作者 :Jack D. Saunders, Alex A. Freitas
发表于 :Applied Intelligence (2025) 55:875
接收日期 :2025年6月8日 / 在线发表 :2025年7月16日
代码开源 :https://github.com/jds39/GA-Auto-PU
数据集 :https://github.com/jds39/Unlabelled-Datasets

摘要
正例-无标签学习(Positive-Unlabelled Learning, PU Learning)是机器学习的一个重要分支,旨在从仅包含标记正例和未标记样本(其中可能混杂正例或负例)的数据中学习分类器。过去二十年间,研究者们提出了大量PU学习方法,但如何为特定任务选择最优方法仍是一个巨大挑战。
本文在前期工作(GA-Auto-PU)的基础上,提出了两种全新的Auto-ML系统:BO-Auto-PU (基于贝叶斯优化)和EBO-Auto-PU(基于混合进化/贝叶斯优化)。通过在60个数据集(20个真实数据集,每个设置3种不同隐藏比例δ=20%,40%,60%)上的大规模实验评估,新提出的系统在保持与基线方法相比具有统计显著性预测精度优势的同时,大幅降低了计算开销(相比初代GA-Auto-PU分别提升27倍和10倍速度)。
关键词:正例-无标签学习 · 自动机器学习 · 贝叶斯优化 · 遗传算法 · 分类
1 引言
在现实世界的机器学习应用中,获取完全标注的数据集往往成本高昂或根本不切实际。正例-无标签学习(PU Learning)应运而生,它处理的数据集仅包含两类样本:
- 标记正例(P):已通过实验或人工确认属于目标类别的样本
- 未标记样本(U):尚未进行标注的混合样本,其中既包含隐藏的正例,也包含真正的负例
1.1 PU Learning的现实动机
PU Learning的应用场景十分广泛:
生物信息学:疾病相关基因已被实验证实(正例),但大量未标注基因中既有潜在的疾病基因也有正常基因。生物医学实验成本极高,无法对所有基因进行功能验证。
网络安全:已知的恶意URL是正例,而海量未标注URL中既有新的威胁也有正常链接。网络爬虫可快速收集海量数据,但人工标注成本极高。
文本挖掘:人工标注网页成本极高,导致未标注数据中混杂着相关与不相关的文档。Scraping网页简单快速,但手动标注昂贵。
1.2 两步法框架
目前最主流的PU Learning方法是两步法(Two-step Approach):
第一步(Step 1):从未标记样本中识别出"可靠负例"(Reliable Negatives, RN)------即那些与正例差异显著、几乎不可能是隐藏正例的样本。通常通过迭代方式处理类别不平衡问题,将未标记集划分为多个子集。
第二步(Step 2):基于标记正例和可靠负例训练标准二分类器,使其能够预测未见实例属于正例的概率。
1.3 Auto-ML的必要性
然而,PU Learning领域已涌现出数十种算法,每种算法都包含大量超参数(如迭代次数、概率阈值、基分类器选择等)。对于非专家用户而言,手动选择最优算法组合几乎是不可能的任务。
为此,作者团队此前提出了GA-Auto-PU------首个面向PU Learning的自动机器学习(Auto-ML)系统,利用遗传算法自动搜索最优算法配置。
尽管GA-Auto-PU在预测性能上显著优于传统方法,但其计算开销极高(单数据集平均耗时225分钟),限制了实际应用。
1.4 本文贡献
本文的核心贡献在于提出了两种更高效的Auto-PU系统:
| 系统名称 | 优化方法 | 核心优势 | 相对GA的速度提升 |
|---|---|---|---|
| BO-Auto-PU | 贝叶斯优化(Bayesian Optimization) | 利用代理模型(Surrogate Model)快速评估配置,每轮仅评估1个候选 | 27倍 |
| EBO-Auto-PU | 进化贝叶斯优化(Evolutionary BO) | 结合遗传算法的探索能力与贝叶斯优化的效率,每轮评估k+1个候选 | 10倍 |
实验结果表明,两种新系统在保持甚至提升预测精度的同时,大幅缩短了搜索时间,其中EBO-Auto-PU在精度与效率之间取得了最佳平衡。
2 相关工作
2.1 PU Learning研究现状
PU Learning是半监督学习的特殊情形,其核心挑战在于完全缺失负例标签。标准机器学习模型会学习区分"已标记"和"未标记",而非区分"正例"和"负例",因此需要特殊处理。
2.1.1 两步法详细流程
两步法是目前最主流的PU Learning范式,包含以下阶段:
Phase 1A:识别初始可靠负例
- 将未标记集划分为多个子集(处理类别不平衡)
- 训练分类器区分标记正例与未标记子集
- 将预测概率低于阈值的样本视为可靠负例
- 关键假设:平滑性(相似样本具有相似标签概率)和可分离性(正负例在特征空间存在自然边界)
Phase 1B(可选):扩展可靠负例集
- 基于Phase 1A得到的可靠负例和标记正例训练初始分类器
- 对剩余未标记样本进行预测,将低置信度样本加入可靠负例集
- 迭代此过程直至收敛
Phase 2:构建最终分类器
- 基于标记正例和Phase 1确定的可靠负例训练最终二分类器
- 输出样本属于正例的概率 P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x),而非仅仅是标记概率 P ( s = 1 ∣ x ) P(s=1|x) P(s=1∣x)
2.1.2 间谍技术(Spy Technique)
间谍技术是识别可靠负例的经典启发式方法,由Liu等人于2002年提出:
- 从标记正例中随机抽取一定比例(Spy Rate,如10%)作为"间谍"混入未标记集
- 使用剩余正例和含间谍的未标记集训练分类器
- 观察间谍样本的预测概率分布,确定阈值使得一定比例(Spy Tolerance)的间谍被误分为负例
- 该阈值用于从纯未标记样本中筛选可靠负例
2.1.3 基线方法
本文选取两个代表性基线:
- S-EM:结合间谍技术与期望最大化(EM)的经典方法,至今仍被广泛用作基准
- DF-PU:将深度森林(Deep Forest)应用于两步法的近期SOTA方法,使用深度森林这一强大的集成学习器
2.2 自动机器学习(Auto-ML)
Auto-ML旨在通过优化方法自动构建面向特定数据集的ML流程,降低人工参与度。主要技术包括:
遗传算法(GA):模拟自然选择过程,通过选择、交叉、变异操作进化候选解决方案(ML流程),以验证集性能作为适应度函数。
贝叶斯优化(BO):迭代式基于模型的优化方法,通过代理模型(如随机森林)估计配置性能,利用采集函数(Acquisition Function)平衡探索与利用,每轮仅需评估极少量的候选配置。
混合方法:结合GA的全局探索能力与BO的效率,使用代理模型指导遗传算法的进化方向,称为代理辅助进化算法(Surrogate-Assisted Evolutionary Algorithm)。
3 基础知识
在详细介绍本文提出的Auto-PU框架之前,本章系统梳理PU Learning与Auto-ML的基础概念,为后续方法理解奠定理论基础。
3.1 PU Learning核心原理
3.1.1 问题形式化定义
PU Learning处理的数据集 D = ( P , U ) \mathcal{D} = (\mathcal{P}, \mathcal{U}) D=(P,U) 包含:
- P = { x i } i = 1 n p \mathcal{P} = \{x_i\}_{i=1}^{n_p} P={xi}i=1np:标记正例样本集,标签 y = 1 y=1 y=1
- U = { x j } j = 1 n u \mathcal{U} = \{x_j\}_{j=1}^{n_u} U={xj}j=1nu:未标记样本集,其中既包含隐藏正例( y = 1 y=1 y=1)也包含负例( y = 0 y=0 y=0)
设 s ∈ { 0 , 1 } s \in \{0,1\} s∈{0,1} 表示样本是否被标记,则 s = 1 ⇒ y = 1 s=1 \Rightarrow y=1 s=1⇒y=1(标记样本必是正例),但 s = 0 ⇏ y = 0 s=0 \nRightarrow y=0 s=0⇏y=0(未标记不代表负例)。
核心目标 :学习分类器 f : X → 0 , 1 f: \mathcal{X} \to 0,1 f:X→0,1 估计真实类别概率 P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x),而非仅仅预测标记概率 P ( s = 1 ∣ x ) P(s=1|x) P(s=1∣x)。
3.1.2 SCAR假设
Selected Completely At Random(SCAR)假设是PU Learning的重要理论基石:
P ( s = 1 ∣ x , y = 1 ) = P ( s = 1 ∣ y = 1 ) = c P(s=1|x, y=1) = P(s=1|y=1) = c P(s=1∣x,y=1)=P(s=1∣y=1)=c
即:正例被标记的概率与其特征无关,标记样本是全体正例的随机无偏采样。在此假设下,可通过标记正例推断未标记集中的正例分布。
评估意义:在SCAR假设下,可以在真实PU数据上估计模型性能,因为标记正例代表了所有正例(包括未标记集中的隐藏正例)。然而更严谨的评估方式是使用人工构造的PU数据集(从标准PN数据集隐藏部分正例标签),这样可以在测试集上计算标准指标。
3.1.3 方法分类体系
根据Bekker和Davis的综述,PU Learning方法可分为三大类:
| 方法类别 | 核心思想 | 代表算法 | 优缺点 |
|---|---|---|---|
| 两步法 | 先识别可靠负例,再训练分类器 | S-EM, DF-PU, PU-bagging | 直观易实现,但依赖负例识别质量 |
| 有偏学习 | 将未标记样本视为带噪声的负例 | Biased SVM, nnPU | 无需显式识别负例,但对类别不平衡敏感 |
| 类别先验法 | 利用正例先验概率修正损失函数 | uPU, Non-negative Risk | 理论优雅,但需要准确估计类别先验 |
本文聚焦于两步法,因其在工业界应用最广泛且与Auto-ML框架天然契合(涉及离散算法选择和连续超参数优化)。
3.2 Auto-ML技术体系
3.2.1 超参数优化(HPO)
Auto-ML的核心是超参数优化问题:
λ ∗ = arg min λ ∈ Λ L ( A λ , D v a l ) \lambda^* = \arg\min_{\lambda \in \Lambda} \mathcal{L}(\mathcal{A}\lambda, \mathcal{D}{val}) λ∗=argλ∈ΛminL(Aλ,Dval)
其中 A \mathcal{A} A 是算法, λ \lambda λ 是超参数配置, L \mathcal{L} L 是验证集损失。根据超参数类型可分为:
- 连续型:学习率、正则化系数、概率阈值
- 离散型:迭代次数、树的数量
- 分类型:算法选择(如SVM/RF/NN)、是否启用某组件(布尔值)
- 条件型:某些超参数仅在特定条件下激活(如使用间谍技术时才需设置Spy Rate)
3.2.2 优化策略对比
| 策略 | 搜索机制 | 并行能力 | 样本效率 | 适用场景 |
|---|---|---|---|---|
| 网格搜索 | 穷举所有组合 | 高 | 极低 | 低维离散空间 |
| 随机搜索 | 均匀随机采样 | 高 | 低 | 高维空间基准 |
| 贝叶斯优化 | 代理模型+采集函数 | 中 | 高 | 昂贵黑盒函数 |
| 遗传算法 | 种群进化 | 中 | 中 | 混合类型优化 |
| 混合方法 | 代理模型指导进化 | 中 | 高 | 复杂搜索空间 |
3.2.3 代理模型(Surrogate Model)
贝叶斯优化依赖代理模型 M : Λ → R M: \Lambda \to \mathbb{R} M:Λ→R 近似真实目标函数 f f f。常用模型包括:
- 高斯过程(GP) :概率化建模,不确定性量化精确,但计算复杂度高 O ( n 3 ) O(n^3) O(n3)
- 随机森林(RF):非参数化,对离散超参数友好,训练快,预测不确定性通过集成方差估计
- Tree-structured Parzen Estimator(TPE) :建模 p ( λ ∣ g o o d ) p(\lambda|good) p(λ∣good) 和 p ( λ ∣ b a d ) p(\lambda|bad) p(λ∣bad),适合条件超参数空间
本文选用随机森林作为代理模型,因其能有效处理Auto-PU中混合类型的超参数(连续阈值+离散分类器选择+布尔标志)。
4 Auto-PU:面向PU学习的自动机器学习框架
本章介绍本文提出的Auto-ML框架,包括搜索空间定义(第4.1节)和评估协议(第4.2节)。该框架适用于三种优化器(GA、BO、EBO),差异仅体现在优化策略,共享相同的搜索空间与目标函数。
4.1 搜索空间定义
Auto-PU的搜索空间基于两步法框架构建,每个候选解决方案是一个完整的PU学习流程配置,包含Phase 1A、1B和2的超参数设置。
4.1.1 基础搜索空间(Base Search Space)
基础搜索空间包含7个超参数,构成相对简单的两步法配置(不使用间谍技术):
| 超参数 | 符号 | 取值范围 | 说明 |
|---|---|---|---|
| Iteration_count_1A | n 1 A n_{1A} n1A | { 1 , 2 , . . . , 10 } \{1,2,...,10\} {1,2,...,10} | Phase 1A迭代次数,将未标记集划分为 n 1 A n_{1A} n1A 个子集处理类别不平衡 |
| Threshold_1A | θ 1 A \theta_{1A} θ1A | { 0.05 , 0.10 , . . . , 0.50 } \{0.05,0.10,...,0.50\} {0.05,0.10,...,0.50} | 可靠负例筛选阈值,低于此概率视为负例 |
| Classifier_1A | C 1 A \mathcal{C}_{1A} C1A | 18种候选分类器 | Phase 1A使用的基分类器 |
| Flag_1B | f 1 B f_{1B} f1B | {True, False} | 是否启用Phase 1B扩展步骤 |
| Threshold_1B | θ 1 B \theta_{1B} θ1B | { 0.05 , 0.10 , . . . , 0.50 } \{0.05,0.10,...,0.50\} {0.05,0.10,...,0.50} | Phase 1B的扩展阈值 |
| Classifier_1B | C 1 B \mathcal{C}_{1B} C1B | 18种候选分类器 | Phase 1B使用的基分类器 |
| Classifier_2 | C 2 \mathcal{C}_{2} C2 | 18种候选分类器 | Phase 2最终分类器 |
候选分类器集合包含:高斯朴素贝叶斯、伯努利朴素贝叶斯、随机森林、决策树、多层感知机、SVM、SGD分类器、逻辑回归、K近邻、深度森林(Deep Forest)、AdaBoost、梯度提升、线性判别分析(LDA)、Extra Tree、Bagging、高斯过程、直方图梯度提升等。
搜索空间规模 :
∣ Λ b a s e ∣ = 10 × 10 × 18 × 2 × 10 × 18 × 18 = 11 , 664 , 000 |\Lambda_{base}| = 10 \times 10 \times 18 \times 2 \times 10 \times 18 \times 18 = 11,664,000 ∣Λbase∣=10×10×18×2×10×18×18=11,664,000

图1:基础搜索空间的候选解决方案结构示意图
说明:展示Phase 1A/1B/2的组件及超参数连接关系。图中应显示Iteration_count_1A、Threshold_1A、Classifier_1A构成Phase 1A;Flag_1B、Threshold_1B、Classifier_1B构成Phase 1B;Classifier_2构成Phase 2。并给出具体示例:如Iteration_count_1A=5表示将未标记集分为5个子集,Classifier_1A=决策树,Threshold_1A=0.25表示预测概率<0.25的样本加入可靠负例集,Flag_1B=True启用Phase 1B使用SVM扩展可靠负例集,最终Phase 2使用深度森林分类器。
配置示例详解:
- n 1 A = 5 n_{1A}=5 n1A=5:将未标记集分为5个子集,每轮用20%未标记数据+全部正例训练,处理类别不平衡
- θ 1 A = 0.25 \theta_{1A}=0.25 θ1A=0.25:预测概率<0.25的样本加入可靠负例集
- C 1 A = \mathcal{C}{1A}= C1A=决策树, C 1 B = \mathcal{C}{1B}= C1B=SVM, C 2 = \mathcal{C}_{2}= C2=深度森林
- f 1 B = f_{1B}= f1B=True:启用Phase 1B扩展可靠负例集,使用SVM分类剩余未标记样本,将预测概率<0.3的加入可靠负例集
4.1.2 扩展搜索空间(Extended Search Space)
扩展搜索空间在基础空间上增加了**间谍技术(Spy Technique)**相关的3个超参数:
| 超参数 | 符号 | 取值范围 | 说明 |
|---|---|---|---|
| Spy_flag | s f l a g s_{flag} sflag | {True, False} | 是否在Phase 1A使用间谍技术 |
| Spy_rate | s r a t e s_{rate} srate | { 0.05 , 0.10 , . . . , 0.35 } \{0.05,0.10,...,0.35\} {0.05,0.10,...,0.35} | 间谍比例,从正例中抽取的比例 |
| Spy_tolerance | s t o l s_{tol} stol | { 0 , 0.01 , . . . , 0.10 } \{0,0.01,...,0.10\} {0,0.01,...,0.10} | 间谍容忍度,允许被误分为负例的间谍比例 |
当 s f l a g = s_{flag}= sflag= True 时,Threshold_1A的值由间谍技术自动确定(而非手动设置):分类器训练后,找到阈值使得恰好 s t o l s_{tol} stol 比例的间谍样本被划分为负例。例如,若 s t o l = 0.05 s_{tol}=0.05 stol=0.05,则5%的间谍实例可以具有小于所确定阈值的预测正类概率。
搜索空间规模 :
∣ Λ e x t ∣ = ∣ Λ b a s e ∣ × 2 × 7 × 11 = 1 , 796 , 256 , 000 |\Lambda_{ext}| = |\Lambda_{base}| \times 2 \times 7 \times 11 = 1,796,256,000 ∣Λext∣=∣Λbase∣×2×7×11=1,796,256,000
值得注意的是,间谍技术仅用于Phase 1A。作者团队初步实验表明,在Phase 1B使用间谍技术无法提升性能但会急剧增加搜索空间(再扩大154倍,达到2766亿候选),因此未予采用。

图2:扩展搜索空间的候选解决方案结构示意图
说明:在图1基础上,突出显示新增的Spy相关超参数(加粗表示)。示例:Spy_flag=True,Spy_rate=0.2(20%正例作为间谍),Spy_tolerance=0.01(1%间谍被允许误分),此时Threshold_1A由算法自动确定而非手动设置。
4.2 候选解决方案评估协议
目标函数用于评估特定PU学习配置在给定数据集上的质量。采用内部5折交叉验证(Internal 5-fold Cross-Validation):
- 将训练集划分为5个子集(分层抽样保持类别分布,确保每折中标记正例比例与整体一致)
- 对每个折 i ∈ { 1 , . . . , 5 } i \in \{1,...,5\} i∈{1,...,5}:
- 使用除第 i i i 折外的数据作为学习集(learning set)
- 基于候选配置在两步框架上训练PU学习器:
- Phase 1A:识别可靠负例
- Phase 1B(若Flag_1B=True):扩展可靠负例集
- Phase 2:训练最终分类器
- 在第 i i i 折(验证集,validation set)上计算F-measure
- 候选配置的适应度(Fitness)= 5折F-measure的均值
评价指标定义:
- Precision = T P T P + F P \frac{TP}{TP+FP} TP+FPTP:预测为正例的样本中真正正例的比例
- Recall = T P T P + F N \frac{TP}{TP+FN} TP+FNTP:真正正例被正确识别的比例
- F-measure = 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l \frac{2 \cdot Precision \cdot Recall}{Precision + Recall} Precision+Recall2⋅Precision⋅Recall:精确率与召回率的调和平均
其中,TP(True Positives)为正确预测为正例的样本数,FP(False Positives)为错误预测为正例的负例数,FN(False Negatives)为错误预测为负例的正例数。
5 三种Auto-PU系统详解
本章详细阐述三种Auto-PU系统的优化机制。所有系统共享第4章定义的搜索空间和目标函数,差异体现在优化策略。
5.1 GA-Auto-PU:遗传算法优化
GA-Auto-PU作为首个Auto-ML for PU Learning系统,采用标准遗传算法流程:
算法1:GA-Auto-PU算法流程
1. 初始化:随机生成 Pop_size 个个体(配置)构成种群 Population
2. 对于 generation = 1 到 #generations 执行:
a. 对于 Population 中的每个 Individual:
i. 若 Individual 的配置未在历史记录中:
- 计算 Fitness = 内部5折CV的F-measure(见4.2节)
- 保存配置与适应度
ii. 否则:从历史记录中读取适应度
b. 保存当前代最适应个体 Fittest_individual(精英保留)
c. 锦标赛选择:基于适应度从 Population 中选择亲代
d. 交叉:对亲代执行均匀交叉(Uniform Crossover),概率 Cross_prob
e. 变异:以概率 Mutation_prob 随机替换某基因值为候选值之一
f. 更新 Population = 新种群 + Fittest_individual
3. 返回历史中最优配置关键参数 :种群大小 P o p s i z e = 101 Pop_{size}=101 Popsize=101,迭代次数50代,交叉概率0.9,变异概率0.1,锦标赛规模2。
计算瓶颈 :每代需评估101个配置,每个配置需训练多个PU模型(Phase 1A迭代+Phase 1B+Phase 2),导致单数据集平均耗时225分钟。
5.2 BO-Auto-PU:贝叶斯优化
针对GA-Auto-PU计算开销过高的问题,提出基于贝叶斯优化的BO-Auto-PU,通过代理模型大幅减少昂贵评估次数。
算法2:BO-Auto-PU算法流程
1. 初始化:随机生成 #Configs 个PU学习配置 Configs
2. 评估:对所有配置运行目标函数(5折CV F-measure),保存为 Scores
3. 建模:训练随机森林回归器 Surr_model,以 Configs 为特征、Scores 为目标
4. 对于 iteration = 1 到 It_count(50次)执行:
a. 生成:随机生成 #Configs 个新配置 New_configs
b. 预测:使用 Surr_model 计算每个新配置的代理得分 Ŷ
c. 选择:Best_config = 根据 Ŷ 得分最高的配置
d. 评估:Score = 对 Best_config 运行目标函数(昂贵操作)
e. 更新:将 Best_config 加入 Configs,Score 加入 Scores
f. 重训练:在更新后的 Configs 和 Scores 上重训练 Surr_model
5. 返回:根据客观得分(真实F-measure)最优的配置特征编码方案:
- 数值超参数(Threshold_1A, Iteration_Count_1A, Threshold_1B):直接作为数值特征
- 布尔超参数(Flag_1B):二元特征(0/1)
- 分类超参数(Classifier_1A, Classifier_1B, Classifier_2):One-Hot编码,每个可能取值对应一个二进制维度,指示是否使用该值
- 基础空间维度:58维特征向量(3数值+1布尔+3×18分类器One-Hot)
- 扩展空间维度:61维(增加Spy_flag布尔+Spy_rate数值+Spy_tolerance数值)
超参数设置(表1):
| 超参数 | 设置值 | 说明 |
|---|---|---|
| It_count | 50 | 优化迭代轮数,与GA的代数一致 |
| #Configs | 101 | 每轮生成的候选配置数,与GA种群大小一致 |
| 代理模型 | 随机森林回归器 | 处理混合类型特征 |
| 采集函数 | 代理模型预测值 | 直接选择预测得分最高者,平衡探索与利用 |
效率提升 :初始评估10个配置,之后每轮仅评估1个 配置,共60次昂贵评估(vs GA的5050次),平均耗时降至8.4分钟(27倍加速)。
5.3 EBO-Auto-PU:进化贝叶斯混合优化
BO-Auto-PU虽快,但存在探索不足问题:每轮仅评估单个基于代理模型选择的配置,缺乏GA的种群多样性,可能陷入局部最优。EBO-Auto-PU结合两者优势,在保持代理模型效率的同时引入遗传算法的进化机制。
核心思想 :在每轮迭代中,除评估代理模型推荐的最优配置(Best_config)外,还通过遗传算子(锦标赛选择、交叉、变异)从当前种群中生成 k k k 个多样性的候选配置进行评估。
算法3:EBO-Auto-PU算法流程
1. 初始化:随机生成 #Configs 个配置 Configs,评估得 Scores,训练 Surr_model
2. 对于 iteration = 1 到 It_count(50次)执行:
a. 复制:将 Configs 复制到临时存储 Temp_Configs
b. 进化:对 Temp_Configs 执行交叉和变异,生成进化后的配置
c. 预测:使用 Surr_model 计算所有配置的代理得分 Ŷ
d. 选择最佳:Best_config = 代理得分最高的配置
e. 锦标赛选择:基于真实得分(Scores)选择 k 个亲代配置加入 k_pop
f. 遗传操作:对 k_pop 执行交叉和变异,生成 k 个新配置
g. 评估:对 Best_config 和 k_pop 中的 k 个配置运行目标函数(共k+1个)
h. 更新:将新评估的 k+1 个配置加入 Configs,得分加入 Scores
i. 重训练:更新 Surr_model
3. 返回:根据客观得分最优的配置关键超参数(表2):
| 超参数 | 设置值 | 来源/说明 |
|---|---|---|
| #Configs | 101 | 与BO/GA保持一致 |
| It_count | 50 | 与BO/GA保持一致 |
| 代理模型 | 随机森林回归器 | 与BO保持一致 |
| k | 10 | EBO特有,每轮额外通过进化评估的配置数 |
| 交叉概率 | 0.9 | 继承GA-Auto-PU |
| 变异概率 | 0.1 | 继承GA-Auto-PU |
| 锦标赛规模 | 2 | 继承GA-Auto-PU |
复杂度分析:
- GA-Auto-PU:每代评估101个配置,50代共 5,050次 昂贵评估
- BO-Auto-PU:初始10次 + 每轮1次×50轮 = 60次 昂贵评估
- EBO-Auto-PU:初始101次 + 每轮11次×50轮 = 651次 昂贵评估
性能定位 :EBO-Auto-PU位于GA与BO之间,平均耗时24.2分钟(约10倍于GA,3倍于BO),但由于引入了遗传多样性,在预测精度上往往优于纯BO方法,特别是在处理复杂搜索空间时。
5.4 计算效率对比
三种系统的计算时间对比(表3):
| 方法 | 每轮/每代评估数 | 总昂贵评估数 | 平均耗时(分钟) | 相对GA速度 |
|---|---|---|---|---|
| GA-1 (基础空间) | 101 | ~5,050 | 226.3 | 1× |
| EBO-1 (基础空间) | 11 | ~651 | 24.2 | 9.4× |
| BO-1 (基础空间) | 1 | ~60 | 8.4 | 26.9× |
| DF-PU (基线) | - | - | 4.9 | - |
| S-EM (基线) | - | - | 1.5 | - |
注:测试环境为48核GPU系统,基于20个数据集的5折外部交叉验证平均
6 实验设计与数据集
6.1 数据集特征
实验在20个公开生物医学数据集上进行,涵盖疾病预测与健康风险评估场景。数据集特征如下(表4):
| 数据集 | 实例数 | 特征数 | 正例比例 | 来源 |
|---|---|---|---|---|
| Alzheimer's | 354 | 9 | 10.73% | 36 |
| Autism | 288 | 15 | 48.26% | UCI 35 |
| Breast cancer Coimbra | 116 | 9 | 55.17% | UCI 35 |
| Breast cancer Wisconsin | 569 | 30 | 37.26% | UCI 35 |
| Breast cancer mutations | 1416 | 53 | 32.42% | 37 |
| Cervical cancer | 668 | 30 | 2.54% | UCI 35 |
| Cirrhosis | 277 | 17 | 25.72% | 38 |
| Dermatology | 359 | 34 | 13.41% | UCI 35 |
| Pima Indians Diabetes | 769 | 8 | 34.90% | UCI 35 |
| Early Stage Diabetes | 521 | 17 | 61.54% | 39 |
| Heart Disease | 304 | 13 | 54.46% | UCI 35 |
| Heart Failure | 300 | 12 | 32.11% | 40 |
| Hepatitis C | 590 | 13 | 9.51% | UCI 35 |
| Kidney Disease | 159 | 24 | 27.22% | UCI 35 |
| Liver Disease | 580 | 11 | 71.50% | UCI 35 |
| Maternal Risk | 1014 | 6 | 26.82% | UCI 35 |
| Parkinsons | 196 | 22 | 75.38% | UCI 35 |
| Parkinsons Biomarkers | 131 | 29 | 23.08% | 41 |
| Spine | 311 | 6 | 48.39% | UCI 35 |
| Stroke | 3427 | 15 | 5.25% | 42 |
数据集来源:13个来自UCI机器学习仓库经典基准集,7个来自近期生物医学研究文献。
PU数据集构造:为模拟真实PU场景,将每个数据集改造为PU版本:
- 在训练集中隐藏 δ % \delta\% δ% 的正例到未标记集(与真实负例混合)
- 测试集保持原始的PN标签,用于准确评估
- δ ∈ { 20 % , 40 % , 60 % } \delta \in \{20\%, 40\%, 60\%\} δ∈{20%,40%,60%},每个数据集生成3个版本,共60个实验数据集
生物医学适用性:这些数据集天然适合PU Learning,因为"未诊断"不等于"无病"------可能未经检测或检测未达阈值,符合PU问题设定。
6.2 嵌套交叉验证协议
采用嵌套交叉验证(Nested Cross-Validation)确保无信息泄露:
外部交叉验证(External CV):
- 分层5折交叉验证(Stratified 5-fold CV)
- 每折保持与全集相同的类别分布
- 轮流使用1折为测试集,其余4折为训练集
- 为什么选5折而非10折?部分数据集正例数极少,10折会导致某些折中正例过少(甚至为0)
内部交叉验证(Internal CV):
- 对每个外部训练集,再次进行分层5折CV
- 用于Auto-PU系统内部的超参数调优(评估候选解决方案)
- 5轮运行后,选择平均F-measure最高的配置作为该训练集的最优配置
- 使用该配置在整个训练集上训练最终模型,评估测试集
基线方法调优:为确保公平,S-EM和DF-PU也使用网格搜索+内部CV进行超参数优化:
- DF-PU优化:可靠负例率(0.01-0.20,步长0.02)、迭代次数(1-10)
- S-EM优化:间谍率(0.05-0.35)、间谍容忍度(0-0.10)
关键约束 :在整个内部CV调优过程中,严禁访问测试集或任何负例标签,仅使用正例和未标记数据进行配置选择,严格保持PU Learning的设定。
6.3 统计显著性检验
采用多层级统计检验:
第一层(两两比较):Wilcoxon符号秩检验(Wilcoxon Signed-Rank Test),非参数检验,适用于比较两个方法在多个数据集上的性能差异。
多重检验校正:Holm校正(Holm Correction),控制族错误率(Family-Wise Error Rate)。步骤如下:
- 对 n n n 个假设按p值从小到大排序: p 1 ≤ p 2 ≤ . . . ≤ p n p_1 \leq p_2 \leq ... \leq p_n p1≤p2≤...≤pn
- 检验 H 1 H_1 H1:若 p 1 < α / n p_1 < \alpha/n p1<α/n,则显著,继续;否则全部不显著
- 检验 H 2 H_2 H2:若 p 2 < α / ( n − 1 ) p_2 < \alpha/(n-1) p2<α/(n−1),则显著,继续
- 依此类推,直到某一步不显著为止
第二层(全局比较) :Friedman检验,先检验所有方法间是否存在显著差异;若显著( p < 0.05 p<0.05 p<0.05),再进行成对Wilcoxon检验。
7 实验结果与分析
7.1 基础搜索空间结果(GA-1, BO-1, EBO-1)
7.1.1 Auto-PU系统间对比
F-measure性能(表5,部分关键数据集):
| 数据集 | δ=20% | δ=40% | δ=60% | 正例比例 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| EBO-1 | GA-1 | BO-1 | EBO-1 | GA-1 | BO-1 | EBO-1 | GA-1 | BO-1 | ||
| Alzheimer's | 0.629 | 0.529 | 0.615 | 0.587 | 0.551 | 0.600 | 0.540 | 0.456 | 0.436 | 10.73% |
| Autism | 0.986 | 0.960 | 0.967 | 0.926 | 0.927 | 0.956 | 0.927 | 0.910 | 0.863 | 48.26% |
| Breast cancer Coi. | 0.966 | 0.705 | 0.694 | 0.952 | 0.687 | 0.701 | 0.615 | 0.510 | 0.586 | 55.17% |
| Breast cancer Wis. | 0.893 | 0.954 | 0.949 | 0.872 | 0.932 | 0.969 | 0.927 | 0.906 | 0.895 | 37.26% |
| Breast cancer mut. | 0.672 | 0.893 | 0.893 | 0.667 | 0.868 | 0.873 | 0.862 | 0.854 | 0.841 | 32.42% |
| Cervical cancer | 0.839 | 0.828 | 0.839 | 0.904 | 0.903 | 0.903 | 0.667 | 0.714 | 0.645 | 2.54% |
| Cirrhosis | 0.532 | 0.573 | 0.545 | 0.453 | 0.464 | 0.529 | 0.507 | 0.443 | 0.489 | 25.72% |
| Dermatology | 0.899 | 0.860 | 0.872 | 0.813 | 0.780 | 0.905 | 0.716 | 0.828 | 0.725 | 13.41% |
| PI Diabetes | 0.654 | 0.677 | 0.647 | 0.661 | 0.649 | 0.645 | 0.634 | 0.606 | 0.594 | 34.90% |
| ES Diabetes | 0.973 | 0.958 | 0.983 | 0.913 | 0.895 | 0.877 | 0.909 | 0.930 | 0.902 | 61.54% |
| Heart Disease | 0.833 | 0.843 | 0.844 | 0.800 | 0.801 | 0.830 | 0.774 | 0.785 | 0.777 | 54.46% |
| Heart Failure | 0.732 | 0.770 | 0.753 | 0.666 | 0.652 | 0.605 | 0.640 | 0.674 | 0.704 | 32.11% |
| Hepatitis C | 0.925 | 0.953 | 0.907 | 0.835 | 0.771 | 0.838 | 0.667 | 0.588 | 0.708 | 9.51% |
| Kidney Disease | 1.000 | 0.976 | 0.988 | 0.938 | 0.988 | 0.964 | 0.646 | 0.754 | 0.806 | 27.22% |
| Liver Disease | 0.827 | 0.834 | 0.820 | 0.819 | 0.803 | 0.817 | 0.717 | 0.804 | 0.795 | 71.50% |
| Maternal Risk | 0.855 | 0.476 | 0.837 | 0.803 | 0.812 | 0.780 | 0.739 | 0.735 | 0.689 | 26.82% |
| Parkinsons | 0.929 | 0.860 | 0.935 | 0.894 | 0.836 | 0.875 | 0.707 | 0.818 | 0.732 | 75.38% |
| Parkinsons Biom. | 0.203 | 0.476 | 0.167 | 0.337 | 0.265 | 0.192 | 0.133 | 0.233 | 0.182 | 23.08% |
| Spine | 0.933 | 0.652 | 0.954 | 0.932 | 0.907 | 0.926 | 0.775 | 0.818 | 0.742 | 48.39% |
| Stroke | 0.239 | 0.474 | 0.244 | 0.225 | 0.255 | 0.153 | 0.229 | 0.255 | 0.208 | 5.25% |
| Average | 0.776 | 0.763 | 0.773 | 0.750 | 0.737 | 0.747 | 0.667 | 0.681 | 0.666 | - |
统计显著性分析(表6):
| δ | 对比系统 | F-measure | Precision | Recall | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 平均秩 | p值 | 调整α | 平均秩 | p值 | 调整α | 平均秩 | p值 | 调整α | ||
| 20% | GA-1 vs BO-1 | 1.52 vs 1.48 | 0.952 | 0.05 | 1.55 vs 1.45 | 0.983 | 0.05 | 1.4 vs 1.6 | 0.114 | 0.017 |
| GA-1 vs EBO-1 | 1.5 vs 1.5 | 0.784 | 0.025 | 1.52 vs 1.48 | 0.446 | 0.017 | 1.38 vs 1.62 | 0.178 | 0.025 | |
| BO-1 vs EBO-1 | 1.52 vs 1.48 | 0.658 | 0.017 | 1.55 vs 1.45 | 0.968 | 0.025 | 1.55 vs 1.45 | 0.983 | 0.05 | |
| 40% | GA-1 vs BO-1 | 1.62 vs 1.38 | 0.334 | 0.025 | 1.55 vs 1.45 | 0.601 | 0.025 | 1.58 vs 1.42 | 0.398 | 0.025 |
| GA-1 vs EBO-1 | 1.6 vs 1.4 | 0.245 | 0.017 | 1.45 vs 1.55 | 0.828 | 0.05 | 1.58 vs 1.42 | 0.381 | 0.017 | |
| BO-1 vs EBO-1 | 1.55 vs 1.45 | 1.000 | 0.05 | 1.45 vs 1.55 | 0.387 | 0.017 | 1.5 vs 1.5 | 0.557 | 0.05 | |
| 60% | GA-1 vs BO-1 | 1.25 vs 1.75 | 0.177 | 0.017 | 1.48 vs 1.52 | 0.513 | 0.025 | 1.25 vs 1.75 | 0.064 | 0.017 |
| GA-1 vs EBO-1 | 1.45 vs 1.55 | 0.312 | 0.025 | 1.5 vs 1.5 | 0.812 | 0.05 | 1.45 vs 1.55 | 0.388 | 0.025 | |
| BO-1 vs EBO-1 | 1.6 vs 1.4 | 0.674 | 0.05 | 1.38 vs 1.62 | 0.184 | 0.017 | 1.62 vs 1.38 | 0.629 | 0.05 |
关键发现:
- δ=20%:三者性能相当,无统计显著差异。EBO-1与GA-1并列,略优于BO-1。
- δ=40%:EBO-1平均秩最优(1.4),但差异未达统计显著。
- δ=60%:GA-1表现最佳(平均秩1.25 vs BO-1的1.75),但同样未达统计显著。
- 总体 :三种Auto-PU系统性能相当,差异不显著,但计算效率差异巨大。
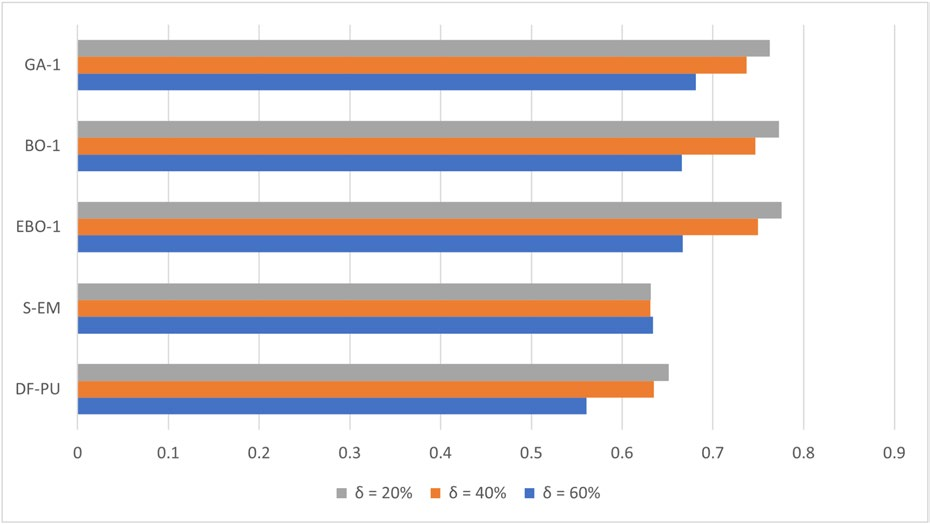
图3:三种Auto-PU系统在不同δ值下的平均F-measure柱状图
说明:x轴为δ值(20%,40%,60%),y轴为F-measure,三种颜色分别代表GA-1、BO-1、EBO-1。显示随δ增加(隐藏正例增多),所有系统性能下降,但下降幅度相似。
7.1.2 与基线方法对比
F-measure对比(表7,基线方法结果):
| 数据集 | δ=20% | δ=40% | δ=60% | 正例比例 | |||
|---|---|---|---|---|---|---|---|
| DF-PU | S-EM | DF-PU | S-EM | DF-PU | S-EM | ||
| Alzheimer's | 0.519 | 0.385 | 0.396 | 0.489 | 0.462 | 0.389 | 10.73% |
| Autism | 0.766 | 0.823 | 0.639 | 0.824 | 0.557 | 0.838 | 48.26% |
| Breast cancer Coi. | 0.680 | 0.896 | 0.894 | 0.903 | 0.618 | 0.903 | 55.17% |
| Breast cancer Wis. | 0.884 | 0.892 | 0.700 | 0.893 | 0.473 | 0.892 | 37.26% |
| Breast cancer mut. | 0.500 | 0.711 | 0.500 | 0.690 | 0.500 | 0.702 | 32.42% |
| Cervical cancer | 0.688 | 0.054 | 0.667 | 0.053 | 0.650 | 0.046 | 2.54% |
| Cirrhosis | 0.458 | 0.438 | 0.389 | 0.442 | 0.364 | 0.465 | 25.72% |
| Dermatology | 0.872 | 0.718 | 0.712 | 0.718 | 0.860 | 0.719 | 13.41% |
| PI Diabetes | 0.566 | 0.536 | 0.582 | 0.535 | 0.584 | 0.575 | 34.90% |
| ES Diabetes | 0.751 | 0.796 | 0.726 | 0.863 | 0.700 | 0.783 | 61.54% |
| Heart Disease | 0.719 | 0.838 | 0.701 | 0.838 | 0.730 | 0.828 | 54.46% |
| Heart Failure | 0.590 | 0.490 | 0.586 | 0.514 | 0.457 | 0.584 | 32.11% |
| Hepatitis C | 0.916 | 0.701 | 0.804 | 0.708 | 0.683 | 0.661 | 9.51% |
| Kidney Disease | 0.874 | 1.000 | 1.000 | 1.000 | 0.607 | 0.951 | 27.22% |
| Liver Disease | 0.806 | 0.834 | 0.829 | 0.726 | 0.753 | 0.798 | 71.50% |
| Maternal Risk | 0.459 | 0.457 | 0.474 | 0.444 | 0.418 | 0.499 | 26.82% |
| Parkinsons | 0.857 | 0.847 | 0.857 | 0.751 | 0.799 | 0.767 | 75.38% |
| Parkinsons Biom. | 0.313 | 0.308 | 0.375 | 0.276 | 0.065 | 0.331 | 23.08% |
| Spine | 0.651 | 0.806 | 0.654 | 0.852 | 0.723 | 0.840 | 48.39% |
| Stroke | 0.155 | 0.102 | 0.214 | 0.102 | 0.207 | 0.103 | 5.25% |
| Average | 0.651 | 0.632 | 0.635 | 0.631 | 0.561 | 0.634 | - |
统计显著性(表8):
| δ | 对比系统 | F-measure | Precision | ||||
|---|---|---|---|---|---|---|---|
| 平均秩 | p值 | 调整α | 平均秩 | p值 | 调整α | ||
| 20% | GA-1 vs DF-PU | 1.05 vs 1.95 | 1E-05 | 0.025 | 1.2 vs 1.8 | 0.001 | 0.025 |
| GA-1 vs S-EM | 1.15 vs 1.85 | 0.006 | 0.05 | 1.18 vs 1.82 | 0.002 | 0.05 | |
| BO-1 vs DF-PU | 1.15 vs 1.85 | 3E-04 | 0.025 | 1.25 vs 1.75 | 0.002 | 0.025 | |
| BO-1 vs S-EM | 1.2 vs 1.8 | 0.003 | 0.05 | 1.22 vs 1.78 | 0.005 | 0.05 | |
| EBO-1 vs DF-PU | 1.05 vs 1.95 | 6E-05 | 0.025 | 1.1 vs 1.9 | 1E-05 | 0.025 | |
| EBO-1 vs S-EM | 1.22 vs 1.78 | 0.002 | 0.05 | 1.08 vs 1.92 | 2E-04 | 0.05 | |
| 40% | GA-1 vs DF-PU | 1.3 vs 1.7 | 0.007 | 0.05 | 1.12 vs 1.88 | 0.001 | 0.05 |
| GA-1 vs S-EM | 1.2 vs 1.8 | 0.002 | 0.025 | 1.12 vs 1.88 | 0.002 | 0.025 | |
| BO-1 vs DF-PU | 1.25 vs 1.75 | 0.008 | 0.05 | 1.12 vs 1.88 | 0.001 | 0.025 | |
| BO-1 vs S-EM | 1.2 vs 1.8 | 0.003 | 0.025 | 1.12 vs 1.88 | 0.002 | 0.05 | |
| EBO-1 vs DF-PU | 1.15 vs 1.85 | 2E-04 | 0.025 | 1.08 vs 1.92 | 2E-04 | 0.025 | |
| EBO-1 vs S-EM | 1.2 vs 1.8 | 4E-04 | 0.05 | 1.08 vs 1.92 | 3E-04 | 0.05 | |
| 60% | GA-1 vs DF-PU | 1.2 vs 1.8 | 0.003 | 0.025 | 1.1 vs 1.9 | 0.001 | 0.05 |
| GA-1 vs S-EM | 1.35 vs 1.65 | 0.216 | 0.05 | 1.22 vs 1.78 | 0.001 | 0.025 | |
| BO-1 vs DF-PU | 1.25 vs 1.75 | 0.011 | 0.025 | 1.1 vs 1.9 | 0.001 | 0.025 | |
| BO-1 vs S-EM | 1.35 vs 1.65 | 0.409 | 0.05 | 1.12 vs 1.88 | 0.001 | 0.05 | |
| EBO-1 vs DF-PU | 1.25 vs 1.75 | 0.006 | 0.025 | 1.15 vs 1.85 | 0.001 | 0.05 | |
| EBO-1 vs S-EM | 1.4 vs 1.6 | 0.498 | 0.05 | 1.15 vs 1.85 | 1E-04 | 0.025 |
关键发现:
- F-measure:所有三种Auto-PU系统在绝大多数情况下显著优于两个基线(DF-PU和S-EM),p值远小于0.05(经Holm校正)。
- Precision:Auto-PU系统显著优于基线,优势极为明显(如EBO-1 vs S-EM在δ=20%时p=2E-04)。
- Recall:基线方法在Recall上往往优于Auto-PU(表中未显示详细对比,但原文提及),这是因为基线方法倾向于过度预测正例,提高Recall但牺牲Precision,导致F-measure整体下降。
- 总体 :即使Auto-PU在最差情况下(δ=60%),其平均F-measure(0.666-0.681)仍高于基线最佳表现(S-EM平均0.634,DF-PU平均0.561)。
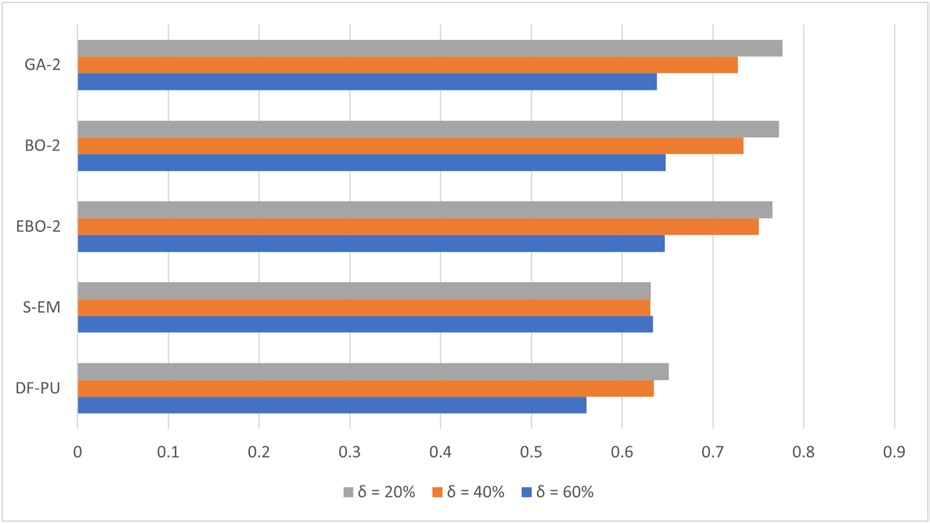
图4:Auto-PU系统与基线方法在不同δ值下的平均F-measure对比图
说明:包含5组柱状图(GA-1, BO-1, EBO-1, S-EM, DF-PU),每组3根柱子代表δ=20%,40%,60%。清晰显示Auto-PU系统(前三组)整体高于基线(后两组),且随δ增加性能下降幅度小于DF-PU。
7.2 扩展搜索空间结果(GA-2, BO-2, EBO-2)
扩展搜索空间增加了间谍技术相关超参数,搜索空间扩大154倍。
7.2.1 Auto-PU系统间对比
F-measure性能(表9):
| 数据集 | δ=20% | δ=40% | δ=60% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EBO-2 | BO-2 | GA-2 | EBO-2 | BO-2 | GA-2 | EBO-2 | BO-2 | GA-2 | |
| Alzheimer's | 0.559 | 0.580 | 0.548 | 0.597 | 0.603 | 0.576 | 0.581 | 0.492 | 0.529 |
| Autism | 0.964 | 0.963 | 0.982 | 0.938 | 0.937 | 0.940 | 0.887 | 0.914 | 0.927 |
| Breast cancer Coi. | 0.967 | 0.667 | 0.711 | 0.952 | 0.618 | 0.671 | 0.923 | 0.000 | 0.553 |
| Breast cancer Wis. | 0.882 | 0.959 | 0.956 | 0.863 | 0.942 | 0.936 | 0.839 | 0.889 | 0.866 |
| Breast cancer mut. | 0.666 | 0.890 | 0.896 | 0.655 | 0.853 | 0.739 | 0.587 | 0.845 | 0.872 |
| Cervical cancer | 0.867 | 0.867 | 0.867 | 0.904 | 0.867 | 0.839 | 0.516 | 0.839 | 0.350 |
| Cirrhosis | 0.506 | 0.497 | 0.446 | 0.493 | 0.515 | 0.397 | 0.322 | 0.472 | 0.204 |
| Dermatology | 0.857 | 0.876 | 0.901 | 0.891 | 0.841 | 0.896 | 0.750 | 0.795 | 0.692 |
| PI Diabetes | 0.668 | 0.653 | 0.642 | 0.665 | 0.648 | 0.646 | 0.607 | 0.615 | 0.634 |
| ES Diabetes | 0.957 | 0.954 | 0.978 | 0.905 | 0.891 | 0.887 | 0.915 | 0.912 | 0.894 |
| Heart Disease | 0.826 | 0.844 | 0.836 | 0.804 | 0.817 | 0.780 | 0.747 | 0.805 | 0.786 |
| Heart Failure | 0.741 | 0.757 | 0.751 | 0.656 | 0.652 | 0.670 | 0.514 | 0.600 | 0.671 |
| Hepatitis C | 0.907 | 0.964 | 0.944 | 0.907 | 0.761 | 0.863 | 0.689 | 0.612 | 0.610 |
| Kidney Disease | 0.911 | 0.976 | 0.925 | 0.897 | 0.976 | 0.951 | 0.656 | 0.789 | 0.806 |
| Liver Disease | 0.832 | 0.822 | 0.831 | 0.800 | 0.815 | 0.817 | 0.748 | 0.722 | 0.748 |
| Maternal Risk | 0.854 | 0.847 | 0.862 | 0.810 | 0.786 | 0.813 | 0.731 | 0.729 | 0.738 |
| Parkinsons | 0.914 | 0.936 | 0.935 | 0.850 | 0.837 | 0.843 | 0.720 | 0.800 | 0.792 |
| Parkinsons Biom. | 0.259 | 0.286 | 0.282 | 0.276 | 0.000 | 0.259 | 0.203 | 0.000 | 0.280 |
| Spine | 0.942 | 0.941 | 0.923 | 0.920 | 0.936 | 0.917 | 0.802 | 0.700 | 0.761 |
| Stroke | 0.232 | 0.256 | 0.241 | 0.225 | 0.255 | 0.239 | 0.201 | 0.233 | 0.243 |
| Average | 0.766 | 0.777 | 0.773 | 0.750 | 0.728 | 0.734 | 0.647 | 0.638 | 0.648 |
统计显著性(表10):
| δ | 对比系统 | F-measure | Precision | ||||
|---|---|---|---|---|---|---|---|
| 平均秩 | p值 | 调整α | 平均秩 | p值 | 调整α | ||
| 20% | GA-2 vs BO-2 | 1.5 vs 1.5 | 0.514 | 0.017 | 1.5 vs 1.5 | 0.647 | 0.05 |
| GA-2 vs EBO-2 | 1.38 vs 1.62 | 0.658 | 0.025 | 1.45 vs 1.55 | 0.632 | 0.025 | |
| BO-2 vs EBO-2 | 1.62 vs 1.38 | 0.825 | 0.05 | 1.52 vs 1.48 | 0.368 | 0.017 | |
| 40% | GA-2 vs BO-2 | 1.55 vs 1.45 | 0.729 | 0.05 | 1.52 vs 1.48 | 0.387 | 0.05 |
| GA-2 vs EBO-2 | 1.65 vs 1.35 | 0.039 | 0.017 | 1.7 vs 1.3 | 0.013 | 0.017 | |
| BO-2 vs EBO-2 | 1.52 vs 1.48 | 0.220 | 0.025 | 1.62 vs 1.38 | 0.297 | 0.025 | |
| 60% | GA-2 vs BO-2 | 1.4 vs 1.6 | 0.388 | 0.017 | 1.42 vs 1.58 | 0.387 | 0.025 |
| GA-2 vs EBO-2 | 1.5 vs 1.5 | 0.756 | 0.025 | 1.52 vs 1.48 | 0.702 | 0.05 | |
| BO-2 vs EBO-2 | 1.4 vs 1.6 | 0.956 | 0.05 | 1.6 vs 1.4 | 0.231 | 0.017 |
关键发现:
- δ=20%:三者性能相当,无显著差异。
- δ=40%:EBO-2在Precision上显著优于GA-2(p=0.013),这是扩展空间中唯一的统计显著差异。
- δ=60%:无显著差异。
- 总体:扩展空间未带来明显的性能提升,可能是因为间谍技术的有效性具有数据集依赖性,而Auto-ML系统学会了在不需要时禁用它(Spy_flag=False在73%的情况下被选中)。
7.2.2 与基线方法对比
扩展空间的Auto-PU系统同样显著优于基线方法(表11):
| δ | 对比系统 | F-measure | Precision | ||||
|---|---|---|---|---|---|---|---|
| 平均秩 | p值 | 调整α | 平均秩 | p值 | 调整α | ||
| 20% | GA-2 vs DF-PU | 1.1 vs 1.9 | 3E-05 | 0.025 | 1.05 vs 1.95 | 1E-04 | 0.025 |
| GA-2 vs S-EM | 1.2 vs 1.8 | 0.002 | 0.05 | 1.12 vs 1.88 | 0.001 | 0.05 | |
| BO-2 vs DF-PU | 1.1 vs 1.9 | 4E-05 | 0.025 | 1.05 vs 1.95 | 2E-04 | 0.025 | |
| BO-2 vs S-EM | 1.25 vs 1.75 | 0.003 | 0.05 | 1.08 vs 1.92 | 0.001 | 0.05 | |
| EBO-2 vs DF-PU | 1.2 vs 1.8 | 2E-04 | 0.025 | 1.1 vs 1.9 | 5E-05 | 0.025 | |
| EBO-2 vs S-EM | 1.3 vs 1.7 | 0.001 | 0.05 | 1.05 vs 1.95 | 8E-05 | 0.05 | |
| 40% | GA-2 vs DF-PU | 1.3 vs 1.7 | 0.027 | 0.05 | 1.12 vs 1.88 | 0.003 | 0.025 |
| GA-2 vs S-EM | 1.2 vs 1.8 | 0.011 | 0.025 | 1.18 vs 1.82 | 0.005 | 0.05 | |
| ... | ... | ... | ... | ... | ... | ... |
注:限于篇幅,仅展示部分结果,完整结果见原文Table 13
一致性结论:无论使用基础还是扩展搜索空间,Auto-PU系统均显著优于传统基线方法。
7.3 超参数选择模式分析
分析Auto-PU系统学到的最优配置,发现以下规律(表12-14):
7.3.1 分类器选择偏好
Phase 1A分类器:
- GA-1:最频繁选择高斯朴素贝叶斯(12.67%,比随机基线高7.11%)
- BO-1:最频繁选择伯努利朴素贝叶斯(8.67%)和逻辑回归
- EBO-1:最频繁选择逻辑回归和LDA
- GA-2:最频繁选择随机森林(非线性,比基线高16.67%)
- 总体:偏好简单线性分类器(NB、LR、LDA),符合两步法的平滑性与可分离性假设
Phase 2分类器:
- LDA 和深度森林 是 recurrent 选择:
- BO-1(基础):LDA占32.67%(比基线高27.11%)
- BO-2(扩展):LDA占51.67%(比基线高46.11%)
- EBO-1:随机森林
- EBO-2:深度森林(10.67%)
- 解释:Phase 2需要区分已确定的正负例,可使用更复杂模型
7.3.2 Phase 1B使用模式
- Flag_1B (是否启用Phase 1B):
- GA-1:True占47.67%(接近随机)
- BO-1:True占52.67%
- EBO-1:True占59.67%
- 结论:Phase 1B的使用高度依赖数据集,无统一最优策略
7.3.3 间谍技术使用模式
- Spy_flag (是否使用间谍技术):
- GA-2:False占73.33%(比基线高23.33%)
- BO-2:False占74.00%(比基线高24.00%)
- EBO-2:False占65.67%(比基线高15.67%)
- 结论:尽管间谍技术在PU文献中被广泛使用,但Auto-ML系统发现它并非总是必要,甚至在多数情况下不启用更优。这验证了Auto-ML的价值------避免人类偏见,数据驱动选择。
7.3.4 类别不平衡处理
分析Phase 1A迭代次数与数据集类别不平衡(正例比例)的关系(表15):
| 方法 | δ=20% | δ=40% | δ=60% |
|---|---|---|---|
| GA-1 | -0.646 | -0.655 | -0.689 |
| GA-2 | -0.631 | -0.687 | -0.723 |
| BO-1 | -0.677 | -0.700 | -0.700 |
| BO-2 | -0.641 | -0.706 | -0.736 |
| EBO-1 | -0.656 | -0.688 | -0.696 |
| EBO-2 | -0.680 | -0.710 | -0.687 |
发现 :所有方法均显示中度到强负相关(r≈-0.65至-0.74)。即:数据集越不平衡(正例比例越低),系统越倾向于选择更高的迭代次数(将未标记集划分为更多子集),以防止Phase 1A分类器被大量未标记样本淹没。
8 结论与未来工作
8.1 主要贡献
本文提出了两种高效的Auto-PU系统:
-
BO-Auto-PU:纯贝叶斯优化方法,通过随机森林代理模型将计算开销降低27倍(从226分钟降至8.4分钟),同时保持与遗传算法相当的预测精度。
-
EBO-Auto-PU:进化贝叶斯混合方法,结合代理模型效率与遗传算法多样性,计算开销降低10倍(24.2分钟),在F-measure和Precision上往往优于纯BO方法,特别是在δ=40%场景下显著优于GA(Precision p=0.013)。
核心优势:
- 精度:所有Auto-PU系统均显著优于基线S-EM和DF-PU(Wilcoxon检验,p<0.05)
- 效率:BO和EBO方法将Auto-ML for PU Learning从"离线研究工具"转变为"实用生产技术"
- 洞察:发现间谍技术并非总是必要(73%情况下禁用),以及系统能自动适应类别不平衡(迭代次数与正例比例负相关r≈-0.7)
8.2 实际应用建议
- 快速原型:选择BO-Auto-PU(8.4分钟),在极短时间内获得优于手工调参的结果
- 生产环境:选择EBO-Auto-PU(24.2分钟),在可接受时间内获得接近最优的性能
- 研究方向:如需绝对最优且时间充裕,可使用GA-Auto-PU,但考虑到EBO已接近其性能,通常不推荐
8.3 局限与未来方向
-
超参数调优:当前Auto-PU系统自身的超参数(如k=10,交叉概率0.9)为固定值,未来可使用元学习(Meta-Learning)或自动调参技术优化这些"超-超参数"。
-
框架扩展:当前基于两步法框架,未来可探索其他PU学习范式(如有偏学习Biased Learning、类别先验方法)的Auto-ML化。
-
冷启动优化:当前使用随机初始化,未来可利用元特征(Meta-Features)或迁移学习,基于相似数据集的配置加速新数据集的优化。
-
多目标优化:当前仅优化F-measure,未来可同时考虑训练时间、模型复杂度等多目标,使用Pareto优化提供配置选项。