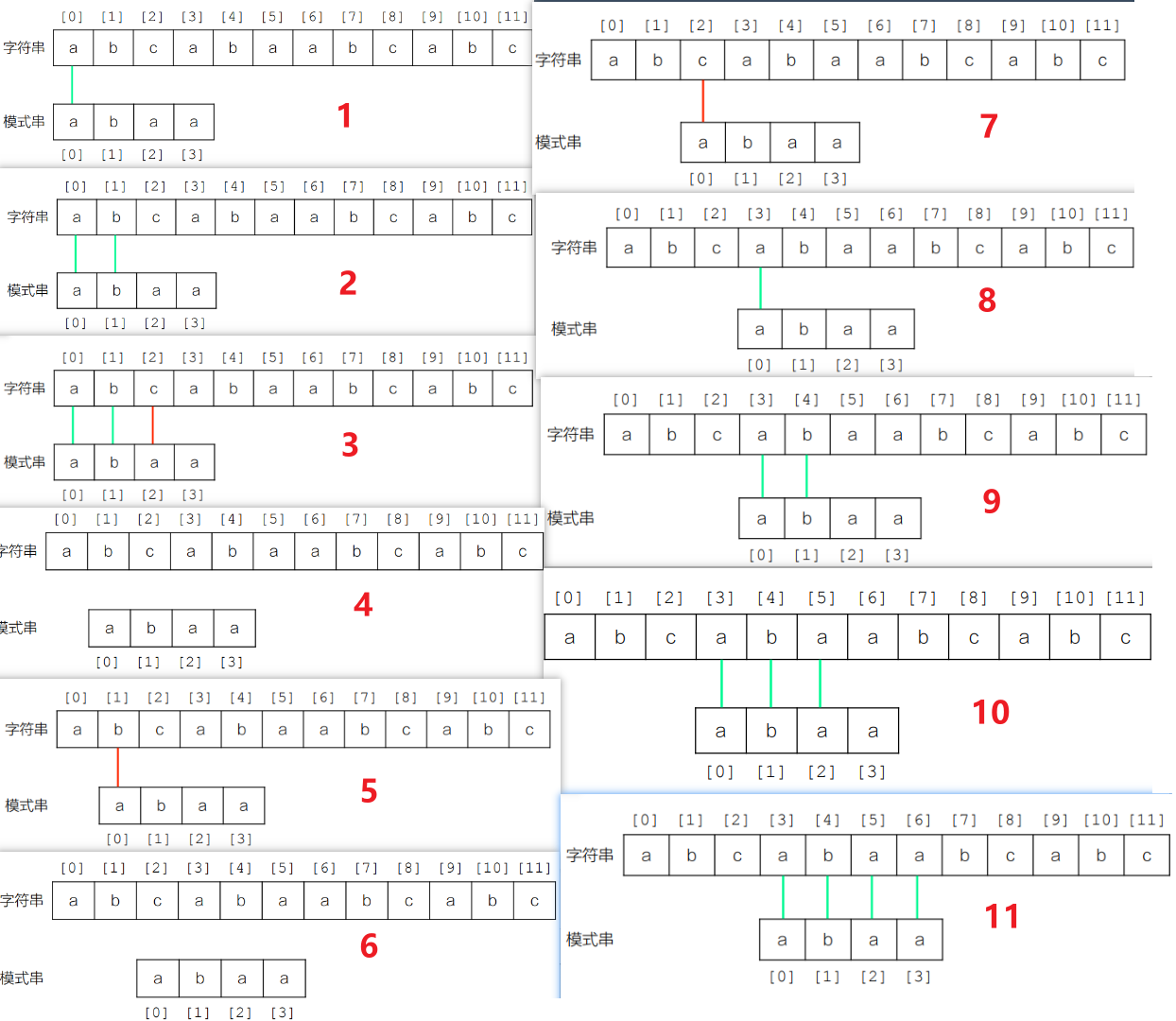
2. C 语言代码实现
cpp
#include <stdio.h>
#include <string.h>
/**
* 暴力字符串模式匹配函数
* @param str 主字符串(被查找的长串)
* @param pattern 模式串(要查找的短串)
* @return 找到:返回模式串在主串中第一次出现的起始下标
* 没找到:返回 -1
*/
int strMatch(char* str, char* pattern)
{
// 获取主字符串的长度
int n = strlen(str);
// 获取模式串的长度
int m = strlen(pattern);
// 外层循环:控制主串的【匹配起始位置】i
// 主串最多只能从 n-m 位置开始匹配,否则剩余字符不够匹配模式串
for (int i = 0; i <= (n - m); i++)
{
// 每次重新匹配,模式串指针 j 都从 0 开始
int j = 0;
// 内层循环:逐字符对比
while(j < m)
{
// 如果当前主串字符 == 模式串字符,两个指针同时向后移动
if (str[i] == pattern[j])
{
i++; // 主串指针后移
j++; // 模式串指针后移
}
// 字符不相等,发生失配,需要回溯
else
{
// 关键:主串 i 回溯到【本次匹配起始位置的下一位】
i = i - j;
// 退出内层循环,重新开始下一轮匹配
break;
}
}
// 如果 j 走完了整个模式串,说明完全匹配成功
if (j == m)
{
// 返回匹配的起始位置(i - j 是因为 i 已经后移过了)
return i - j;
}
}
// 循环结束都没找到,返回 -1
return -1;
}
// 主函数:测试暴力匹配算法
int main(int argc, char const *argv[])
{
// 定义主串
char* str = "abcabaabcabc";
// 定义要查找的模式串
char* pattern = "abaa";
// 调用匹配函数
int pos = strMatch(str, pattern);
// 输出结果:找到则输出下标,没找到输出 -1
printf("模式串出现的位置:%d\n", pos);
return 0;
} 3. 算法特点
3. 算法特点
- 优点:逻辑简单,代码实现直观,无需额外的预处理步骤,适合短字符串的简单匹配场景。
- 缺点 :效率低下,存在大量的无效回溯 。当主字符串和模式串存在部分匹配的前缀时,主字符串指针需要回退到初始位置,重新比对,最坏时间复杂度为O(n*m)(n 为主串长度,m 为模式串长度)。
- 测试结果 :上述代码中主串
abcabaabcabc与模式串abaa无匹配,最终输出-1。
二、KMP 算法
KMP 算法由 Knuth、Morris、Pratt 三位学者提出,是对暴力匹配算法的优化,核心解决了暴力算法中主字符串指针回溯 的问题,通过对模式串进行预处理生成 next 数组,记录模式串失配时的回退位置,让主字符串指针始终只向后移动,大幅提升匹配效率。

1. 算法核心原理
KMP 算法的核心是next 数组 ,next 数组的长度与模式串一致,next[j]表示模式串中第j位字符失配时,模式串指针需要回退到的位置,本质是找模式串前缀和后缀的最长相等子串长度。整个算法分为两个阶段:
- 预处理阶段:遍历模式串,生成 next 数组,记录每个位置的失配回退点。
- 匹配阶段 :主串指针
i和模式串指针j均从 0 开始,逐位比对;若失配,根据 next 数组让模式串指针j回退,主串指针i保持不变;若匹配成功,两个指针同时后移,直到匹配完成或主串遍历结束。
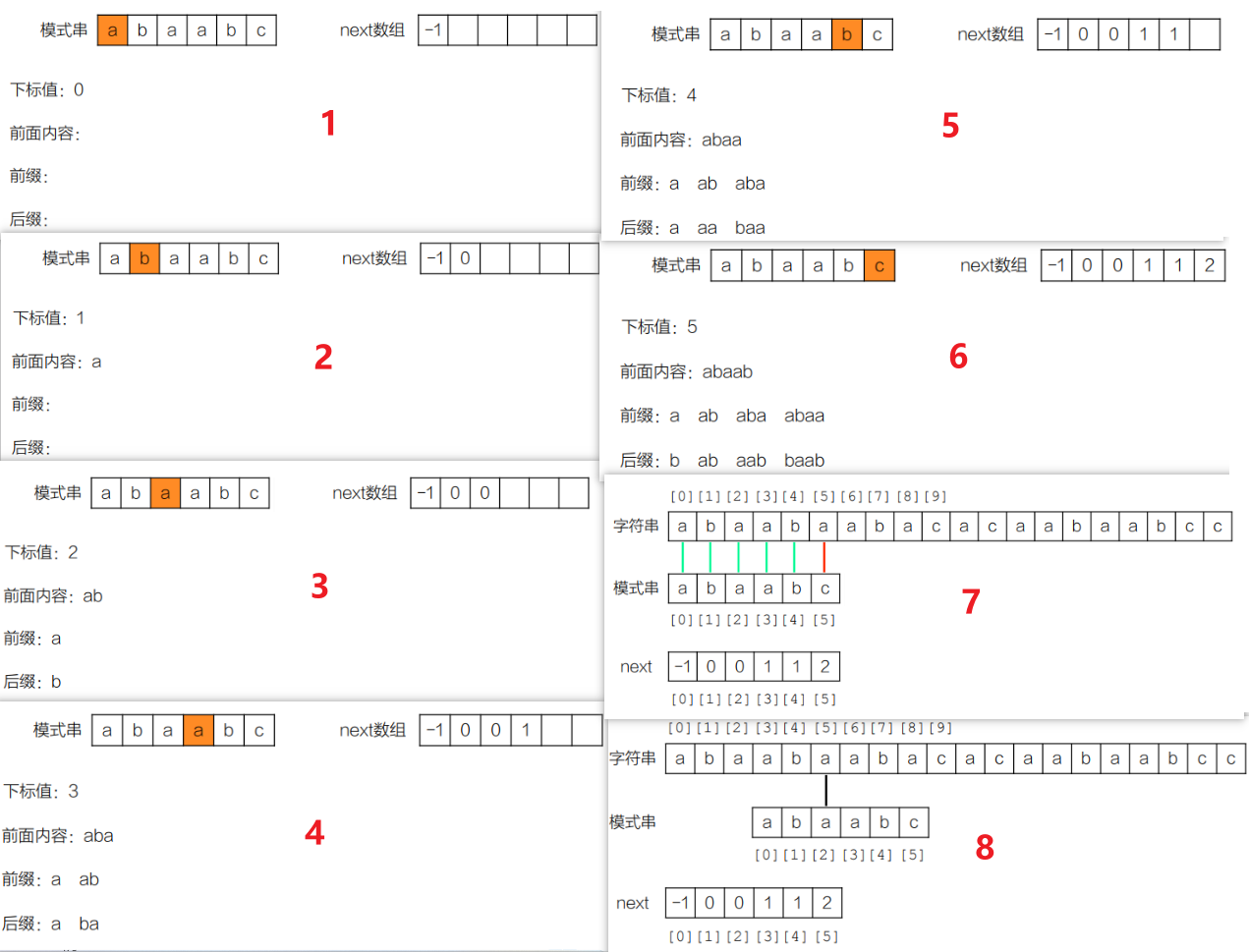
2. 关键:next 数组的生成
next 数组的生成规则(本文实现为基础版 next 数组):初始化next[0] = -1(模式串首位失配,主串指针后移,模式串指针回退到 -1,这是人为定义的边界条件),同时定义两个指针:i为模式串的遍历指针,从 0 开始,负责逐个遍历模式串字符;j为前缀后缀匹配指针,初始值为 - 1,负责记录当前位置前的模式串中,前缀和后缀的最长相等子串长度,也是失配时的回退目标位置。
随后进入循环遍历模式串(i < 模式串长度m),核心逻辑分两种情况:
- 当
j == -1或pattern[i] == pattern[j]时 :j == -1表示当前回到匹配起点,无任何前缀后缀可匹配;而pattern[i] == pattern[j]表示当前字符匹配成功,说明找到更长的相等前后缀。此时将i和j同时向后移动一位,再将next[i]赋值为j,这个j值就是模式串第i位字符失配时,需要回退到的目标位置。 - 当
pattern[i] != pattern[j]时 :说明当前字符匹配失败,无法形成更长的相等前后缀,此时需要让j根据已生成的 next 数组向前回退 ,即j = next[j],重新寻找更短的相等前后缀,直到满足j == -1或字符匹配成功为止。
整个 next 数组的生成过程,本质是模式串自己和自己做匹配 ,通过不断寻找前后缀的最长相等子串,提前记录所有位置的失配回退点,为后续的主串匹配阶段做预处理,这一步的时间复杂度为O(m)(m 为模式串长度)。
3. C 语言代码实现(带完整详细注释)
cpp
#include <stdio.h>
#include <string.h>
/**
* 预处理模式串,生成KMP核心的next数组
* @param pattern 待处理的模式串
* @param next 用于存储回退位置的next数组
*/
void getNext(char* pattern, int* next)
{
int m = strlen(pattern); // 获取模式串长度
int i = 0; // 模式串遍历指针,从0开始
int j = -1; // 前后缀匹配指针,初始为-1(边界条件)
next[0] = -1; // next数组首位固定为-1,人为定义的失配边界
// 遍历模式串,生成完整的next数组(i < m 避免数组越界)
while(i < m)
{
// 边界情况 或 当前字符匹配成功,拓展相等前后缀
if (j == -1 || pattern[i] == pattern[j])
{
i++; // 模式串遍历指针后移
j++; // 前后缀匹配长度+1,回退位置后移
next[i] = j; // 记录当前位置的失配回退点
}
else
{
j = next[j]; // 字符匹配失败,j根据next数组向前回退
}
}
}
/**
* KMP算法核心匹配函数
* @param str 主字符串(被查找的长串)
* @param pattern 模式串(要查找的短串)
* @return 匹配成功:返回模式串在主串中首次出现的起始下标
* 匹配失败:返回-1
*/
int kmp(char* str, char* pattern)
{
int i = 0; // 主串遍历指针,从不回溯,仅向后移动
int j = 0; // 模式串遍历指针,失配时根据next回退
int next[100]; // 定义next数组,存储模式串失配回退点
getNext(pattern, next); // 预处理模式串,生成next数组
int n = strlen(str); // 获取主串长度
int m = strlen(pattern); // 获取模式串长度
// 主串和模式串均未遍历完时,继续匹配
while(i < n && j < m)
{
// 模式串回退到边界 或 当前主串与模式串字符匹配成功
if (j == -1 || str[i] == pattern[j])
{
i++; // 主串指针后移,继续匹配下一位
j++; // 模式串指针后移,继续匹配下一位
}
else
{
j = next[j]; // 字符失配,主串指针不动,模式串指针按next回退
}
}
// 若模式串指针遍历完所有字符,说明完全匹配成功
if (j == m)
{
return i - j; // 计算并返回模式串在主串中的起始下标
}
else
{
return -1; // 匹配失败,返回-1
}
}
// 主函数:测试KMP算法匹配效果
int main(int argc, char const *argv[])
{
char* str = "abaabaabacacaabaabcc"; // 定义主字符串
char* pattern = "abaabc"; // 定义要查找的模式串
printf("%d\n", kmp(str, pattern)); // 调用KMP函数,打印匹配结果
return 0;
} 4. 算法匹配执行示例
4. 算法匹配执行示例
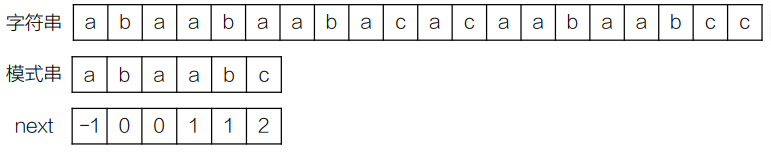
以上述测试代码为例,主串为abaabaabacacaabaabcc,模式串为abaabc,经getNext函数预处理后,生成的 next 数组为[-1,0,0,1,2,0]。
匹配过程中,主串指针i始终向后移动,当遇到字符失配时,模式串指针j根据 next 数组回退到对应位置(而非重置为 0),最终会在主串下标 5 的位置匹配到模式串,因此代码运行结果输出5。
5. 算法特点
- 优点 :彻底解决了暴力算法的无效回溯问题,主串指针仅遍历一次,预处理阶段时间复杂度 O (m),匹配阶段时间复杂度 O (n),整体时间复杂度为 O (n+m)(n 为主串长度,m 为模式串长度),在长字符串匹配场景下效率远高于暴力算法。
- 缺点 :基础版 next 数组存在少量冗余回退(可通过优化 next 数组为 nextval 数组解决);需要额外的数组空间存储 next 数组,空间复杂度为 O (m),属于空间换时间的经典算法设计思路。
三、暴力算法与 KMP 算法核心对比
| 对比维度 | 暴力匹配算法(BF) | KMP 算法 |
|---|---|---|
| 核心思路 | 逐位匹配,失配后主串、模式串指针均回溯 | 预处理模式串生成 next 数组,失配仅模式串指针回退,主串指针不回溯 |
| 时间复杂度 | 最坏 O (n*m),最好 O (n) | 整体 O (n+m),无最坏情况,效率稳定 |
| 空间复杂度 | O (1),无需额外辅助空间 | O (m),需要存储 next 数组 |
| 实现难度 | 逻辑简单,代码易实现 | 需理解 next 数组原理,实现稍复杂 |
| 适用场景 | 短字符串、简单匹配场景,对效率要求不高 | 长字符串、高频匹配场景,对效率要求较高 |
四、408真题演练

KMP 算法的核心是next 数组 ,失配时通过next数组回退模式串指针j,主串指针i保持不变。
-
确定模式串
t:t = "abaababc",索引从 0 开始:索引 j 0 1 2 3 4 5 6 7 字符 t j a b a a b a b c -
计算模式串的
next数组 :next[j]表示t[0..j-1]的最长公共前后缀长度。next[0] = -1(约定)next[1] = 0(子串"a"无前后缀)next[2] = 0(子串"ab")next[3] = 1(子串"aba",最长公共前后缀为"a")next[4] = 2(子串"abaa",最长公共前后缀为"ab")next[5] = 2(子串"abaab",最长公共前后缀为"ab")next[6] = 3(子串"abaaba",最长公共前后缀为"aba")next[7] = 4(子串"abaabab",最长公共前后缀为"abab")
完整
next数组:[-1, 0, 0, 1, 2, 2, 3, 4] -
失配处理 :题目中第一次失配时
i=5, j=5,根据 KMP 规则:- 主串指针
i保持不变,即i=5 - 模式串指针
j回退到next[j] = next[5] = 2
- 主串指针
答案:C

步骤 1:计算模式串 S 的 next 数组
模式串 S = "abaabc",索引从 0 开始:
| 索引 j | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 字符 S j | a | b | a | a | b | c |
next[j] 定义为子串 S[0..j-1] 的最长公共前后缀长度,约定 next[0] = -1:
next[0] = -1next[1] = 0(子串"a"无前后缀)next[2] = 0(子串"ab")next[3] = 1(子串"aba",最长公共前后缀为"a")next[4] = 2(子串"abaa",最长公共前后缀为"ab")next[5] = 2(子串"abaab",最长公共前后缀为"ab")
最终 next 数组:[-1, 0, 0, 1, 2, 2]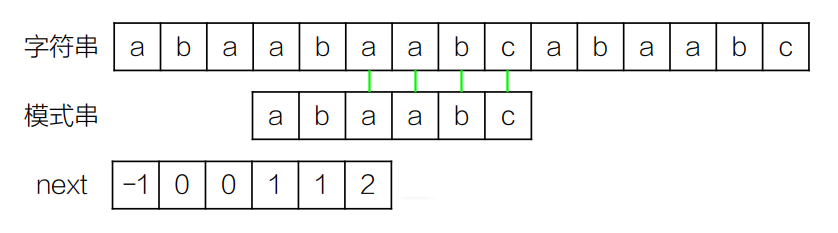
步骤 2:逐次模拟 KMP 匹配过程
主串 T = "abaabaab cababaabc",模式串 S = "abaabc",初始化 i=0(主串指针)、j=0(模式串指针),比较次数 count=0。
-
第 1~6 次比较:
T[0]=avsS[0]=a→ 匹配,i=1,j=1,count=1T[1]=bvsS[1]=b→ 匹配,i=2,j=2,count=2T[2]=avsS[2]=a→ 匹配,i=3,j=3,count=3T[3]=avsS[3]=a→ 匹配,i=4,j=4,count=4T[4]=bvsS[4]=b→ 匹配,i=5,j=5,count=5T[5]=avsS[5]=c→ 失配,count=6- 失配处理:
j = next[5] = 2,i保持5
-
第 7 次比较:
T[5]=avsS[2]=a→ 匹配,i=6,j=3,count=7
-
第 8~11 次比较:
T[6]=avsS[3]=a→ 匹配,i=7,j=4,count=8T[7]=bvsS[4]=b→ 匹配,i=8,j=5,count=9T[8]=cvsS[5]=c→ 匹配,i=9,j=6,count=10- 此时
j=6等于模式串长度6,匹配成功 ✅
答案:B
五、总结
字符串模式匹配中,暴力算法是最基础的实现方式,凭借逻辑简单的优势,在短字符串匹配中仍有一定应用;而 KMP 算法通过预处理生成 next 数组的巧妙设计,用少量的空间开销换来了时间效率的大幅提升,解决了暴力算法的无效回溯问题,成为长字符串模式匹配的经典算法。
理解 KMP 算法的关键在于掌握next 数组的生成原理------ 本质是模式串的自匹配,记录每个位置的最长相等前后缀长度,这也是 KMP 算法的核心精髓。掌握这两种算法,能为后续学习更高效的字符串匹配算法(如 BM 算法、Sunday 算法)打下坚实的基础。