服务器挂了你不知道、接口慢了没人发现、Redis 被打爆了才后知后觉......
这些问题的根源只有一个:没有监控。
本文基于 Docker,手把手搭建一套完整的监控告警体系:Prometheus(指标采集 + 存储)+ AlertManager(告警路由)+ PrometheusAlert(飞书/钉钉通知)+ Grafana(看板),所有命令可直接复制执行。
一、架构总览
各类 Exporter Prometheus AlertManager
(node/redis/mysql/...) ──▶ (采集 + 存储 + 规则评估) ──▶ (告警路由 + 分组)
│ │
│ ▼
│ PrometheusAlert
│ (飞书/钉钉/企微通知)
▼
Grafana
(看板 + 可视化)| 组件 | 作用 | 端口 |
|---|---|---|
| Prometheus | 指标采集、存储、告警规则评估 | 9090 |
| AlertManager | 告警路由、分组、抑制、静默 | 9093 |
| PrometheusAlert | 将告警转发到飞书/钉钉/企微 | 8087 |
| Grafana | 数据可视化看板 | 3000 |
二、部署 Prometheus
1. 创建目录
bash
mkdir -p /data/prometheus/{config,data,rules}
# Prometheus 容器内以 nobody(65534) 运行
chown -R 65534:65534 /data/prometheus/data2. 配置文件
创建 /data/prometheus/config/prometheus.yml:
yaml
global:
scrape_interval: 15s
# 告警配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.0.1.1:9093
# 告警规则文件
rule_files:
- "/prometheus/rules/*.yml"
# 采集配置
scrape_configs:
# ---- Prometheus 自身 ----
- job_name: 'prometheus'
static_configs:
- targets: ['10.0.1.1:9090']
# ---- 应用监控(Spring Boot Actuator) ----
- job_name: 'app'
scrape_interval: 1m
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['10.0.1.2:7000', '10.0.1.2:8000']
# ---- 主机监控(Node Exporter) ----
- job_name: 'node-exporter'
static_configs:
- targets: ['10.0.1.1:9100']
labels:
instance: 'mw-server'
nodename: 'mw-server'
- targets: ['10.0.1.2:9100']
labels:
instance: 'api-server'
nodename: 'api-server'
- targets: ['10.0.1.3:9100']
labels:
instance: 'bd-server'
nodename: 'bd-server'
# ---- Redis Cluster(每个节点一个 Exporter) ----
- job_name: 'redis-cluster-1'
static_configs:
- targets: ['10.0.1.1:9121']
labels: { instance: 'redis1:6379' }
- job_name: 'redis-cluster-2'
static_configs:
- targets: ['10.0.1.1:9122']
labels: { instance: 'redis2:6380' }
- job_name: 'redis-cluster-3'
static_configs:
- targets: ['10.0.1.1:9123']
labels: { instance: 'redis3:6381' }
# ... 根据实际节点数继续添加
# ---- MySQL ----
- job_name: 'mysql'
static_configs:
- targets: ['10.0.1.1:9104']
labels: { instance: 'master' }
# ---- MongoDB ----
- job_name: 'mongodb'
static_configs:
- targets: ['10.0.1.1:9220']
labels: { instance: 'mongo-primary' }
# ---- Elasticsearch ----
- job_name: 'elasticsearch'
scrape_interval: 60s
scrape_timeout: 30s
static_configs:
- targets: ['10.0.1.1:9114']
# ---- ClickHouse ----
- job_name: 'clickhouse'
static_configs:
- targets: ['10.0.1.3:9363']
# ---- RocketMQ ----
- job_name: 'rocketmq'
static_configs:
- targets: ['10.0.1.1:5557']
# ---- Kafka ----
- job_name: 'kafka-exporter'
static_configs:
- targets: ['10.0.1.3:9308']
# ---- ZooKeeper ----
- job_name: 'zookeeper'
static_configs:
- targets: ['10.0.1.1:9141']
metric_relabel_configs:
- source_labels: [zk_host]
target_label: instance
# ---- Flink ----
- job_name: 'flink-jm'
static_configs:
- targets: ['10.0.1.3:9020']
labels: { group: jm }
- job_name: 'flink-tm'
static_configs:
- targets: ['10.0.1.3:9021']
labels: { group: tm }
# ---- DolphinScheduler ----
- job_name: 'dolphinscheduler'
metrics_path: '/dolphinscheduler/actuator/prometheus'
static_configs:
- targets: ['10.0.1.3:12345']
labels: { service: dolphinscheduler }
metric_relabel_configs:
- source_labels: [application]
target_label: app
- regex: 'application'
action: labeldrop
# ---- Jenkins ----
- job_name: 'jenkins'
metrics_path: '/prometheus/'
static_configs:
- targets: ['10.0.1.4:12123']
# ---- AlertManager 自身 ----
- job_name: 'alertmanager'
static_configs:
- targets: ['10.0.1.1:9093']
# ---- PrometheusAlert 自身 ----
- job_name: 'prometheusalert'
static_configs:
- targets: ['10.0.1.1:8087']这份配置覆盖了 15 种组件的监控,按需保留或删除即可。
各 Exporter 的部署方式不在本文展开(每个都是一条
docker run),可参考文末系列文章中各中间件的专项搭建指南。
3. 告警规则示例
创建 /data/prometheus/rules/basic-rules.yml:
yaml
groups:
- name: 基础告警
rules:
- alert: CPU 使用率过高
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 90
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU 使用率 {{ printf \"%.1f\" $value }}%"
description: "CPU 使用率超过 90%,持续 1 分钟"更多告警规则可参考系列文章中 Redis、ZooKeeper、RocketMQ 的专项告警配置。
4. 启动 Prometheus
bash
docker run -d \
--name=prometheus \
-p 9090:9090 \
--restart=always \
-v /data/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/prometheus/data:/prometheus/data \
-v /data/prometheus/rules:/prometheus/rules \
prom/prometheus:v3.5.0 \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus/data \
--web.enable-lifecycle验证:
bash
# 访问 Web UI
curl http://localhost:9090/-/healthy
# 输出 Prometheus Server is Healthy
# 查看已注册的 targets
curl -s http://localhost:9090/api/v1/targets | python3 -m json.tool | head -20
--web.enable-lifecycle开启后可以通过curl -X POST http://localhost:9090/-/reload热加载配置,不用重启容器。
三、部署 AlertManager
AlertManager 负责将 Prometheus 触发的告警进行分组、路由、抑制,然后转发给通知渠道。
1. 配置文件
创建 /data/prometheus/config/alertmanager.yml:
yaml
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_by: ['alertname', 'job', 'severity']
group_wait: 30s # 新分组首次发送前等待
group_interval: 5m # 同一分组内告警发送间隔
repeat_interval: 3h # 重复告警最小间隔(防刷屏)
routes:
# critical 级别单独处理,缩短重复间隔
- match:
severity: critical
receiver: 'notify-critical'
repeat_interval: 1h
receivers:
# 默认接收器:通过 PrometheusAlert 转发到飞书
- name: 'default-receiver'
webhook_configs:
- url: 'http://10.0.1.1:8087/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_TOKEN&at=all'
send_resolved: true
# Critical 告警:同样走 PrometheusAlert,缩短重复间隔
- name: 'notify-critical'
webhook_configs:
- url: 'http://10.0.1.1:8087/prometheusalert?type=fs&tpl=prometheus-fs&fsurl=https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_TOKEN&at=all'
send_resolved: true
# 抑制规则:同一 instance 出现 critical 时,抑制 warning
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['instance']2. 启动
bash
docker run -d \
--name alertmanager \
-p 9093:9093 \
--restart=always \
-v /data/prometheus/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
prom/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yml \
--web.external-url=http://10.0.1.1:9093验证:
bash
curl http://localhost:9093/-/healthy四、部署 PrometheusAlert(飞书/钉钉通知)
AlertManager 原生只支持邮件和 Webhook,要发飞书/钉钉/企微,需要一个消息转发中间件。PrometheusAlert 就是干这个的。
1. 启动
bash
# 先启动一次,拷贝 db 文件(模板数据)
docker run -d \
--name prometheusalert-init \
-p 8087:8080 \
-e PA_LOGIN_USER=admin \
-e PA_LOGIN_PASSWORD=YourPassword \
-e PA_TITLE=Prometheus告警 \
-e PA_OPEN_FEISHU=1 \
-e PA_FSURL="https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_TOKEN" \
--restart=always \
feiyu563/prometheus-alert:latest
# 拷贝 db 数据到宿主机,实现持久化
mkdir -p /data/PrometheusAlert
docker cp prometheusalert-init:/app/db /data/PrometheusAlert/db
docker rm -f prometheusalert-init
# 正式启动(挂载 db 目录)
docker run -d \
--name prometheusalert \
-p 8087:8080 \
-e PA_LOGIN_USER=admin \
-e PA_LOGIN_PASSWORD=YourPassword \
-e PA_TITLE=Prometheus告警 \
-e PA_OPEN_FEISHU=1 \
-e PA_FSURL="https://open.feishu.cn/open-apis/bot/v2/hook/YOUR_WEBHOOK_TOKEN" \
-v /data/PrometheusAlert/db:/app/db \
--restart=always \
feiyu563/prometheus-alert:latest2. 验证
访问 http://10.0.1.1:8087,用 admin / YourPassword 登录,可以管理告警模板。
告警实例:

五、部署 Grafana
1. 创建目录
bash
mkdir -p /data/grafana/data
# Grafana 容器内以 uid 472 运行
chown -R 472:472 /data/grafana/data2. 启动
bash
docker run -d \
--name grafana \
-p 3000:3000 \
--restart=always \
-e TZ=Asia/Shanghai \
-e GF_SECURITY_ADMIN_PASSWORD=YourPassword \
-v /data/grafana/data:/var/lib/grafana \
grafana/grafana:latest3. 配置数据源
- 访问
http://10.0.1.1:3000,用admin/YourPassword登录 - 左侧菜单 → Connections → Data sources → Add data source
- 选择 Prometheus
- URL 填
http://10.0.1.1:9090 - 点击 Save & Test
4. 导入看板
推荐的 Dashboard ID:
| 监控目标 | Dashboard ID | 说明 |
|---|---|---|
| 主机(Node Exporter) | 1860 | 最经典的主机监控看板 |
| Redis | 11835 | Redis 集群看板 |
| MySQL | 14057 | MySQL 看板 |
| MongoDB | 12079 | MongoDB 看板 |
| Elasticsearch | 2322 | ES 集群看板 |
| RocketMQ | 14612 | RocketMQ 看板 |
| ClickHouse | 13606 | ClickHouse 看板 |
| Spring Boot | 4701 | 应用 JVM + HTTP 看板 |
| Kafka | 21078 | Kafka 看板 |
| Flink | 14911 | Flink 看板 |
| DolphinScheduler | 24841 | 调度器看板 |
导入方式:仪表板 → 新建 → 导入 → 输入 Dashboard ID → 加载 → 选择 Prometheus 数据源 → Import。
实例:
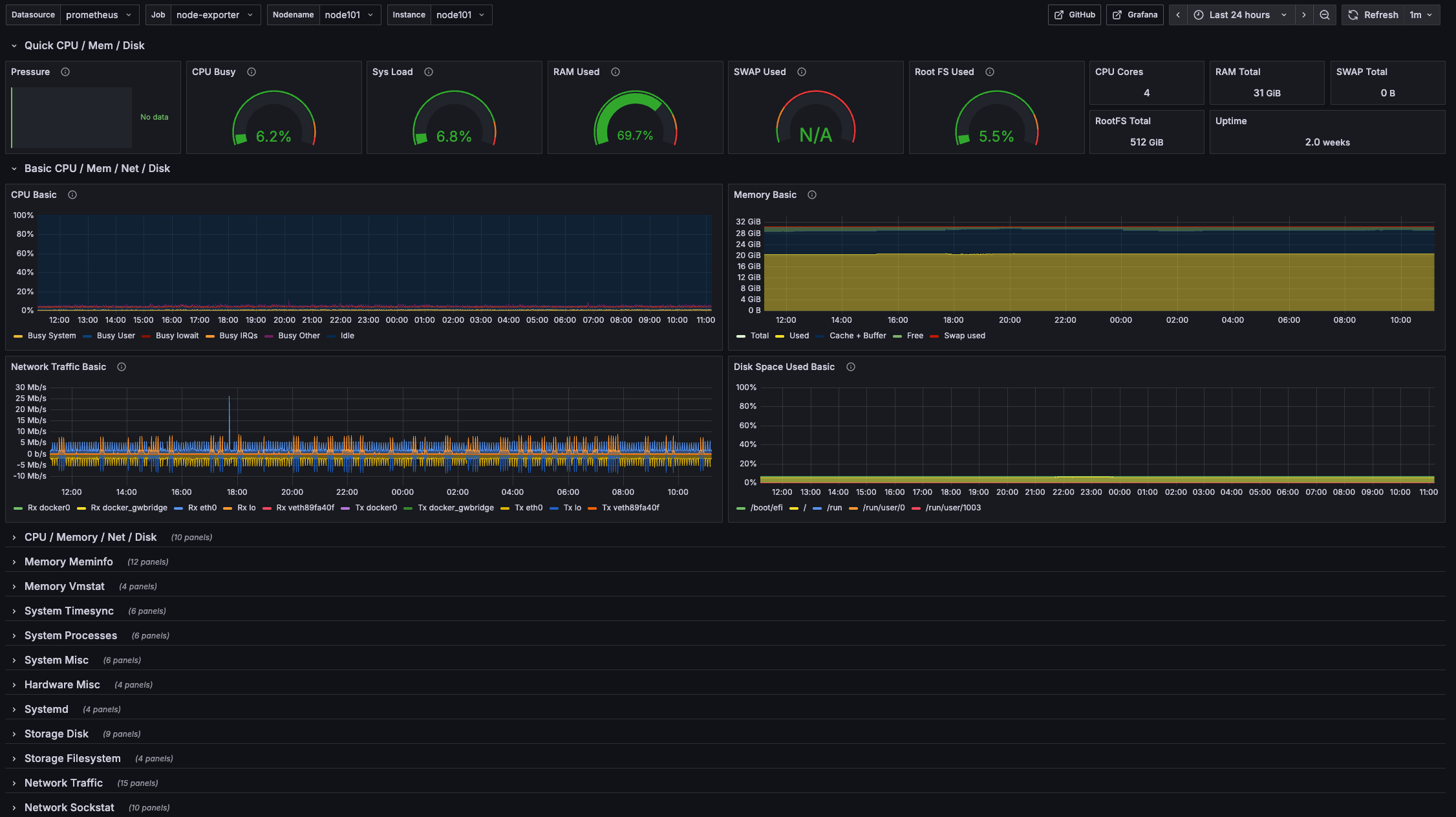
六、完整部署清单
| 步骤 | 组件 | 命令 | 验证 |
|---|---|---|---|
| 1 | Prometheus | docker run ... prom/prometheus:v3.5.0 |
curl localhost:9090/-/healthy |
| 2 | AlertManager | docker run ... prom/alertmanager |
curl localhost:9093/-/healthy |
| 3 | PrometheusAlert | docker run ... feiyu563/prometheus-alert |
访问 localhost:8087 |
| 4 | Grafana | docker run ... grafana/grafana |
访问 localhost:3000 |
四个容器,四条命令,半小时搞定一套完整的监控告警体系。
部署完只是起点,真正有用的是告警规则。各中间件的专项告警规则可参考: